chatgpt专题
vue.js
qt
批量重命名
NAND
powershell
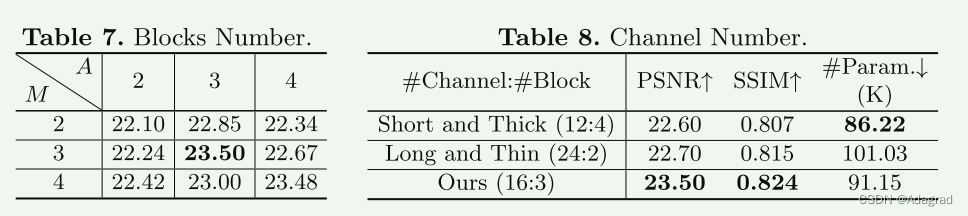
知识蒸馏
终端
iot
美食分享系统
harbor
eureka
恢复显示屏异常显示的方法
skill command
控制浏览器的方式
批量替换
语音小夜灯IC
主从复制
申博
语音信号处理
transformer
2024/4/11 15:10:07
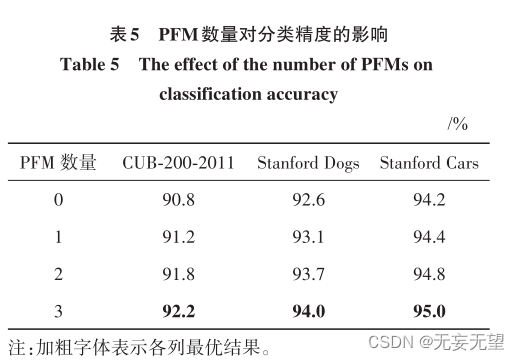
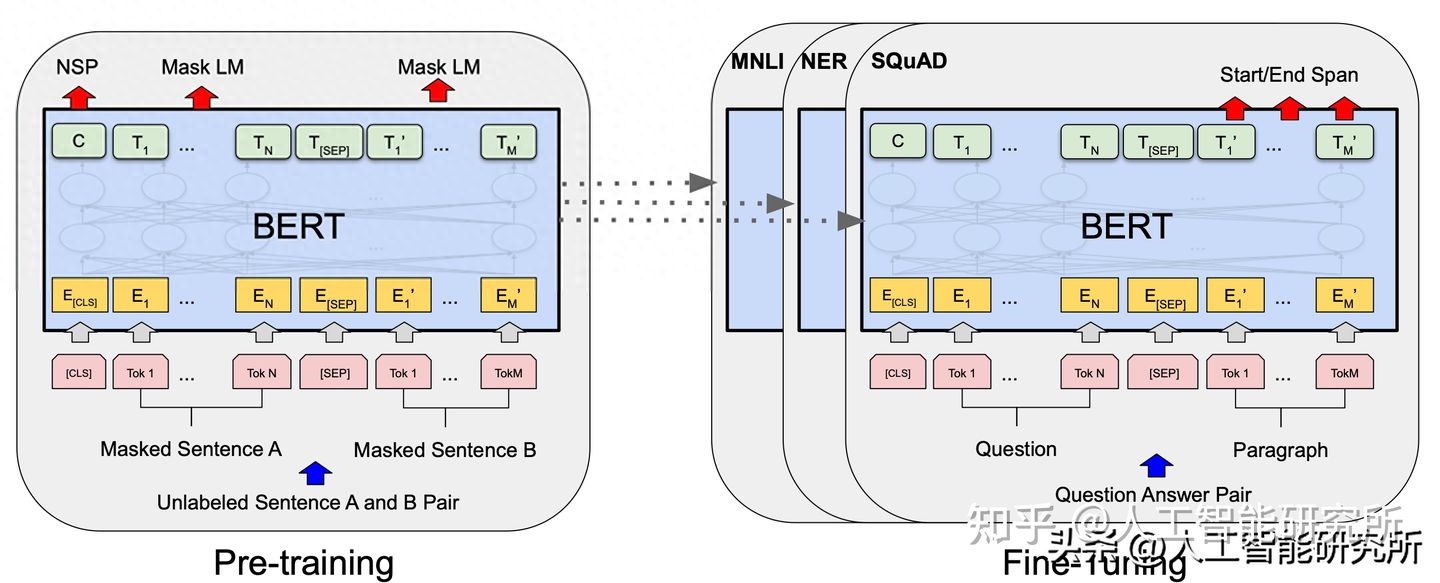
ChatGPT基础组件Transformer的代码实现(纯净版Transformer实现)
最近ChatGPT大火,其实去年11月份就备受关注了,最近火出圈了,还是这家伙太恐怖了,未来重复性的工作很危险。回归主题,ChatGPT就是由无数个(具体也不知道多少个,哈哈哈哈)Transformer语…

自然语言处理---Transformer机制详解之Self attention机制详解
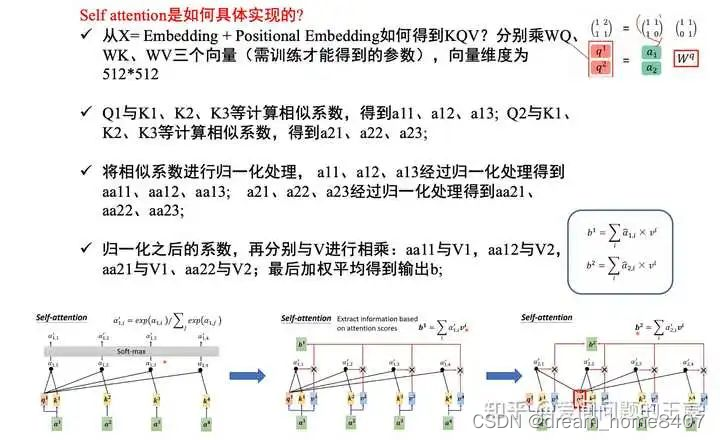
1 Self-attention的特点
self-attention是一种通过自身和自身进行关联的attention机制, 从而得到更好的representation来表达自身.
self-attention是attention机制的一种特殊情况,在self-attention中, QKV, 序列中的每个单词(token)都和该序列中的其他所有单词(to…

MS-Model【3】:Medical Transformer
文章目录前言1. Abstract & Introduction1.1. Abstract1.2. Introduction2. Medical Transformer (MedT)2.1. Model structure2.2. Attention2.2.1. Self-Attention Overview2.2.2. Axial-Attention2.2.3. Gated Axial-Attention2.3. Local-Global Training2.4. Loss funct…
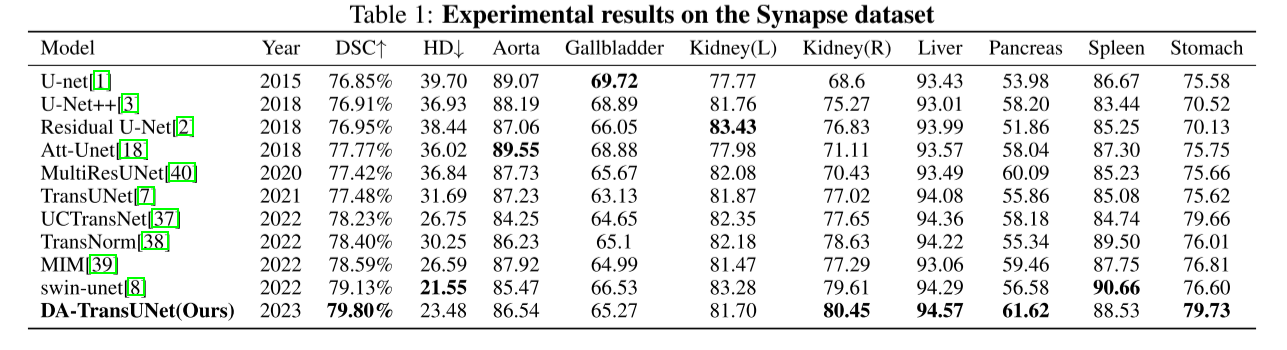
Da-transunet:将空间和通道双重关注与Transformer u-net相结合用于医学图像分割
DA-TRANSUNET: INTEGRATING SPATIAL AND CHANNEL DUAL ATTENTION WITH TRANSFORMER U-NET FOR MEDICAL IMAGE SEGMENTATION 1、方法1.1 模型1.2 双注意力模块(DA-Block)1.2.1 PAM( 位置注意力模块)1.2.2 CAM(通道注意力…

新闻文本分类任务:使用Transformer实现
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…

【nlp】3.2 Transformer论文复现:1. 输入部分(文本嵌入层和位置编码器)
Transformer论文复现:输入部分(文本嵌入层和位置编码器) 1 输入复现1.1 文本嵌入层1.1.1 文本嵌入层的作用1.1.2 文本嵌入层的代码实现1.1.3 文本嵌入层中的注意事项1.2 位置编码器1.2.1 位置编码器的作用1.2.2 位置编码器的代码实现1.2.3 位置编码器中的注意事项1 输入复现…
自然语言处理的bert, GPT, GPT-2, transformer, ELMo, attention机制都是些何方神圣???
2018年是NLP领域巨变的一年,这个好像我们都知道,但是究竟是哪里剧变了,哪里突破了?经常听大佬们若无其事地抛出一些高级的概念,你却插不上嘴,隐隐约约知道有这么个东西,刚要开口:噢&…

