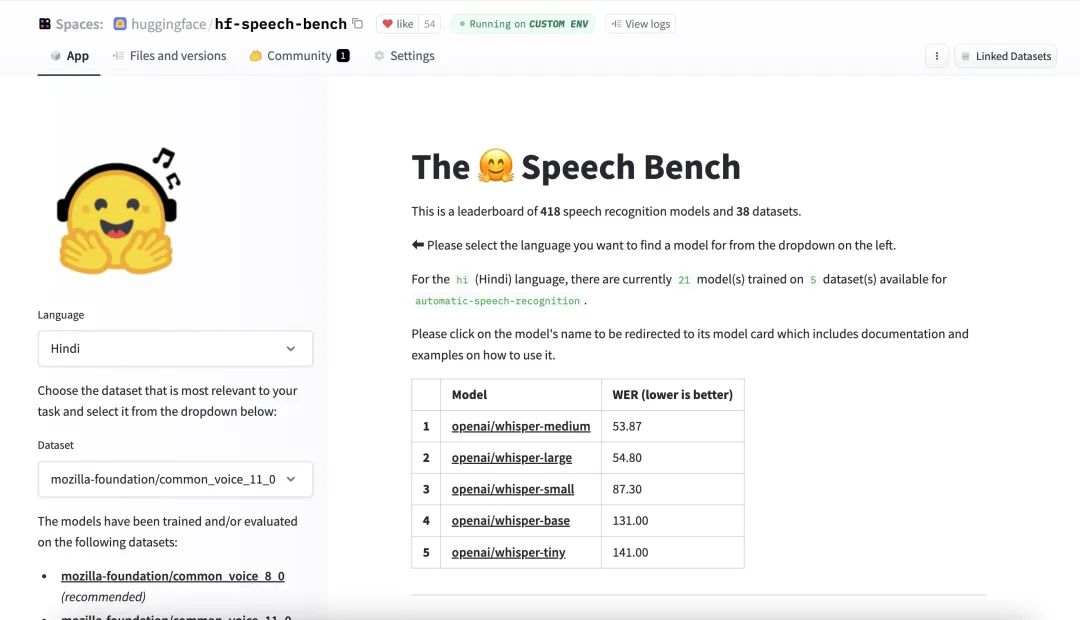
ESP8266
python兼职
left join
1024
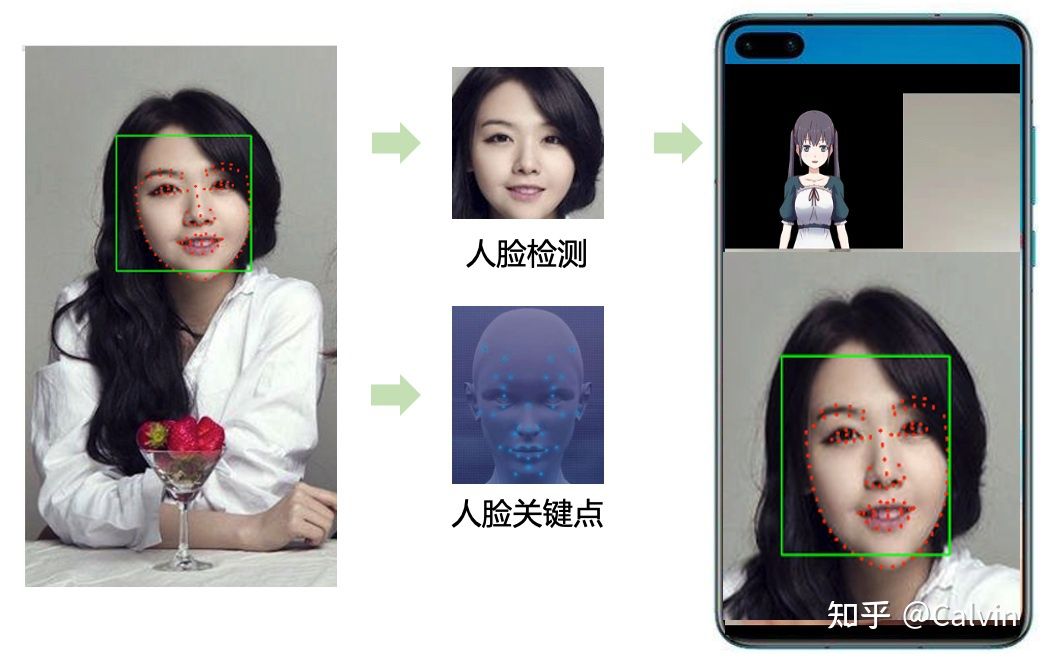
人脸识别
美食论坛系统
DASCTF2022十月挑战赛
正则
滤波器
tokenizer
Impala
CyclicBarrier
pthread
redux
光照度传感器
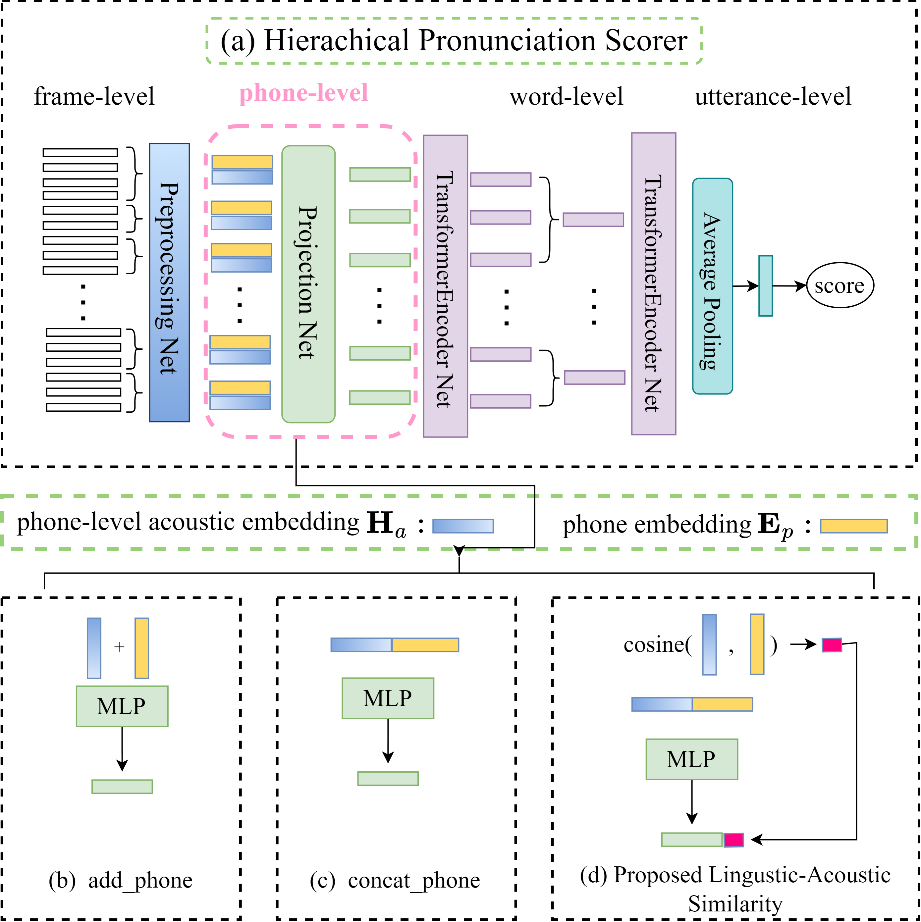
大模型
光纤光栅
removebg
西枢纽
小世界网络
语音识别
2024/4/11 14:30:21
南洋才女,德艺双馨,孙燕姿本尊回应AI孙燕姿(基于Sadtalker/Python3.10)
孙燕姿果然不愧是孙燕姿,不愧为南洋理工大学的高材生,近日她在个人官方媒体博客上写了一篇英文版的长文,正式回应现在满城风雨的“AI孙燕姿”现象,流行天后展示了超人一等的智识水平,行文优美,绵恒隽永&…

国际语音群呼系统的产品优势有哪些?为什么要使用国际语音群呼系统?
一、国际语音群呼系统的产品优势:
1.巨量群呼
支持大容量并发群呼,呼叫不受限制,充裕的线路保障造就百万级平台容量,可以短时间内同时拨打大量电话,让语音快速到达,大大提高发送效率;
2.自主…

Web1.0——Web2.0时代——Web3.0
Web1.0
Web1.0是互联网的早期阶段,也被称为个人电脑时代的互联网。在这个阶段,用户主要通过web浏览器从门户网站单向获取内容,进行浏览和搜索等操作。在这个时代,技术创新主导模式、基于点击流量的盈利共通点、门户合流、明晰的主…

如何在线文字转语音?
截止2020年12月,我国短视频用户达到了8.73亿,占整体网民的88.3%。由于门槛低、传播性广更容易受到用户接受。随着用户量增加,越来越多的创作者内容也从图文转向短视频创作。
零基础如何入手短视频?
文案、拍摄、剪辑、配音是做短…
paddlespeech asr语音转录文字;sherpa 实时语音转录
1、paddlespeech asr语音转录文字
参考: https://github.com/PaddlePaddle/PaddleSpeech
安装后运行可能会numpy相关报错;可能是python和numpy版本高的问题,我这里最终解决是python 3.10 numpy 1.22.0;
pip install paddlepadd…

这么火的录音转文字软件,你用过吗?
录音转文字功能是很多人的刚需,不管是需要将会议内容转换成文字,还是将课程录音转换成文档,这些都需要用到录音转文字工具。当然,录音转文字,你最担心什么?好好想想,是不是担心自己的格式不能转…
【Matlab语音处理】音频信号提取分析【含GUI源码 1738期】
一、代码运行视频(哔哩哔哩)
【Matlab语音处理】音频信号提取分析【含GUI源码 1738期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,…
【Matlab语音处理】音频信号FIR+IIR(高通+低通+带通)滤波器频谱分析【含源码 1732期】
一、代码运行视频(哔哩哔哩)
【Matlab语音处理】音频信号FIRIIR(高通低通带通)滤波器频谱分析【含源码 1732期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第…
【Matlab语音处理】汉宁窗FIR陷波滤波器语音信号加噪去噪【含GUI源码 1711期】
一、代码运行视频(哔哩哔哩)
【Matlab语音处理】汉宁窗FIR陷波滤波器语音信号加噪去噪【含GUI源码 1711期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学…
【Matlab语音处理】低通滤波器语音信号加噪与去噪【含GUI源码 1708期】
一、代码运行视频(哔哩哔哩)
【Matlab语音处理】低通滤波器语音信号加噪与去噪【含GUI源码 1708期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社…

元宇宙密室逃脱游戏攻略来啦!
今天还是数字人小杜如果有一款线上 PC 端游戏,不用安装下载,一秒登入,且在开头5分钟就甚至能撸出大致结局,你会去玩吗?今晚我在 Vland 元宇宙空间,体验语音版的密室逃脱。LetmeOut密室逃脱无界社区 Mixlab …
【Matlab语音识别】DWT算法0~9数字语音识别【含源码 1726期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】DWT算法0~9数字语音识别【含源码 1726期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社ÿ…

android实现调用科大讯飞语音识别功能详细步骤
一、申请注册科大用户和下载SDK(里面的appid要和自己的一样才可以使用)
详细步骤就不写了,注册网址:http://www.xfyun.cn
二、注册完之后,点击创建应用-选择要使用的平台和选择自己所要实现的功能,点击下…
简单搭建whisper模型完成语音识别
主要步骤
安装Anaconda安装python环境安装ffmpeg用于解析音频视频测试(两种方法)
安装Anaconda(不做介绍)
安装python环境 建议建个新环境,避免和旧环境冲突 conda create -n whisper_env python3.8进入环境 conda …
【Matlab语音处理】录音信号时域频域分析(带面板)【含GUI源码 064期】
一、代码运行视频(哔哩哔哩)
【Matlab语音处理】录音信号时域频域分析(带面板)【含GUI源码 064期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版ÿ…

语音芯片的“等级”之分
语音芯片,你或许不晓得这个“芯”也是有高低之分,你可能听说过手机“发烧级”高性能芯片,同样在语音芯片中存在着性能不同等级的语音芯片。一般我们将普通芯片主要分为3个等级:商业级(又称民用级)、工业级和…
![[Unity+OpenAI TTS] 集成openAI官方提供的语音合成服务,构建海王暖男数字人](https://img-blog.csdnimg.cn/a006eaca336d496a986ed7ea9d2a2c32.png)
[Unity+OpenAI TTS] 集成openAI官方提供的语音合成服务,构建海王暖男数字人
1.简述 最近openAI官方发布了很多新功能,其中就包括了最新发布的TTS语音合成服务的api接口。说到这个语音合成接口,大家可能会比较陌生,但是说到chatgpt官方应用上的聊天机器人,那个台湾腔的海王暖男的声音,可能就有印…

智能家居语音控制系统的设计与实现
1 项目概况
1.1 背景和基础
通过人工智能,大数据,云计算,5G等多项技术驱动下,智能家居开始进入快速发展的阶段,逐渐代替了传统家居。在2019年的政府工作报告中,明确政策导向已经证明了“智能”在我国的前…

前端未来的发展前景如何?
从疫情暴发到现在,各行各业都开始线上办公,而线上工作就需要有前端后端
从电脑到手机,再到可穿戴设备等一切移动终端都需要有交互式来驱动。 从VR看房、VR装修、AI机器人到手机厂商的智慧大屏都需要前端技术的支持。 如果说以前Web 应用更多…
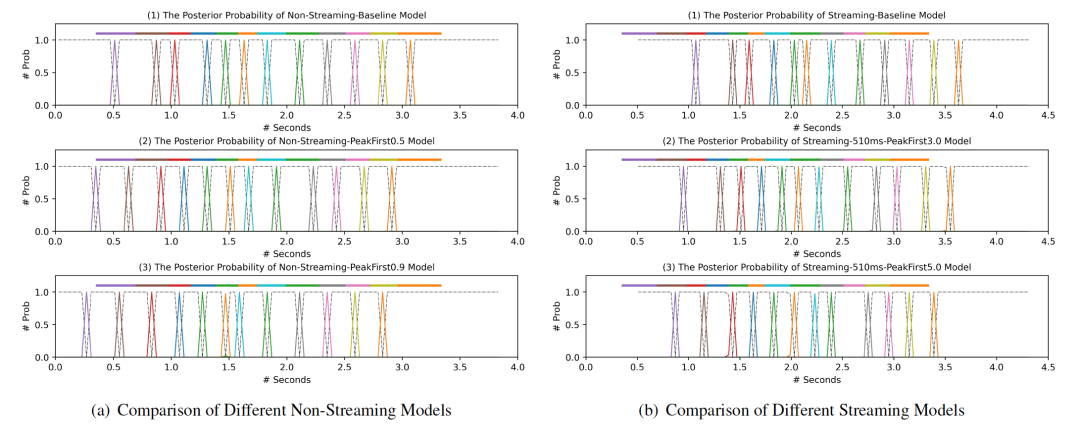
低延迟流式语音识别技术在人机语音交互场景中的实践
美团语音交互部针对交互场景下的低延迟语音识别需求,提出了一种全新的低出字延迟流式语音识别方案。本方法将降低延迟问题转换成一个知识蒸馏过程,极大地简化了延迟优化的难度,仅通过一个正则项损失函数就使得模型在训练过程中自动降低出字延…
AI语音机器人可以为企业提供什么工作效率?ai机器人源码
AI语音机器人是一种基于人工智能技术的语音交互系统,能够通过自然语言理解和语音合成技术实现与用户的智能对话。AI语音机器人可以为企业提供以下方面的帮助,从而提高工作效率: 自动客服:AI语音机器人可以代替人工客服完成一些简单…
【小沐学Python】Python实现TTS文本转语音(speech、pyttsx3、百度AI)
文章目录 1、简介2、Windows语音2.1 简介2.2 安装2.3 代码 3、pyttsx33.1 简介3.2 安装3.3 代码 4、ggts4.1 简介4.2 安装4.3 代码 5、SAPI6、SpeechLib7、百度AI8、百度飞桨结语 1、简介
TTS(Text To Speech) 译为从文本到语音,TTS是人工智能AI的一个模组…
小程序语音聊天_如何将语音消息集成到您的流聊天应用程序中
小程序语音聊天A voice message is a message containing audio of one’s voice. They have been around for quite a while and have been widely adopted by users around the world as a convenient way of sending normal or time-sensitive messages.语音消息是包含一个人…

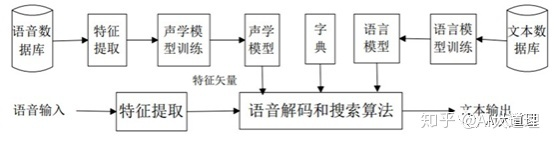
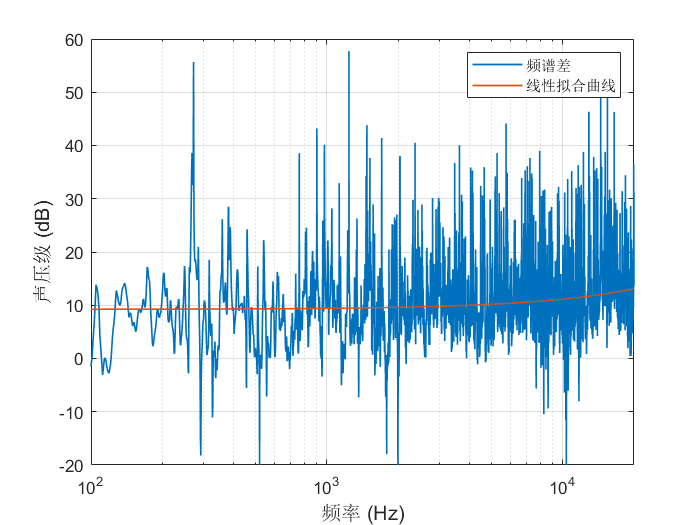
语音(八)——GMM-HMM声学模型
语音(八)——GMM-HMM声学模型 语音(九)——基于GMM-HMM的连续语音识别系统 语音(十)——N-gram语言模型 语音(十一)——WFST解码器(上) 语音(十二…

人工智能Java SDK:TTS 文本转为语音
TTS 文本转为语音
注意: 为了防止克隆他人声音用于非法用途,代码限定音色文件只能使用程序中给定的音色文件。 声音克隆是指使用特定的音色,结合文字的读音合成音频,使得合成后的音频具有目标说话人的特征,从而达到克隆的目的。 …
无论是数字经济还是元宇宙,虚拟人的交互已经成为迫切要解决的问题
封面:在元宇宙中,人们都有一个“虚拟人”的身份,能不能介绍下目前“虚拟人”技术的发展情况? 娄超:其实除了语音应用,我们还有多维信息、多模信息的相互融合和识别技术。例如,我们把语音识别、人…
自训练和与预训练在语音识别中的互补
Self-training and Pre-training are Complementary for Speech Recognition自训练和与预训练在语音识别中的互补 分析

梨花声音研修院,严肃与刚毅是音色核心
在为军旅剧提供配音服务时,配音员需捕捉并展现军事场合的严肃气氛、军人的刚毅品质以及他们对职责的忠诚。军旅剧往往围绕着军人的日常生活、战场经历、战友之情以及对祖国的热爱等主题展开,所以配音需能传递这些情感和价值。以下是进行军旅剧配音的一些…

语音识别技术在医疗行业中的应用案例
随着语音识别技术和计算机视觉技术的不断提高,现代医学正在进入全面数字化时代。 追求高质量的训练数据是人工智能产业的信条,得到更为精准的语音机器模型更离不开语音数据的不断供给。本文讲介绍:
什么是语音识别技术语音识别技术如何应用于医疗行业
…
人工智能可能会过度干预人类,甚至深度介入人类情感
从实战中,建立更可靠的情感纽带关系,仍然是小冰框架所能提供的重点。李笛以汽车为例——前几年大家所看到的汽车里面的智能座舱的体验基本上是面向司机的,主要以向司机提供服务、帮助司机更好的通过语音的方式来实现很多功能,以这…

回顾丨2023 SpeechHome 第三届语音技术研讨会
下面是整体会议的内容回顾:
18日线上直播回顾
18日上午9:30,AISHELL & SpeechHome CEO卜辉宣布研讨会开始,并简要介绍本次研讨会的筹备情况以及报告内容。随后,CCF语音对话与听觉专委会副主任、清华大学教授郑方,…
最新ChatGPT网站系统源码+AI绘画系统+支持GPT语音对话+详细图文搭建教程/支持GPT4.0/H5端系统/文档知识库
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…
2021-10-10
Speech recognition——陈果果——深蓝目前语言领域(包括语言识别、唤醒)的进展,以及实际落地中遇到的困难? 唤醒:小度、亚马逊 >> 二级系统、一级系统;低功耗芯片语言识别: 挑战…
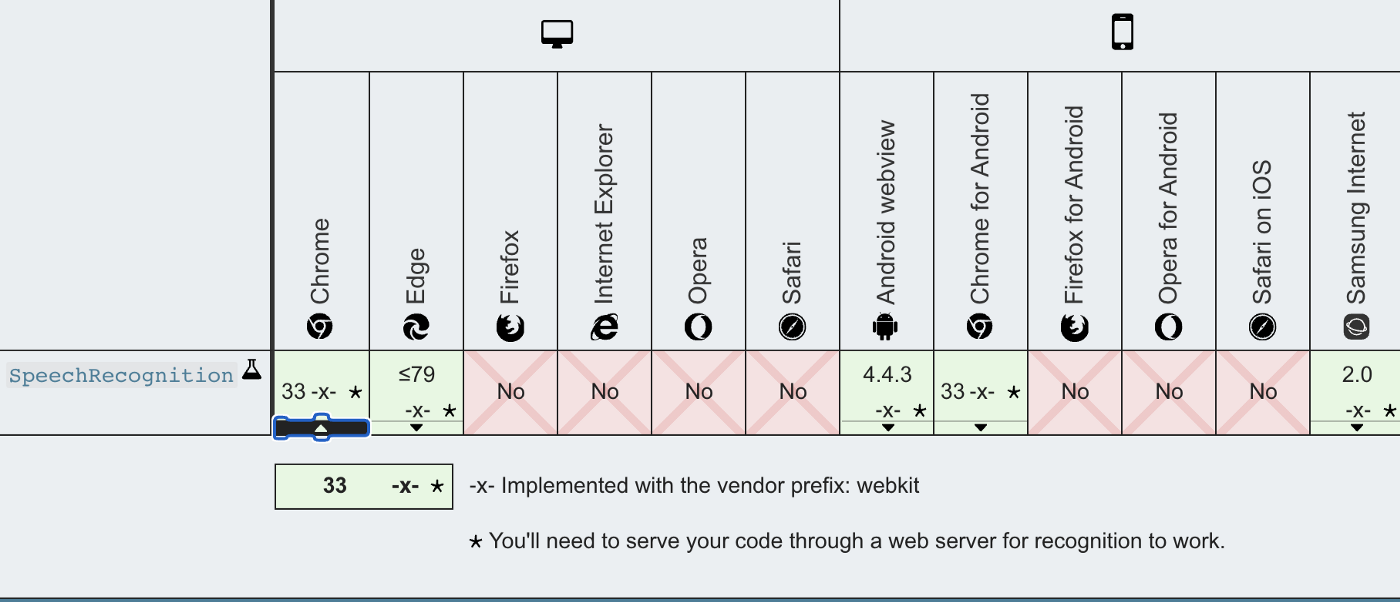
在Javascript应用程序中执行语音识别
语音识别是计算机科学和计算语言学的一个跨学科子领域。它可以识别口语并将其翻译成文本,它也被称为自动语音识别(ASR),计算机语音识别或语音转文本(STT)。
机器学习(ML)是人工智能…
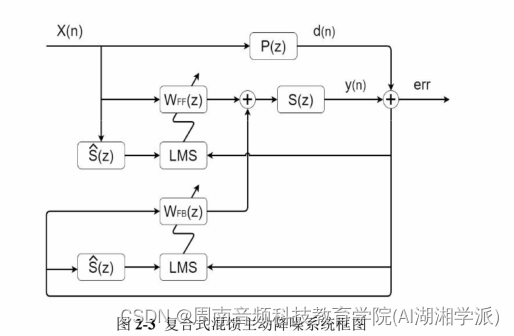
混合式ANC主动降噪耳机系统设计(含C源代码)
混合式ANC主动降噪耳机系统设计(含C源代码) 是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,+群赠送语音信号处理降噪算法,蓝牙音频,DSP音频项目核心开发资料, 1 FF信号链路与FB 链路算法处理上一样
X(n)为噪声输…
语音房交友app开发丨语音房交友app都需要哪些功能?
语音房APP是一种强大的工具,为用户提供了与他人进行语音交流的平台。它的功能和特性直接决定了用户体验的质量,因此在开发过程中需要考虑到用户的需求和期望。本文将介绍语音房APP开发中需要考虑的一些重要功能。
首先,语音房APP应该具备高质…
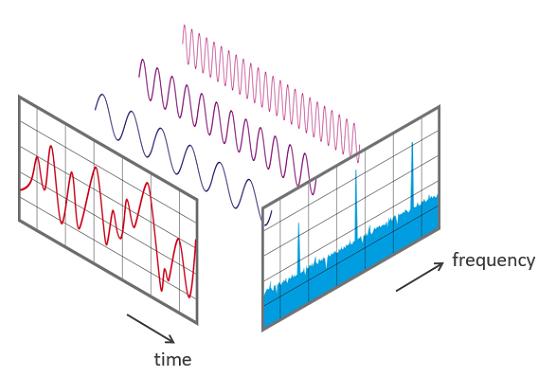
人工智能Java SDK:TacotronSTFT 提取mel(梅尔)频谱
TacotronSTFT 提取mel(梅尔)频谱
为什么tacotron生成语音时需要先生成Mel(梅尔)频谱? 一般认为语音的频域信号(频谱)相对于时域信号(波形振幅)具备更强的一致性(相同的发音频谱上表现一致但波形差别很大&a…
语音领域的几个特征的含义
F0(音高相关)
在语音信号处理中,F0代表基频(Fundamental Frequency),也被称为音高或声音的基本频率。基频是指声音波形中最低频率的周期性振荡,它决定了人的声音听起来是低音还是高音。基频通常…
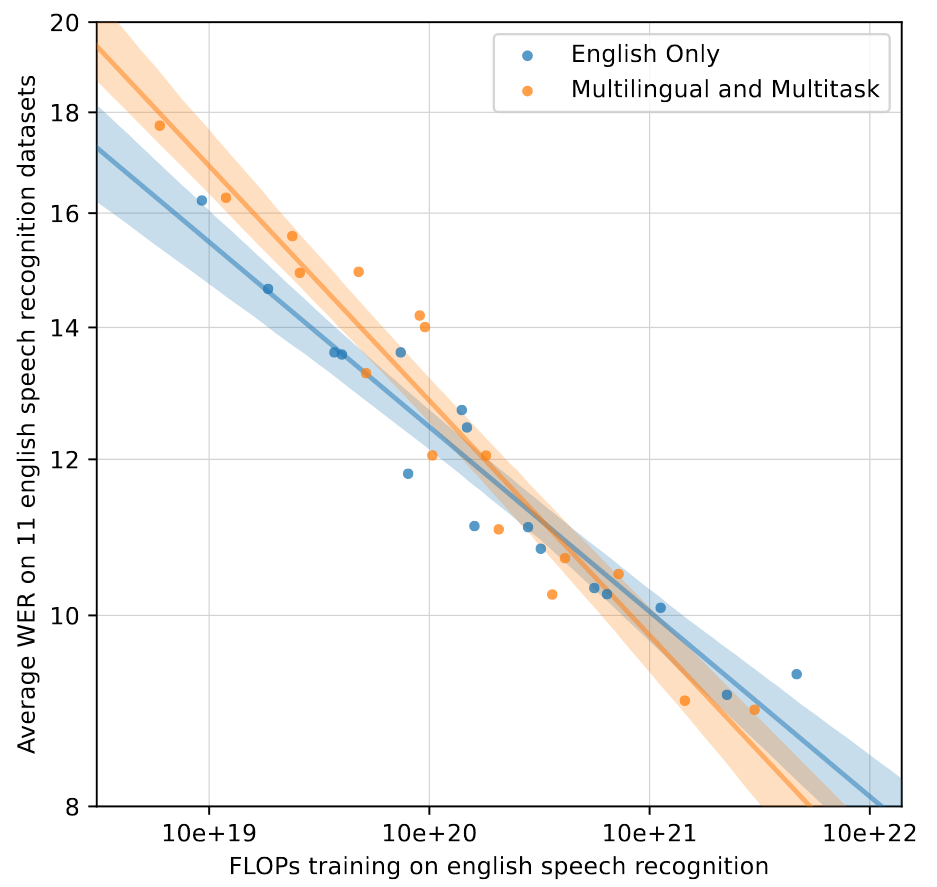
【论文精读】Robust Speech Recognition via Large-Scale Weak Supervision
Robust Speech Recognition via Large-Scale Weak Supervision 前言Abstract1. Introduction2. Approach2.1. Data Processing2.2. Model2.3. Multitask Format2.4. Training Details 3. Experiments3.1. Zero-shot Evaluation3.2. Evaluation Metrics3.3. English Speech Reco…

Spring Cloud入门系列(十一)- 服务熔断与降级之Hystrix(已停更,建议切换到Sentinel)
前言
服务降级,既可以配置在客户端,也可以配置在服务端,需要根据具体的业务需求,进行灵活配置。
本文模拟的情况,是在服务端80进行配置。
服务降级
服务降级,是通过注解 HystrixCommand 来实现的。
/*…
【人工智能】大模型之编码器基础知识
【人工智能】大模型之编码器基础知识 文章目录 【人工智能】大模型之编码器基础知识1. 引言2. 技术原理及概念2.1 基本概念解释2.2 技术原理介绍一、自注意力机制二、编码器的基本工作流程三、代码示例2.3 相关技术比较3. 实现步骤与流程3.1 准备工作:环境配置与依赖安装3.2 核…
前置语音群呼与语音机器人群呼哪个更好
最近通过观察自己接到的营销电话,通过语音机器人外呼的量应该有所下降。同时和客户交流获取到的信息,也是和这个情况类似,很多AI机器人群呼的量转向了OKCC前置语音群呼。询问原因,说是前置语音群呼转化更快,AI机器人群…

利用微软接口制作的文字转语音神器Read Aloud
最近心血来潮又把抖音(菊部创意)用起来了,偶尔会传一些电脑/手机录屏,基本上也就是一些曾经分享过的好用的软件的实操,有兴趣的朋友可以关注一下,也帮忙提提意见。
看到别人总是用一些语音解说类的操作&am…

离线语音通断器开发-稳定之后顺应新需求
使用云知声的US516p6方案开发了一系列的离线语音通断器,目前已经取得了不小的收获,有1路的,3路的,4路的,唛头和扬声器包括唛头线材也在不断的更新打磨中找到了效果特别好的供应商。
离线语音通断器,家用控…
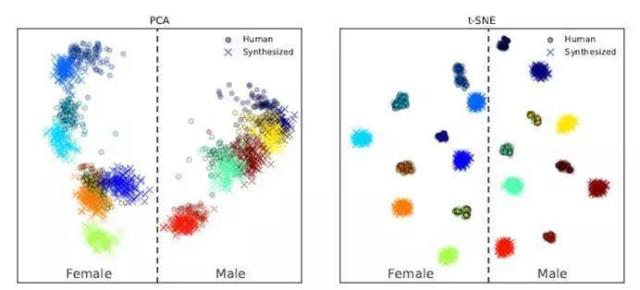
人工智能Java SDK:音特征编码器提取特征向量
音特征编码器提取特征向量
Google 团队提出了一种文本语音合成(text to speech)神经系统,能通过少量样本学习到多个不同说话者(speaker)的语音特征, 并合成他们的讲话音频。此外,对于训练时网络…

WebDAV之π-Disk派盘 + 读出通知
手机各种推销通知太多,如何避免那些繁琐的通知内容,做出一键就能够阅读重要通知的最佳体验,帮助您更加快速和便捷的体验到那些应用内容?推荐大家使用读出通知。 读出通知APP可以设置接收通知的app,还可以用耳机操作,操作简单,你还可以指定播报设备,还有播报的声音的设置…
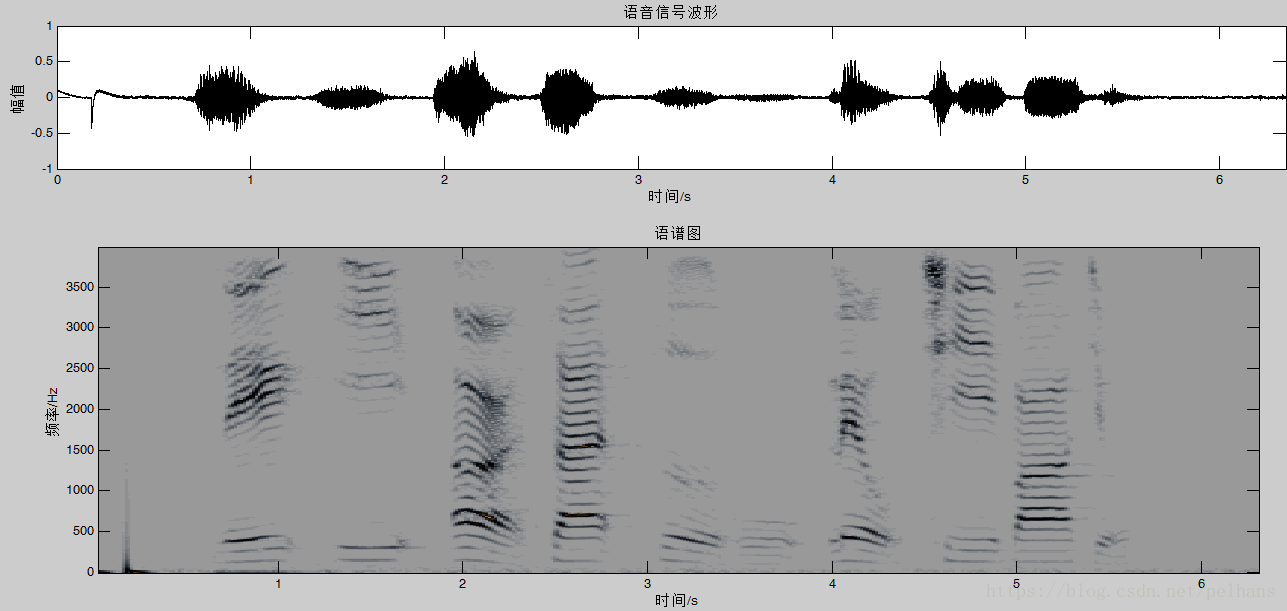
现代语音信号处理笔记 (三)
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本节针对《现代语音信号处理》这本书的第四章,对应短时傅里叶分析部分。 时域分析
傅里叶分析是分析线性系统和平稳信号稳态特性的有力手段,这种以复指数函数…

语音识别系列之脉冲神经网络特征工程
人工神经网络(Artificial Neural Network, ANN)中的单个人工神经元是对生物神经元的高度抽象、提炼和简化,模拟了后者的若干基本性质。得益于误差反向传播算法,网络权重可根据设定的目标函数得到有效地调整,ANN在视觉、…
智能环境与可持续发展:人工智能为地球未来添翼
导言 在全球迅速发展的背景下,人工智能技术的应用逐渐深入到环境保护和可持续发展领域。随着全球环境问题的加剧,人工智能技术在环境和可持续发展领域的应用成为推动绿色未来的关键力量。本文将深入探讨人工智能在智能环境中的角色,以及如何通…

windows10或ubuntu系统下,中文音频转汉字
目录
1.安装开源库;
2.下载中文model(也可以先不下载) 3.使用转换 4. 效果展示 (唠嗑)出发背景:我听到一段长达一小时的音频,里面讲的特别好,我就想下载转成文字再看看,可是用软件超1分钟就要…
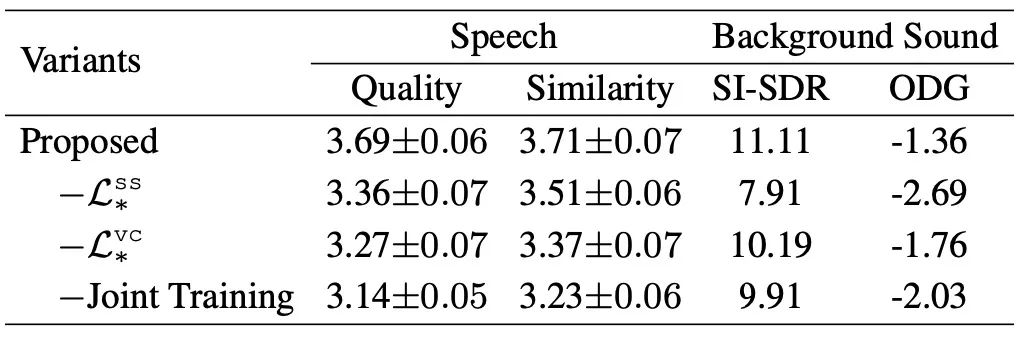
ICASSP2023 | 基于多任务学习的保留背景音的语音转换
在影视、有声书内容中,背景音是一种表现丰富的艺术形式。语音转换(Voice Conversion)如能将源说话人语音转换成目标说话人语音的同时,保留源语音中的背景音,将会提供更沉浸的语音转换体验。之前的语音转换研究主要关注…
初识马尔科夫模型(Markov Model)
初识马尔科夫模型(Markov Model)一、概念二、性质三、学习步骤一、概念
马尔科夫模型(Markov Model)是一种概率模型,用于描述随机系统中随时间变化的概率分布。马尔科夫模型基于马尔科夫假设,即当前状态只…
巴别塔再现?高质量端到端数据助力Meta推出AI模型SeamlessM4T
追求卓越与无限的精神一直流淌在人类的基因里。圣经中有故事:在古代,人们说着同一种语言,决定建造一座高耸入云,塔顶能触及天堂的塔,被称为巴别塔,以彰显人类的力量和创造力。然而上帝看到人类的意图&#…
基础课18——智能客服系统架构
1.基础设施层
基础设施主要包括以下几点:
1. 硬件设施:包括服务器、存储设备、网络设备等,这是整个系统运行的物理基础。 2. 软件设施:包括操作系统、数据库管理系统、自然语言处理(NLP)工具和机器学习算法等,这些是…
语音机器人的两种常见业务场景
第一个业务场景
之前写过一篇语音机器人是真人录音好,还是TTS转语音更好的文章。今天再来说一说TTS一个很细微的场景。
假设一句话
这里是*****银行委托机构,您在*****银行的信用卡长期逾期至今仍未依照约定履行还款义务,为避免逃废债给您…

科研快讯 | 14篇论文被信号处理领域顶级国际会议ICASSP录用
ICASSP 2023
近日,2023年IEEE声学、语音与信号处理国际会议(2023 IEEE International Conference on Acoustics, Speech, and Signal Processing,ICASSP 2023)发布录用通知,清华大学人机语音交互实验室(TH…
发布 Copilot Chat Sample App
我们很高兴为您介绍 Semantic Kernel 的 Copilot Chat Sample App!借助此应用程序,开发人员可以使用自然语言处理、语音识别和文件上传等高级功能轻松构建自己的聊天机器人。通过利用基于 LLM 的 AI,您可以通过 Semantic Kernel 使用您自己的…
信息时代的必修课:信息压缩比和失真率之间的平衡原则
文章目录 引言I 预备知识1.1 香农第一定律1.2 哈夫曼编码1.3 利用信息等价性原理进行信息压缩1.4 利用相关性进行压缩编码1.5 失真度1.6 高比例的信息压缩,丢失了高频信息II 信息压缩2.1无损压缩2.2 有损压缩III 压缩比和失真率平衡原则3.1 做事的目的性3.2 丢失部分信息,会增…

基础课15——语音标注
语音数据标注是对语音数据进行处理和分析的过程,目的是让人工智能系统能够理解和识别语音中的信息。这个过程包括了对语音信号的预处理、特征提取、标注等步骤。
在语音数据标注中,标注员需要对语音数据进行分类、切分、转写等操作,让人工智…
C#使用System.Speech制作语音提示功能
c#实现语音阅读以及文本转语音文件是基于c#的一个类库(SpeechSynthesizer )实现的 1.添加引用: 使用该类必须要添加引用using System.Speech.Synthesis 直接是无法添加引用的,先对项目进行添加引用 2.语音朗读 SpeechSynthes…

ASRPRO语音识别模块
ASRPRO语音识别模块
SOFT IIC 与PCA9685模块通信
pca9685 iic通信 地址位 ADDR<<1|0 左移一位 #define I2C_WRITE 0
#define I2C_READ 1
否则通信地址错误
asrpro
通过UART与电脑连接,可以进行简单的交互
将STM32作为接口扩展,通过SPI或I…
多篇论文入选ICASSP 2023 火山语音有效解决多类实践问题
近日由IEEE主办、被誉为世界范围内最大规模、也是最全面的信号处理及其应用方面的顶级学术会议ICASSP2023于希腊召开,该会议具有权威、广泛的学界以及工业界影响力,备受AI领域多方关注。会上火山语音多篇论文被接收并发表,内容涵盖众多前沿领…
顶顶通电话机器人接口对接开源ASR(语音识别)
前景介绍
目前大部分用户使用的都是在线ASR按照分钟或者按次付费,之前开源ASR效果太差不具备商用的条件,随着 阿里达摩院发布了大量开源数据集或者海量工业数据训练的模型,识别效果已经和商用ASR差距非常小,完全具备了很多场景代…
【Matlab语音处理】语音原始信号+变速信号时域频域分析(带面板)【含GUI源码 294期】
一、代码运行视频(哔哩哔哩)
【Matlab语音处理】语音原始信号变速信号时域频域分析(带面板)【含GUI源码 294期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第…
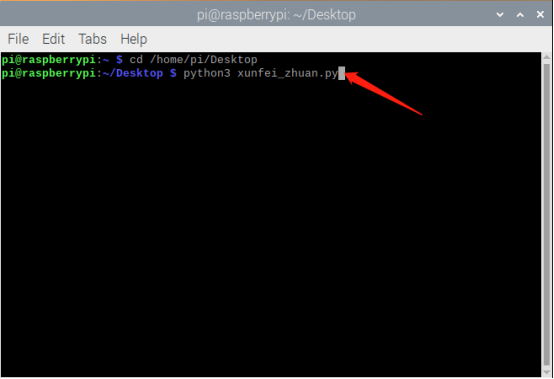
在树莓派中写入科大讯飞语音转文字识别程序
在树莓派桌面里新建一个xunfei_zhuan.py文件,然后打开文件,然后使用默认软件编程
点击terminal,在里面使用以下命令安装cffi1.12.3库
pip3 install cffi1.12.3使用以下命令安装gevent1.4.0库
pip3 install gevent1.4.0使用以下命令安装g…
android 语音唤醒,录音并识别
在百度语音SDKDemo的基础上保存语音并进行识别
项目参考 https://ai.baidu.com/ai-doc/SPEECH/Ek39uxgre 最近在做公司的一个项目,基于百度的语音识别技术,做了一个API开放平台,准备在里面添加一部分自己的功能,对应的,平台做了就需要考虑提供配套的调用功能,在这里分享…
树莓派基于语音活性检测VAD的应用
如果你想尝试用树莓派打造一款语音对话机器人,那么你肯定避免不了一点,录音!
前言: 我之前的文章中提到过alsa的arecord录制,录音时间固定,当程序运行一次后就会出现arecord资源被占用的情况,除…
解放双手,这款音频转文字工具实在太香了
工作时,最头疼的就是将音频文件转化为文字。不是工作有多复杂,而且需要反复听录音,修改文本,实在太难了。有没有快速将文件转化成文本的技巧?给大家推荐AI智能识别工具。只需要将文件上传到工作框,一键自动…

有什么软件可以把文字变成语音?声音多点更好了
文字转语音用到就是AI智能功能,基于深度的学习技术,给用户提供了流畅、自然的发音服务。很多用户在线使用传统的配音工具时,经常遇到发音机械、选择主播有限、广告众多等各种缺点。选择知意配音的优点实在太多了简直不要套多,海量…
利用人类医生学习曲线 构建医学人工智能学习模式
2020年6月23日,林浩添教授和刘西洋教授及其团队面向媒体发布了这一重磅研发成果。 图像标注是所有人工智能算法感知世界的基础。但是,既往诊断算法常使用单一图片级二分类标注方法进行数据集构建,损失了大量有效解剖学信息。团队观察到&#…
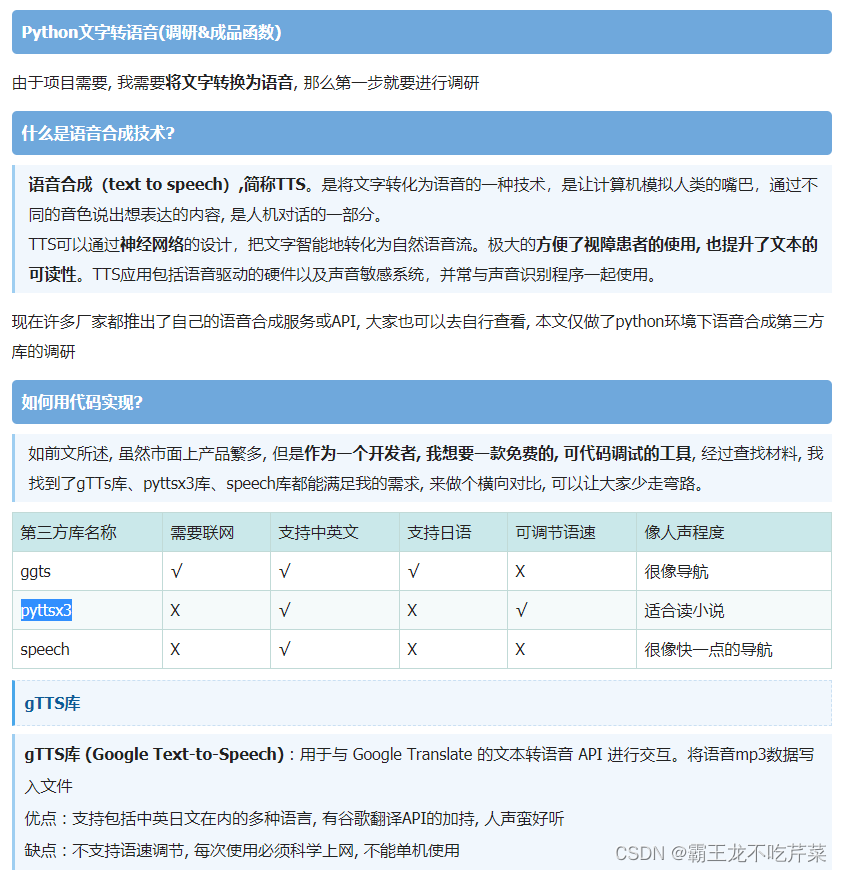
关于python 语音转字幕,字幕转语音大杂烩
文字转语音 Python语音合成之第三方库gTTs/pyttsx3/speech横评(内附使用方法)_python_脚本之家 代码示例 from gtts import gTTStts gTTS(你好你在哪儿!,langzh-CN)tts.save(hello.mp3)import pyttsx3engine pyttsx3.init() #创建对象"""语速"…
语音(六)——混合高斯模型(GMM)
语音(六)——混合高斯模型(GMM) 语音(附六)——EM算法
语音(一)| 语音识别基础(深度解析)
1 声音特性
声音(sound)是由物体振动产生的声波。是通过介质传播并能被人或动物听觉器官所感知的波动现象。最初发出振动的物体叫声源。声音以波的形式振动传播。声音是声波通过任何介质传播形成的运动。
频率:是每秒经过一给定点的声波数量…
whisper large-v3 模型文件下载链接
#源码里找到的_MODELS {"tiny.en": "https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt","tiny": "https://openaipublic.azureedge.net/main/whisp…
基础课23——设计客服机器人
根据调查数据显示,使用纯机器人完全替代客服的情况并不常见,人机结合模式的使用更为普遍。在这两种模式中,不满意用户的占比都非常低,不到1%。然而,在满意用户方面,人机结合模式的用户满意度明显高于其他模…

技术文章 | 智能语音交互:阿里的研究和实践
本文来源于阿里云-云栖社区,原文点击这里。 云栖TechDay40期,iDST智能语音交互团队总监智捷带来智能语音交互的演讲。本文主要讲解了语音识别的核心组件,语音识别准确率以及影响准确率因素,还分享了iDST智能语音交互以及阿里云的对…
【OpenAI】新功能发布
OpenAI Dev Day 提供了多项更新,总结如下:
GPT 4-Turbo
现在可以通过API使用GPT 4-Turbo。提供了更长的128k令牌上下文,之前为32k。相比GPT-4,成本降低了50%以上。知识更新至2023年4月,之前为2021年9月。性能优于GPT…

Python足够开一家语音识别公司的中文语音识别系统源码方案
标题中开一家公司有些夸张,但是足够你用来学习练手了。对于刚开始接触语音领域的新人来说,如何学习入门是一个棘手的问题。那么今天我就在这里做一些如何入门的介绍和相关资料的推荐吧。
做语音识别主要需要学习这三大类:数学、程序设计、算法,如果涉及到应用落地,还需要…

Python让AI虚拟主播接入微软Azure语音合成并精准嘴型同步
上一篇文字中讲了利用Python实现利用微软Azure无限免费将文本转mp3格式的音频文件并下载到本地。微软Azure TTS的优点不用多说,今天将讲如何利用Python将其接入到虚拟主播中来。
订阅专栏,我将免费向您提供具体的方案。
看过专栏其他文章的朋友&#x…
四、FM1288调试方案-影响音质环节及其解决方案
本篇主要描述在未开始调试前,放音、录音环节就会影响音质的地方,以及他们的解决方案。 文章目录 1. 前言1.1 音频测试项列表(可直接看)1.2 FM1288调试难点在哪?1.3 音频测试介绍1.4 相关spec信息1.5 测试音频2. speaker2.1 speaker频响2.2 PA功放2.3 功率检测2.4 THD总谐…

基础课19——客服系统知识库的搭建流程
1.收集整理业务数据
注意:我们在做业务数据收集时,往往是甲方提供给我们的,这时就需要确定一个标准,否则对知识库梳理工作会带来很大的难度,建议和甲方沟通确认一个双方都统一的知识库原材料。 2.创建知识库
在创建知…
全自动深度学习技术攻克了染色体生物学中的核心科学问题
项目团队用了5年时间潜心研究,最终采用端到端的全自动深度学习技术和图像处理技术,与染色体生物学有机结合,攻克了染色体生物学中的核心科学问题,通过运用计算机信息科学的最新理论知识和方法,为解决染色体生物学领域中…
数智化零售:决策智能赋能零售支撑业务增长
传统零售行业数字化转型的需求愈加迫切,在价值链渐趋细分化、线上线下消费者边界渐趋消弭的背景下,零售企业的差异化打法和消费者对产品和服务的个性化需求让决策智能有了用武之地。尽管领先零售商对于人工智能等技术有初步应用探索,但在如何…
互联网时代构建了产业互联网强大的数据和用户基础
可以说,互联网时代构建了产业互联网强大的数据和用户基础,新技术时代构建了产业互联网强大的技术基础,金融的数字化构建了产业互联网时代强大的金融基础……当有关产业互联网的基础设施开始逐渐完备之后,产业互联网才从一个虚无缥…
研究现实版帮助人类可能不符合人工智能自身的利益
当然,我们也拥有一个合理地应对高级人工智能的出现的积极方式,就是将其视为人类进化的下一个阶段。就像人类从“低等的”、不那么聪明的猿类进化而来那样,一个高级的人工智能,将以人类为基础进化出来。前面讨论的电影《人工智能》…
人工智能技术与音乐相结合听起来非常有趣
InfoQ:人工智能技术与音乐相结合听起来非常有趣,主要的结合点有哪些?您能整体介绍一下吗? 谭旭:在回答这个问题前,我想先解答下可能大多数人心中的一个疑惑:音乐作为一门艺术,怎…
人工智能和溯因推理 AI的历史一直被演绎和归纳所主导
在20世纪80年代和90年代,溯因在溯因逻辑编程(Abductive Logic Programming)的尝试中走进了AI讨论,但这些努力都存在缺陷,后来被放弃了。拉森认为:“它们是对逻辑编程的重写,是演绎的一种变体。”…
在真实世界里,需要机器人的场景往往都是异常复杂的
研究人员从每个环境中挑选出了10种表现最好的人工生命,并从头开始训练它们完成绕过障碍物、推球或者把箱子推上斜坡等全新的八个任务(见图6)。 图6. 人工生命需要完成的8种新任务,包括巡逻、越障、探索和逃离等。 结果是&…

AI智能外呼okcc呼叫中心外呼的几种形式
外呼系统,很多人喜欢称呼为电销系统。那么今天我们就按照这个称呼来分享下外呼的几种形式。当然,OKCC不只是一套外呼系统,而是一套完整的呼叫中心系统,呼出呼入都可以实现。只是目前客户群体比较多的,是外呼这个场景占…
强人工智能指人可能会被人工智能取代或者会被人工智能威胁
而所谓强人工智能,指的是未来有一天我们的生活当中充斥着大量的人工智能,人可能会被人工智能取代或者会被人工智能威胁等。我觉得这些未来也许会出现,但可能不是我们现阶段作为科研工作者去考虑的。 InfoQ:在《钢铁侠》中…
飞桨paddlespeech语音唤醒推理C实现
上篇(飞桨paddlespeech 语音唤醒初探)初探了paddlespeech下的语音唤醒方案,通过调试也搞清楚了里面的细节。因为是python 下的,不能直接部署,要想在嵌入式上部署需要有C下的推理实现,于是我就在C下把这个方…

资讯精选 | 阿里巴巴创新中心发起2017人工智能领域TOP20•投资人评选
本文来源于阿里云-云栖社区,原文点击这里。 2017,关于人工智能的讨论甚嚣尘上,投资机构对于这一领域的布局也早已开始。从之前的大数据到现在的无人驾驶,几乎所有人都笃定这一领域将会像当年互联网的崛起一样爆发。 根据亿欧智…
超大智能模型将成为人工智能发展战略基础设施
研发出我国首个万亿级参数的超大规模智能模型“悟道”,首次实现基于相变存储器的神经网络高速训练系统,运营汇集全球超10万AI科研及技术人员的学术社区……这些人工智能领域的瞩目成就,由一个成立仅三年的年轻研究院所创造,也折射…
智能电话机器人是如何自主学习的
电话机器人主要通过语音识别和针对语意的理解识别客户所说的内容,针对性的回答问题,为企业高效筛选意向客户。除了电话机器人语音识别之外,电话机器人能够自主学习,不断完善产品知识及话术等,是它智能的另一种体现。那…

基于tensorflow 的中文语音识别模型
目前网上关于tensorflow 的中文语音识别实现较少,而且结构功能较为简单。而百度在PaddlePaddle上的 Deepspeech2 实现功能却很强大,因此就做了一次大自然的搬运工把框架转为tensorflow…. 简介
百度开源的基于PaddlePaddle的Deepspeech2实现功能强大&am…
FPGA(VHDL)语音识别
在Altera DE0上使用MATLAB和VHDL的简单语音识别系统。
介绍
该项目是一个试验,目的是在低端和教育性FPGA(如Altera DE0)上开发简单的语音识别引擎。 耗尽低端FPGA的局限性并驯服它们来做高级工作也是一个简单的挑战。
设计该系统的目的是识…

51单片机蓝牙APP自助商品售卖机12864投币找零
实践制作DIY- GC0132-蓝牙APP自助商品售卖机
一、功能说明:
基于51单片机设计-蓝牙APP自助商品售卖机 二、功能介绍:
硬件组成:STC89C52单片机最小系统LCD12864显示蜂鸣器ULN2003步进电机模拟出商品多个按键(找零、确认、投…

语音(二)——语音预处理
1 预滤波
CODEC说得通俗一点,对于音频就是A/D和D/A转换。前端带宽为300-3400Hz(语音能量主要集中在250~4500Hz)的抗混叠滤波器。
工程测量中采样频率不可能无限高也不需要无限高,因为一般只关心一定频率范围内的信号成份。为解决…

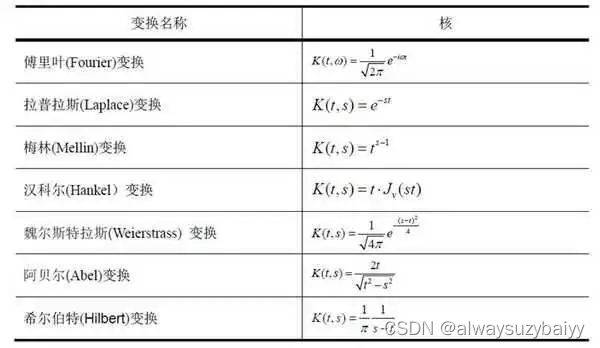
语音(三)——傅里叶变换家族
语音(三)——傅里叶变换家族
1 特征提取流程
在语音识别和说话者识别方面,最常用到的语音特征就是梅尔倒谱系数(Mel-scaleFrequency Cepstral Coefficients,简称MFCC)。MFCC提取过程包括预处理、快速傅里…

可以使用的MFCC程序
在CSDN里面找了几个MFCC的程序,一点点调试,终于得到一个可以使用程序,作为人生中的第一篇博客贴出来。关于MFCC提取过程中的数学推导还不够理解,以后再看咯,以下我自己整理的从录音到MFCC提取的两个MATLAB程序组&#…

短时傅里叶变换函数编写
文章目录 傅里叶变换与短时傅里叶变换什么是窗?自己对手实现短时傅里叶变换 傅里叶变换与短时傅里叶变换
在了解短时傅里叶变换之前,首先要知道是什么是傅里叶变换( fourier transformation,FT),傅里叶变换…

语音信号处理给音乐信号增加房间混响效果
语音信号处理给音乐信号增加房间混响效果 是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务
1 源码布局 2 源文件与音频文件和生成文件 3 编译方法
人工神经网络模型的特点,人工神经网络模型定义
神经网络优缺点,
优点:(1)具有自学习功能。例如实现图像识别时,只在先把许多不同的图像样板和对应的应识别的结果输入人工神经网络,网络就会通过自学习功能,慢慢学会识别类似的图像。自学习功能…

一键全自动批量剪辑,混剪裂变过审神器,免费批量混剪软件在线手机批量剪辑
一键全自动批量剪辑,混剪裂变过审神器,免费批量混剪软件在线手机批量剪辑 www.shipinshanshan.com 🎉亲们,今天给大家分享一款超级实用的手机在线批量剪辑神器!这款工具可以帮助您一键全自动批量剪辑,轻松实…
人工智能AI系列 - 元宇宙 - 2D虚拟人
官网:
官网链接
2D虚拟人
最近元宇宙的概念越来越火。虚拟人技术是其中重要的组成部分。 其原理是通过视频来捕捉人脸,并且将人的面部动作同步到人物身上。人们只需要一个摄像头就可以制造出一个生动活泼的虚拟形象了。
虚拟数字人
虚拟数字人系统一…

基于GUI的卷积神经网络和长短期神经网络的语音识别系统,卷积神经网的原理,长短期神经网络的原理
目录
背影 卷积神经网络CNN的原理 卷积神经网络CNN的定义 卷积神经网络CNN的神经元 卷积神经网络CNN的激活函数 卷积神经网络CNN的传递函数 长短期神经网络的原理 基于GUI的卷积神经网络和长短期神经网络的语音识别系统 代码下载链接:基于MATLABGUI编程的卷积神经网络和长短期…

STM32单片机蓝牙APP智能急救手表跌倒报警心率报警MAX30102
实践制作DIY- GC0083-智能急救手表
一、功能说明:
基于STM32单片机设计-智能急救手表
功能介绍:
STM32F103C系列最小系统板OLED显示器MAX30102心率传感器蜂鸣器ADXL345角度模块DS1302时钟芯片HC05蓝牙模块4个按键
1.单片机采集MAX30102心率传感器获取…
海量的人物知识数据,实现了多模态的技术融合
百度领先的AI专利布局将为元宇宙重要的基础设施建设提供有力支撑。在2021世界VR产业大会云峰会上,百度表示希望成为元宇宙的“基建狂魔”,利用强大的AI技术做好元宇宙基建工作。在百度世界2021上亮相的“一句话生成形象”技术结合增强现实、知识图谱、语…
【Matlab语音识别】DTW MFCC 0-9数字语音识别(带面板)【含GUI源码 385期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】DTW MFCC 0-9数字语音识别(带面板)【含GUI源码 385期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版&…
人工智能Java SDK:模型生成文本基于目标音色的梅尔频谱图
模型生成文本基于目标音色的梅尔频谱图
声音克隆是指使用特定的音色,结合文字的读音合成音频,使得合成后的音频具有目标说话人的特征,从而达到克隆的目的。 在训练语音克隆模型时,目标音色作为Speaker Encoder的输入,…
人工智能Java SDK:声纹识别
声纹识别
所谓声纹(Voiceprint),是用电声学仪器显示的携带言语信息的声波频谱。人类语言的产生是人体语言中枢与发音器官之间一个复杂的生理物理过程, 人在讲话时使用的发声器官–舌、牙齿、喉头、肺、鼻腔在尺寸和形态方面每个人的差异很大,…

探索 Web API:SpeechSynthesis 与文本语言转换技术
一、引言
随着科技的不断发展,人机交互的方式也在不断演变。语音识别和合成技术在人工智能领域中具有重要地位,它们为残障人士和日常生活中的各种场景提供了便利。Web API 是 Web 应用程序接口的一种,允许开发者构建与浏览器和操作系统集成的…
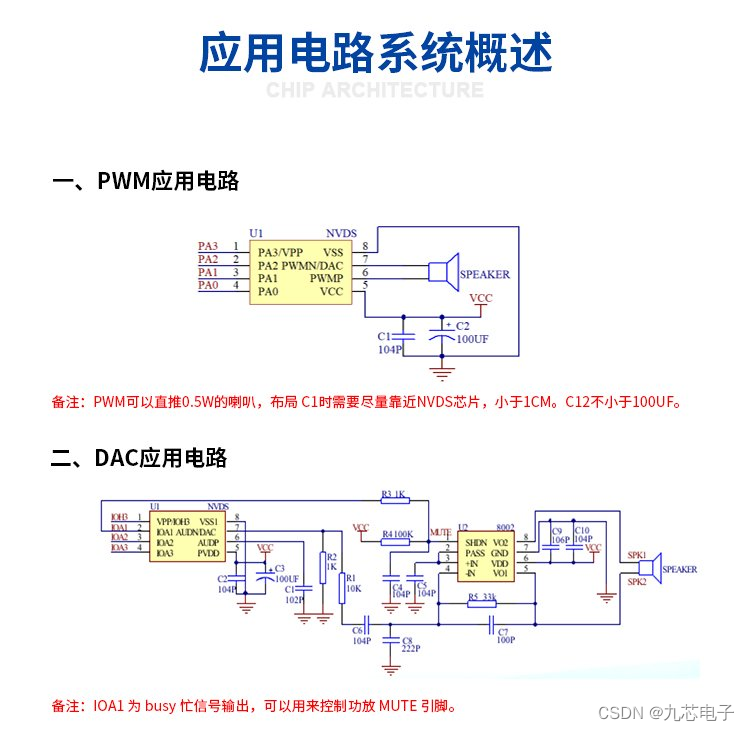
洗地机充电底座语音芯片选型?NV040DS语音芯片
一、洗地机语音提示功能的价值
洗地机充电底座加入语音提示功能,主要是为了提高洗地机的智能化程度和使用便利性!
1. 提高使用效率:底座语音提示充电状态可以使用户更方便地掌握底座电量和洗地机的使用情况,从而更快捷地对底座进…
基于 EmotiVoice 的批量 TXT 文本转语音工具
比老版本文本转语音更好的TTS工具来了~
!!!除了正常的输入文本转为语音功能之外,还新增了 从 txt 文本批量转为语音的功能。
!!!支持超过 2000 种不同的说话者声音
!!…
【Matlab语音识别】声纹识别【含GUI源码 537期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】声纹识别【含GUI源码 537期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1] 包子阳,余继周,杨杉.智能优化算法及其MATLAB实例(第2版)[M].电子工业出版社&#…
ai智能语音电销机器人怎么选?
智能语音电销机器人哪家好?如何选择一款智能语音电销机器人?这几年生活中人工智能的普及越来越广泛,就如智能语音机器人在生活当中的应用还是比较方便的,有许多行业都会选择这类的智能语音系统来把工作效率提高上去,随…

华为ICT——第五章语音处理理论与实践
目录 语言学: 主要应用场景: 语言学: 语言学: 语音学(1) 语音学(2)
语音处理介绍:
人类语音的来源:
语言数据:
语言信号预处理:
…
【Matlab语音识别】HMM 0~9数字语音识别(带面板)【含GUI源码 1393期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】HMM 0~9数字语音识别(带面板)【含GUI源码 1393期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版ÿ…
【Matlab语音识别】语音识别信号灯图像模拟控制【含GUI源码 757期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】语音识别信号灯图像模拟控制【含GUI源码 757期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社&am…
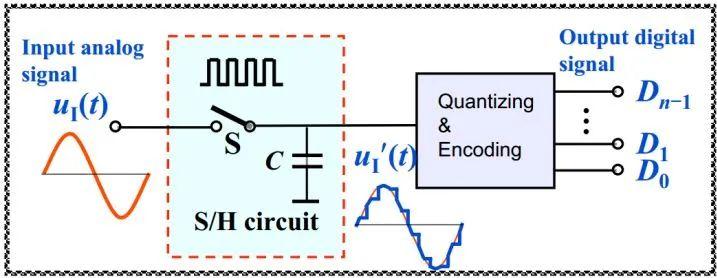
G.711语音编解码器详解
语音编解码利用人听觉上的冗余对语音信息进行压缩从而达到节省带宽的目的。值得注意的是,本文说的是语音编解码器,也就Speech codec,而常用的还有另一种编解码器称作音频编解码器,英文是Audio codec,它们的区别如下。 以前在学校的时候研究了很多VoIP的编解码器从G.723到A…
语音播报speechSynthesis最简单的例子(亲测有用)
最简单的例子,在chrome上亲测有效:
const utterThis new SpeechSynthesisUtterance(我来试试呀);
const synth window.speechSynthesis;
synth.speak(utterThis);加入配置,可以配置语言、音量、语速、音高,继续玩: …
通过顶顶通呼叫中心中间件玩转FreeSWITCH媒体流
怎么获取FreeSWITCH的媒体流是一个老生常谈的问题了,最常见的方法media_bug,我在2019年就做的FreeSWITCH对接ASR开源的例子https://gitcode.net/iyaosan/FreeSWITCH-ASR用的就是media_bug,对接ASR常见的方法还有通过mod_mrcp模块对接mrcp的asrserver。
…

praat学习笔记——五度值分析(石峰T值法)
一. 调域上下限的确定 语音录制了阴平“山”、阳平“昨”、上声“宝”、去声“去”四个声调,每个声调用不同的字发了十遍音,导入praat进行分析。
将Spectrogram setting中的窗口长度改为0.03,出现窄带语图,分析基频。 通过对阴平…
最新ChatGPT网站源码,支持Midjourney绘画,GPT语音对话+GPT-4识图理解能力+ChatFile文档对话总结+DALL-E3文生图
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…
ai电话呼叫系统的功能有哪些,能帮到我们什么?呼叫系统
人工智能产品的研发,是为了帮助企业更好的生存,更好的利润放大,而不是用于不正规的工作,现在的电话呼叫中心软件让企业员工从简单重复的工作中得以解放,那电话呼叫系统的强大功能有哪些? 知识自学习&#x…

虹科案例 | 最佳活动体验!虹科HK-RDL为大型活动提供可靠通信覆盖
你有没有遇到过这样的情况?在参加演唱会、音乐节等大型活动时手机就没有办法收到信号,甚至有时候走到人群密集的地方也会失去信号连接。 背景 在北美,有一家为数百万用户提供无线语音、消息和数据服务的大型移动网络提供商,他们希…
应用案例——楼宇对讲、可视门铃芯片组成分析
语音通话芯片:D34018,D34118,D5020,D31101; D34018 单片电话机通话电路,合并了必 需的放大器、衰减器和几种控制 功能,包括发送和接收衰减器、 背景噪声电平检测系统和一个衰 减器控制系统,对发送和接收电 平好于背景噪声做…
如何实现电脑语音输入功能?
现在的手机都具备语音输入功能,并且识别率非常高,语音输入是目前最快速的文字输入方式,但是电脑上却无语音输入的功能,那么如何实现在电脑端也可进行语音输入的梦想呢?现在介绍一款小工具“书剑电脑语音输入法”&#…
【Matlab语音识别】MFCC GMM语音识别【含源码 535期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】MFCC GMM语音识别【含源码 535期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019…

【PyTorch深度学习项目实战100例】—— 基于Pytorch的语音情感识别系统 | 第71例
前言
大家好,我是阿光。
本专栏整理了《PyTorch深度学习项目实战100例》,内包含了各种不同的深度学习项目,包含项目原理以及源码,每一个项目实例都附带有完整的代码+数据集。
正在更新中~ ✨
🚨 我的项目环境: 平台:Windows10语言环境:python3.7编译器:PyCharmPy…

基于卷积神经网络和连接性时序分类的语音识别系统,含核心Python工程源代码(深度学习)个人可二次开发
目录 前言总体设计系统整体结构图系统流程图 运行环境模块实现1. 特征提取2. 声学模型3. CTC 解码4. 语言模型 系统测试工程源代码下载其它资料下载 前言
本项目基于卷积神经网络和连接性时序分类方法,采用中文语音数据集进行训练,实现声音转录为中文拼…

python实现语音识别(讯飞开放平台)
文章目录 讯飞平台使用python实现讯飞接口的语音识别第一步:导入需要的依赖库第二步:初始化讯飞接口对象第三步:收到websocket建立连接后的处理函数第四步:收到websocket消息的处理函数第五步:整合运行各函数 讯飞平台…
python知识点100篇系列(12)-使用windows自带的模块实现语音识别
使用SAPI实现语音识别:
开发运行环境: win10 64位 Python版本:3.8 使用模块: speech
基础知识:
什么是SAPI? SAPI是微软Speech API , 是微软公司推出的语音接口,而从WINXP开始,系统上就已经有语音识别的功能了; Speech模块: 该模块的主要功能有:语音识别、将指定文…
语音模块 STC11L08XE代码功能简介
硬件模块化的开发笔记-语音模块 STC11L08XE
void ExtInt0Handler(void) interrupt 0 中断处理函数 当LD3320识别成功后,会引发IO口中断 nAsrRes LD_GetResult(); /获取结果/ User_handle(nAsrRes);//用户执行函数
main Led_test(); 开机闪灯3次 MCU_init(); 单片…
ETL (数据仓库技术)
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并…

全方位解读智能中控屏发展趋势!亚马逊Alexa语音+Matter能力成必备
随着智能家居行业逐步从碎片化的智能单品阶段,迈向体验更完整的全屋互联阶段,智能中控屏作为智能家居最佳的入口之一,在年轻人青睐全屋智能装修的风潮下,市场潜力彻底被引爆。
一、为什么是智能中控屏?
在智能音箱增…
【Matlab语音识别】BP神经网络0到10数字语音识别【含GUI源码 672期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】BP神经网络0到10数字语音识别【含GUI源码 672期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社&a…
vue实现自动语音播报功能,未解决。(已用js解决20220210)
这个放不出来
<template><div><i click"reader" class"el-icon-microphone"></i> //elementUI 麦克风图标
<div id"group">{{words}}</div> //语音播报的文字</div></template><script>…
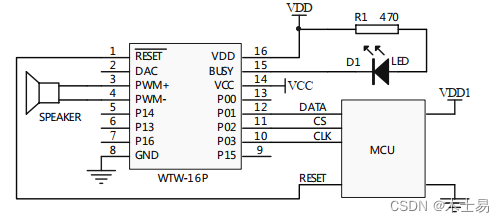
WTW-16P 应用电路
1、WTW-16P 按键控制 PWM 输出应用电路
软件设置: 按键控制模式。 I/O 口定义: 选取 I/O 口 P00、P01、P02、P03 作为触发口,在编辑 WT588D 语音工程时,把触发口的按键定义为可触发播放的触发方式,就可进行工作。 BUS…
【Matlab语音去噪】FIR窗函数音频去噪【含GUI源码 875期】
一、代码运行视频(哔哩哔哩)
【Matlab语音去噪】FIR窗函数音频去噪【含GUI源码 875期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,…

Avatar是不是元宇宙入口?
Metaverse 人类简史虚构和讲故事,赋予智人以前所未有的能力,让我们得以集结大批人力、灵活合作。虚构不存在的事物,我们创造了无数的虚拟形象。而更有趣的是,我们不仅在虚拟中仿真现实,还在现实中虚构真实的人……MyMe…
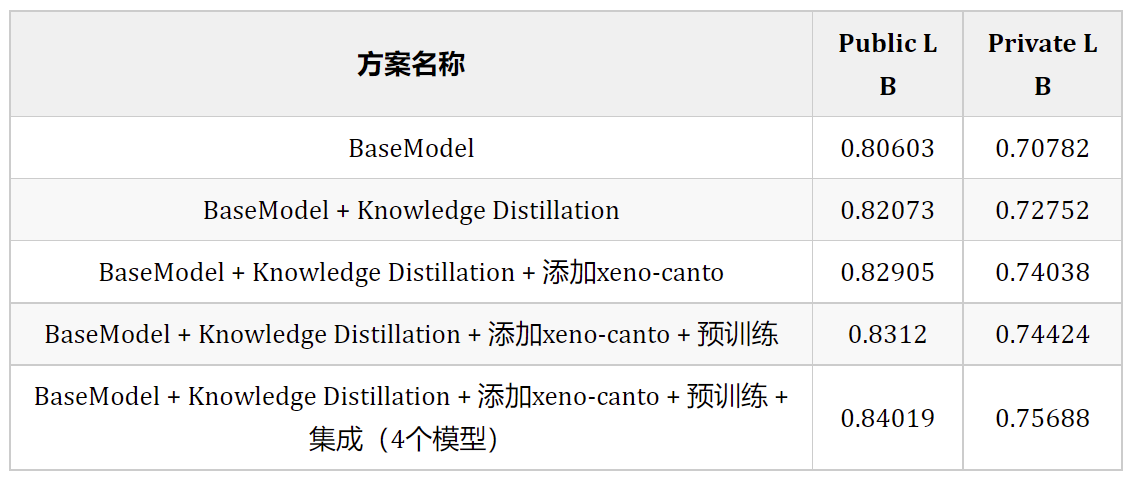
Kaggle 比赛总结:BirdCLEF 2023
赛题名称:BirdCLEF 2023赛题任务:识别音景中的鸟叫声赛题类型:语音识别
https://www.kaggle.com/competitions/birdclef-2023文章目录 一、比赛背景二、比赛任务三、评价方法四、优胜方案4.1 第一名4.2 第二名4.3 第三名4.4 第四名4.5 第五名…
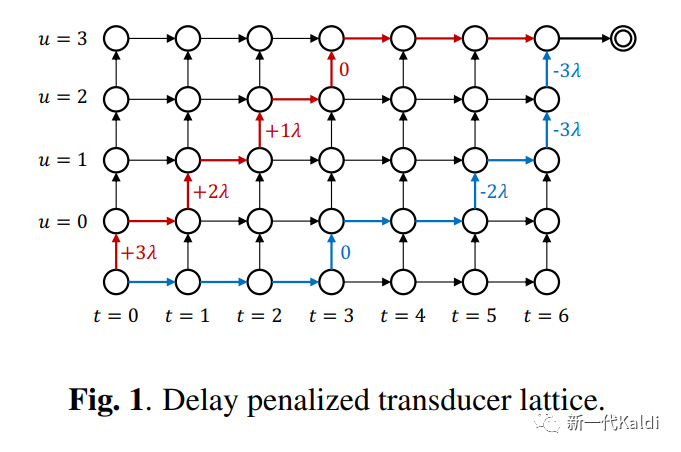
2022年新一代kaldi团队技术输出盘点
目录
1. 技术创新
1.1 Pruned RNN-T loss
1.2 RNN-T 的快速 GPU 解码
1.3 多码本量化索引的知识蒸馏
1.4 RNN-T 和 CTC 的低延时训练
1.5 Zipformer
1.6 Small tricks
2. 模型部署
2.1 Sherpa
2.1 Sherpa-ncnn
3. 更多的 recipe 和模型
参考资料 1. 技术创新
1.1 …

python实现对语音信号的离散余弦变换(DCT)与离散余弦逆变换(IDCT)
python实现对语音的离散余弦变换与离散余弦逆变换离散余弦变换离散余弦逆变换调包实现离散余弦变换
离散余弦变换(DCT)信号谱分量丰富、能量集中,且不需要对语音相位进行估算等优点,在较低的运算复杂度下取得较好的语音增强效果。…
【Matlab语音加密】语音信号加密解密(带面板)【含GUI源码 181期】
一、代码运行视频(哔哩哔哩)
【Matlab语音加密】语音信号加密解密(带面板)【含GUI源码 181期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[…