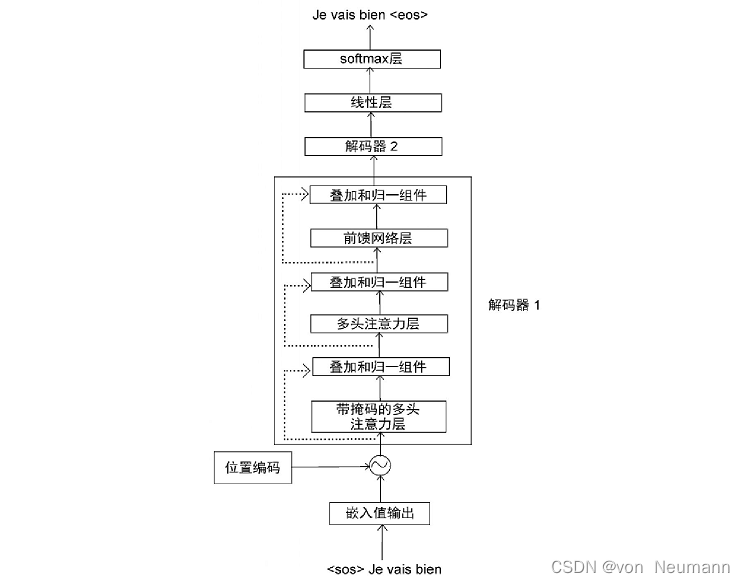
【nlp】3.5 Transformer论文复现:3.解码器部分(解码器层)和4.输出部分(线性层、softmax层)
Transformer论文复现:3.解码器部分(解码器层)和4.输出部分(线性层、softmax层) 3.1 解码器介绍3.2 解码器层3.2.1 解码器层的作用3.2.2 解码器层的代码实现3.2.3 解码器层总结3.3 解码器3.3.1 解码器的作用3.3.2 解码器的代码实现3.3.3 解码器总结4.1 输出部分介绍4.2 线性…
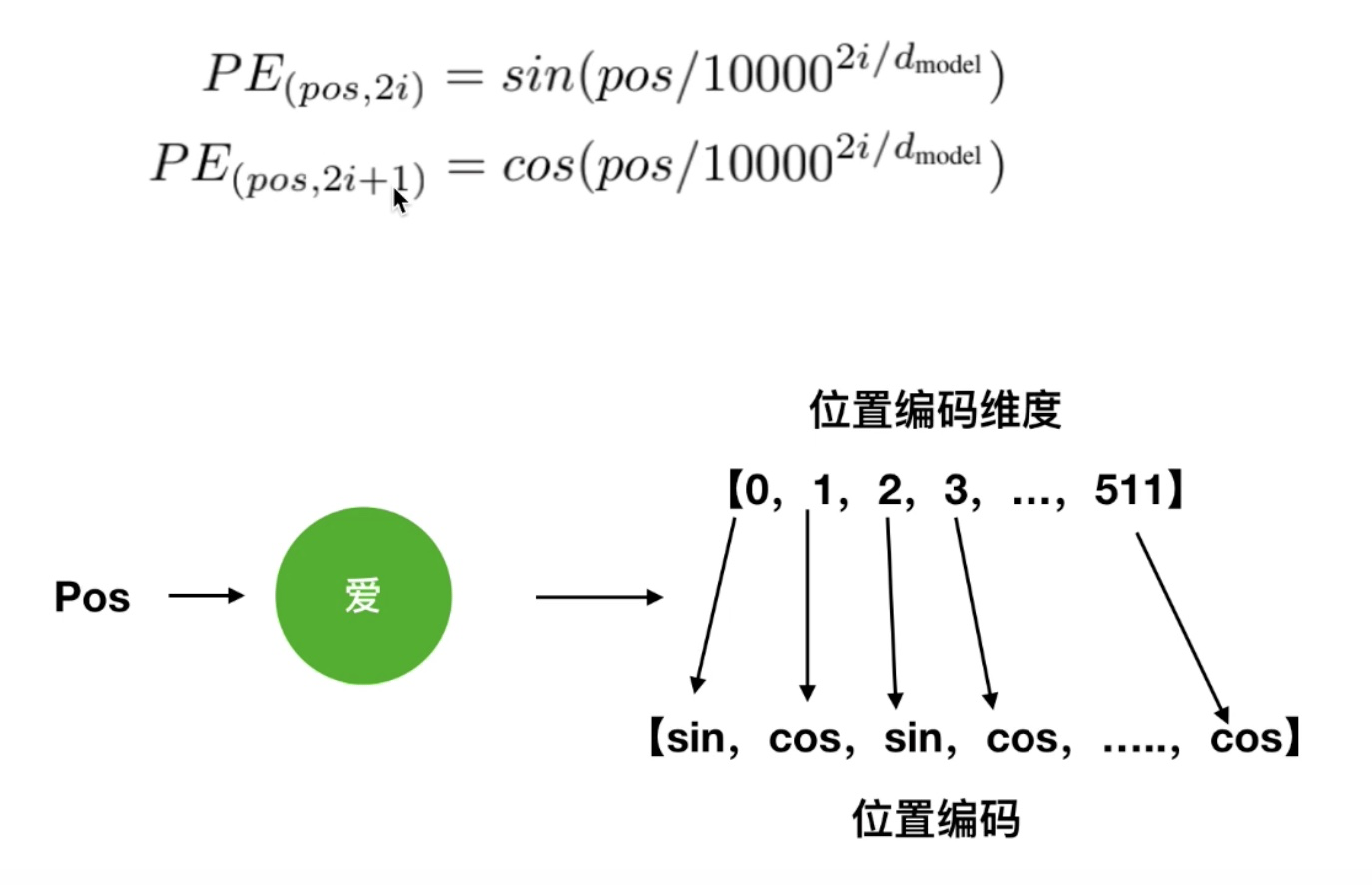
1401 位置编码公式详细理解补充
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html Self-Attention:对于每…

【HuggingFace Transformer库学习笔记】基础组件学习:pipeline
一、Transformer基础知识 pip install transformers datasets evaluate peft accelerate gradio optimum sentencepiece
pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge在host文件里添加途中信息,可以避免运行代码下载模型时候报错…
第86步 时间序列建模实战:Transformer回归建模
基于WIN10的64位系统演示
一、写在前面
这一期,我们介绍Transformer回归。
同样,这里使用这个数据:
《PLoS One》2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal Sy…
Transformer模型 | 基于双向时空自适应Transformer的城市交通流预测
城市交通流预测是智能交通系统的基石。现有方法侧重于时空依赖建模,而忽略了交通预测问题的两个内在特性。首先,不同预测任务的复杂性在不同的空间(如郊区与市中心)和时间(如高峰时段与非高峰时段)上分布不均匀。其次,对过去交通状况的回忆有利于对未来交通状况的预测。基于…
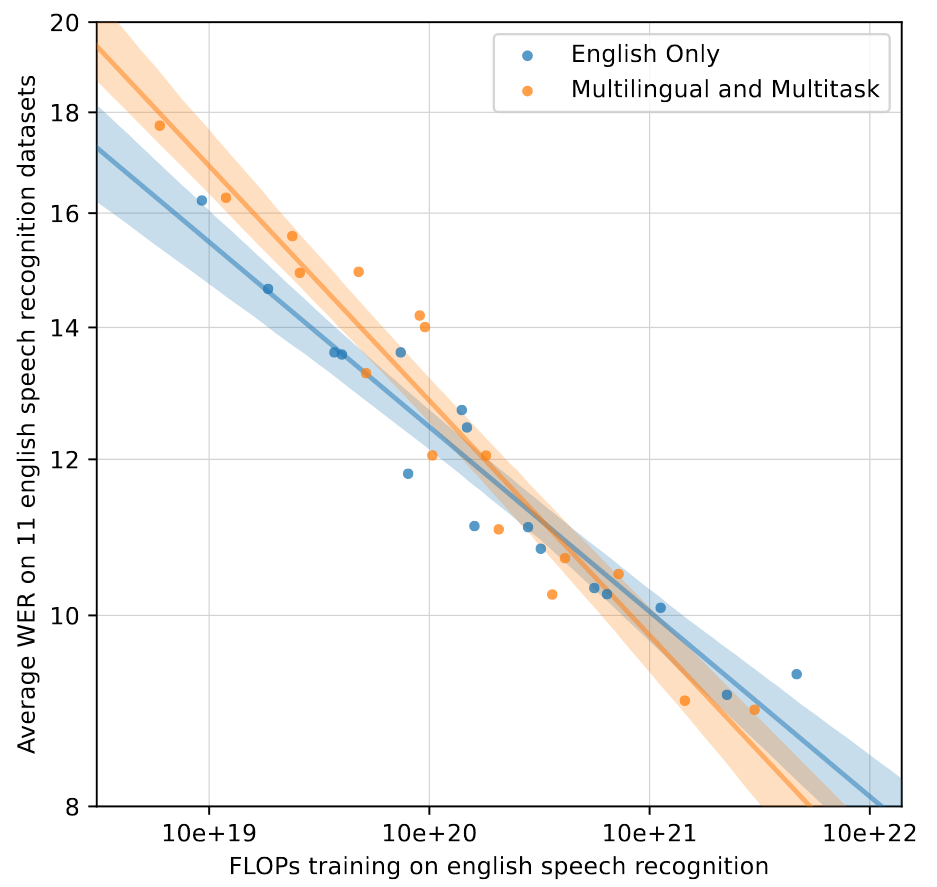
【论文精读】Robust Speech Recognition via Large-Scale Weak Supervision
Robust Speech Recognition via Large-Scale Weak Supervision 前言Abstract1. Introduction2. Approach2.1. Data Processing2.2. Model2.3. Multitask Format2.4. Training Details 3. Experiments3.1. Zero-shot Evaluation3.2. Evaluation Metrics3.3. English Speech Reco…
Transformer模型 | Transformer时间序列预测,单步、多步(Python)
(1)原理
Transformer框架原本是为NLP任务,特别是机器翻译而设计的。但由于其独特的自注意力机制,Transformer在处理顺序数据时表现出色,因此被广泛应用于各种序列数据任务,包括回归任务。
(a)回归任务中的Transformer:
(a1)在回归任务中,Transformer可以捕捉数据…
Lstm+transformer的刀具磨损预测
视频讲解:
基于Lstm+transformer的刀具磨损预测实战_哔哩哔哩_bilibili
结果展示: 数据展示: 主要代码:
# pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple/
# pip install optuna -i https://pypi.tuna.tsinghua.edu.cn/simple/
import numpy as np…
记录:自回归 模型在记忆 全随机序列 的潜变量 统计量爆炸现象
只是一个记录
8层12头512维度的 GPT 模型,使用它来记忆 10000 条 512长度 的无序序列,vocab_size 为100。
模型要自回归生成这些序列,不可能依赖局部推理,必须依赖全局视野,即记住前面的序列。
然后统计 最后一个no…
机器学习笔记 - 数据科学中基于 Scikit-Learn、Tensorflow、Pandas 和 Scipy的7种最常用的特征工程技术
一、概述 特征工程描述了制定相关特征的过程,这些特征尽可能准确地描述底层数据科学问题,并使算法能够理解和学习模式。换句话说:您提供的特征可作为将您自己对世界的理解和知识传达给模型的一种方式。 每个特征描述一种信息“片段”。这些部分的总和允许算法得出有关目标变…
【nlp】3.1 Transformer背景介绍及架构
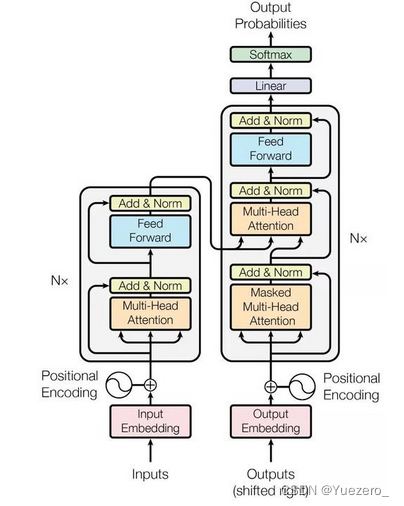
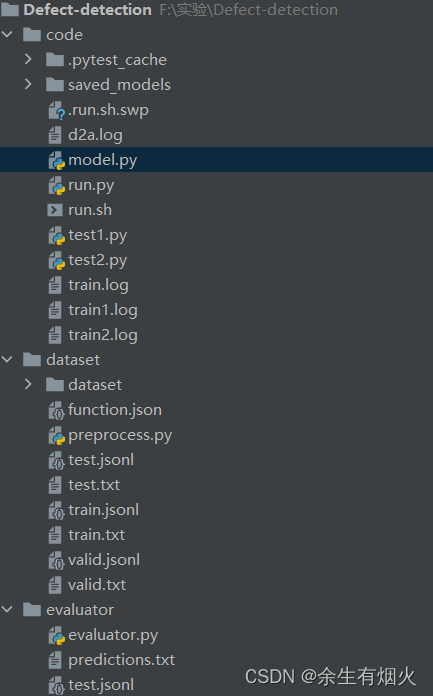
Transformer背景介绍 1 Transformer的诞生2 Transformer的优势3 Transformer的市场4 Transformer架构4.1 Transformer模型的作用4.2 Transformer总体架构图4.2.1 输入部分4.2.2 输出部分包含4.2.3 编码器部分4.2.4 解码器部分1 Transformer的诞生
2018年10月,Google发出一篇论…
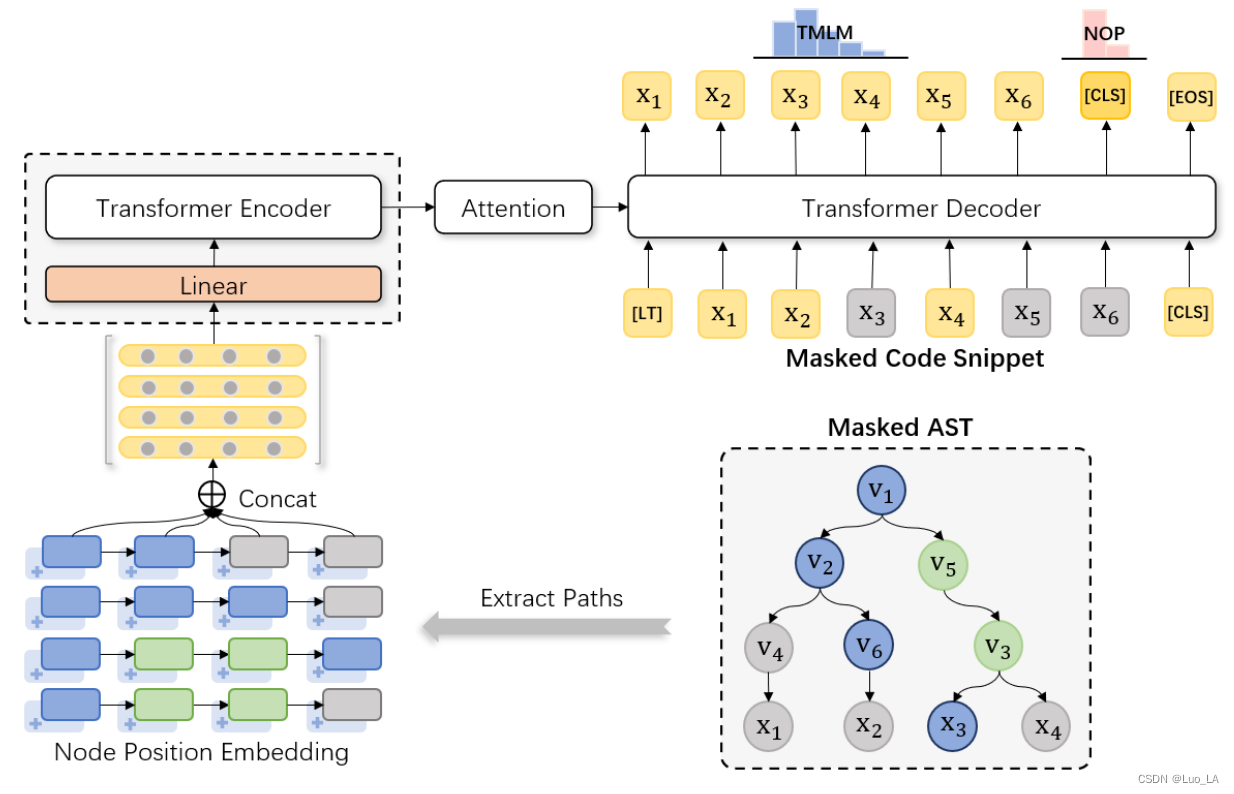
TreeBERT:基于树的编程语言预训练模型。
TreeBERT
https://arxiv.org/abs/2105.12485
Comments: Accepted by UAI2021 Subjects: Machine Learning (cs.LG); Programming Languages (cs.PL) Cite as: arXiv:2105.12485 [cs.LG]
1 Introduction
现有挑战: 设计适当的机制来学习程序的语法结构 代码是强结…
DINO训练自己的数据集(swin transformer backbone)
源码:https://github.com/IDEA-Research/DINO
数据集:coco格式
COCODIR/├── train2017/├── val2017/└── annotations/├── instances_train2017.json└── instances_val2017.json
环境配置
1. 下载代码
git clone https://github.com/…

基于Vision Transformer的图像去雾算法研究与实现(附源码)
基于Vision Transformer的图像去雾算法研究与实现
0. 服务器性能简单监控
\LOG_USE_CPU_MEMORY\文件夹下的use_memory.py文件可以实时输出CPU使用率以及内存使用率,配合nvidia-smi监控GPU使用率
可以了解服务器性能是否足够;运行时在哪一步使用率突然…
Transformer模型 | Transformer模型原理
基本原理
Transformer 是一种使用注意力机制(attention mechanism)的神经网络模型,能够有效地处理序列数据,如句子或文本。
它的设计灵感来自于人类在理解上下文时的方式。
简单来说,Transformer 会将输入的序列分成若干个小块,并通过计算注意力得分来决定每个块在输出…

【Pytorch】Transformer原理及其Pytorch实现
Seq-to-Seq (encoderattentiondecoder) CNN RNN transformer
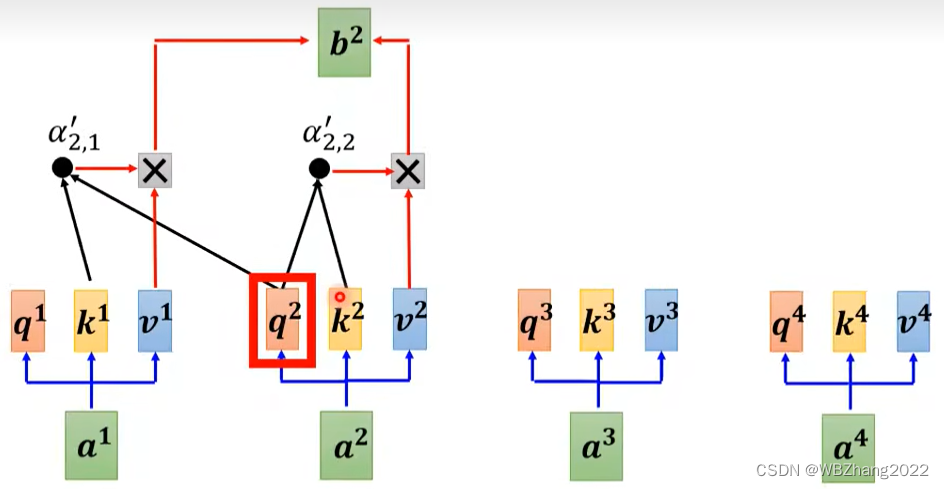
Transformer class Transformer α1{\alpha}_1α1就是q1q_1q1和k1k_1k1做点积然后softmax得到。
self-attention 以q2q_2q2为例 q2q_2q2和别的kkk做点积,得到α1....αm{\alpha}_1...…

【Transformer论文】用于 TextVQA 的指针增强多模态变换器的迭代答案预测
文献题目:Iterative Answer Prediction with Pointer-Augmented Multimodal Transformers for TextVQA文献时间:2020
摘要
许多视觉场景包含带有关键信息的文本,因此理解图像中的文本对于下游推理任务至关重要。例如,警告标志上…
【Transformer论文】CMKD:用于音频分类的基于 CNN/Transformer 的跨模型知识蒸馏
文献题目:CMKD: CNN/Transformer-Based Cross-Model Knowledge Distillation for Audio Classification文献时间:2022
摘要
音频分类是一个活跃的研究领域,具有广泛的应用。 在过去十年中,卷积神经网络 (CNN) 已成为端到端音频分…
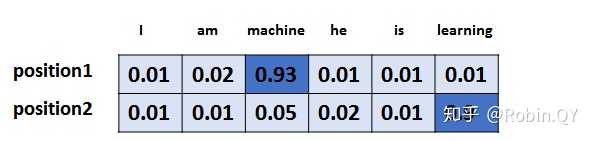
17 Transformer 的解码器(Decoders)——我要生成一个又一个单词
Transformer 编码器
编码器在干吗:词向量、图片向量,总而言之,编码器就是让计算机能够更合理地(不确定性的)认识人类世界客观存在的一些东西
Transformer 解码器
解码器会接收编码器生成的词向量,然后通…
YoloV8改进策略:EfficientViT,高效的视觉transformer与级联组注意力提升YoloV8的速度和精度,打造高效的YoloV8
文章目录 摘要论文:《EfficientViT:高效视觉transformer与级联组注意力》1、简介2、用视觉transformer加速2.1. 内存效率2.2. 计算效率2.3. 参数效率3、高效视觉Transformer3.1. EfficientViT的构建块3.2、EfficientViT网络架构4、实验4.1. 实现细节4.2. ImageNet上的结果4.3…
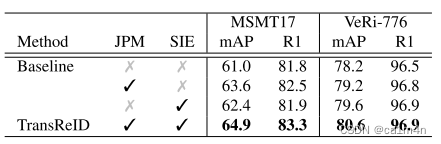
TransReID | 首次将transformer应用于行人重识别
0x00 什么是Transformer
Transformer由Attention is all you need论文提出。
摘要
优势的序列转换模型基于复杂的递归或卷积神经网络,包括一个编码器和一个解码器。性能最好的模型还通过注意力机制连接编码器和解码器。我们提出了一种新的简单网络架构࿰…
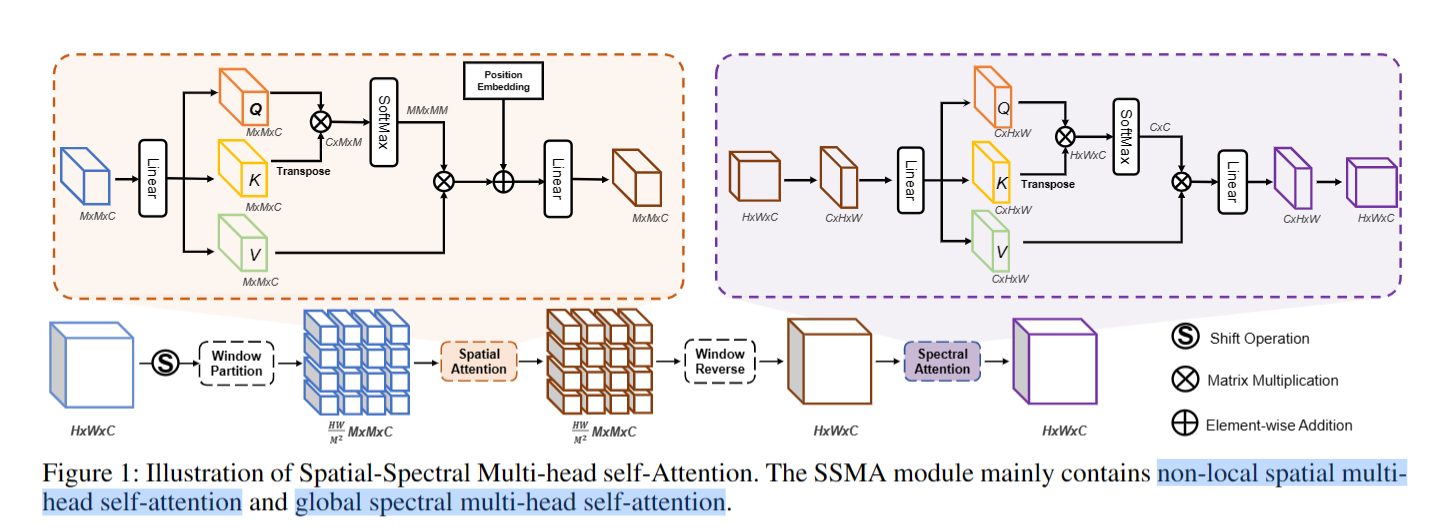
【AAAI2023】Spatial-Spectral Transformer for Hyperspectral Image Denoising
论文:https://readpaper.com/paper/4694783227240398849 代码:https://github.com/MyuLi/SST 1、总体介绍
高光谱图像(HSI)去噪是后续HSI应用的关键预处理过程,但是基于CNN的方法需要在计算效率与非局部特征建模能力之…

全套解决方案:基于pytorch、transformers的中文NLP训练框架,支持大模型训练和文本生成,快速上手,海量训练数据!
全套解决方案:基于pytorch、transformers的中文NLP训练框架,支持大模型训练和文本生成,快速上手,海量训练数据!
1.简介
目标:基于pytorch、transformers做中文领域的nlp开箱即用的训练框架,提…
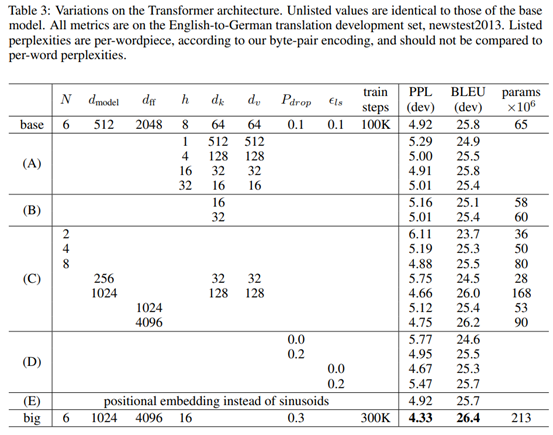
【深度学习】Transformer简介
近年来,Transformer模型在自然语言处理(NLP)领域中横扫千军,以BERT、GPT为代表的模型屡屡屠榜,目前已经成为了该领域的标准模型。同时,在计算机视觉等领域中,Transformer模型也逐渐得到了重视&a…