再也不用敲代码了,自从有了语音助手 | Mixlab知识社群
“对不起,我不明白你的意思“当你认真地对着智能音箱发问,得到的却是让人失望的回答。相信使用过智能音箱的朋友,对这一场景都不会陌生吧……虽然说,稍有尴尬的情况,但是智能音箱还是有用武之地的。比如回答,小孩子的各种十万个为什么。智能音…
科普丨语音芯片喇叭的工作原理及高、中、低频
喇叭基础原理
喇叭其实是一种电能转换成声音的一种转换设备,当不同的电子能量传至线圈时,线圈产生一种能量与磁铁的磁场互动,这种互动造成纸盘振动,因为电子能量随时变化,喇叭的线圈会往前或往后运动,因此…
颠覆性语音识别:单词级时间戳和说话人分离
vbenjs/vue-vben-admin[1]
Stars: 19.7k License: MIT Vue Vben Admin 是一个免费开源的中后台模板,使用最新的 vue3、vite4 和 TypeScript 等主流技术进行开发。该项目提供了现成的中后台前端解决方案,并可用于学习参考。 使用先进的前端技术如 Vue3/…

请问哪些好用文字转语音软件?
好用的文字转语音软件给大家推荐UU在线工具,这里你可以自由调节语速、音调、音量以及发音人。播放合成的语音,将音频导出到本地就可以了。
缺点就是生成的音质比较单一,只能选择四款发音人,无法添加音乐、添加间隔等等。
想要应…

有没有好用的文字转语音软件?
文字转语音技术实际上就是将上传的文本转换成音频模式,传统的配音工具功能比较单一,生成的音质苍白、机械,无法应对多元化场景。随着国内人工智能的发展,依托于先进的AI学习技术,文字转语音也取得突破性进步。高度模拟…
在Android Studio下使用百度语音识别的一个简单例子
一、引言
利用百度语音识别和百度语音合成可以很方便的设计一个语音交互应用,这里记录一下百度在线语音识别的简单例子以便快速上手。 我所用的语音识别包的版本是Baidu-Voice-SDK-Android-1.6.2.zip,开发平台用的是Android Studio 1.3.2,操…
五、FM1288调试方案-调试原理
本篇只讲述调试原理,侧重流程、理论,不涉及细节,比如应该调哪一块、哪些寄存器这些。 文章目录 1. 结构框图1.1 回声消除原理1.2 硬件结构2. 调试方案2.1 uart串口调试2.2 I2C调试1. 结构框图
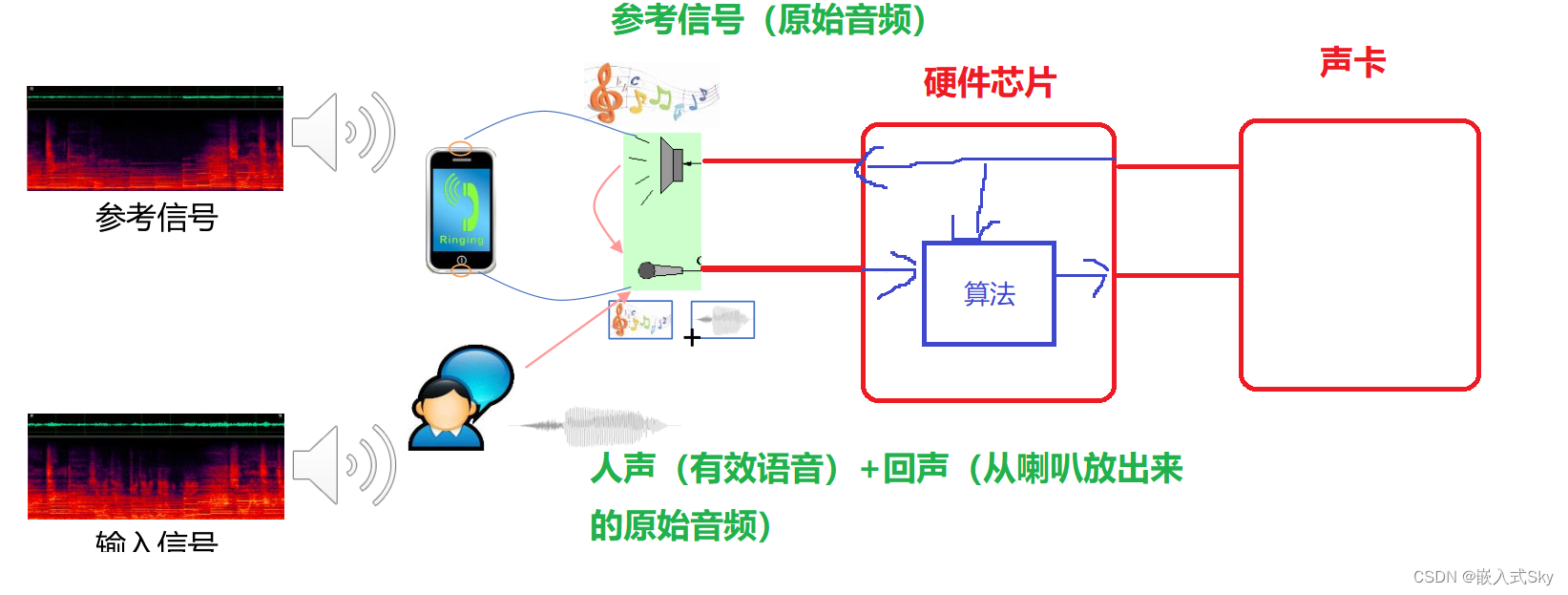
1.1 回声消除原理
回声消除的详细原理,牵涉到算法相关的东西,不太了解,只描…
Speaker Diarization
Speaker Diarization(声纹分割聚类、说话人日志),解决的问题是“who spoke when”,即给定一个包含多人交替说话的语音,需要判断每个时间点是谁在说话。
技术流程框架 1、语音检测
利用语音检测模型(如VAD…
ChatGPT在智能家居控制和环境管理中的应用如何?
智能家居控制和环境管理是近年来在科技领域迅速发展的重要领域之一。智能家居技术通过将物联网、人工智能和自动化技术相结合,实现了家居设备的智能化、自动化控制和远程管理。ChatGPT作为强大的自然语言处理模型,在智能家居控制和环境管理方面具有广泛的…

婴儿摇篮音乐芯片 N9300-S16:为宝宝带来高品质的音乐体验
对于父母来说,给婴儿提供一个安稳舒适的睡眠环境是至关重要的。宝宝的睡眠品质对于其健康和发展至关重要。在成长过程中,音乐对婴儿的情绪、认知和智力发展都有积极的影响。因此,厂家在婴儿摇篮中选择一款合适的婴儿摇篮音乐芯片尤为重要。…
音乐人声分离工具:极简的人声和背景音乐分离工具
项目地址:jianchang512/vocal-separate: an extremely simple tool for separating vocals and background music, completely localized for web operation, using 2stems/4stems/5stems models 这是一个极简的人声和背景音乐分离工具,本地化网页操作&a…
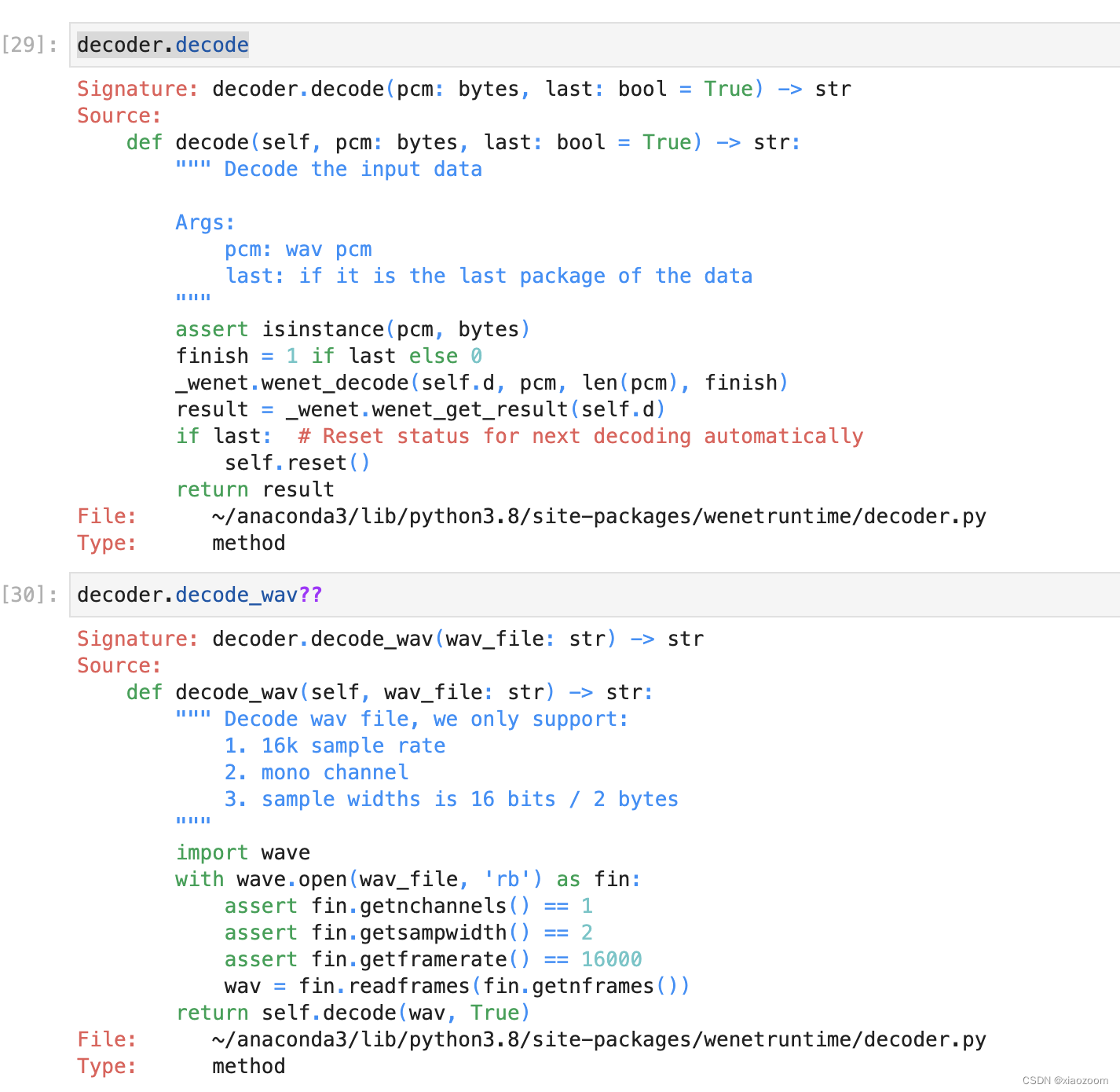
深度学习应用-WeNet语音识别实战01
概括 本文对WeNet声音识别网络的Python API上介绍的Non-Streaming Usage和 Streaming-Usage分别做了测试,两者本质相同。API对应采样的声音帧率、声道都做了限制。效果还可以,但是部分吐字不清晰、有歧义的地方仍然不能识别清晰。 项目地址: …

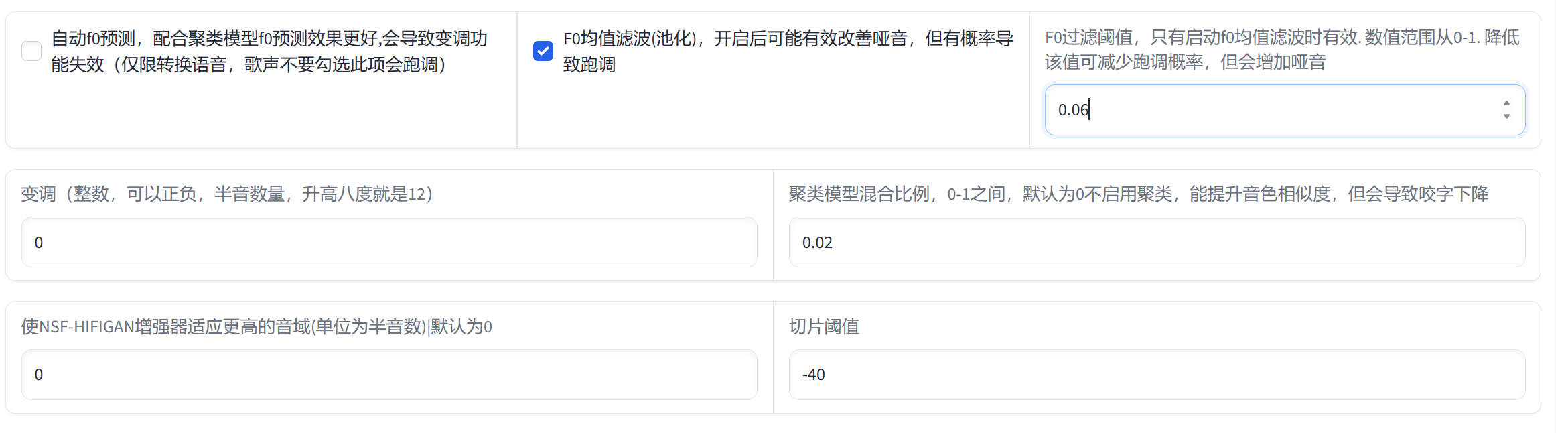
Whisper对于中文语音识别与转写中文文本优化的实践(Python3.10)
阿里的FunAsr对Whisper中文领域的转写能力造成了一定的挑战,但实际上,Whisper的使用者完全可以针对中文的语音做一些优化的措施,换句话说,Whisper的“默认”形态可能在中文领域斗不过FunAsr,但是经过中文特殊优化的Whi…

小程序中使用微信同声传译插件实现语音识别、语音合成、文本翻译功能----文本翻译(三)
官方文档链接:https://mp.weixin.qq.com/wxopen/plugindevdoc?appidwx069ba97219f66d99&token370941954&langzh_CN#- 要使用插件需要先在小程序管理后台的设置->第三方设置->插件管理中添加插件,目前该插件仅认证后的小程序。
文本翻译…
AAAI 2024 | 清华大学人机语音交互实验室的3篇录用论文分享
分享3篇清华大学人机语音交互实验室(THUHCSI) 在AAAI 2024上被录用的论文,本次被录用的3篇论文涉及基于大语言模型(LLM)的语音情感描述生成、基于强化学习(RL)的多样化舞蹈动作生成、基于节点相…
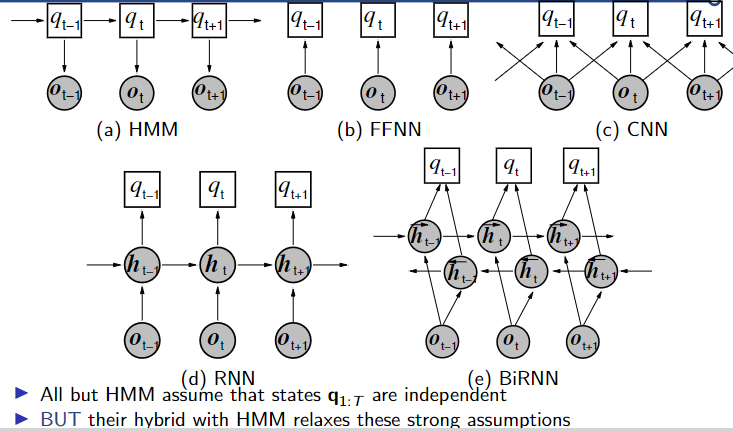
囫囵吞枣【语音处理的隐性马可夫模型HMM】
语音是一个时间演变的过程,对口语进行分类的一种简单的确定性方法是: 计算观察中所有特征向量与特定单词 wj 的参考向量vj 的平均距离,再延伸为,使用长度为 T 的参考模板而不是参考向量,这一概念,如果模板的…
第三章--第一篇:什么是对话系统?
对话系统是一种人机交互的技术,旨在使计算机能够与人类进行自然而流畅的对话。它是人工智能领域的重要研究方向,具有重要的实际应用价值和广泛的普适性。 首先,对话系统的重要性在于它可以提供高效便捷的人机交互方式。传统的人机界面,如图形用户界面(GUI)和命令行界面(…
ai电销机器人原理是什么?它的语音识别是如何实现的?
电销机器人原理是什么?它的语音识别是如何实现的?智能电销机器人的真正价值是帮助电销企业解决电销上带来的一些问题,可以提高效率。为电销人员节省大量的时间与精力,提高电销水平。随着智能语音技术的成熟、智能ai学习技术的不断…
02调制+滤波器+冲激函数的傅立叶变换
目录
一、调制方式
1.1 什么是调制?
1.2 为什么要调制?
1.3 如何调制?
1.4 调制包含的信号类型?
1. 消息信号
2. 载波信号
3. 调制信号
1.5 调制类型?
1. 调幅
2. 调频
3. 调相
4. 模拟脉冲调制
5. 脉冲…

万万没想到,我用文心一言开发了一个儿童小玩具
最近关注到一年一度的百度世界大会今年将于10月17日在北京首钢园举办,本期大会的主题是“生成未来(PROMPT THE WORLD)”。会上,李彦宏会做主题为「手把手教你做AI原生应用」的演讲,比较期待 Robin 会怎么展示。据说&am…
【Matlab语音识别】声纹识别系统(带面板)【含GUI源码 1022期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】声纹识别系统(带面板)【含GUI源码 1022期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].…
【Matlab语音识别】智能语音识别门禁系统【含GUI源码 596期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】智能语音识别门禁系统【含GUI源码 596期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社ÿ…
Unity AI 语音识别、语音合成、人机交互(一)
自我介绍
大家好,我是VAIN,这是我在CSDN的第一篇文章,之前一直在微博博客上写文章,今后会用CSDN给大家更新一些技术帖,还希望大家多多关照!
项目介绍
因为公司项目要求,今天给大家分享一个un…

Achronix推出基于FPGA的加速自动语音识别解决方案
提供超低延迟和极低错误率(WER)的实时流式语音转文本解决方案,可同时运行超过1000个并发语音流
2023年11月——高性能FPGA芯片和嵌入式FPGA(eFPGA IP)领域的领先企业Achronix半导体公司日前自豪地宣布:正式…

手把手教你用Python打造一个语音合成系统
目录
引言
一、了解语音合成技术
1.1 什么是语音合成技术
1.2 语音合成技术的分类
二、准备所需工具和库
2.1 Python编程语言
2.2 TensorFlow深度学习框架
2.3 WaveNet模型
三、搭建语音合成系统
3.1 数据准备
3.2 数据预处理
3.3 构建WaveNet模型
3.4 训练WaveNe…

DuDuTalk:4G语音工牌,如何实现家庭上门维修服务过程的智能化管理?
随着上门按摩、上门养老、上门买菜、上门维修等互联网上门服务的兴起,越来越多的居民开始采用线上下单,享受企业安排人员上门到家的服务。而家庭维修作为到家服务里面典型的一个场景,已成为许多人不可或缺的一部分。然而,与此同时…

基于Kaldi的中文在线识别系统
三音子模型词错误率为:36.03%,对比单音素模型词错误率为50.58%。 可见三音素模型识别率已经有了提高。 不管模型识别率怎么样,先利用三音子模型搭建一个中文在线识别系统看看效果。 在线识别与离线识别
本文主要搭建在线语音识别࿰…
轻松识别几个小时的长音视频文件
前言
之前的文章绍一个准确率非常高的语音识别框架,但那个只能识别实时的短音频,如果想要识别一个非常长的音频,几十分钟,甚至几个小时,那之前的那个是做不到的所以就有了本文。本文介绍搭建一个长语音识别服务&#…
pyttsx3 实现文字转语音
pyttsx3 实现文字转语音代码代码 #-*- coding: UTF-8 -*-import pyttsx3engine pyttsx3.init()txt 《长相思一重山》五代:李煜一重山,两重山。山远天高烟水寒,相思枫叶丹。菊花开,菊花残。塞雁高飞人未还,一帘风月闲…
【Matlab语音识别】傅立叶变换0-9数字语音识别【含源码 384期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】傅立叶变换0-9数字语音识别【含源码 384期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社&#x…

智能台灯语音控制丨解放双手
台灯是日常生活中一种常见的照明产品。以往的台灯大多都是采取手动控制,通过按键去对台灯的亮度进行调整。随着科技的发展,台灯也开始走向了智能化。人们已经能够对智能台灯进行语音控制,通过调节灯光开关、色温、灯光亮度等操作,…

智能语音血压计:NV040DS芯片呵护您的健康
随着科技的发展。血压计已告别传统的水银血压计,迈向电子血压计时代。电子血压计往往体积小。携带方便。智能血压计能自动检测人体的血压值,并给予语音提示与科学指导、帮助人们更好地了解自己的身体状况。
一、产品介绍
深耕语音芯片的九芯电子科技带…
配音软件哪个好用?2023比较火的配音软件app推荐
我们在生活中有很多时候都会遇到需要将文字转语音的情况,例如为自己录制的vlog配音、自制有声小说、朗读新闻等等。
但是却有许多小伙伴不知道如何实现这些操作,或者是找不到合适的软件,毕竟现在市面上的工具鱼龙混杂,要找到既好…
楼宇对讲门铃的芯片构成分析
目前很多的高层住宅都使用了对讲门铃了,在频繁使用中,门铃会出现的越来越多种类,下面我就简单的介绍会有用到的几款芯片.
语音通话芯片:D34018,D34118,D5020,D31101; D34018 单片电话机通话电路,合并了必 需的放大器…

语音识别与Python编程实践
博主简介 博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,…

不登录QQ,恢复QQ聊天中的语音到电脑上,并导出为MP3
之前发过一篇文章,专门讲了如何恢复导出微信的语音到电脑上,并转为MP3,用来方便整理的,本篇文章专门讲如何恢复QQ的语音,并导出到电脑上,保存为MP3。
QQ和微信一样,聊天记录中使用的语音使用的…
最新智能AI系统ChatGPT网站程序源码+详细图文搭建部署教程,Midjourney绘画,GPT语音对话+ChatFile文档对话总结+DALL-E3文生图
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…
开源免费语音识别引擎 RapidASR
作为中文社区最大的模型白嫖组织,rapid AI的使命是将模型工业化、工程化,让你们从模型白嫖到开箱即用。 我们的另一著名的项目是rapidOCR
https://github.com/RapidAI/RapidASR RapidASR目前已经完成了所有的基础开发工作,接下来将保持一周一…

Advancing Transformer Transducer for Speech Recognition on Large-Scale Dataset》
本文是观看上海交通大学陈谐老师在《人机语音通信》课程的讲座的笔记,原视频链接,本文参考[3] [4]。
1 Model Overview: Transformer Transducer
语音识别发展背景: 首先是GMM-HMM:混合高斯模型作声学模型,n-gram作为…
实现离线版语音转文本-支持Python,java等
使用开源的 VOSK-API开源代码地址测试步骤:开源代码地址
https://github.com/alphacep/vosk-api
1.升级pip python3 -m pip install -U pip
2.安装vosk python3 -m pip install -U vosk
3.直至成功安装,比如: Successfully installed vos…

FLASH语音芯片和MP3音乐芯片的不同之处
语音芯片除了不可重复擦写的otp语音芯片之外还有内置flash可重复擦写的语音芯片,还有音质相对来说更好的mp3音乐芯片,接下来让我们就flash芯片和MP3芯片来展开讨论,看看两者之间究竟有哪些不同之处。
flash语音芯片
Flash语音芯片是可以进行…
ESP32 Tensorflow 实现语音识别
教程介绍如何通过外部麦克风 I2S 将 Tensorflow 微语音与 ESP32 结合使用。换句话说,我们想要定制 Tensorflow 微语音示例,以便它在使用 I2S 协议连接到外部麦克风的 ESP32 上运行。在本例中,我们将使用连接到 ESP32 的 INMP441 来捕获音频。虽然 ESP32-EYE 具有内置麦克风,…

启英泰伦推出「离线自然说」,离线语音交互随意说,不需记忆词条
离线语音识别是指不需要依赖网络,在本地设备实现语音识别的过程,通常以端侧AI语音芯片作为载体来进行数据的采集、计算和决策。但是语音芯片的存储空间有限,通过传统的语音算法技术,最多也只能存储数百条词条,导致用户…

小程序中使用微信同声传译插件实现语音识别、语音合成、文本翻译功能----语音识别(一)
官方文档链接:https://mp.weixin.qq.com/wxopen/plugindevdoc?appidwx069ba97219f66d99&token370941954&langzh_CN#- 要使用插件需要先在小程序管理后台的设置->第三方设置->插件管理中添加插件,目前该插件仅认证后的小程序。
语音识别…
【Matlab语音处理】音频信号处理(调音+调速+调频+滤波)(带面板)【含GUI源码 299期】
一、代码运行视频(哔哩哔哩)
【Matlab语音处理】音频信号处理(调音调速调频滤波)(带面板)【含GUI源码 299期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信…

AI绘画Midjourney绘画提示词Prompt大全,各种风格大全
一、Midjourney绘画工具
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭…
为什么我们能判断声音的远近
想象一下,当我们走在路上时,听到了头顶的鸟儿在树梢间的叫声,即使无法透过浓密的树叶看见它,也可以大致知道鸟儿的距离。此时身后传来由远到近自行车铃铛声,我们并不需要回过头去看,便为它让开了道路。这些…
传统语音识别系统流程
文章目录 概述语音识别原理公式语音识别术语:分帧提取声学特征声学模型 概述
语音识别传统方法主要分两个阶段:训练和识别,训练阶段主要是生成声学模型和语言模型给识别阶段用。传统方法主要有五大模块组成,分别是特征提取&#…
【Matlab语音处理】语音信号处理与滤波【含GUI源码 1663期】
一、代码运行视频(哔哩哔哩)
【Matlab语音处理】语音信号处理与滤波【含GUI源码 1663期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社࿰…

chatgpt图片识别、生成图片、语音对话多模态深度试玩
大模型替代人的工作的能力,越来越明显了。最近chatgpt支持多模态了,看这大佬们玩的不易乐乎,手痒也想试一试,因此有给openai上供了20刀。 另外我是gpt的拥护者,但是周围的同事有对此担忧,因为他们长期积累的…
语音遥控器2-语音功能实现
语音语义识别方案我们采用的是思某驰。
调查了一下语音相关代码,不管腾某讯,还是思某驰,
一般都会涉及到以下几个部分的工作:
对接语音识别SDK
Sdk对接主要是密钥,认证,消息的处理;
方案采…

张弛语言课奇幻剧配音,一场特殊的体验
在为奇幻剧进行配音时,配音艺术家要将自己投入到一个充斥着魔法、幻想生物和超自然现象的虚构世界中。奇幻剧侧重于构建一个超越现实的幻境,因此配音工作要求既要呈现角色的个性化特征,也要与剧中的奇幻氛围相得益彰。以下是进行奇幻剧配音的…
DAY9__new__方法+单例模式
概述
__new__方法的作用是,创建并返回一个实例对象,如果__new__只调用了一次,就会得到一个对象。继承自object的新式类才有new这一魔法方法。
注意事项
__new__是在一个对象实例化的时候所调用的第一个方法。 __new__至少必须要有一个参数…
【ASOC全解析(五)】编译测试与验证
【ASOC全解析(五)】编译测试与验证 主要内容源码来源如何编译如何进行测试 /*****************************************************************************************************************/
声明: 本博客内容均由https://blog.csdn.net/weixi…
asr_syllabel_master语音识别详解
data_list: 主要为了存储数据集的标签文本。(st_cmds,thchs30)
general_function: 包括:feature_extract.py:主要用来计算语谱图。features_extract.py: 该脚本用于提取语音特征,包括MFCC、FBANK以及语谱图特征&#…
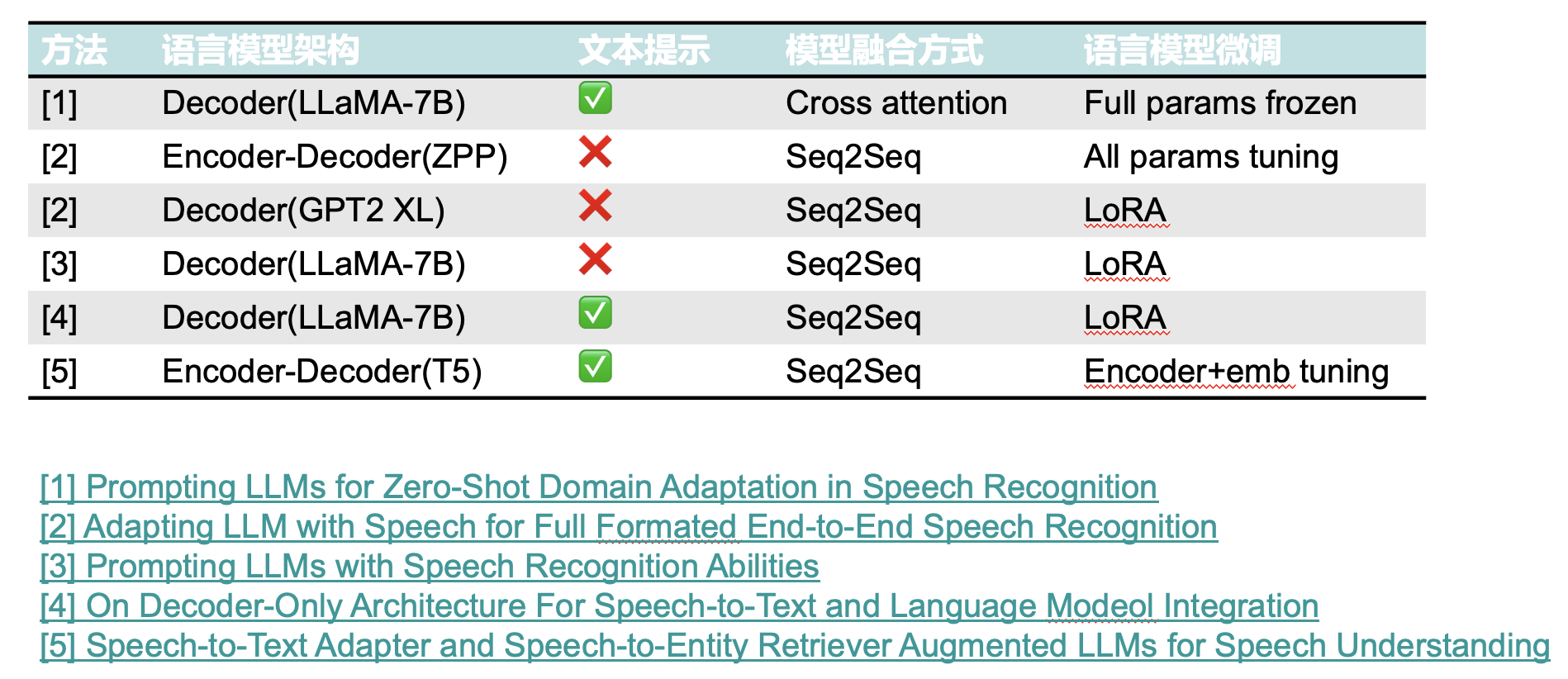
ASR(自动语音识别)任务中的LLM(大语言模型)
一、LLM大语言模型的特点 二、大语言模型在ASR任务中的应用
浅度融合
浅层融合指的是LLM本身并没有和音频信息进行直接计算。其仅对ASR模型输出的文本结果进行重打分或者质量评估。
深度融合
LLM与ASR模型进行深度结合,统一语音和文本的编码空间或者直接利用ASR…
音频筑基:窄带、宽带、超宽带、全带一次说透
音频筑基:窄带、宽带、超宽带、全带一次说透 窄带、宽带、超宽带、全带定义参考资料 音频信号中,经常遇到窄带、宽带等说法,本文进行一个小结归类。
窄带、宽带、超宽带、全带定义 窄带、宽带到全带,总体来说是,指对音…
垂直领域对话系统架构
垂直领域对话系统是指针对特定领域或行业的需求而构建的对话系统。这种系统通常需要具备高度的专业知识和对特定领域的知识库进行深入的学习和训练,以便能够提供准确、高效、实用的服务。
垂直领域对话系统的构建通常包括以下步骤:
确定目标领域或行业…
智能语音信息处理团队14篇论文被语音技术顶会Interspeech 2023接收
近日,Interspeech 2023会议发出了审稿结果通知,语音及语言信息处理国家工程研究中心智能语音信息处理团队共14篇论文被会议接收,论文方向涵盖语音识别、语音合成、话者识别、语音增强、情感识别、声音事件检测等,各接收论文简介见…

在SIP 语音呼叫中出现单通时要怎么解决?
在VoIP的环境中,特别是基于SIP通信的环境中,我们经常会遇到一些非常常见的问题,例如,单通,注册问题,回声,单通等。这些问题事实上都有非常直接的排查方式和解决办法,用户可以按照一定…
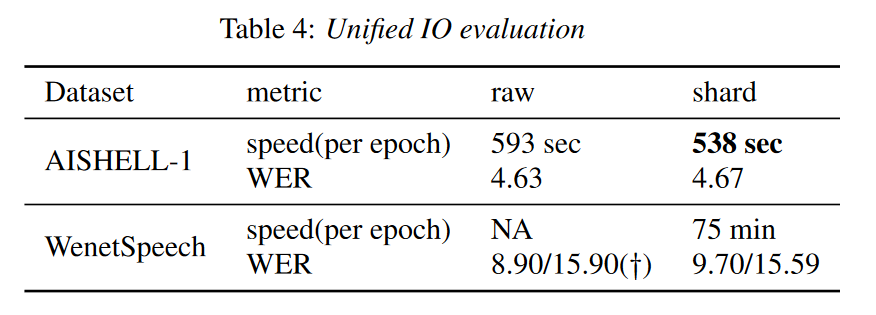
WeNet2.0:提高端到端ASR的生产力
摘要
最近,我们提供了 WeNet [1],这是一个面向生产(工业生产环境需求)的端到端语音识别工具包,在单个模型中,它引入了统一的两次two-pass (U2) 框架和内置运行时(built-in runtime)…
Meta NMT / Speech - 小记
文章目录 Mata Blog :USTSpeechMatrix 语音到语音翻译语料库FLORES 数据集M2M-100 模型LASER 数据挖掘VoxPopuliCCMatrixCCAlignedXLS-RWav2vec 2.0NLLB-200Mata Blog :
https://ai.facebook.com/blog/ https://research.facebook.com/research-areas/

活动预告 | Hugging Face 音频 AI 派对直播
嘿嘿嘿,🤗 宝子们!我们正在准备一个超级激动人心的音频 AI 派对,千万别错过!为了庆祝 Hugging Face 新开设的免费开源 Audio Transformers 课程的启动,我们组织了一场不容错过的网络直播活动! &…
【Matlab语音识别】隐马尔可夫模型(HMM)孤立字语音识别【含源码 576期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】隐马尔可夫模型(HMM)孤立字语音识别【含源码 576期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版&#x…

AI天后,在线飙歌,人工智能AI孙燕姿模型应用实践,复刻《遥远的歌》,原唱晴子(Python3.10)
忽如一夜春风来,亚洲天后孙燕姿独特而柔美的音色再度响彻华语乐坛,只不过这一次,不是因为她出了新专辑,而是人工智能AI技术对于孙燕姿音色的完美复刻,以大江灌浪之势对华语歌坛诸多经典作品进行了翻唱,还原…
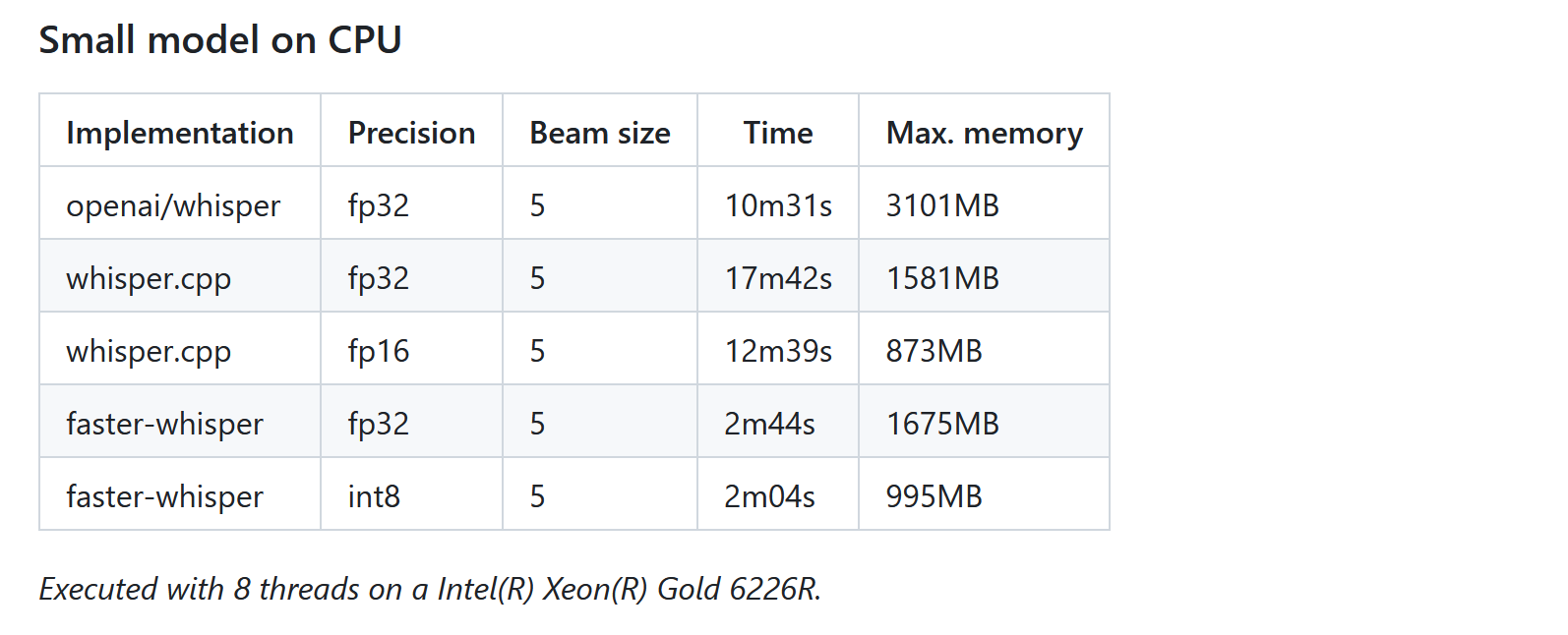
基于OpenAI的Whisper构建的高效语音识别模型:faster-whisper
1 faster-whisper介绍
faster-whisper是基于OpenAI的Whisper模型的高效实现,它利用CTranslate2,一个专为Transformer模型设计的快速推理引擎。这种实现不仅提高了语音识别的速度,还优化了内存使用效率。faster-whisper的核心优势在于其能够在…

进阶课1——声纹识别
声纹识别是一种生物识别技术,也称为说话人识别,包括说话人辨认和说话人确认两种技术。该技术通过将声信号转换成电信号,再使用计算机进行识别,不同的任务和应用会使用不同的声纹识别技术,例如在缩小刑侦范围时可能需要…
音频筑基:基音、基频和共振峰
音频筑基:基音、基频和共振峰 是什么深入理解相关参考 音频信号分析中,经常遇到基音、周期、共振峰的概念,这里总结下自己的粗浅理解,不当之处,还望各位大佬提出指正。
是什么 基音,是复音中强度最大、频率…
机器学习笔记 - 将音频转换为图像进行分类的机器学习模型
一、简述 语音识别技术是将音频信号转化为文本的过程。其基本原理如下: 1. 音频录制:首先需要对口语发音进行录制,并将其转化为数字形式的音频文件。 2. 预处理:对音频信号进行预处理,包括去除杂音干扰、增加音频的信噪比以及消除不必要的语音、噪声等。 3. 特征提取:特征…

ACM MM 2023 | 中科院自动化所何晖光课题组提出多视图对比学习技术助力实现基于EEG的听觉注意解码...
中科院自动化所神经计算与脑机交互团队(NeuBCI)基于多视图VAE,结合认知神经科学的先验知识,提出了一种基于多视图任务相关对比学习的听觉注意力解码模型。相关研究成果以Auditory Attention Decoding with Task-Related Multi-Vie…

基于ESP32和blinker的红外小夜灯控制
一. 系统设计及框图:
本设计可以实现通过手机APP使用蓝牙或WIFI远程控制红外设备,也可以通过离线语音模块语音控制红外设备。可以控制市面上常见的NEC格式的红外设备, 这里是控制小夜灯,其它红外设备在控制原理上是相通的。本设计可用作课程…
语音顶会 ICASSP 2022 成果分享:基于时频感知域模型的单通道语音增强算法
近日,阿里云视频云音频技术团队与新加坡国立大学李海洲教授团队合作论文 《基于时频感知域模型的单通道语音增强算法 》(Time-Frequency Attention for Monaural Speech Enhancement ) 被 ICASSP 2022 接收, 并受邀于今年 5 月在会议上向学术和工业界做研究报告。IC…

如何将视频的语音变成文字播放出来?
看到回答中很多人分享的是软件,每次使用都需要下载,给大家分享两款在线端语音转文字工具,不用下载安装,在线登录就能使用,非常方便。
1、网易见外
网易见外是网易团队上线的一款转文本工具,上线了视频转写…

Web Speech API-语音合成
使用场景
通过 TTS 引擎把文本转化成语音输出,web使用在网页文字转语音播放、页面阅读等功能上 依赖windows的TTS引擎 知识点
Web Speech API 使您能够将语音数据合并到 Web 应用程序中。 Web Speech API 有两个部分:SpeechSynthesis 语音合成…

STM32单片机OLED语音识别路灯台灯控制系统人检测亮度调节
实践制作DIY- GC0143-OLED语音识别路灯台灯控制系统 基于STM32单片机设计---OLED语音识别路灯台灯控制系统 二、功能介绍:
电路:STM32F103C系列最小系统串口语音识别模块LED灯板1个红外传感器OLED显示器1个手动自动模式键1个开关按键
1.有两个模式1个手…
TensorFlowLite 声音识别
开发
添加tensorflow的核心依赖
implementation org.tensorflow:tensorflow-lite-task-audio:0.4.0将训练模型放到main/assets文件夹下 在build.gradle中配置
因为打包时tflite文件可能会被压缩,所以需要配置如下 buildFeatures {viewBinding true}androidResources {noComp…
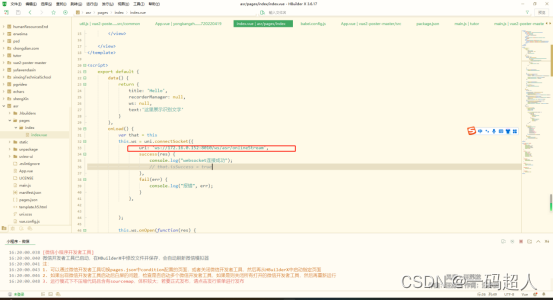
百度飞桨paddlespeech实现小程序实时语音流识别
前言:
哈哈,这是我2023年4月份的公司作业。如果仅仅是简单的语音识别倒也没什么难度,wav文件直接走模型输出结果的事。可是注意标题,流式识别、实时!
那么不得不说一下流式的优点了。
1、解决内存溢出的烦恼。
2、…
python_视频中语音识别转出文本
注意:没有“stepladder”的同学建议不要看啦
目录
1. 安装需要的包
2. 视频转音频
3. 对音频进行切割
4. 对视频进行切割
5. 从音频中识别出文本
5.1 使用离线方法
5.2 使用在线方法
5.3 两种方法比较
6. 用到的包下载 1. 安装需要的包
1.1 安装SpeechRe…

【AI视野·今日Sound 声学论文速览 第十五期】Fri, 29 Sep 2023
AI视野今日CS.Sound 声学论文速览 Fri, 29 Sep 2023 Totally 1 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers
Audio-Visual Speaker Verification via Joint Cross-Attention Authors R. Gnana Praveen, Jahangir Alam使用语音信号进行了说话人验证的…
AISHELL-3语料库及格式解读
AISHELL-3希尔贝壳中文普通话语音数据库AISHELL-3的语音时长为85小时88035句,可做为多说话人合成系统。录制过程在安静室内环境中, 使用高保真麦克风(44.1kHz,16bit)
声调的标记格式
采用数字1、2、3、4、5,代替《汉…
树莓派基于pyaudio实现录音功能
因为在做一个语音识别机器人,需要用到录音模块,本来想直接用arecord命令:
os.system(arecord -d 4 -r 16000 -c 1 -t wav -f S16_LE -D plughw:1,0 record.wav)但每次运行结束后再次运行就会出现“arecord”资源被占用,输入ps -a…

语音芯片在射击游乐设备上的应用
射击打靶体验馆项目,产品设备仿真程度高、趣闻性强、外观逼真,现场体验是一种集体验,体育竞技为一体且室内外均可使用的游乐!
在靶上能够看到击中目标的效果,而且会语音报环靶,通过低音炮,可以…
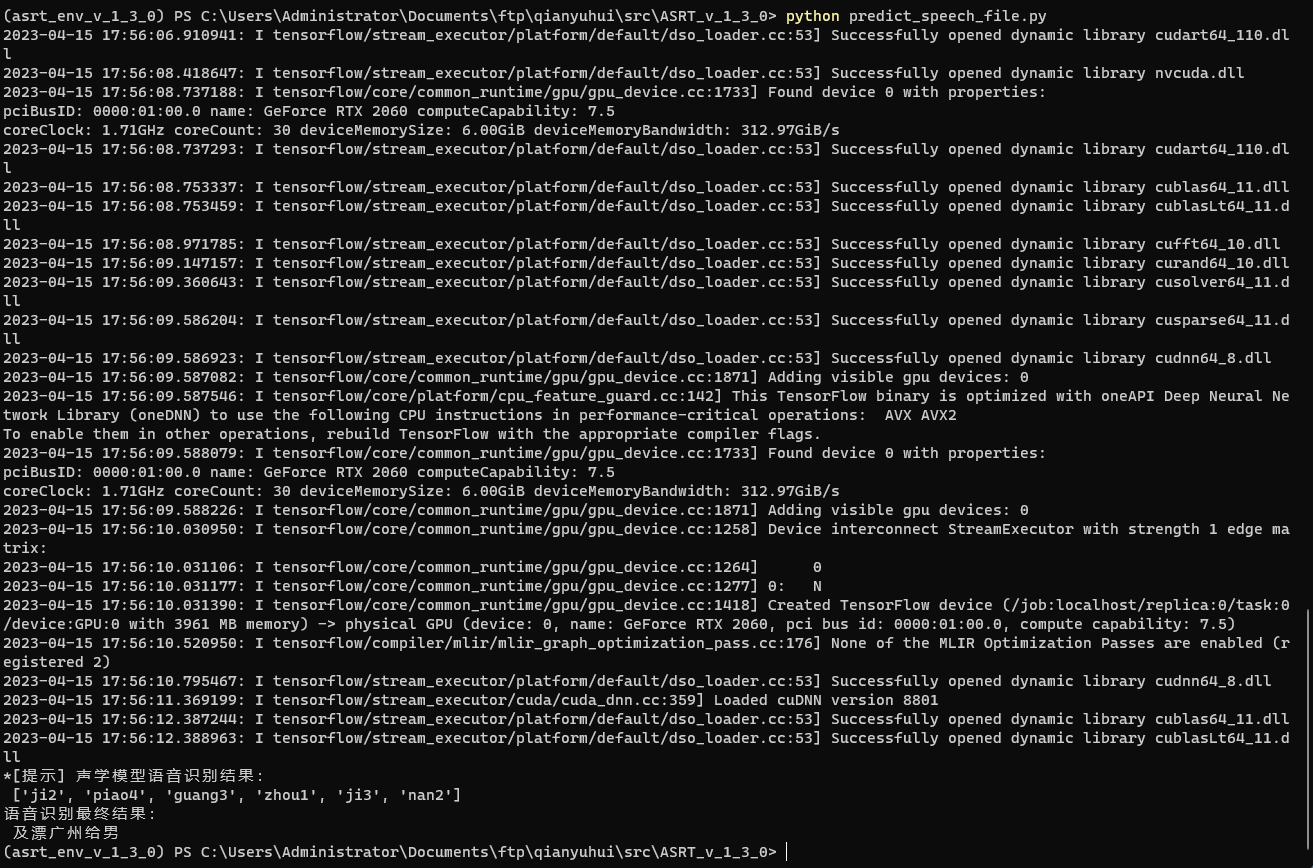
ASRT语音识别系统部署及模型训练笔记
ASRT语音识别系统部署及模型训练笔记
前言
ASRT是一个中文语音识别系统,由AI柠檬博主开源在GitHub上。
GitHub地址:nl8590687/ASRT_SpeechRecognition
国内Gitee镜像地址:AI柠檬/ASRT_SpeechRecognition
文档地址:ASRT语音识…
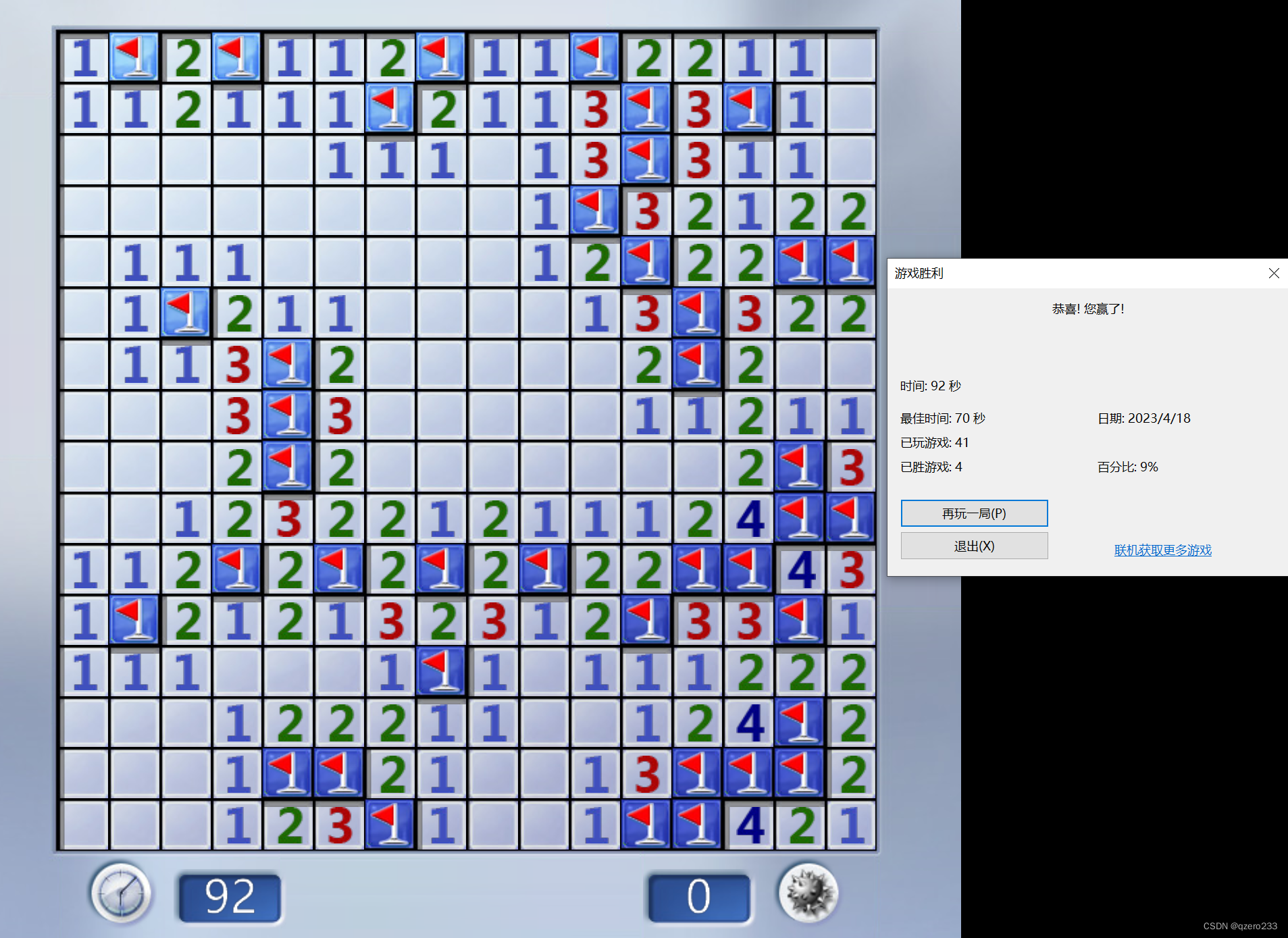
使用java实现自动扫雷
写在前面
本项目已在github开源,链接https://github.com/QZero233/JavaAutoMinesweeper 本文的写作风格可能会有些奇怪,这是笔者的一次全新的尝试,后续会换回写blog的文风的
摘要
本文提出了一个全自动完成扫雷游戏的解决方案,…
使用 Transformers 为多语种语音识别任务微调 Whisper 模型
本文提供了一个使用 Hugging Face 🤗 Transformers 在任意多语种语音识别 (ASR) 数据集上微调 Whisper 的分步指南。同时,我们还深入解释了 Whisper 模型、Common Voice 数据集以及微调等理论知识,并提供了数据准备和微调的相关代码。如果你想…
【Matlab语音处理】数字音频分析与处理系统【含GUI源码 1739期】
一、代码运行视频(哔哩哔哩)
【Matlab语音处理】数字音频分析与处理系统【含GUI源码 1739期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社&#…
【Matlab语音处理】音频数据处理【含GUI源码 1734期】
一、代码运行视频(哔哩哔哩)
【Matlab语音处理】音频数据处理【含GUI源码 1734期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019…
【Matlab语音识别】HMM 0~9数字和汉字语音识别(带面板)【含GUI源码 1716期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】HMM 0~9数字和汉字语音识别(带面板)【含GUI源码 1716期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版&am…
【Matlab语音分析】语音信号分析【含GUI源码 1718期】
一、代码运行视频(哔哩哔哩)
【Matlab语音分析】语音信号分析【含GUI源码 1718期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019…
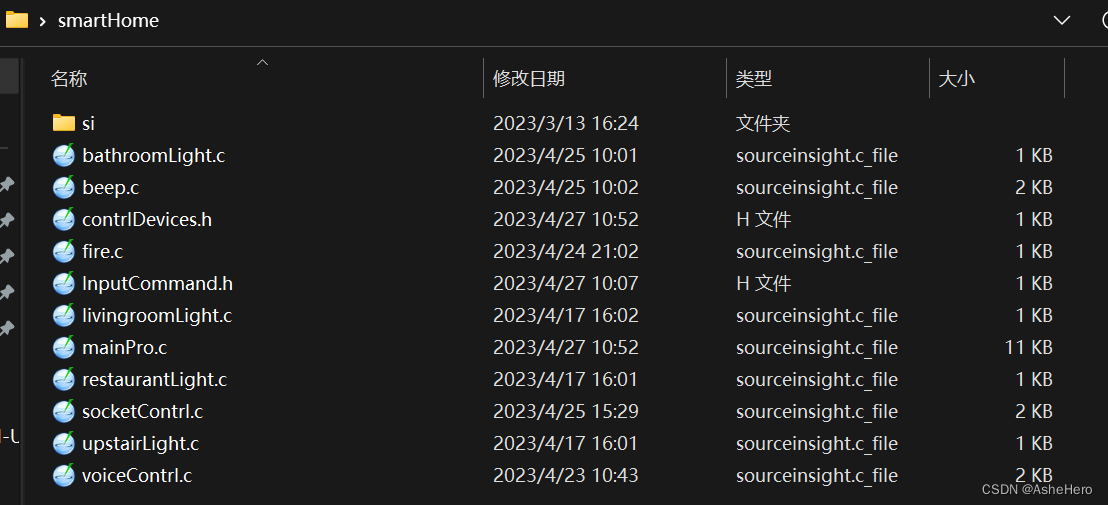
基于RAM树莓派实现智能家居:语音识别控制,Socket网络控制,火灾报警检测,实时监控
目录
一 项目说明
① 设计框架
② 功能说明
③ 硬件说明
④ 软件说明
二 项目代码
<1> mainPro.c 主函数
<2> InputCommand.h 控制设备头文件
<3> contrlDevices.h 外接设备头文件
<4> bathroomLight.c 泳池灯
<5> livin…
【Matlab语音识别】MFCC+VQ说话人识别系统【含GUI源码 1153期】
一、代码运行视频(哔哩哔哩)
【Matlab语音识别】MFCCVQ说话人识别系统【含GUI源码 1153期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社…
【Matlab语音去噪】音频信号去噪【含GUI源码 1386期】
一、代码运行视频(哔哩哔哩)
【Matlab语音去噪】音频信号去噪【含GUI源码 1386期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019…
【Matlab语言去噪】IIR+FIR滤波器语音去噪【含GUI源码 1027期】
一、代码运行视频(哔哩哔哩)
【Matlab语音处理】音频信号处理(调音调速调频滤波)(带面板)【含GUI源码 299期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信…

油烟机语音方案:NV040D语音芯片,支持MCU输入UART指令
随着人们生活水平的提高和厨房使用频率的增加,油烟机成为现代家庭生活中必不可少的一种家用电器,而语音智能化技术的发展也使得油烟机功能更加智能化。九芯电子的NV040D语音芯片是一种具备MCU输入UART指令功能的专业语音芯片,可以广泛应用于油…
Bark:基于转换器的文本到音频模型
Bark是由Suno创建的一个基于转换器的文本到音频模型。Bark可以生成高度逼真的多语言语音以及其他音频,包括音乐、背景噪音和简单的音效。该模型还可以产生非语言交流,如大笑、叹息和哭泣。为了支持研究社区,我们正在提供对预先训练的模型检查…
通过Python的speech_recognition库将音频文件转为文字
文章目录 前言一、音频准备二、音频声音三、格式转换四、音频转文字1.引入库2.定义音频路径3.创建一个Recognizer对象4.打开音频文件,将音频文件读入Recognizer对象5.尝试使用Google Web API将语音转换为文字6.转换结果 总结 前言 大家好,我是空空star&a…
一、FM1288调试方案-调试基础知识
为了方便后续的调试,我这边针对调试过程中,会遇到的专业基础知识做一下扫盲,方便后面阅读理解方案, 已经掌握或了解的可以直接跳过 文章目录 1. 声音的产生和记录(采样率/声道/精度/PCM编码)2. 语音的基本特征3. 声音的三要素:音调/音量/音色3. 人类听觉范围4. 人声的频…
FM1288回声消除芯片调试方案 - 综述
FM1288调试方案总体解决的问题: 1、怎么调试FM1288(原理)?调试成什么样算调好了(评价标准)? 2、影响音质的关节环节有哪些?怎么确认这些环节是没问题的? 3、怎么快速高效的完成音频调试?或者说实际…

现代语音信号处理笔记 (七) 语音特征参数估计
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本节针对《现代语音信号处理》这本书的第八章,对应基音估计和共振峰估计两部分。 基音估计
基音是语音信号的重要参数,在语音产生的数字模型中,也…
双11购物节国外剁手党同狂欢 阿里云视频云电商直播实时字幕
2020的双11狂潮已然提早,年度氪金剁手大会已吹响号角。
比起往年,今年格外不同,天猫双11早在10月21日便揭起预售大幕,8亿人蹲守淘宝直播,仅当日的李佳琦直播间,观看人次就突破了1.5亿,直至10月…
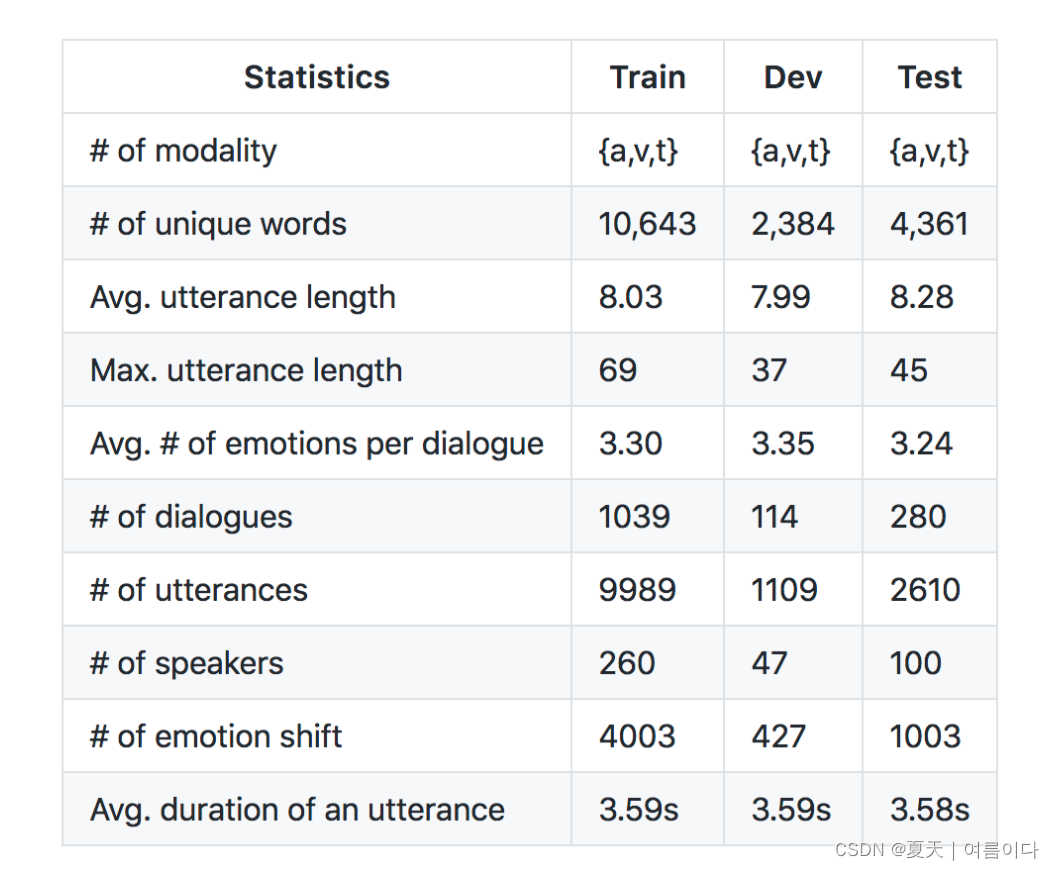
数据集 | 基于语音(Speech)/多模态(Multimodal)的情绪识别数据集,格式及下载
本文主要介绍了一些常用的语音🗣识别数据集,文件格式以及下载地址:
目录
1.IEMOCAP Emotion Speech Database(English)
2.Emo-DB Database(German)
文件命名 对象
3.Ryerson Audio-Visual Database of Emotional Speech and Song (Engli…

校园安全,一键报警主机助力保障
校园安全,一键报警主机助力保障
随着社会发展和科技进步,校园安全问题日益受到重视。如何保障师生们的安全成为了学校一项重要任务。而校园可视一键报警主机就是一种非常有效的安保设备。
这种报警主机集合了视频监控、安全防范、数据处理等多个功能&a…
kaldi源码解析实践
AIBigKaldi(十六)| Kaldi的quick模型(源码解析) AIBigKaldi(十五)| Kaldi的说话人自适应模型(源码解析) AIBigKaldi(十四)| Kaldi的特征转换模型(…
人工智能技术并非已经完全成熟,而进入发展应用的阶段
但实际上,在这个之后,奇迹并没有发生。准确一点说,今后或许会在个别领域取得进展,但是不会像之前预计的那样全面开花。特别是中国市场乐观的认为“中国市场大、数据多,运用又不受限制,所以将来奇迹一定会发…

语音识别 | kaggle鸟叫识别新赛赛题解析
整理自kaggle平台 赛题题目: BirdCLEF 2023 kaggle - 鸟声识别大赛
赛题链接:https://www.kaggle.com/competitions/birdclef-2023
赛题背景
鸟类是生物多样性变化的极好指标,因为它们具有高度流动性并且具有多样化的栖息地要求。因此物种…
有没有好用的文字转语音的工具帮推荐?
当然有了,像很多剪辑工具就能轻松将文字转换成语音,生成的音频文件直接添加到视频上。今天就给大家推荐三款简单又好用的配音神器,话不多说,一起来看看。
1、Mierosoft Edge
Mierosoft Edge是一款浏览器工具,同时也上…

STM32单片机蓝牙APP可烘干升降晾衣架带照明灯
实践制作DIY- GC0123-蓝牙APP可烘干升降晾衣架 一、功能说明:
基于STM32单片机设计-蓝牙APP可烘干升降晾衣架
功能介绍:
硬件组成:
STM32F103C系列最小系统单片机1个uln2003步进电机(模拟升降)1个uln2003步进电机&a…
中文语音语料数据集介绍(附数据集下载)
中文语音语料
zhvoice: Chinese voice corpus
tips: 中文或汉语的语言简称缩写是zh。
喜欢请star!你就是superstar!
语料简介
zhvoice语料由8个数据集,经过降噪和去除静音处理而成,说话人约3200个,音频约900小时&…


如何选择语音芯片?主流语音方案如何选,九芯电子来推荐
市场分析
近年来,随着我国半导体的不断发展和技术领域的不断突破,语音芯片实现了越来越多的国产化。其中涌现出的像NVD系列、NRK330X系列等不乏国产优秀产品。凭借其优秀的性能、设计,赢得了市场上的好评如潮。 对比分析
OTP语音芯片&#…
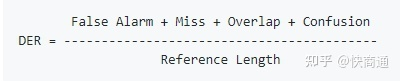
编辑距离与字符错误率CER
在语音识别场景中,字符错误率(Character Error Rate,CER)是衡量语音识别效果的一个重要指标。下文将介绍CER的原理,并且给出python实现的代码。
1 编辑距离
说到CER,不得不提的是编辑距离(Edi…

音频格式对ASR模型的影响
如果你写过read或load音频文件的程序,你会发现,音频数组和采样率通常会同时出现。如果你不知道采样率是什么,可以看看这篇文章。
作为一个炼丹师,对参数的敏感已经成为条件反射,很自然会想到的一个问题是:…

聚焦机器同传前沿进展,第二届机器同传研讨会将在NAACL举办
此前,向世界传递中国声音的“女神翻译官”们实力出圈,引发了大众对于同声传译的关注。为推动机器同传技术发展,2021年6月10-11日,第二届同声传译研讨会(The 2nd Workshop on Automatic Simultaneous Translation&#…

半入耳蓝牙耳机什么牌子好?口碑最好的半入耳蓝牙耳机推荐
入耳式耳机由于有橡胶耳塞起到的密封效果,音质和降噪效果都表现出色,但是并不是所有人群都适合,耳朵大小因人而异,但是半入耳的包容性好太多了,只是利用流线型的外形,轻轻地挂在耳甲腔上,就可以…
3款良心文字转语音工具,不仅功能强大,还好用到哭!
多想做抖音、快手 、视频号、西瓜等,自媒体短视频的朋友,都会遇到一个很头疼问题,那就是视频拍好了,却不知道如何配音 ,用自已的声音嘛觉得不好听,请别人配音嘛死贵,那都是按字数收费的啊!一次性…

血压计语音IC方案,低功耗语音芯片NV080C-SOP8
近年来,随着智能化的发展,我们看到越来越多的医疗设备被智能化并应用到人们的生活中。这其中,血压计是其中之一,这是一种简单而普遍的医疗测量设备,用来测试人体的血压指数,它在生活中应用十分广泛。如今…
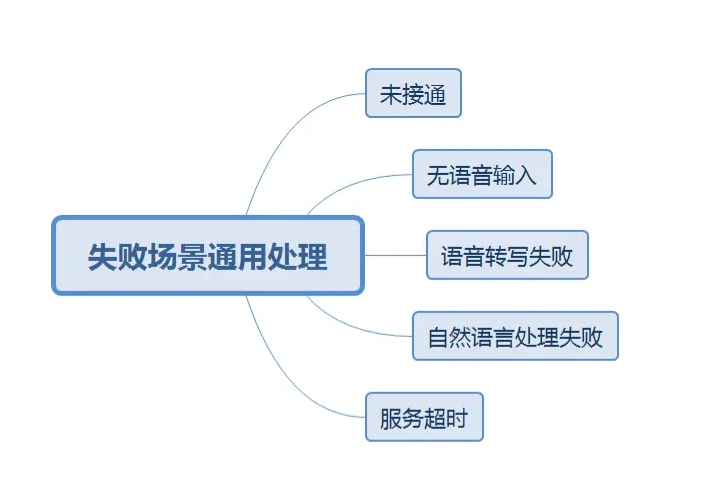
AI机器人外呼失败的处理方法
AI技术革新了外呼行业的工作模式,AI语音机器人外呼替代或者辅助着人工坐席,极大的提高了外呼的效率。各大公司也本着节省投入,提高效率的原则,快马加鞭地上了AI语音机器人进行外呼工作。那么AI语音机器人外呼,失败的数…

人工智能交互系统界面设计(Tkinter界面设计)
文章目录前言一、项目介绍二、项目准备三、项目实施1.导入相关库文件2.人脸信息验证功能3.语音交互与TCP数据通信4.数据信息可视化四、相关附件前言
在现代信息化时代,图形化用户界面(Graphical User Interface, GUI)已经成为各种软件应用和…
讯飞语音合成andriod版本
目录直达1、成员变量声明2、参数设置3、获取离线资源4、语音合成监听5、调用方法合成语音6、在onCreate中初始化合成对象7、添加一个按钮8、按钮按下监听在离线命令的基础上,我们可以添加语音合成功能,因为讯飞语音合成于离线命令识别有相同的地方&#…
SFSpeechRecognitionTask.error 错误码对照表
iOS 语音识别引擎中常见错误对照表 加注释了
error
An error object that specifies the error that occurred during a speech recognition task.
iOS 10.0 macOS 10.15 Mac Catalyst 13.1
Declaration
property(nonatomic, readonly, copy, nullable) NSError *error;…
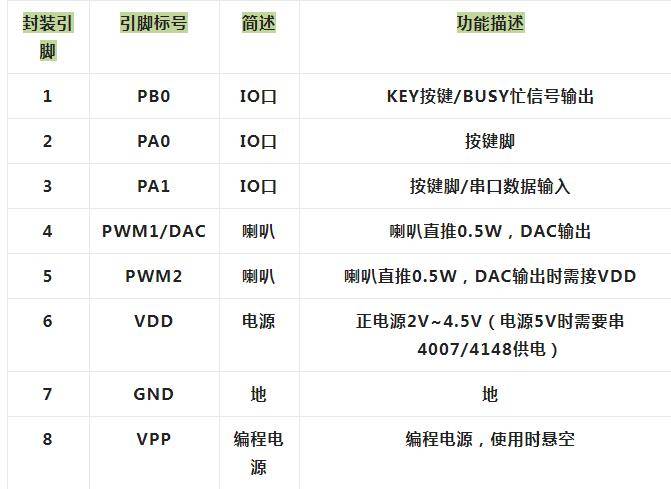
多功能料理锅语音播放芯片——NV040C
多功能料理锅就是一锅搭配多个锅盘,可以实现火锅、烤肉、花式煎蛋、丸子等多种烹饪功能。 多功能料理锅语音方案设计需求:
多功能锅本身体积有限,按钮比较少,相应功能的字体要贴按钮旁边,字体也是比较小的,…

60行代码出炫酷效果之 python语音控制电脑壁纸切换
前言
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 电脑大家有吧!手大家有吧!今天!!
就由我带领大家用区区60行代码打造一款语音壁纸切换器程序!!! 单纯的桌面有时候会让人觉得单调,…
whisper 语音识别AI 声音To文字
whisper介绍
Whisper 是一个由 OpenAI 训练并开源的神经网络,功能是语音识别,能把语音转换为文字,在英语语音识别方面的稳健性和准确性接近人类水平。
1、Whisper支持语音转录和翻译两项功能并接受各种语音格式,模型中、英、法、德、意、日等主流语言上…
实用篇 | huggingface的简单应用
本文主要介绍hugging Face(拥抱脸)的简单介绍以及常见用法,用来模型测试是个好的工具~ 如下图所示左边框是各项任务,包含多模态(Multimodal),计算机视觉(Computer Vision),自然语言处理(NLP)等,…

是否有将文字转换为语音的应用?
仅仅将文字转换为语音的应用还不行,生成的音质必须还要清晰、不破音,听起来像真人一样。给大家分享三款超实用配音工具,每一款好用到爆炸。
1、Amazon Polly
经常使用亚马逊购物的用户对这款软件非常熟悉了,Amazon Polly是亚马逊…

有没有一个比较好的文字转换成语音的手机软件?
好的文字转换成语音软件必须要满足使用简单、转写效率高特点。下面给大家准备了两款好用的文字转语音工具,每一款都非常实用。
1、手机自带配音功能
现在手机基本上自带文字转语音助手,通过功能设置,也能实现文字配音,以华为手机…

有没有能将语音转为文字的App或者网站呢?
平时有没有这种困扰?将音/视频中的文件转换为文本时,需要反复播放文件,一遍听一边写才能完整将内容整理成文字,这样的工作效率实在太慢了。近几年人工智能发展,各种AI智能识别工具应用在工作中。以语音转文字为例&…