【万字长文】深度解析 Transformer 和注意力机制(含完整代码实现)
深度解析 Transformer 和注意力机制 在《图解NLP模型发展:从RNN到Transformer》一文中,我介绍了 NLP 模型的发展演化历程,并用直观图解的方式为大家展现了各技术的架构和不足。有读者反馈图解方式虽然直观,但深度不足。考虑到 Tra…

Yolov8轻量化:EMO,结合 CNN 和 Transformer 的现代倒残差移动模块设计,性能优于EdgeViT、Mobile-former等网络
论文: https://arxiv.org/pdf/2301.01146.pdf 🏆🏆🏆🏆🏆🏆Yolo轻量化模型🏆🏆🏆🏆🏆🏆 重新思考了 MobileNetv2 中高效的倒残差模块 Inverted Residual Block 和 ViT 中的有效 Transformer 的本质统一,归纳抽象了 MetaMobile Block 的一般…
LSTM已死,Transformer永生(面试问答RNN/LSTM/Transformer)
计算机视觉面试题-Transformer相关问题总结:https://zhuanlan.zhihu.com/p/554814230 计算机视觉面试31题 CV面试考点,精准详尽解析:https://zhuanlan.zhihu.com/p/257883797
1. 循环神经网络(Recurrent Neural Networks, RNN&am…
gradio使用transformer模块demo介绍1:Text Natural Language Processing
文章目录 文本生成 Text Generation自动完成 Autocomplete情感分析 Sentiment Analysis命名实体识别 Name Entity Recognition NER多语种翻译文本生成 Text Generation
import gradio as gr
from transformers import pipelinegenerator = pipeline(text-generation, model=&l…
深度学习一点通:PyTorch Transformer 预测股票价格,虚拟数据,chatGPT同源模型
预测股票价格是一项具有挑战性的任务,已引起研究人员和从业者的广泛关注。随着深度学习技术的出现,已经提出了许多模型来解决这个问题。其中一个模型是 Transformer,它在许多自然语言处理任务中取得了最先进的结果。在这篇博文中,…
chatgpt技术总结(包括transformer,注意力机制,迁移学习,Ray,TensorFlow,Pytorch)
最近研读了一些技术大咖对chatgpt的技术研讨,结合自己的一些浅见,进行些许探讨。 我们惊讶的发现,chatgpt所使用的技术并没有惊天地泣鬼神的创新,它只是将过去的技术潜能结合现在的硬件最大化的发挥出来,也正因如此&am…
Transformer模型 | Transformer模型描述
谷歌推出的BERT模型在11项NLP任务中夺得SOTA结果,引爆了整个NLP界。而BERT取得成功的一个关键因素是Transformer的强大作用。谷歌的Transformer模型最早是用于机器翻译任务,当时达到了SOTA效果。Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快…
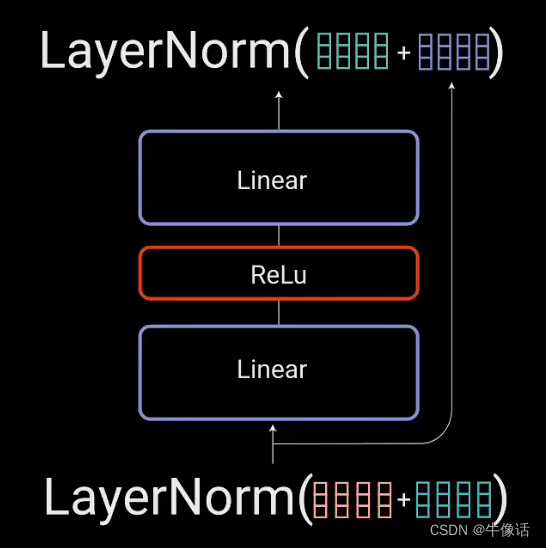
Transformer——encoder
本文参考了b站的Eve的科学频道中的深入浅出解释Transformer原理和DASOU讲AI中的Transformer从零详解。 入浅出解释Transformer原理 Transformer从零详解
前言:
在自然语言识别中,之前讲过lstm,但是lstm有明显的缺陷,就是当文本过…

从统计语言模型到预训练语言模型---预训练语言模型(Transformer)
预训练模型的概念在计算机视觉领域并不陌生, 通常我们可以在大规模图像数据集上预先训练出一个通用 模型, 之后再迁移到类似的具体任务上去, 这样在减少对图像样本需求的同时, 也加速了模型的开发速度。计 算机视觉领域采用 Image…
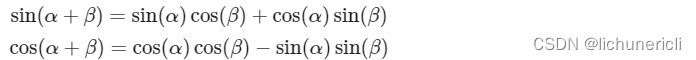
自然语言处理---Tr ansformer机制详解之Transformer结构
1 Encoder模块
1.1 Encoder模块的结构和作用
经典的Transformer结构中的Encoder模块包含6个Encoder Block.每个Encoder Block包含一个多头自注意力层,和一个前馈全连接层.
1.2 Encoder Block
在Transformer架构中,6个一模一样的Encoder …

P12-Retentive NetWork-RetNet挑战Transformer
论文地址:https://arxiv.org/abs/2307.08621 目录 Abstract
一.Introduction
二.Retentive Networks
2.1Retention
2.2Gated Multi-Scale Retention
2.3Overall Architecture of Retention Networks
2.4Relation to and Differences from Previous Methods
三.Experime…
Transformer中的多头注意力机制-为什么需要多头?
Transformer为什么使用多头注意力机制呢?
多头可以学习到不同维度的特征和信息。为什么可以学习到不同维度的信息呢?
答案是:多头注意力机制的组成是有单个的self attention,由于self attention通过产生QKV矩阵来学习数据特征&a…
使用 Transformer 模型进行自然语言处理
自然语言处理是一项重要的人工智能技术,旨在帮助计算机理解人类语言。在过去的几年中,Transformer 模型已经成为自然语言处理领域的一种非常流行的模型。在本文中,我们将介绍 Transformer 模型的原理和实现,并展示如何使用 Transf…
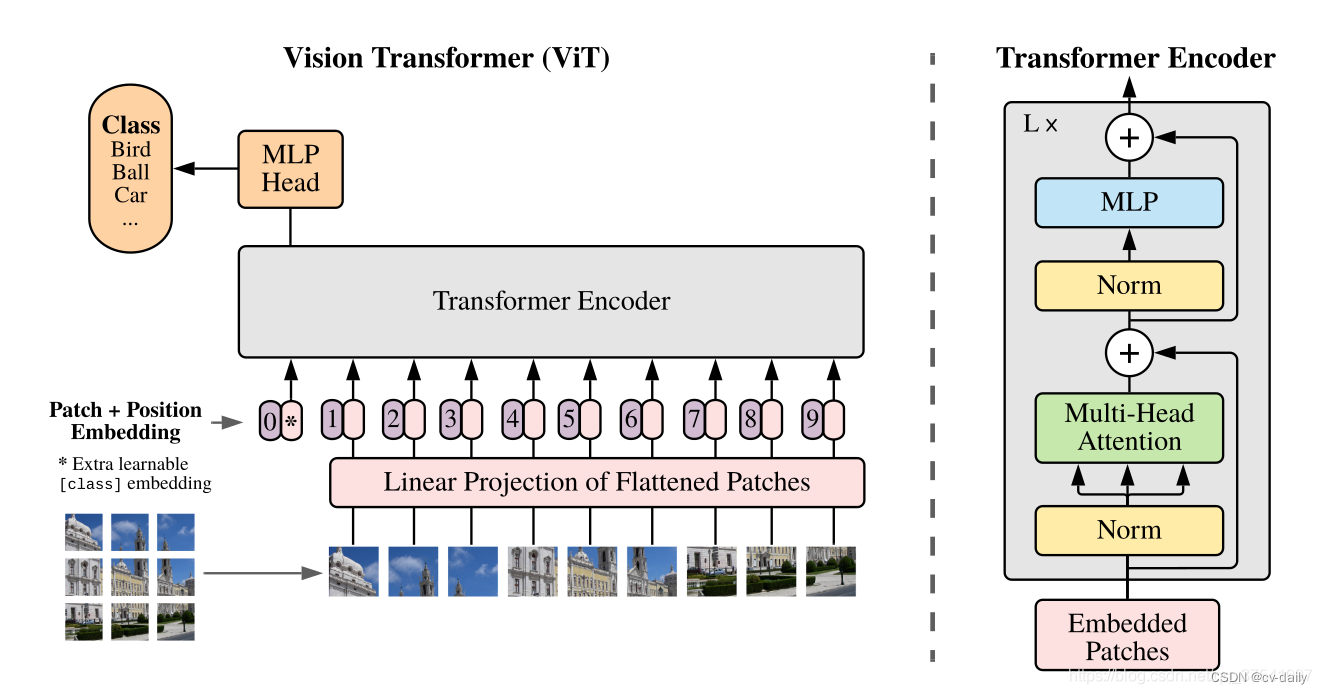
VIT 和Swin Transformer
VIT:https://blog.csdn.net/qq_37541097/article/details/118242600 Swin Transform:https://blog.csdn.net/qq_37541097/article/details/121119988 一、VIT 模型由三个模块组成: Linear Projection of Flattened Patches(Embedding层) Tran…
【10大专题,2.8w字详解】:从张量开始到GPT的《动手学深度学习》要点笔记
🚀 《动手学深度学习PyTorch版》复习要点全记录 📘 🎯 专注于查漏补缺、巩固基础,这份笔记将带你深入理解深度学习的核心概念。通过一系列精心整理的小专题,逐步构建起你的AI知识框架。 🧠 从最基础的张量操…

Vision Transformer(ViT) 2: 应用及代码讲解
文章目录1. 代码讲解1.1 PatchEmbed类1)__init__ 函数2) forward 过程1.2 Attention类1)__init__ 函数2)forward 过程1.3 MLP类1)__init__ 函数2)forward函数1.4 Block类1)__init__ 函数2)forwa…

Word2Pix: Word to Pixel Cross Attention Transformer in Visual Grounding,2021
**本文内容仅代表个人理解,如有错误,欢迎指正**
1. Problem
本篇论文主要解决的问题:将query编码成一个holistic sentence embedding,忽略了每个词对于Visual grounding框选的重要性,从而降低了模型的…
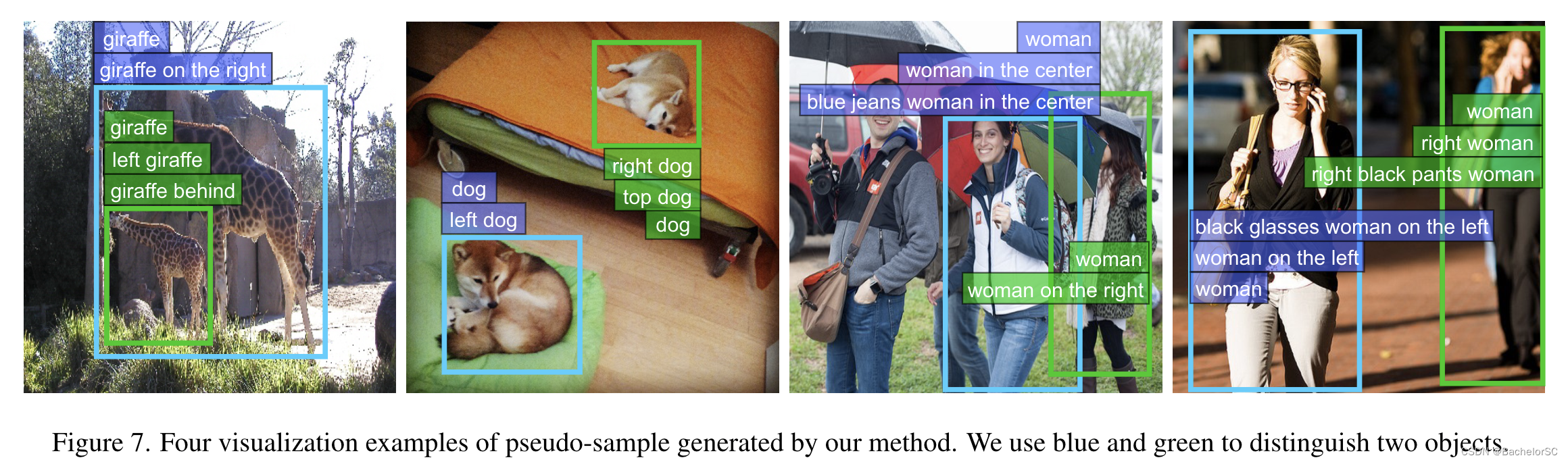
Pseudo-Q: Generating Pseudo Language Queries for Visual Grounding, 2022 CVPR
**本文内容仅代表个人理解,如有错误,欢迎指正**
1. Problem & Background Information
1.1 Problem
- 目前,人们基本上都采用基于深度学习的方法来解决Visual grounding任务。不论是全监督学习还是弱监督学习,都十分依赖人…

Vision Transformer(ViT)论文解读与代码实践(Pytorch)
Vision Transformer
Vision Transformer(ViT)是一种基于Transformer架构的神经网络模型,用于处理计算机视觉任务。传统的计算机视觉模型如卷积神经网络(CNN)在处理图像任务时取得了很大的成功,但CNN存在一…
esbuild中文文档-路径解析配置项(Path resolution - External、Main fields)
文章目录 路径解析配置项 Path resolution外部模块 External主字段 Main fields对于包的开发者 结语 哈喽,大家好!我是「励志前端小黑哥」,我带着最新发布的文章又来了! 老规矩,小手动起来~点赞关注不迷路!…
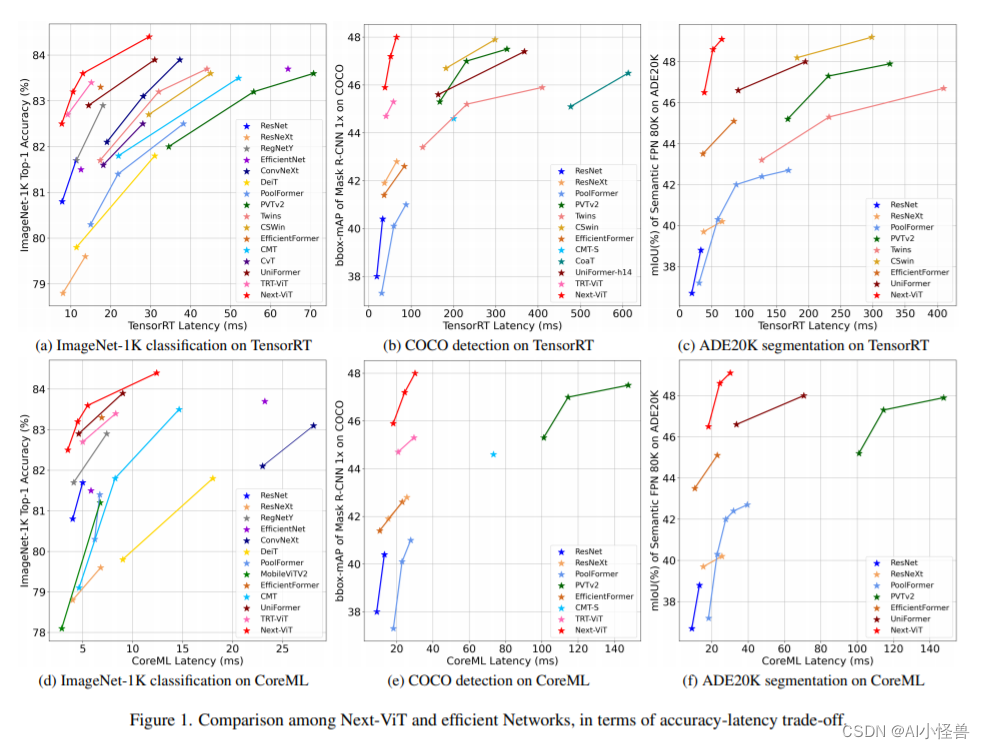
Yolov8轻量级:Next-vit,用于现实工业场景的下一代视觉 Transformer
1.Next-vit介绍
论文:https://arxiv.org/pdf/2207.05501.pdf 由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样…

读书笔记:多Transformer的双向编码器表示法(Bert)-4
多Transformer的双向编码器表示法
Bidirectional Encoder Representations from Transformers,即Bert;
第二部分 探索BERT变体 从本章开始的诸多内容,以理解为目标,着重关注对音频相关的支持(如果有的话)…
bert 环境搭建之PytorchTransformer 安装
这两天跑以前的bert项目发现突然跑不了,报错信息如下:
Step1 transformer 安装
RuntimeError: Failed to import transformers.models.bert.modeling_bert because of the following error (look up to see its traceback): module signal has no att…

【Transformer系列】深入浅出理解Positional Encoding位置编码
一、参考资料
一文教你彻底理解Transformer中Positional Encoding Transformer Architecture: The Positional Encoding The Annotated Transformer Master Positional Encoding: Part I 如何理解Transformer论文中的positional encoding,和三角函数有什么关系&…
【基于transformer:PanSharpening】
PANFORMER: A TRANSFORMER BASED MODEL FOR PAN-SHARPENING
(PANFORMER:一种基于transformer的PAN锐化模型)
全色锐化的目的是从同一颗卫星获取的低分辨率(LR)多光谱(MS)图像及其对应的全色&a…

论文浅尝 | 利用知识图谱增强的Transformer进行跨领域方面抽取
笔记整理:沈小力,东南大学硕士,研究方向为知识图谱链接:https://dl.acm.org/doi/pdf/10.1145/3511808.3557275动机情感分析是自然语言处理的基础任务,它包含介绍了细粒度情感分析中的一个常见任务——基于方面的情感分…
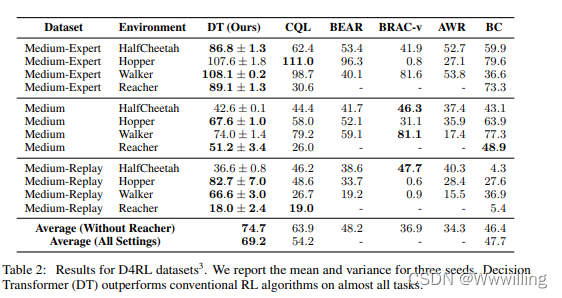
Online Decision Transformer
摘要
最近的工作表明,离线强化学习 (RL) 可以表述为序列建模问题 (Chen et al., 2021; Janner et al., 2021),并通过类似于大规模语言建模的方法来解决。 然而,RL 的任何实际实例化还涉及在线组件,其中在被动离线数据集上预训练的…
【原创】AIGC之ChatGPT工作原理
AIGC是什么 AIGC - AI Generated Content (AI生成内容),对应我们的过去的主要是 UGC(User Generated Content)和 PGC(Professional user Generated Content)。 AIGC就是说所有输出内容是通过AI机…
YoloV5改进策略:EfficientViT,高效的视觉transformer与级联组注意力提升YoloV5的速度和精度,打造高效的YoloV5
文章目录 摘要论文:《EfficientViT:高效视觉transformer与级联组注意力》1、简介2、用视觉transformer加速2.1. 内存效率2.2. 计算效率2.3. 参数效率3、高效视觉Transformer3.1. EfficientViT的构建块3.2、EfficientViT网络架构4、实验4.1. 实现细节4.2. ImageNet上的结果4.3…
SwiftFormer:基于Transformer的高效加性注意力用于实时移动视觉应用的模型
自注意力已经成为各种视觉应用中捕获全局上下文的默认选择。然而,相对于图像分辨率来说,它的二次计算复杂性限制了它在实时应用中的使用,尤其是在资源受限的移动设备上的部署。尽管已经提出了混合方法来结合卷积和自注意力的优点以获得更好的…
综述----知识蒸馏
4.1 模型改进
未来的研究可以集中在改进无图学习模型的性能和泛化能力。例如,可以研究更有效的知识表示和传递方法,以提高学生模型对教师模型知识的理解和利用能力。此外,可以探索新的模型结构和训练算法,以提高模型的效率和稳定…
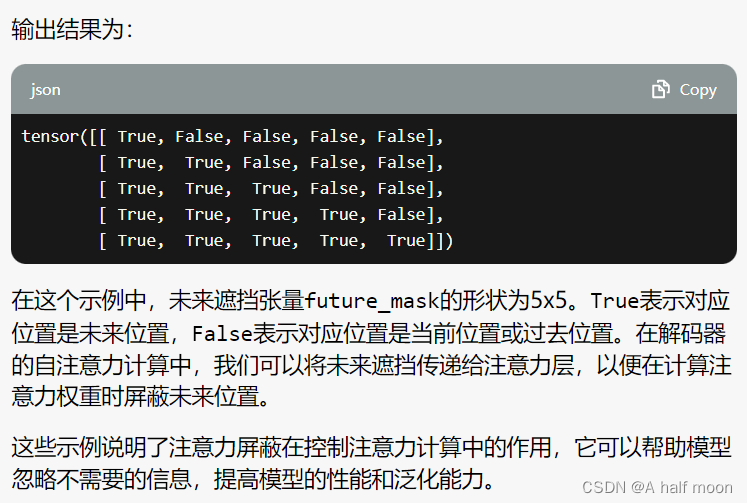
注意力屏蔽(Attention Masking)在Transformer中的作用 【gpt学习记录】
填充遮挡(Padding Masking): 未来遮挡(Future Masking):
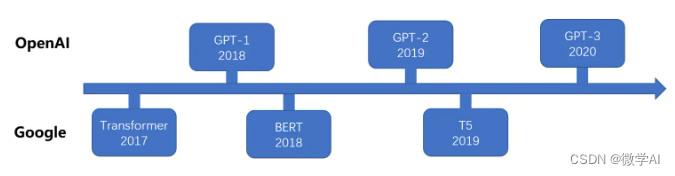
使用 Hugging Face Transformer 创建 BERT 嵌入
介绍 最初是为了将文本从一种语言更改为另一种语言而创建的。BERT 极大地影响了我们学习和使用人类语言的方式。它改进了原始 Transformer 模型中理解文本的部分。创建 BERT 嵌入尤其擅长抓取具有复杂含义的句子。它通过检查整个句子并理解单词如何连接来做到这一点。Hugging F…
Transformer预测 | Pytorch实现基于Transformer的锂电池寿命预测(NASA数据集)
文章目录 效果一览文章概述模型描述程序设计参考资料效果一览 文章概述 Pytorch实现基于Transformer 的锂电池寿命预测,环境为pytorch 1.8.0,pandas 0.24.2 随着充放电次数的增加,锂电池的性能逐渐下降。电池的性能可以用容量来表示,故寿命预测 (RUL) 可以定义如下: SOH(t…

【读点论文】FMViT: A multiple-frequency mixing Vision Transformer-期待源码
FMViT: A multiple-frequency mixing Vision Transformer
Abstract transformer模型近年来在计算机视觉任务中得到了广泛的应用。然而,由于自关注的时间和内存复杂度是二次的,并且与输入token的数量成正比,大多数现有的(Vision transformer,…
DETR纯代码分享(五)__init__.py(datasets)
一、导入各种包
import torch.utils.data
import torchvisionfrom .coco import build as build_coco
这段代码导入了PyTorch中的数据加载和视觉工具库(torch.utils.data和torchvision),以及一个名为build的自定义模块(build_co…
YOLOv8-Seg改进:Backbone改进 |Next-ViT堆栈NCB和NTB 构建先进的CNN-Transformer混合架构
🚀🚀🚀本文改进:Next-ViT堆栈NCB和NTB 构建先进的CNN-Transformer混合架构,包括nextvit_small, nextvit_base, nextvit_large,相比较yolov8-seg各个版本如下: layersparametersgradientsGFLOPsnextvit_small61033841075