怎么才能在手机上把语音转成文字啊?
语音转文字是生活中经常遇到的问题,借助的录音快速几率会议、课堂、讲座等重要场景内容,通过语音转文字工具快速整理成文本。既能避免重要内容被遗忘,也能提高工作、学习效率。说实话,市场上不缺乏优秀的语音转文字工具。但是要兼…

盘点PC端超好用的文字转语音工具,赶紧收藏起来
文字转语音一直是生活中常见问题,目前市场上主要分为真人配音和软件配音。
真人配音:自由切换不同场景的配音情感,配出的声音更加真实。 软件配音:价格实惠,选择配音主播众多,生成的音质具有特色。 尽管目…
Alexa交叉编译(avs-device-sdk)
Alexa交叉编译(avs-device-sdk)1 前言2 环境准备2.1 工程目录构建2.2 下载三方库文件2.3 下载源码3 编译依赖库3.1 编译portaudio3.2编译nghttp23.3 编译curl3.4 编译gstreamer3.4.1 编译zlib3.4.2 编译libffi3.4.3 编译glib3.4.4 编译gstreamer3.4.5 编…
Unity 科大讯飞语音唤醒
今天更新unity讯飞的语音唤醒功能,由于之前使用的是语音识别,识别出唤醒词来做了一个假的语音唤醒。 缺点:语音识别一直处于识别中。结果可想而知,一天的识别量达到了1W次,这次多么恐怖的一件事啊。 要想知道1000元购买…
Android音频延时问题
这个问题在Android上是个难点。 Android在诞生之初对声音的播放和录音延时并没有非常严格的要求。手机厂商之前也都不在意延时指标,这几年才慢慢有改观。Android最近几年的新版本也一直在逐步改善延时问题,不过各大手机厂有多重视就不得而知了。 …

用JS方法定义nav滑动门打开特定选项卡_Bootstrap5
分享一段用JS方法定义nav滑动门打开特定选项卡的效果,可以用到的朋友直接拷贝走。效果如下: <!doctype html>
<html lang"zh-CN">
<head>
<title>最强大的CMS_逐浪CMS</title>
<meta name"Generator&qu…
AI智能阅读助力全栈开发-逐浪CMS语音辅助2.0发布
北京时间2021年11月1日: 引领CMS门户与全栈开发的逐浪软件科技集团,正式官宣:发布AI语音应用体系2.0。 此次发布的AI语音应用体系,是基于开放平台技术,打造的人工智能语音,其主要体现,可以在为网…
【Matlab声学检测】MFCC+GMM安全事件声学检测系统【含源码 1699期】
一、代码运行视频(哔哩哔哩)
【Matlab声学检测】MFCCGMM安全事件声学检测系统【含源码 1699期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社&…
【Matlab语音去噪】傅立叶变换语音降噪混频【含GUI源码 297期】
一、代码运行视频(哔哩哔哩)
【Matlab语音去噪】傅立叶变换语音降噪混频【含GUI源码 297期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社&#x…

离线语音识别芯片IC方案,打造智能眼部按摩仪WTK6900H-C-24SS
随着科技的不断进步,智能化产品已经成为人们日常生活中的一部分。眼部按摩仪作为舒缓眼部疲劳的利器,如今更是加入了离线语音识别芯片IC方案,让使用体验更加智能化、便捷化,WTK6900H-C-24SS离线语音识别芯片IC方案,将为…

全连接神经网络的缺点,神经网络有什么用
神经网络优缺点,
优点:(1)具有自学习功能。例如实现图像识别时,只在先把许多不同的图像样板和对应的应识别的结果输入人工神经网络,网络就会通过自学习功能,慢慢学会识别类似的图像。自学习功能…
人工智能算法 上市公司,人工智能算法公司排名
人工智能上市公司龙头股票有哪些
一、科大讯飞(002230),属于人工智能稀缺标的,多领域布局苦尽甘来,业绩拐点临近。二、浪潮信息(000977),人工智能基础设施提供商,目前具备业界最全CPU服务器产品线。
三、中科曙光(60…

现代语音信号处理笔记 (六) 语音信号的非线性分析
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本节针对《现代语音信号处理》这本书的第七章,对语音信号的非线性分析部分。 语音信号的非线性分析
统计信号处理的经典方法建立在线性、平稳及二阶统计量(特别是服从高斯…

李宏毅DLHLP.11.Speech Separation.1/2. Deep Clusterring, PIT
文章目录介绍Speaker SeparationEvaluationPermutation IssueDeep ClusterringMaskingIdeal Binary Mask (IBM)Deep ClusteringDeep Clustering – TrainingPermutation Invariant Training(PIT)介绍
本门课程是2020年李宏毅老师新课:Deep Learning for Human Lang…

TDNN时延神经网络---TDNN-F
1.TDNN时延神经网络 【转载】
近来在了解卷积神经网络(CNN),后来查到CNN是受语音信号处理中时延神经网络(TDNN)影响而发明的。本篇的大部分内容都来自关于TDNN原始文献【1】的理解和整理。该文写与1989年,…
让你真正理解HMM(Hidden Markov Model)的算法演示程序
HMM, 隐Markov模型, 在人脸, 步态, 语音识别等领域有着广泛的用途.
通过以Javascript语言演示其使用方法, 读者可方便地理解其计算过程(其实,并不难).
理论就不讲解了,直接看计算过程: <html>
<head>
<meta charset"UTF-8"/>
<me…
智能语音(识别+格式转换+合成+相似度分析+问答)
from aip import AipSpeech 文件格式转换(os)翻译成文字(原流001010)提取有效信息文段利用相似度(simnet)人工制定答案
将答案与voice合成音频写入mp3
from aip import AipNlp
import os
#lsi模型
App_ID"11520823&…
人工智能项目(介绍)
人工智能(Artificial Intelligence),英文缩写为AI。百度百科是这样介绍的:它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
下面我将用技术的层面解释人工智能的实现:一…
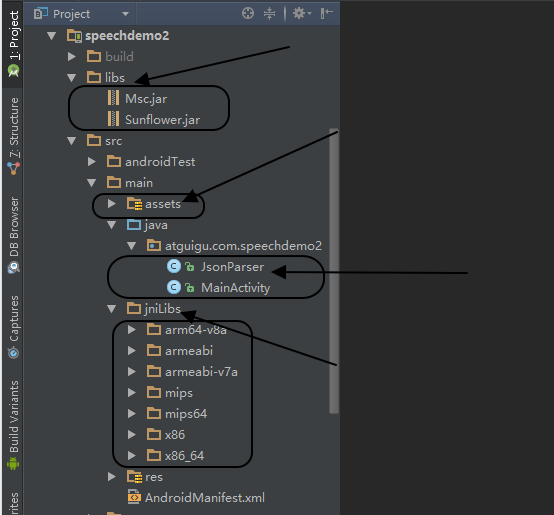
Android科大讯飞语音集成,非常详细的使用讲解
讯飞语音开发集成地址http://www.xfyun.cn/ 解压后的doc文件夹下的msc develop 文件中有详细集成步骤 AppId: 1.先要注册开发者账户, 添加我的应用 , 下载sdk 2.下载后将sdk解压, 把案例导入工程中运行看看效果 3.将libs下的两个jar包添加到libs目录下, 将同路径下的其它 …
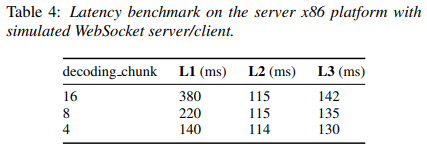
完美解释:wenet-流式与非流式语音识别统一模型
Unified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recognition[1] ,本文以该篇论文为主线,进行扩展。参考了很多大佬博客,非常感谢。如有错误,请指正。 流式与非流式语音识别统一模型-出门问问&西工…

基于RNN的CTC loss
CTC loss
依据RNN网络的性质,每个时刻输出一个字符,RNN的最终输出是字符序列S ,需要后处理才能得到标签T 。在实际应用中,例如文字识别过程中,S 和T 的长度是变化的,且不是等长的,那么就需要一…
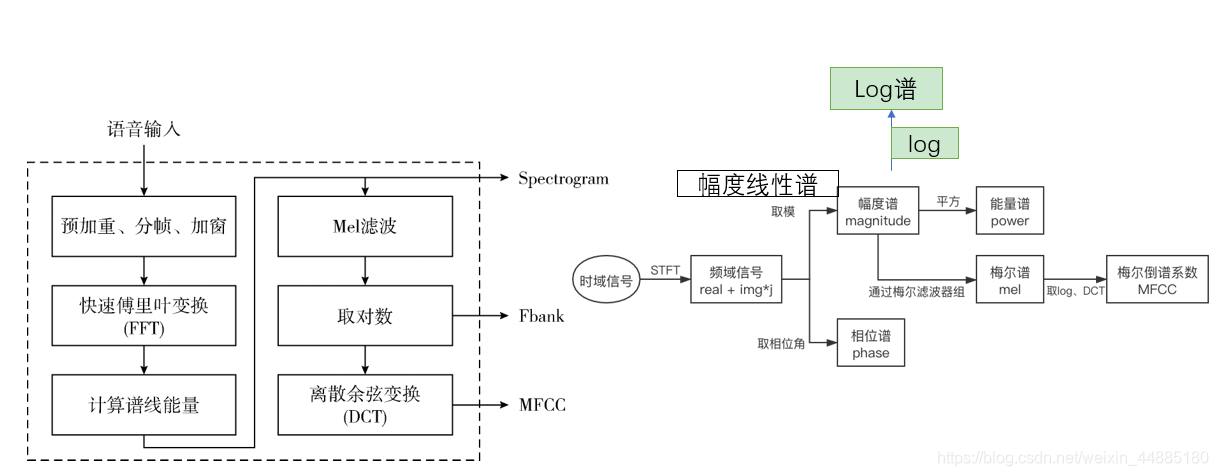
语音特征:mfcc、fbank和语谱图概述
语谱图一般口语上说的是语音的log谱特征,就是你用audition或者Audacity看到的横轴是时间,纵轴是频域的图像。简单看一下语音特征的提取过程就可以知道这两者之间的关系了:
对语音序列做STFT,其中包括分帧,加窗和对每一…
语音识别开源项目汇总
语音识别技术随着神经网络的兴起和发展,准确率得到了很大的改善,在很多场景下都可以逐步商用落地了,很多公司也组建了语音团队。其实在github上,语音识别相关的项目也是层出不穷,其中的一些项目的质量很高,…
Python 实现语音转文本
Python 实现语音转文本
Python可以使用多种方式来实现语音转文本,下面介绍其中两种。
方法一:使用Google Speech API
Google Speech API 是 Google 在 2012 年推出的一个 API,可以用于实现语音转文本。使用 Google Speech API 需要安装 Sp…

基于MFCC特征提取和GMM训练的语音信号识别matlab仿真
目录
1.算法运行效果图预览
2.算法运行软件版本
3.部分核心程序
4.算法理论概述
4.1 MFCC特征提取
4.2 Gaussian Mixture Model(GMM)
4.3. 实现过程
4.4 应用领域
5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本
matlab2022a
3…
Buzz语音转文字安装使用(含Whisper模型下载)
简介:
Transcribe and translate audio offline on your personal computer. Powered by OpenAI’s Whisper. 转录和翻译音频离线在您的个人计算机。由OpenAI的Whisper提供动力。 可以简单理解为QT的前端界面,python语言构建服务端,使用Whis…

树莓派实现语音识别与语音合成——百度云语音识别API
本文采用百度云语音识别API接口,实现低于60s音频的语音识别,也可以用于合成文本长度小于1024字节的音频,此外采用snowboy离线语音唤醒引擎可实现离线语音唤醒,实现语音交互。基于本内容可实现语音控制小车,语音控制音箱…
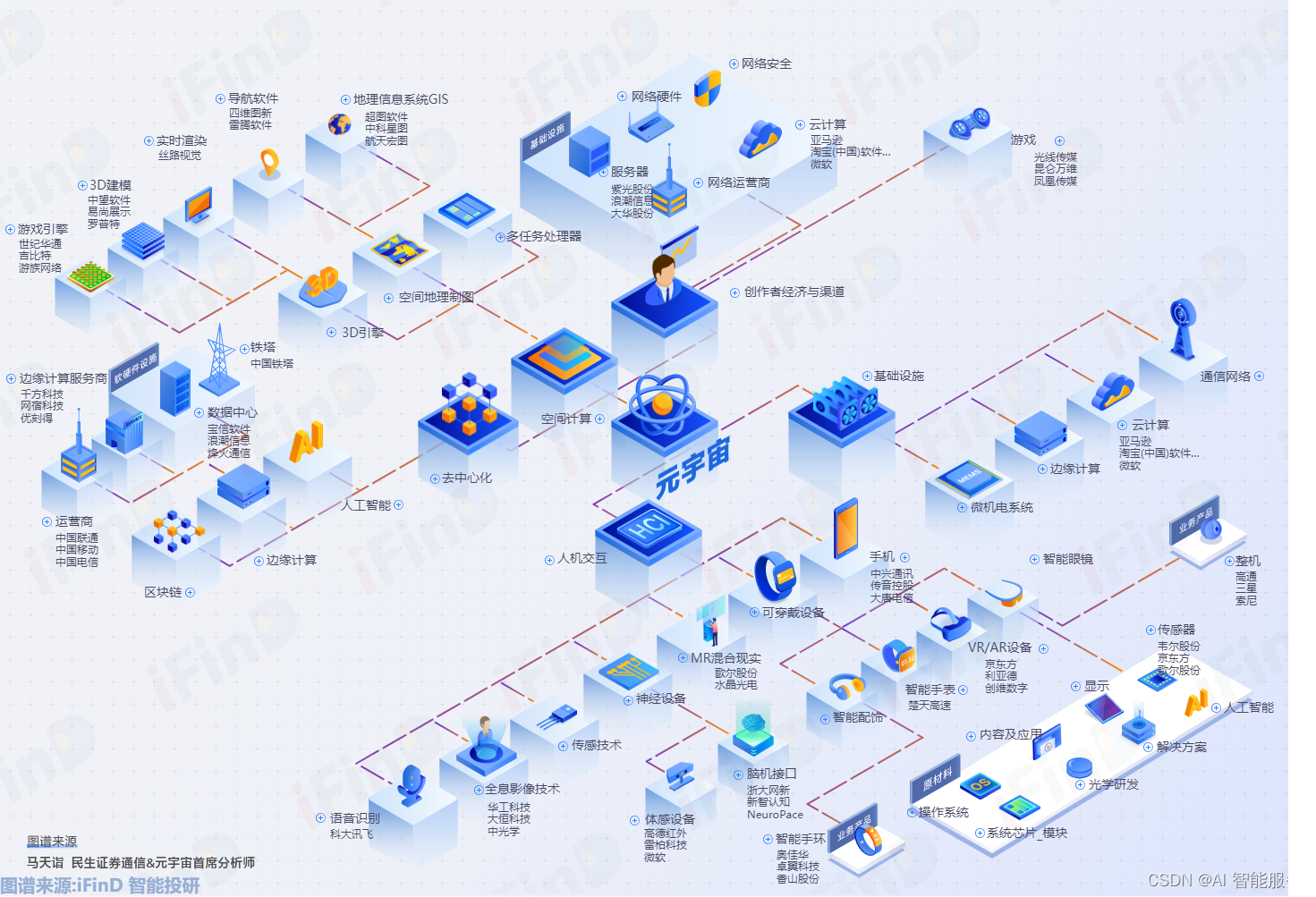
虚拟数字人的产业生态
虚拟数字人的产业生态包括以下方面:
创作工具:为创作者提供高效、便捷的创作工具,如3D建模软件、动画制作软件等,以及可编程的虚拟数字人引擎。内容制作:为影视、游戏、动漫、音乐、舞蹈等娱乐领域提供虚拟数字人形象…

YS-LDV7语音模块二次开发
1.YS-LDV7语音模块:
工作电压:5V通信方式:串口通信单片机型号:STC11L08XE
2.源码修改:
(1)使用 Keil uVision4 进行修改,打开 code: 或者打开keil4 APP文件夹…

NV040D语音芯片丨助力空气净化器语音功能
空气净化器通过过滤网和电子静电等技术,可以清除室内空气中的有害物质,如灰尘、花粉、细菌、甲醛等,达到净化空气的目标,让人们呼吸到更加清新的空气,保护人体健康。在空气净化器中加入九芯语音芯片的提醒功能…

机器学习原来这么有趣!第五章:Google 翻译背后的黑科技:神经网络和序列到序列学习
第一章:全世界最简单的机器学习入门指南 https://blog.csdn.net/wskzgz/article/details/89917343 第二章:用机器学习制作超级马里奥的关卡 https://blog.csdn.net/wskzgz/article/details/89945137 第三章:图像识别-深度学习与卷积神经网络 https://blo…

小蜗语音工具1.9、文本,小说,字幕生成语音、多角色对话,语音识别、读取音频字幕
小蜗语音免费工具 一、文本转字幕文本内容和TXT文件 二、文本转语音1、文本内容生成语音2、字幕生成语音3、多角色对话4、选择文件5、批量处理 三、语音识别、音频MP31、语音识别2、下载模型下载地址 一、文本转字幕
可以把正本小说,生成字幕文件。不限制文件的大小…
【项目】—— 语音小管家Sosuke
项目简介
借助图灵机器人和百度语音识别和合成等第三方平台和第三方工具使用C编写一个智能AI对话和语音命令执行的语音管理工具除去交流功能之外还可以执行Linux下相关命令,可执行的命令支持自己配置
项目技术点
C STL中主要是map和unorder_map的使用了解http第三…
视频高效剪辑,批量调整视频速度,让视频更加精彩
你是否曾经需要调整多个视频的速度,但却苦于手动操作效率低下?如果你也遇到了这样的问题,那么是时候采取行动,使用一款高效易用的视频处理工具了。
首先,我们要进入好简单批量智剪,并在板块栏里选择“任务…

智能文字识别技术——AI赋能古彝文保护
前言 人工智能在古彝文古籍保护方面具有巨大的潜力和意义。通过数字化、自动化和智能化的手段,可以更好地保护和传承古彝文的文化遗产,促进彝族文化的传承和发展。 文章目录 前言一、古彝文是什么?1.1古彝文的背景1.2古彝文古籍保护背景 二、…

批量混剪系统视频闪闪批量剪辑:只需几段素材片段即可批量混剪大量成片,快速制作大量成片的秘密
视频闪闪批量混剪系统:快速制作大量成片的秘密
在今天这个视频内容爆炸的时代,如何快速处理大量的素材并生成优质的成片,是许多视频制作人员面临的挑战。而视频闪闪批量混剪系统,却能帮助你轻松解决这一难题。
视频闪闪批量混剪…

ai智能语音机器人必须具备的功能
近年来,大多数互联网公司都进入了智能化领域。 随着人工智能技术的不断升级和突破,智能出境行业涌现出许多新品牌。 这些品牌有的以价格取胜,有的以产品性能取胜,这确实给消费者增加了很多选择。
然而,智能外呼产品…
AI智能机器人的语音识别是如何实现的 ?
什么是智能语音识别系统?语音识别实际就是将人类说话的内容和意思转化为计算机可读的输入,例如按键、二进制编码或者字符序列等。与说话人的识别不同,后者主要是识别和确认发出语音的人并非其中所包含的内容。语音识别的目的就是让机器人听懂…

KT148A语音芯片的组合播放详细说明 包含语音制作 压缩 下载 播放
目录 一、组合播放简介
2.1第一步:生成语音素材
2.2第二步:将需要的语音素材剪裁
2.3第三步:使用我们的压缩软件进行压缩-F1A
2.4第四步:使用我们的下载软件--下载到KT148A芯片里面去
2.4第五步:使用MCU发送一线串…
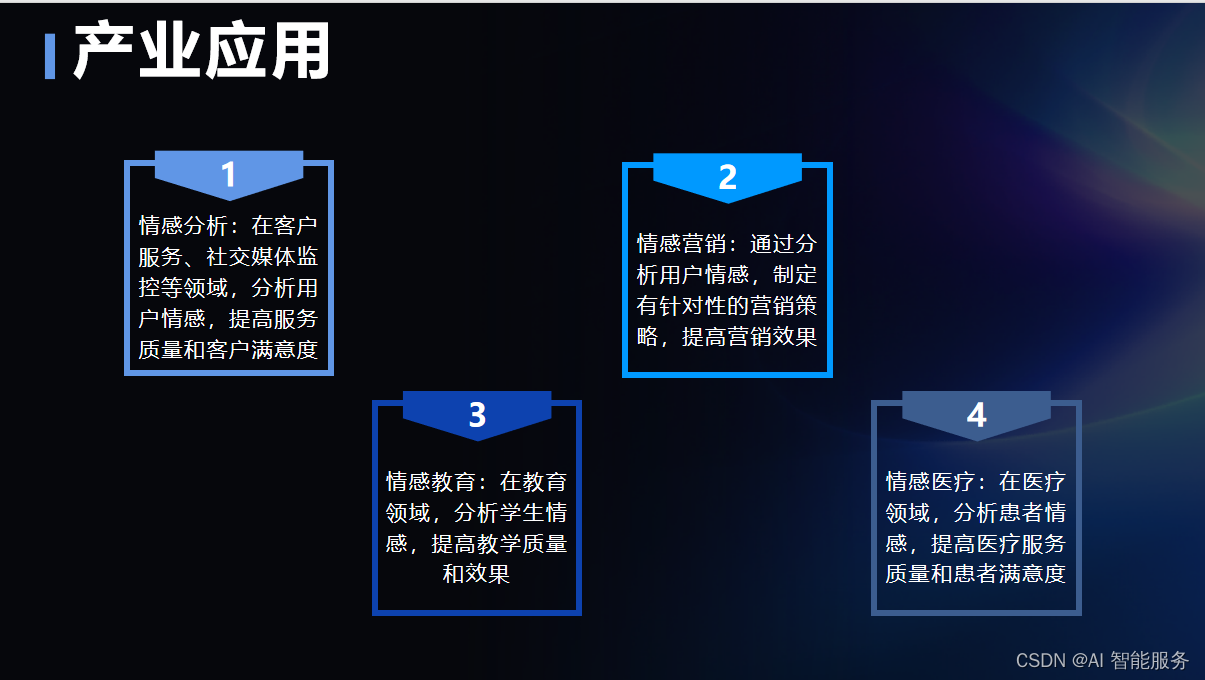
文本情感计算技术(深度)
文本情感计算技术的发展得益于社交媒体的蓬勃发展。文本情感计算的研究至今已有 20年的历史,仍是国内外学术界和产业界的研究热点。随着新技术的变迁、新任务的出现,以及更高性能算法需求的增长,文本情感计算涉及多项有挑战性的研究任务。文本…

人机交互-语音交互的人类感知机制
声音的产生 肺中的空气受到挤压形成气流,气流通过声门(声带)沿着声道(由咽、喉、口腔等组成)释放出去,就形成了声音。
人的发声过程包括两个步骤:
首先声门、声带产生不同频率的声音ÿ…
AI 语音 - 人物音色训练
前情提要
2023-07-02 周日 杭州 阴晴不定
AI 入门三大项,AI 绘画基础学习,AI 语音合成,AI 智能对话训练,进入 AI 语音合成阶段了,搓搓小手很激动的,对于一个五音不全的我来说,这个简直了(摆脱…
python-语音识别
使用pyttsx的python包,你可以将文本转换为语音。
安装命令
pip install pyttsx3 -i https://pypi.tuna.tsinghua.edu.cn/simple
运行一个简单的语音 ‘大家好’。
import pyttsx3 as pyttsx
engine = pyttsx.init() #初始化
engine.say(大家好)
engine.runAndWait()
另一…

Youtube视频加字幕需要的软件电脑版+手机版 2020语音视频自动生成字幕软件
1.抖音出品剪映手机版 : https://lv.ulikecam.com/
2.快手软件快影 手机版: https://www.kuaishou.com/kuaiying
电脑版配合模拟器使用 挨个网站点了一圈,有下载的,但都不是快影电脑版。又到快影官网查看,根本没有电…
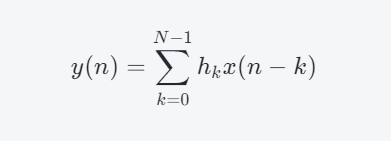

智能电话机器人的出现,能够解决哪些问题?
经济的繁荣与高速的发展,使得电销这个方式快速地融合在房地产与金融投资等大部分行业上。在电销人员与客户的沟通上,难免会出现很多问题,毕竟所面对的客户都是各行各业,他们有着不同的经历和身份。
对于时常需要处理客户投诉、安…
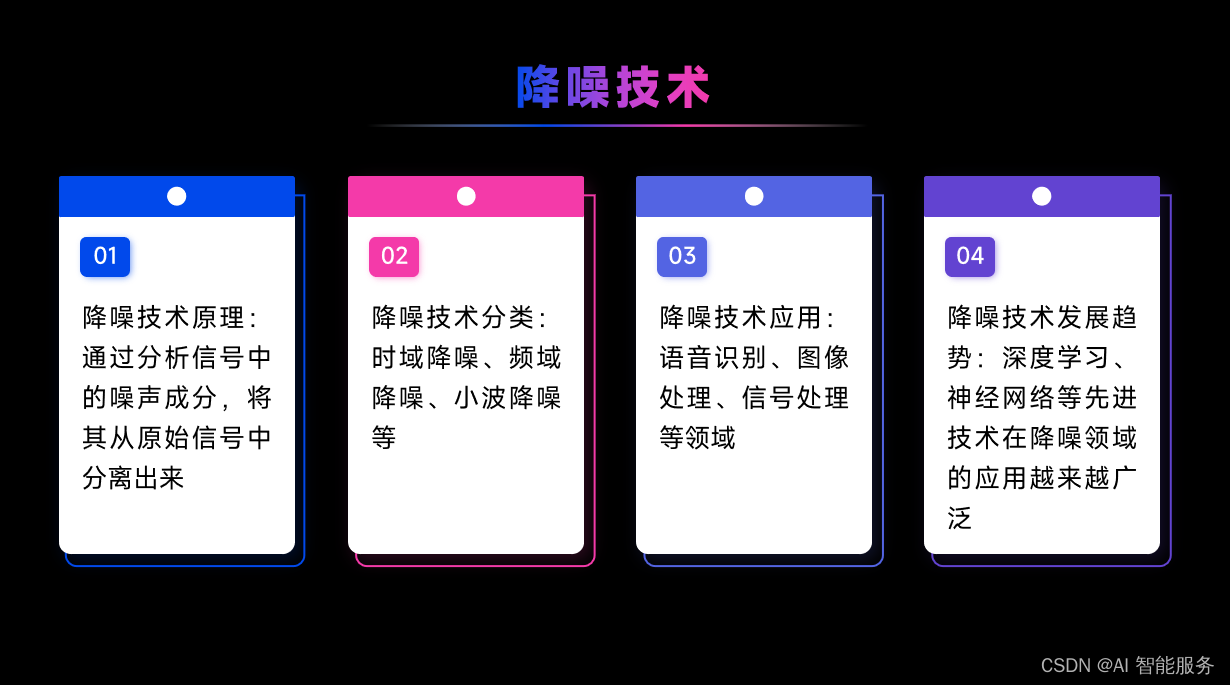
基础课4——语音识别技术
ASR 是自动语音识别(Automatic Speech Recognition)的缩写,是一种将人类语音转换为文本的技术。ASR 系统可以处理实时音频流或已录制的音频文件,并将其转换为文本。它是一种自然语言处理技术,广泛应用于许多领域&#…

电压放大器在电子实验中有哪些作用
电压放大器在电子实验中扮演着重要的角色,它可以实现对电压信号的放大,为实验提供所需的电压级别。下面是电压放大器在电子实验中的几个常见作用: 信号放大:电压放大器的主要作用是将输入信号的幅度放大,以便进行更准确…
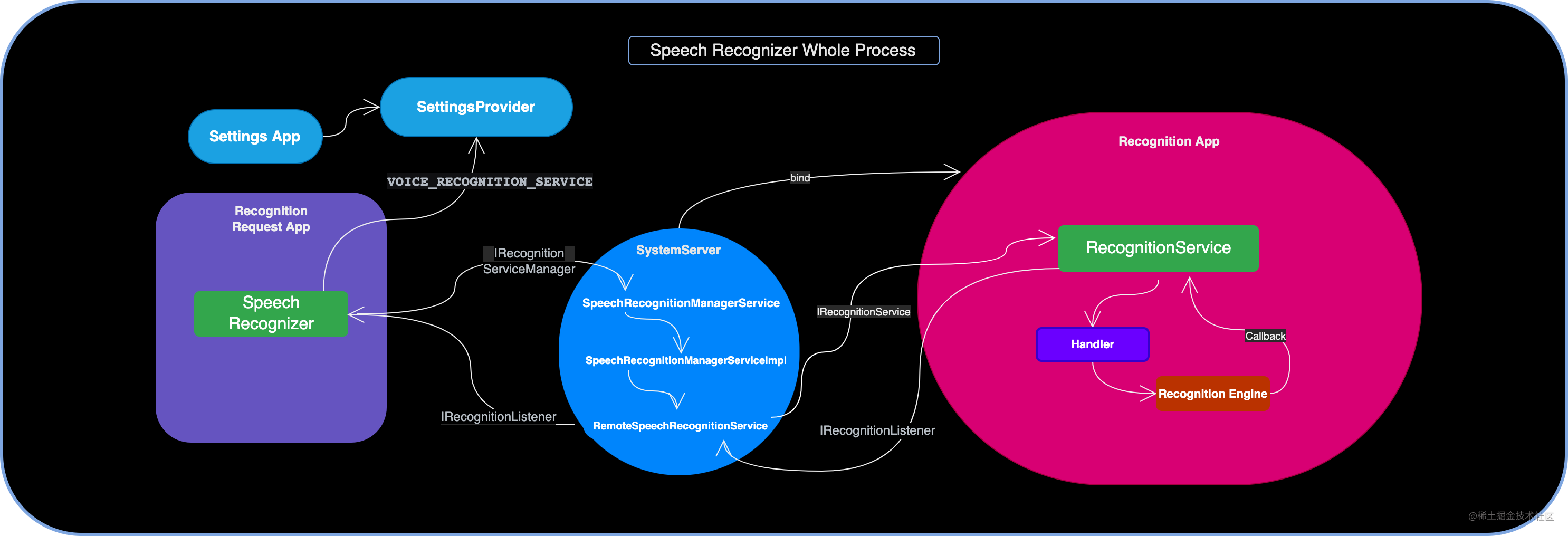
Android 标准语音识别框架:SpeechRecognizer 的封装和调用
前言
此前,笔者梳理了语音相关的两篇文章:
如何打造车载语音交互:Google Voice Interaction 给你答案:介绍的是 3rd Party App 如何通过 Voice Interaction API 快速调用系统的语音交互服务快速完成确认、选择的基础语音对话直面…
![[语音识别] 基于Python构建简易的音频录制与语音识别应用](https://img-blog.csdnimg.cn/7282dce02ace4c1bbffedde6c6a817e3.png)
[语音识别] 基于Python构建简易的音频录制与语音识别应用
语音识别技术的快速发展为实现更多智能化应用提供了无限可能。本文旨在介绍一个基于Python实现的简易音频录制与语音识别应用。文章简要介绍相关技术的应用,重点放在音频录制方面,而语音识别则关注于调用相关的语音识别库。本文将首先概述一些音频基础概…
测试SpeechSynthesisUtterance方法基本使用
一、SpeechSynthesisUtterance基本介绍
SpeechSynthesisUtterance是HTML5中新增的API,用于将指定文字合成为对应的语音.也包含一些配置项,指定如何去阅读(语言,音量,音调)等
二、SpeechSynthesisUtterance基本属性
SpeechSynthesisUtterance.lang 获取并设置话语的语言
Spe…
毕业设计-基于深度学习的单通道语音降噪技术
目录
前言
课题背景和意义
实现技术思路
一、基于子空间投影的时域语音降噪
二、基于噪声信息辅助的双阶段语音降噪 三、感知高相关时频损失函数研究
实现效果图样例
最后 前言 📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学…
基于VHDL语言的汽车测速系统设计_kaic
摘 要 汽车是现代交通工具。车速是一项至关重要的指标。既影响着汽车运输的生产率,又关乎着汽车行驶有没有超速违章,还影响着汽车行驶时人们的人身安全。而伴随着我国国民的安全防范意识的逐步增强,人们也开始越来越关心因为汽车的超速而带来的极其严重…
使用 PyAudio、语音识别、pyttsx3 和 SerpApi 构建简单的基于 CLI 的语音助手
德米特里祖布☀️ 一、介绍 正如您从标题中看到的,这是一个演示项目,显示了一个非常基本的语音助手脚本,可以根据 Google 搜索结果在终端中回答您的问题。 您可以在 GitHub 存储库中找到完整代码:dimitryzub/serpapi-demo-project…

科普丨语音芯片烧录流程概述
语音芯片的烧录是将特定的固件或软件加载到芯片中,以使其能够执行特定的语音处理功能。以下是一般的语音芯片烧录过程:
1. 准备固件或软件:开发人员需要编写或获取特定的固件或软件,这些固件或软件包含了语音处理算法和功能的代码…

ASRT从零搭建并测试
参考文章:从零开始搭建属于自己的语音识别API服务器(ASRT开源项目)_asrt_v0.6.1_志 谦的博客-CSDN博客w我是用VM搭建使用的,用的Ubuntu20.04 Server
1. Server默认没有很多工具,例如ifconfig【net-tools安装】…

公共4G广播音柱有哪些用处
公共广播音柱有哪些用处
公共广播音柱是一种用于广播音频信号的设备,一般安装在公共场所或街道上。它具有以下几个主要用处:
1. 喊话广播:公共广播音柱可以用于喊话广播,用来传达重要信息、紧急通知、警报等,如公共安…

【Python小项目之Tkinter应用】随机点名/抽奖工具大优化:新增查看历史记录窗口!语音播报功能!修复预览文件按钮等之前版本的bug!
文章目录 前言一、实现思路二、关键代码查看历史记录按钮语音播报按钮三、完整代码总结前言
老生常谈,先看效果:(订阅专栏可获取完整代码) 初始状态下,我们为除了【设置】外的按钮添加弹窗,提示用户在使用工具之前要先【设置】。在设置界面,我们主要修改了【预览文件】…
开源日报 0822 | 语音识别与推理
这些项目包括 JavaScript 算法示例、系统编程语言 Rust、高性能的自动语音识别推理项目 Whisper.cpp 以及键盘工作者的单词记忆与英语肌肉记忆锻炼软件 Qwerty Learner。
trekhleb/javascript-algorithms
Stars: 174.1k License: MIT
这个项目是一个包含许多流行算法和数据结…
手机也可以将声音转为字幕!支持中英日韩4种语言
快去看看你的华为手机有没有这个功能——AI字幕,可以将手机里的音频转换为文字(以字幕形式展现,可保存在手机备忘录) AI字幕有什么用途?
1. 在听觉不太好使的环境下,将音频信息转化到视觉(文本…
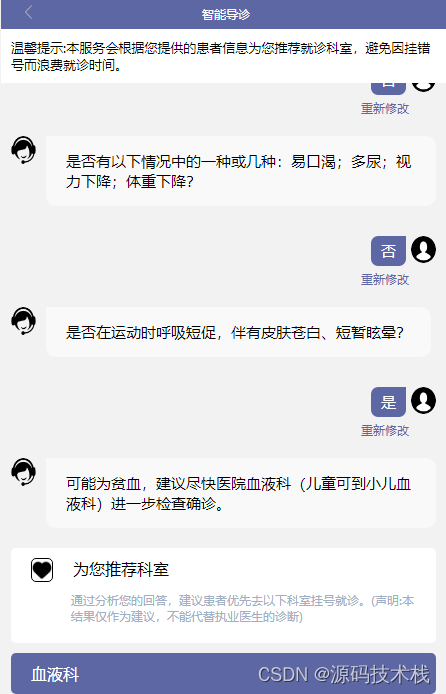
【Java】人工智能交互智慧导诊系统源码
随着人工智能技术的快速发展,语音识别与自然语言理解技术的成熟应用,基于人工智能的智慧导诊导医逐渐出现在患者的生活视角中,智能导诊系统应用到医院就医场景中,为患者提供导诊、信息查询等服务,符合智慧医院建设的需…

QSOP24封装的语音芯片优势列举
1. 封装紧凑:QSOP24封装采用了更小的封装尺寸,相比于其他大型封装,它的体积更小、尺寸更紧凑。这使得它在空间受限的应用中更加适用,可以方便地集成到小型或薄型设备中,提供更高的设计灵活性。
2. 强大的功能…

人机交互——对话管理
人机交互中的对话管理主要是指在人机交互过程中,对交互的对话内容和流程进行管理,以实现自然、流畅、高效的交互效果。对话管理包括对话状态追踪、对话策略优化等多个方面。
对话状态追踪是指对当前对话的状态进行跟踪,例如对用户输入的语…

【轮趣-科大讯飞】M260C 环形六麦测试 2 - ROS1功能测试与唤醒、语音识别程序解析
所有内容请看:
博客学习目录_Howe_xixi的博客-CSDN博客https://blog.csdn.net/weixin_44362628/article/details/126020573?spm1001.2014.3001.5502原文在飞书,请联系我获取阅读链接,我太懒了
FL Studio21最新中文汉化解锁版,2024怎么激活FL Studio
FL Studio2024最新中文汉化解锁版是一款功能强大的数字音频工作站(DAW),它广泛应用于音乐创作和音乐制作领域。在使用FL Studio时,购买正版软件是否有必要呢?本文将详细探讨FL Studio的功能特点以及正版软件的重要性。…

音频处理库libros安装使用教程笔记
音频处理库libros安装使用教程
1.音频处理库librosa
sr:采样率
hop_length:帧移
overlapping:连续帧之间的重叠部分
n_fft:窗口大小
spectrum:频谱
spectrogram:频谱图或叫做语谱图
amplitude&…
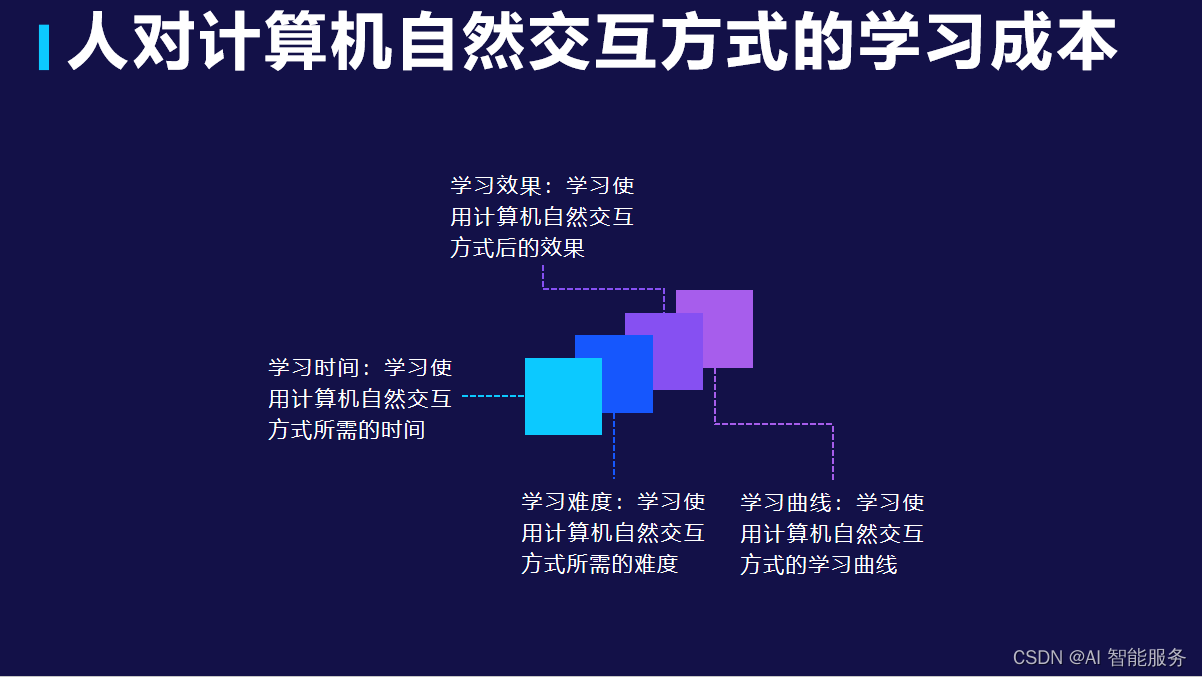
人机言语交互模型的评估要素
智能客服中的言语交互模型评估要素,主要包括以下几个方面:
有效性:指模型能否准确识别和理解用户的言语意图,以及生成正确和合适的回答。可以通过比较模型生成的回答与人工回答的准确率来评估。流畅性:指模型在回答问…
语音芯片基础知识 什么是语音芯 他有什么作用 发展趋势是什么
目录 一、语音芯片的简介
常见的语音芯片有哪些?
语音芯片的种类有很多,大体区分下来也就4个类别而已:
选型的经验说明如下:
推荐使用flash型语音芯片 一、语音芯片的简介
语音芯片基础知识: 什么是语音芯片&…
Netty对接阿里云语音识别和录音识别
阿里云实时语音识别:https://help.aliyun.com/document_detail/84430.html?spm=a2c4g.324262.0.0.564f73e9O6yq25
阿里云录音识别:https://help.aliyun.com/document_detail/90727.html?spm=a2c4g.90726.0.0.662d73e9qr8DqE 语音识别的流程为:前端和后端构建websocket连接…
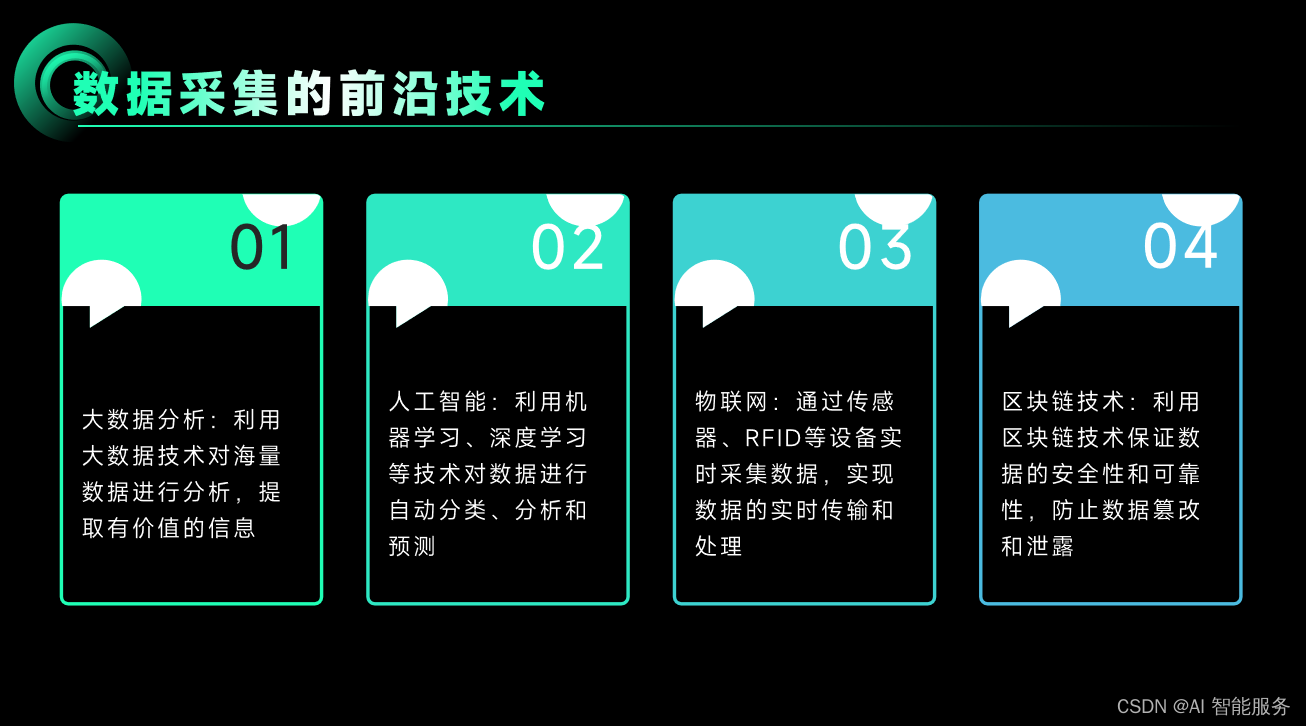
基础课12——数据采集
数据采集是指从传感器和其它待测设备等模拟和数字被测单元中自动采集非电量或者电量信号,送到上位机中进行分析处理。数据采集系统是结合基于计算机或者其他专用测试平台的测量软硬件产品来实现灵活的、用户自定义的测量系统。采集一般是采样方式,即隔一定时间(称采样周期)对同…
关于FTP的一些往事
公司每天都要从美国的服务器下载大量的语音文件。然后根据语音的内容完成相关的医疗报告。不同语音的实时性要求是不一样的,有些要求6小时内完成(TAT6) ,有些则是12小时。中美之间的网速又特别慢,所以,如何…
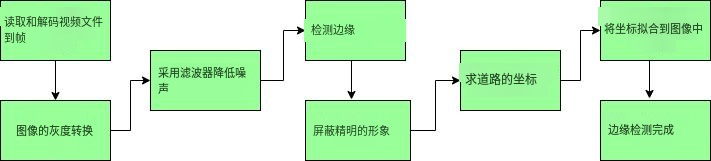
OpenCV—自动驾驶实时道路车道检测(完整代码)
自动驾驶汽车是人工智能领域最具颠覆性的创新之一。在深度学习算法的推动下,它们不断推动我们的社会向前发展,并在移动领域创造新的机遇。自动驾驶汽车可以去传统汽车可以去的任何地方,并且可以完成经验丰富的人类驾驶员所做的一切。但正确地训练它是非常重要的。自动驾驶汽…

AI智能语音识别模块(二)——基于Arduino的语音控制MP3播放器
文章目录 简介离线语音控制模块Mini MP3模块0.96寸 OLED模块实验准备安装库接线定义主要程序实验效果注意事项总结 简介
在前面一篇文章里我们对AI智能语音识别模块进行了介绍,并对离线语音模组下载固件的过程进行了一个简单描述,不知道大家还记不记得&…
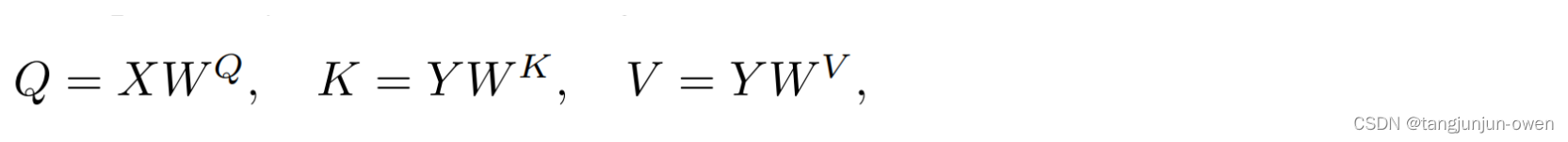
Attention Is All You Need原理与代码详细解读
文章目录 前言一、Transformer结构的原理1、Transform结构2、位置编码公式3、transformer公式4、FFN结构 二、Encode模块代码解读1、编码数据2、文本Embedding编码3、位置position编码4、Attention编码5、FFN编码 三、Decode模块代码解读1、编码数据2、文本Embedding与位置编码…

基础课14——文本标注
人工智能界流传一句俏皮话:“有多少人工,就有多少智能。”
1.人工智能数据标注介绍
2018年9月,百度智能云与山西综改示范区达成合作,在太原共同建立了百度(山西)人工智能基础数据产业基地(简称…
基于深度学习的语音识别算法的设计与实现
收藏和点赞,您的关注是我创作的动力 文章目录 概要 一、课题内容二、需求分析2.1 算法需求分析2.2 语音录制2.3 声学模型2.4 语言模型2.5 训练集和测试集2.6 深度神经网络 三 算法设计原理3.1 语音识别系统3.1.1 声学模型3.1.2 语言模型3.1.3 发音词典 四 简单问答…

科普丨音乐播放芯片的发声原理
音乐播放芯片是现代电子设备中常见的一种芯片,它在音频播放方面发挥着重要作用。音乐播放芯片能够将数字音频信号转化为模拟音频信号,并通过扬声器或耳机等音频设备发出声音。下面让我们来具体谈谈音乐播放芯片的发声原理。 1.接收音频源的数字音频信号 …
基础课20——智能客服系统的使用维护
1.智能客服系统的维护
智能客服系统在上线后,仍然需要定期的维护和更新。这是因为智能客服系统是一个复杂的软件系统,涉及到多个组件和功能,需要不断优化和改进以满足用户需求和保持市场竞争力。
保持系统的稳定性和性能:随着用…
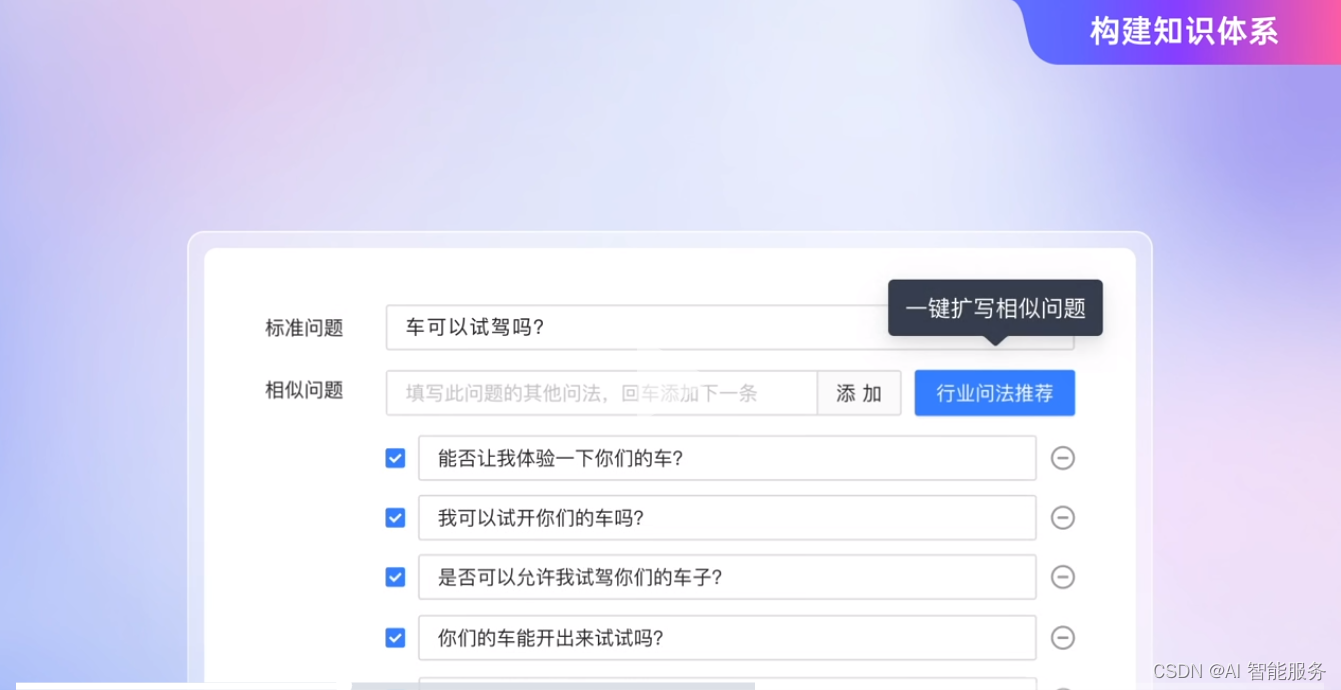
基础课21——知识库管理
1.知识库的概念、特点与功能
智能客服中的知识库是一个以知识为基础的系统,可以明确地表达与实际问题相对应的知识,并构成相对独立的程序行为主体,有利于有效、准确地解决实际问题。它储存着机器人对所有信息的认知概念和理解,这…
基础课24——开放域QA问答
早期的对话机器人通常采用基于规则的开放问答系统。这种系统依赖于专家系统的语义模板,即根据预先定义的模板来匹配和回答问题。这种方法的优点是准确性相对较高,因为它是基于人类专家的知识和经验来设计的。然而,这种系统的可扩展性和灵活性…

全能图片转文字:多功能图片处理软件
全能图片转文字是一款支持将图片文件实时转换为文字的处理软件。该软件可以帮助用户快速地获取图片文件中的文字内容,减少人工摘录的时间和成本,同时具备图片转excel、智能配音及PDF编辑等其他热门功能,轻松满足办公、学习中的各类需求。支持…

离线语音与IoT结合:智能家居发展新增长点
离线语音控制和物联网(IoT)相结合在家居中具有广泛的应用和许多优势。离线语音控制是指在设备在本地进行语音识别和处理,而不需要依赖云服务器进行处理。IoT是指借助网络,通过手机APP、小程序远程控制家居设备。
启英泰伦基于AI语…

Python语音识别处理详解
概要
人们对智能语音助手的需求不断提高,语音识别技术也随之迅速发展。在这篇文章中,我们将介绍如何使用Python的SpeechRecognition和pydub等库来实现语音识别和处理,从而打造属于自己的智能语音助手。 1. 什么是语音识别?
语音…

语音芯片故障的原因简述
语音芯片在语音设备或者相关产品中应用时会出现故障情况,常见的故障情况更多的是无法发出声音或者声音不连贯,还有声音播报不完整或者混乱等情况。下面让我们来探究芯片本身内部的故障问题,以及外部的原因。
芯片内部自身的故障:…
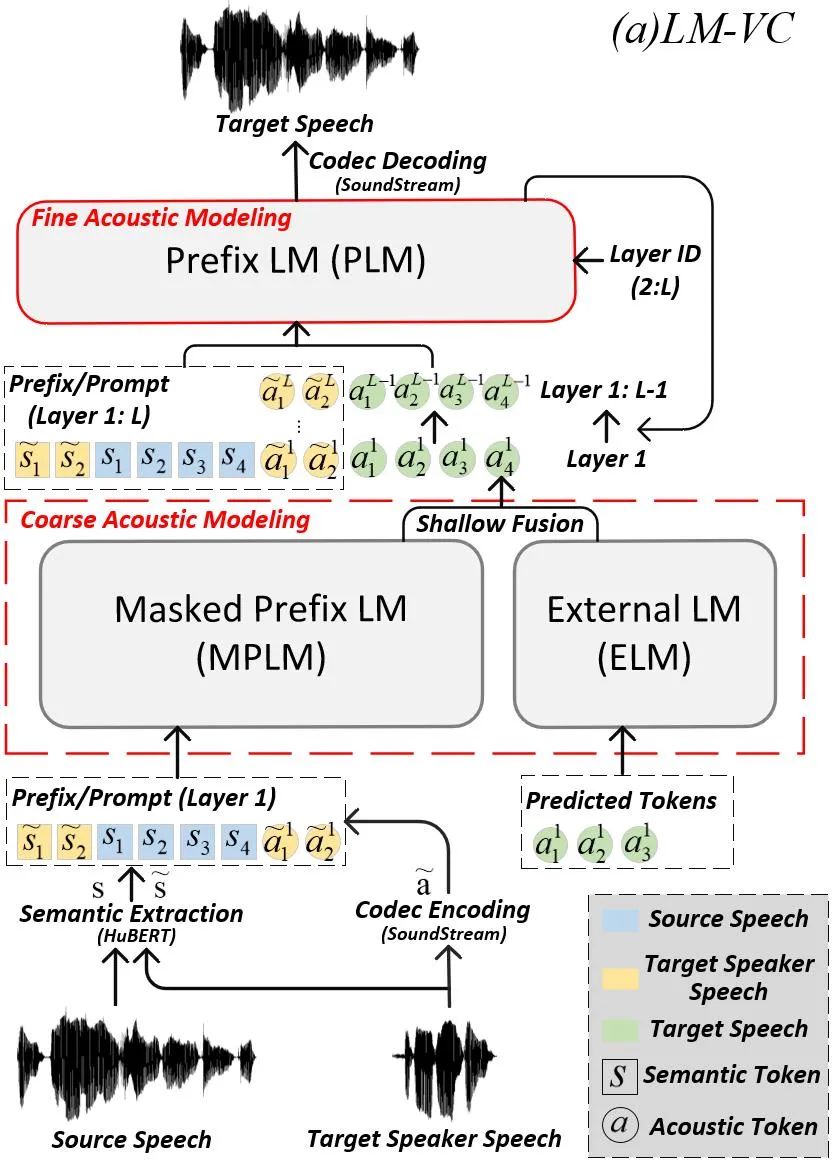
视频编软件会声会影2024中文版功能介绍
会声会影2024中文版是一款加拿大公司Corel发布的视频编软件。会声会影2024官方版支持视频合并、剪辑、屏幕录制、光盘制作、添加特效、字幕和配音等功能,用户可以快速上手。会声会影2024软件还包含了视频教学以及模板素材,让用户剪辑视频更加的轻松。 会…
物奇平台耳机在盒 在耳状态切换功能实现
是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,+群赠送语音信号处理降噪算法,蓝牙音频,DSP音频项目核心开发资料,
物奇平台耳机在盒 在耳状态切换功能实现 一 需求与场景
1 两只耳机在耳时,取下一只耳机
(1…
开放领域问答机器人2——开发流程和方案
开放领域问答机器人是指在任何领域都能够回答用户提问的智能机器人。与特定领域问答机器人不同,开放领域问答机器人需要具备更广泛的知识和更灵活的语义理解能力,以便能够回答各种不同类型的问题。
开发开放领域问答机器人的流程和方案可以包括以下步骤…
4K三路虚拟情景实训教学系统VR4300:实现“微课录制+课堂实训”双教学需求
如今,ChatGPT横空出世,产生了极大的破圈效应。各种AI、大模型概念风起云涌,给千行百业带来了极大的机遇与挑战。
4K三路虚拟情景实训教学系统VR4300基于计算机技术,虚拟现实技术,抠像合成技术,AI大模型等优…

语音识别数据的采集方法:基本流程数据类型
“人工智能是一种模仿人类功能的产品。数据采集的方法需要针对特定的场景需求。”—–Mark Brayan (澳鹏CEO) 我们一直说,对于一个高质量的人工智能产品离不开高质量的训练数据。对于不同的人工智能我们需要不同的数据对其训练。要采集正确的数据去训练特定的模型才…

中文连续视觉语音识别挑战赛
视觉语音识别,也称唇语识别,是一项通过口唇动作来推断发音内容的技术。该技术在公共安全、助老助残、视频验真等领域具有重要应用。当前,唇语识别的研究方兴未艾,虽然在独立词、短语等识别上取得了长足进展,但在大词表…

KT142C-sop16语音芯片ic的功能介绍 支持pwm和dac输出 usb直接更新内置空间
1.1 简介
KT142C是一个提供串口的SOP16语音芯片,完美的集成了MP3的硬解码。内置330KByte的空间,最大支持330秒的语音长度,支持多段语音,支持直驱0.5W的扬声器无需外置功放
软件支持串口通信协议,默认波特率9600.同时…
论文分享丨西工大音频语音与语言处理研究组四篇论文被IEEE Trans. ASLP和SPL录用
近日,实验室三篇论文被语音研究顶级期刊IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP)录用,一篇论文被重要期刊IEEE Signal Processing Letters (IEEE SPL)录用,论文方向涉及说话人识别中的对抗攻击、基于扩散模型…

提高广播新闻自动语音识别模型的准确性
语音识别技术的存在让机器能够听懂人类的语言,让机器理解人类的语言。语音识别技术发展至今,已经应运而上了各种各样的语音智能助手,可能有一天我们身边的物体都能和我们说话,万物相连的时代也如期而至。
数据从何而来࿱…
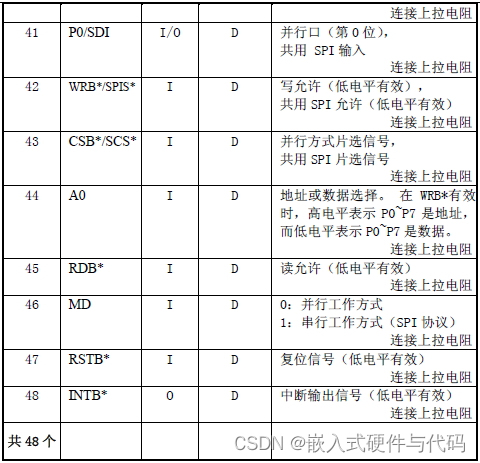
语音识别芯片LD3320介绍
语音识别芯片LD3320简介 LD3320 芯片是一款“语音识别”芯片,集成了语音识别处理器和一些外部电路,包括AD、DA 转换器、麦克风接口、声音输出接口等。LD3320不需要外接任何的辅助芯片如Flash、RAM 等,直接集成在LD3320中即可以实现语音识别/声控/人机对…
本地部署_语音识别工具_Whisper
1 简介
Whisper 是 OpenAI 的语音识别系统(几乎是最先进),它是免费的开源模型,可供本地部署。
2 docker
https://hub.docker.com/r/onerahmet/openai-whisper-asr-webservice
3 github
https://github.com/ahmetoner/whisper…

小程序实现语音识别功能
不废话,直接上代码
<template><view><u-popupround"16" :show"recordShow" :close-on-click-overlay"false":safe-area-inset-bottom"false"close"close"open"open"><view clas…
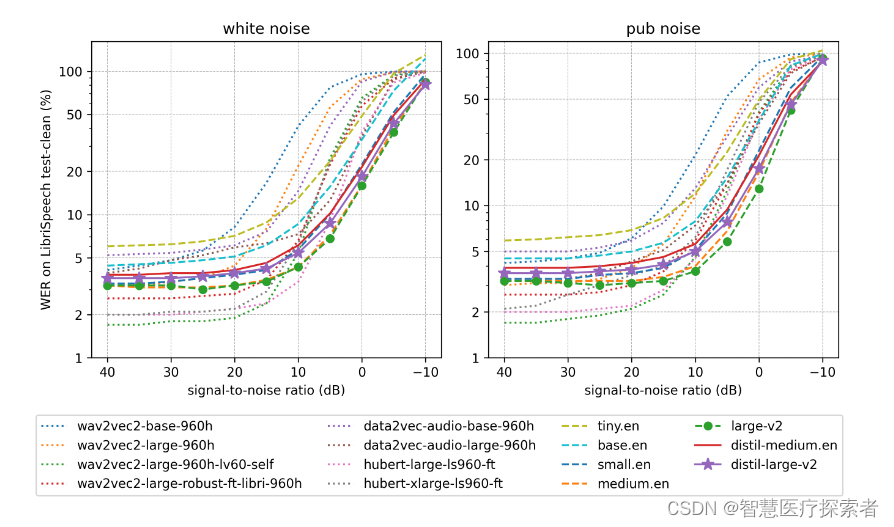
OpenAI的Whisper蒸馏:速度提升6倍的Distil-Whisper
1 Distil-Whisper诞生
Whisper 是 OpenAI 研发并开源的一个自动语音识别(ASR,Automatic Speech Recognition)模型,他们通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask&am…

NRK3301语音芯片在智能窗帘上的应用
窗帘是人们日常生活中所经常使用的家居产品,传统的窗帘大多都需要手动拉动窗帘使用;存在着拉拽费劲,挂钩容易掉落等问题。随着数字化转型的升级,推进了窗帘市场的高质量发展。智能窗帘也“适时出现”出现了,一款带有语…

OTA语音芯片NV040C在智能电动牙刷的应用
以往我们对牙齿的清洁是使用的是手动方式进行,用柔软的牙刷刷毛去进行牙齿的清洁。但现在我们拥有了一种新颖的刷牙方式,靠电力去驱动、清洁我们的牙齿。电动牙刷的刷头通过快速旋转,产生高频振动,将牙膏迅速分解为细小的泡沫&…
合肥中科深谷嵌入式项目实战——基于ARM语音识别的智能家居系统(一)
基于ARM语音识别的智能家居系统 我们接下来带大家完成基于语音识别的智能家居系统嵌入式项目实战,使用到stm32开发板,讯飞的离线语音识别,我们在此之前,我们先学习一些Linux系统的基本操作。 。 一、Linux简介
在嵌入式开发中&am…
花儿朵朵-全自动视频混剪,批量剪辑批量剪视频,探店带货系统,精细化顺序混剪,故事影视解说,视频处理大全,精细化顺序混剪,多场景裂变,多视频混剪
一、全自动视频混剪
你是否曾经厌烦于冗长的视频剪辑过程?是否曾经为了一个短短的混剪视频而熬夜加班?现在,视频闪闪为你带来全新的解决方案——全自动视频混剪!我们的混剪功能强大、操作简单,只需轻点几下鼠标&#…

开放领域问答机器人1
开放领域问答机器人是一种智能机器人,它不受限制,可以回答任何问题。这种机器人主要通过自然语言处理技术来理解用户的问题,并从大量的数据中获取相关信息,以提供准确的答案。它的应用领域广泛,包括客户服务、教育、医…
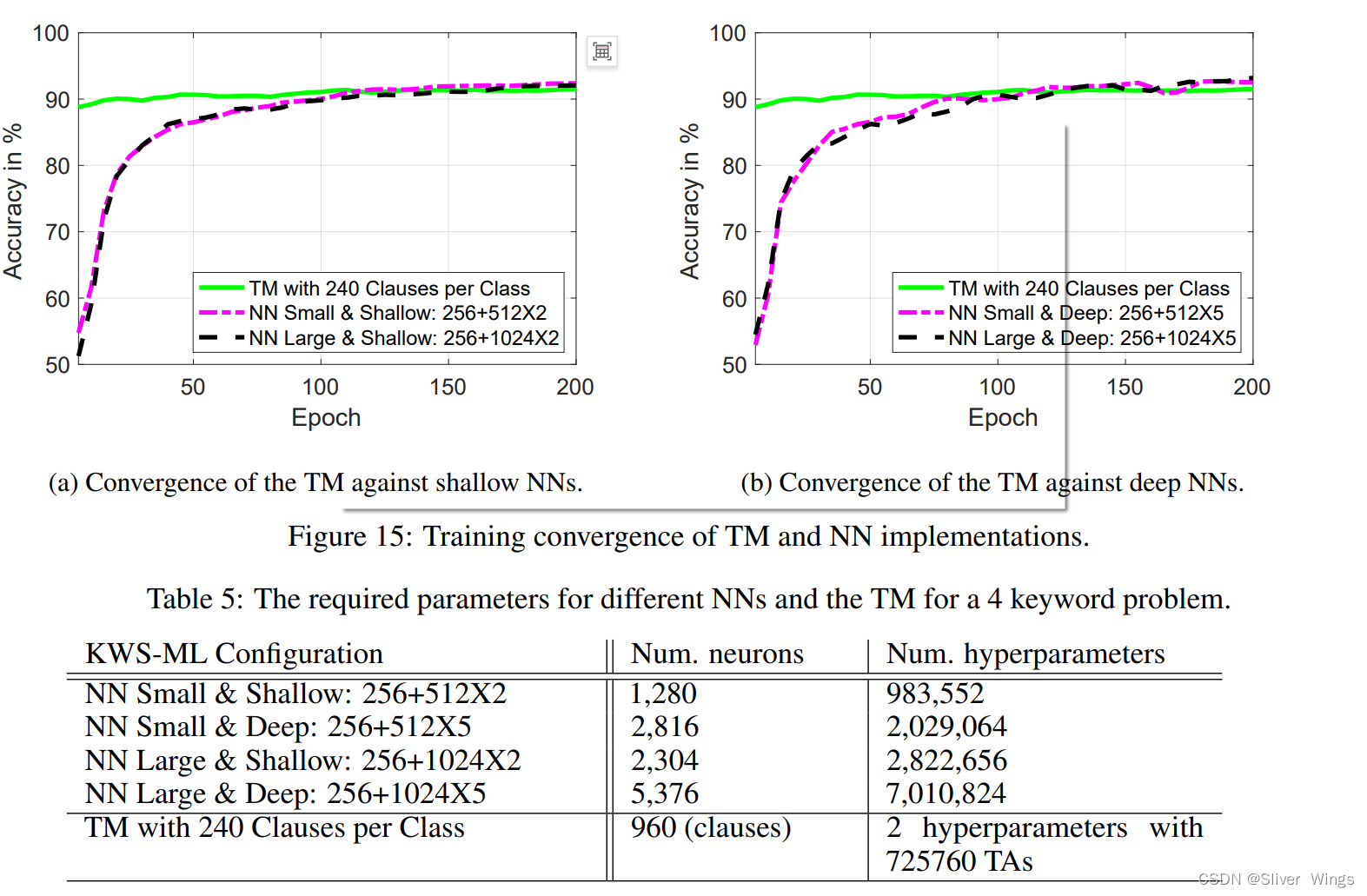
LOW-POWER AUDIO KEYWORD SPOTTING USING TSETLIN MACHINES
基于TM的低功耗语音关键字识别 摘要1介绍2TM的介绍3KWS的音频预处理技术4实验结果MFC4.1C设置分位数数量4.3增加关键词数量4.4 声音相似的关键词4.5 每个类别的子句数量对KWS-TM的比较学习收敛和复杂性分析 摘要
在本文中,我们探讨了一种基于TM的关键词识别&#x…

使用百度语音识别技术实现文字转语音的Java应用
探讨如何使用百度语音识别技术将文字转换为语音的Java应用。百度语音识别技术是一种强大的语音识别服务,可以将输入的文字转换为自然流畅的语音输出。我们将使用Java编程语言来实现这个应用,并提供相应的源代码。
首先,我们需要准备一些前提…
基于STM32+射频模块设计的导盲杖
基于STM32设计的列车座位导盲杖是一个集成了RFID读卡技术与SYN6288语音模块的智能辅助设备,专为视觉障碍者在列车上定位座位而设计。当导盲杖触碰到座位时,其上的M4255 RFID读卡器模块会读取座位上的卡号信息,信息包含了车厢与座位的具体位置。一旦读取成功,SYN6288语音模块…

单片机语音芯片在工业控制中的应用优势
单片机语音芯片,这一智能化的代表产品,不仅在家庭和消费电子领域发挥着重要的作用,更为工业控制领域注入了新的活力。将单片机语音芯片与语音交互技术相结合,为工业设备的控制和监测提供了前所未有的解决方案。
首先,…
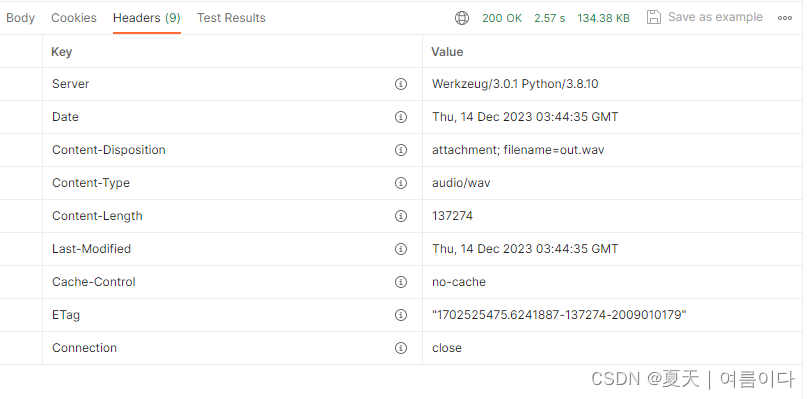
Python | Flask测试:发送post请求的接口测试
HTTP/1.1 协议规定的 HTTP 请求方法有OPTIONS、GET、HEAD、POST、PUT、DELETE、TRACE、CONNECT 几种。POST通常用来向服务端提交数据,主要用于提交表单、上传文件。
HTTP 协议是以ASCII码传输,建立在 TCP/IP 协议之上的应用层规范。规范把 HTTP 请求分为…
机器学习笔记 - 隐马尔可夫模型的简述
隐马尔可夫模型是一个并不复杂的数学模型,到目前为止,它一直被认为是解决大多数自然语言处理问题最为快速、有效的方法。它成功地解决了复杂的语音识别、机器翻译等问题。看完这些复杂的问题是如何通过简单的模型得到描述和解决,我们会由衷地感叹数学模型之妙。 人类信息交流…
python中文语音识别
1) 生成需要识别的wav文件,SpeechRecognition需要wav文件,不能识别mp3文件
安装库:
sudo apt install espeak ffmpeg libespeak1 pip install pyttsx3
代码:
def demo_tts_wav(): import pyttsx3 engine pytt…
KT404A语音芯片U盘更新语音方案说明_通讯协议 硬件设计参考
一、功能简介
KT404A语音芯片用U盘更换语音文件,适用于广告机、提示器等等场景
为了满足客户不方便使用PC电脑端更新,我们在KT404A芯片的基础上,开发了U盘更换声音文件的功能,保持和之前的标准本本【也就是KT404A芯片的基础版本…