工具系列:TimeGPT_(3)处理假期和特殊日期
日历变量和特殊日期是预测应用中最常见的外生变量类型之一。它们为时间序列的当前状态提供了额外的上下文信息,特别是对于基于窗口的模型(如TimeGPT-1)而言。这些变量通常包括添加每个观测的月份、周数、日期或小时数的信息。例如,…
从原理到实践 | Pytorch tensor 张量花式操作
文章目录 1.张量形状与维度1.1标量(0维张量):1.2 向量(1维张量):1.3矩阵(2维张量):1.4高维张量: 2. 张量其他创建方式2.1 创建全零或全一张量:2.2…
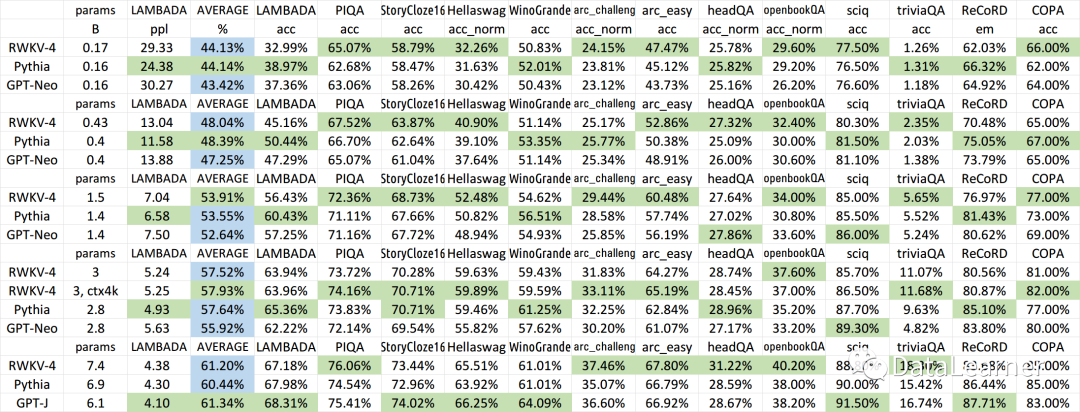
HF宣布在transformers库中引入首个RNN模型:RWKV,一个结合了RNN与Transformer双重优点的模型
RWKV是一个结合了RNN与Transformer双重优点的模型架构。由香港大学物理系毕业的彭博首次提出。简单来说,RWKV是一个RNN架构的模型,但是可以像transformer一样高效训练。今天,HuggingFace官方宣布在transformers库中首次引入RNN这样的模型&…
人工智能并行计算,很大程度提升了语言模型的训练速度
循环智能最早的三位创始人陈麒聪、杨植麟与张宇韬相识于清华大学的知识工程实验室,都有一股「用AI创造社会价值」的热血。三人都是技术出身,后来因为业务发展,循环智能在2018年又引入了另一位擅长技术产品运营的「第四把手」揭发。 自成立…

YOLOv8-seg改进:注意力系列篇 | 一种简单有效的可变形的自注意力模块DAT | CVPR 2022
🚀🚀🚀本文改进:Deformable Attention Transformer,一种简单有效的可变形的自注意力模块,增强sparse attention 的表征能⼒;
🚀🚀🚀DAT小目标分割&复杂场景首选,实现涨点 🚀🚀🚀YOLOv8-seg创新专栏:http://t.csdnimg.cn/KLSdv
学姐带你学习YOL…
【Image captioning】Meshed-memory transformer自有数据集的文件预处理
Meshed-memory transformer自有数据集的文件预处理
作者:安静到无声 个人主页 目录 Meshed-memory transformer自有数据集的文件预处理生成与coco_detections.hdf5相似的特征文件生成训练、测试和验证对应的JSON和字幕ID推荐专栏生成与coco_detections.hdf5相似的特征文件
c…
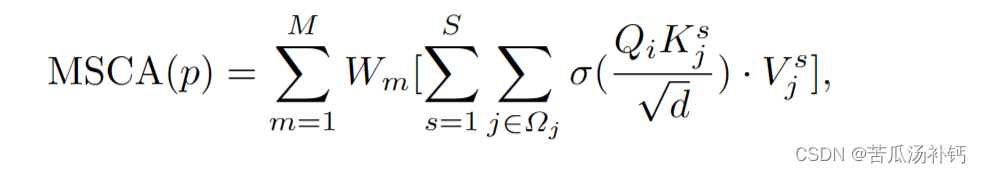
论文阅读:CenterFormer: Center-based Transformer for 3D Object Detection
目录
概要
Motivation
整体架构流程
技术细节
Multi-scale Center Proposal Network
Multi-scale Center Transformer Decoder
Multi-frame CenterFormer
小结 论文地址:[2209.05588] CenterFormer: Center-based Transformer for 3D Object Detection (arx…
Transformer和RNN的区别?
Transformer和循环神经网络(RNN)是两种不同的序列建模模型,它们在结构和工作原理上有一些重要的区别。 结构: Transformer:Transformer模型是一种基于自注意力机制的序列建模模型。它主要由编码器和解码器组成…
Transformer预测 | Pytorch实现基于mmTransformer多模态运动预测(堆叠Transformer)
文章目录 文章概述程序设计参考资料文章概述 Transformer预测 | Pytorch实现基于mmTransformer多模态运动预测(堆叠Transformer) 程序设计 Initialize virtual environment: conda create -n mmTrans python=3.7# -*- coding: utf-8 -*-
import argparse
import os
Transformer 模型中常见的特殊符号
Transformer 模型中常见的特殊符号 通过代码一起理解一下 Transformer 模型中常见的特殊符号,
示例代码,
special_tokens{unk_token: [UNK], sep_token: [SEP], pad_token: [PAD], cls_token: [CLS], mask_token: [MASK]}这段代码是定义了一个字典spec…

云端部署ChatGLM-6B
大模型这里更新是挺快的,我参考的视频教程就和我这个稍微有些不一样,这距离教程发布只过去4天而已… 不过基本操作也差不多 AutoDL算力云:https://www.autodl.com/home ChatGLM3:https://github.com/THUDM/ChatGLM3/tree/main Hug…

Attention is all your need——Transformer论文
摘要
此序列转录模型仅仅依赖于注意力机制,而不使用循环或者是卷积,将循环全部换成了multi-headed self- attention
介绍
RNN的特点、并行程度低。
Attention在RNN上的应用。
引入注意力机制,提高并行度。
背景
使用卷积对长的序列难以…
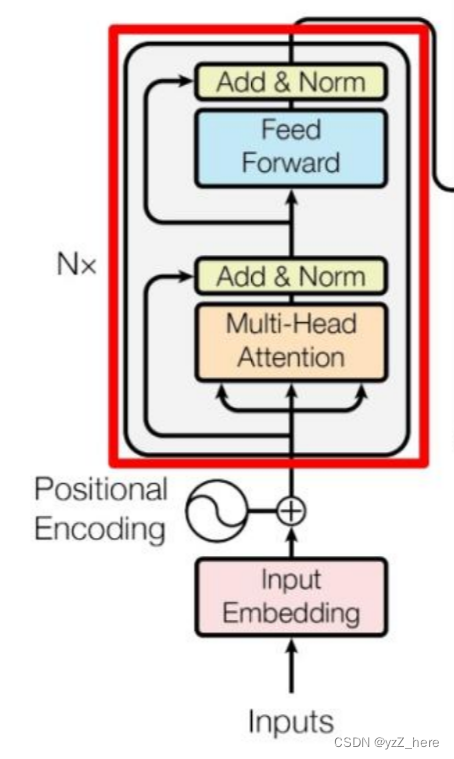
Transformer结构细节
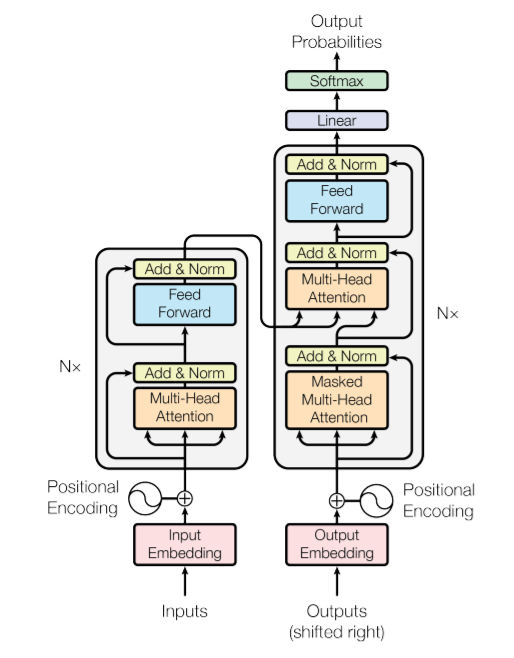
一、结构
Transformer 从大的看由 编码器输入、编码器、解码器、解码器输入和解码器输出构成。
编码器中包含了词嵌入信息编码、位置编码、多头注意力、Add&Norm层以及一个全连接层;
解码器中比编码器多了掩码的多头注意力层。
二、模块
2.1 Input Embeddi…
解析Transformer基本结构与实现
1.基本结构
Transformer总体架构可分为4个部分: 输入部分-输出部分-编码器部分-解码器部分 输入部分包含:
原文本嵌入层(Input embedding)及其位置编码(position encoding)目标文本嵌入层及其位置编码器 文本嵌入层的作…
【基于卷积和Transformer:多光谱图像光谱重建】
Spectral Reconstruction From Satellite Multispectral Imagery Using Convolution and Transformer Joint Network
(基于卷积和Transformer联合网络的卫星多光谱图像光谱重建)
基于卫星多光谱(MS)图像的光谱重建(S…
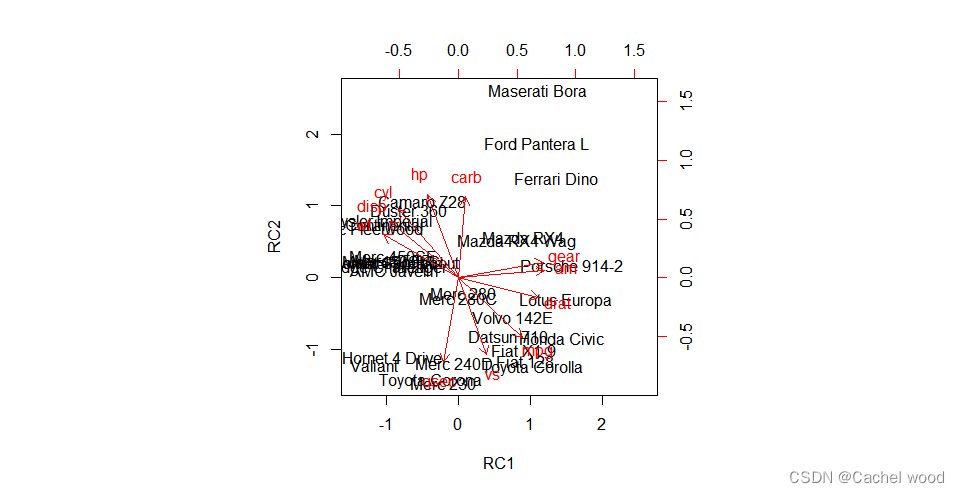
R语言:因子分析 factor analysis
文章目录 因子分析数据集处理步骤主成分法做因子分析最大似然法做因子分析 因子分析 因子分析的用途与主成分分析类似,它也是一种降维方法。由于因子往往比主成分更易得到解释,故因子分析比主成分分析更容易成功,从而有更广泛的应用。 从方法…
NLP系列——Transformer源码解析(TensorFlow版)
目录前言1. \__init\__()2. encode()2. decode()3. linear projection4. 代码地址前言 这篇博客是对transformer源码的解析,这个源码并非官方的,但是比官方代码更容易理解。 采用TensorFlow框架,下面的解析过程只针对模型构建过程&#x…
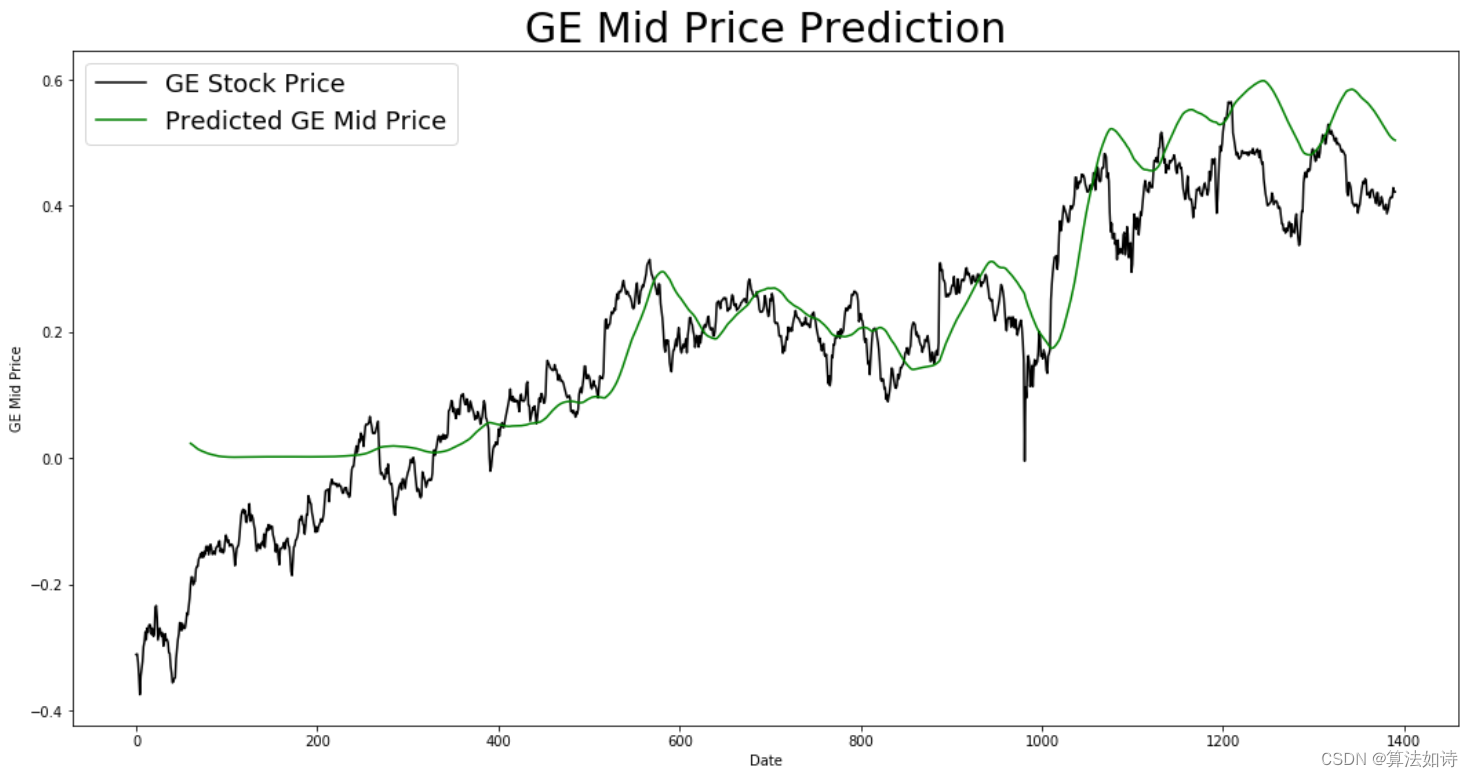
Transformer预测 | Python实现基于Transformer的股票价格预测(tensorflow)
文章目录 效果一览文章概述程序设计参考资料效果一览 文章概述 Transformer预测 | Python实现基于Transformer的股票价格预测(tensorflow) 程序设计 import numpy as np
import matplotlib.pyplot
RepViT:从ViT视角重新审视移动CNN
文章目录 摘要1、简介2、相关工作3、方法论3.1、初步3.2、Block设计3.3、宏观设计3.4、微观设计3.5、网络架构4、实验4.1、图像分类4.2、目标检测与实例分割4.3、语义分割5、结论A. RepViTs架构一些名词的理解mobile-friendlinessEarly Convolutions摘要
https://arxiv.org/pd…