AI辅助带货直播场景源码系统 附带网站的搭建教程
互联网技术的发展和普及,直播带货行业迅速崛起。然而,直播带货在带来商机的同时,也面临着诸多挑战。如直播内容缺乏新意、转化率低等问题。针对这些问题,AI辅助带货直播场景源码系统应运而生,旨在利用人工智能技术&…
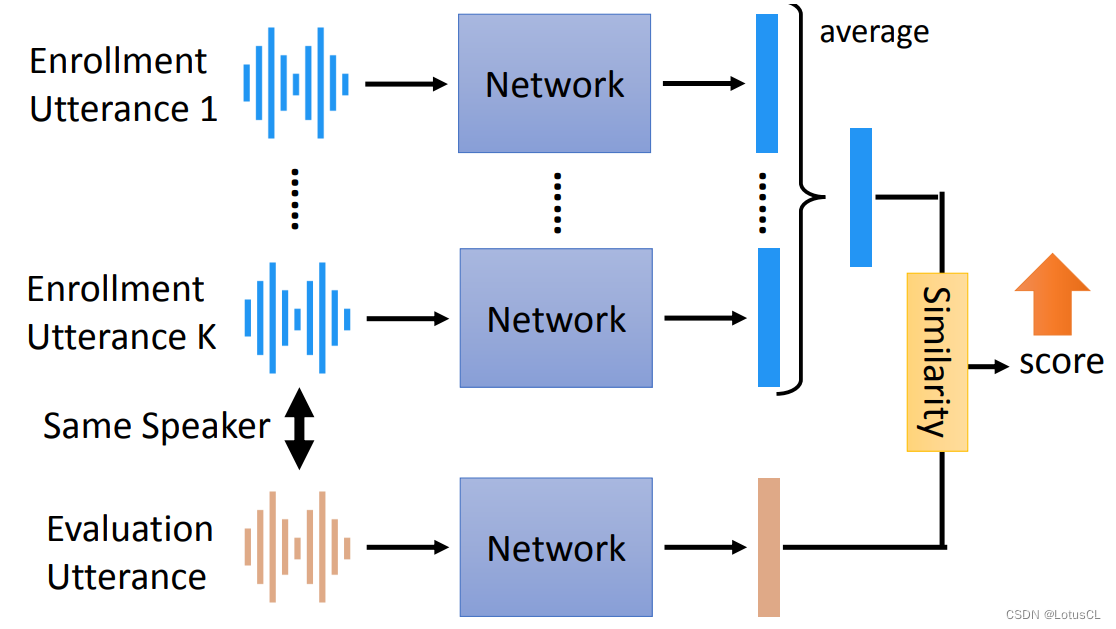
Speaker Verification,声纹验证详解——语音信号处理学习(九)
参考文献: Speaker Verification哔哩哔哩bilibili 2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 声纹识别 - 16 - 知乎 (zhihu.com) (2) Meta Learning – Metric-based (1/3) - YouTube 如何理解等错误率(EER, Equal Error Rate)?请不要只给定义 - 知…
AI创作系统ChatGPT网站源码,支持AI绘画,GPT语音对话+智能思维导图生成+智能AI思维导图生成
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…
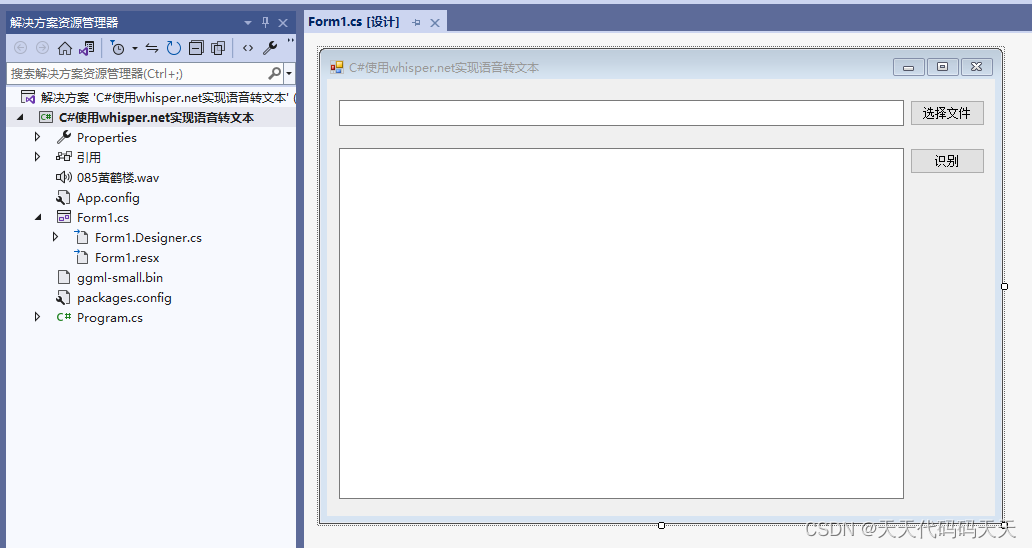
C#使用whisper.net实现语音识别(语音转文本)
目录
介绍
效果
输出信息
项目
代码
下载 介绍
github地址:https://github.com/sandrohanea/whisper.net
Whisper.net. Speech to text made simple using Whisper Models
模型下载地址:https://huggingface.co/sandrohanea/whisper.net/tree…

单片机语音芯片开发要解决的问题
在单片机语音芯片开发过程中,可能会遇到多种问题,这些问题可能来自于技术层面,也可能来自于芯片本身的设计和应用层面。下面让我们具体从芯片的功耗、语音识别的准度、芯片的尺寸和芯片的可靠性四个方面开展讨论。
1.芯片的功耗问题
首先&a…

情感对话机器人的任务体系
人类在处理对话中的情感时,需要先根据对话场景中的蛛丝马迹判断出对方的情感,继而根据对话的主题等信息思考自身用什么情感进行回复,最后结合推理出的情感形成恰当的回复。受人类处理情感对话的启发,情感对话机器人需要完成以下几…
OpenAI Whisper 语音识别 模型部署及接口封装【干货】
一、安装依赖
pip install -U openai-whisper二、安装ffmpeg
cd /opt
# 下载 5.1 版本的 ffmpeg
wget http://www.ffmpeg.org/releases/ffmpeg-5.1.tar.gz
# 解压下载的压缩包
tar -zxvf ffmpeg-5.1.tar.gz
# 进入解压后的文件夹
cd ffmpeg-5.1
# 安装ffplay需要的依赖
sudo …

【TinyALSA全解析(四)】扩展篇-从TinyALSA到底层音频驱动的全流程分析
扩展篇-从TinyALSA到底层音频驱动的全流程分析 第一节 本文说明第二节 声卡驱动统一入口进行ops替换过程2.1 tinyalsa到Linux kernel2.2 Linux Kernel中,由主设备号ops分流到次设备号ops 第三节 次设备中file_operations的open函数3.1 本节主要内容3.2 为何次设备的…
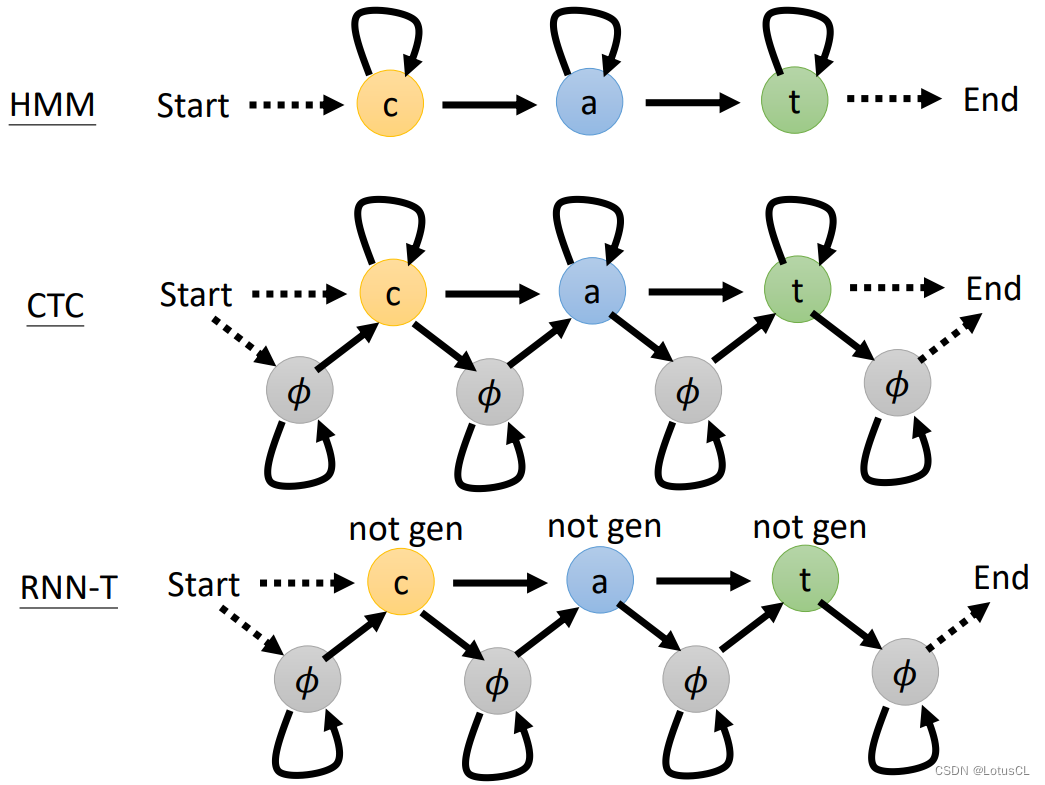
Alignment of HMM, CTC and RNN-T,对齐方式详解——语音信号处理学习(三)(选修二)
参考文献: Speech Recognition (option) - Alignment of HMM, CTC and RNN-T哔哩哔哩bilibili 2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 Alignment - 7 - 知乎 (zhihu.com) 本次省略所有引用论文 目录
一、E2E 模型和 CTC、RNN-T 的区别
E2E 模型的思路
C…
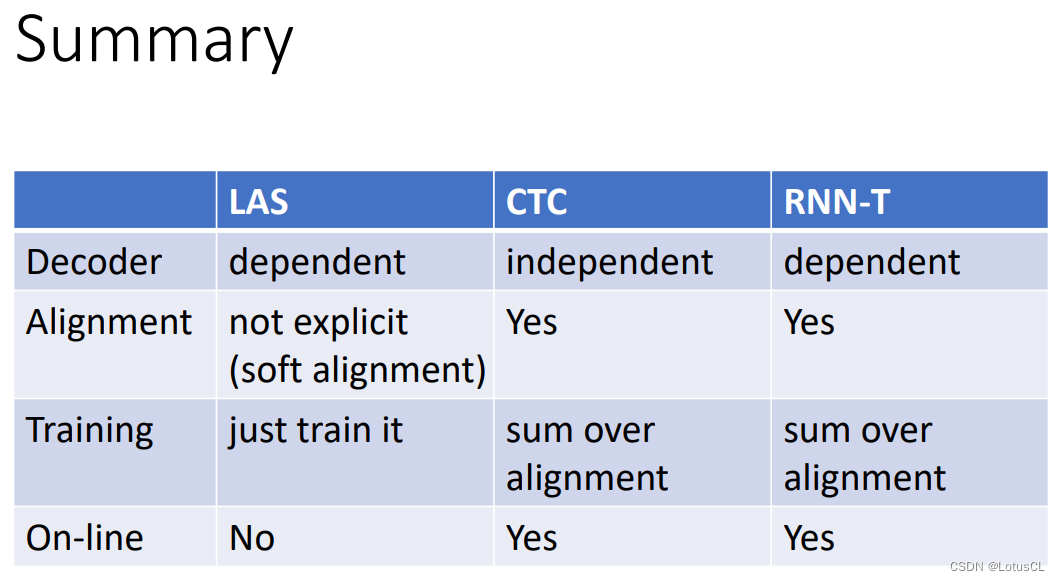
RNN-T Training,RNN-T模型训练详解——语音信号处理学习(三)(选修三)
参考文献: Speech Recognition (option) - RNN-T Training哔哩哔哩bilibili 2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 Alignment Train - 8 - 知乎 (zhihu.com) 本次省略所有引用论文 目录
一、如何将 Alignment 概率加和
对齐方式概率如何计算
概率加和计…

Vue语音播报,不用安装任何包和插件,直接调用。
Vue语音播报功能可以通过使用浏览器提供的Web Speech API来实现。这个API允许你的应用程序通过浏览器朗读文本,不用安装任何包和插件,直接调用。以下是一个简单的介绍,演示如何在Vue中使用语音提示功能: 一、JS版本
<template…
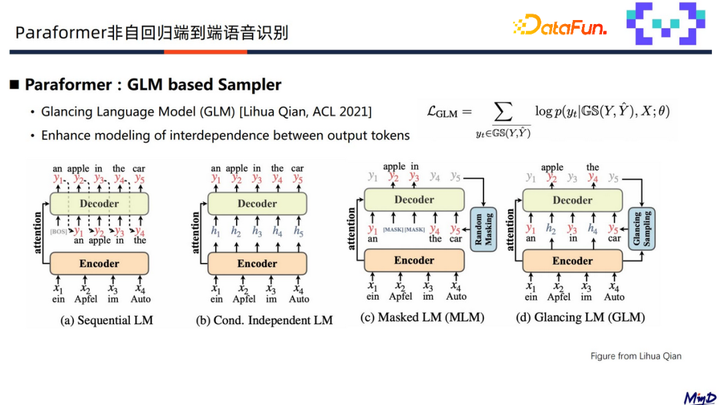
Paraformer 语音识别原理
Paraformer(Parallel Transformer)非自回归端到端语音系统需要解决两个问题:
准确预测输出序列长度,送入预测语音信号判断包含多少文字。 如何从encoder 的输出中提取隐层表征,作为decoder的输入。 采用一个预测器(Predictor&…
markdown的常用语法格式
Markdown的语法格式是怎么样的
首先强调文本是用两个星号给包裹住 加粗文本使用两个*号包裹
无序列表使用方式
首先,无序列表可以用-或者*来开头其次,无序列表开头之后需要加上一个空格
有序列表的使用方式
有序列表直接用数字加点号 2.点号后面不用…

国际语音通知系统有哪些优点?国际语音通知系统有哪些应用场景?
国际语音通知是一种全球性的通信工具,它通过语音方式向用户发送各种重要信息和提示。无论是快递到货的取件提醒、机场航班的延误通知,还是银行账户的余额提醒,国际语音通知都能准确、迅速地将信息传达给用户。
三、国际语音通知系统有哪些优…

人机交互——言语信息表示模型
如何将大量的言语碎片进行统一表示和存储,以便能够提取不同类型言语信息中的重要特征和语义信息,并计算和推理用户的交互意图,是一个极具挑战性的问题。 1.言语信息表示模型概述 2.言语信息表示模型结构 3.言语信息表示模型应用
AI创作系统ChatGPT网站源码,支持Midjourney绘画,GPT语音对话+智能AI思维导图生成
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…
wav2vec 2.0 语音特征提取器的使用方法
1 wav2vec 2.0 可以用来做什么?
很多人看完了wav2vec 2.0 不知道该怎么用,也不知道有什么用。下面将介绍怎么使用它和它到底有什么用。 用处:我们知道声音其实是个序列,那么该如何提取声音的序列特征呢?简单来说wav2v…

语音识别(1)- 音频数据的读取与绘制
语音识别(1)- 音频数据的读取与绘制 代码如下: # -*- coding:utf-8 -*-
音频数据的读取与绘制 import numpy as np
import matplotlib.pyplot as plt# 读取语音文件
from scipy.io import wavfile# 从 wavfile 包中读取文件
sampling_freq, audio wavfile.read(input_freq.w…

语音识别(2)-自定义参数生成音频信号
语音识别之自定义参数生成音频信号 代码如下: #-*- coding:utf-8 -*-
生成音频信号import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import write# 定义存储音频的输出文件
output_file output_generated.wav# 指定音频的生成参数
# 指定生成一个…
语音识别(3)-合成有趣的音乐
语音识别(3)-合成音乐 #-*- coding:utf-8 -*-
import json
import numpy as np
from scipy.io.wavfile import write
import matplotlib.pyplot as plt# 定义函数基于输入参数合成音调
def synthesier(freq,duration,amp1.0,sampling_freq44100):# 创建时间轴t np.linspace(0,…

制作一个成功的虚拟主持人需要具备哪些要素?
随着多媒体技术的广泛应用,这种数字展厅的建设形式,逐渐成为了展示产品和服务的重要途径,而在多媒体技术的展示形式中,虚拟主持人成为高人气互动展项之一,它在其中扮演着引导观众、传递信息的角色,并发挥着…

uni-app学习笔记(3):组件
文章目录1、console2、定时器3、网络请求4、页面跳转5、数据缓存6、图片7、视频1、console
HBuilderX中有2个重要的代码块,敲clog:可直接输出console.log();敲clogv:可输出console.log(": " );,并且出现双…

影响语音芯片识别率的因素概述
语音芯片识别率是指芯片对人类语音信号的识别能力。在实际应用中,语音芯片识别率的高低直接影响了用户对芯片的体验和满意度。因此,提高语音芯片识别率是当前语音技术领域的重要任务之一。
1.、语音芯片的硬件设计:设计良好的芯片可以更好地…

中文读唇总动员:CNVSRC 2023 视觉语音识别挑战赛启动
由 NCMMSC 2023 组委会发起,清华大学、北京邮电大学、海天瑞声、语音之家共同主办的 CNVSRC 2023 中文连续视觉语音识别挑战赛即日启动,诚邀参与报名。
赛事官网:http://cnceleb.org/competition
视觉语音识别,也称唇语识别&…
AI系统ChatGPT网站系统源码AI绘画详细搭建部署教程,支持GPT语音对话+DALL-E3文生图+GPT-4多模态模型识图理解
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…
基础课16——客服中心内部使用的智能客服系统
客服中心内部使用的智能客服系统主要包括以下几类:
智能客服机器人(呼入、呼出):可以自动回答用户的问题,并能根据用户需求进行多轮对话。它采用了先进的自然语言处理技术,能理解并回答用户的问题,并根据需要自主分析…
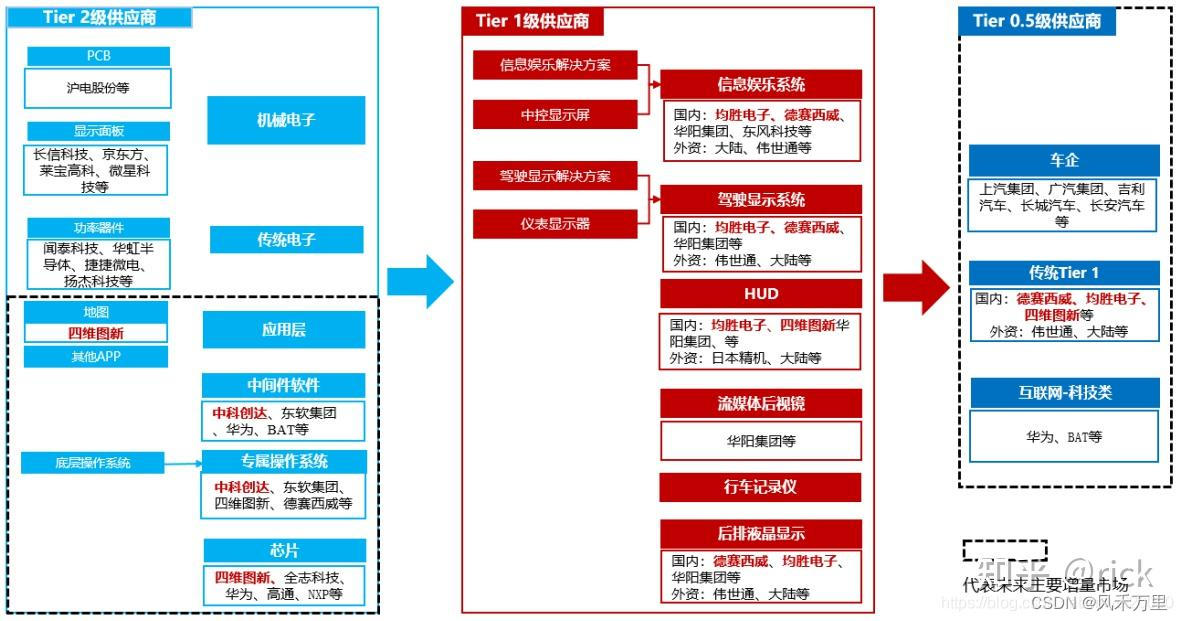
智能座舱架构与芯片 - (2) 架构篇
一、定义
1.1 智能座舱定义
按照百度百科的定义,智能座舱(intelligent cabin)旨在集成多种IT和人工智能技术,打造全新的车内一体化数字平台,为驾驶员提供智能体验,促进行车安全。目前国内外已经有很多研究…

AI电销机器人好不好用关键是什么?
影响AI电销机器人是否好用的两个因素分别是,识别系统以及线路。 有很多电销企业都想找一个好用的AI电销机器人,可是什么样的机器人才是好用的机器人呢?有哪些因素会影响AI电销机器人好不好用呢? 添加图片注释,不超过 140 字(可选…
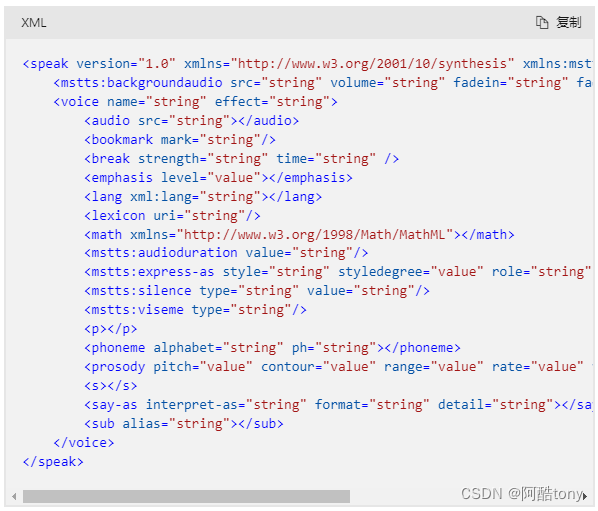
文本转语音:微软语音合成标记语言 (SSML) 文本结构和事件
SSML 的语音服务实现基于万维网联合会的语音合成标记语言版本 1.0。 语音服务支持的元素可能与 W3C 标准不同。
每个 SSML 文档是使用 SSML 元素(或标记)创建的。 这些元素用于调整语音、风格、音节、韵律、音量等。
下面是 SSML 文档的基本结构…
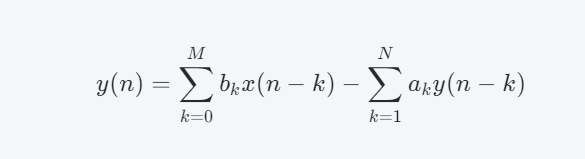
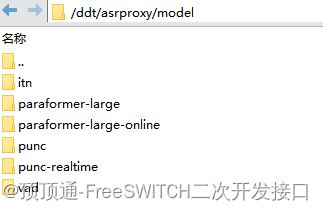
顶顶通ASR安装配置说明
联系顶顶通申请Asrproxy授权,勾选asrproxy和asrserver模块。下载语音识别模型
百度网盘链接: https://pan.baidu.com/s/1ugh-fVwhdt30A0ueMjdvHg?pwd65e4 提取码: 65e4移动网盘链接: https://caiyun.139.com/m/i?125CmlZ1I6TVr 提取码:m92H 安装asrpr…
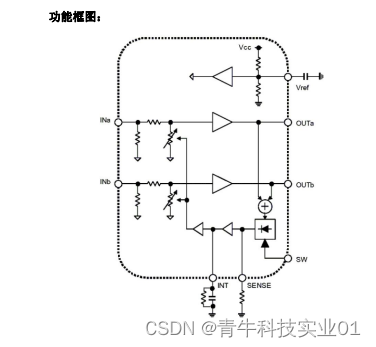
工作电压范围宽的国产音频限幅器D2761用于蓝牙音箱,输出噪声最大仅-90dBV
近年来随着相关技术的不断提升,音箱也逐渐从传统的音箱向智能音箱、无线音箱升级。同时在消费升级的背景下,智能音箱成为人们提升生活品质的方式之一。智能音箱是智能化和语音交互技术的产物,具有点歌、购物、控制智能家居设备等功能…
前端语音识别(webkitSpeechRecognition)
前端语音识别(webkitSpeechRecognition)-CSDN博客 Excerpt 文章浏览阅读1.8k次,点赞4次,收藏4次。浏览器实现语音转文字_webkitspeechrecognition webkitSpeechRecognition(语音识别)
<span class="token comment">// 创建一个webkitSpeechRecognition实…
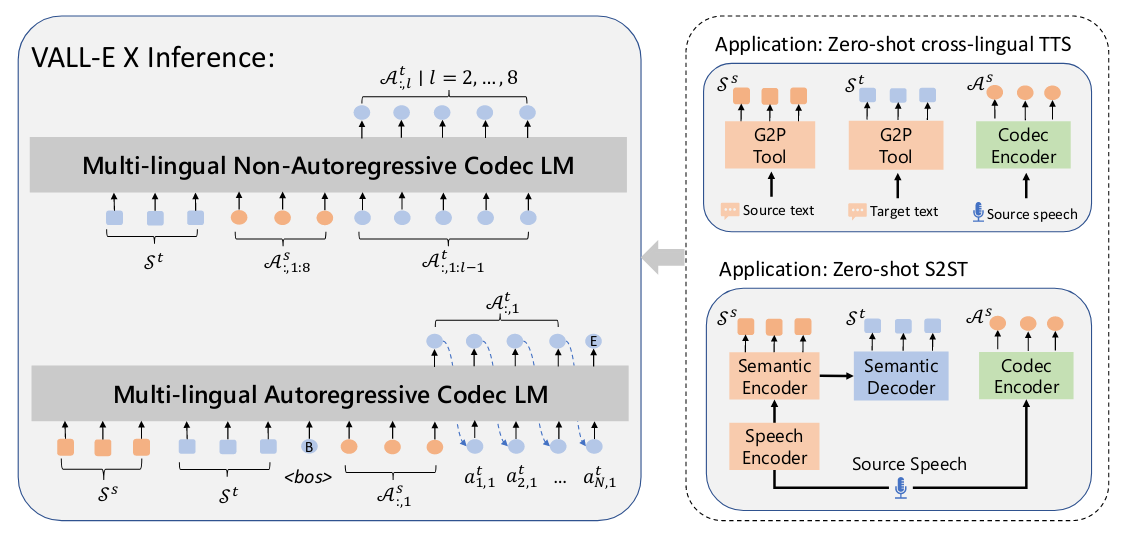
论文阅读_语音合成_VALLE-X
论文信息
name_en: Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling name_ch: 用你自己的声音说外语:跨语言神经编解码器语言建模 paper_addr: http://arxiv.org/abs/2303.03926 date_read: 2023-04-25 date_publish:…

语音识别芯片NRK3301在智能茶吧机的应用
传统的饮水机传大多只能提供热水和冷水,而智能茶吧机则是一款集合了热饮水机、煮茶器、泡茶壶等多种功能于一体的多功能生活电器。它不仅具备了传统饮水机的所有功能,还可以根据不同的需求,提供多种水温的饮水方式;还具备了煮茶和…
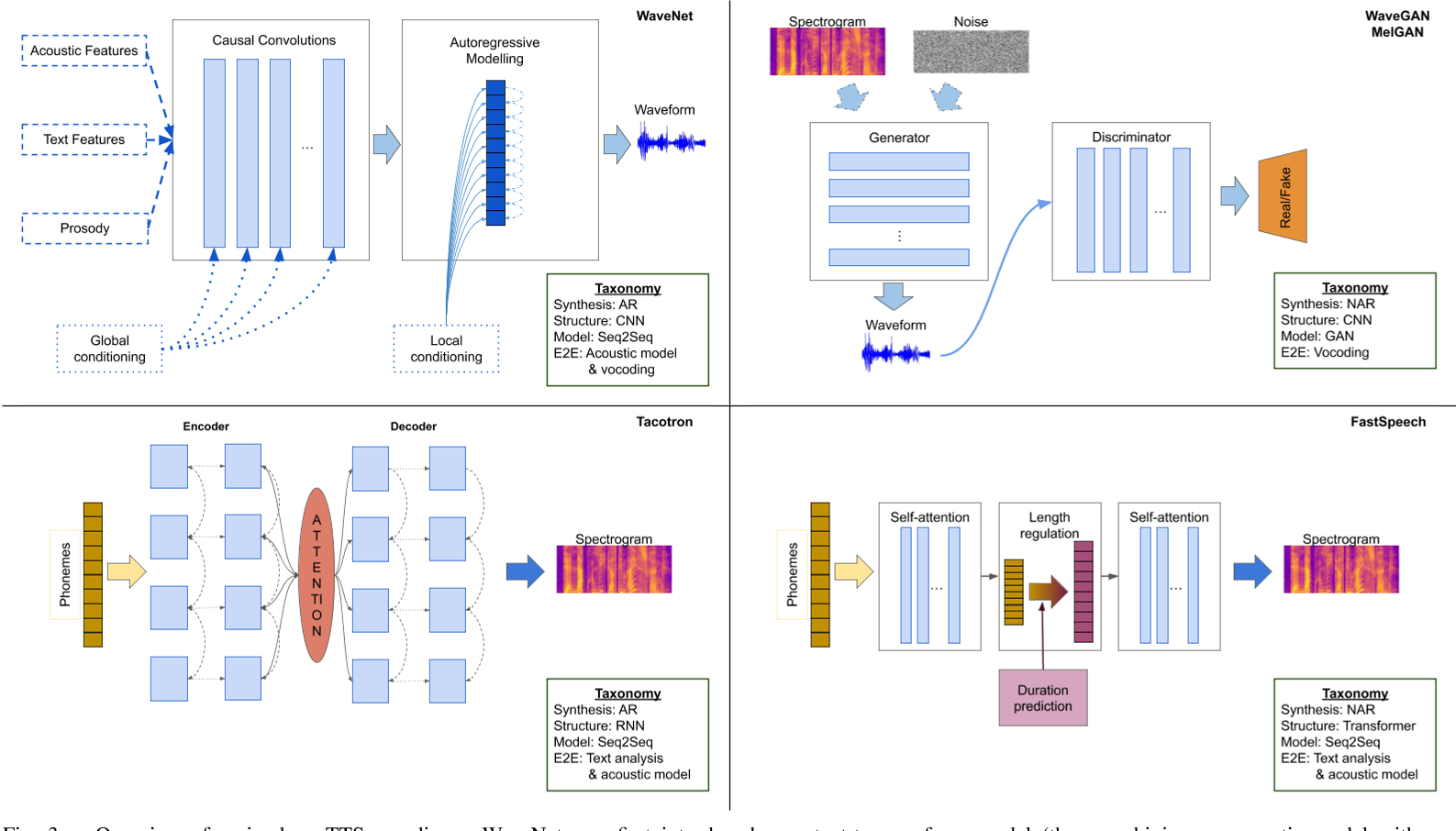
语音合成综述Speech Synthesis
一、语音合成概述
语音信号的产生分为两个阶段,信息编码和生理控制。首先在大脑中出现某种想要表达的想法,然后由大脑将其编码为具体的语言文字序列,及语音中可能存在的强调、重读等韵律信息。经过语言的组织,大脑通过控制发音器…
SpeechSynthesisUtterance 语音合成
const synth window.speechSynthesis;
const msg new SpeechSynthesisUtterance();
msg.text 这是一个测试用例;
msg.lang zh-CN;
msg.rate 3; //设置语速
// msg.pitch 1; //设置语调// 播放语音
synth.speak(msg);
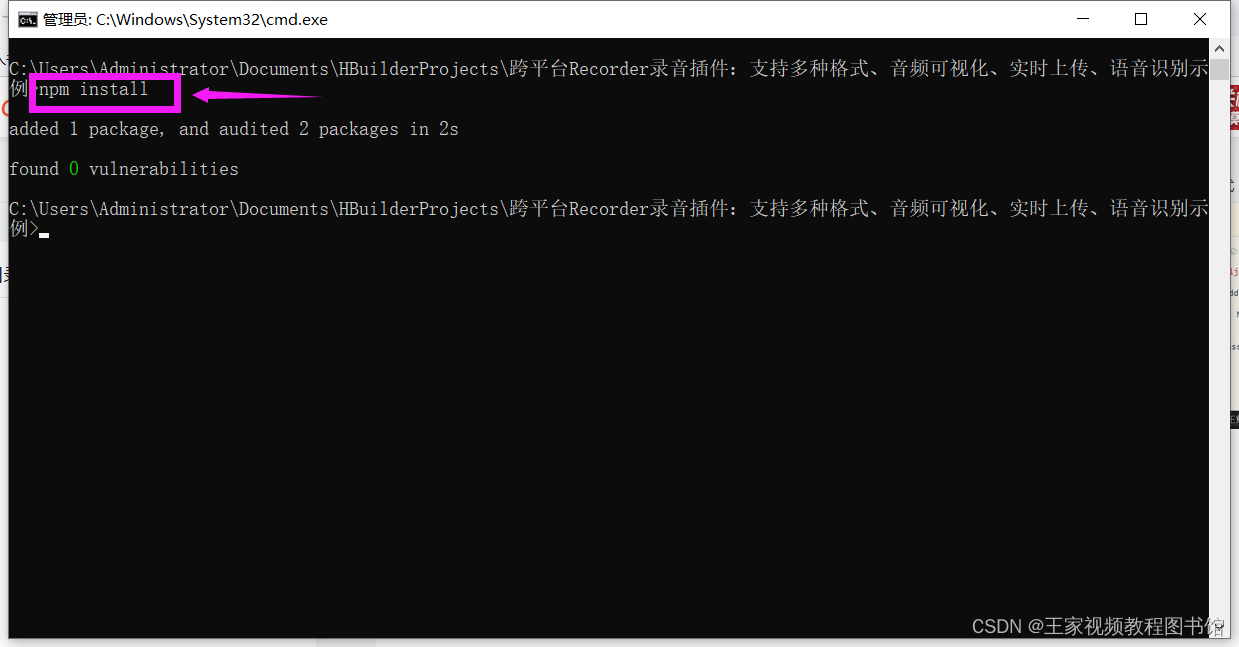
跨平台Recorder录音插件:支持多种格式、音频可视化、实时上传、语音识别
视频教程地址:【跨平台Recorder录音插件:支持多种格式、音频可视化、实时上传、语音识别】 https://www.bilibili.com/video/BV1jQ4y1c7e4/?share_sourcecopy_web&vd_sourcee66c0e33402a09ca7ae1f0ed3d5ecf7c /** 先引入Recorder ( 需先…
运放的常见应用(收藏)
运放对于外人来说可能有点陌生,但它在我们生活中无处不在,运放的最基本电路符号: 01 放大器 1、反相放大器电路图 输入输出波形: 2、同相放大器: 输入输出波形: 3、电压跟随器 输入输出波形: 4、…
顶顶通语音识别使用说明
介绍
顶顶通语音识别软件(asrproxy)是一个对接了多种语音识别接口的语音识别系统。可私有化部署(支持中文英文和方言等,支持一句话识别、实时流识别、多声道录音文件识别。
原理
asrproxy内嵌了阿里达摩院的开源语音识别工具包FunASR,后续我们也会使用自有的预料…
最新国内免费使用GPT4教程,GPT语音对话使用,Midjourney绘画
一、前言
ChatGPT3.5、GPT4.0、GPT语音对话、Midjourney绘画,相信对大家应该不感到陌生吧?简单来说,GPT-4技术比之前的GPT-3.5相对来说更加智能,会根据用户的要求生成多种内容甚至也可以和用户进行创作交流。 然而,GP…

单病种质量管理上报系统该如何选型
01案例分析
以某三级医院为例,全院2020年需上报的病例总数约为7140份,在国家直报系统用时2个月上报总数约为1200份,按此进度计算,所有病例上报完毕还需耗时约10个月。
经过多层筛选,该院最终选择并使用了米软单病种质…
大语言模型:开启自然语言处理新纪元
导言 大语言模型,如GPT-3(Generative Pre-trained Transformer 3),标志着自然语言处理领域取得的一项重大突破。本文将深入研究大语言模型的基本原理、应用领域以及对未来的影响。
1. 简介 大语言模型是基于深度学习和变压器&…
IEEE TASLP | 联合语音识别与口音识别的解耦交互多任务学习网络
尽管联合语音识别(ASR)和口音识别(AR)训练已被证明对处理多口音场景有效,但当前的多任务ASR-AR方法忽视了任务之间的粒度差异。细粒度单元(如音素、声韵母)可用于捕获与发音相关的口音特征&…
【Python百宝箱】Python律动:探索声纹识别与语音合成的Python奇迹
语音的魔法方程:Python引领语音领域的创新探索
前言
在数字化时代,语音处理技术的快速发展为人机交互、安全认证、虚拟现实等领域带来了无限可能。本文深入探讨了声纹识别和语音合成的整合,以及Python在声学领域中的关键角色。通过详细介绍…
【每日刷题——语音信号篇】
思考与练习
练习2.1
语音信号在产生的过程中,以及被感知的过程中,分别要经过人体的哪些器官?
1.产生过程: 肺部空气 → \rightarrow →冲击声带 → \rightarrow →通过声道(可以调节) → \rightarrow →…
OKCC语音机器人的人机耦合来啦
目前市场上语音机器人的外呼形式基本就分为三种,一种纯AI外呼,第二种也是目前主流的AI外呼转人工。那么第三种也可能是未来的一种趋势,人机耦合,或者也叫人机协同。 那么什么是人机耦合呢? 人机耦合是为真人坐席创造相…
[python]基于faster whisper实时语音识别语音转文本
语音识别转文本相信很多人都用过,不管是手机自带,还是腾讯视频都附带有此功能,今天简单说下:
faster whisper地址:
https://github.com/SYSTRAN/faster-whisperhttps://link.zhihu.com/?targethttps%3A//github.com…

汉字的音韵之美:中文拼音的魅力之旅
导语:中文拼音作为汉字的语音表达方式,已经深入人心。它不仅有助于汉字的学习与传播,还为汉语的国际化铺平了道路。本文将为您详细介绍中文拼音的起源、发展及其在我国教育、科技、文化等方面的广泛应用,带您领略这一古老而又现代…

Stability AI一种新型随心所欲生成不同音调、口音、语气的文本到语音(TTS)音频模型
该模型无需提前录制人声样本作为参考,仅凭文字描述就能生成所需的声音特征。用户只需描述他们想要的声音特点,例如“一个语速较快、带有英国口音的女声”,模型即可相应地生成符合要求的语音。它不仅能模仿已有的声音,还能根据用户…
AI智能电销机器人有哪方面的技术优势?
随着科学技术的发展,人工智能逐渐进入了公众的视野,与人工智能相关的智能产品,也从工业革命的诞生开始在生活中不断涌现,虽然说人类没有被机器所取代,但在之后的人工智能时代,人类真的会被取代吗࿱…

个性化语音生成:五种基于Python的方法
引言
随着人工智能技术的不断发展,语音生成已经成为一个热门的研究领域。个性化语音生成技术可以根据用户的需求和特点,生成具有高度相似度的语音,广泛应用于语音助手、虚拟人物、语音合成等领域。本文将介绍五种基于Python的个性化语音生成…
MATLAB中的语音质量评估: 详细指南与代码实现 - SDR、SAR、STOI、ESTOI、PESQ
第一部分:简介与SDR、SAR的实现
1. 简介
在数字音频处理中,评估语音质量是至关重要的。为了确保音频信号的质量,研究人员和工程师经常使用各种指标来测量语音的清晰度、噪声水平和其他相关的质量参数。在本文中,我们将使用MATLA…
uni-app/vue 文字转语音朗读(附小程序语音识别和朗读)uniapp小程序使用文字转语音播报类似支付宝收款播报小程序语音识别和朗读)
uni-app/vue 文字转语音朗读(小程序语音识别和朗读)
uniapp小程序功能集合
1、uniapp小程序文字转语音播报
一、第一种方式:直接加语音包
固定的文本 先利用工具生成了 文本语音mp3文件,放入项目中,直接用就好了
…

计算机毕业设计(校园旧物回收)之安卓app用户端
毕业设计之安卓app用户端,实现的主要功能如下
1.注册,短信验证主要运用了mob的第三方平台 mob官网,因为没有进行具体的登记,只能运用其提供的短信模板并且次数限制为一个手机号每天10次。 2,用户端首页,这…
Openai通用特定领域的智能语音小助手
无穷尽的Q&A
钉钉...钉钉... 双双同学刚到工位,报销答疑群的消息就万马纷沓而来。她只能咧嘴无奈的摇摇头。水都还没有喝一口就开始“人工智能”的去回复。原本很阳光心情开始蒙上一层薄薄阴影。在这无休无止的Q&A中,就算你对工作有磐石一般强硬࿰…

HMM隐马尔科夫模型
隐马尔科夫模型(HMM) 隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐藏的马尔可夫链随机生成的状态的序列,称为状态序列(…
TensorFlow学习记录-- 6.百度warp-ctc 参数以及测试例子2解释
1 百度CTC
https://github.com/baidu-research/warp-ctc/blob/master/README.zh_cn.md 优点:速度快很多。。。
2 CTC详解
总的来说就是想不对齐标签,来设计一个loss,通过最小化这个loss,可以得到精确的识别效果(即最后还能在不…
2 Connectionist Temporal Classification在语音识别中的运用(未完待续)
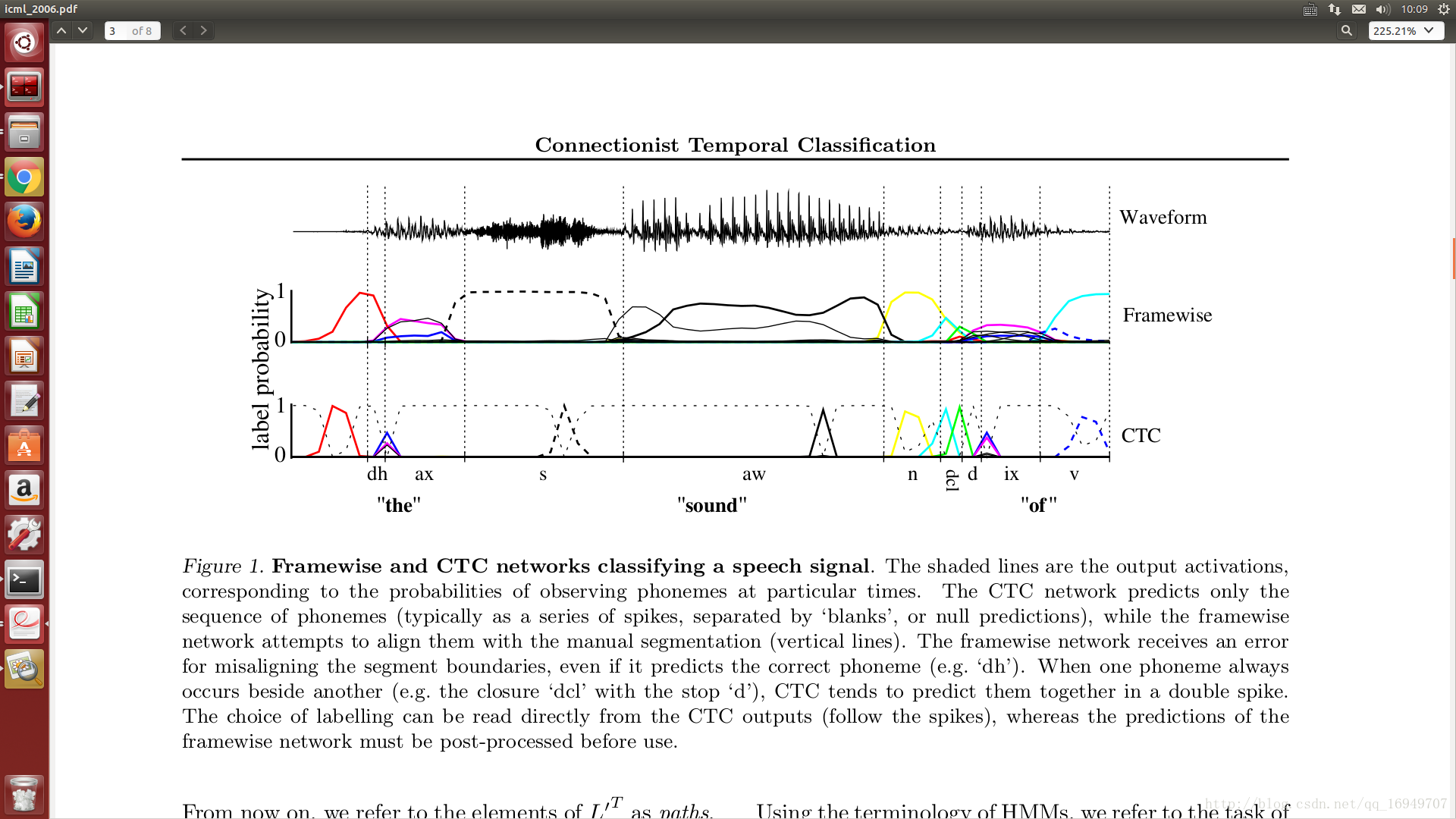
一 摘要
RNN运用到序列的学习中很有用,但是还是需要预处理数据,即例如处理语音数据,之前每一帧的输入需要对应一个label,本文直接利用RNN处理未预处理的数据,并在TIMIT语料库中进行实验,相对HMM和HMM-RNN取…
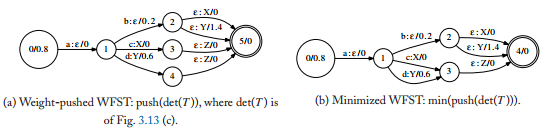
1.简谈语音识别中的WFTS
用WFST来表征ASR中的模型(HCLG),可以更方便的对这些模型进行融合和优化,于是可以作为一个简单而灵活的ASR的解码器(simple and flexible ASR decoder design)。 利用WFTS,我们可以吧ctc label&…

报名开启丨2023 SpeechHome 语音技术研讨会
2023 SpeechHome 语音技术研讨会将于11月18日—11月19日,在北京举办,同时举行开源语音技术交流会和第八届Kaldi技术交流会。
欢迎大家报名参加(报名链接在文末)!
本届研讨会覆盖5大主题,包括语音前沿技术…
【正在更新】从零开始认识语音识别:DNN-HMM混合系统语音识别(ASR)原理
摘要 | Abstract TO-BE-FILLED
1.前言 | Introduction 近期想深入了解语音识别(ASR)中隐马尔可夫模型(HMM)和深度神经网络-隐马尔可夫(DNN-HMM)混合模型,但是尽管网络上有许多关于DNN-HMM的介绍,如李宏毅教授的《深度学习人类语言处理》[1],…
最新ChatGPT网站系统源码+详细搭建部署教程+Midjourney绘画AI绘画
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…
安卓之视频智能字幕的应用场景以及各种技术优劣分析
一、文章摘要 随着技术的发展,智能字幕已经成为了安卓平台上一个重要的功能,特别是在视频播放方面。它为用户提供了一种更方便、更快捷的方式来理解视频内容,尤其是在多种语言环境下或者在没有声音的环境中。下面我们将详细探讨安卓平台上视频…
用python实现文字转语音的5个较好用的模块
文章目录 一. 用 gtts 模块二. 用pyttsx3模块基本使用直接朗读更改语音、速率和音量 三. baidu-aip四. pywin32五. speech 一. 用 gtts 模块
参考文档:https://gtts.readthedocs.io/en/latest/
使用前需要先安装:pip3 install gtts ,样例如…
【阿里云】图像识别 智能分类识别 增加垃圾桶开关盖功能点和OLED显示功能点(二)
一、增加垃圾桶开关盖功能
环境准备
二、PWM 频率的公式 三、pthread_detach分离线程,使其在退出时能够自动释放资源 四、具体代码实现
图像识别数据及调试信息wget-log打印日志文件
五、增加OLED显示功能 六、功能点实现语音交互视频
一、增加垃圾桶开关盖功能…

GEC6818 智能语音家居系统——原神主题的平板
GEC6818 智能语音家居系统——原神主题的平板 文章目录 GEC6818 智能语音家居系统——原神主题的平板一、 滑动解锁密码解锁二、 在桌面有两种方式可以进行选择2.1 普通点击模式2.1.1 电子相册2.1.2 监控2.1.3 画板2.1.4 视频播放2.1.5 五子棋小游戏2.1.6 烟雾传感器GY39RFID 2…

HMM(Hidden Markov Model)详解——语音信号处理学习(三)(选修一)
参考文献: Speech Recognition (Option) - HMM哔哩哔哩bilibili 2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 HMM - 6 - 知乎 (zhihu.com) 隐马尔可夫(HMM)的解码问题维特比算法 - 知乎 (zhihu.com) 本次省略所有引用论文 目录
一、介绍
二、建模单…
最新AI系统ChatGPT网站系统源码,支持AI绘画,GPT语音对话,ChatFile文档对话总结,DALL-E3文生图,MJ绘画局部编辑重绘
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧。已支持GPT…
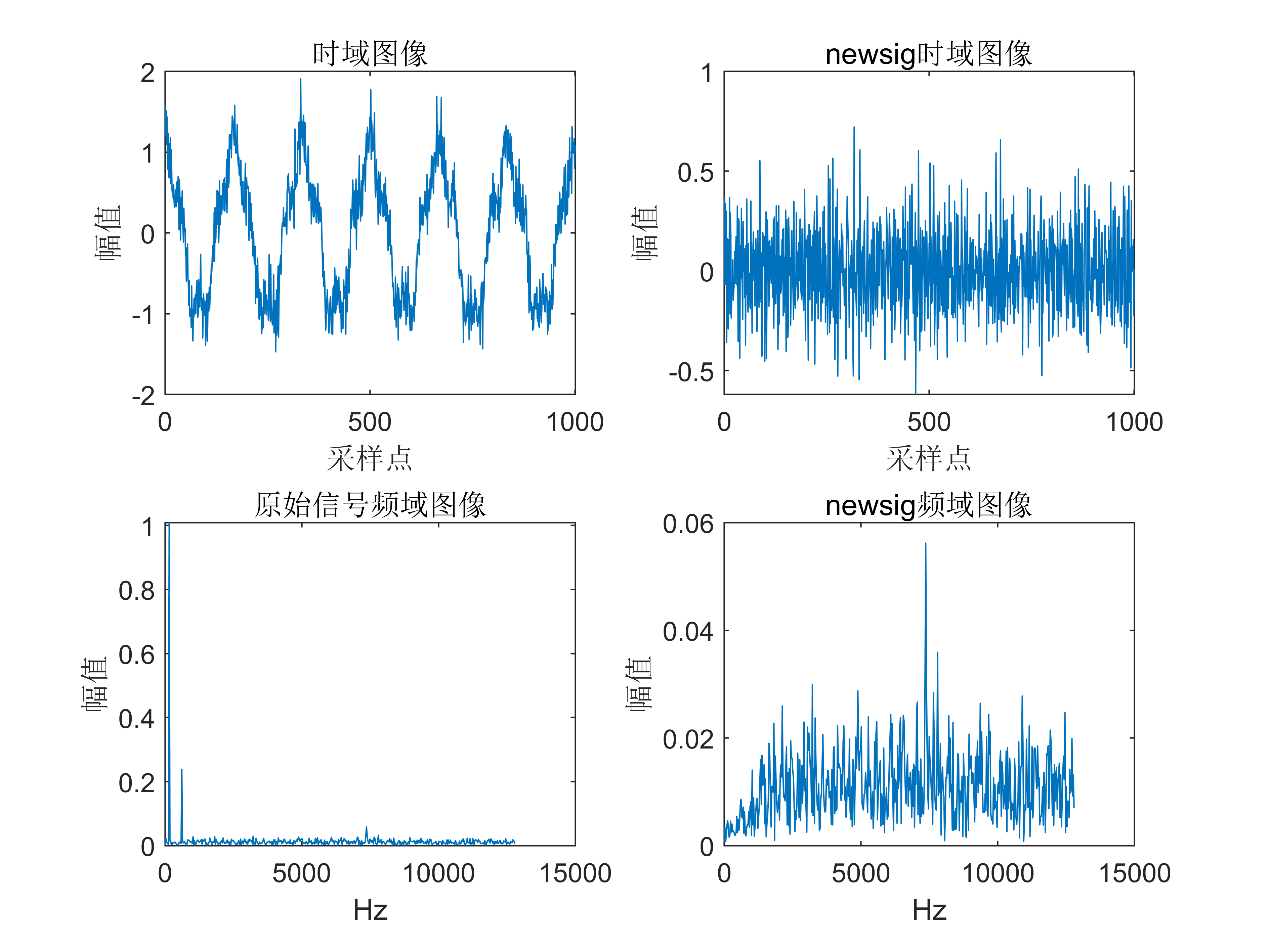
【MATLAB】mlptdenoise分解+FFT+HHT组合算法
有意向获取代码,请转文末观看代码获取方式~也可转原文链接获取~
1 基本定义
MLPT Denoise是一种基于小波变换的信号分解算法,可以将信号分解为多个具有不同频率特性的小波分量,并对每个小波分量进行频域分析。它基于最大似然参数调整&#…

在百模大战中AI行业发展有何新趋势?
目录 1. 多模态AI
2. 自适应学习
3. AI可解释性
4. 边缘计算
5. AI与人类协作 在百模大战中,AI行业的发展有以下几个新趋势:
1. 多模态AI 多模态AI是指能够同时处理不同输入模式(如文本、图像、语音等)的人工智能技术。…
Android集成科大讯飞语音识别与语音唤醒简易封装
目录 一、语音唤醒部分
1、首先在科大讯飞官网注册开发者账号
2、配置唤醒词然后下载sdk
3、选择对应功能下载
4、语音唤醒lib包全部复制到工程目录下
5、把语音唤醒词文件复制到工程的assets目录
6、复制对应权限到AndroidManifest.xml中
7、唤醒工具类封装
二、语音识…
民谣女神唱流行,基于AI人工智能so-vits库训练自己的音色模型(叶蓓/Python3.10)
流行天后孙燕姿的音色固然是极好的,但是目前全网都是她的声音复刻,听多了难免会有些审美疲劳,在网络上检索了一圈,还没有发现民谣歌手的音色模型,人就是这样,得不到的永远在骚动,本次我们自己构…
WeNet语音识别+Qwen-72B-Chat Bot+Sambert-Hifigan语音合成
WeNet语音识别Qwen-72B-Chat Bot👾Sambert-Hifigan语音合成 简介 利用 WeNet 进行语音识别,使用户能够通过语音输入与系统进行交互。接着,Qwen-72B-Chat Bot作为聊天机器人接收用户的语音输入或文本输入,提供响应并与用户进行对话…

基础课11——数据来源
随着科技的进步和数字化转型的加速,全球数据量正以惊人的速度增长。根据IDC的最新报告,2020年全球数据总量已经达到了约53 ZB(Zettabyte,万亿亿GB),而这个数字在2025年预计会达到175 ZB。这种指数级增长不仅…

PyTorch语音识别的理论基础——MFCC
在语音识别研究领域,音频特征的选择至关重要。本书大部分内容中都在使用一种非常成功的音频特征—梅尔频率倒谱系数(Mel-Frequency Cepstrum Coefficient,MFCC)。
MFCC特征的成功很大程度上得益于心理声学的研究成果,…

python实现语音识别
1. 首先安装依赖库
pip install playsound # 该库用于播放音频文件
pip install speech_recognition # 该库用于语音识别
pip install PocketSphinx # 语音识别模块中只有sphinx支持离线的,使用该模块需单独安装
pip install pyttsx3 # 该库用于将文本转换为语音播…

STM32F103C8T6制作简易示波器
1设计需求
通过stm32f103c8t6实现一个简易示波器功能,该示波器可以检测0-3.6khz频率范围内的波形。
也可以输出波形,输出方波、三角波、正弦波。 2技术方案
通过stm32的ADC功能,采集输入信号,最后由oled屏进行显示。
采样频率…
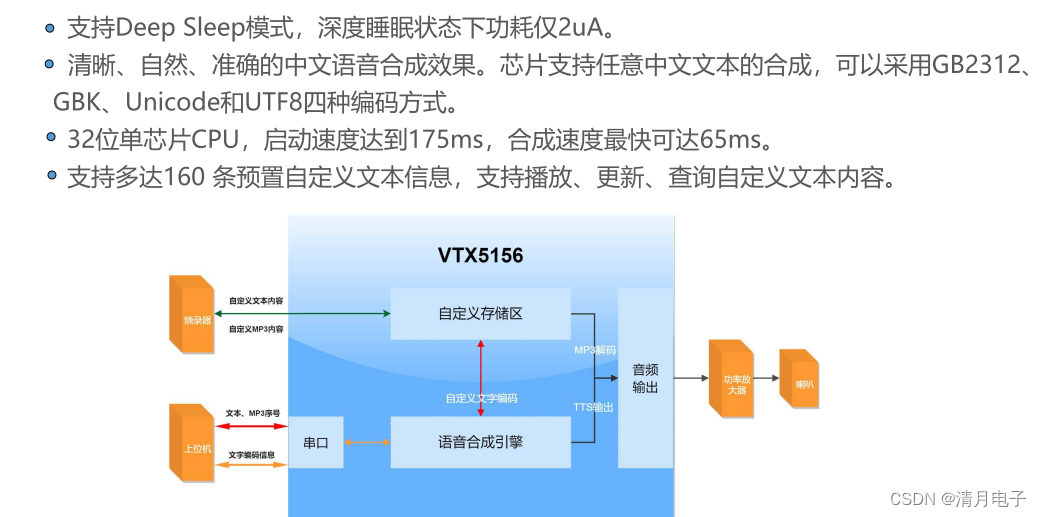
常用的语音芯片工作原理_分类为语音播报 语音识别 语音合成tts
1.0 语音芯片分类-语音播报-语音识别-语音合成 关于声音的需求,从始至终,都是很刚需的需求 。从语音芯片的演化就能看出很多的端倪,很多很多的产品他必须要有语音,才能实现更好的交互。而语音芯片的需求分类,其实也是很…

如何给音乐场景降噪?音乐场景降噪技术和方案解析
音乐场景应用在泛娱乐社交和互动中十分常见,比如语聊房、在线KTV以及直播等场景在人们的日常生活中占据越来越重要的地位,用户对于音质的要求也越来越高,因此超越传统语音降噪算法的AI降噪算法应运而生,目前各大RTC厂商普遍使用AI…

谷歌和微软的ASR的差异和特点
为满足海外客户的业务需求,目前天天讯通的AI机器人系统正在对接谷歌和微软的ASR,目前微软的开发进入尾声了。 这两家是国际上知名的ASR厂商了,当然还有亚马逊、IBM等,之所以选择这两家来对接测试,主要也是海外的客户给…
语音叠加和谐振的计算
语音叠加和谐振的计算
什么是语音处理? 1.语音信号的研究和这些信号的处理方法 2.数字信号的一个特例应用于语音信号的处理符号
什么是声音? 声能,机械,海浪, 空气穿过的振动(或其他介质),(空气)压力变化…
MFCCA多通道多说话人语音识别模型上线魔搭(ModelScope)
实验室研发的基于多帧跨通道注意力机制(MFCCA)的多说话人语音识别模型近日上线魔搭(ModelScope)社区,该模型在AliMeeting会议数据集上获得当前最优性能。欢迎大家下载。开发者可以基于此模型进一步利用ModelScope的微调…
ChatGPT 有哪些神奇的使用方式?
ChatGPT在语言处理领域有着非常广泛的应用,可以用来进行语音识别、文本摘要、问答系统、机器翻译、智能客服、情感分析、智能写作等方面的应用。随着技术的不断发展和进步,ChatGPT在未来的应用场景和领域也将会有更加广泛的拓展和应用。ChatGPT可以应用于…
【S2ST】Direct Speech-to-Speech Translation With Discrete Units
【S2ST】Direct Speech-to-Speech Translation With Discrete Units AbstractIntroductionRelated workModelSpeech-to-unit translation (S2UT) modelMultitask learningUnit-based vocoder ExperimentsDataSystem setupBaselineASRMTTTSS2TTransformer Translatotron Evaluat…

flstudio21破解汉化版2024最新水果编曲使用教程
如果你一直梦想制作自己的音乐(无论是作为一名制作人还是艺术家),你可能会想你出生在这个时代是你的幸运星。这个水果圈工作室和上一版之间的改进水平确实令人钦佩。这仅仅是FL Studio 21所提供的皮毛。你的音乐项目的选择真的会让你大吃一惊。你以前从未有过这…

基础课22——听见voc客户之声
1.什么是VOC
1993年,客户之声(Voice of the Customer,简称VoC)第一次出现,在麻省理工同名论文中,VoC被形容为对客户要求的详细理解,产品开发的共同语言和产品创新的跳板。 图片来源百度 但30年…
【小沐学Python】Python实现语音识别(Whisper)
文章目录 1、简介1.1 whisper简介1.2 whisper模型 2、安装2.1 whisper2.2 pytorch2.3 ffmpeg 3、测试3.1 命令测试3.2 代码测试:识别声音文件3.3 代码测试:实时录音识别 结语 1、简介
https://github.com/openai/whisper
1.1 whisper简介
Whisper 是…

【小沐学Python】Python实现语音识别(SpeechRecognition)
文章目录 1、简介2、安装和测试2.1 安装python2.2 安装SpeechRecognition2.3 安装pyaudio2.4 安装pocketsphinx(offline)2.5 安装Vosk (offline)2.6 安装Whisper(offline) 3 测试3.1 命令3.2 fastapi3.3 go…
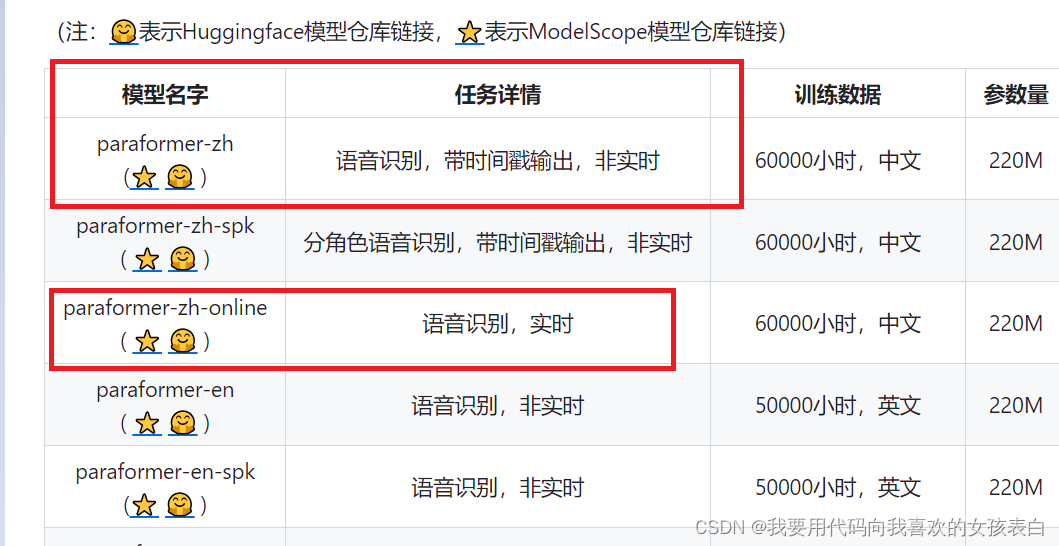
中文语音标注工具FunASR(语音识别)
全称 A Fundamental End-to-End Speech Recognition Toolkit(一个语音识别工具)
可能大家用过whisper(openAi),它【标注英语的确很完美】,【但中文会出现标注错误】或搞了个没说的词替换上去,所…

人机交互——自然语言理解
人机交互中的自然语言理解是人机交互的核心,它是指用自然语言(例如中文、英文等)进行交流,使计算机能理解和运用人类社会的自然语言,实现人机之间的自然语言通信。
自然语言理解在人工智能领域中有着非常重要的地位&a…
WebClient 实现openai 文本转语音报错: DecoderException
错误信息:
OpenAI返回数据异常t:{}io.netty.handler.codec.DecoderException: java.lang.NullPointerExceptionat io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:471) ~[netty-codec-4.1.53.Final.jar:4.1.53.Final]Suppres…
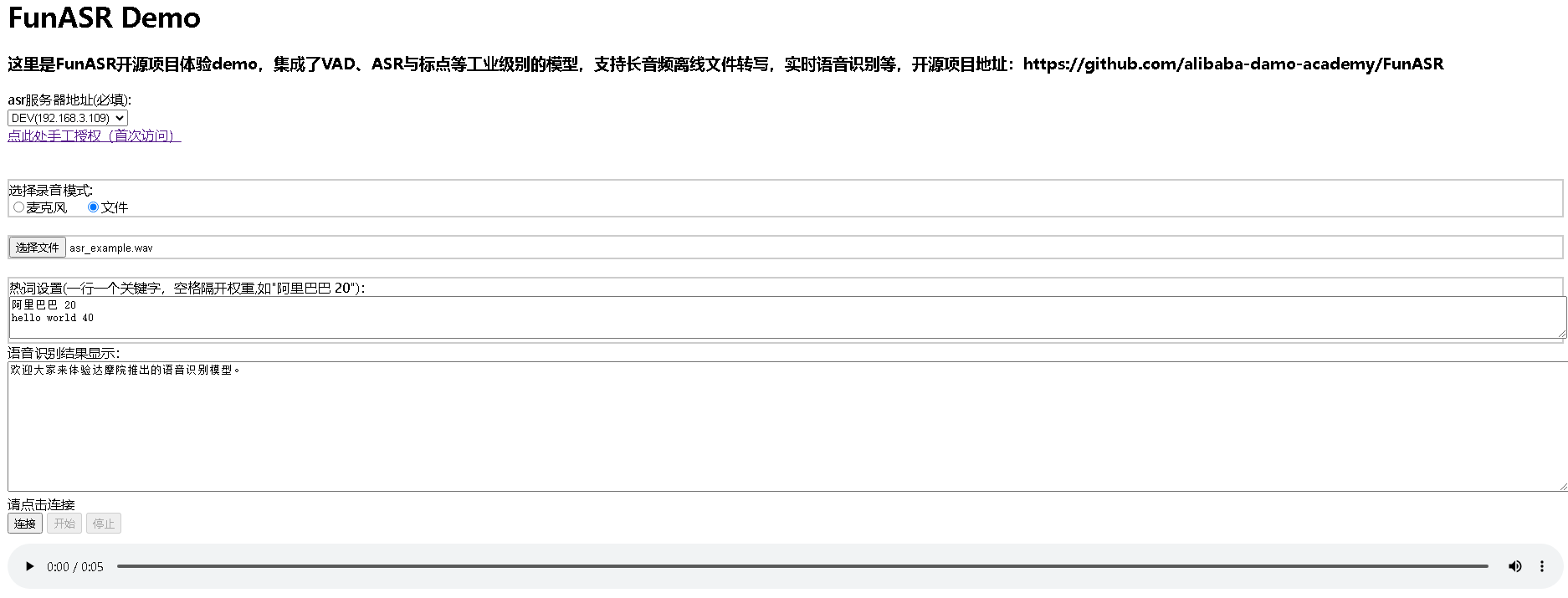
【FunASR】Paraformer语音识别-中文-通用-16k-离线-large-onnx
模型亮点
模型文件: damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorchParaformer-large长音频模型集成VAD、ASR、标点与时间戳功能,可直接对时长为数小时音频进行识别,并输出带标点文字与时间戳: ASR模型…

NV040D语音芯片应用于取暖桌:智能语音提高用户体验
科技与生活的结合,是科技发展的展示。天气的降温,取暖桌越来越取得用户的心,时至今日传统的取暖桌已经没有办法满足用户的需求,智能语音取暖桌给用户的生活带来了不一样的体验。 NV040D语音芯片是一款性能稳定的芯片,拥…
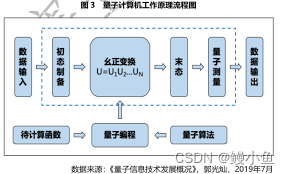
人工智能与量子计算:开启未知领域的智慧之旅
导言 人工智能与量子计算的结合是科技领域的一场创新盛宴,引领我们进入了探索未知领域的新时代。本文将深入研究人工智能与量子计算的交汇点,探讨其原理、应用以及对计算领域的深远影响。 量子计算的崛起为人工智能领域注入了新的活力,开启了…
【实用】解决.gitignore文件不生效
文章目录背景原因解决方法背景 针对:.gitignore文件不生效,哪怕是将某个目录、文件加入到忽略规则里 原因
.gitignore只能忽略那些原来没有被追踪的文件如果某些文件已经被纳入了版本管理中,那么修改.gitignore是无效的。
解决方法 先把本地…
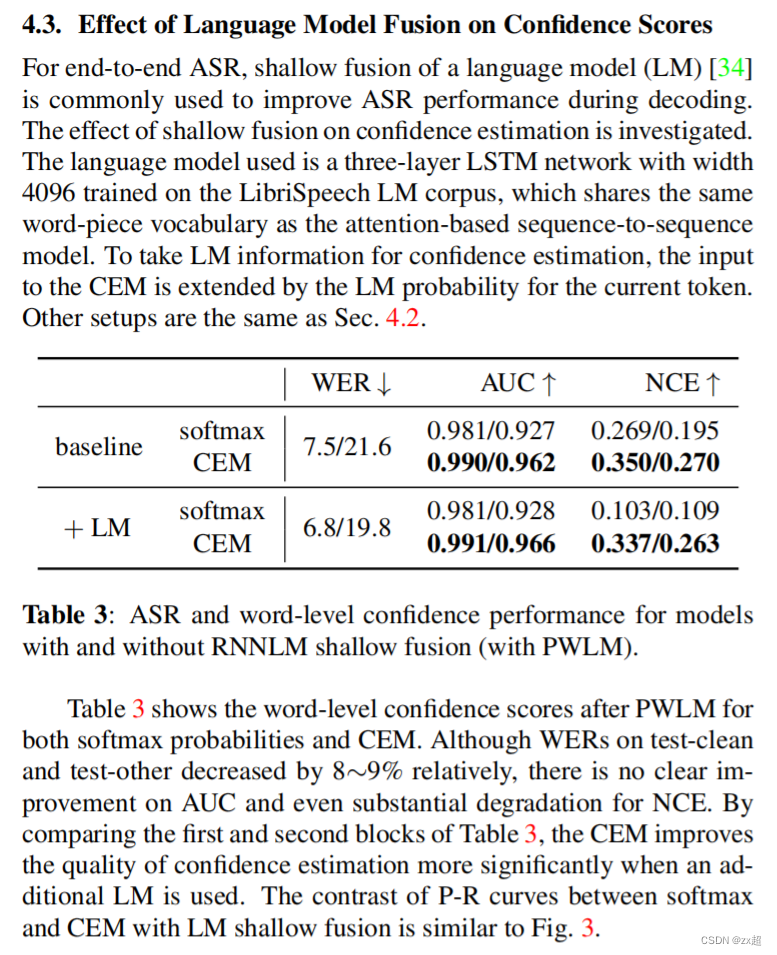
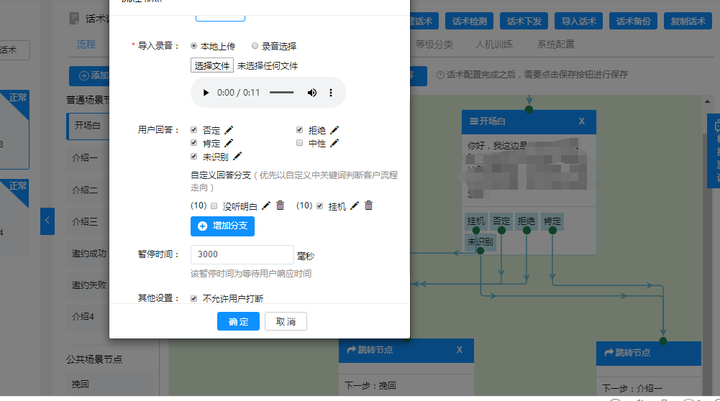
AI语音机器人的重点功能配置之话术
AI机器人运营中的重中之重就是对话术的配置,如何将话术运营好将是影响AI机器人效果的关键因素,那接下来我们了解一下AI机器人的话术模块的几个重点功能。 话术配置
有节点库、关键词、话术内容、转接人工、发送短信、知识库标签、客户意向、允许打断、…

人机交互——自然语言生成
自然语言生成是让计算机自动或半自动地生成自然语言的文本。这个领域涉及到自然语言处理、语言学、计算机科学等多个领域的知识。
1.简介
自然语言生成系统可以分为基于规则的方法和基于统计的方法两大类。基于规则的方法主要依靠专家知识库和语言学规则来生成文本࿰…

请问电脑视频制作需要自己的配音,有什么好用的配音软件推荐呢?
短视频、活动促销都能看到配音的身影,真人配音效果好,但是价格也普遍不低。越来越的用户看向了音质真实、价格实惠的软件配音。给大家分享两款常用的配音工具,看看你喜欢的有没有上榜。
1、录音啦
录音啦是一款桌面端文字转语音工具&#x…

IP网络电话呼叫转移设置
这里的网络电话呼叫转移设置,我们以IP电话系统用方位的网络电话机为例说明
通话转移
当用户正在与对方通话时,并希望将呼叫转移到其他号码,这里有两种方法来转移呼叫,出席移转和非出席移转。
出席移转
出席移转也被称为“礼貌…

Voice Control for ChatGPT 沉浸式的与ChatGPT进行交流学习。
Voice Control for ChatGPT
日常生活中,我们与亲人朋友沟通交流一般都是喜欢语音的形式来完成的,毕竟相对于文字来说语音就不会显的那么的苍白无力,同时最大的好处就是能解放我们的双手吧,能更快实现两者间的对话,沟通…

智能防盗防偷门锁语音方案设计
智能锁主要功能
防撬报警功能(非必须,但很实用):防撬报警功能可以说是指纹密码锁功能中对提升家居安全有效的功能之一。当指纹锁受到外暴力破坏时,就会自动发出警报声,提醒小区安保。好一点的甚至可以自动…

通信原理课设(gec6818) 007:语音识别
目录
1、去科大讯飞官网下载对应的sdk
2、科大讯飞文件夹的意思
3、配置ARM的录音环境
4、编程实现语音识别 我们的需求是将一个语音文件从客户端传到服务器,因此我们最好是选用tcp 现在市面上面常用的语音识别解决方案为:科大讯飞c和百度c
离…

简述低功耗语音芯片的含义与特点
低功耗语音芯片是一种功耗较低的集成电路,其集成了语音处理、控制逻辑等多个功能。相比传统的语音芯片,低功耗语音芯片能够在功耗较低的情况下完成更多的功能,因此非常适合移动设备和可穿戴设备等对功耗要求较高的场景。 低功耗语音芯片的主要…
BES2700H开发不完全手册
BES2700H开发不完全手册
是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,群赠送语音信号处理降噪算法,ANC AEC ENC EQ BF BES蓝牙耳机音频资料 1 成功编译 2 代码 3 开放文档

最优秀的完整的数字音频工作站水果音乐FL Studio21.1.1.3750中文解锁版
FL Studio21.1.1.3750中文解锁版简称 FL 21,全称 Fruity Loops Studio 21,因此国人习惯叫它"水果"。目前最新版本是FL Studio21.1.1.3750中文解锁版版本,它让你的计算机就像是全功能的录音室,大混音盘,非常先…

Distil-Whisper:比Whisper快6倍,体积小50%的语音识别模型
内容来源:xiaohuggg Distil-Whisper:比Whisper快6倍,体积小50%的语音识别模型
该模型是由Hugging Face团队开发,它在Whisper核心功能的基础上进行了优化和简化,体积缩小了50%。速度提高了6倍。并且在分布外评估集上…

python编写的语音识别+机器人对话+文字播报一体
1.语音识别 这里用到了百度api的语音识别,目前开源的语音识别成文字的效果都很差,百度api的语音识别效果还可以。 2.机器人对话,这里用到了青云客机器人对话,通过爬虫获取对话的内容,机器人对话效果一般,没…
【Matlab语音去噪】语音加噪和降噪处理(带面板)【含GUI源码 473期】
一、代码运行视频(哔哩哔哩)
【Matlab语音去噪】语音加噪和降噪处理(带面板)【含GUI源码 473期】
二、matlab版本及参考文献
1 matlab版本 2014a
2 参考文献 [1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)…
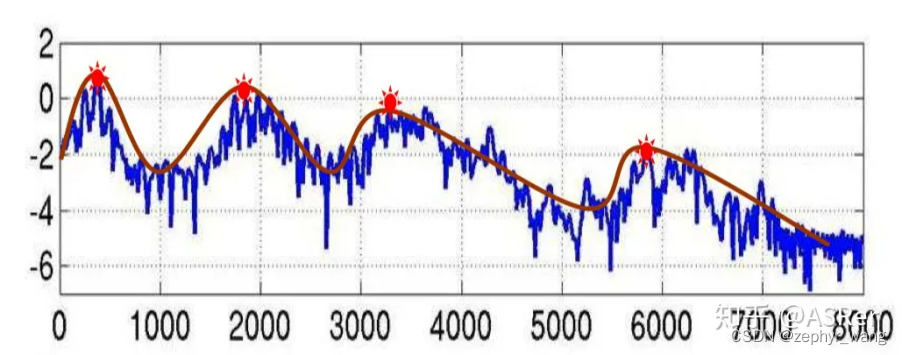
语音特征:spectrogram、Fbank(fiterbank)、MFCC
1.各种语音特征
语音特征用于语音识别和语音合成等。
语音特征有声谱图spectrogram、Fbank(fiterbank)、MFCC(Mel-frequency cepstral coefficients)等。
Fbank 特征提取方法就是相当 于 MFCC 去掉最后一步的离散余弦变换(有损变换).
在深度学习之前…
未来杯区域赛临近收官,多家高校队伍共同挑战人工智能领域的难题
由中软国际教育科技集团旗下睡前Futurelab携手中国青少年发展基金会、DeepTech和华为手机共同主办,清华语音和语言技术中心、北京希尔贝壳科技有限公司和厦门大学海洋与地球学院共同协办的“2020未来杯高校AI挑战赛”,自年初开启“战疫特别赛事”以来&am…

现代语音信号处理笔记 (五) 线性预测分析
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本节针对《现代语音信号处理》这本书的第六章,对线性预测分析应部分。 线性预测分析
线性预测(Linear Prediction COding, LPC)可及精确地估计语音参数,其基…
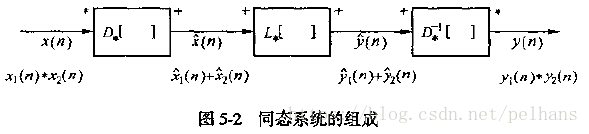
现代语音信号处理笔记 (四) 倒谱分析与同态滤波
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本节针对《现代语音信号处理》这本书的第五章,对应倒谱分析与同态滤波部分。 倒谱分析与同态滤波
语音信号可用一个线性时不变系统的输出表示,即看做声门激励…

基于语音信号识别性别(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…

MP3 Module 语音播放模块(Arduino和串口控制)
MP3 Module 语音播放模块(Arduino和串口控制) 前言电气参数原理图MP3文件所放位置和命名规则:接线代码串口控制通讯指令(部分)实验结果 前言
Emakefun MP3语音模块内置8 MB存储空间,无需外接SD卡ÿ…
【SU-03T离线语音模块】:学习配置使用
前言 时不可以苟遇,道不可以虚行。 一、介绍
1、什么是语音识别模块 语音识别模块是在一种基于嵌入式的语音识别技术的模块,主要包括语音识别芯片和一些其他的附属电路,能够方便的与主控芯片进行通讯,开发者可以方便的将该模块嵌…

端到端的语音识别模型
端到端的语音识别模型CTC(李宏毅深度学习HLP课程笔记)
一、CTC
1、模型介绍
CTC可以用于在线流式语音识别,因此encoder部分需要选择uni-directional RNN,模型结构图如下,输入的语音信号经过encoder逐一转换成语音表…
语音输入转文字怎么操作?分享几种语音转文字技巧
相信有不少小伙伴在整理语音文件的时候,都会有过怎样把这些语音直接转换成文字的想法吧。每次在我开完会之后,需要对会议语音进行整理时,都会产生这种想法。因为我们需要不断的去听这个会议的语音内容,这样做既费时又费力。但其实…

阿里「杀手锏」级语音识别模型来了!推理效率较传统模型提升10倍,已开源
阿里达摩院,又搞事儿了。
这两天,它们发布了一个全新的语音识别模型: Paraformer。 开发人员直言不讳:这是我们“杀手锏”级的作品。
——不仅识别准确率“屠榜”几大权威数据集,一路SOTA,推理效率上相比…
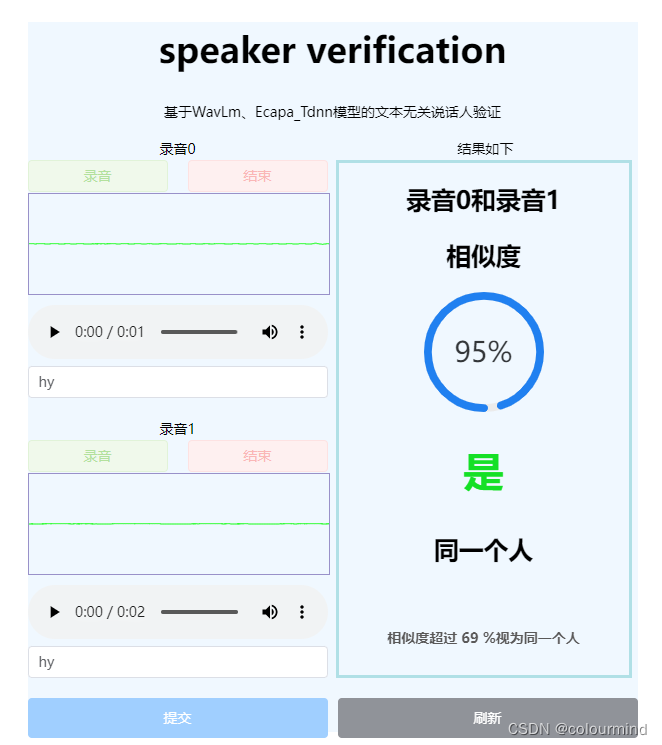
声纹识别之说话人验证speaker verification
目录
一、speaker verification简介
二、主流方案和模型
1、Ecapa_TDNN模型
2、WavLm
三、代码实践
1、Ecapa_TDNN方案
a、模型结构
b、loss
c、数据处理
d、模型训练和评估
e、说话人验证推理
2、WavLm预训练方案
a、模型结构和loss
b、数据处理
c、模型训练
…

whisper语音识别部署及WER评价
1.whisper部署 详细过程可以参照:🏠 创建项目文件夹 mkdir whisper
cd whisper conda创建虚拟环境 conda create -n py310 python3.10 -c conda-forge -y 安装pytorch pip install --pre torch torchvision torchaudio --extra-index-url 下载whisper p…

什么是Natural Language Understanding(NLU)?
文章目录 1.什么是NLU?2.NLU的应用有哪些?3.NLU的实现方式有哪些?4.NLU实现的难点 1.什么是NLU?
自然语言理解(Natural Language Understanding, NLU)是所有支持机器理解文本内容的方法模型或任务的总称,即能够进行常…
2020未来杯高校AI挑战赛为参赛选手免费提供GPU
由中软国际教育科技集团旗下睡前Futurelab携手中国青少年发展基金会和华为手机,面向海内外高校在读学生的“2020未来杯高校AI挑战赛”已进入区域赛比赛阶段。
与前两届大赛相同,本次大赛主办方联合华为云,为参赛选手免费提供GPU计算资源&…

python语音识别whisper
一、背景
最近想提取一些视频的字幕,语音文案,研究了一波
二、whisper语音识别
Whisper 是一种通用的语音识别模型。它在不同音频的大型数据集上进行训练,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。 …
Kaldi Data preparation
链接:GitHub - nessessence/Kaldi_ASR_Tutorial: speech recognition using Kaldi framework
Lets start with formatting data. We will randomly split wave files into test and train dataset(set the ratio as you want). Create a directory data and,then t…

当人工智能还不够智能的时候
原文地址
《黑镜》视频里家中的一切设施都是声控的,早上起床说句开门,房间门就开了。开灯,灯就自动亮了。说句制作奶昔,榨汁机听到指令就会制作奶昔。这些人工智能的来源都是用声音来实现。 当然机器不是人,人工智能偶…

儿童牙刷语音方案,低功耗语音芯片NV040C,支持UART指令
随着人们对生活品质的追求越来越高,家庭中的日常用品也开始注重便携性、功能性与智能化。牙刷作为家庭必备的清洁用品,同样也在走向智能化的方向。为此,市场上出现了一些支持语音指令的儿童牙刷语音方案,其中低功耗语音芯片NV040C…

【语音之家公开课】Audio-Text Cross Modal Translation
本次语音之家公开课邀请到 Wenwu Wang 进行分享 Audio-Text Cross Modal Translation。 公开课简介
主题:Audio-Text Cross Modal Translation
时间:2023年4月4日16:00-17:00 嘉宾介绍 Wenwu Wang
Wenwu Wang is a Professor in Signal Processing an…

13*12数码管显示驱动+语音播报功能二合一方案,WT2003H4-B002
在现代科技飞速发展的时代,语音芯片作为人机交互的重要组成部分,扮演着越来越重要的角色。为了满足市场对多功能、高性能的需求,深圳唯创知音推出了一款创新的语音芯片方案——单芯片可以驱动13x12数码管显示语音播报功能的语音芯片。让我们一…

移动端网页录音上传,服务端智能语音识别
移动端网页录音上传,服务端智能语音识别
最近,看了创业时代的魔镜,想法突如起来,能不能手机发送一条语音,语音上传到后台,自动识别语音的信息,转化为文字,将文字分析,然…
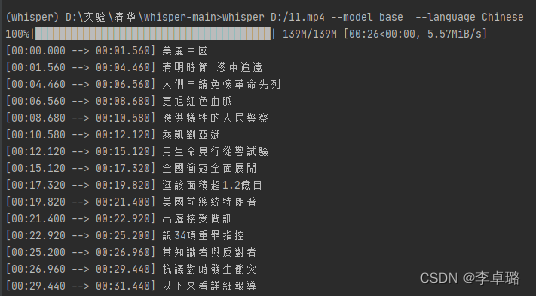
学习实践-Whisper语音识别模型实战(部署+运行)
1、Whisper内容简单介绍
OpenAI的语音识别模型Whisper,Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务…

李宏毅学习笔记10.Why Deep(上)
文章目录前言深度学习是不是越深越好?魔主化(Modularization)魔主化在语音识别的应用人类语言的架构语音识别的第一步传统做法DNN的做法通用原理小结 Universality Theorem前言
本节课老师从深度学习的学习效率与深度的关系开始展开…
免费的语音转文字软件有哪些?推荐一款好用的
随着人工智能技术的不断发展,语音识别技术已经得到了广泛的应用。语音转文字软件是其中的一种应用,它能够将人们说出的话语自动转化为文字,从而方便人们进行文本处理、记录、存档等操作。在现实生活中,有很多人需要使用语音转文字…

ChatGPT在语音识别技术领域的应用
第一章:引言
近年来,随着深度学习技术的飞速发展,语音识别技术已经成为了人工智能领域中备受关注的重要领域之一。在语音识别技术的应用中,ChatGPT作为一款先进的语言模型,可以发挥其强大的文本生成和自然语言处理能力…
烟花智能直播助手,直播带货必备爆单工具【直播助手脚本+技术教程】
烟花智能直播助手软件教程介绍: 1.账号管理:可以登陆多个账号,一键切换 2.商品批量管理:可一键删除/添加直播商品,一键设置商品卖点 3.自动弹讲解:可设置指定,单个,列表循环自动弹商品讲解 4.智能文字客服:可设置指定关键词对公屏信息进行回复,不限添加条…
html语音播报功能问题
语音播报有个问题,就是弹出层有时无法关闭页面的播报,如果弹出层也有语音播报,就会造成语音混者播放
解决办法就是在弹出窗口(我用的弹出层框架是layui的)之前清空语音
window.operEdit function (url, title){window.speechSynthesis.can…

语音唤醒的具体技术方案
\qquad昨天的文章说的是不同的语音激活检测技术,传送门今天要说的是这个技术中间的具体的语音唤醒技术。语音唤醒技术到目前已经经过了三代的发展了。 第一代的技术很好理解,就是先构建一些模板,然后遇到语音,和模板进行匹配&…

HW-VAD SW-VAD StandBy
\qquad这是三种语音唤醒的处理方法。VAD(Voice Activity Detection 语音激活检测)是用于检测当前输入信号中是否有语音的技术。VAD一般会综合分析输入信号的能量特征,以及频谱特征等信息判断是否存在语音。 \qquad由这两段话的分析可知&#…

智能质检技术的核心环节:语音识别和自然语言处理
随着呼叫中心行业的快速发展和客户服务需求的不断提高,越来越多的企业开始采用智能质检技术,以提高呼叫中心的质量和效率。而在智能质检技术中,语音识别和自然语言处理是其核心环节,对于提高质检的准确性和效率具有重要作用。 语音…
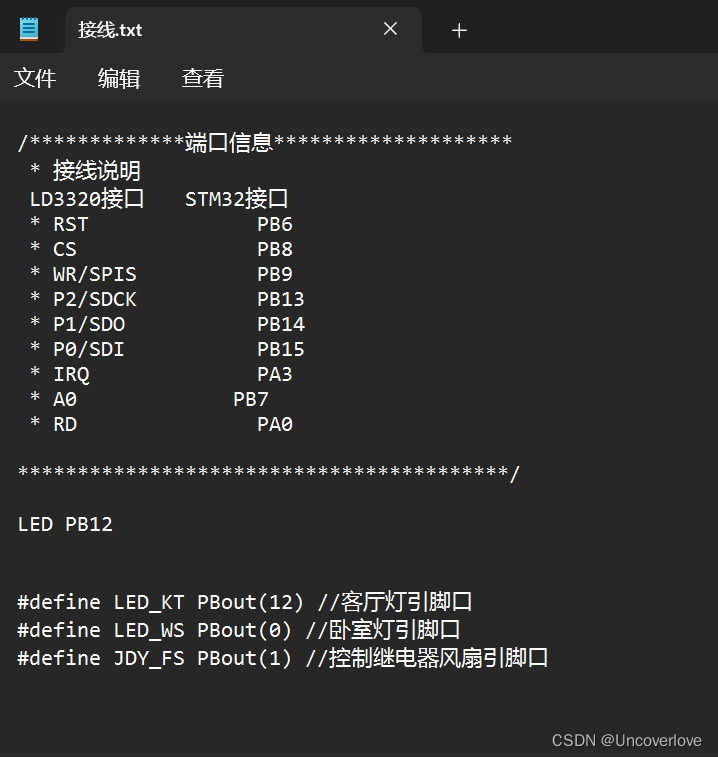
实现语音识别系统:手把手教你使用STM32C8T6和LD3320(SPI通信版)实现语音识别
本文实际是对LD3320(SPI通信版)的个人理解,如果单论代码和开发板的资料而言,其实当你购买LD3320的时候,卖家已然提供了很多资料。我在大学期间曾经多次使用LD3320芯片的开发板用于设计系统,我在我的毕业设计…

【人工智能124种任务大集合】-集齐了自然语言处理(NLP),计算机视觉(CV),语音识别,多模态等任务
大家好,我是微学AI,今天给大家介绍一下人工智能124种任务大集合,任务集合主要包括4大类:自然语言处理(NLP)、计算机视觉(CV)、语音识别、多模态任务。
我这里整理了124种应用场景任…


ASR 语音识别接口封装和分析
这个文档主要是介绍一下我自己封装了 6 家厂商的短语音识别和实时流语音识别接口的一个包,以及对这些接口的一个对比。分别是,阿里,快商通,百度,腾讯,科大,字节。
zxmfke/asrfactory (github.c…

深度学习在语音识别方面的应用
前言
语音识别是一项非常重要的技术,它可以将人类的语音转化为计算机可以理解的形式。深度学习是一种非常强大的机器学习技术,它在语音识别方面也有广泛的应用。本文将详细介绍深度学习在语音识别方面的应用。 语音识别的基本步骤
语音识别的基本步骤包…

Unity 科大讯飞离线语音合成
好久没有更新文章了,今天我们继续更新科大讯飞的语音的文章。 之前在语音合成部分由于在线语音合成的处理时间太长,所以使用了C#自带的语音合成,处理是快了,但是合成的声音特别难听。 所以今天更新一个离先语音合成的文章。 废话不…

Unity制作批量配音制作工具
最近一直在忙项目,都没有时间和大家分享文章了。今天是来送福利的,送个大家一个语音合成音频工具,当然这也是用Unity制作的。看到讯飞官网有个配音制作,还需要收费,我就不能忍啊,就把之前之前做的批量配音制…

Sphinx语音识别
一、语音识别简介 语音识别的一般框架一般包含几个部分:声学模型、语音模型、以及词典。语音信号(波形)经过前级处理(包括降噪,语音增强,人声检测等)后,提取特征,送入解码…

Meta 开源语音 AI 模型支持 1,100 多种语言
自从ChatGPT火爆以来,各种通用的大型模型层出不穷,GPT4、SAM等等,本周一Meta 又开源了新的语音模型MMS,这个模型号称支持4000多种语言,并且发布了支持1100种语言的预训练模型权重,最主要的是这个模型不仅支…
语音活性检测器py-webrtcvad安装使用
谷歌为WebRTC项目开发的VAD是目前最优秀、最先进和免费的产品之一。webrtcvad是WebRTC语音活动检测器(VAD)的python接口。兼容python2和python3。功能是将一段音频数据分为静音与非静音。它对于电话和语音识别很有用。 1、安装pip yum -y install epel-release
yum -y install …

基于神经网络的数字识别,神经网络语音识别原理
脉冲神经网络的简介
脉冲神经网络(SNN-SpikingNeuronNetworks)经常被誉为第三代人工神经网络。第一代神经网络是感知器,它是一个简单的神经元模型并且只能处理二进制数据。
第二代神经网络包括比较广泛,包括应用较多的BP神经网络。但是从本…
四款AI视频翻译产品横评
本文内容节选自 Paxi.ai 的文章分享,从其中摘录了我觉得有意思的一部分。Paxi.ai 是一个基于 GPT-4 打造的帮用户快速使用AI的AI工具,通过与它的小助手对话可以了解各种AI的产品功能和使用方式。对本文内容感兴趣的朋友可以上他们官网查看。 有没有想过把…

挂耳式耳机品牌排行榜,良心推荐这四款蓝牙耳机
在蓝牙耳机越来越普及的同时,大家开始重视佩戴耳机时的舒适度,市面上的耳机形式也逐步迭代,目前流行的开放式耳机不仅很好的避免长期佩戴耳机产生的酸痛感,而且对耳道健康问题的处理也具有极佳的效果。那么,面对市面上…

chatgpt赋能python:Python小波分解:一种更高效的数据处理方法
Python小波分解:一种更高效的数据处理方法
介绍
在现代科技时代,数据处理在各个领域都扮演着至关重要的角色。比如信号、图像、音频和视频等数据的处理,这些领域需要能够处理数据,核心是要可以提取出它们的特征。这正是小波变换…
chatgpt赋能python:Python彩色输出:让代码更加生动有趣
Python 彩色输出:让代码更加生动有趣
如果你是一名Python程序员,那么你一定知道代码的可读性有多么重要。合理的排版和注释代码可以使你的代码更易于理解,但有时候你需要一些额外的工具来使代码更加生动有趣。这时候,Python 的彩…
论AI WeNet语音识别系统的架构设计
摘要 2020年初,我司启动了智能贸易撮合交易平台的建设工作。我在该项目中担任系统架构设计师的职务,主要负责设计平台系统架构和安全体系架构。该平台以移动信息化发展为契机,采用”AI+国际贸易+语音识别”的模式解决现有应用的多样化沟通需求。平台整体的逻辑复杂,对系统的…
实用工具 | 语音文本对齐MFA的安装及使用
Montreal Forced Aligner(MFA)[1]是一个用于将音频和文本进行对齐的工具。它可以用于语音识别、语音合成和发音研究等领域。MFA支持多种语言和语音,用户可以根据需要自定义训练模型。
本博客介绍如何使用MFA对音频和文本进行对齐,…
多篇论文入选ICASSP 2023,火山语音有效解决多类实践问题
近日由IEEE主办、被誉为世界范围内最大规模、也是最全面的信号处理及其应用方面的顶级学术会议ICASSP2023于希腊召开,该会议具有权威、广泛的学界以及工业界影响力,备受AI领域多方关注。会上火山语音多篇论文被接收并发表,内容涵盖众多前沿领…

OKCC呼叫中心使用中常见问题及处理方法
经常有客户咨询在使用OKCC呼叫中心系统时遇到的一些常见但不复杂的问题,下面整理了一些问题和处理方法给伙伴们参考:一、外呼任务为何启动后会自动暂停?1.检查该账户余额是否充足;2.外呼任务班组中是否有空闲坐席;3.分…
计算机工程与应用期刊投稿经验
计算机工程与应用期刊投稿经验
直接上图: 经历了两个多月的时间终于录用了,可能是因为十月一放假了,拖了很长时间。主要经过了两次外审,两次复审。其实论文没有太多进行修改,外审专家询问的较多,这时候只要…
语音识别降噪思路和总结
噪声问题一直是语音识别的一个老大难的问题,在理想的实验室的环境下,识别效果已经非常好了,之前听很多音频算法工程师抱怨,在给识别做降噪时,经常发现WER不降反升,降低了识别率,有点莫名其妙&am…
语音识别—kaldi常用文件查看指令
1. ark特征文件
copy-feats 可以用来改变特征数据的格式,因此可以转换ark格式文件为txt格式: 用法: copy-feats [options]
例子: 先查找copy-feats的目录(每个人可能不一样):
find /home/speech.AI/kal…

解析kaldi中的yesno的语音分帧和模型
看了很多内容,还是不明白kaldi是如何处理每一段语音的。可以做下面的实验
为了结合kaldi,可以将kaldi中yesno的对齐结果解析出来。步骤如下: 1、跑完yesno的run.sh脚本,获得模型0.mdl、HCLG.fst和ali.1.gz ࿱…

从零开始学习Java神经网络、自然语言处理和语音识别,附详解和简易版GPT,语音识别完整代码示例解析
🏅 欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! 目录一、神经网络简介二、实现简单神经网络三、Java自然语言处理示例代码(简易版GPT)四、Java简易版语音识别示例代码五、结论神经网络是一种模仿人脑神经…
极速进化,光速转录,C++版本人工智能实时语音转文字(字幕/语音识别)Whisper.cpp实践
业界良心OpenAI开源的Whisper模型是开源语音转文字领域的执牛耳者,白璧微瑕之处在于无法通过苹果M芯片优化转录效率,Whisper.cpp 则是 Whisper 模型的 C/C 移植版本,它具有无依赖项、内存使用量低等特点,重要的是增加了 Core ML 支…


Android 百度语音合成手把手教学
文章目录前期准备运行官方demo自己项目中集成前期准备
申请 key 和创建应用的步骤这里不再赘述,可以参考:在线合成Android-SDK介绍 官方文档
运行官方demo
1、下载 在线语音合成Android SDK
离线语音合成SDK只能免费使用 在线合成功能,纯…

AI语音工牌在通讯行业营业大厅场景应用
在运营商营业大厅中,每天都有大量的客户来访咨询、办理业务。同时也会经常产生大量的客诉纠纷和服务差评。但因为缺乏有效的管理工具,加上线下沟通场景的数据采集难度高,数字化程度低,管理一直处于盲区。如何有效的管控营业厅人员…
Android--语音识别
现在国内语音就讯飞和百度,百度免费的,果断采用。
一、首先去官网注册,申请KEY(http://ai.baidu.com/tech/speech/asr)。
二、下载SDK(DEMO里有SDK和jniLibs),开始集成
库文件路径…
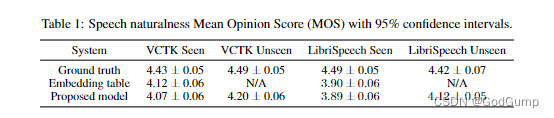
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis翻译(不含实验部分)
感谢阅读阅读须知摘要原文翻译可能不知道意思的英文代码的思考介绍原文翻译可能不懂意思的生词Multispeaker speech synthesis model原文2.1 Speaker encoder2.2 Synthesizer2.3 Neural vocoder2.4 Inference and zero-shot speaker adaptation翻译2.1 说话者编码器2.2 合成器2…

提高Tesseract-OCR验证码识别率
Tesseract-OCR训练自己需要的语言
在正常使用Tesseract-OCR的默认eng去识别复杂的验证码失败率很高,这时候就需要自己训练出自己需要的语言来提高识别成功率。如何训练呢?
训练提高识别率
从jTessBoxEditor:https://sourceforge.net/proje…

《TensorFlow语音识别实战》简介
#好书推荐##好书奇遇季#《TensorFlow语音识别实战》,京东当当天猫都有发售。配套源码、PPT课件、数据集、开发环境与答疑服务。 自动语音识别(Automatic Speech Recognition,ASR)简称为语音识别,是目前科学界、互联网界…
20230811在WIN11下使用python3批量将中英文的SRT格式的字幕合并
20230811在WIN11下使用python3批量将中英文的SRT格式的字幕合并 2023/8/11 8:35 缘起:将google翻译成为的简体中文字幕和剪影/RP2023直接通过语音OCR获取的SRT格式的英文字幕合并成为中英文的字幕! 由于已经解决了UTF8的编码问题,ANSI/GBK编码…

哈工大开源“活字”对话大模型
一、介绍
大规模语言模型(LLM)在自然语言处理的通用领域已取得了令人瞩目的成功。对于广泛的应用场景,这种技术展示了强大的潜力,学术界和工业界的兴趣也持续升温。哈工大自然语言处理研究所30余位老师和学生参与开发了通用对话大…

使用Python将文本转换成语音?
使用Python将文本转换成语音? 超酷的Python应用:将文本转换成语音!这不仅是一个有趣的项目,还能让你体验到Python的神奇之处。废话不多说,让我们开始动手吧!
为什么要转换文本成语音? 在这个信…
一键识别垃圾分类应用 垃圾识别工具箱微信小程序源码 语音识别和图像识别 采用 百度智能云平台服务
前端开发方面,本项目选择了使用uni-app作为开发框架。uni-app是一个基于Vue.js的前端框架,它能够将开发者编写的一套代码发布到多个平台,包括iOS、Android、H5以及各种小程序(如微信、支付宝、百度、头条、QQ、钉钉等)。这种开发方式能够大大提高开发效率,方便同时在多个…
如何在机器学习中实现分类?
机器学习和统计学中的分类是一种监督学习方法,其中计算机程序从给定的数据中学习并进行新的观察或分类。在本文中,我们将详细了解机器学习中的分类。
本博客涵盖以下主题: 目录 什么是机器学习中的分类? 机器学习中的分类术语 分类算法
speech_recognition + PocketSphinx 实现语音唤醒
文章目录 前言环境下载中文包制作激活词 编码实现唤醒 前言
这玩意是干啥的呢,主要的话就是最近有个小项目,需要在ros上面实现一个语音唤醒的操作。同时要求,离线操作,只能使用离线的SDK。然后逛了一圈,发现科大讯飞的…

Unity3D集成腾讯语音GVoice SDK
简述
我们项目中用到了实时语音功能,在最初语音 SDK 技术选型的时候测试过融云、声网和腾讯的 GVoice 。融云和声网我都在我们项目中使用过,但是效果都不如王者荣耀游戏中的实时语音效果,这两天好好研究了一下腾讯的 GVoice,终于…
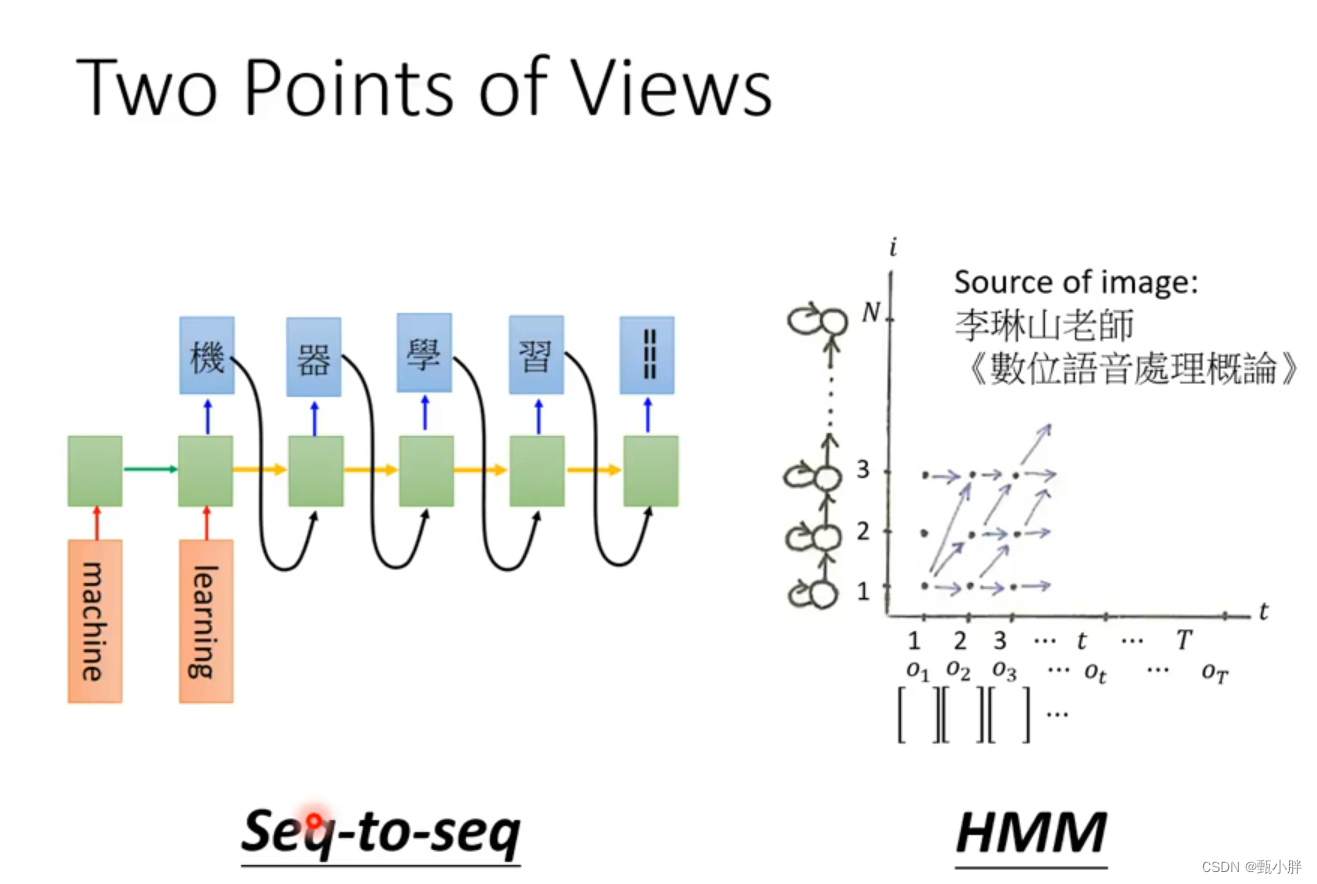
NLP-D32-毕设答辩准备-《人类语言处理》03-04
—0446呜呜呜,怎么会有人给我的csdn打赏呢???惊!感谢!!! 今天的主要任务应该准备毕设的答辩&&下阶段学习任务确定&&日常学习
------0453可以开始该ppt啦~~
《人类…

android 意大利语_制作方法:带有意大利语语的音乐家抽认卡
android 意大利语Update: Now in French too Update 2: and in German Update 3: now with Web Speech API (scroll to the bottom) 更新:现在也使用法语更新2:和德语更新3:现在具有Web Speech API (滚动到底部) Heres a little app that giv…
ffmpeg 音频处理
视频抽取音频
ffmpeg -threads 16 -i xxx.mp4 xxx.wav (能提取5.1声道,采用这个!!!) 或 ffmpeg -threads 16 -i xxx.mp4 xxx.wav -acodec aac -vn -ac 2 -ar 48000 -ab 128000 xxx.aac (有压…

【ACL 2021】《 RADDLE:An Evaluation Benchmark and Analysis Platform for Robust Task-oriented Dialog Sys
【ACL 2021】《 RADDLE:An Evaluation Benchmark and Analysis Platform for Robust Task-oriented Dialog Systems》实验分析
英文标题:RADDLE:An Evaluation Benchmark and Analysis Platform for Robust Task-oriented Dialog Systems 中…
物奇平台蓝牙耳机SOC MIC气密性测试配置方法
物奇平台蓝牙耳机SOC MIC气密性测试配置方法 是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,+群赠送语音信号处理降噪算法,蓝牙耳机音频,DSP音频项目核心开发资料, 1 正常的MIC频响曲线 2 异常的MIC频响曲线
FF…

【AI视野·今日Sound 声学论文速览 第四十一期】Thu, 4 Jan 2024
AI视野今日CS.Sound 声学论文速览 Thu, 4 Jan 2024 Totally 8 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers
Multichannel blind speech source separation with a disjoint constraint source model Authors Jianyu Wang, Shanzheng Guan多通道卷积…
Unity 工具 之 Azure 微软连续语音识别ASR的简单整理
Unity 工具 之 Azure 微软连续语音识别ASR的简单整理 目录
Unity 工具 之 Azure 微软连续语音识别ASR的简单整理
一、简单介绍
二、实现原理
三、注意实现
四、实现步骤 五、关键脚本 一、简单介绍
Unity 工具类,自己整理的一些游戏开发可能用到的模块&#x…

MATLAB环境下一种音频降噪优化方法—基于时频正则化重叠群收缩
语音增强是语音信号处理领域中的一个重大分支,这一分支已经得到国内外学者的广泛研究。当今时代,随着近六十年来的不断发展,己经产生了许多有效的语音增强算法。根据语音增强过程中是否利用语音和噪声的先验信息,语音增强算法一般…

智能语音识别源码系统+语义理解+对话管理+语音合成 带完整的搭建教程
人工智能技术的不断发展,智能语音识别技术逐渐成为人们日常生活和工作中不可或缺的一部分。然而,目前市场上的智能语音识别产品大多存在一定的局限性,如识别率不高、功能单一等。为了解决这些问题,罗峰给大家分享一款基于智能语音…

关于举办“数字孪生核心技术开发与应用研修班”的通知!
为积极响应科研及工程技术人员的需求,根据《国务院关于推行终身职业技能培训制度的意见》提出的“紧跟新技术、新职业发展变化,建立职业分类动态调整机制,加快职业标准开发工作”要求,中国人工智能培训网、中国管理科学研究院现代…
linux 基于科大讯飞的文字转语音使用
官方文档地址:离线语音合成 Linux SDK 文档 | 讯飞开放平台文档中心
一、SDK下载
1、点击上面官方文档地址的链接,可以跳转到以下界面。 2、点击“普通版”,跳转到以下界面。 3、点击“下载”跳转到以下界面 4、最后,点击“SDK下…
最新ChatGPT商业运营网站程序源码,支持Midjourney绘画,GPT语音对话+DALL-E3文生图+文档对话总结
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…

基于单片机的语音识别自动避障小车(论文+源码)
1.系统设计
此次基于单片机的语音识别自动避障小车,以STC89C52单片机作为系统的主控制器,利用超声波模块来实现小车与障碍物距离的测量并通过LCD液晶显示,当距离低于阈值时会通过WT588语音模块进行报警提示,并且小车会后退来躲避…

WeNet语音识别分词制作词云图
在线体验 ,点击识别语音需要等待一会,文件太大缓存会报错 —
介绍
本篇博客将介绍如何使用 Streamlit、jieba、wenet 和其他 Python 库,结合语音识别(WeNet)和词云生成,构建一个功能丰富的应用程序。我们将深入了解代…
最新AI系统ChatGPT网站H5系统源码,支持Midjourney绘画,GPT语音对话+ChatFile文档对话总结+DALL-E3文生图
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…

用 kaldi 和 CVTE开源模型 实现语音识别
用 kaldi 和 CVTE开源模型 实现语音识别 文章目录用 kaldi 和 CVTE开源模型 实现语音识别下载模型使用测试自己的数据集准备文件0. 音频文件1. wav.scpwav.scp 格式2. utt2spkutt2spk 格式3. spk2uttspk2utt 格式测试:下载模型
CVTE开源了kaldi的中文模型ÿ…
kaldi 的安装和thchs30语音识别测试
kaldi 的安装和测试 文章目录kaldi 的安装和测试1. 下载源码2. 安装3. Kaldi 目录介绍子目录egs子目录src训练、识别、测试语料下载测试结果1. 下载源码
git clone https://github.com/kaldi-asr/kaldi.git kaldi --origin upstream
cd kaldi
git pull2. 安装
cd kaldi
cd to…

Day07 面向对象-2.1 --构造方法、构造代码块与局部代码块、this
1.构造方法
1.构造方法格式: 构造方法的格式:修饰符 方法名【与类同名】 (参数列表){方法体}普通方法的格式:修饰符 返回值类型 方法名(参数列表){方法体}区别:构造方法是与类同名没…
ai智能电话机器人的工作流程是什么
人工智能高速发展,很多人工智能的产品出现在我们的生活和工作中,除了正式使用的人工智能配送机器人,最受关心的是人工智能产品莫过于是智能电话机器人了。目前已经有不少如保险、金融、房地产、汽车等传统电销行业都在使用智能电话机器人。
…

ASR自动语音识别基础理论
基础理论对话式AI的理解与其子任务的介绍ASR自动语音识别简史和发展历程工作流程及原理ASR自动语音识别简介ASR自动语音识别应用场景ASR自动语音识别理论自动语音识别工具包的简介及设计架构使用先进的ASR工具快速实现第一个语音识别应用对话式AI的理解与其子任务的介绍 ASR自动…
外呼系统和呼叫中心系统的优势和特点
在金融投资、教育培训、保险、互联网、旅游、房地产、广告等行业服务或产品电话营销中;在节日促销、招商加盟、活动通知等项目中;作为企业的管理者的您,是否还在因为销售人员效率低,人员成本高等问题头疼?
其实,您只…
ICASSP 2024 丨十一场顶级赛事汇总
IEEE声学、语音与信号处理国际会议(ICASSP 2024)将于2024年4月14日在韩国首尔举办,作为语音研究顶级会议,历年来备受语音开发者的关注,小管家整理了 ICASSP 2024 公示的11场赛事汇总分享给大家。
官网:htt…

AI智能语音机器人的基本业务流程
先画个图,了解下AI语音机器人的基本业务流程。 上图是一个AI语音机器人的业务流程,简单来说就是首先要配置话术,就是告诉机器人在遇到问题该怎么回答,这个不同公司不同行业的差别比较大,所以一般每个客户都会配置其个性…
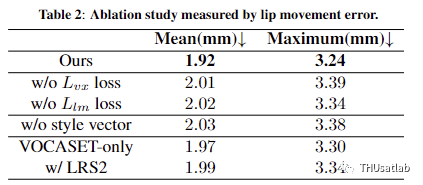
可控情感的表现力语音驱动面部动画合成
高度逼真的面部动画生成需求量很大,但目前仍然是一项具有挑战性的任务。现有的语音驱动面部动画方法可以产生令人满意的口部运动和嘴唇同步,但在表现力情感表达和情感控制的灵活性方面仍存在不足。本文提出了一种基于深度学习的新方法,用于从…
ChatGPT在智能语音识别和声纹识别中的应用如何?
ChatGPT在智能语音识别和声纹识别领域的应用正逐渐引领着语音技术的创新浪潮。作为一种先进的自然语言处理技术,ChatGPT可以被用来分析、理解和生成人类语音,从而在智能语音识别和声纹识别方面发挥重要作用。本文将详细探讨ChatGPT在这些领域的应用情景、…
记录科目三的考试细节
用时两个月,历经种种折磨,终于把C1驾照拿到了,在这里记录一下我的科三考试流程,一方面为了记录,另一方面能帮到后来的人。 记录科三考试细节 中午吃了饭再去,别慌 考试各个流程记清楚 听到广播说参加科目三考试的学员后…
FunASR语音识别GUI界面应用
前言
本文将介绍一个基于FunASR开发的语音识别界面应用,这个应用可以选择本地音频,也可以录音识别。支持多种音频格式和视频格式,可以对识别的结果加上时间戳做成字幕。
安装环境
安装Pytorch,根据自己机器的情况可以选择安装C…
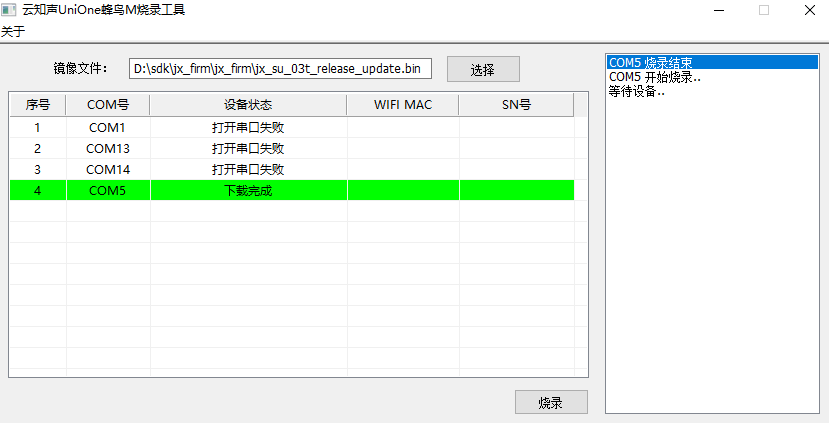
AI智能语音识别模块(一)——离线模组介绍
文章目录 离线语音控制模块简介引脚定义开发平台总结 离线语音控制模块 简介
这是一款低成本,低功耗,小体积的高性价比离线语音识别开发板。能快速学习、验证离线语音控制各种外设,如继电器、LED灯,PWM调光等。 板载了Micro USB接…
基于ADAU1452 DSP语音信号处理算法系统构建
是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?加我微信hezkz17, 本群提供音频技术答疑服务,群赠送音频,DSP音频项目核心开发资料 1 LMS, NLMS 最小均方自适应滤波算法 2 语音活动检测,去混响,波束形成算…
docker启动paddlespeech服务,并使用接口调用
一、检查docker容器是否启动
1.输入命令 systemctl status docker
启动 systemctl start docker
守护进程重启 sudo systemctl daemon-reload
重启docker服务 systemctl restart docker
重启docker服务 sudo service docker restart
关闭docker service docker…

视频闪闪一键视频批量剪辑视频处理批量混剪在线处理的软件功能都有哪些?
视频闪闪是一款功能强大的视频处理软件,提供了多种视频处理和剪辑功能,可以满足用户批量剪辑、混剪和在线处理的需求。以下是视频闪闪的主要功能: 批量剪辑:支持将多个视频文件进行批量剪辑,可以按照设定的时间范围截…

Kaldi的简单介绍和基本使用说明
Kaldi的简单介绍和基本使用说明 前言一、ASR简介1.语音识别系统特征提取:声学模型发音词典语言模型语音解码 2. ASR项目 二、Kaldi简介三、Kaldi项目的结构四、Kaldi的安装1. 安装依赖的几个系统开发库2. 安装依赖的第三方工具库3. 编译Kaldi代码配置Kaldi编译Kaldi…

智能油烟机 优化烹饪体验
如果说空调是夏天最伟大的发明,那么油烟机则是健康厨房的伟大推进者。随着科技的发展,智能化的油烟机逐渐走进了人们的日常生活。每当我们在爆炒、油炸食物的时候,油烟总能呛得人眼睛痛、鼻子难受,传统的油烟机面前我们还需要手动…
stm32利用语音识别与播报智能控制led灯
stm32利用语音识别与播报智能控制led灯上次写了一个语音识别的文章,但是那个模块是用串口进行通信的。这次要讲的是另一种识别与播报模块,这种模块相对于上次那种,功能更多,当然价格也更贵。这种识别模块与播报模块都是利用IIC进行…

SOP8封装 NV400F的语音芯片在电动车充电桩的应用
充电桩作为电动汽车的配套设施,为其提供充电服务,功能类似加油站里的加油机。一般安装在公共建筑和居民小区内供电动车车主使用。随着国家对节能减排和保护环境越来也重视。在城市中,新能源的电动车得到了空前的发展,电动汽车零污…
语音识别whisper的介绍、安装、错误记录
介绍
Whisper是OpenAI于2022年9月份开源的通用的语音识别模型。它是在各种音频的大型数据集上训练的模型,也是一个可以执行多语言语音识别、语音翻译和语言识别的多任务模型。 论文链接:https://arxiv.org/abs/2212.04356 github链接:https:…

科普向丨语音芯片烧录工艺的要求
语音芯片烧录工艺要求烧录精度、速度、内存容量、电源稳定性、兼容性和数据安全性。这些要素需优化和控制以保证生产高效、稳定、安全并烧录出高质量的语音芯片。不同厂家生产的语音芯片在烧录工艺上存在差异,需相应设计和研发以实现兼容。 一、烧录精度
语音芯片烧…
10路混音播放芯片,AD按键可扩展,IO口资源丰富,WTR096A-16S
随着科技的不断进步,我们的生活中对于音频体验的需求也在日益增加。无论是玩具、娱乐设备还是智能家居产品,都需要高性能、多功能的混音播放芯片来提供卓越的音频处理和控制能力。正是在这个背景下,我们引入了全新的WTR096A-16S混音芯片&…
黑盟菜鸟剪辑短视频助手是什么
今天我们来讲一下视频综合处理功能,首先我们来打开软件主界面,通过模块化功能合集视频综合处理进入我们的这个功能。首先我们来看一下功能的布局,左边是导入视频的地方,右边是功能区,这里总共包括 32 种功能࿰…

低信噪比环境下的语音端点检测
端点检测技术 是 语音信号处理 的关键技术之一为提高低信噪比环境下端点检测的准确率和稳健性,提出了一种非平稳噪声抑制和调制域谱减结合功率 归一化 倒谱距离的端点检测算法 1 端点检测
1-1 定义
定义:在 存在背景噪声 的情况下检测出 语音的起始点和…
最新AI系统ChatGPT网站系统源码,Midjourney绘画,GPT语音对话+ChatFile文档对话总结+DALL-E3文生图+思维导图一站式解决方案
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…
雷达DoA估计的跨行业应用--麦克风阵列声源定位(Matlab仿真)
一、概述 麦克风阵列: 麦克风阵列是由一定数目的声学传感器(麦克风)按照一定规则排列的多麦克风系统,而基于麦克风阵列的声源定位是指用麦克风拾取声音信号,通过对麦克风阵列的各路输出信号进行分析和处理,…
ai智能外呼机器人的功能,机器人对话常用语模板搭建
智能外呼机器人就是用来往外呼出打电话的;经常看到有文章说电话机器人将要代替传统人工话务员、电话销售员要失业了、外呼机器人要颠覆电销革命了等等,我想说的是,目前市场上的电话机器人还远远不能达到,未来几年内也不一定会实现。 下面就简…

文字转语音在线合成系统源码 附带完整的安装部署教程
现如今,文字转语音(TTS)技术逐渐成为人们获取信息的重要手段之一。然而,市面上的TTS工具大多需要下载安装,且功能较为单一,无法满足用户多样化的需求。因此,开发一款功能强大、易于部署的文字转…

评测集开放丨中文读唇总动员:CNVSRC 2023 中文连续视觉语音识别挑战赛
CNVSRC 2023 (Chinese Continuous Visual Speech Recognition Challenge 2023) 是由 NCMMSC 2023 组委会发起,由清华大学、北京邮电大学、海天瑞声、语音之家联合承办的视觉语音识别竞赛。本次竞赛的核心目的是验证当前视觉语音识别 (或称唇语识别) 技术在大词表连续…
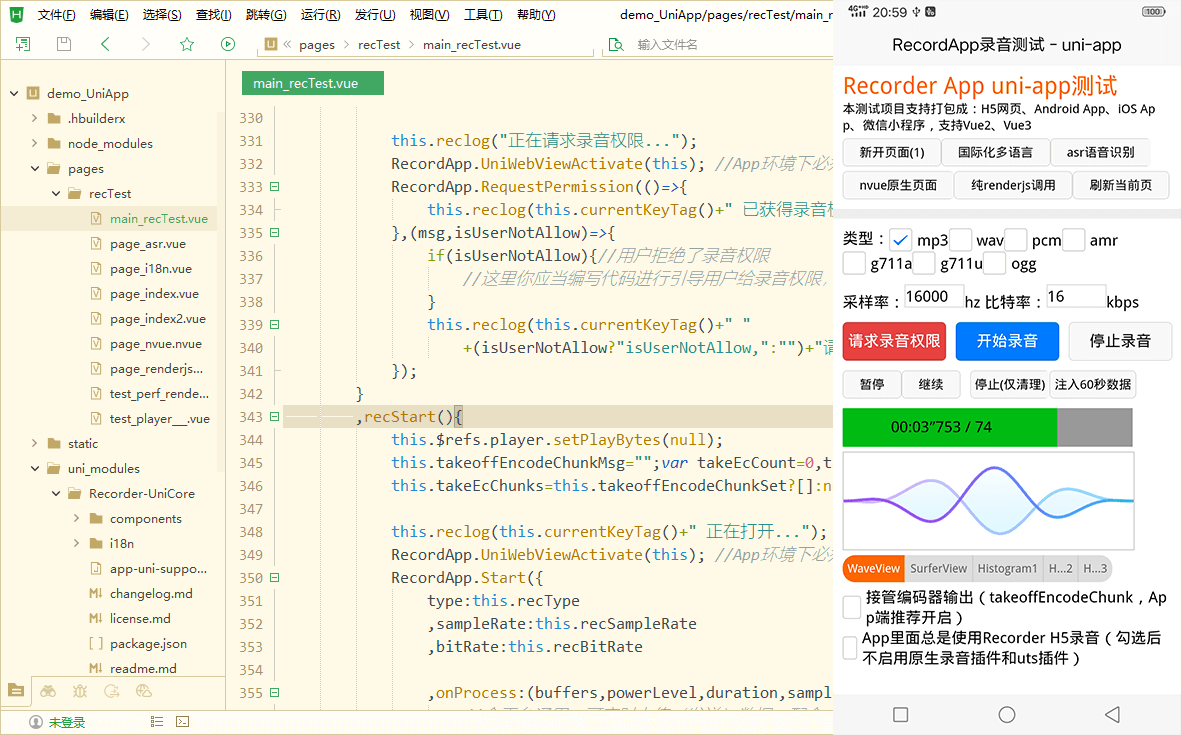
uniapp中实现H5录音和上传、实时语音识别(兼容App小程序)和波形可视化
文章目录 Recorder-UniCore插件特性集成到项目中调用录音上传录音ASR语音识别 在uniapp中使用Recorder-UniCore插件可以实现跨平台录音功能,uniapp自带的recorderManager接口不支持H5、录音格式和实时回调onFrameRecorded兼容性不好,用Recorder插件可避免…

2024基于AI与大数据的智能客服展望
随着新的一年的到来,客服行业正在经历一场革命。技术的飞速发展,特别是人工智能(AI)、大数据和大语言模型,正在彻底改变客服行业的面貌。本文将深入分析2024年客服行业的一些关键趋势,这些趋势预计将塑造未…
AI语音机器人的发展
第一代AI语音机器人具体投入研发的开始时间不太清楚,只记得2017年的下半年就已经开始接触到成型的AI语音机器人,并且正式商用。语音识别效果还不多,大多都是接入的科大讯飞或者百度的ASR。 2018年算是AI语音机器人的“青春期”吧,…

“Morpheus-1”的全新人工智能模型声称能引发清醒梦境
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
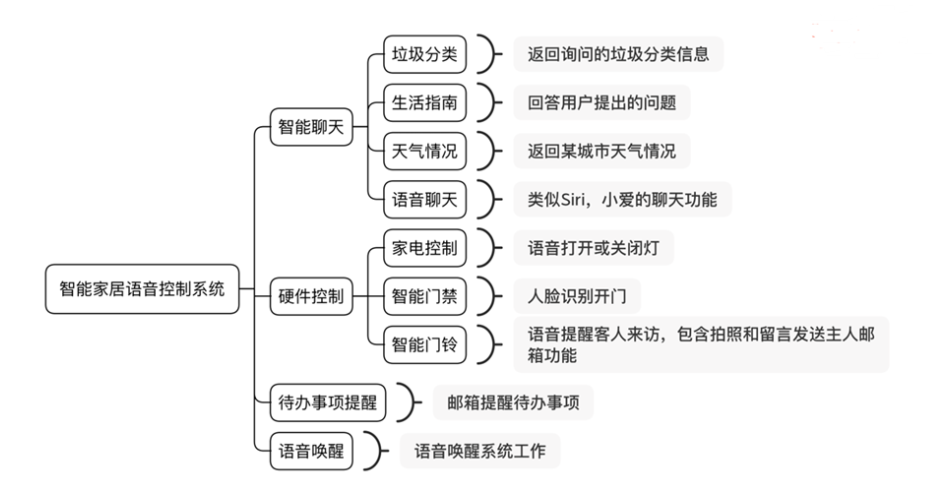
AI:142-开发一种智能家居系统,通过语音识别和情感分析实现智能互动
🚀点击这里跳转到本专栏,可查阅专栏顶置最新的指南宝典~
🎉🎊🎉 你的技术旅程将在这里启航! 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带关键代码,详细讲解供大家学习,希望…

【AI视野·今日Sound 声学论文速览 第五十一期】Mon, 4 Mar 2024
AI视野今日CS.Sound 声学论文速览 Mon, 4 Mar 2024 Totally 6 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers
VoxGenesis: Unsupervised Discovery of Latent Speaker Manifold for Speech Synthesis Authors Weiwei Lin, Chenhang He, Man Wai Mak, …
ASR语音识别纠错-fast correct
1、使用方式说明
ASR对应的文本越长,识别准确率和召回率越高
识别的错误分类:
编号错误类型示例1谐音字词配副眼睛-配副眼镜2混淆音字词流浪织女-牛郎织女3多字错误关关机-关机4少字错误 爱有天意-假如爱有天意 5形似字错误高梁-高粱6中文拼音全拼xin…
Python实现视频转音频、音频转文本加文本实体识别
文章目录 概述必备第三方库视频转音频音频转文字完整代码命名实体识别NER注意点概述
本教程希望可以识别出目前活跃的视频平台(例如抖音、快手等)中视频文案中蕴含的实体信息,首先有两条技术路径: 直接提取视频帧,之后实现逐帧的字幕识别,最后合并为视频文案。 优点:准…
高通GAIA V3命令参考手册的研读学习(十二):第四个示例
主机和设备交互通信的第四个示例,也就最后一个示例:设置默认音量失败
这个示例描述了主机发送一个设置默认音量的请求,其中包含一个无效的值。 对于设备而言,因为语音音量的有效范围是0到15 (0x00到0x0f),也就是一共…
OpenVoice文本转语音大模型实战部署
1. 下载
git clone https://github.com/myshell-ai/OpenVoice.git2. 配置conda
2.1 添加国内镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes2.2 conda源操作
conda config --sho…
本地部署whisper模型(语音转文字)
Whisper是 OpenAI 2022年发布的一款语音预训练大模型,集成了多语种ASR、语音翻译、语种识别的功能。 Whisper使用弱监督训练的方法,可以直接进行多任务的学习
1. 安装ffmpeg
1.1 更新yum
yum update1.2 安装gcc
yum install gcc1.3 在线安装ffmpeg
1.3.1 Install the EP…
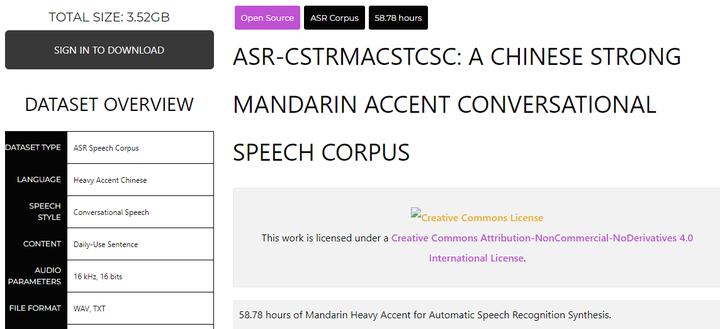
webhub123整理 中文语音识别数据集
我们收集和整理了常用的中文语音识别数据集,合计超过12000小时的数据集。已经按照不同来源整理收录到
webhub123整理 中文语音识别数据集https://www.webhub123.com/#/home/detail?projectHashid64335220&ownerUserid22053727
整理后的效果如下 每个卡片…
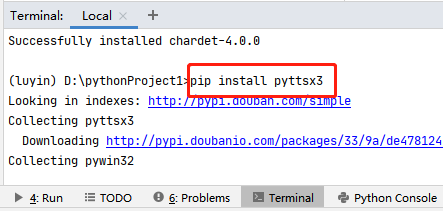
5行代码进行语音合成输出
1.下载pyttsx3
pip install pyttsx32.第一行代码是导入pyttsx3语音合成库
import pyttsx33.第二行代码,pyttsx3.init(),表示调用pyttsx3语音合成库的初始化类。
e pyttsx3.init()4.第三行表示等待运行,等待语音合成
e.runAndWait()5.第四…
WhisperFusion:具有超低延迟无缝对话功能的AI系统
WhisperFusion 基于 WhisperLive 和 WhisperSpeech 的功能而构建,在实时语音到文本管道之上集成了大型语言模型 Mistral (LLM)。
LLM 和 Whisper 都经过优化,可作为 TensorRT 引擎高效运行,从而最大限度地提高性能和实时处理能力。WhiperSpe…
语音处理——Pyannote使用学习
文章目录 引言正文Pyannote的介绍Pyannote安装Pyannote使用问题总结SSLError 总结 引言 在进行AD检测的模型中,原来使用的是whisper进行的语音转换,但是whisper只能实现ASR任务,并不能检测出不同说话者,所以需要学习一下SpeechBra…
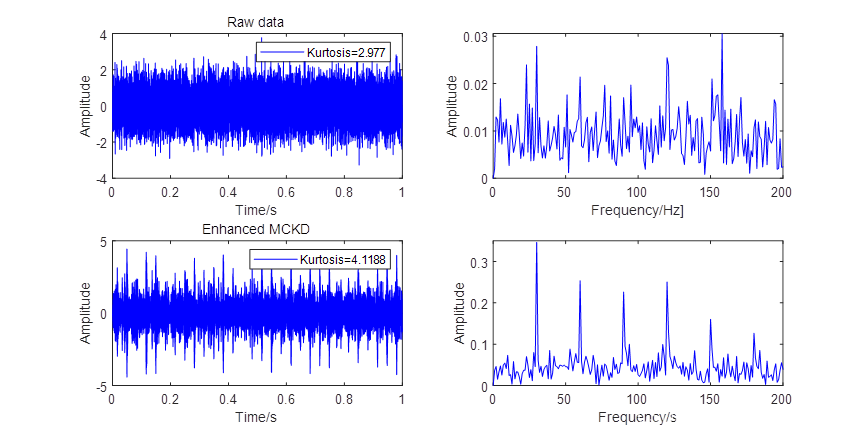
MATLAB环境下基于改进最大相关峭度解卷积的滚动轴承故障诊断
相关峭度解卷积MCKD是一种新的解卷积方法,其设计了一个新的目标函数—相关峭度,并以此为优化目标设计一系列的FIR滤波器,为实现最好的效果,需要从中找到最优滤波器并最终实现对信号中噪声的抑制和对信号中冲击成分的突出的目的。M…
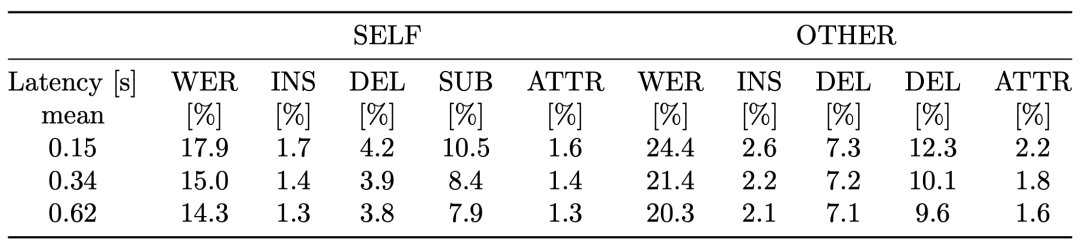
CHiME丨MMCSG(智能眼镜多模态对话)
CHiME 挑战赛已经正式开启,今天分享下 CHiME 的子任务MMCSG(智能眼镜多模态对话),欢迎大家投稿报名!
赛事官网:https://www.chimechallenge.org/current/task3/index
CHiME (Computational Hearing in Multisource Environments…

《Python 语音转换简易速速上手小册》第10章 未来趋势和发展方向(2024 最新版)
文章目录 10.1 语音技术的未来展望10.1.1 基础知识10.1.2 主要案例:语音驱动的虚拟助理案例介绍案例 Demo案例分析10.1.3 扩展案例 1:情感敏感的客服机器人案例介绍案例 Demo案例分析10.1.4 扩展案例 2:多模态智能会议系统案例介绍案例 Demo
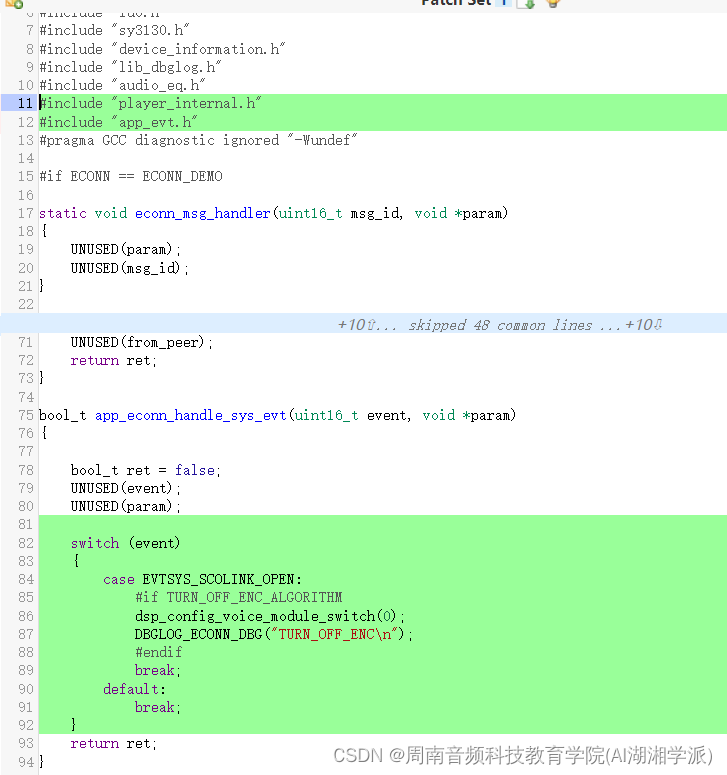
物奇ENC算法开关接口修改方法
物奇ENC算法开关接口修改 是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,群赠送语音信号处理降噪算法,蓝牙耳机音频,DSP音频项目核心开发资料, 1 配置工具事件接口 2 代…
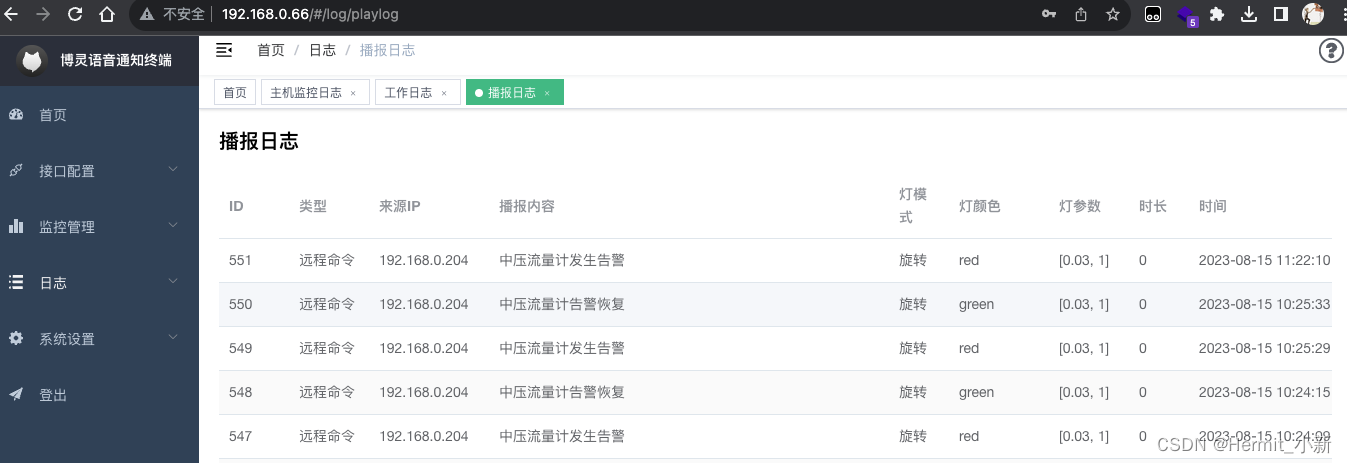
组态王-实现语音播报告警点位信息及语音通知-语音播报器|声光报警器|工业报警方案|语音报警器|工业报警器|语音播报模块
需求简介
本文将介绍组态王如何对产生的告警实现声光语音播报,根据不同的告警点位,朗读具体的告警内容。 本文使用大连英仕博科技有限公司生产的博灵语音通知终端A4与北京亚控开发的组态王进行联动。
本文章分2部分讲解
第一部分为demo调用演示第二部…
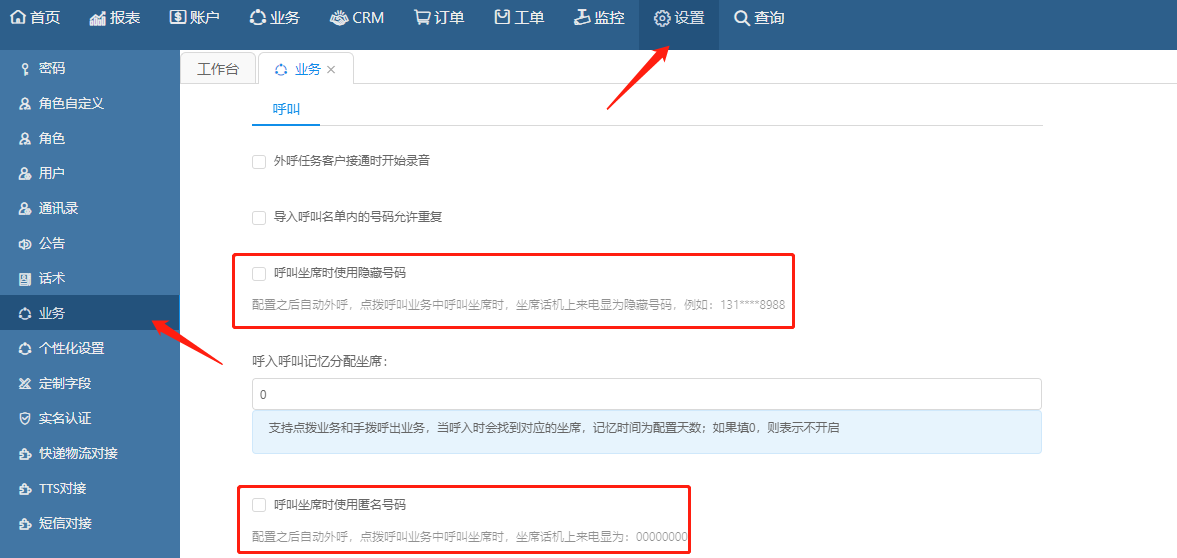
OKCC在系统安全方面做了哪些措施?
语音通信行业,运营者普遍比较关心的问题是,运营风险如何控制?运营安全如何保证?OKCC呼叫中心又有那些风控措施来保证运营安全。
当前阶段,语音通信运营,最主要的风险主要包括以下几个方面: 一、…

MATLAB环境下一种改进的瞬时频率(IF)估计方法
相对于频率成分单一、周期性强的平稳信号来说,具有非平稳、非周期、非可积特性的非平稳信号更普遍地存在于自然界中。调频信号作为非平稳信号的一种,由于其频率时变、距离分辨率高、截获率低等特性,被广泛应用于雷达、地震勘测等领域。调频信…
swift -- 系统语音识别(转文字)
文章目录 一、系统类1. 导入系统库2. SFSpeechRecognizer声音处理器3. SFSpeechAudioBufferRecognitionRequest 语音识别器4. AVAudioEngine 处理声音的数据5. SFSpeechRecognitionTask 语言识别任务管理器 二、代码整理1. 初始化属性2. 判断权限3. 开始语音识别4. 停止语音识别…
本地化语音识别、视频翻译和配音工具:赋能音频和视频内容处理
随着人工智能技术的飞速发展,语音识别、视频翻译和配音等任务已经变得更加容易和高效。然而,许多现有的工具和服务仍然依赖于互联网连接,这可能会导致延迟、隐私问题和成本问题。为了克服这些限制,我们介绍了一种本地化、离线运行…

【DL】深度学习之语音识别
目录
1 核心概念
2 安装依赖库
3 实践 语音信号处理(Speech Signal Processing)简称语音处理。
语音识别(ASR)和自然语言处理(NLP):语音识别就是将语音信号转化成文字文本,简单实…
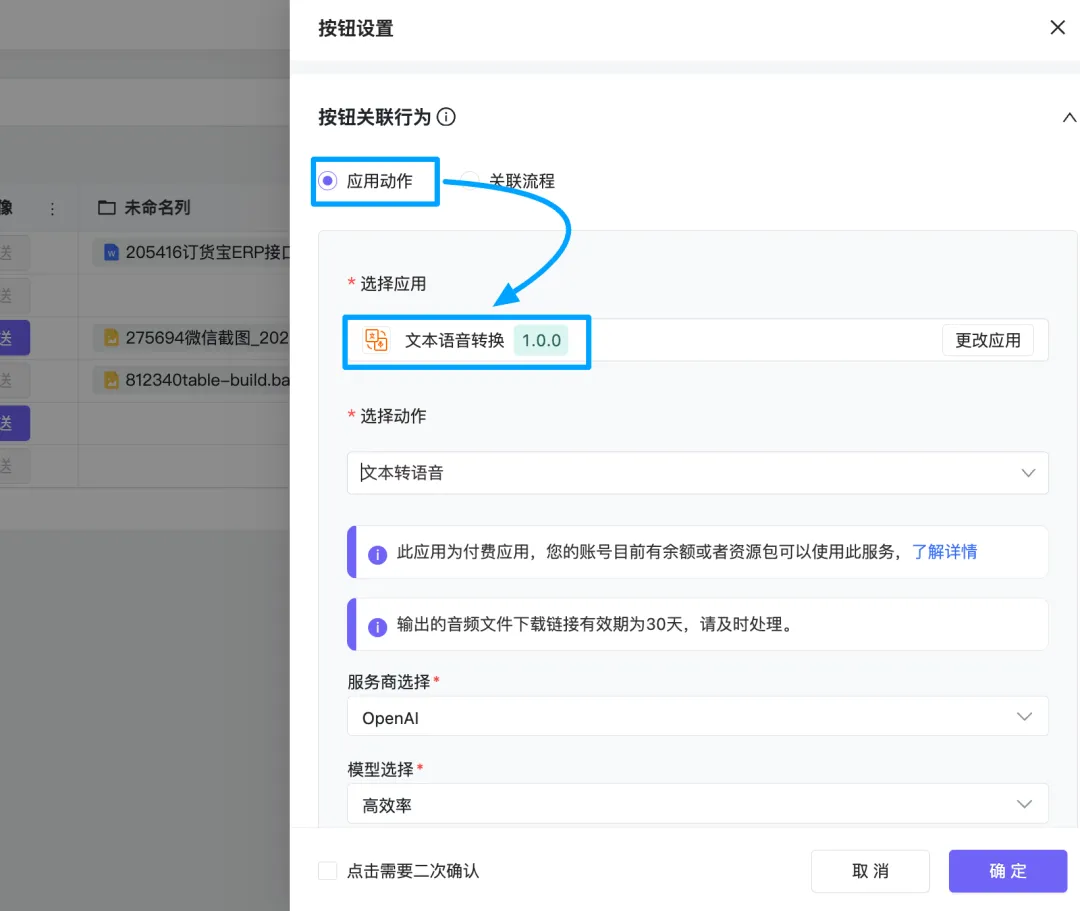
集简云新增“文本语音转换”功能,实现智能语音交互
为丰富人工智能领域的应用集成,为用户提供更便捷和智能化的信息获取和视觉创作方式,本周集简云上线了内置应用—文本语音转换。目前支持OpenAI TTS和TTS HD模型,实现文本语音高效智能转换,也可根据你的产品或品牌创建独特的神经网…
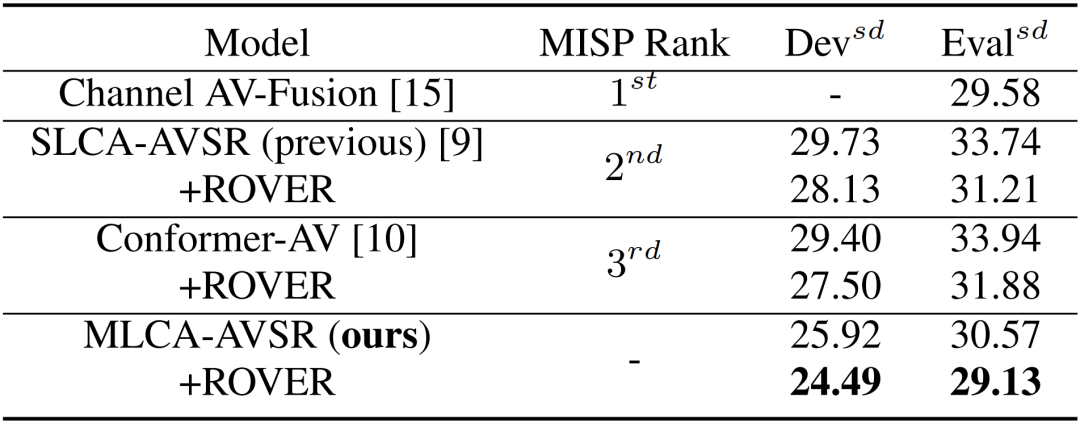
ICASSP2024 | MLCA-AVSR: 基于多层交叉注意力机制的视听语音识别
视听语音识别(Audio-visual speech recognition, AVSR)是指结合音频和视频信息对语音进行识别的技术。当前,语音识别(ASR)系统在准确性在某些场景下已经达到与人类相媲美的水平。然而在复杂声学环境或远场拾音场景&…
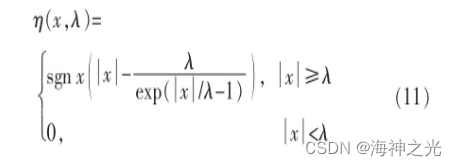
【语音增强】多维谱自适应小波语音信号去噪【含Matlab源码 1972期】
⛄一、自适应小波语音信号去噪
1 引言 语音信号在传输过程中,容易受到环境噪声和其他语音的干扰,降低了语音通信质量,影响了语音处理系统工作。所以,语音的净化处理技术,在现代语音通信和数字音频广播系统中起到愈来愈…
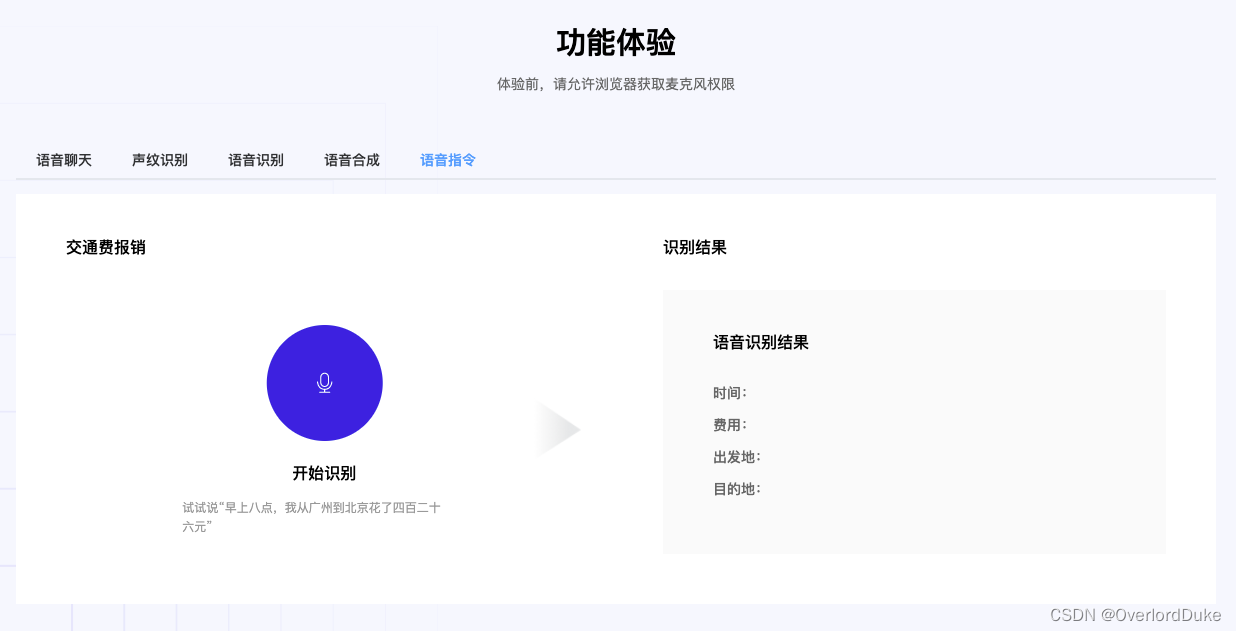
“智能语音指令解析“ 基于NLP与语音识别的工单关键信息提取
“智能语音指令解析“ 基于NLP与语音识别的工单关键信息提取 1. 背景介绍1.1 场景痛点1.2 方案选型 2. 准备开发环境3. PaddleSpeech 语音识别快速使用4. PaddleNLP 信息抽取快速使用5. 语音工单信息抽取核心功能实现6. 语音工单信息抽取网页应用6.1 网页前端6.2 网页后端6.3 a…
《Sora视频生成技术探秘:从压缩到生成,语言理解引领创新》
Sora背后的技术原理:深度探索Video Compression Network与Transformer模型在视频生成中的应用
摘要
随着人工智能技术的不断发展和创新,视频生成技术在许多领域中都得到了广泛的应用。作为一种前沿的视频生成技术,Sora凭借其高效的视频处理…
【让我们深度理解语音识别:Siri与Alexa如何运用深度学习和循环神经网络将声音转化为文字
语音识别技术是近年来人工智能领域的重要研究对象,它的出现大大改善了人与机器的交互方式,增强了人们生活的便捷度。今天,我将带领大家深度了解语音识别技术的内部运作原理,以及语音助手如Siri和Alexa如何运用这些先进技术&#x…
防疫健康码身份证核验扫码盒有用吗?
为了更好地核验健康码,不少的大型公共场所都专立了健康码核验通道。其中包括地铁口、汽车站、医院、购物中心等。根据防疫出行政策对某些特殊场所落实查(48小时/72小时)检测结果、疫苗接种情况(某些地区已发布通知未接种疫苗将影响出行)与健康码查验的严格管控要求&…
2021-10-22制氧机控制板开发吸氧机方案
家用智能制氧机工作原理:利用分子筛物理吸附和解吸技术.制氧机内装填分子筛,在加压时可将空气中氮气吸附,剩余的未被吸收的氧气被收集起来,经过净化处理后即成为高纯度的氧气。分子筛在减压时将所吸附的氮气排放回环境空气中&…
支持跨语言、人声狗吠互换,仅利用最近邻的简单语音转换模型有多神奇
AI 语音转换真的越复杂越好吗?本文就提出了一个方法简单但同样强大的语言转换模型,与基线方法相比自然度和清晰度毫不逊色,相似度更是大大提升。
AI 参与的语音世界真神奇,既可以将一个人的语音换成任何其他人的语音,…
Android毕业设计,基于Android 语音朗读书籍管理系统
视频演示: 基于Android 语音朗读书籍管理系统 基于 Android 的语音朗读书籍管理系统可以提供用户管理书籍、朗读书籍的功能。以下是一个简单的步骤和功能列表: 用户注册和登录功能: 用户可以注册新账号或使用现有账号登录系统。用户信息可以包…