Congested Crowd Instance Localization with Dilated Convolutional Swin Transformer阅读笔记
Abstract
研究如何在高密度人群场景中实现精准的实例定位,以及如何缓解传统模型由于目标遮挡、图像模糊等而降低特征提取能力的问题。为此,我们提出了一 Dilated Convolutional Swin Transformer(DCST)对于拥挤的人群场景
Speci…
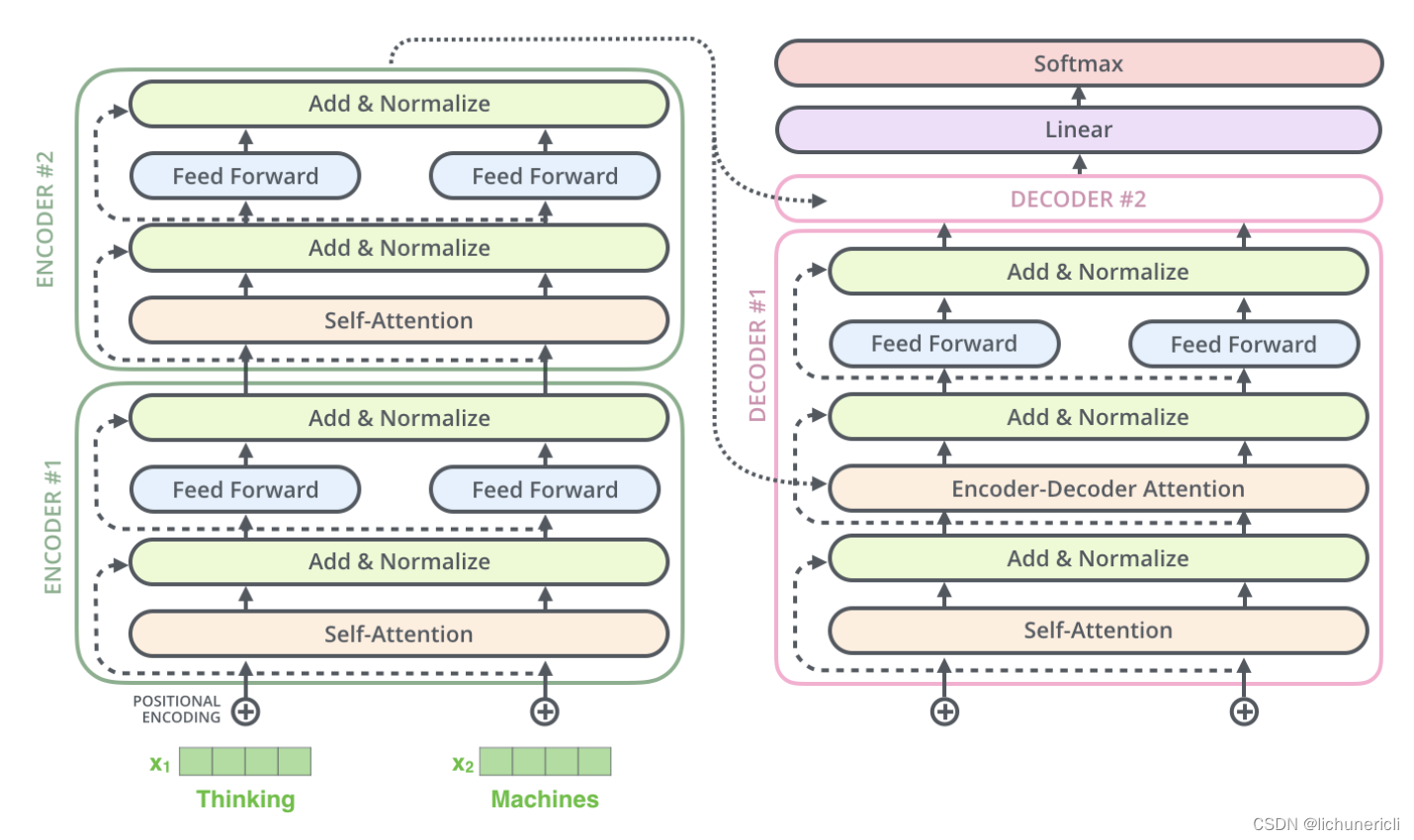
自然语言处理---Transformer机制详解之Transformer优势
1 Transformer的并行计算
对于Transformer比传统序列模型RNN/LSTM具备优势的第一大原因就是强大的并行计算能力.
对于RNN来说,任意时刻t的输入是时刻t的输入x(t)和上一时刻的隐藏层输出h(t-1),经过运算后得到当前时刻隐藏层的输出h(t),这个…
Vision Transformer
论文名称: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
一、Patch Embedding模块 class PatchEmbed(nn.Module): # 对应Patch Embedding模块def __init__(self, img_size224, patch_size16, in_c3, embed_dim768, norm_layerNone…
为什么要引入Attention机制?
Attention mechanism在序列学习任务上具有巨大的提升作用,在编解码器框架内,通过在编码段加入Attention模型,对源数据序列进行数据加权变换,或者在解码端引入Attention 模型,对目标数据进行加权变化,可以有…

CrossCLR: Cross-modal Contrastive Learning for Multi-modal Video Representations, 2021 ICCV
**本文内容仅代表个人理解,如有错误,欢迎指正**
1. Points
这篇论文主要解决两个问题
1. 跨模态对比学习(Cross-modal Contrastive learning)更注重于不同模态下的数据,而非同一模态下的数据。
- 也就是说,将不同模态下的数据…

Transformer回顾与细节
我们在《Seq2seq Attention模型详解》中,详细地回顾了以 RNN 为基础模块的Seq2seq模型。本文所讲述的Transformer也采用Seq2seq式的编码器-解码器结构,不过它摒弃了经典的 RNN,采用 self-Attention。由于并行计算、长时序建模、模型容量大等优…
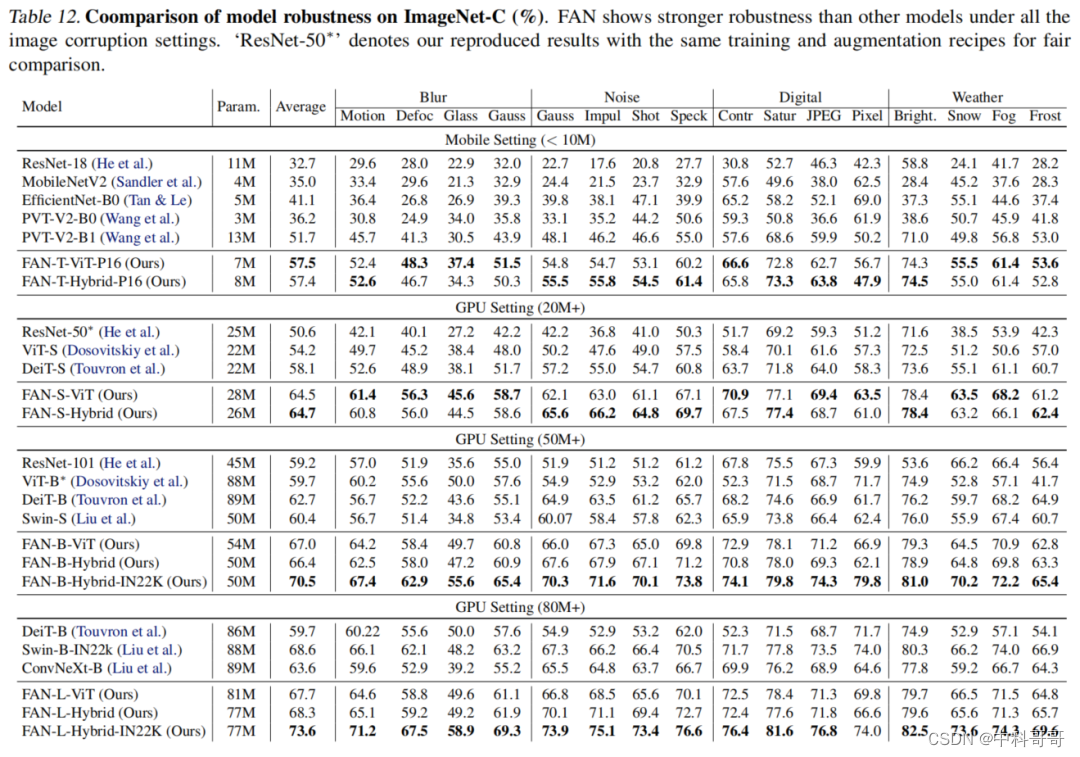
FAN(Understanding The Robustness in Vision Transformers)论文解读,鲁棒性和高效性超越ConvNeXt、Swin
FAN(Understanding The Robustness in Vision Transformers)论文解读,鲁棒性和高效性超越ConvNeXt、Swin < center > < center >
最近的研究表明,Vision Transformers对各种Corruptions表现出很强的鲁棒性。虽然这一特性部分归…
风格转换模型style_transformer项目实例 pytorch实现
风格转换模型style_transformer项目实例 pytorch实现
有没有想过,利用机器学习来画画,今天,我将手把手带大家进入深度学习模型neural style的代码实战当中。 neural-style模型是一个风格迁移的模型,是GitHub上一个超棒的项目&…
Attention——Transformer——Bert——FineTuning——Prompt
目录 一、Attention机制
二、Transformer模型
三、Bert模型
四、Fine-Tuning微调
五、Prompt 一、Attention机制
1、核心逻辑:从关注全部到关注重点;
2.计算attention公式: 3.优点:
(1)参数少&#…