车载多通道语音识别挑战赛(ICMC-ASR)丨ICASSP2024
由希尔贝壳、理想汽车、西工大音频语音与语言处理研究组、新加坡南洋理工大学、天津大学、WeNet开源社区、微软、中国信通院等单位发起的“车载多通道语音识别挑战赛”(ICMC-ASR)将作为IEEE声学、语音与信号处理国际会议(ICASSP2024ÿ…
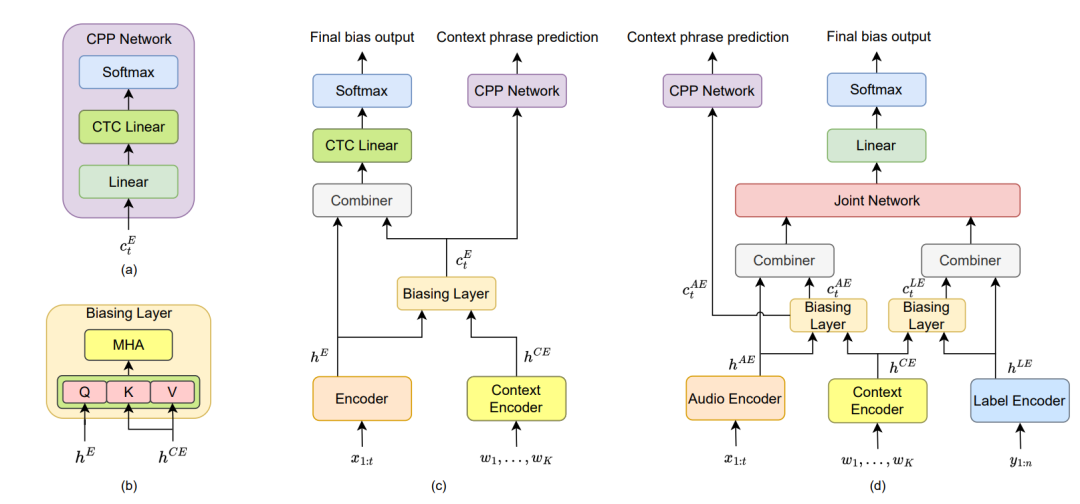
西工大 ASLP 实验室在 WeNet 中开源基于 CPPN 的神经网络热词增强语音识别方案
语境偏置(Contextual biasing)旨在将语境知识集成到语音识别(ASR)系统中,以提高在相关领域词汇(俗称“热词”)上的识别准确率。在许多ASR场景中,待识别语音中可能会包含训练数据中数…
Python小项目之Tkinter应用】随机点名/抽奖工具大优化:新增查看历史记录窗口!语音播报功能!修复预览文件按钮等之前版本的bug!
文章目录 前言一、实现思路二、关键代码查看历史记录按钮语音播报按钮三、完整代码总结前言
老生常谈,先看效果:(订阅专栏可获取完整代码) 初始状态下,我们为除了【设置】外的按钮添加弹窗,提示用户在使用工具之前要先【设置】。在设置界面,我们主要修改了【预览文件】…

A Framework to Evaluate Fusion Methods for Multimodal Emotion Recognition
题目A Framework to Evaluate Fusion Methods for Multimodal Emotion Recognition译题一种评估多模态情感识别融合方法的框架时间2022年仅用于记录学习,不作为商用
一种评估多模态情感识别融合方法的框架
摘要:情绪识别的多模态方法考虑了预测情绪的几…
torch其他层和联合使用
recurrent layers一般是特定的结构,在语音识别和创作用的比较多,又RNN,LSTM,GRU一些东西。
transform 层nlp常用,在cv领域表现得很不错
线性层,infeature和outfeature还有一个偏置
dropout层,是为了防止过拟合&…
小程序 语音搜索功能,语音识别翻译成文本进行搜索
1.使用的是wepy框架。
<view class"{{recordState?speakInfoActive:speakInfo}}" catchtouchstart"touchStart" catchtouchend"touchEnd">按住说话</view>
2.js部分
const plugin requirePlugin(WechatSI);
const manager plu…
Python手写语音识别文字
Python手写语音识别文字
1. 算法思维导图
以下是使用mermanid代码表示的手写语音识别算法的实现原理的思维导图: #mermaid-svg-JiYawvOFrbWLA0Mz {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-JiYawv…
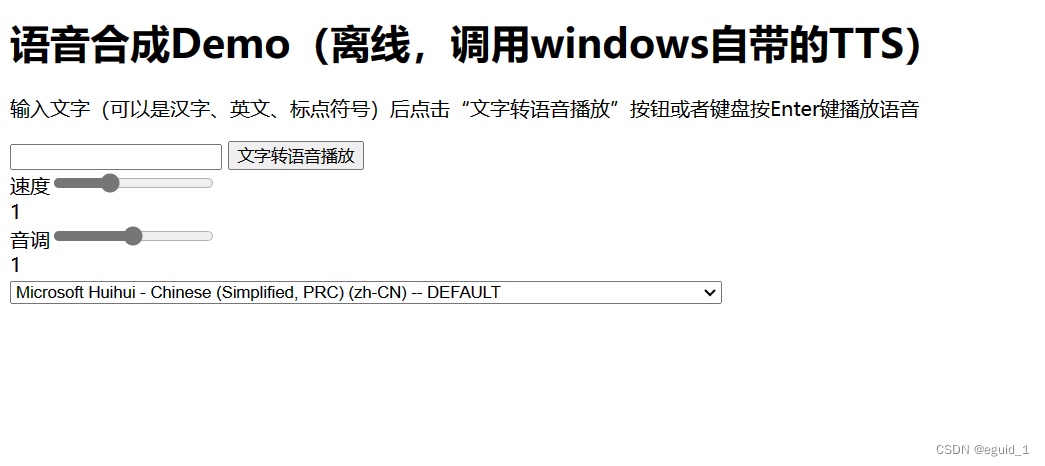
浏览器原生JavaScript离线文字转语音TTS播放,支持Windows自带TTS语音和移动端(安卓、IOS)
前言
JS已经可以实现语音合成(文字转语音)和语音识别(语音转文字),各个浏览器支持列表如下所示: 语音识别支持列表:
因此,浏览器上面使用语音合成非常简单。
页面效果示例:
实现功能
1、支持速度,音调设置 2、支持下拉选择语音模板 3、文字转语音
代码实现 …

AI智能语音机器人的优势
1.高效自动拨号功能。
导入客户数据,外呼机器人自动拨号,无需看守,真人录音话术,定制场景问答和1秒内的问答响应,为客户带来真实准确的咨询体验。同时,每次通话结束后,外呼系统根据通话时间和关…

Whisper.cpp 编译使用
Whisper.cpp 编译使用
whisper.cpp 是牛人 ggerganov 对 openai 的 whisper 语音识别模型用 C 重新实现的项目,开源在 github 上,具有轻量、性能高,实用性强等特点。这篇文章主要记录在 windows 平台,如何使用该模型在本地端进行…
青鸾剪辑-全自动视频混剪,批量剪辑批量剪视频,探店带货系统,精细化顺序混剪,故事影视解说,视频处理大全,精细化顺序混剪,多场景裂变,多视频混剪
随着数字媒体的快速发展,视频剪辑已经成为各行各业不可或缺的一部分。而在众多视频剪辑工具中,青鸾剪辑以其独特的功能和高效的操作赢得了广大用户的喜爱。本文将详细介绍青鸾剪辑的全自动视频混剪、批量剪辑批量剪视频、探店带货系统、精细化顺序混剪、…
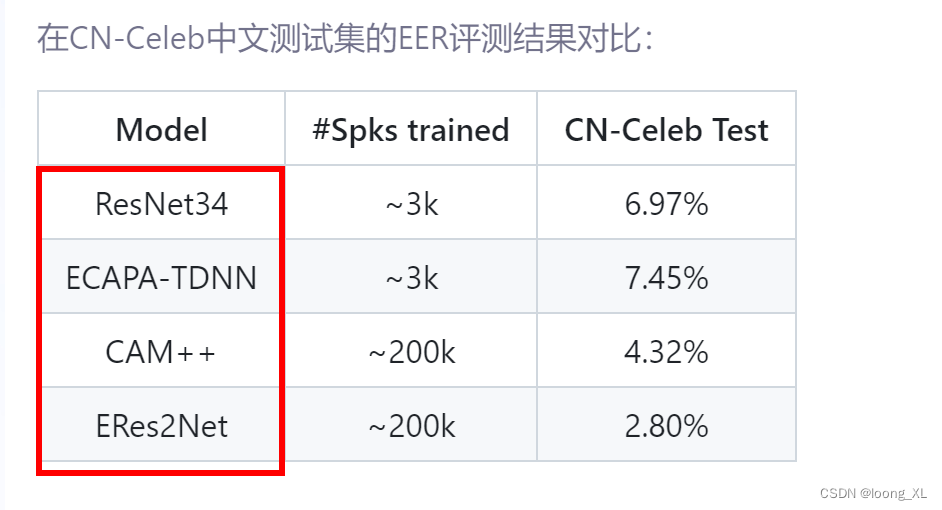
说话人识别声纹识别CAM++,ECAPA-TDNN等算法
参考:https://www.modelscope.cn/models?page=1&tasks=speaker-verification&type=audio https://github.com/alibaba-damo-academy/3D-Speaker/blob/main/requirements.txt 单个声纹比较可以直接modelscope包运行
from modelscope.pipelines import pipeline
sv_pi…
情侣游戏情侣飞行棋小程序系统:智能化互动,增添情感交流
随着科技的不断发展,智能化已经成为我们生活中不可或缺的一部分。在情侣互动游戏中,智能化互动也为情侣们带来了更加丰富、便捷的交流方式。本文将介绍情侣飞行棋小程序系统的智能化互动特点及其为情侣情感交流带来的益处。
一、情侣飞行棋小程序系统的…

Google colab部署VITS——零门槛快速克隆任意角色声音
目录 序言 查看GPU配置
复制代码库并安装运行环境
选择预训练模型
上传视频链接(单个不应长于20分钟)
自动处理所有上传的数据
训练质量相关:实验发现目前使用CJ模型勾选ADD_AUXILIARY,对于中/日均能训练出最好的效果&#x…
ChatGPT在航空航天工程和太空探索中的潜在应用如何?
ChatGPT在航空航天工程和太空探索领域具有广泛的潜在应用。这些应用可以涵盖从设计和模拟到任务控制和数据分析的多个方面。本文将探讨ChatGPT在航空航天和太空探索中的各种可能应用,包括设计优化、任务规划、智能导航、卫星通信、数据分析和太空探测器运行。
### …
AI一点通: OpenAI whisper 在线怎么调用,怎么同时输出时间信息?
OpenAI 语音转文字 whisper API提供了两个端点,即转录和翻译,这基于我们最先进的开源大型v2 Whisper模型。它们可以用来:
将音频转录成音频所在的语言。 翻译并将音频转录成英文。 文件上传目前限制为25 MB,支持以下输入文件类型…

芯片方案应用于终端产品时需要哪些技术支持和保障?
在芯片方案应用于终端产品时,客户可能会遇到三大类问题:一是芯片本身的质量缺陷;二是芯片与终端系统软硬件联合调试及验证;三是终端生产。
接下来,小编简短介绍启英泰伦是如何全方位支持客户项目,保障客户…

柯桥商务英语口语,口语学习中怎样学习语法和基础单词
英语语法和词汇是成功的英语口语沟通的基础!无论你是在准备英语考试、职场交流,还是在国际旅行中,具备坚实的语法和词汇基础都是至关重要的! 接下来将为大家介绍一些有效的方法,帮助你建立和巩固这两个关键的语言技能&…
实时语音通讯技术的应用场景与挑战
随着互联网和移动通信技术的快速发展,实时语音通讯技术已经成为人们日常生活和工作中不可或缺的一部分。实时语音通讯技术可以让人们通过网络进行实时语音通话,不受时间和地点的限制,带来了极大的便利和效率提升。本文将探讨实时语音通讯技术…
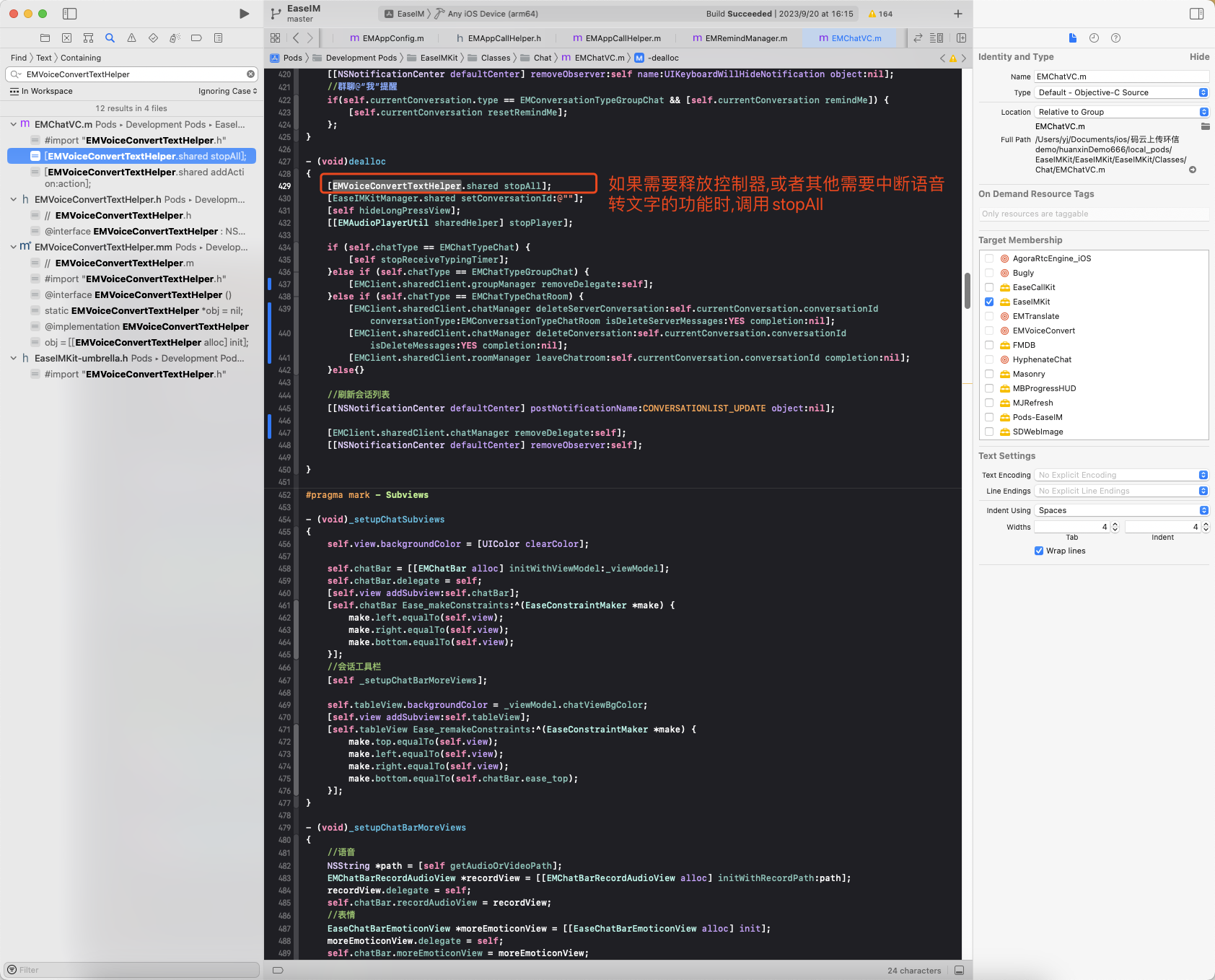
iOS如何实现语音转文字功能?
1.项目中添加权限
Privacy - Speech Recognition Usage Description : 需要语音识别权限才能实现语音转文字功能 2.添加头文件
#import <AVFoundation/AVFoundation.h>
#import<Speech/Speech.h> 3.实现语音转文字逻辑:
3.1 根据wav语音文件创建请求 SFSpeechU…

进阶课2——语音分类
语音分类主要是对语音从不同的维度进行识别和分类,这些维度可以包括语种、性别、年龄段、情绪、说话人身份等,具体如下:
语种分类:根据发音人的母语或者惯用语言,将语音分为不同的语种,例如中文、英文、法…

启英泰伦通话降噪方案,采用深度学习降噪算法,让通话更清晰
生活中的通话应用场景无处不在,如电话、对讲机、远程会议、在线教育等。普遍存在的问题是环境噪音、干扰声导致通话声音不清晰,语音失真等。
为了解决这一问题,启英泰伦基于自适应线性滤波联合非线性滤波的回声消除方案和基于深度学习的降噪…

音乐播放芯片选型规则概述
在选择音乐播放芯片时,应该先了解芯片的参数和特性;做到心中有数。常见的参数包括:采样率、位深度、动态范围、总谐波失真(THD)、信噪比(SNR)等。这些参数决定了芯片的音频处理能力和音质表现。…
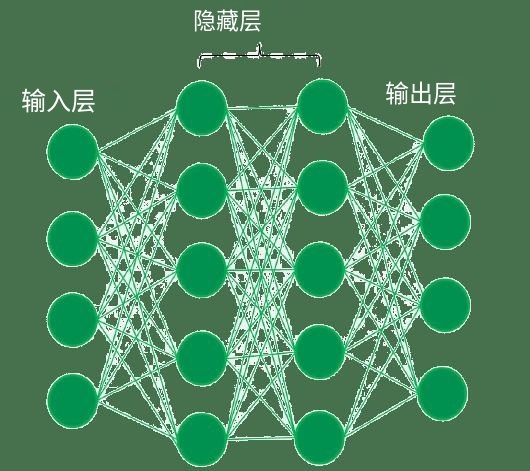
第二章:人工智能深度学习教程-深度学习简介
深度学习是基于人工神经网络的机器学习的一个分支。它能够学习数据中的复杂模式和关系。在深度学习中,我们不需要显式地对所有内容进行编程。近年来,由于处理能力的进步和大型数据集的可用性,它变得越来越流行。因为它基于人工神经网络&#…

基础课26——业务流程分析方法论
基础课25中我们提到业务流程分析方法包括以下几种:
价值链分析法:主要是找出或设计出哪些业务能够使得客户满意,实现客户价值最大化的业务流程。要进行价值链分析的时候可以从企业具体的活动进行细分,细分的具体方面可以从生产指…
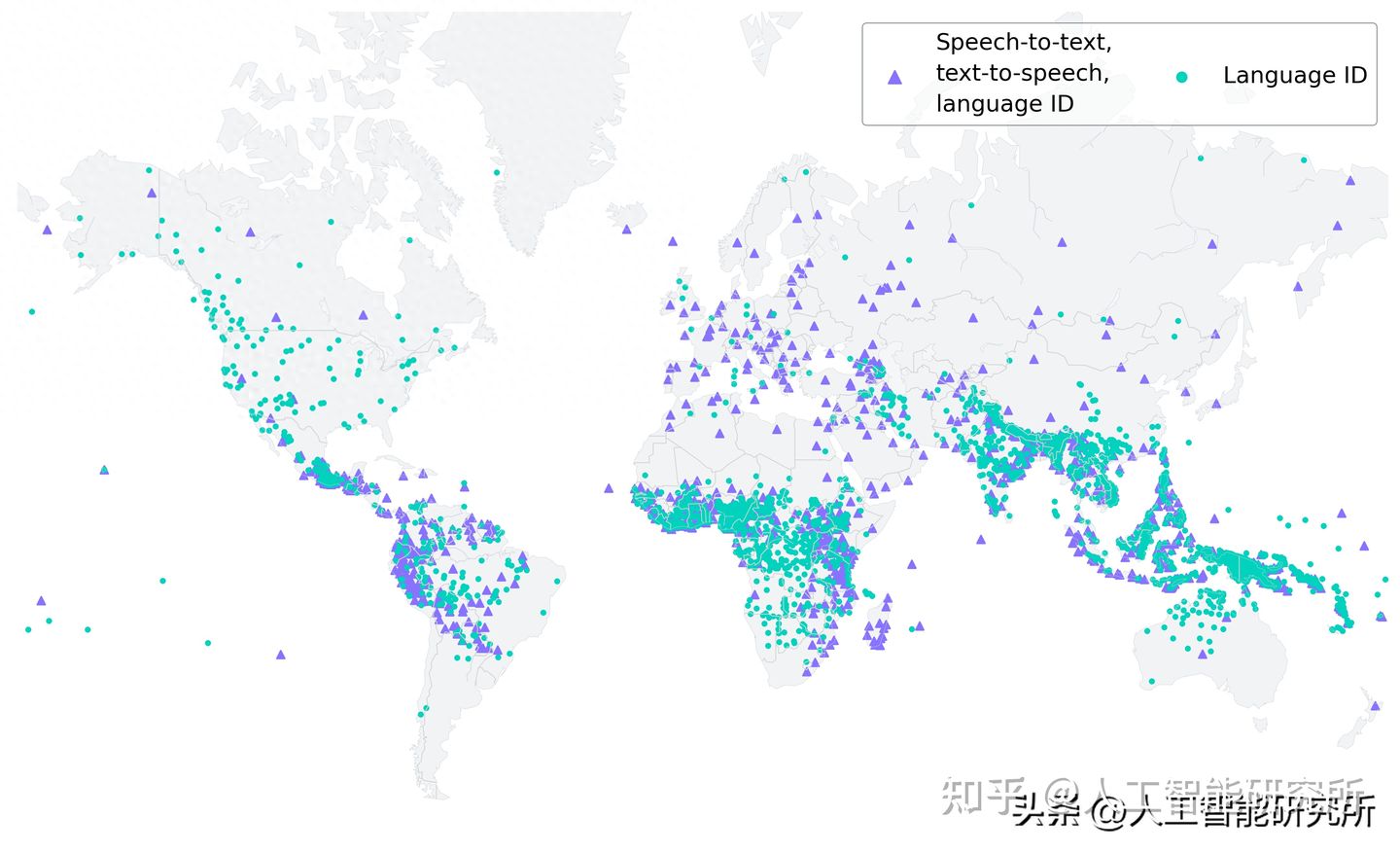
Meta开源支持1000多种语言的文本转语音与语音识别大语言模型
据不完全统计,地球上有超过7000多种语言,而现在的大语言模型仅仅只涉及到了主流的100多种语言。相对全球7000多种语言来讲,这仅仅只是其中的一小部分。如何让全球的人获益,把大语言模型扩展到更多的语言上,一直是大语言模型研究的重点。Meta发布了涵盖 1406 种语言的预训练…
【阿里云】图像识别 摄像模块 语音模块
USB 摄像头模块测试及配置
一、首先将 USB 摄像头插入到 Orange Pi 开发板的 USB 接口中二、然后通过 lsmod 命令可以看到内核自动加载了下面的模块三、通过 v4l2-ctl 命令可以看到 USB 摄像头的设备节点信息为 /dev/video0四、使用 fswebcam 测试 USB 摄像头五、使用 motion …
离线语音识别PocketSphinx(一)
总述
对于设备的控制,最简单方便的交互当属语音控制了,目前市面上也有许多的离线语音控制模块,可以任意更换需要识别的语句,但是识别模型这块都是闭源的,能够配置改动的不多,PocketSphinx是一个开源的离线…

物奇平台耳机宕机恢复功能实现
是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,群赠送语音信号处理降噪算法,蓝牙音频,DSP音频项目核心开发资料,
物奇平台耳机宕机恢复功能实现
一 需求与场景
1 使…
c# 字符串转化成语音合成,System.Speech
C# 语音合成可以使用 System.Speech.Synthesis 命名空间中的 SpeechSynthesizer 类来实现。SpeechSynthesizer 类提供了一系列方法和属性,可以用来控制语音合成的过程,包括设置语音、音调、语速等。
下面是一个简单的示例,用来演示如何使用 …
第十二篇【传奇开心果系列】Python文本和语音相互转换库技术点案例示例:深度解读SpeechRecognition语音转文本
传奇开心果系列 系列博文目录Python的文本和语音相互转换库技术点案例示例系列 博文目录前言一、SpeechRecognition语音转文本一般的操作步骤和示例代码二、SpeechRecognition 语音转文本的优势和特点三、易用性深度解读和示例代码四、多引擎支持深度解读和示例代码五、灵活性示…
AI智能电销机器人效果怎么样?呼叫部署
我们的生活早已变得无处不智能,从智能手机到无人车、虚拟VR到智能家居,你迎接的每一个清晨、享受的每一个夜晚,可能都离不开智能设备的服务。 工作中,智能化产业也正在影响着企业,电销机器人正在帮助各大企业获得更高的…
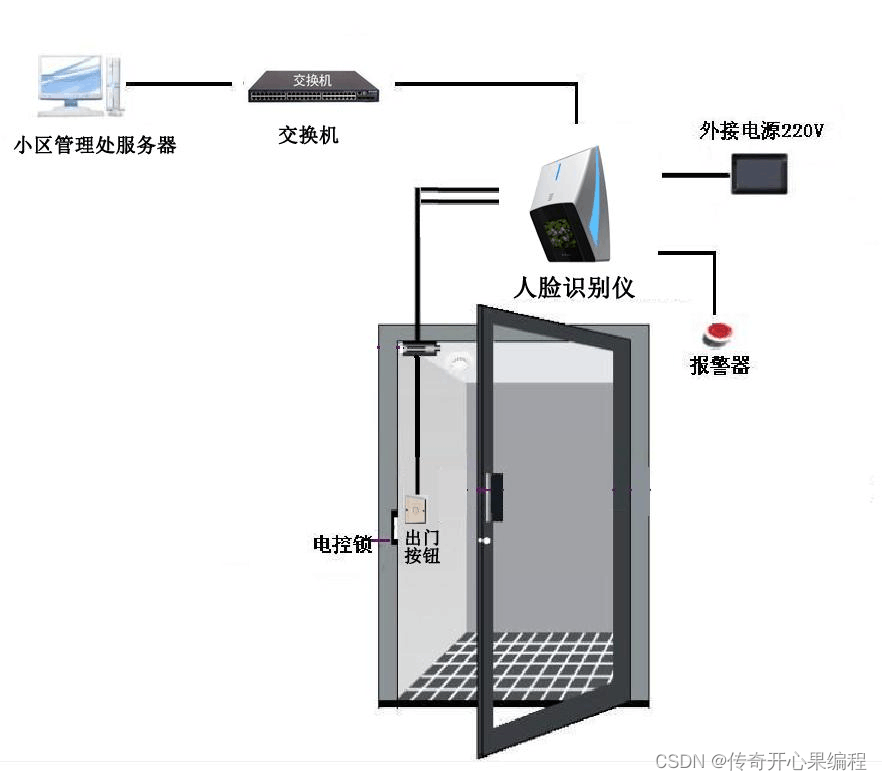
第十三篇【传奇开心果系列】Python的文本和语音相互转换库技术点案例示例:Microsoft Azure的Face API开发人脸识别门禁系统经典案例
传奇开心果博文系列 系列博文目录Python的文本和语音相互转换库技术点案例示例系列 博文目录前言一、实现步骤和雏形示例代码二、扩展思路介绍三、活体检测深度解读和示例代码四、人脸注册和管理示例代码五、实时监控和报警示例代码六、多因素认证示例代码七、访客管理示例代码…
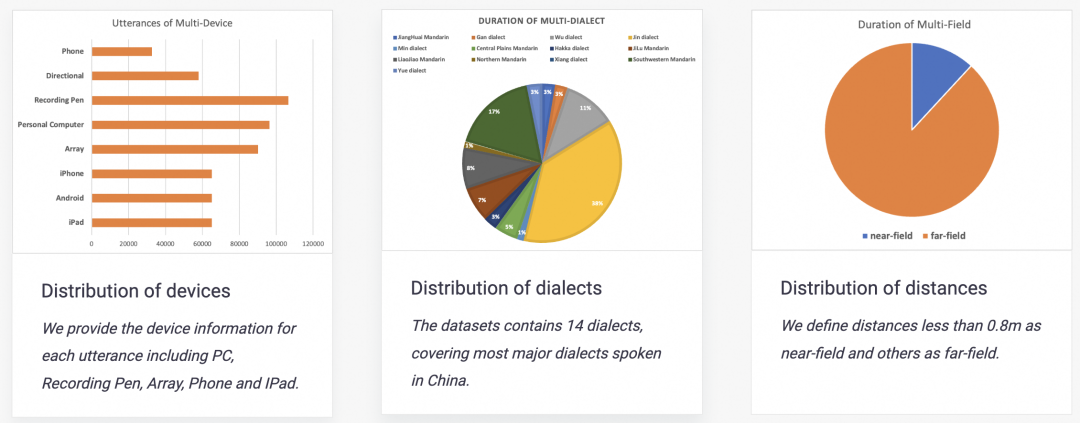
多模态说话人开源项目3D-Speaker
3D-Speaker是通义实验室语音团队贡献的一个结合了声学、语义、视觉三维模态信息来解决说话人任务的开源项目。本项目涵盖说话人日志,说话人识别和语种识别任务,开源了多个任务的工业级模型,训练代码和推理代码。
本项目同时还开源了相应的研…

评测本地部署的语音识别模型
1 引言
最近,朋友给我发来了一段音频,想转录成文字,并使用大型润色文本。音频中的普通话带有一定的口音,并且讲解内容较为专业,所以一般的语音识别工具很难达到较高的识别率。
于是试用了两个大模型。Whisper 是目前…

新书速览|PyTorch语音识别实战(人工智能技术丛书)
实战语音唤醒、音频特征抽取、语音情绪分类、Whisper语音转换、鸟叫多标签分类、多模态语音文字转换 01
本书内容 《PyTorch语音识别实战》使用PyTorch 2.0作为语音识别的基本框架,循序渐进地引导读者从搭建环境开始,逐步深入到语音识别基本理论、算法以…
Linux安装Whisper-Jax
博客 如需私有化部署欢迎咨询,包含whisper,whisper jax,faster whisper。
一、前提条件
ubuntu 20.04
python 3.9
cuda 11.8
nvidia-cublas-cu11 11.11.3.6
nvidia-cuda-cupti-cu11 11.8.87
nvidia-cuda-nvcc-cu11 11.8.89
nvidia-cuda-nvrtc-cu11 1…
开源(且支持中文)离线语音识别(语音转文本)工具or类库整理
开源(且支持中文)离线语音识别(语音转文本)工具or类库整理
open ai 的开源工具:whisper
whisper介绍
Open AI在2022年9月21日开源了号称其英文语音辨识能力已达到人类水准的Whisper神经网络,且它亦支持其它98种语言的自动语音辨识。 Whisper系统所提供…
【AudioPolicy To AudioHAL笔记(二)】AudioPolicyAudioFliger To AudioHAL
/*****************************************************************************************************************/
声明: 本博客内容均由https://blog.csdn.net/weixin_47702410原创,转载or引用请注明出处,谢谢!
创作不易,如果文章…
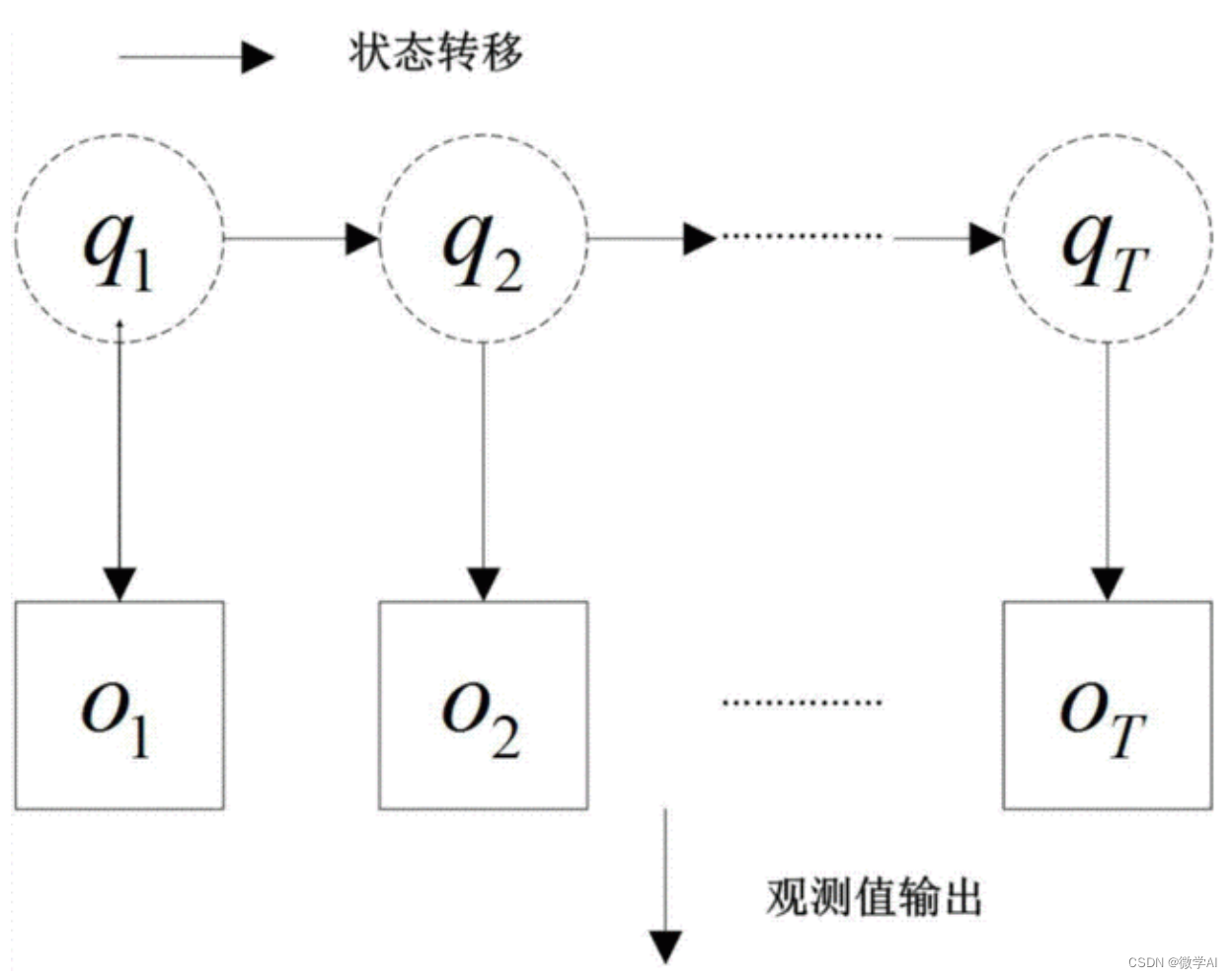
人工智能基础部分17-隐马尔科夫模型在序列问题的应用
大家好,我是微学AI,今天给大家介绍一下人工智能基础部分16-隐马尔科夫模型在序列问题的应用,隐马尔可夫模型(HMM)是一种统计模型,广泛应用于各种领域,如语音识别、自然语言处理、生物信息学等。本文将介绍隐马尔可夫模…
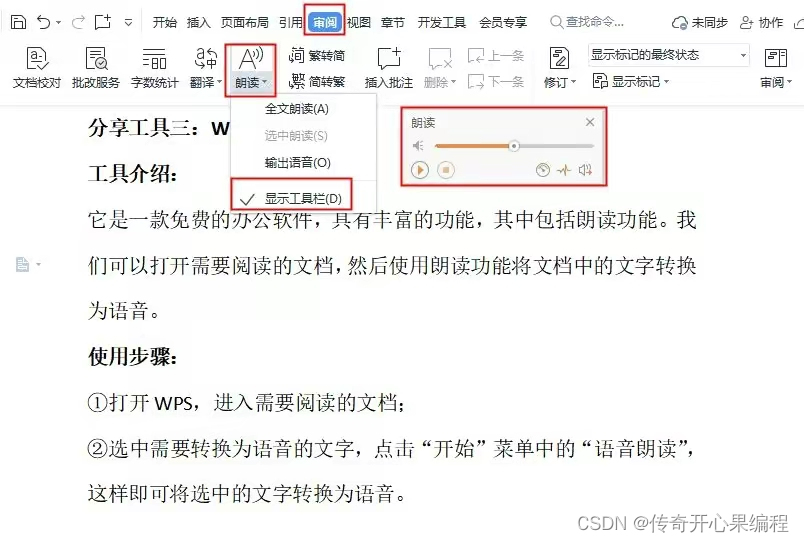
第二篇【传奇开心果系列】Python的文本和语音相互转换库技术点案例示例:深度解读pyttsx3支持多种语音引擎
传奇开心果短博文系列 系列短博文目录Python的文本和语音相互转换库技术点案例示例系列 短博文目录前言一、三种语音引擎支持介绍和示例代码二、SAPI5引擎适用场景介绍和示例代码三、nsss引擎适用场景介绍和示例代码四、eSpeak适用场景介绍和示例代码五、归纳总结 系列短博文目…

什么样的蓝牙耳机佩戴舒适?蓝牙耳机佩戴舒适度排名
越来越多的人开始使用运动蓝牙耳机了,不仅仅是因为蓝牙耳机的它无耳机线的束缚,日常还很便携,市面上的蓝牙耳机质量参差不齐,有些佩戴舒适度也比较差,下面整理了几款评分还不错的几款蓝牙耳机。
一、南卡小音舱Lite2蓝…

语音识别入门——常用软件及python运用
工具以及使用到的库
ffmpegsoxaudacitypydubscipylibrosapyAudioAnalysisplotly 本文分为两个部分:
P1:如何使用ffmpeg和sox处理音频文件 P2:如何编程处理音频文件并执行基本处理 P1 处理语音数据——命令行方式 格式转换
ffmpeg -i video…
【阿里云】图像识别 智能分类识别 增加网络控制功能点(三)
一、增加网络控制功能
实现需求TCP 心跳机制解决Soket异常断开问题
二、Linux内核提供了通过sysctl命令查看和配置TCP KeepAlive参数的方法。
查看当前系统的TCP KeepAlive参数修改TCP KeepAlive参数
三、C语言实现TCP KeepAlive功能 四、setsockopt用于设置套接字选项的系…
吉他初学者学习网站搭建系列(3)——如何实现吉他在线调音
文章目录 背景知识teoriapitchytone效果 背景知识
学过初中物理就会知道,声音是由空气振动产生的。振动产生波,所以声音就是不同振幅和频率的波构成的。振幅决定了声音的响度,频率决定了声音的音高。想更进一步了解的可以访问这个网页wavefo…

NV040C语音芯片:让自助ATM机使用更加安全快捷
近年来,移动支付方式的兴起、银行加强线上化服务、数字人民币项目推进等因素的影响,人们使用ATM机的频率呈现小幅度的下降趋势。然而,自助ATM机并未从我们的视野中消失,它们仍然在金融领域发挥着重要的作用。未来,ATM机…

vue使用WEB自带TTS实现语音文字互转
前言
时隔多日,自己已经好久没更新文章了;今年一直跟随公司的政策[BEI YA ZHA]中,做了一个又一个的需求,反而没有多少自己的时间,更别说突破自己 ˚‧(˚ ˃̣̣̥᷄⌓˂̣̣̥᷅ )‧˚(雾) 然…
不会代码(零基础)学语音开发
目录
为什么要学习语音开发,有什么优势,未来前景怎么样?
学习语音开发应该掌握哪些技能
有必要从最底层学起么?
新手如何选择语音开发板 为什么要学习语音开发,有什么优势,未来前景怎么样? …
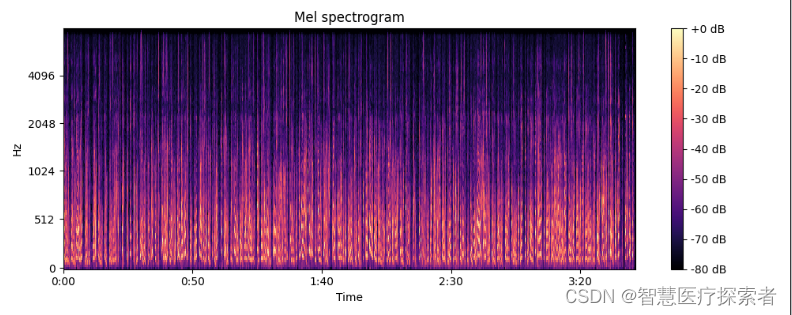
语音信号处理:librosa
1 librosa介绍
Librosa是一个用于音频和音乐分析的Python库,专为音乐信息检索(Music Information Retrieval,MIR)社区设计。自从2015年首次发布以来,Librosa已成为音频分析和处理领域中最受欢迎的工具之一。它提供了一…
2017年上半年上午易错题(软件设计师考试)
CPU 执行算术运算或者逻辑运算时,常将源操作数和结果暂存在( )中。 A . 程序计数器 (PC) B. 累加器 (AC) C. 指令寄存器 (IR) D. 地址寄存器 (AR) 某系统由下图所示的冗余部件构成。若每个部件的千小时可靠度都为 R &…
【AI】【工具】五个推荐的AI视频制作工具
【详细视频介绍】
https://www.bilibili.com/video/BV1aH4y11752/
【DESCRIPT】
直接在线使用 用修改文档的方法来编辑视频。 导入视音频文件后Descript会生成相应的描述文档,通过修改此文档你就可以实时获得修改后的视频和音频。 自动加字幕当然也很方便。 还带…
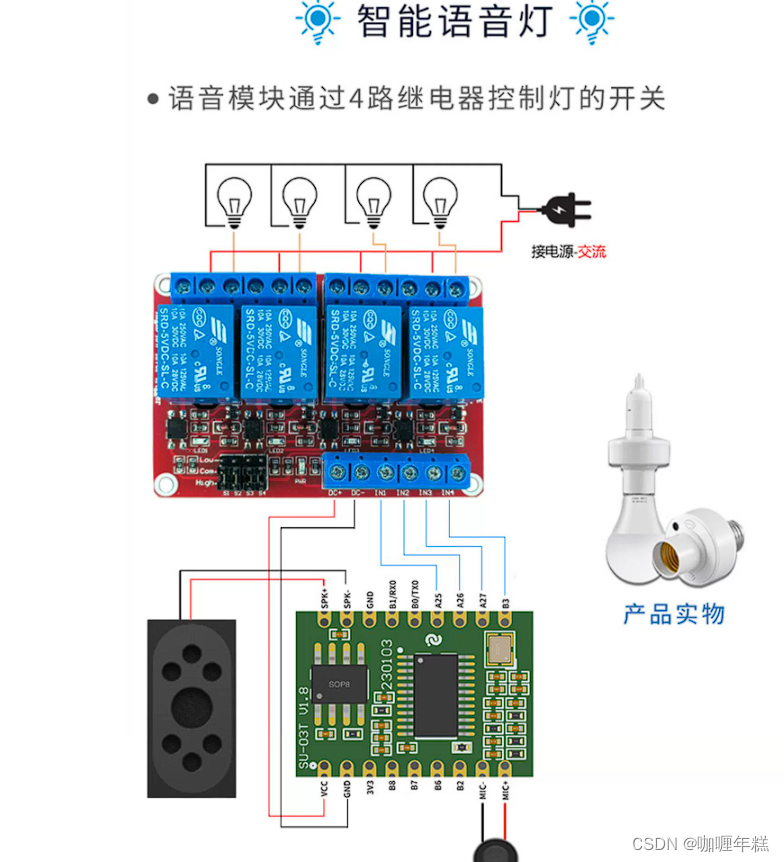
【智能家居】三、添加语音识别模块的串口读取功能点
语音识别模块SU-03T 串口通信线程控制代码
inputCommand.h(输入控制指令)voiceControl.c(语音控制模块指令)main.c(主函数)编译运行结果
语音识别模块SU-03T
AI智能语音识别模块离线语音控制模块语音识别…
基础课14——语音识别
ASR 是自动语音识别(Automatic Speech Recognition)的缩写,是一种将人类语音转换为文本的技术。ASR 系统可以处理实时音频流或已录制的音频文件,并将其转换为文本。它是一种自然语言处理技术,广泛应用于许多领域&#…
数字信号处理、语音信号处理、现代信号处理
推荐他的博客: 手撕《数字信号处理》——通俗易懂的数字信号处理章节详解集合 手撕《语音信号处理》——通俗易懂的语音信号处理章节详解集合 手撕《现代信号处理》——通俗易懂的现代信号处理章节详解集合

方言翻译APP小程序开发具备哪些功能?
我国语言文华博大精深,很多地方都有着民族特色方言,在当地很盛行但是外地人听不懂也不会说,这就給沟通造成了一定的困扰。方言翻译APP软件是专门针对地方性方言开发的一款系统软件,提供全国各地方言翻译功能,一键在线就…
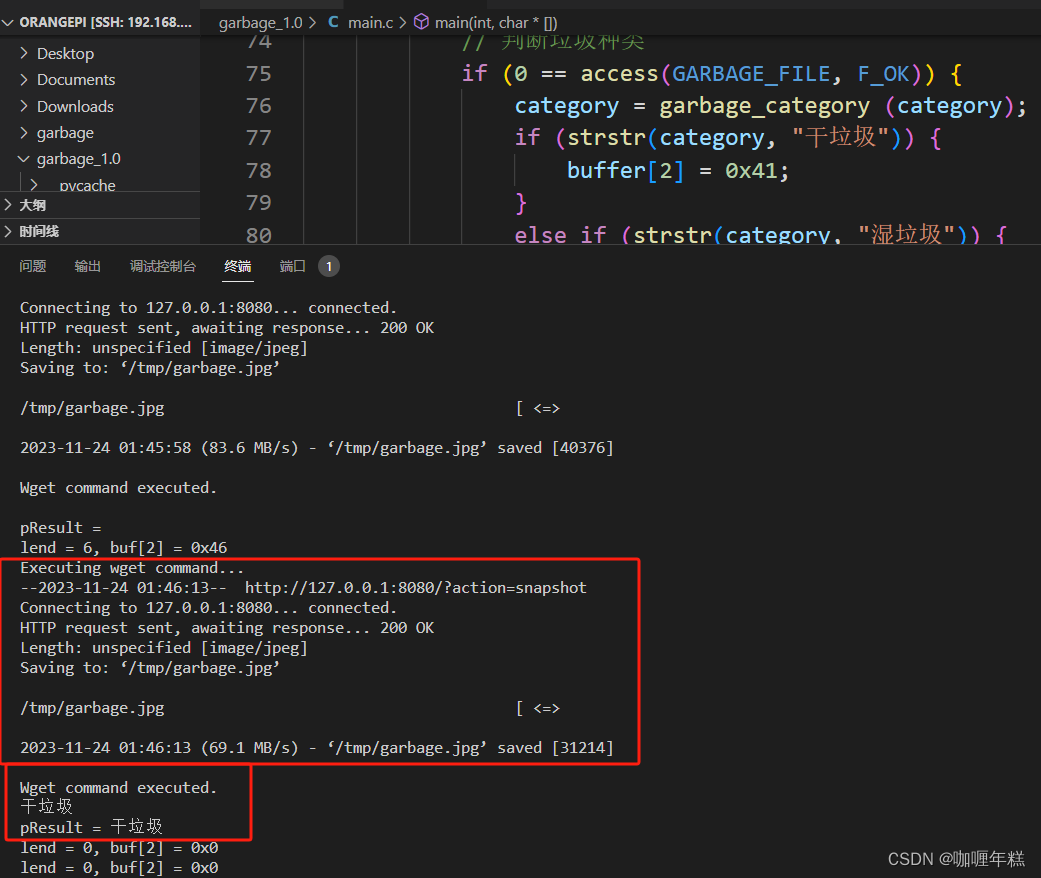
【阿里云】图像识别 智能分类识别 项目开发(一)
语音模块和阿里云图像识别结合 环境准备 代码实现 编译运行 写个shell脚本用于杀死运行的进程
语音模块和阿里云图像识别结合
使用语音模块和摄像头在香橙派上做垃圾智能分类识别 语音控制摄像下载上传阿里云解析功能点实现
环境准备 将语音模块接在UART5的位置 在orange…
人工神经网络算法的应用,网络神经算法的应用
深度神经网络算法用什么软件处理
微软介绍,这种新型语音识别软件采用了名为“深度神经网络”的技术,使得该软件处理人类语音的过程与人脑相似。
对此微软必应(Bing)搜索业务部门主管斯特凡维茨(StefanWeitz)在本周一表示:“我们试图复制人脑…
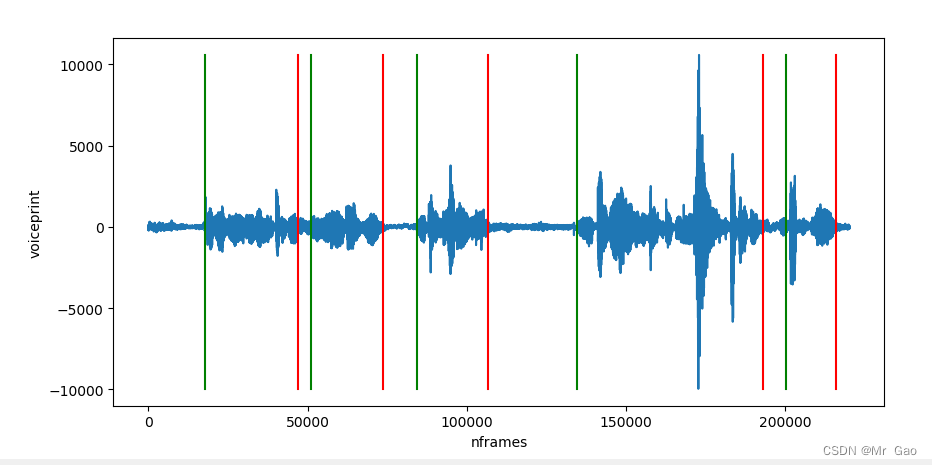
python pyaudio对音频进行端点检测,检测出说话区间
python pyaudio对音频进行端点检测,检测出说话区间
主要采用过零率和语音能量来进行检测,并设置双阈值。 代码如下:
# -*- coding: utf-8 -*-
import wave
import os
import matplotlib.pyplot as plt
import numpy as np# 判断是否变号
de…
人工智能-语音识别技术paddlespeech的搭建和使用
PaddleSpeech 介绍
PaddleSpeech是百度飞桨(PaddlePaddle)开源深度学习平台的其中一个项目,它基于飞桨的语音方向模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。PaddleSpe…
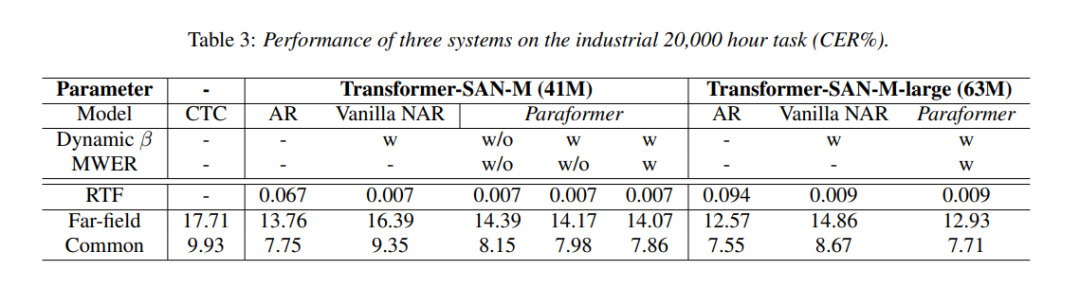
细数语音识别中的几个former
随着Transformer在人工智能领域掀起了一轮技术革命,越来越多的领域开始使用基于Transformer的网络结构。目前在语音识别领域中,Tranformer已经取代了传统ASR建模方式。近几年关于ASR的研究工作很多都是基于Transformer的改进,本文将介绍其中应…

你是否会被人工智能哭泣的声音所打动?| Mixlab 技术前沿
#音频工程#、#AI语音技术#、#AI Deepfake#AI 语音—— 语音识别技术,与语音合成语音识别技术是指机器自动将人的语音,转成文字的技术,即ASR技术:Automatic Speech Recognition。语音合成是计算机将机器内部的文字信息转变为&#…
最新AI系统ChatGPT网站H5系统源码,支持Midjourney绘画局部编辑重绘,GPT语音对话+ChatFile文档对话总结+DALL-E3文生图
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧。已支持GPT…

基于百度语音识别API智能语音识别和字幕推荐系统——深度学习算法应用(含全部工程源码)+测试数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理2. 翻译3. 格式转换4. 音频切割5. 语音识别6. 文本切割7. main函数 系统测试工程源代码下载其它资料下载 前言
本项目基于百度语音识别API,结合了语音识别、视频转换音频识别以及语句停顿…
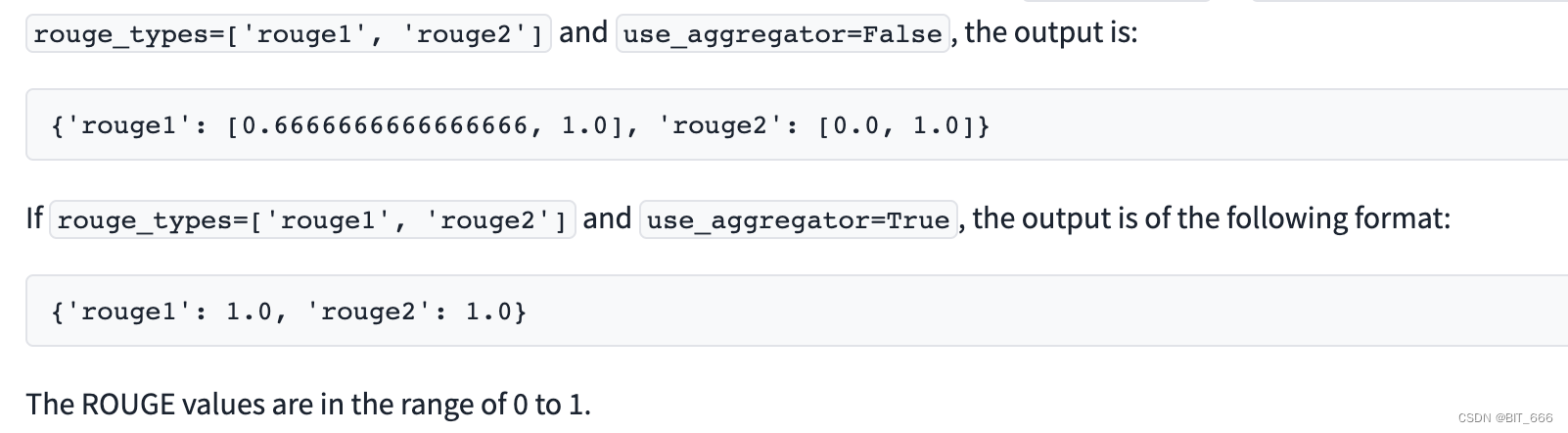
LLM - 大模型评估指标之 ROUGE
目录
一.引言
二.ROUGE-简介
1.ROUGE-N
2.ROUGE-L
3.ROUGE-W
4.ROUGE-S
三.ROUGE-实现
1.How To Use
2.Inputs
3.Outputs
四.总结 一.引言
ROUGE 代表面向召回的研究,用于 Gisting 评估。它包括通过将摘要与人类创建的其他摘要进行比较来自动确定摘要质…
一键搭讪以及打招呼设置(swift)
项目描述:用户通过打招呼设置录制打招呼语音,添加打招呼文字,首页feed页面展示sayhi的小动画,点开可查看将要搭讪的列表,选择想要搭讪的用户以及搭讪的文字和语音,也可随机选择文案、语音,未通过…

ai语音机器人接听自动外呼配置
一,添加能转接到机器人的拨号方案
{cti_robot_flow_exists({destination_number})} 这是判断路由条件设置的机器人话术是否存在
cti_robot ${destination_number} 启动机器人流程
set park_timeout3600 设置park最大的时间,机器人和用户最大的通话时间…
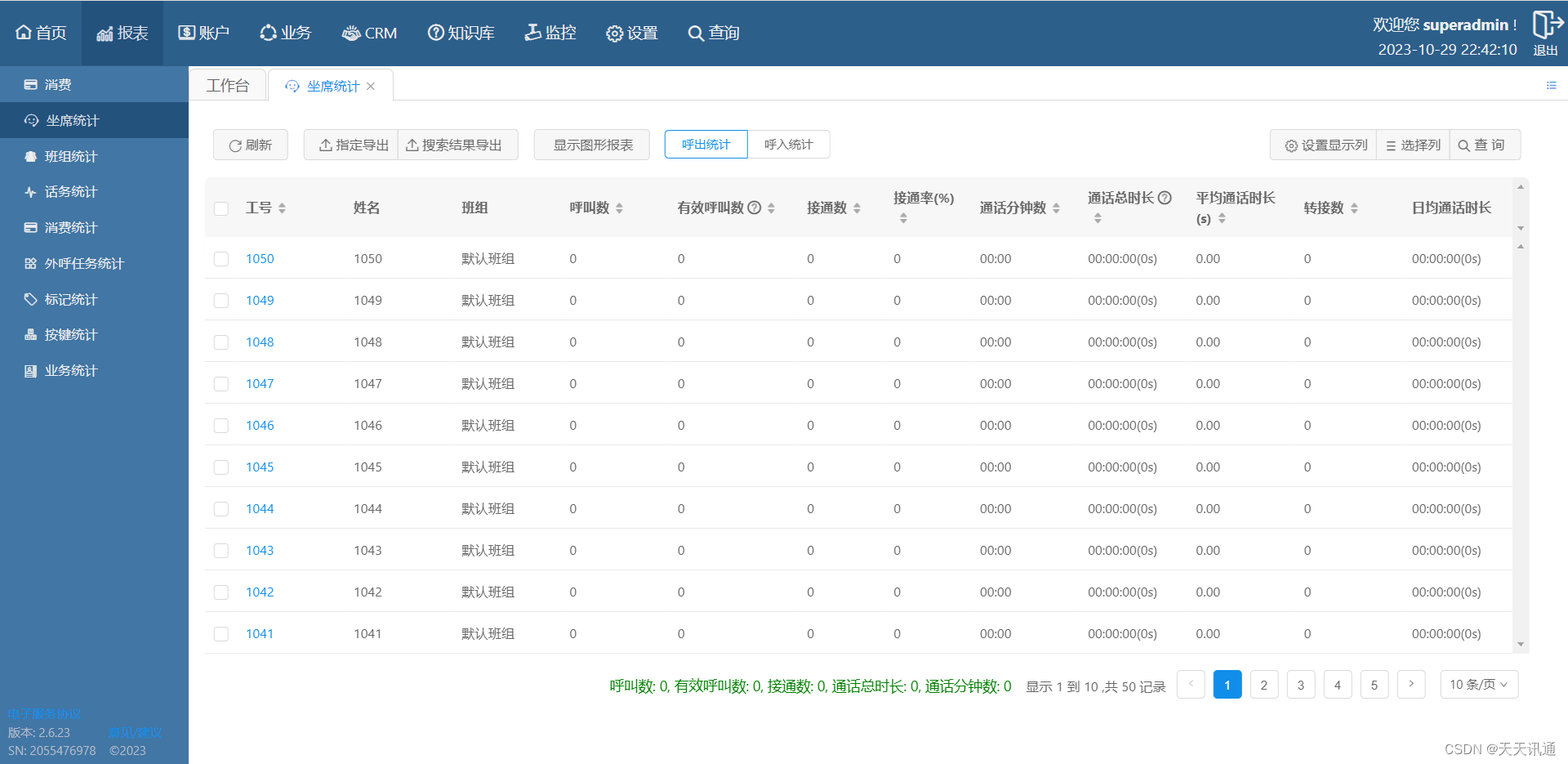
呼叫系统的客服的计费模式有哪些?
大家都已经了解呼叫总的区分为两种呼入和呼出。呼入就是建立客服呼叫中心,呼出就是电销回访外呼中心。那么相应的计费模式也是有不同的。下面看看以下几种收费模式 : 一、按月收费模式 也叫固定客服模式,是根据上月结算的费用,企业…

智安网络|语音识别技术:从历史到现状与未来展望
语音识别技术是一种将语音信号转化为可识别的文本或命令的技术,近年来得到了广泛应用和关注。
一. 语音识别的发展现状
1.历史发展 语音识别技术的起源可以追溯到20世纪50年代,但直到近年来取得了显著的突破和进展。随着计算机性能的提升和深度学习算法…
Athena-signa开源语音信号处理算法源码介绍
Athena-signa开源语音信号处理算法源码介绍 是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,+群赠送蓝牙耳机音频,车载DSP音频项目核心开发资料, Athena-signal是一个开源的语音信号处理算法库。 它旨在帮助希望…
基于Jupyter Notebook 深度学习神经网络开发方法
基于Jupyter Notebook 深度学习神经网络开发方法
是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,+群赠送基于深度学习语音信号处理算法相关技术课程资料, Jupyter Notebook 介绍? Jupyter Notebook 是一个开源的…
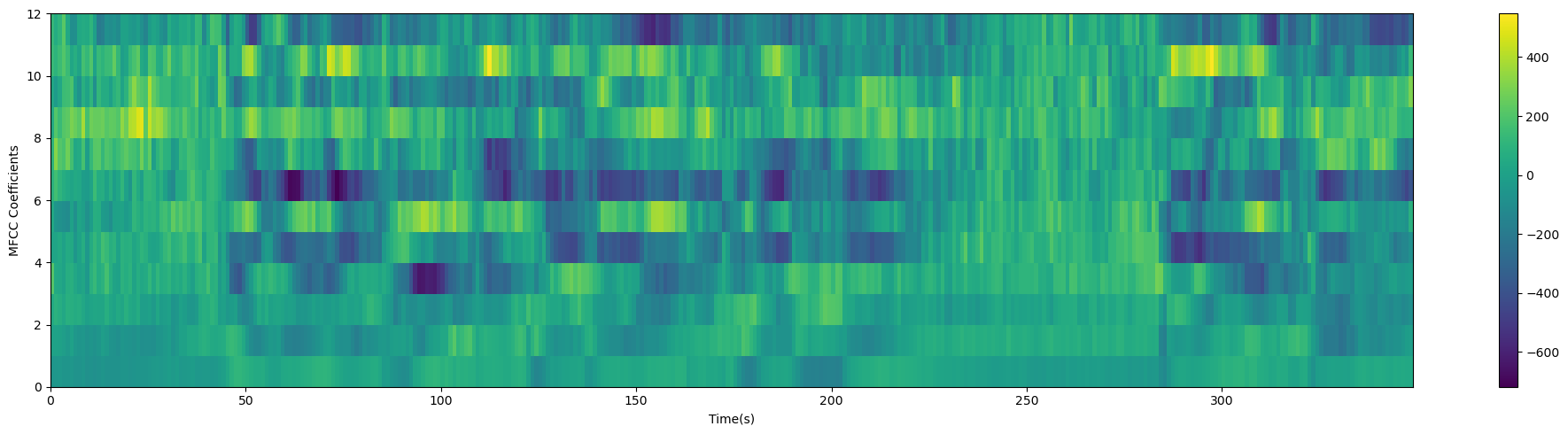
语音识别从入门到精通——1-基本原理解释
文章目录 语音识别算法1. 语音识别简介1.1 **语音识别**1.1.1 自动语音识别1.1.2 应用 1.2 语音识别流程1.2.1 预处理1.2.2 语音检测和断句1.2.3 音频场景分析1.2.4 识别引擎(**语音识别的模型**)1. 传统语音识别模型2. 端到端的语音识别模型基于Transformer的ASR模型基于CNN的…
会声会影2024永久汉化中文版本百度网盘下载
会声会影2024破解版免费下载是经过修改的视频剪辑软件,它能够免费为您提供很多功能。会声会影2024免费下载提供超过 1500 种独特的效果,可让您提升自我。会声会影破解版是用于是制作独一无二的视频的最强大、功能最全的软件。 它是一个简单而快速的视频编…

楼宇对讲、可视门铃案例分析
语音通话芯片:D34018,D34118,D5020,D31101;
D34018 单片电话机通话电路,合并了必 需的放大器、衰减器和几种控制 功能,包括发送和接收衰减器、 背景噪声电平检测系统和一个衰 减器控制系统,对发送和接收电 平好于背景噪声做出反…
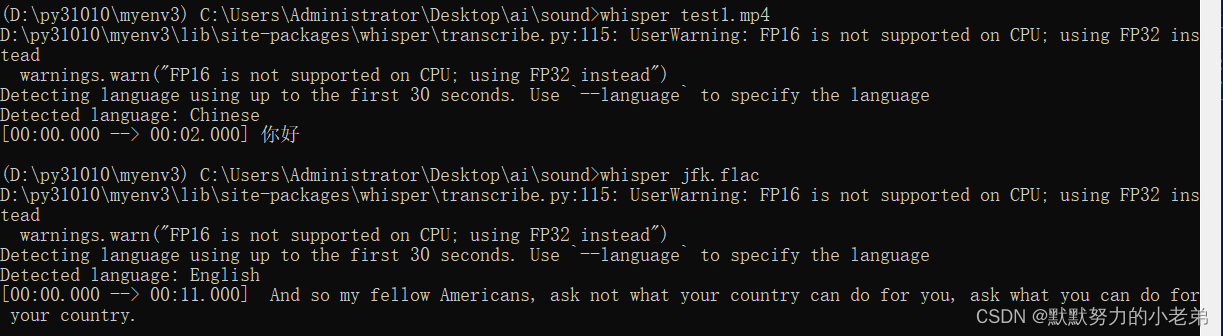
语音识别之百度语音试用和OpenAiGPT开源Whisper使用
0.前言: 本文作者亲自使用了百度云语音识别,腾讯云,java的SpeechRecognition语言识别包 和OpenAI近期免费开源的语言识别Whisper(真香警告)介绍了常见的语言识别实现原理
1.NLP 自然语言处理(人类语言处理) 你好不同人说出来是不同的信号表示 单位k 16k16000个数字表示 1秒160…

WebDAV之π-Disk派盘 + Keepass2Android
推荐一款密码管理器,允许人们使用复杂的组合进行登录,而不必记住所有的组合。
Keepass2Android可以支持大多数安卓互联网浏览器, Android设备上同步软件,还支持通过WebDAV添加葫芦儿派盘。 Keepass2Android 目前安全方面最大的问题之一是大多数人几乎在任何地方都使用通用…
AI创作系统ChatGPT商业运营网站系统源码,支持AI绘画,GPT语音对话+DALL-E3文生图
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…
会声会影2024软件还包含了视频教学以及模板素材
会声会影2024中文版是一款加拿大公司Corel发布的视频编软件。会声会影2024官方版支持视频合并、剪辑、屏幕录制、光盘制作、添加特效、字幕和配音等功能,用户可以快速上手。会声会影2024软件还包含了视频教学以及模板素材,让用户剪辑视频更加的轻松。 会…
Python办公自动化 – 语音识别和文本到语音的转换
Python办公自动化 – 对图片处理和文件的加密解密
以下是往期的文章目录,需要可以查看哦。 Python办公自动化 – Excel和Word的操作运用 Python办公自动化 – Python发送电子邮件和Outlook的集成 Python办公自动化 – 对PDF文档和PPT文档的处理 Python办公自动化 –…
Android开发中实时语音开发之华为实时语音识别
上一篇(Android开发中,百度语音集成之一)简单的讲解了百度语音的识别,今天讲解一个华为的语音识别: 1.初始化: initRecognizer()mSpeechRecognizer MLAsrRecognizer.createAsrRecognizer(context)
mSpeechRecognizer.setAsrListener(SpeechR…

人工智能助力重度瘫痪女性重新获得发声能力
原创 | 文 BFT机器人 01
创新技术:用于解码大脑信号的脑机接口(Brain-Computer Interface,BCI) 加州大学旧金山分校和加州大学伯克利分校的研究人员开发了一种脑机接口(BCI),成功地让一名因脑…
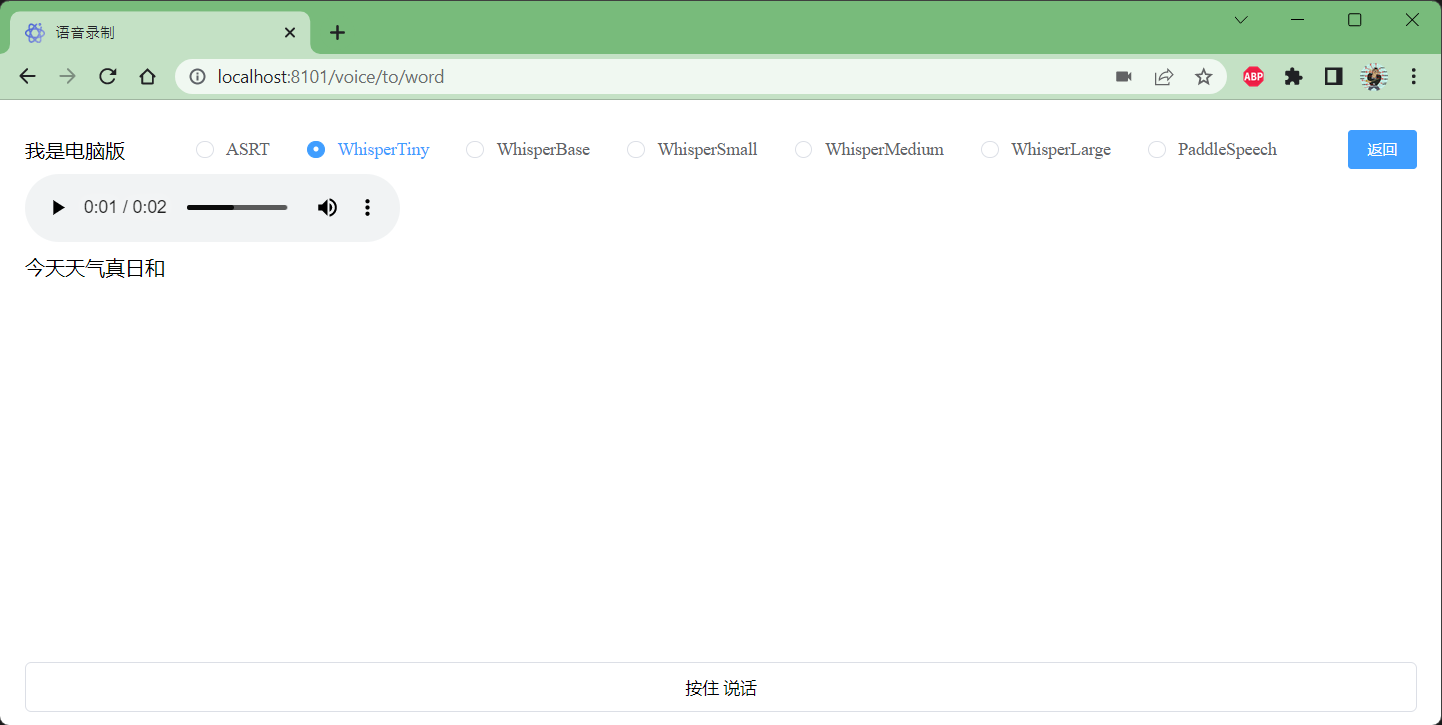
.Net 使用OpenAI开源语音识别模型Whisper
.Net 使用OpenAI开源语音识别模型 Whisper
前言
Open AI在2022年9月21日开源了号称其英文语音辨识能力已达到人类水准的 Whisper 神经网络,且它亦支持其它98种语言的自动语音辨识。 Whisper系统所提供的自动语音辨识(Automatic Speech Recognition&…

OpenAI的人工智能语音识别模型Whisper详解及使用
1 whisper介绍 拥有ChatGPT语言模型的OpenAI公司,开源了 Whisper 自动语音识别系统,OpenAI 强调 Whisper 的语音识别能力已达到人类水准。 Whisper是一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练,能够在…
App Inventor 2 语音交互机器人Robot,使用讯飞语音识别引擎
应用介绍
App Inventor 2 语音识别及交互App。识别语言指令并控制机器人运动,主要用到语音识别器及文本朗读器组件,语音识别相关开发最佳入门。代码逻辑简单,App交互性及趣味性非常强~ 视频预览
语音Robot教程(难度系数…
污染信号频谱分析模块程序
[y,fs,nbits]wavread(OriSound.wav); % 语音信号采集 sound(y,fs,nbits); % 回放语音信号便于比较效果 n length (y) ; % 计算语音信号长度 Noise0.2*randn(n,1); % 产生随机噪声信号 Noise syNoise; % 将 Noise 添加到原始信号,得到污 染信号 s so…
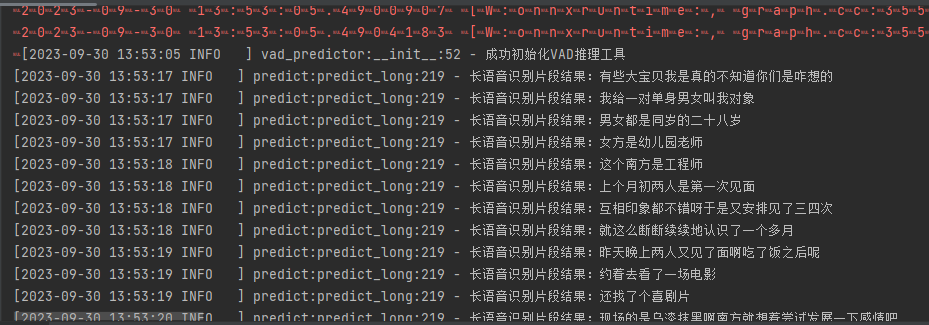
一键智能视频语音转文本——基于PaddlePaddle语音识别与Python轻松提取视频语音并生成文案
前言
如今进行入自媒体行业的人越来越多,短视频也逐渐成为了主流,但好多时候是想如何把视频里面的语音转成文字,比如,录制会议视频后,做会议纪要;比如,网课教程视频,想要做笔记&…

Android学习之路(17) Android Adapter详解
Adapter基础讲解
本节引言
从本节开始我们要讲的UI控件都是跟Adapter(适配器)打交道的,了解并学会使用这个Adapter很重要, Adapter是用来帮助填充数据的中间桥梁,简单点说就是:将各种数据以合适的形式显示到view上,提供 给用户看…

景联文科技语音数据标注:AUTO-AVSR模型和数据助力视听语音识别
ASR、VSR和AV-ASR的性能提高很大程度上归功于更大的模型和训练数据集的使用。 更大的模型具有更多的参数和更强大的表示能力,能够捕获到更多的语言特征和上下文信息,从而提高识别准确性;更大的训练集也能带来更好的性能,更多的数据…
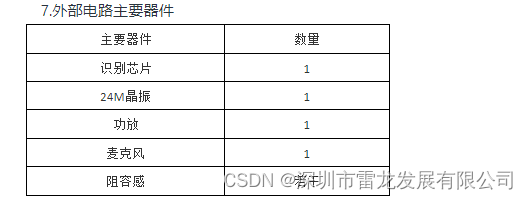
思必驰:离线语音识别芯片简介
一.使用场景 夏天某个凉爽的早晨,当你躺在床上玩着手机,突然一阵困意袭来,原来已经中午了,此时你一个侧身准备休息,突然发现一阵酷热袭来,你定睛一看,原来是风扇没有打开,…

1024 CSDN 程序员节-知存科技-基于存内计算芯片开发板验证语音识别
前言
在今年的 CSDN 程序员节上,我参与了这次知存科技举办的一个 AI Workshop 小活动——“基于存内计算芯片开发板验证语音识别”,并且有幸成为完成任务的学习者之一XD。上一次参与类似的活动是算能公司举办的“千校万里行”AIGC 大模型编译部署活动&a…

支小蜜校园防霸凌系统的具体功能是什么?
在当今社会,校园霸凌问题日益严重,成为影响学生健康成长的一大隐患。为了应对这一问题,许多学校开始引入校园防霸凌系统。这一系统以其独特的功能,为校园安全提供了有力保障,为学生的健康成长创造了良好环境。
校园防…
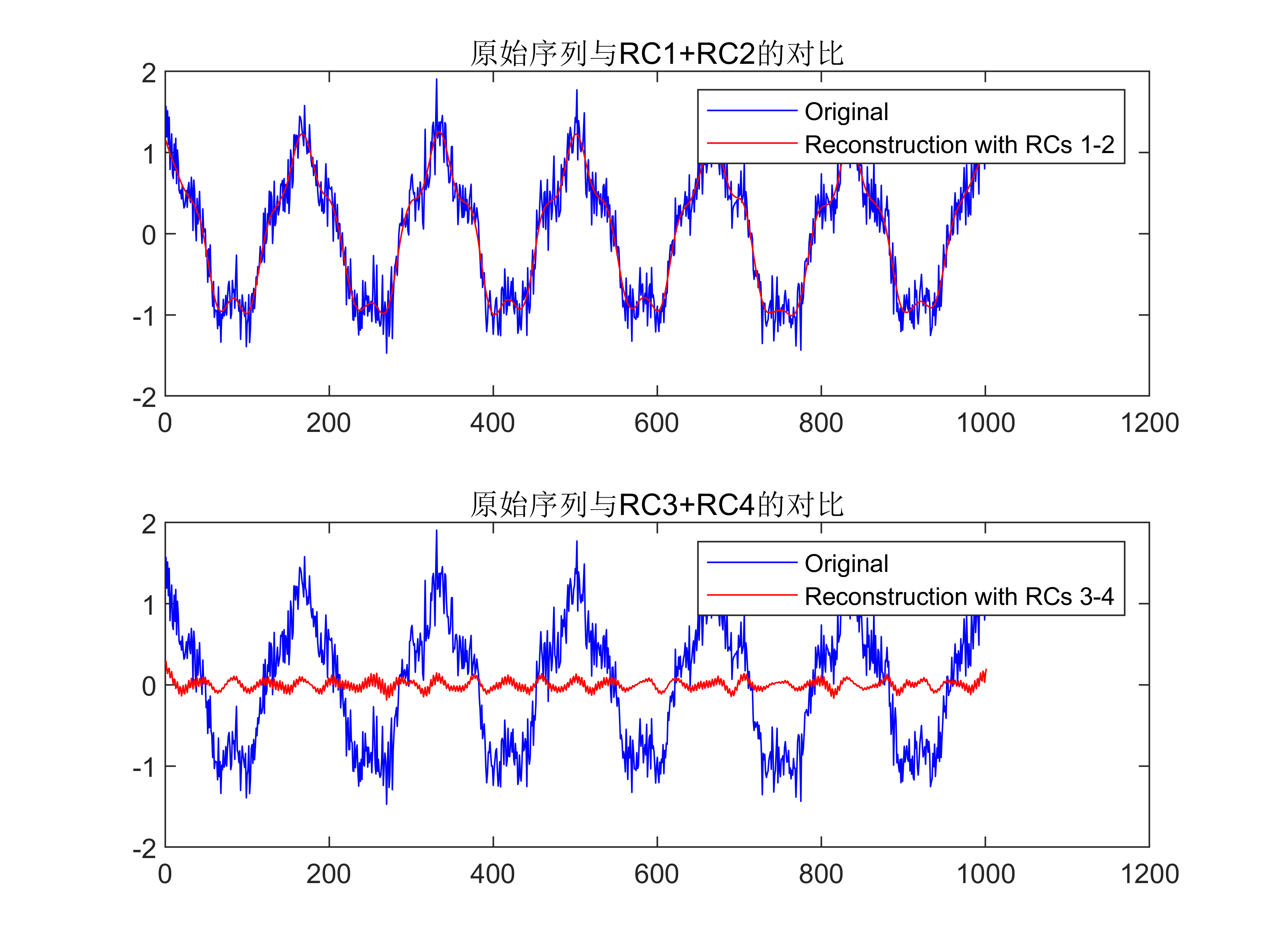
【MATLAB】SSA+FFT+HHT组合算法
有意向获取代码,请转文末观看代码获取方式~也可转原文链接获取~
1 基本定义
SSAFFTHHT组合算法是一种基于奇异谱分析(SSA)、快速傅里叶变换(FFT)和希尔伯特-黄变换(HHT)的组合算法。
其中&am…
最新AI创作系统ChatGPT系统源码+DALL-E3文生图+AI绘画+GPT语音对话功能
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…

OTP语音芯片 NV080D在智能空气检测仪的应用
随着人们对健康和环保的关注度不断提高,人们对看不见的家居环境也越来越重视。智能空气检测仪的市场需求也在不断增长中,呈现稳中向好的趋势。智能空气检测仪能够检测室内空气中的PM2.5、甲醛、TVOC等有害物质,同时还可以检测温湿度、空气质量…
基础课5——语音合成技术
TTS是语音合成技术的简称,也称为文语转换或语音到文本。它是指将文本转换为语音信号,并通过语音合成器生成可听的语音。TTS技术可以用于多种应用,例如智能语音助手、语音邮件、语音新闻、有声读物等。
TTS技术通常包括以下步骤: …

楼宇对讲门铃的芯片选型分析
目前很多的高层住宅都使用了对讲门铃了,在频繁使用中,门铃会出现的越来越多种类,下面我就简单的介绍会有用到的几款芯片.
语音通话芯片:D34018,D34118,D5020,D31101; D34018 单片电话机通话电路,合并了必 需的放大器…
开源语音识别faster-whisper部署教程
1. 资源下载
源码地址
模型下载地址:
large-v3模型:https://huggingface.co/Systran/faster-whisper-large-v3/tree/main
large-v2模型:https://huggingface.co/guillaumekln/faster-whisper-large-v2/tree/main
large-v2模型:…
唯创知音WTK6900H语音识别芯片:引领语音控制IC技术新标杆
随着人工智能和物联网的飞速发展,语音识别技术已成为人机交互的重要方式。在这个背景下,唯创知音的WTK6900H语音识别芯片应运而生,凭借其在语音技术上的卓越性能,为行业树立了新的标杆。
一、高可靠的唤醒识别率
WTK6900H语音识…
如何使用 Rask AI 进行视频本地化
链接:
Login or Sign up
Rask AI 是一个提供视频本地化服务的平台,支持 60 多种语言。该服务的主要功能包括:
VoiceClone:利用 AI 生成来自原始影片发言人的语音,让你可以将其用作全球范围内品牌形象的一部分。Mul…
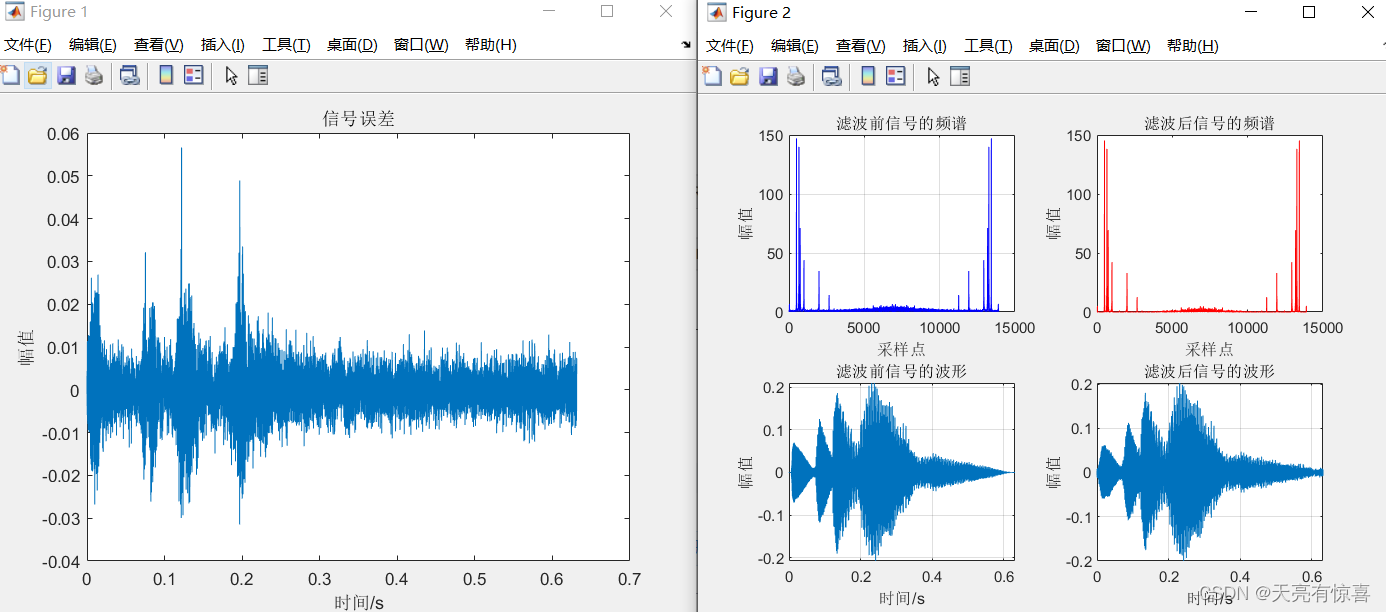
MATLAB语音去噪系统
目录
一、背景
二、GUI页面
三、程序
3.1 LMS滤波程序
3.2 GUI程序
四、附录 一、背景 本文介绍了一种最佳的自适应滤波器结构,该结构采用最小均方差(LMS)作为判据,通过不断迭代自适应结构来调整得到最佳滤波器…

一、OpenAI API介绍
Open AI API可以应用到任何的业务场景。 文本生成 创造助理 嵌入数据 语音转化 图片生成 图片输入
1. 核心概念
1.1 Text generation models
OpenAI 的文本生成模型(通常被称为generative pre-trained transformers 模型简称:GPT),有GPT-4和G…
卫星为什么要挂在天上,而不放在地上?
经常有客户问我,30W调频广播发射机可覆盖多大半径、100W发射机可以覆盖多大半径,今天就无线电发射机的覆盖半径,给大家做一个科普性的讲解。 无线电信号的传输和多个因素都有关系,发射机有效功率、天线增益、天线高度、馈线损耗、…
语音识别与人机交互:发展历程、挑战与未来前景
导言 语音识别技术作为人机交互领域的重要组成部分,近年来取得了巨大的发展。本文将深入研究语音识别与人机交互的发展历程、遇到的问题、解决过程、未来的可用范围,以及在各国的应用和未来的研究趋势。我们将探讨在这个领域,哪一方能取得竞争…
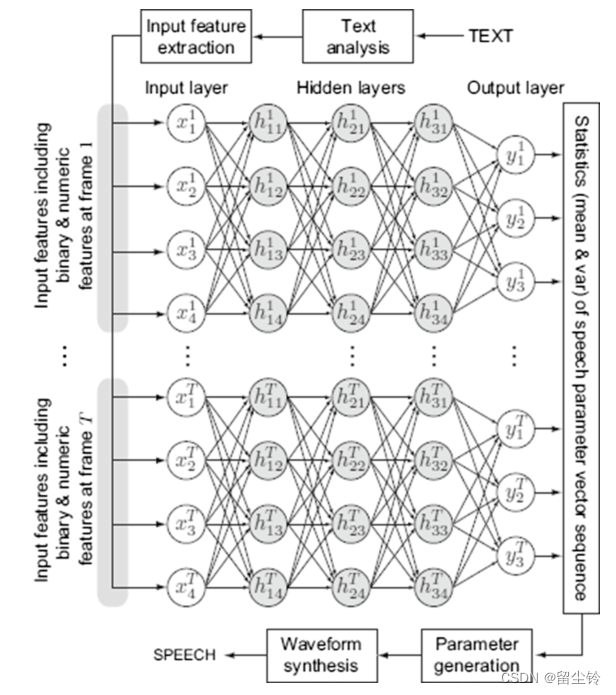
TTS 文本转语音模型综合简述
本文参考文献: [1] Kaur N, Singh P. Conventional and contemporary approaches used in text ot speech synthesis: A review[J]. Artificial Intelligence Review, 2023, 56(7): 5837-5880. [2] TTS | 一文了解语音合成经典论文/最新语音合成论文篇【20240111更新…
实时语音识别(Python+HTML实战)
项目下载地址:FunASR
1 安装库文件 项目提示所需要下载的库文件:pip install -U funasr 和 pip install modelscope 运行过程中,我发现还需要下载以下库文件才能正常运行: 下载:pip install websockets,pi…
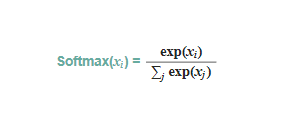
第四章:人工智能深度学习教程-激活函数(第三节-Pytorch 中的激活函数)
在本文中,我们将了解 PyTorch 激活函数。
目录
什么是激活函数以及为什么使用它们?
Pytorch 激活函数的类型
ReLU 激活函数:
Python3
Leaky ReLU 激活函数:
Python3
S 形激活函数:
Python3
Tanh 激活函数&am…

最新AI智能系统ChatGPT网站源码V6.3版本,GPTs、AI绘画、AI换脸、垫图混图+(SparkAi系统搭建部署教程文档)
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧。已支持GPT…
阿里云语音合成TTS nodejs sdk接入示例
npm i alicloud/pop-core -S实例化客户端
// 官方文档:SDK方式获取Token_智能语音交互(ISI)-阿里云帮助中心
const RPCClient require(alicloud/pop-core).RPCClient
const ttsClient new RPCClient({accessKeyId: xxx, // 阿里云申请accessKeySecret: xxx, // 阿…
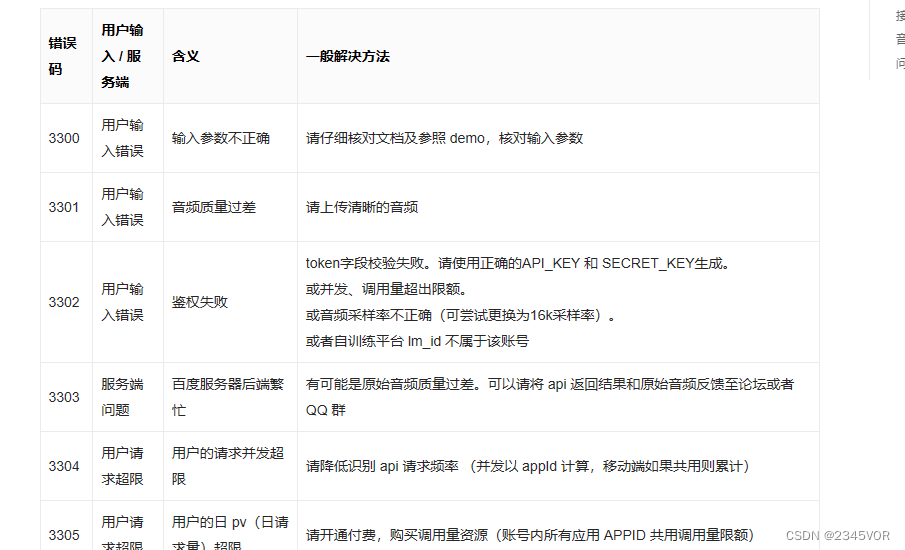
【ESP32S3 Sense接入语音识别+MiniMax模型+TTS模块语音播报】
【ESP32S3 Sense接入语音识别MiniMax模型TTS模块语音播报】 1. 前言2. 功能模块概述2.1 语音接入2.2 大模型接入2.3 TTS模块接入 3. 先决条件3.1 环境配置3.2 所需零件3.3 硬件连接步骤 4. 核心代码4.1 源码分享4.2 代码解析 5. 上传验证5.1 对话测试5.2 报错 6. 总结 1. 前言 …
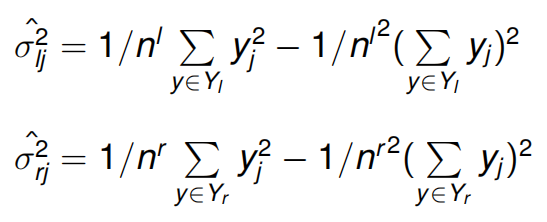
【语音识别】声学建模中基于树的状态绑定
01 基本想法
单音素HMM模型不能很好的应对自然说话人发音时的渐变过程,比如从一个音素转换到另一个音素时会存在协同发音现象。因此语音识别的先驱者提出了上下文建模概念,即使用中心音素(单因素)和前后两个音素组成三音素对每一…

基于Whisper的实时语音识别(1): 流式显示视频帧和音频帧
Whistream (微流)是基于openai-whisper 大语音模型下的流式语音识别工具
本期主要介绍实时显示工具Whishow,可以实时逐帧显示视频流(RTSP/RTMP)和离线文件(mp4,avi等)
下载地址:ht…
Python编程-带你制作实用工具-语音识别、音频转换、音频转文字、录音转Mp3、文字生成音频(附代码和源码)
目录
音频mp3、flac、wav、ogg格式转换
安装
批量执行
SpeechRecognition
安装
下载中文声学模型和语言模型
音频转文字
文字转语音
安装pyttsx3
Kaldi sherpa-ncnn 端侧语音识别
本文介绍一款基于新一代 Kaldi 的、超级容易安装的、实时语音识别 Python 包:sherpa-ncnn。 小编注: 它有可能是目前为止,最容易 安装的实时语音识 别 Python 包(谁试谁知道)。 它的使用方法也是极简单的。 安装
pip install sherpa-ncnn对的,就是这一句,所有的依赖都从…
智能语音机器人ai外呼机器人的运行原理和优势
在销售行业中,销售人员如果想尽可能的多获得客户,就需要不断的联系客户,慢慢孵化,但是效率十分低,尤其是在大量拨打电话的这一过程中,很多都是无效外呼,但是ai外呼机器人的出现完全改变了销售人…

【超简单】基于PaddleSpeech搭建个人语音听写服务
一、【超简单】之基于PaddleSpeech搭建个人语音听写服务
1.需求分析 亲们,你们要写会议纪要嘛?亲们,你们要写会议纪要嘛?亲们,你们要写会议纪要嘛?当您面对成吨的会议录音,着急写会议纪要而不得不愚公移山、人海战术?听的头晕眼花,听的漏洞百出,听的怀疑人生,那么你…
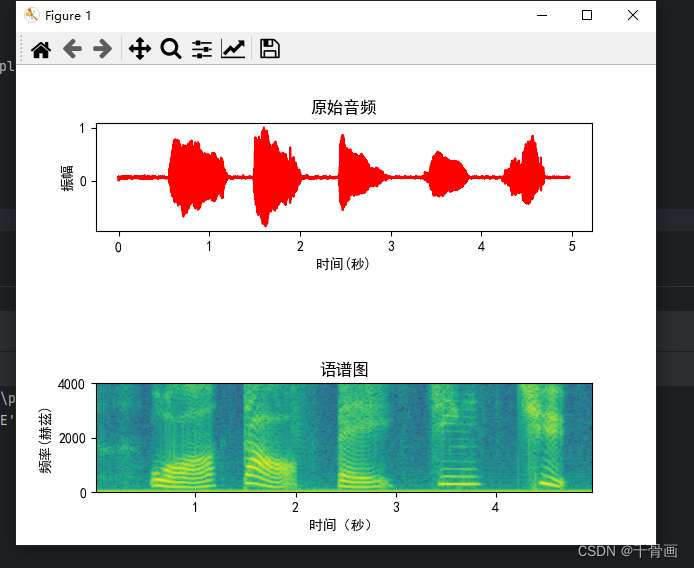
语音特征的反应——语谱图
语谱图的横坐标为时间,纵坐标为对应时间点的频率。坐标中的每个点用不同颜色表示,颜色越亮表示频率越大,颜色越淡表示频率越小。可以说语谱图是一个在二维平面展示三维信息的图,既能够表示频率信息,又能够表示时间信息。
创建和绘制语谱图的…

基于Whisper语音识别的实时视频字幕生成 (二): 在线实时字幕
Whisream Whistream(微流)是基于Whisper语音识别的的在线字幕生成工具,支持rtsp/rtmp/mp4等视频流在线语音识别
1. whistream介绍
whistream将在whishow基础上引入whisper进行在线语音识别生成视频字幕
2. 使用
python:
pyth…

语音识别(录音与语音播报)
语音识别(录音与语音播报)
简介
语音识别人工智能技术的应用领域非常广泛,常见的应用系统有:语音输入系统,相对于键盘输入方法,它更符合人的日常习惯,也更自然、更高效;语音控制系…
安卓系统内置语音识别技术——Speech-to-Text的研究与实践
摘要 本文聚焦于安卓系统内置的Speech-to-Text技术,对其基本概念、工作原理、具体使用方法、性能优劣以及典型应用场景进行深入剖析,并结合实例代码阐述其在安卓开发中的应用。安卓系统内置的Speech-to-Text功能作为一项基础的语音识别服务,为…

紧急 CCF-C ICPR 2024摘要投稿日期延期至4月10日 速投速成就科研梦
会议之眼 快讯
第27届ICPR(The International Conference on Pattern Recognition)即国际模式识别会议将于 2024年 12月1日-5日在印度加尔各答的比斯瓦孟加拉会议中心举行!ICPR是国际模式识别协会的旗舰会议,也是模式识别、计算机…
助听器算法研究开发源码介绍
助听器算法研究开发源码介绍 是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,+群赠送蓝牙音频,DSP音频项目核心开发资料, openMHA(Open Master Hearing Aid)是一个开源的听力辅助设备软件项目。它包含了openMHA工…

语音识别与自然语言处理(NLP):技术前沿与未来趋势
语音识别与自然语言处理(NLP):技术前沿与未来趋势 随着科技的快速发展,语音识别与自然语言处理(NLP)技术逐渐成为人工智能领域的研究热点。这两项技术的结合,使得机器能够更好地理解和处理人类语…
OpenAI的Whisper蒸馏:蒸馏后的Distil-Whisper速度提升6倍
1 Distil-Whisper诞生
Whisper 是 OpenAI 研发并开源的一个自动语音识别(ASR,Automatic Speech Recognition)模型,他们通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask&am…
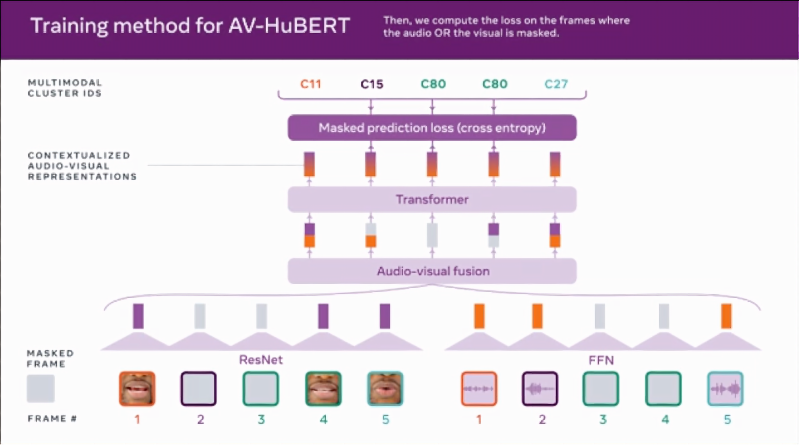
AI 看唇语,在嘈杂场景的语音识别准确率高达75%
事实上,研究表明视觉线索在语言学习中起着关键的作用。相比之下,人工智能语言识别系统主要是建立在音频上。而且需要大量数据来训练,通常需要数万小时的记录。
为了研究视觉效果,尤其是嘴部动作的镜头,是否可以提高语…
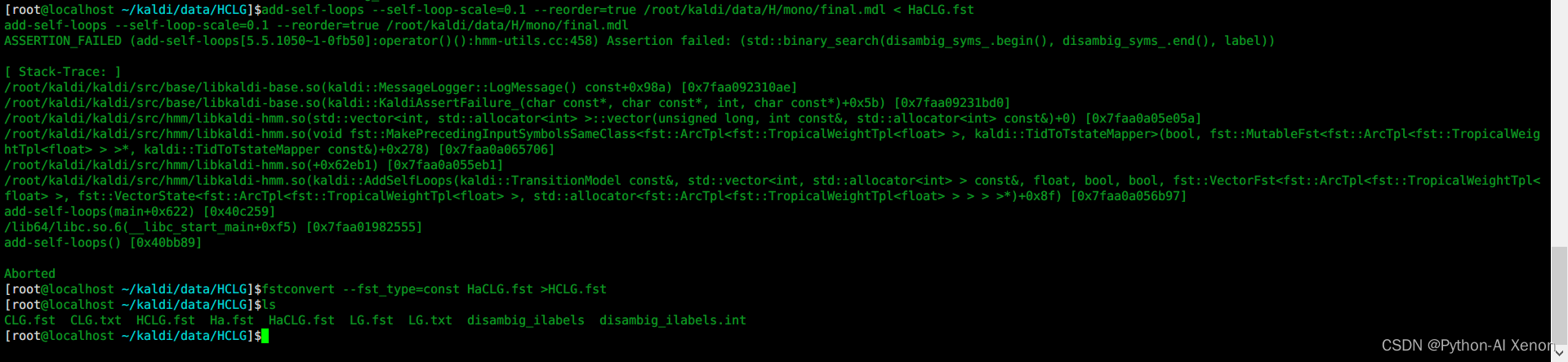
Kaldi语音识别技术(八) ----- 整合HCLG
Kaldi语音识别技术(八) ----- 整合HCLG 文章目录Kaldi语音识别技术(八) ----- 整合HCLGHCLG 概述组合LG.fst可视化 LG.fst组合CLG.fst可视化CLG.fst生成H.fst组合HCLG.fst生成HaCLG.fst生成HCLG.fstHCLG 概述
HCLG min(det(H o min(det(C o min(det(L o G)))))
将…
choices参数的使用、MVC和MTV的模式、创建表对表关系的三种创建方式
【1】choices参数的使用 应用场景:针对表中可能列表完全的字段,采用choices参数 例如:性别,代码如下 # 1.创建一张表class gender_info(models.Model):name models.CharField(max_length32)password models.CharField(max_lengt…
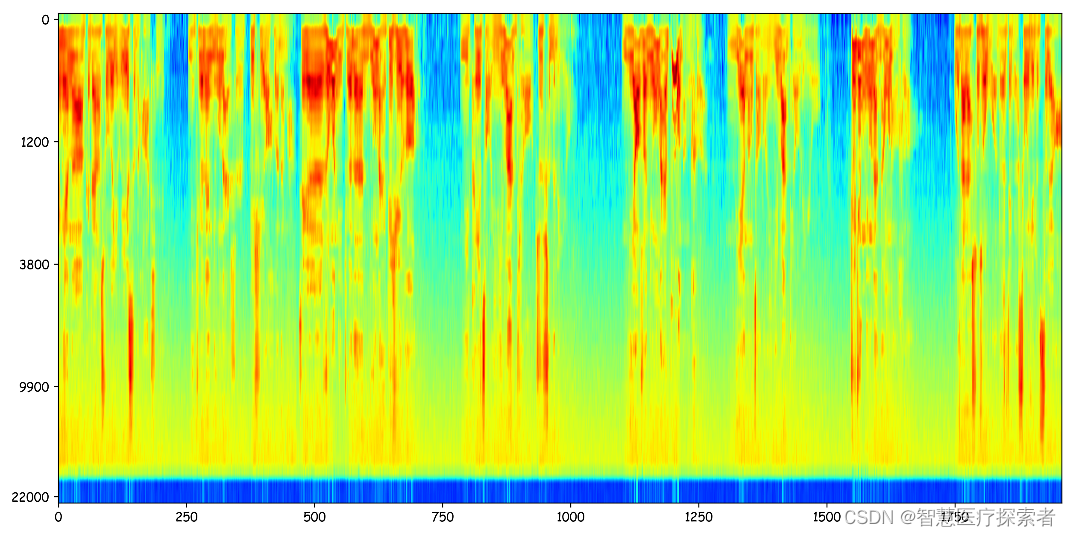
语音特征提取: 梅尔频谱(Mel-spectrogram)与梅尔倒频系数(MFCCS)
1 核心概念
1.1 语音信号
语音信号是一个非平稳的时变信号,但语音信号是由声门的激励脉冲通过声道形成的,经过声道(人的三腔,咽口鼻)的调制,最后由口唇辐射而出。认为“短时间”(帧长/窗长:10~30ms)内语音信号是平稳…
【HTML5】HTML5 语音合成
一、前言
前一段时间在项目中需要用到播报文字语音。找到了 HTML 5 有这样的功能。
现在有时间进行总结下。
二、SpeechSynthesis
SpeechSynthesis 接口是语音服务的控制接口。它可以用于获取设备上关于可用的合成声音的信息,
开始、暂停语音,或者别…
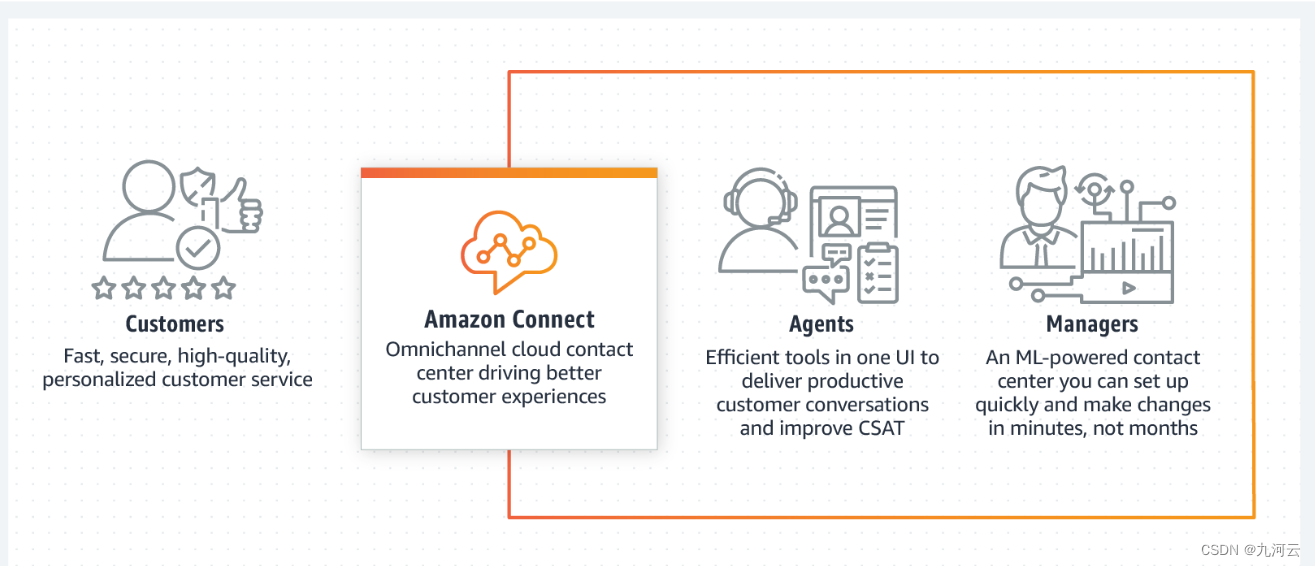
AWS的云端电话呼叫中心服务对企业出海有用吗?
出海,对企业而言是开阔业务、增强自身实力的主要渠道,也是近些年来国内企业之间的热潮。许多出海企业对于因为接收全球各地客户咨询不能及时反馈,或者通过消耗大量人力来解决。针对于这项痛点,九河云基于多年从云经验为企业选择AW…

论文分享 | 利用单模态自监督学习实现多模态AVSR
以下文章来源于智能语音新青年 ,作者ttslr 论文地址:
https://aclanthology.org/2022.acl-long.308.pdf 代码仓库:
https://github.com/LUMIA-Group/Leveraging-Self-Supervised-Learning-for-AVSR 训练一个基于Transformer的模型需要大量的…

【TinyALSA全解析(三)】tinyplay、tincap、pcm_open源码解析
tinyplay、tincap、pcm_open源码解析 一、本文的目的二、tinyplay.c源码分析三、tinycap.c源码分析四、pcm.c如何调度到Linux Kernel4.1 pcm_open解析4.1.1 pcm_open的主要流程4.1.2 流程说明4.1.3 调用方法 4.2 pcm_write解析 /*********************************************…
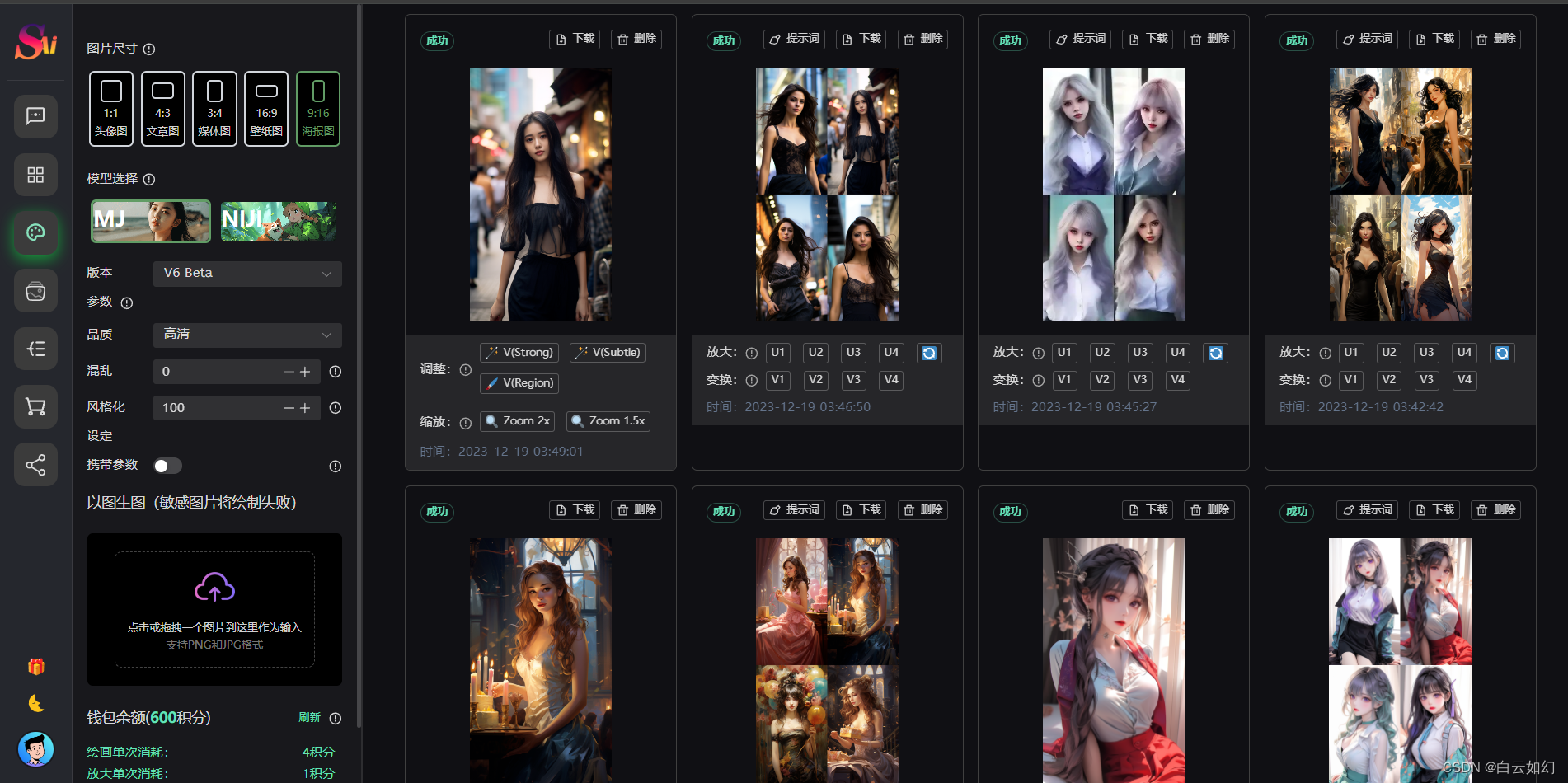
最新国内使用GPT4教程,GPT语音对话使用,Midjourney绘画,ChatFile文档对话总结+DALL-E3文生图
一、前言
ChatGPT3.5、GPT4.0、GPT语音对话、Midjourney绘画,文档对话总结DALL-E3文生图,相信对大家应该不感到陌生吧?简单来说,GPT-4技术比之前的GPT-3.5相对来说更加智能,会根据用户的要求生成多种内容甚至也可以和…
AI创作系统ChatGPT系统源码,支持Midjourney绘画,GPT语音对话+DALL-E3文生图
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…
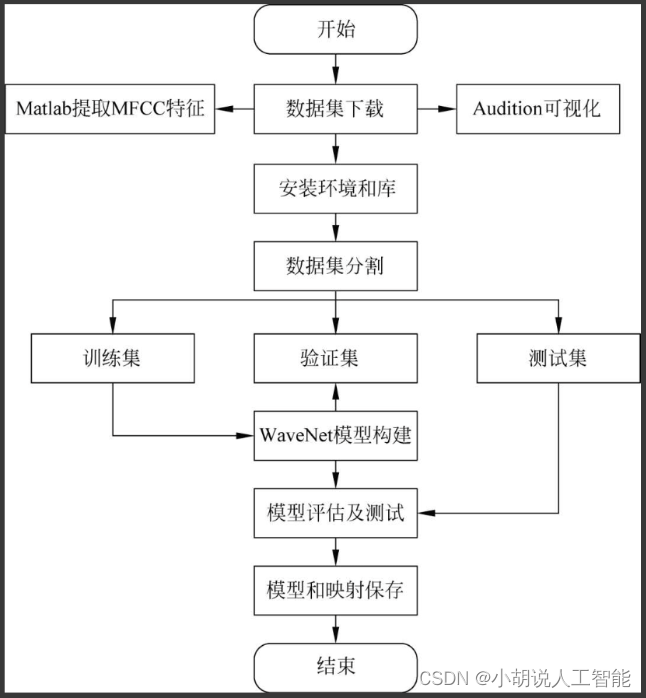
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(一)
目录 前言引言总体设计系统整体结构图系统流程图 运行环境Python环境TensorFlow 环境Jupyter Notebook环境Pycharm 环境 相关其它博客工程源代码下载其它资料下载 前言
博主前段时间发布了一篇有关方言识别和分类模型训练的博客,在读者的反馈中发现许多小伙伴对方言…
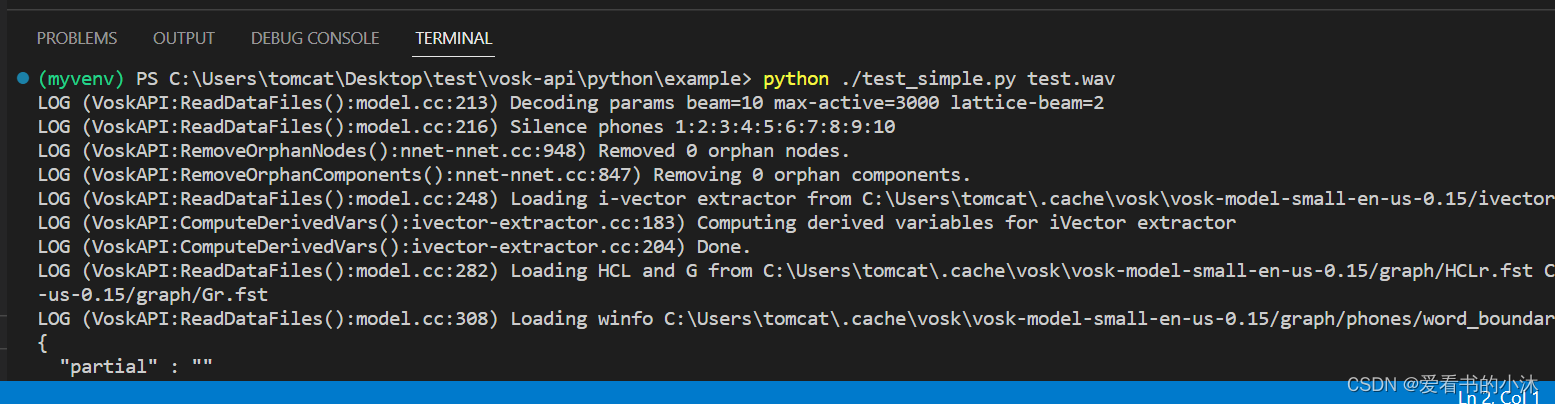
【小沐学Python】Python实现语音识别(vosk)
文章目录 1、简介1.1 vosk简介1.2 vosk模型1.3 vosk服务 2、安装3、测试3.1 命令行测试3.2 代码测试 结语 1、简介
https://alphacephei.com/vosk/index.zh.html Vosk 是一个语音识别工具包。 1.1 vosk简介
支持二十种语言 - 中文,英语,印度英语&#…
人工智能中的对比学习:算法原理与应用探索
导言 对比学习作为人工智能领域中的一种重要学习范式,在模型训练和应用中展现出独特的优势。然而,随着应用范围的扩大,对比学习也面临一些挑战。本文将深入探讨对比学习的算法原理、应用场景以及其在人工智能中的前景,并提出一些可…
2023 亚马逊云科技 re:lnvent 大会探秘: Amazon Connect 全渠道云联络中心
2023 亚马逊云科技 re:lnvent 大会探秘: Amazon Connect 全渠道云联络中心 前言一. Amazon Connect 介绍 🗺️二. Amazon Connect 使用教程 🗺️1.我们打开URl链接找到对应服务2.输入Amazon Connect选中第一个点击进入即可;3.在进入之后我们就…
语音识别技术paddlespeech的安装和使用
PaddleSpeech 介绍
PaddleSpeech是百度飞桨(PaddlePaddle)开源深度学习平台的其中一个项目,它基于飞桨的语音方向模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。PaddleSpe…

合肥中科深谷嵌入式项目实战——基于ARM语音识别的智能家居系统(三)
基于ARM语音识别的智能家居系统
我们上一篇,我们实现在Linux系统下编译程序,我们首先通过两个小练习来熟悉一下如何去编译。今天,我们来介绍一下LCD屏幕基本使用。
一、LCD屏幕基本使用 如何使用LCD屏幕? 1、打开开发板LCD设…
第14章-Python-人工智能-语言识别-调用百度语音识别
百度语音识别API是可以免费试用的,通过百度账号登录到百度智能云,在语音技术页面创建的应用,生成一个语音识别的应用,这个应用会给你一个APIKey和一个Secret Key,如图14.1所示。 我们在自己的程序中用 API Key 和 Secr…
RK3308语音识别----c和c++代码混编工程Makefile文件编写
最近在做语音识别相关,发现这个领域大部分代码都是C和C都混编都工程,研究了下混编方式,写下记录过程
custvirtualbox:~/alsa_test$ ls
alsa libasound.so libasound.so.2 libasound.so.2.0.0 main.cpp Makefile test_one.c test_one.…

基于SYN7318智能家居语音识别系统的设计
摘要:随着机器学习和人工智能的热闹,国内语音行业也可谓是百花齐放,尤其是最近几年,人工智能AI技术以及智能家居得到了飞速的发展。本项目将近年来发展迅速的嵌入式技术和非特定语音识别芯片SYN7318有机的结合,设计开发了一种能够通过语音来控制家用电器的开启和关闭、拨打…
实时语音通讯技术:多人通话和语音识别
实时语音通讯技术是一种基于网络传输的语音通讯技术,可以实现语音通话、语音聊天、语音会议等功能。随着互联网的发展,实时语音通讯技术越来越受到人们的关注和应用。本文将重点介绍实时语音通讯技术中的多人通话和语音识别两个方面。
多人通话
多人通…
语音合成 - TTS-VUE 学习
今天给小伙伴测试了一款人工智能文字合成语音的工具,测试中发现应该是某位大神开发的开源工具,经过一下午的测试,发现有可学习之处,有兴趣的小伙伴可以一起来学习下。 一、简单介绍
微软的语音合成助手利用强大的微软AI语音库&am…
大模型进军汽车产业:智能座舱成为突破口?
大模型进军汽车产业:智能座舱成为突破口?
1. 引言2. 模型与应用 2.1 模型简介2.2 应用场景 3. 智能座舱概述4. 大模型在智能座舱的应用 4.1 语音识别与控制4.2 乘客情绪识别与调节4.3 个性化推荐与信息服务 5. 持续发展与商业模式6. 展望与结论
1. 引言…
Realitykit结合Speech实现语音控制AR机器人移动(完整代码)
利用Apple最新的Realitykit搭配ARkit实现虚拟物体的放置,结合内置的Speech库实现语音的识别功能,将语音内容转为文本内容,从而让机器进行运动。
大体思路:
1、配置并启动ARkit环境。
2、构建Entity实体。可以用Apple官方的Crea…
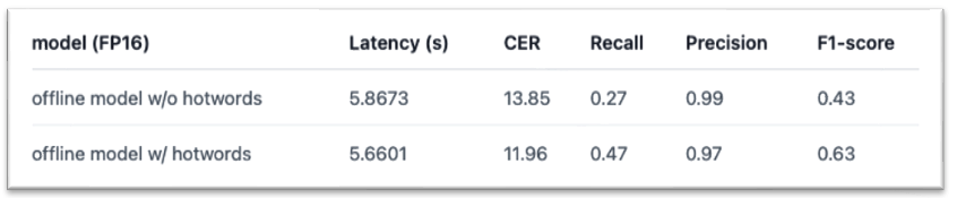
58同城AI Lab在WeNet中开源GPU热词增强功能
01 前言
端到端语音识别系统在足够多数据上训练后,往往能达到不错的识别效果,然而在实际应用场景中,对于不常见的专有名词,例如人名、产品名、小区名等,往往容易识别错误,此类问题需要快速修复,…

文本转语音最新便携版Balabolka2.15.806 + 10个左右的发音人
Balabolka 绿色中文版是一个文本转语音(TTS)和语音朗读程序。Balabolka 可以使用计算机系统上安装的所有语音。屏幕上的文字可以被保存为一个WAV,MP3,OGG或者WMA文件。该软件可以读取剪贴板的内容,可以查看AZW…

MATLAB 可以做什么有趣的事
图像处理(人脸识别) 从test文件夹任选一张人脸分类器会自动从train文件夹里面搜索出最接近的人像使用PCA降维和最小距离分类器,分类效果还不错算法比较简单,有线性代数知识就能理解,这里不多介绍(如果有一定…
win10常用快捷键及官网说明
win10快捷键官网
https://support.microsoft.com/zh-cn/help/12445/windows-keyboard-shortcuts
常用快捷键
按键功能winR运行winE资源管理器winS查看语音助手winT后台程序切换winA打开通知中心winL锁屏winP投影切换WinTab激活任务视图WinC通过语音激活CortanaWinD显示桌面W…
开源(离线)中文语音识别ASR(语音转文本)工具整理
开源(离线)中文语音识别ASR(语音转文本)工具整理
目录 文章目录 目录[toc] open ai 的开源工具:whisperwhisper介绍引用 ASRT语音识别项目ASRT介绍引用 微软语音服务(付费)微软语音服务介绍实时语音转文本批量转录自定义语音 引用 PaddleSpeechPaddleSpeech介绍引用…

语音与语言处理技术交流会(深圳)
嘉宾介绍 嘉宾介绍:罗艺,2021年在美国哥伦比亚大学获得博士学位后加入腾讯AI Lab Shenzhen任高级研究员,研究方向主要为音频前端处理,包括但不限于音频分离、单/多通道语音增强等。
报告题目:腾讯AI Lab音频与语音前端…

Python智能语音识别语翻译平台|项目后端搭建
Python程序设计基础,第三方库Django、requests、hashlib、pyttsx3等的使用,百度API语音识别业务接口、文本朗读业务接口、翻译业务接口的传入。 01、任务实现步骤
任务描述:本任务利用Django框架搭建智能语音识别与翻译平台的后端࿰…
使用Arduino开发板进行语音识别
语音识别技术在自动化中非常有用,它不仅可以让您免提控制设备,还可以提高系统的安全性。除了制造语音控制小工具外,语音识别还为患有各种残疾的人们提供了重要帮助。
在之前的帖子中,我们制作了基于Arduino的文本到语音ÿ…
HarmonyOS学习路之开发篇—AI功能开发(语音识别)
语音识别概述
语音识别功能提供面向移动终端的语音识别能力。它基于华为智慧引擎(HUAWEI HiAI Engine)中的语音识别引擎,向开发者提供人工智能应用层API。该技术可以将语音文件、实时语音数据流转换为汉字序列,准确率达到90%以上…
树莓派 ubuntu20.04下 python调讯飞的语音API,语音识别和语音合成
目录 1.环境搭建2.去讯飞官网申请密钥3.语音识别(sst)4.语音合成(tts)5.USB声卡可能报错 1.环境搭建
#环境说明:(尽量在ubuntu下使用, 本次代码均在该环境下实现)
sudo apt-get install sox # 安装语音播放软件
pip …
华为FreeClip耳机可以调节音量大小吗?附教程!
不会只有我一个人吧?都用华为FreeClip耳机一段时间了,才发现它竟然不支持在耳机上直接调节音量,也是没谁了!但是后来自己摸索了一下,发现了华为FreeClip耳机原来是几个简单有效的调节音量大小的方法滴~不得不说&#x…
通过Python的speech_recognition库将声音转为文字
文章目录 前言一、PortAudio1.PortAudio是什么?2.安装PortAudio 二、使用方法1.引入库2.创建一个Recognizer对象3.使用麦克风录音,从麦克风录制音频4.将音频转换为文字5.转换结果 总结 前言 大家好,我是空空star,本篇给大家分享一…

基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(三)
目录 前言引言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理2. 模型构建1)定义模型结构2)优化损失函数 3. 模型训练及保存1)模型训练2)模型保存3)映射保存 相关其它博客工程源代码下载其它资料下载…
最新GPT4教程,GPT语音对话使用,Midjourney绘画,ChatFile文档对话总结+DALL-E3文生图教程工具
一、前言
ChatGPT3.5、GPT4.0、GPT语音对话、Midjourney绘画,文档对话总结DALL-E3文生图,相信对大家应该不感到陌生吧?简单来说,GPT-4技术比之前的GPT-3.5相对来说更加智能,会根据用户的要求生成多种内容甚至也可以和…
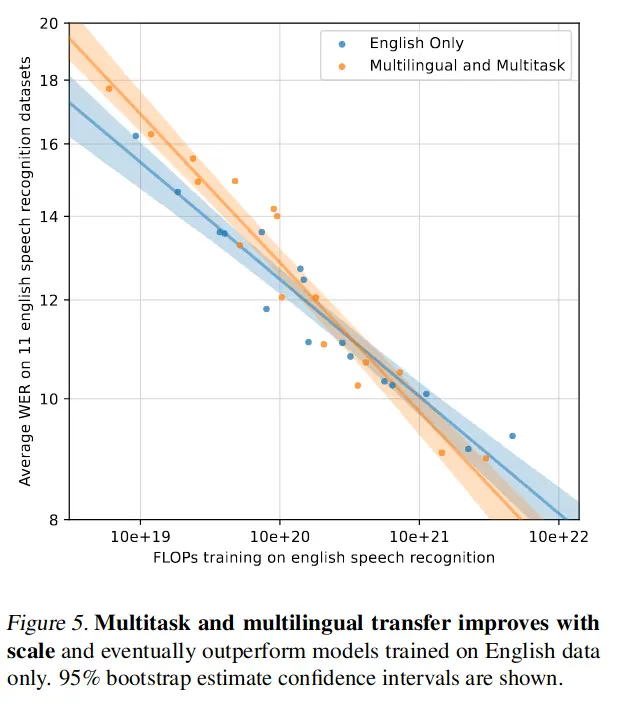
论文阅读_语音识别_Wisper
英文名称: Robust Speech Recognition via Large-Scale Weak Supervision
中文名称: 通过大规模弱监督实现鲁棒语音识别
链接: https://proceedings.mlr.press/v202/radford23a.html
代码: https://github.com/openai/whisper
作者: Alec Radford, Jong Wook Kim, Tao Xu, Greg…
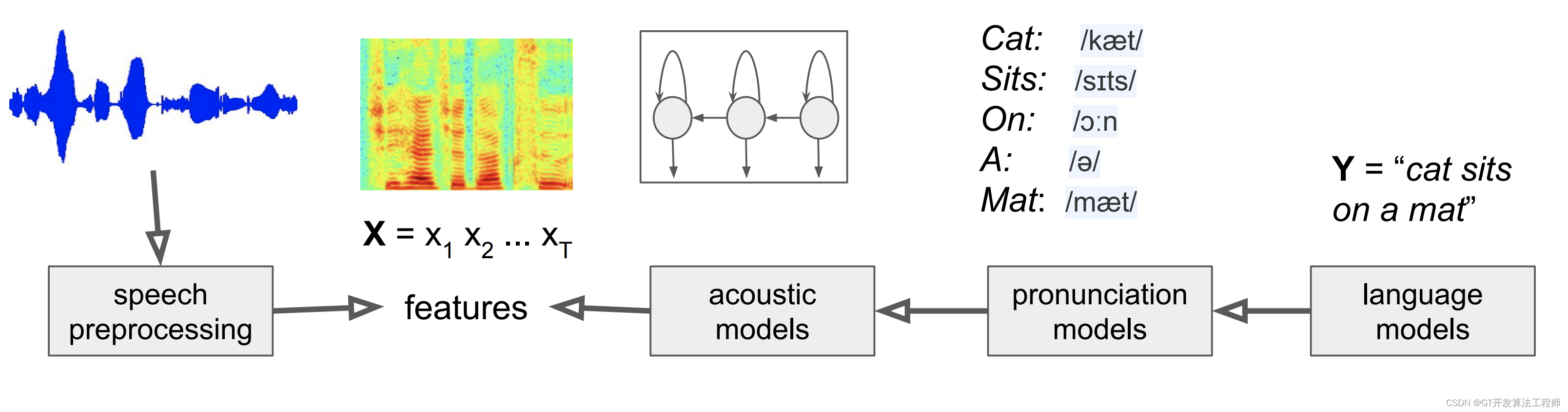
基于TensorFlow的LibriSpeech语音识别
一、引言 随着人工智能技术的日益成熟,深度学习在语音识别领域取得了显著的突破。本博客将介绍如何使用TensorFlow框架,结合LibriSpeech数据集,构建一个高效的语音识别系统。
目录
一、引言
二、环境准备
为了运行本示例代码,…

英语语音翻译在线翻译器有哪些?分享5个翻译软件
英语语音翻译在线翻译器有哪些?随着全球化的深入,语言沟通成为了连接世界的桥梁。在众多的语言翻译工具中,英语语音翻译在线翻译器因其便捷性和实用性受到了广泛关注。本文将为你介绍五款优秀的英语语音翻译在线翻译器,助你轻松跨…
语音系统智能AI机器人AI源码营销机器人拨号机器人语音机器人空号识别科大识别阿里识别语音识别语音翻译
AI智能电话机器人市场越来越火,市场竞争越来越激烈,成本越来越高,你需要一套独立的电销机器人系统,电销机器人系统源码独立部署了,你只需一次性买断,将系统部署在你的服务器上,自己做品牌,…
最新AI系统ChatGPT网站H5系统源码,支持AI绘画,GPT语音对话+ChatFile文档对话总结+DALL-E3文生图
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…

楼宇对讲门铃选型分析
目前很多的高层住宅都使用了对讲门铃了,在频繁使用中,门铃会出现的越来越多种类,下面我就简单的介绍会有用到的几款芯片.
语音通话芯片:D34018,D34118,D5020,D31101; D34018 单片电话机通话电路,合并了必 需的放大器…
AIGC系统ChatGPT系统源码,Midjourney绘画,GPT语音对话+ChatFile文档对话总结+DALL-E3文生图+思维导图一站式解决方案
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…
离线语音识别 sherpa-ncnn 尝鲜体验
文章目录 1、ubuntu 编译运行依赖安装下载与编译模型下载运行 2、树莓派 4B 编译运行确认树莓派 4B 环境交叉编译交叉编译模型下载与运行模型对比测试树莓派 4B 运行大模型 Sherpa-NCNN 是一个基于 C 的轻量级神经网络推理框架,是 kaldi 下的一个子项目,…
WeNet语音识别调用通义千问
WeNet语音识别调用通义千问 WeNet语音识别对通义千问(Qwen-72B-Chat Bot)调用,首先通过WeNet将用户的语音输入转录为文本,然后将此文本输入通用问答模型以获取答案。 本人原创作品,体验一下 连续对话
WeNet语音识别…
[语音识别]开源语音识别faster-whisper模型下载地址
官方源码:
https://github.com/SYSTRAN/faster-whisper
模型下载地址:
large-v3模型:https://huggingface.co/Systran/faster-whisper-large-v3/tree/main large-v2模型:https://huggingface.co/guillaumekln/faster-whisper-l…


普中STM32-PZ6806L开发板(USART2 串口 + HI-LINK-V20离线语音模块控制LED灯)
简介 买了HI-LINK-V20型号的离线语音识别模块, 为了后面可以做有意思的东西, 现在先来用用, 使用USART2 串口 接收来自我在HI-LINK-V20中预设的动作, 当识别到词条时发送对应的指令到串口, HI-LINK串口接的就是STM32F03ZET6的USART2, 且往下看。 电路原理图
连线图
连线引脚表…

不会代码(零基础)学语音开发(语音控制板载双电机)
电机,可以说是在生活中无处不见。有句话形容它:只要动的地方就有电机的身影。
比方说:空调、冰箱、洗衣机、油烟机、电扇、吸尘器、电动剃须刀、电吹风、豆浆机、破壁机、空气净化器、洗碗机、电动牙刷等种种电器产品,无一不是使…
语音机器人话术设计重点
要使用语音机器人,首先得要先准备一套业务的话术脚本,这个话术脚本的设计,可能直接决定了语音机器人后续的使用效果。这个脚本的编写一般不是机器人厂家直接能完成的,只有业务的使用方,他们才最了解自己的业务…
Java调用百度云语音识别【音频转写】
百度云文档 ttps://ai.baidu.com/ai-doc/SPEECH/Bk5difx01 示例代码:
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import lombok.extern.slf4j.Slf4j;
import okhttp3.*;
import org.json.JSONObject;
import org.springframework.stereoty…
ai智能电销机器人外呼系统搭建需要哪些技术
电销是每个企业不可或缺的一股销售力量,其优势就是让企业和客户在未见面的前提下就能建立合作意向,相比跑外寻找客户要方便很多。同时,电销在企业中的弊端也极为突出,人工成本高,工作效率低都是令企业头疼的事。但是&a…
VALL-E X语音大模型,支持跨语言文本语音合成、语音克隆
引言
“ Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling ”。
微软亚洲研究院最近发布了 VALL-E X,可以通过一个几秒的源语音片段生成目标语言的语音,并保留说话者的声音、情感和声学环境。VALL-E X 不需…

AudioGPT 语音技术全覆盖:语音识别、增强、分离、风格迁移等 | 开源日报 No.114
stevearc/oil.nvim
Stars: 1.7k License: MIT
oil.nvim 是一个类似于 vim-vinegar 的文件浏览器,允许您像普通 Neovim 缓冲区一样编辑文件系统。其主要功能包括支持常见插件管理器、通过适配器抽象进行所有文件系统交互以及提供 API 来执行各种操作。该项目的关键…

英伟达推新AI语音识别模型Parakeet 号称优于Whisper
领先的开源对话 AI 工具包 NVIDIA NeMo宣布推出 Parakeet ASR 模型系列,这是一系列最先进的自动语音识别(ASR)模型,能够以出色的准确性转录英语口语。Parakeet ASR 模型与 Suno.ai 合作开发,是语音识别领域的一大突破&…
ChatSDK 全双工语音识别库
ChatSDK :是对AIUI的语音SDK封装,套餐费用最低在6万/年iflylib :是对原始msc的语音SDK封装,相对AIUI便宜很多baidulib :是对百度语音SDK封装,百度号称永久免费AIUITools :AIUI网络测试工具-折线图动态测试可持续观测 共同特点:实现了全双工语音识别iat、…
【AIOT-语音】pythoAudioOp
语音信号有三个重要的参数:声道数、取样频率和量化位数。 声道数:可以是单声道或者是双声道采样频率:一秒内对声音信号的采集次数,44100Hz采样频率意味着每秒钟信号被分解成44100份。换句话说,每隔144100秒就会存储一次,如果采样率高,那么媒体播放音频时会感觉信号是连续…
基于Asterisk和TTS/ASR语音识别的配置示例
基于Asterisk和TTS/ASR语音识别的配置示例如下:
1. 安装Asterisk:首先,确保你已在服务器上成功安装Asterisk。可以选择从Asterisk官方网站下载最新版本的安装包并按照指南进行安装。
2. 安装TTS引擎:选择适合你需求的TTS&#x…
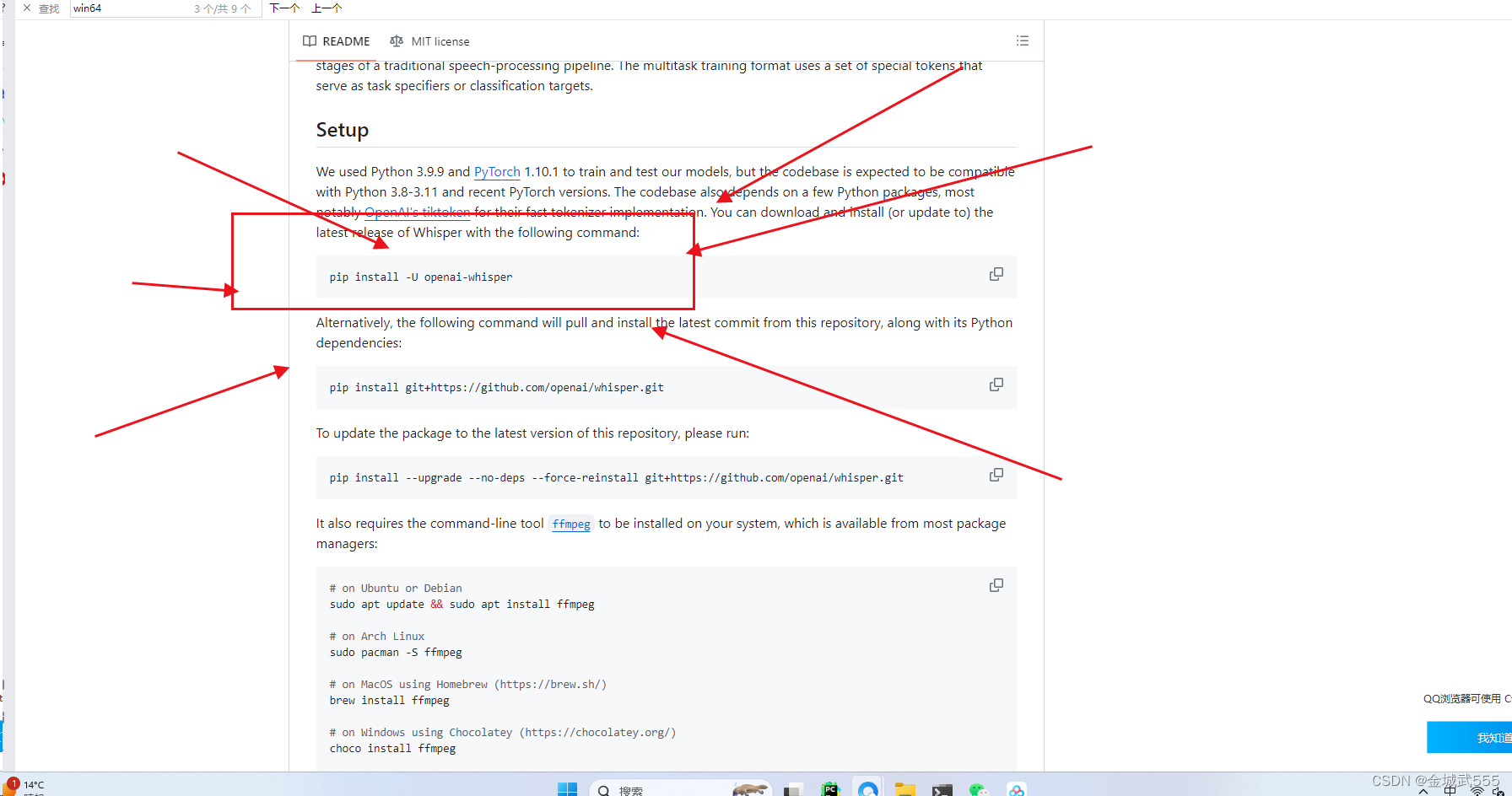
AI语音识别模块--whisper模块
1.下载 ffmpeg,挑一个自己电脑系统的版本,下载,如我win64:
地址:
Releases BtbN/FFmpeg-Builds GitHub 下载压缩包zip,到本地
解压安装,其实无需安装,只需把对应的目录下的bin&…
Whisper——部署fast-whisper中文语音识别模型
whisper:https://github.com/openai/whisper/tree/main 参考文章:Whisper OpenAI开源语音识别模型 环境配置
pip install faster-whisper transformers准备tiny模型 需要其他版本的可以自己下载:https://huggingface.co/openai 原始中文语音…
一款非常好用的语音转文字工具介绍
最近发现一款非常好用的语音转文字的工具Whisper,支持将视频和语音转换成文字,同时记录语音的位置信息,支持语言的翻译,可以将英文转换成中文。同时支持实时的语音自动采集录制。
下面是下载的地址:
【免费】视频、语…

小程序中使用微信同声传译插件实现语音识别、语音合成、文本翻译功能----语音合成(二)
官方文档链接:https://mp.weixin.qq.com/wxopen/plugindevdoc?appidwx069ba97219f66d99&token370941954&langzh_CN#- 要使用插件需要先在小程序管理后台的设置->第三方设置->插件管理中添加插件,目前该插件仅认证后的小程序。
语音合成…
2024最新AI系统ChatGPT商业运营网站源码,支持Midjourney绘画AI绘画,GPT语音对话+ChatFile文档对话总结+DALL-E3文生图
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…
物麒平台DRC动态范围控制修改方法
物奇平台DRC动态范围控制修改 是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,+群赠送语音信号处理降噪算法,蓝牙耳机音频,DSP音频项目核心开发资料, 在音频处理中,DRC是动态范围压缩(Dynamic Range Compr…

Apple的这篇人工智能论文提出了声学模型融合,用以大幅降低语音识别系统中的单词错误率
Apple人工智能论文在提高自动语音识别 (ASR) 系统的准确性和效率方面取得了重大改进。最近的研究深入探讨将外部声学模型 (AM) 集成到端到端 (E2E) ASR 系统中,提出了一种解决域不匹配这一持续挑战的方法,这是语音识别技术中的常见障碍。Apple的这种方法…

文献速递:深度学习--端到端深度学习方法用于通过语音信号检测帕金森病
文献速递:深度学习–端到端深度学习方法用于通过语音信号检测帕金森病
Title
题目
End-to-end deep learning approach for Parkinson’s
disease detection from speech signals
端到端深度学习方法用于通过语音信号检测帕金森病
01
文献速递介绍
帕金森病…
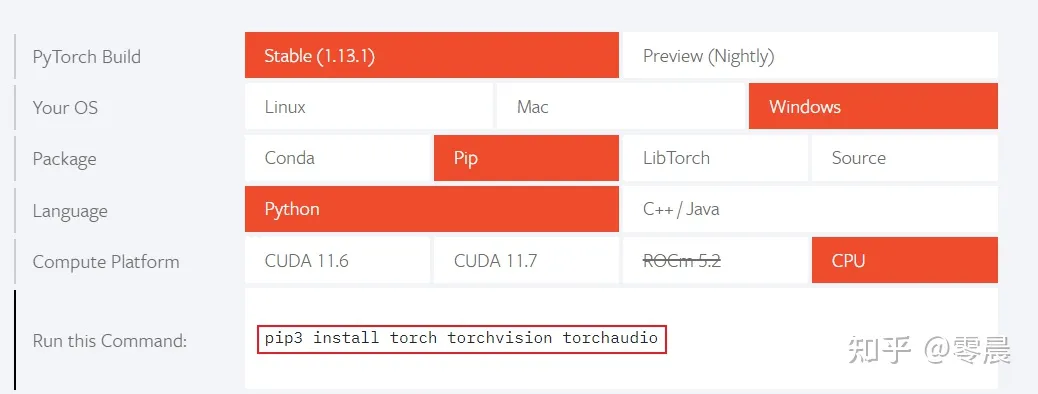
Whisper实现语音识别转文本
#教程
主要参考开源免费离线语音识别神器whisper如何安装, OpenAI开源模型Whisper——音频转文字
Whisper是一个开源的自动语音识别系统,它在网络上收集了680,000小时的多语种和多任务监督数据进行训练,使得它可以将多种语言的音频转文字。…

【MATLAB】语音信号识别与处理:卷积滑动平均滤波算法去噪及谱相减算法呈现频谱
1 基本定义
卷积滑动平均滤波算法是一种基于卷积操作的滤波方法,它通过对信号进行卷积运算来计算移动平均值,以消除噪声。该算法的主要思想是将滤波窗口的加权系数定义为一个卷积核,对信号进行卷积运算来得到平滑后的信号。这样可以有效地去…
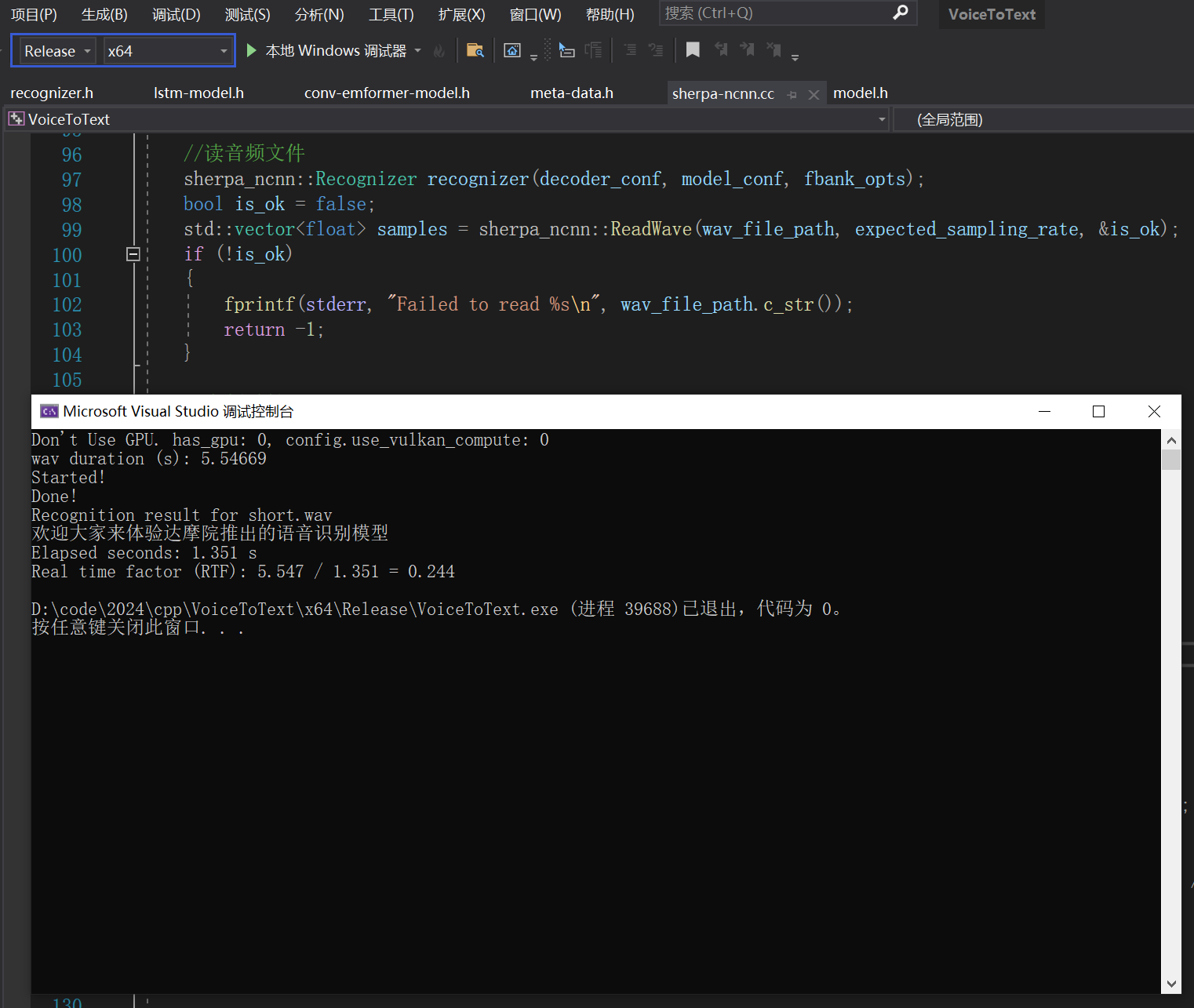
语音转文字——sherpa ncnn语音识别离线部署C++实现
简介
Sherpa是一个中文语音识别的项目,使用了PyTorch 进行语音识别模型的训练,然后训练好的模型导出成 torchscript 格式,以便在 C 环境中进行推理。尽管 PyTorch 在 CPU 和 GPU 上有良好的支持,但它可能对资源的要求较高&#x…
Ubuntu开启麦克风降噪功能
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pulseaudio是什么?二、module-echo-cancel三、声卡四、开启降噪1.内置声卡2.外置声卡3.其它设置 五、配置持久化六、给些建议总结 前言
最近有…

硬核分享|AI语音识别转文字与自动生成字幕
硬核分享|AI语音识别转文字与自动生成字幕_哔哩哔哩_bilibili 在现代快节奏的生活中,语音转文字工具成为了我们工作和学习中的得力助手。它能够将我们说出的话语迅速转化为文字或者将语音视频自动生成字幕,提供便捷和高效。
语音转文字转字幕工具是一种…
ai智能语音机器人系统的话术怎样设置效果比较好
设置一个AI智能语音机器人的话术,以实现最佳效果,涉及以下几个关键方面:
1. 自然语言处理(NLP):AI机器人的话术需要能够理解和处理用户的自然语言输入。使用NLP技术来识别语义、意图和实体,并针…

vue使用科大讯飞的语音识别(语音听写)
使用的是封装好的插件:voice-input-button2
真的很好使很好使
1、先使用npm下载插件
npm i voice-input-button2 -save -dev
2、在main.js中引入
import voiceInputButton from voice-input-button2 3、全局引入
Vue.use(voiceInputButton, { appId: xxx, // …
利用ffmpeg对两个音频文件进行混音处理
前言
最近,拿到了一个语音识别程序,想测试一下它识别的准确性。原本程序有一段自己的测试音频,准确性还可以,但是,自己想增加一下测试素材的复杂性。想到了在原本的测试音频中引入干扰数据(噪点ÿ…

万用表革新升级,WT588F02BP-14S语音芯片助力智能测量新体验v
万能表功能:
万能表是一款集多功能于一体的电子测量工具,能够精准测量电压、电流、电阻等参数,广泛应用于电气、电子、通信等领域。其操作简便、测量准确,是工程师们进行电路调试、故障排查的得力助手,为提升工作效率…
带语音播报的51单片机电子体重秤设计(源码+原理图+资料)
目录 1、概要 2、所用到的物料 3、实物照片 4、原理图 5、模块使用说明 6、程序 1、概要
1、实现0~150KG的量程称量; 2、实时显示称量结果在1602上; 3、最小误差为0.01KG; 4、称量体重或物体时待结果稳定后,实现语音播报结果&a…

鸿蒙应用开发-录音并使用WebSocket实现实时语音识别
功能介绍:
录音并实时获取RAW的音频格式数据,利用WebSocket上传数据到服务器,并实时获取语音识别结果,参考文档使用AudioCapturer开发音频录制功能(ArkTS),更详细接口信息请查看接口文档:AudioCapturer8和…
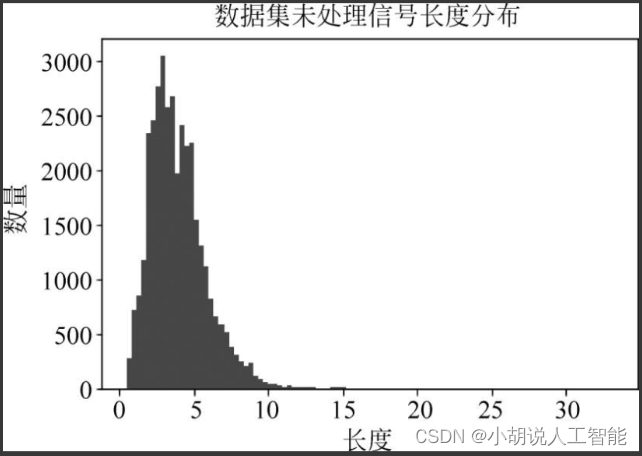
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(二)
目录 前言引言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理1)数据介绍2)数据测试3)数据处理 相关其它博客工程源代码下载其它资料下载 前言
博主前段时间发布了一篇有关方言识别和分类模型训练的博客,在读者…

基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(四)
目录 前言引言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理2. 模型构建3. 模型训练及保存4. 模型生成 系统测试1. 训练准确率2. 测试效果 相关其它博客工程源代码下载其它资料下载 前言
博主前段时间发布了一篇有关方言识别和分类模型训练的博客ÿ…

ESP32语音转文字齐护百度在线语音识别
一、导入(10分钟) 学习目的 二、新授(70分钟) 1.预展示结果(5分钟) 2.本节课所用的软硬件(5分钟) 4.图形化块介绍(10分钟) 5.单个模块的简单使用(10分钟) 6.在线语音转换工具逻辑分析(10分钟) 7.在线语音转换工具分步实现(30分钟) 三、巩固练习(5分钟) 四、课堂小结…
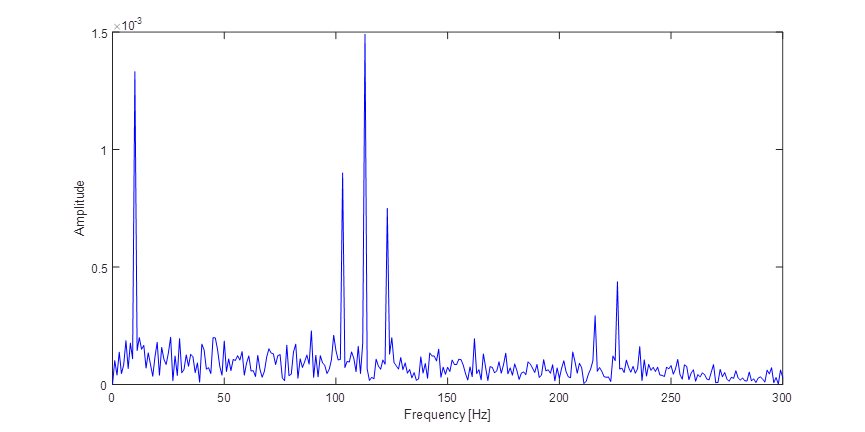
MATLAB环境下基于稀疏最大谐波噪声比反卷积的信号处理方法
状态监测与故障诊断是保障机械设备安全、稳定运行的基础。滚动轴承是旋转机械的核心部件,其服役性能直接影响整台设备的运行安全。在测试的振动信号中,周期性冲击是滚动轴承发生故障的重要标志。因此,如何从振动信号中提取出与故障相关的周期…
实现AI机器人语音交互功能的主流技术有哪些?智能机器人搭建电销机器人源码
实现机器人语音交互功能的技术可以涵盖多个方面,以下是一些主流技术及其应用:
1. 自然语言处理(NLP): NLP 是实现机器人语音交互的核心技术之一,包括语音识别、语音合成、文本理解和生成等子领域。语音识别…
语音革命:打造您的个人AI助手,悄悄分享我的开源语音识别全攻略!
在AI智能化时代,人工智能助手不仅提高了我们的工作效率,而且变得越来越人性化。AI助手在此基础上又增添了一个引人瞩目的新功能——语音识别。在本文中,将详细讲解如何在.Net环境下实现这一功能,并且分享开源项目,让更…
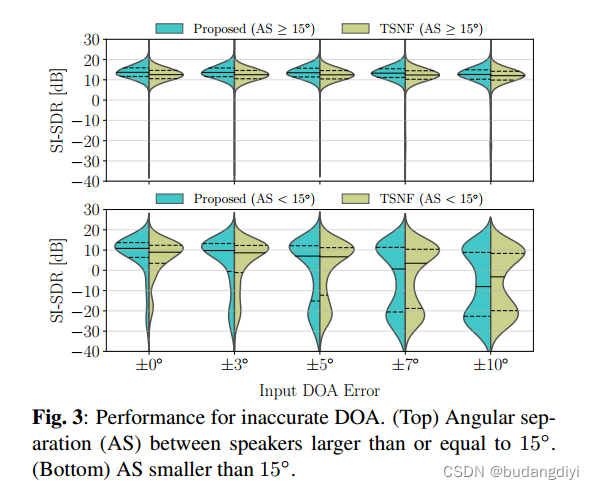
波束形成器制导的目标说话人提取
波束形成器制导的目标说话人提取
第二章 目标说话人提取之《BEAMFORMER-GUIDED TARGET SPEAKER EXTRACTION》 文章目录 波束形成器制导的目标说话人提取前言一、任务二、动机三、挑战四、方法1.基于注册语音的SCTSE2.BG-TSE方法3. 后端波束形成4. 损失函数 五、实验评价1.数据…
ASR-LLM-TTS 大模型对话实现案例;语音识别、大模型对话、声音生成
参考:https://blog.csdn.net/weixin_42357472/article/details/136305123(llm+tts) https://blog.csdn.net/weixin_42357472/article/details/136411769 (asr+vad) 这里LLM用的是chatglm;电脑声音播报用的playsound 1、实时语音识别版本 注意:暂时这项目有个缺陷就是tts…
语音识别:基于HMM
HMM语音识别的解码过程
从麦克风采集的输入音频波形被转换为固定尺寸的一组声学向量: 其中是维的语音特征向量(例如MFCC)。
解码器尝试去找到上述特征向量序列对应的单词(word)的序列: 单词序列的长度是。…

【ESP32S3 Sense接入语音识别+MiniMax模型对话】
1. 前言
围绕ESP32S3 Sense接入语音识别MiniMax模型对话展开,首先串口输入“1”字符,随后麦克风采集2s声音数据,对接百度在线语音识别,将返回文本结果丢入MiniMax模型,进而返回第二次结果文本,实现语言对话…

【超详细教程】GPT-SoVITs从零开始训练声音克隆教程(主要以云端AutoDL部署为例)
目录
一、前言
二、GPT-SoVITs使用教程
2.1、Windows一键启动
2.2、AutoDL云端部署
2.3、人声伴奏分离
2.4、语音切割
2.5、打标训练数据
2.6、数据集预处理
2.7、训练音频数据
2.8、推理模型
三、总结 一、前言 近日,RVC变声器的创始人(GitH…
最新AI创作系统ChatGPT网站系统源码,Midjourney绘画V6 ALPHA绘画模型,ChatFile文档对话总结+DALL-E3文生图
一、前言
SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧。已支持GPT…
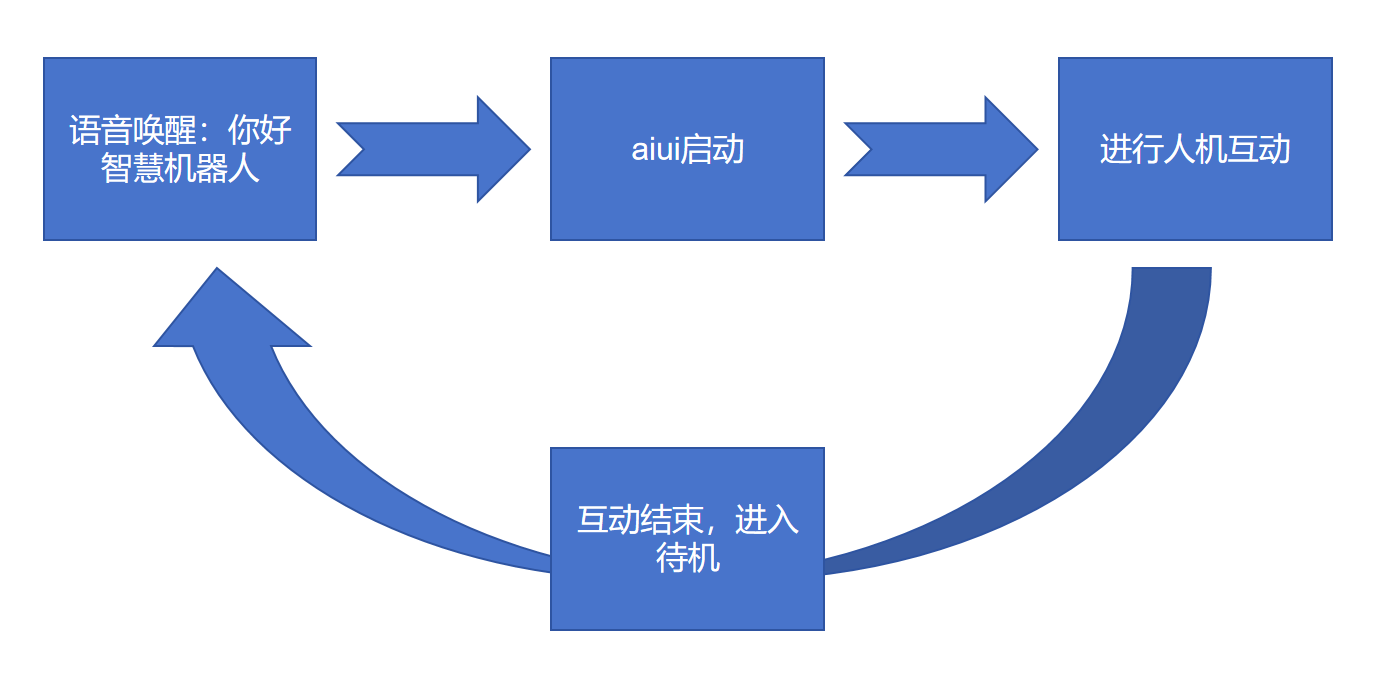
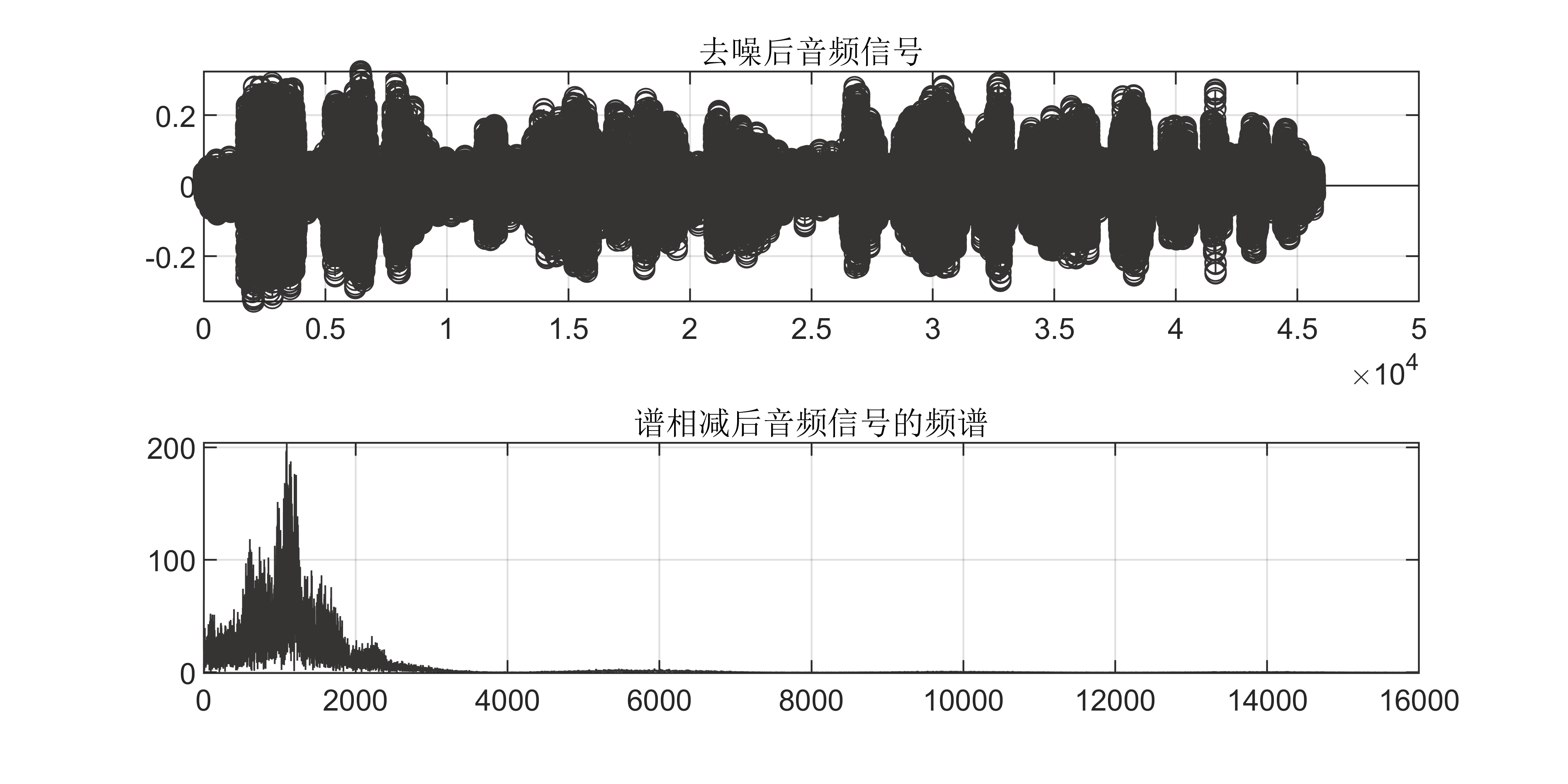
【MATLAB】语音信号识别与处理:T1小波滤波算法去噪及谱相减算法呈现频谱
1 基本定义
T1小波滤波算法是一种基于小波变换的信号去噪算法。它可以有效地去除信号中的噪声,并保留信号的主要特征。该算法的主要思想是将信号分解为多个不同尺度的小波系数,然后通过对小波系数进行阈值处理来去除噪声。 具体来说,T1小波滤…

ASR自动语音识别代码操作
JupyterLab语音识别操作流程录制语音文件合并为单声道文件导入nemo工具包及asr工具类加载Quartznet中文版预训练模型测试模型识别效果语音识别操作流程
使用音频软件或手机录制语音指令音频文件执行语音格式转换及声道合并代码块导入ASR工具包及相关工具类加载模型,…
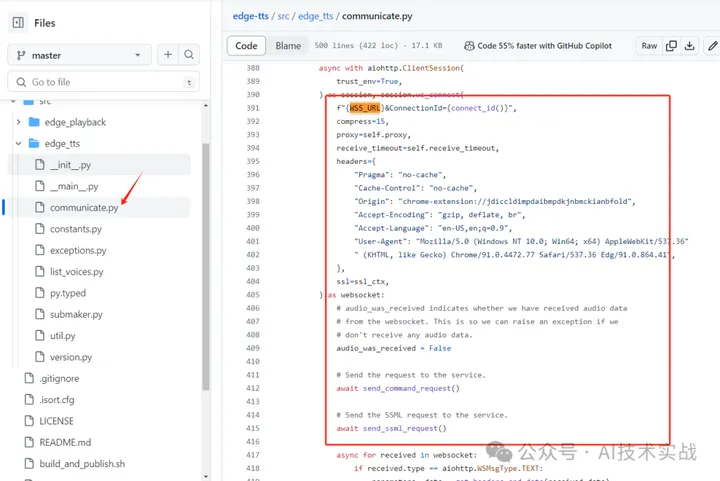
2.8k star! 用开源免费的edge-tts平替科大讯飞的语音合成服务
edge-tts是github上的一个开源项目,可以免费将文本转为语音,别看它只有2.8k star,替代科大讯飞的收费TTS服务完全没问题,因为这个项目实际是调用的微软edge的在线语音合成服务,支持40多种语言,300多种声音&…
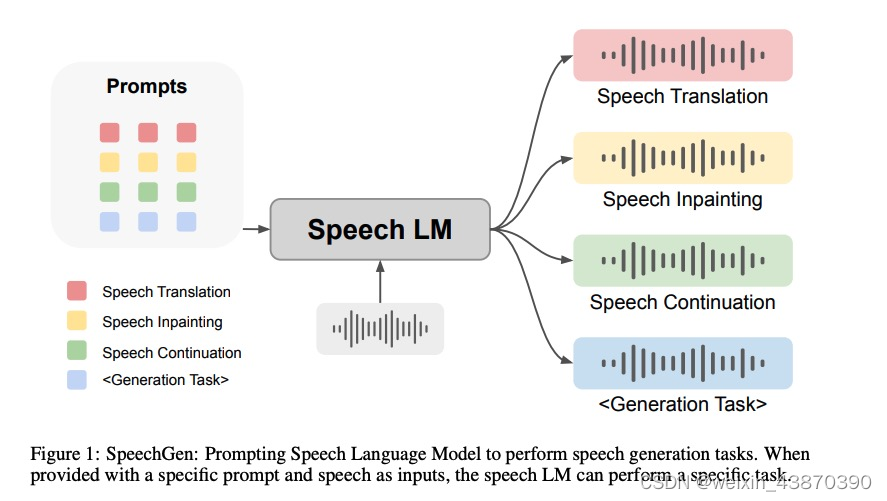
简单介绍SpeechPrompt、SpeechPrompt V2、SpeechGen
主要介绍SpeechPrompt、SpeechPrompt V2、SpeechGen
SpeechPrompt
模型结构和原理(语音到符号) 整体思路:音频特征提取(HuBert/CPC),离散–》deep prompt speechLM(GSLM)—》概率映射–>目标Verbaliz…
论文笔记 - 基于振动信号的减速器故障诊断(进行中...)
基于振动信号的减速器故障诊断, 沈晴,2018
问题1 倒谱
倒谱 就是近似db坐标,对吧? 倒谱(Cepstrum)是一种信号处理技术,其名称来源于"频谱"(spectrum)一词,通过将信号的对…
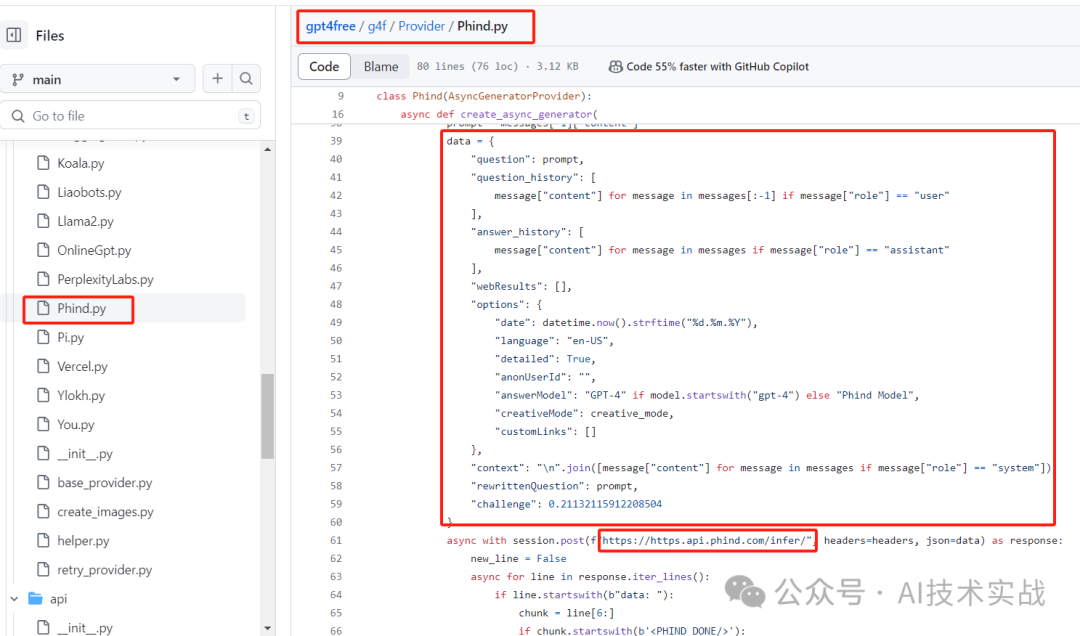
52.2k star! 自己部署gpt4free, 免费使用各种GPT
GPT4Free是一个由开发者Xtekky在GitHub上发布的开源项目,它可以免费地使用GPT-3.5、GPT-4、llama、gemini-pro、bard、claude等多种大模型。截止到当前(2024.1.30)已经有52.2k star,可见其受欢迎程度。 github地址:https://github.com/xtekky…
chatGPT的耳朵!OpenAI的开源语音识别AI:Whisper !
语音识别是通用人工智能的重要一环!可以说是AI的耳朵!
它可以让机器理解人类的语音,并将其转换为文本或其他形式的输出。
语音识别的应用场景非常广泛,比如智能助理、语音搜索、语音翻译、语音输入等等。
然而,语音…
AI智能电销机器人帮助我们开发业务的效果如何呢?
AI电销机器人获客效果怎么样?AI电销机器人是人工智能语音识别系统的应用产品,2018年6月以后,全国电销机器人全面开花,呈现出井喷的状态。疫情3年,全球AI巨头们没有停下深度研发的步伐,AI电销机器人在不断的…
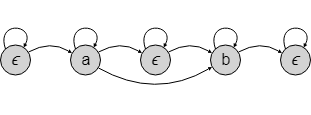
连接时序分类 Connectionist Temporal Classification (CTC)
CTC全称Connectionist temporal classification,是一种常用在语音识别、文本识别等领域的算法,用来解决输入和输出序列长度不一、无法对齐的问题。在CRNN中,它实际上就是模型对应的损失函数(CTC loss)。
一、背景
字母和语音的对齐(align)非…

语音识别技术的探索与应用
目录 前言1 语音识别技术简介2 技术解析2.1 语音识别的基本流程详解2.2 深度学习在语音识别中的创新应用2.3 端到端语音识别的兴起 3 语音识别技术的多维应用展示3.1 智能助理:人机交互的新纪元3.2 自动字幕生成:突破语言障碍3.3 客户服务自动化…
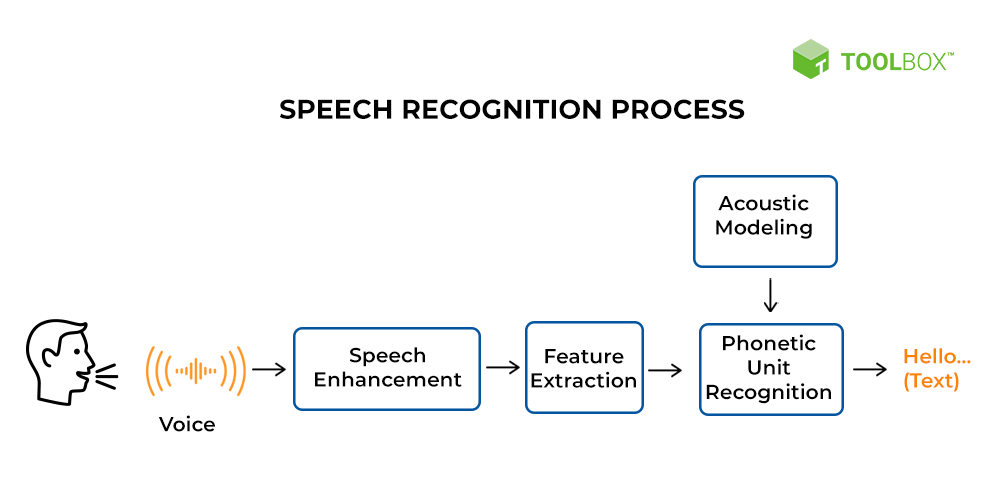
汽车IVI中控开发入门及进阶(十三):语音识别
前言:
IVI中控上的语音识别,在目前市场上也是非常显眼的一个创新,大幅改变了传统IVI的操作习惯。 语音识别Speech recognition,也称为自动语音识别(ASR)、计算机语音识别或语音到文本,是一种使程序能够将人类语音处理成书面格式的能力。 语音识别Speech recognition是计…
大模型在语音识别领域的最新进展与挑战
摘要:
本文概述了大模型在语音识别领域的最新进展与挑战,包括基础知识、核心组件、实现步骤、代码示例、技巧与实践、性能优化与测试、常见问题与解答、结论与展望等内容。
引言
语音识别技术的发展历程中,大模型的应用和重要性日益凸显。…
pyaudio webrtcvad实现实时录制语音加VAD检测没人说话自动停止录制
vad检测没人说话超过2秒就自动停止录制并保存前面有人说话的音频文件 pip install webrtcvad代码:
import pyaudio
import wave
import time
import webrtcvadCHUNK = 320 # 20ms 的语音帧
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
WAVE_OUTPUT_FILENAME
pyttsx3应用场景案例
pyttsx3是一个Python中的文本到语音转换库,其应用场景广泛且多样。以下是一些pyttsx3的应用场景案例:
辅助阅读:对于视力不佳的用户,pyttsx3可以将电子书、网页内容或其他文本信息转换为语音,帮助他们更轻松地获取信息…

QTextToSpeech的使用——Qt
前言
之前随便看了几眼QTextToSpeech的帮助就封装使用了,达到了效果就没再管了,最近需要在上面加功能(变换语速),就写了个小Demo后,发现不对劲了。 出现的问题
场景
写了个队列添加到语音播放子线程中&a…
软件无线电系列——模拟无线电、数字无线电、软件无线电
本节目录
一、模拟无线电
二、数字无线电
1、窄带数字无线电
2、宽带数字无线电
三、软件无线电本节内容 一、模拟无线电 20世纪80年代的模拟体制(美国的AMPS/欧洲的TACS)被称为第一代移动通信,简称1G,主要目标是为在大范围内有限的用户提供移动电话服务。最主要的…
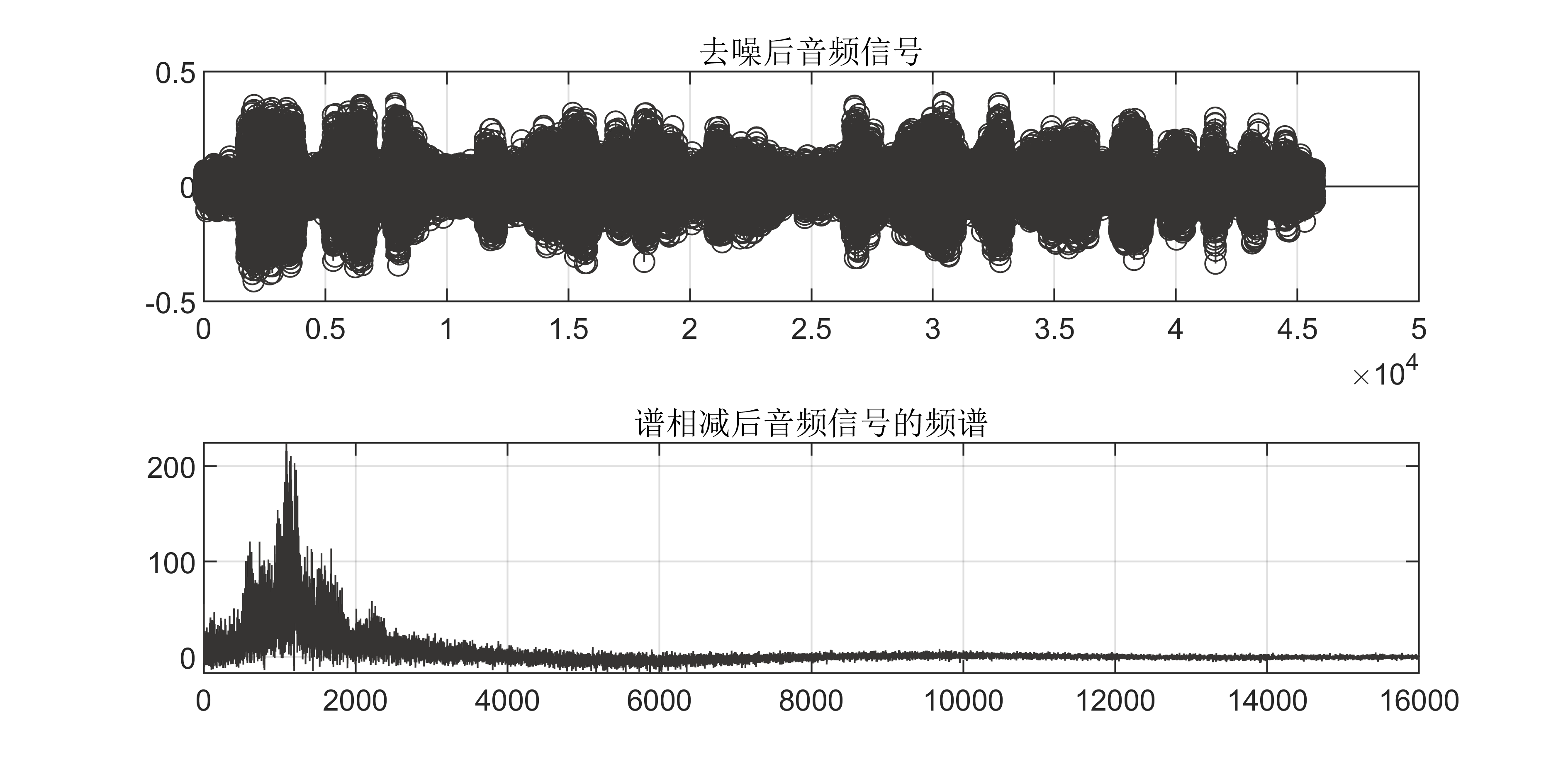
【MATLAB】语音信号识别与处理:移动中位数滤波算法去噪及谱相减算法呈现频谱
1 基本定义
移动中位数滤波算法是一种基于中位数的滤波方法,它通过对信号进行滑动窗口处理,每次取窗口内的中位数作为当前点的估计值,以去除噪声。该算法的主要思想是利用中位数的鲁棒性,对信号中的噪声进行有效的消除。 具体来说…

AI智能电话机器人的核心技术是什么?
电话机器人是近几年兴起的人工智能产品,它主要通过电话群呼潜在客户,沟通进行信息筛选,帮助企业选择意向客户。企业使用电话机器人可以减少人工成本,提高工作效率。我们一起来看看智能电话机器人的核心技术是什么? 电话…
Python使用whisper实现语音识别(ASR)
目录
Whisper的安装
Whisper的基本使用
识别结果转简体中文
断句 Whisper的安装
Whisper是OpenAI的一个强大的语音识别库,支持离线的语音识别。在使用之前,需要先安装它的库:
pip install openai-whisper
使用whisper,还需…

语音识别教程:Whisper
语音识别教程:Whisper
一、前言
最近看国外教学视频的需求,有些不是很适应,找了找AI字幕效果也不是很好,遂打算基于Whisper和GPT做一个AI字幕给自己。
二、具体步骤
1、安装FFmpeg
Windows: 进入 https://github.com/BtbN/FF…
科大讯飞开放平台-python语音转文字教程
文章目录 简介实际使用代码coding简介
科大讯飞的语音转写(Long Form ASR)——基于深度全序列卷积神经网络,将长段音频(5小时以内)数据转换成文本数据,为信息处理和数据挖掘提供基础。
转写的是已录制音频(非实时),音频文件上传成功后进入等待队列,待转写成功后用户…
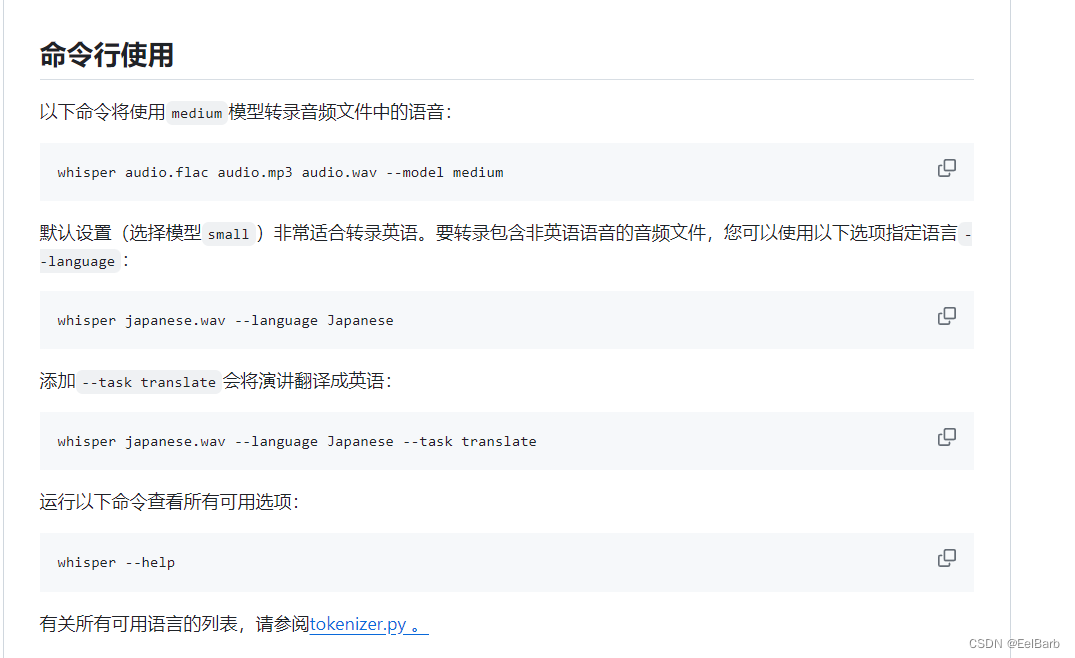
实战whisper:本地化部署通用语音识别模型
前言 Whisper 是一种通用语音识别模型。它是在大量不同音频数据集上进行训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。 这里呢,我将给出我的一些代码,来帮助你尽快实现【语音转文字】的服务部署。 以下…
Python使用PaddleSpeech实现语音识别(ASR)、语音合成(TTS)
目录
安装
语音识别
补全标点
语音合成
参考 PaddleSpeech是百度飞桨开发的语音工具
安装
注意,PaddleSpeech不支持过高版本的Python,因为在高版本的Python中,飞桨不再提供paddle.fluid API。这里面我用的是Python3.7
需要通过3个pip…
基于WEKWS模型的语音唤醒关键词识别
一、模型描述
1.1 论文解读
本文所使用的模型网络结构继承自论文《Compact Feedforward Sequential Memory Networks for Small-footprint Keyword Spotting》,文中研究了将低秩矩阵分解与传统FSMN相结合的紧凑型前馈顺序记忆网络(cFSMN)用…
AI智能电销机器人可以做哪些事情呢?智能机器人搭建
随着科技不断发展,选择使用电销智能机器人的行业有很多,因为它的适用性和实用性都非常广,电销智能机器人使用之后能够让企业的整体工作效率变得更加高效,全天候灵活响应也能帮助企业做好业务工作。对于一些还不太了解电销智能机器…
从零开始一步一步掌握大语言模型---(2-什么是Token?)
了解自然语言处理或者听说过大语言模型的同学都听过,token。一般来说,它代表的是语言中不可再分的最小单元。我们人类的语言不仅有文字,还有语音。针对文字、语音来说,它们都各自有不同的划分token的方法。本节将尽可能详细的介绍…
语音识别技术的进步:大模型在噪声环境下的表现优化
1. 背景介绍
语音识别技术是人工智能领域的一个重要分支,它将人类的语音信号转换为相应的文本信息。随着深度学习技术的快速发展,语音识别技术取得了显著的进步。然而,在噪声环境下,语音识别的准确率仍然面临挑战。为了提高语音识…
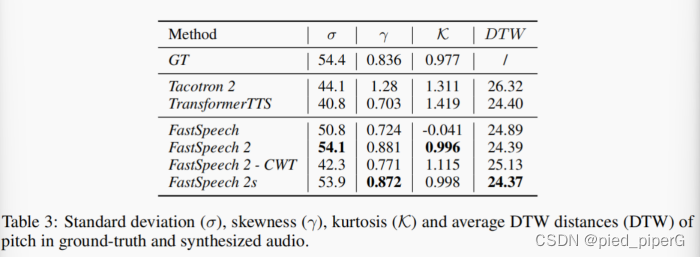
FastSpeech2——TTS论文阅读
笔记地址:https://flowus.cn/share/1683b50b-1469-4d57-bef0-7631d39ac8f0 【FlowUs 息流】FastSpeech2
论文地址:lFastSpeech 2: Fast and High-Quality End-to-End Text to Speechhttps://arxiv.org/abs/2006.04558
Abstract:
tacotron→…
语音识别文字 免费 openai-whisper
语音和别文字
git地址
https://github.com/openai/whisper
简单的测试一下功能 具体使用请访问 git
环境搭建
python 环境
pip install githttps://github.com/openai/whisper.git自行安装 ffmpeg 命令行工具
测试效果
# "/Users/mac/Downloads/aad.mp3" 为本…
面对来势汹汹的AIGC,作为一个IT技术工程师我们应该怎么应对
面对AIGC技术的快速发展,作为IT技术工程师,有几个策略可以帮助你不仅适应这种变化,还能够在未来的职业生涯中保持竞争力和创新力:
持续学习和适应新技术 跟上最新发展:定期关注AIGC领域的最新研究和技术进展ÿ…
爆火的1分钟声音克隆GPT-SoVITS项目 linux系统 ubuntu22.04安装2天踩坑教程
原项目地址:https://github.com/RVC-Boss/GPT-SoVITS 1分钟素材,最后出来的效果确实不错。
1. cuda环境安装
cuda环境准备
根据项目要求在cuda11.8和12.3都测试了通过。我这里是用cuda11.8
cuda11.8安装教程: ubuntu 22.04 cuda多版本和…
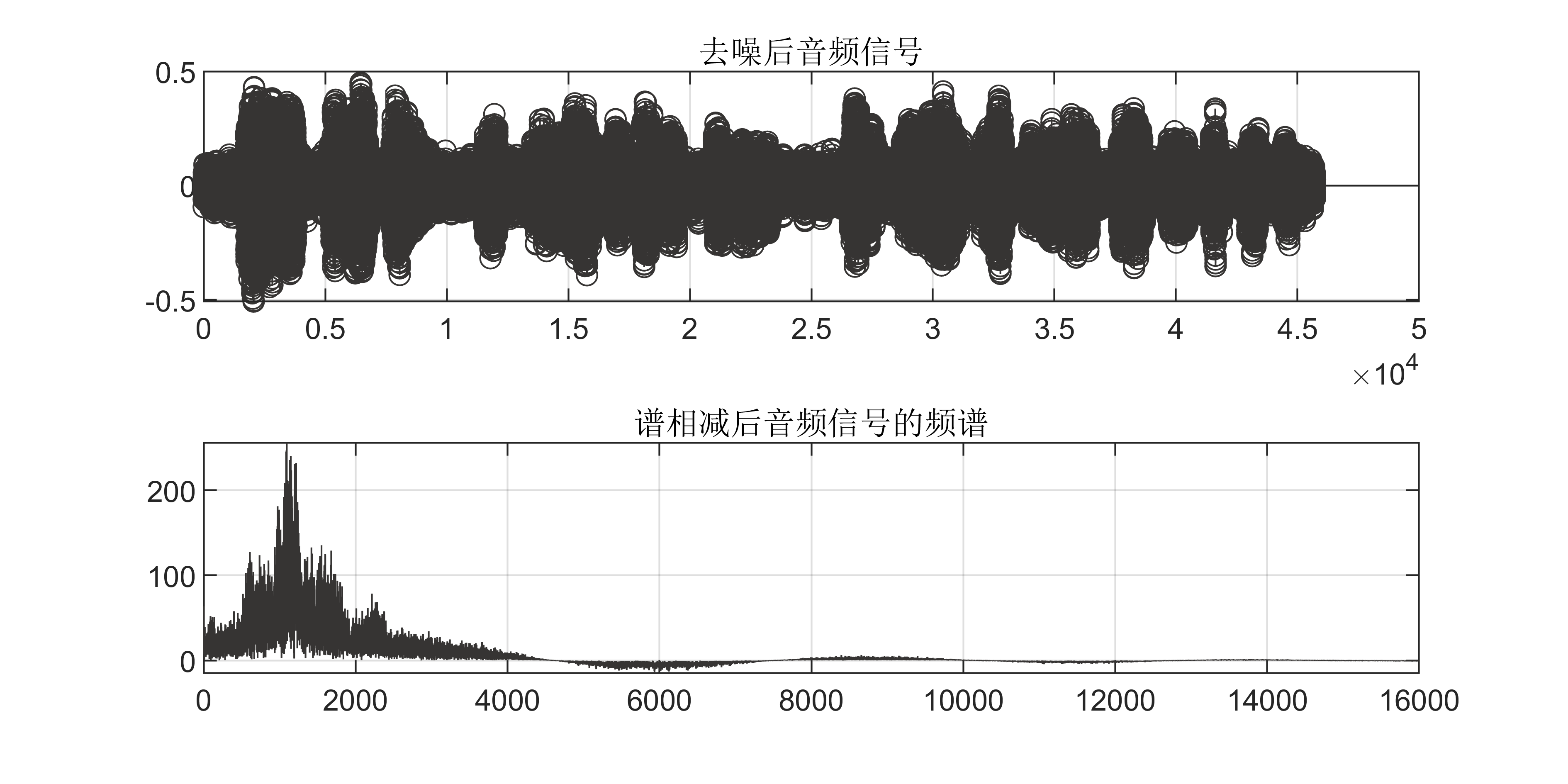
【MATLAB】语音信号识别与处理:SG滤波算法去噪及谱相减算法呈现频谱
1 基本定义
SG 滤波算法(Savitzky - Golay 滤波算法)是一种数字信号处理算法,用于对信号进行平滑处理。该算法利用最小二乘法拟合局部数据段,然后用拟合的函数来估计每个数据点的值,从而实现平滑处理。 SG 滤波算法的…

TenorFlow多层感知机识别手写体
文章目录 数据准备建立模型建立输入层 x建立隐藏层h1建立隐藏层h2建立输出层 定义训练方式建立训练数据label真实值 placeholder定义loss function选择optimizer 定义评估模型的准确率计算每一项数据是否正确预测将计算预测正确结果,加总平均 开始训练画出误差执行结…

让AI帮你说话--GPT-SoVITS教程
有时候我们在录制视频的时候,由于周边环境嘈杂或者录音设备问题需要后期配音,这样就比较麻烦。一个比较直观的想法就是能不能将写好的视频脚本直接转换成我们的声音,让AI帮我们完成配音呢?在语音合成领域已经有很多这类工作了&…
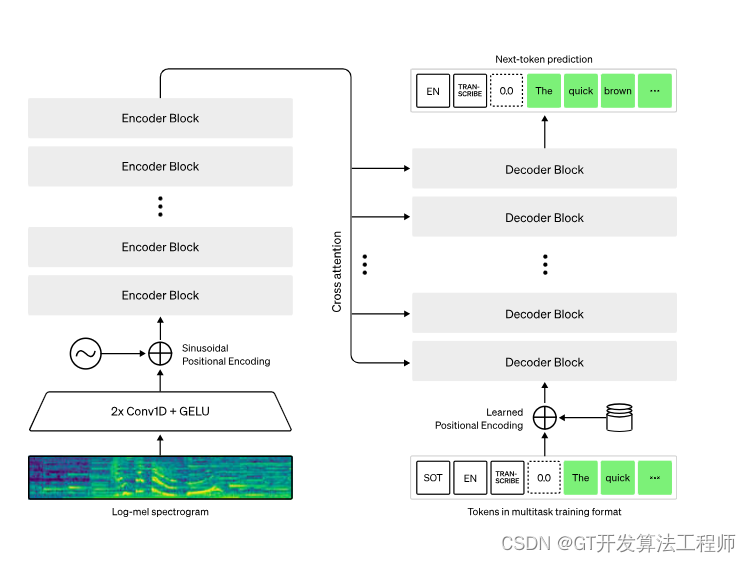
扩展语音识别系统:增强功能与多语言支持
一、引言 在之前的博客中,我们成功构建了一个基于LibriSpeech数据集的英文语音识别系统。现在,我们将对系统进行扩展,增加一些增强功能,并尝试支持多语言识别。 二、增加增强功能
语音合成 --除了语音识别,我们还可以…
多组件卡片式问答引擎
#本篇文章联合同花顺人工智能领域开发者严同学创作
1.简介
为了满足用户个性化需求以及精细化运营,越来越多的企业推出多组件式的卡片问答,这种回答方式不会千篇一律,能够更好地为客户提供服务,帮助客户解决问题。
使用这种问答…
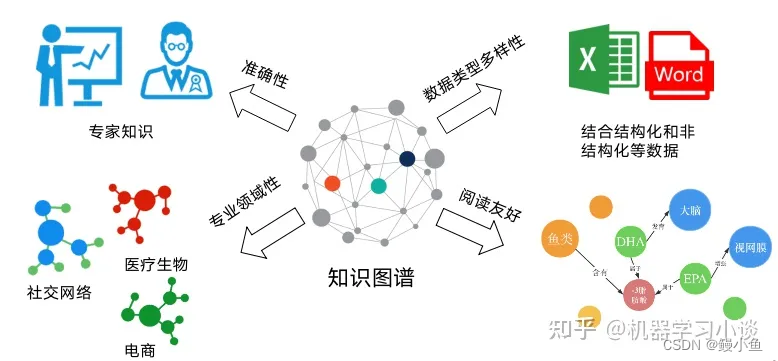
人工智能知识图谱:智慧连接的未来
导言 人工智能知识图谱作为知识管理和智能推理的重要工具,正在为人工智能领域带来革命性的变化。本文将深入研究人工智能知识图谱的发展、技术特点以及对多领域的深远影响。
1. 背景与定义 人工智能知识图谱是一个庞大的知识网络,将实体、关系、…
机器翻译:跨越语言边界的智能大使
导言 机器翻译作为人工智能领域的瑰宝,正在以前所未有的速度和精度,为全球沟通拓展新的可能性。本文将深入研究机器翻译的技术原理、应用场景以及对语言交流未来的影响。
1. 简介 机器翻译是一项致力于通过计算机自动将一种语言的文本翻译成另一种语言的…

四、OpenAI之文本生成模型(Text Generation)
文本生成模型 OpenAI的文本生成模型(也叫做生成预训练的转换器(Generative pre-trained transformers)或大语言模型)已经被训练成可以理解自然语言、代码和图片的模型。模型提供文本的输出作为输入的响应。对这些模型的输入内容也被称作“提示词”。设计提示词的本质是你如何对…

智能家居系统设计(裸机stm32/μCOS-III)
智能家居系统设计[裸机stm32/μCOS-III] 在正式讲解之前,先来总结一下。该项目是对大学学过的部分知识进行整合,同时这也是我大学的毕业设计,也算是对大学的一个交待。 首先来讲述一下该项目具体实现了哪些功能,方便大…
whisper 语音识别项目部署
1.安装anaconda软件 在如下网盘免费获取软件: 链接:https://pan.baidu.com/s/1zOZCQOeiDhx6ebHh5zNasA 提取码:hfnd
2.使用conda命令创建python3.8环境
conda create -n whisper python3.83.进入whisper虚拟环境
conda activate whisper4.…

基于深度学习的语音识别的未来
基于深度学习的语音识别是当前人工智能领域的研究热点之一。随着语音技术的不断发展,语音识别技术将在未来扮演更加重要的角色。
语音识别技术的发展已经有几十年的历史,但是基于深度学习的语音识别技术在近年来才取得了突破性的进展。深度学习技术可以…
2024 AI 辅助研发的新纪年
随着人工智能技术的持续发展与突破,2024年AI辅助研发正成为科技界和工业界瞩目的焦点。从医药研发到汽车设计,从软件开发到材料科学,AI正逐渐渗透到研发的各个环节,变革着传统的研发模式。在这一背景下,AI辅助研发不仅…

AI机器学习 | 基于librosa库和使用scikit-learn库中的分类器进行语音识别
专栏集锦,大佬们可以收藏以备不时之需
Spring Cloud实战专栏:https://blog.csdn.net/superdangbo/category_9270827.html
Python 实战专栏:https://blog.csdn.net/superdangbo/category_9271194.html
Logback 详解专栏:https:/…
Corel会声会影视频编辑软件英文名是Corel VideoStudio2023
Corel会声会影视频编辑软件英文名是Corel VideoStudio2023,可以抓取、编制和导出多种常见的视频格式。介绍整理从早期的会声会影9、会声会影10后到会声会影X系列版本包括X2、X3、X4、X5、X6、X7、X8、X9、X10,2018,2019,2020&…
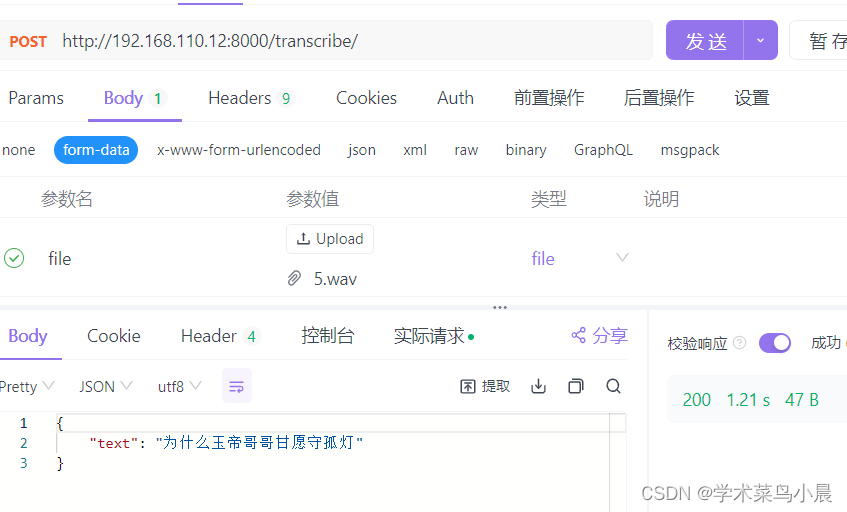
语音识别:whisper部署服务器(远程访问,语音实时识别文字)
Whisper是OpenAI于2022年发布的一个开源深度学习模型,专门用于语音识别任务。它能够将音频转换成文字,支持多种语言的识别,包括但不限于英语、中文、西班牙语等。Whisper模型的特点是它在多种不同的音频条件下(如不同的背景噪声水…
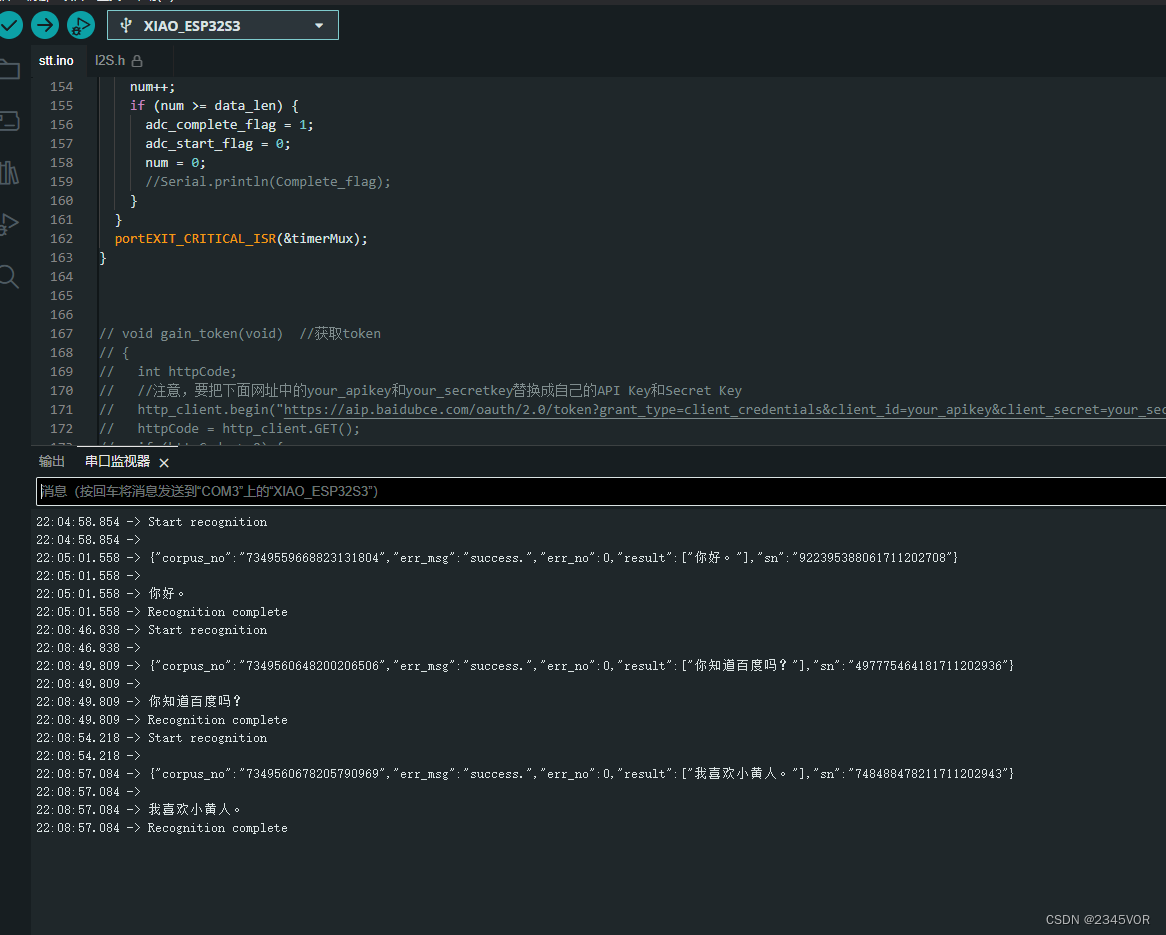
【ESP32S3 Sense接入百度在线语音识别】
视频地址: ESP32S3 Sense接入百度在线语音识别 1. 前言 使用Seeed XIAO ESP32S3 Sense开发板接入百度智能云实现在线语音识别。自带麦克风模块用做语音输入,通过串口发送字符“1”来控制数据的采集和上传。 步骤概括 (1) 在百度云控制端选择“语音…
LPC/LSP/LSF辨析
我们在阅读语音或者数字信号处理的论文书籍时经常会遇到LPC,LSF和LSP这些和线性预测相关的名词,刚接触时容易一头雾水,今天我们就介绍下它们之间的关系。
LPC/LSP/LSF
线性预测编码(Linear Predictive coding ,LPC),是一种用于语音信号压缩和分析的方法。在LPC模型中,…
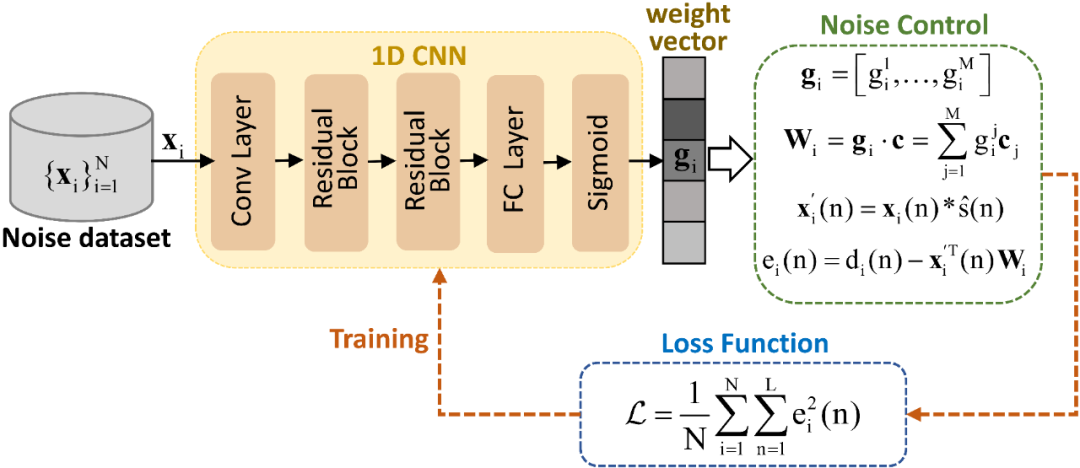
南洋理工大学NTU-生成式有源噪声控制GFANC
最近南洋理工大学DSP实验在TASLP,SPL,ICASSP上发表了生成式固定滤波器主动噪声控制(Deep Generative Fixed-filter Active Noise Control, GFANC) 的相关文章。这些研究侧重于探索实用性强的AI ANC (Active Noise control)方法,将AI技术与传统…
AI孙燕姿 ?AI东雪莲 !—— 本地部署DDSP-SVC一键包,智能音频切片,本地训练,模型推理,为你喜欢的角色训练AI语音模型小教程
目录
感谢B站UP羽毛布团
演示视频
稻香——东雪莲
虚拟——东雪莲
反方向的钟——东雪莲
晴天龙卷风——东雪莲
DDSP-SVC 3.0 (D3SP) 是什么?
下载资源:
解压整合包
准备数据集
智能音频切片
数据集准备
填写训练设置和超参数 开始训练
推…
文字转语音:语音合成(Speech Synthesis) 数组文字循环播放
前言:
HTML5中和Web Speech相关的API实际上有两类,一类是“语音识别(Speech Recognition)”,另外一个就是“语音合成(Speech Synthesis)”, 这两个名词实际上指的分别是“语音转文字”,和“文字变语音”。 speak() –…
使用 LinkAi 打造自己的知识库和数字人
其他系列文章导航 Java基础合集数据结构与算法合集 设计模式合集 多线程合集 分布式合集 ES合集 文章目录
其他系列文章导航
文章目录
前言
一、LinkAi 介绍
二、文档库
2.1 创建知识库
2.2 配置知识库
2.3 Ai配置
2.4 导入文档
2.5 接入微信
三、扩展
四、总结…
![[Deep Learning 译文] LeCun、Bengio和Hinton三大牛的联合综述(上)](http://img.ptcms.csdn.net/article/201506/01/556b858e8685e_middle.jpg?_=4335)
[Deep Learning 译文] LeCun、Bengio和Hinton三大牛的联合综述(上)
英文原文链接:Deep Learning 三大牛人 联合综述 译文下篇链接:[Deep Learning 译文] LeCun、Bengio和Hinton三大牛的联合综述(下) 【翻译】本文为该综述文章中文译文的上半部分,深入浅出地介绍了深度学习的基本原理和…
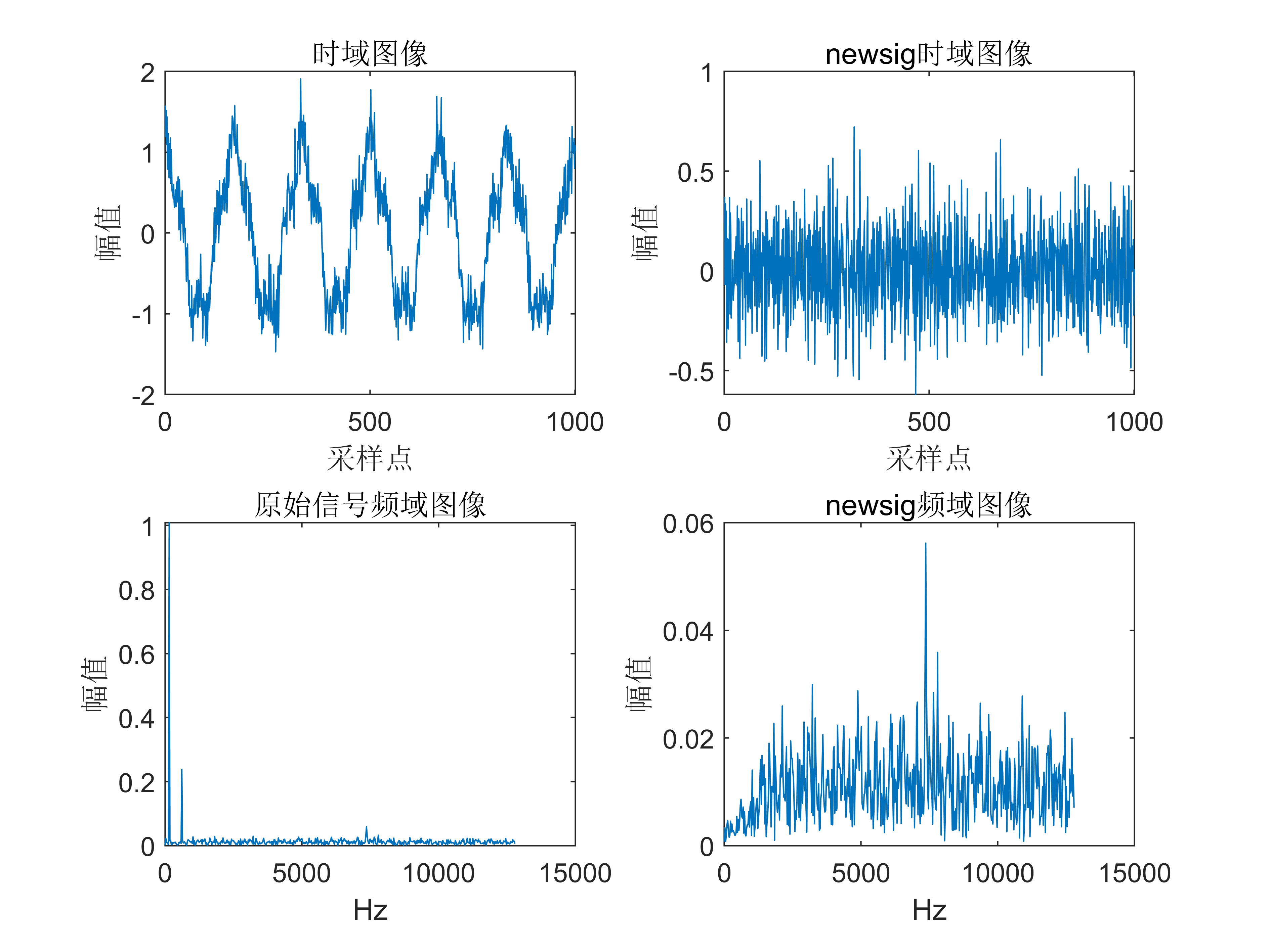
【MATLAB】VMD分解+FFT+HHT组合算法
有意向获取代码,请转文末观看代码获取方式~也可转原文链接获取~
1 基本定义
VMD(Variational Mode Decomposition)是一种信号分解方法,基于HHT(Hilbert-Huang Transform,希尔伯特-黄变换)。HH…

ICASSP2024 | ICMC-ASR 车载多通道语音识别挑战赛总结
为促进驾驶场景中语音处理和识别研究,在ISCSLP 2022上成功举办智能驾驶座舱语音识别挑战 (ICSRC)的基础上,西工大音频语音与语言处理研究组 (ASLPNPU)联合理想汽车、希尔贝壳、WeNet社区、字节、微软、天津大学、南洋理工大学以及中国信息通信研究院等多…
ICASSP2023 | TEA-PSE 3.0: 深度噪声抑制(DNS)竞赛个性化语音增强冠军方案解读
实时通信 (RTC) 在我们的日常生活中变得不可或缺,诸如腾讯会议在内的语音RTC应用已经成为我们日常使用的在线交流工具。然而在通话过程中,语音质量受到背景噪声、混响、干扰说话人等多种干扰的显著影响。因此语音增强技术在 RTC 链路中起着至关重要的作用…
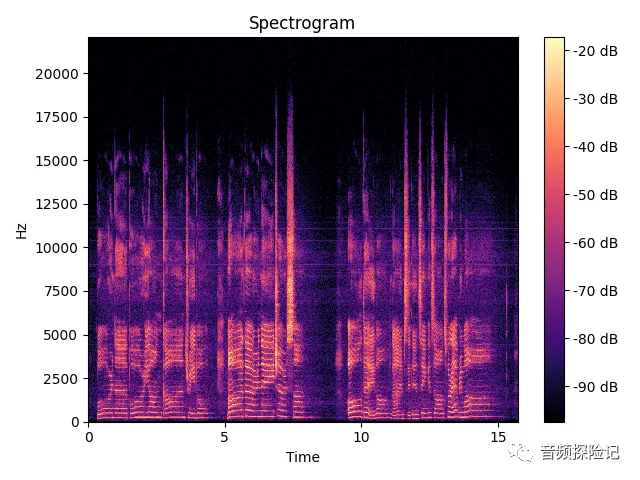
语谱图(一) Spectrogram 的定义与机理
1. 语谱图 spectrogram
在音频、语音信号处理领域,我们需要将信号转换成对应的语谱图(spectrogram),将语谱图上的数据作为信号的特征。
语谱图的横坐标是时间,纵坐标是频率,坐标点值为语音数据能量。由于是采用二维平面表达三维…
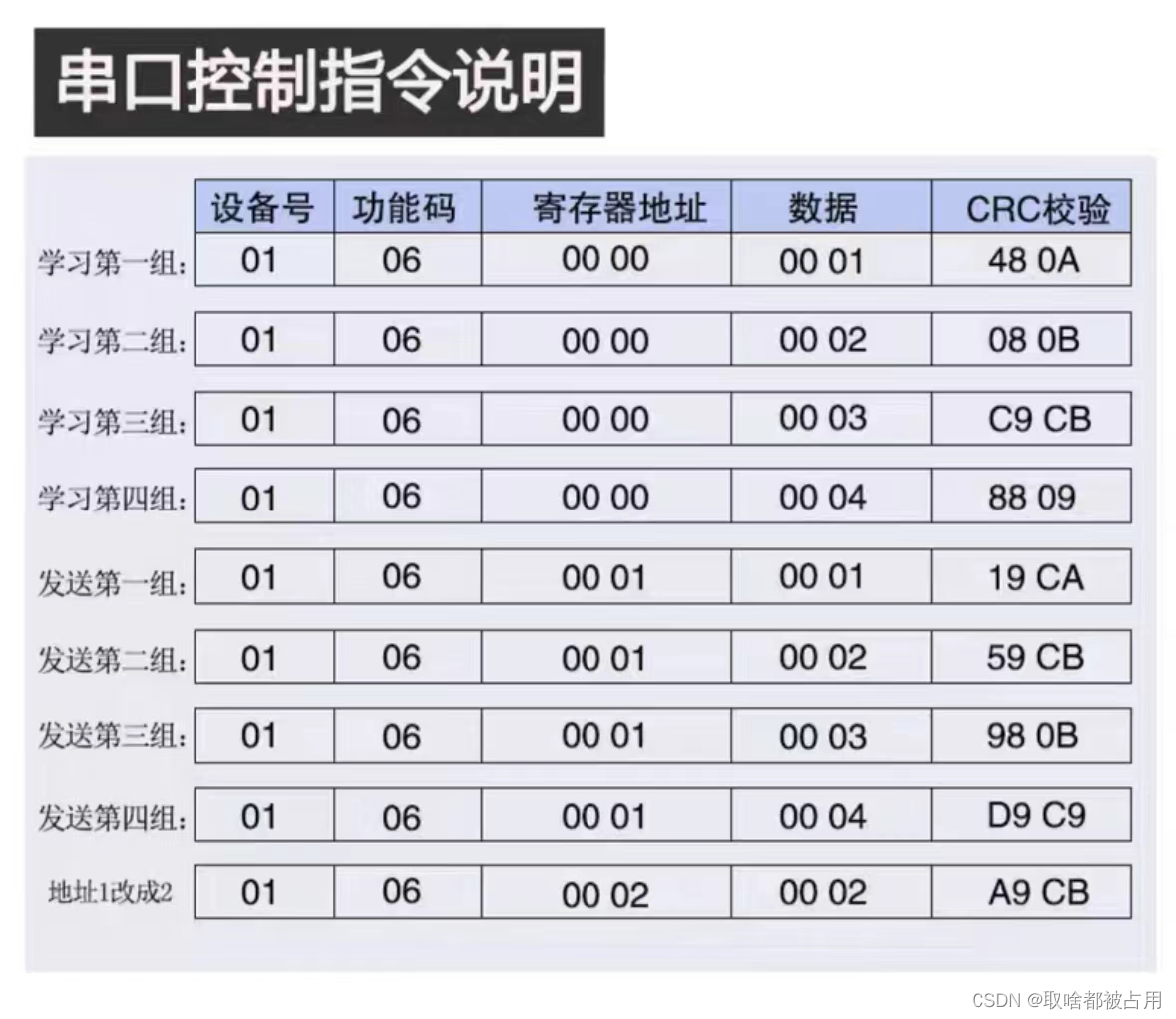
【开个空调】语音识别+红外发射
废话少说,直接上空调板子:YAPOF3。红外接收发射模块用的某宝上发现的YF-33(遗憾解码还没搞清楚,不然做个lirc.conf功能才多)。最后是语音识别用的幻尔的,某宝自然也有,它是个i2c的接口。 本篇胡说八道其实纯粹为了留个…