【Transformer系列论文】TransFuser:端到端自动驾驶的多模态融合Transformer
Article
作者:Aditya Prakash, Kashyap Chitta, Andreas Geiger文献题目:TransFuser:端到端自动驾驶的多模态融合Transformer文献时间:2021文献链接:https://arxiv.org/abs/2104.09224
摘要
互补传感器的表征应该如…

【强化学习论文】Decision Transformer:通过序列建模进行强化学习
Article
文献题目:Decision Transformer: Reinforcement Learning via Sequence Modeling 文献时间:2021
摘要
我们引入了一个将强化学习(RL)抽象为序列建模问题的框架。 这使我们能够利用 Transformer 架构的简单性和可扩展性…
TrOCR – 基于 Transformer 的 OCR 入门
一、TrOCR 架构 近些年,光学字符识别 (OCR) 出现了多项创新。它对零售、医疗保健、银行和许多其他行业的影响是巨大的。与深度学习的许多其他领域一样,OCR领域也看到了Transformer 神经网络的重要性和影响。如今,出现了像TrOCR(Transformer OCR)这样的模型,它在准确性方面…
t5模型为什么可以通过传入past_key和past_value值来进行优化模型
t5模型是常用于文本生成部分的一个模型,也是目前我看到的各个nlp模型之中,唯一完整地使用transformer的所有完整结构(encoder部分加上decoder部分)的一个模型,接下来聊一下t5模型的生成优化过程。
优化的部分
首先对于生成这一块࿰…
[bug][未解决] transformer encoder对不同的输入,输出全部一样
多标签分类问题,输入是蛋白质特征,输出是蛋白质的功能(即,一个由标签组成的DAG)
motivation:输入是一个有multi-hot向量组成的张量,multi-hot的每一位代表着某一种特征。
考虑到不同特征之间可…
Transformer-based模型的综述:AMMUS : A Survey of Transformer-based Pretrained Models in NLP
论文地址: https://arxiv.org/abs/2108.055421 导言 预训练的来源 最开始是基于规则的学习,后来被机器学习取代早期机器学习需要特征工程,需要专业领域的知识,耗时由于硬件和词嵌入的发展,类似于CNN、RNN的深度学习模型…
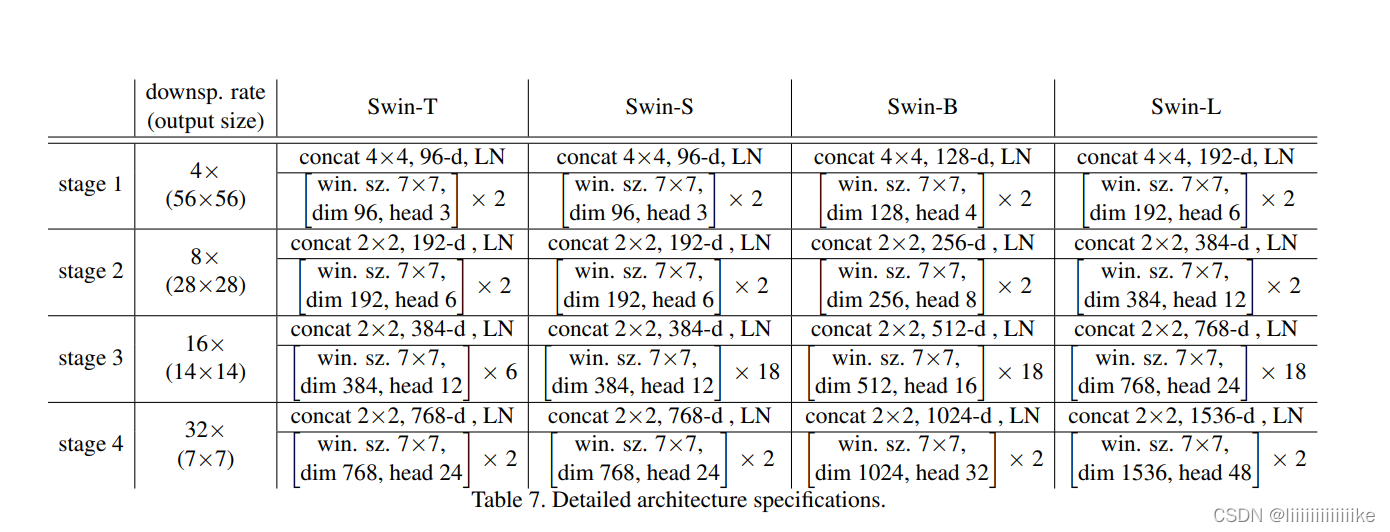
Swin Transformer网络架构、相应改进模块的理解
swin-Transformer
Transformer越来越火,个人感觉基于Transformer来做视觉真是把矩阵用得出神入化!! Swin-Transformer相较于VIT改进的方法:
SwinT使用类似CNN中层次化构建方法,这样的backbone有助于在此基础上构建检…
Transformer面试题总结
1.框架 Transformer和seq2seq一样由解码器和编码器组成,用多头注意力替换编码器和解码器架构中最常用的循环层 1.1 编码器:编码器有一堆N6的相同层组成,每一层有两个子层,第一个子层包含多头注意力机制,第二个子层是前…

层层剥开Transformer;Windows Copilot初版非常简陋
🦉 AI新闻
🚀 微软Win11引入Windows Copilot功能,但初版非常简陋
摘要:微软在Win11 Build 23493预览版更新中引入了Windows Copilot功能,该功能在任务栏上新增了一个图标按钮。点击按钮后,屏幕右侧会跳出…

【论文阅读】UniDiffuser: Transformer+Diffusion 用于图、文互相推理
而多模态大模型将能够打通各种模态能力,实现任意模态之间转化,被认为是通用式生成模型的未来发展方向。
最近看到不少多模态大模型的工作,有医学、金融混合,还有CV&NLP。
今天介绍: One Transformer Fits All Di…
pytorch 使用 xformers 库 加速多头注意力计算 和 大幅节省显存
效果概览: 好处:使用 google PALM 架构的小模型做 生成任务,改为 xformers 实现后,加速比为 2倍,显存消耗为原来的 1/3 ,非常给力。 缺点:相比pytorch的原生实现,误差略大。。。
xf…
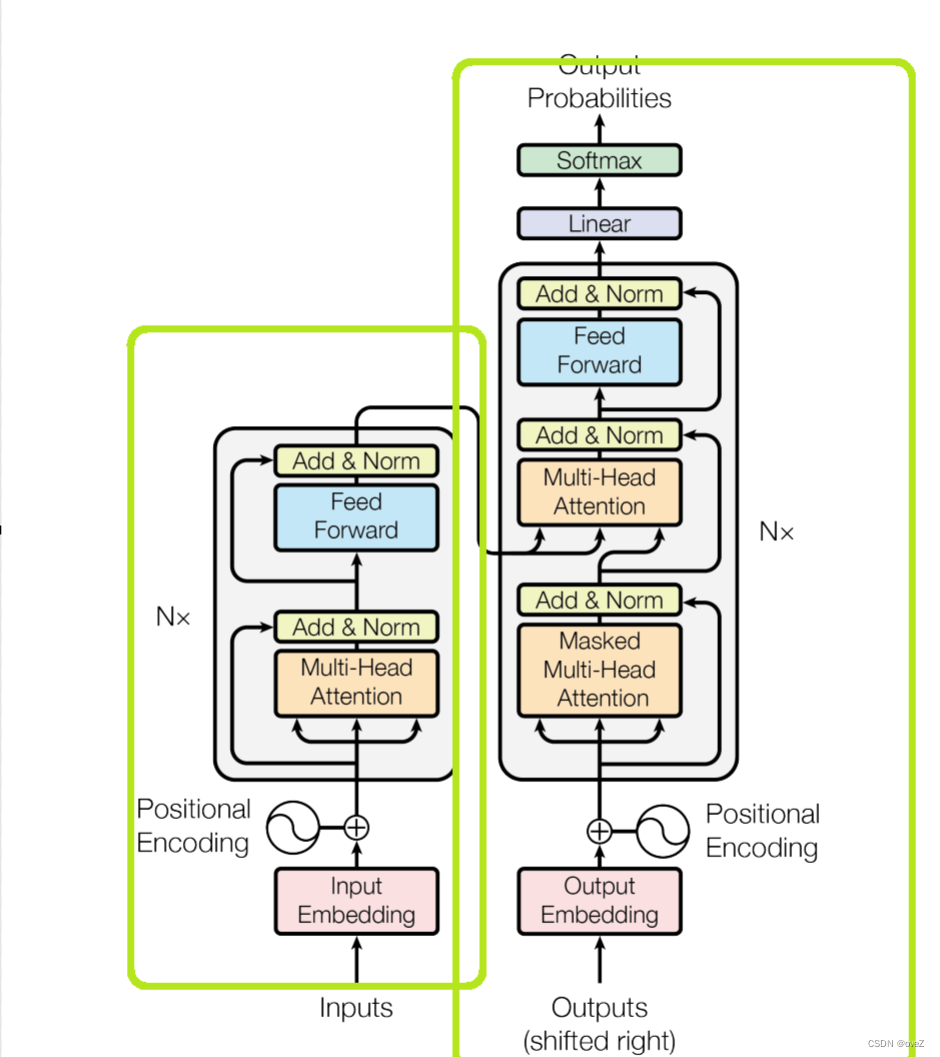
基于PyTorch的Transformer组件实现
最近看了不少介绍LLM工作原理的文章,发现每一篇都会试图跟读者讲明白作为baseline的Transformer架构到底长啥样。但是好像比较少有代码实现的示例和具体的例子帮助理解。于是自己也想尝试着写一篇含有代码实现和具体例子解释的文章,希望能够给喜欢编程朋…

36k字从Attention讲解Transformer及其在Vision中的应用(pytorch版)
文章目录 0.卷积操作1.注意力1.1 注意力概述(Attention)1.1.1 Encoder-Decoder1.1.2 查询、键和值1.1.3 注意力汇聚: Nadaraya-Watson 核回归1.2 注意力评分函数1.2.1 加性注意力1.2.2 缩放点积注意力1.3 自注意力(Self-Attention)1.3.1 自注意力的定义和计算1.3.2 自注意…

(2021|NIPS,)CogView:通过 Transformer 掌握文本到图像的生成
CogView: Mastering Text-to-Image Generation via Transformers
公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料) 0. 摘要
通用领域中的文本到图像生成长期以来一直是一个悬而未决的问题&#…
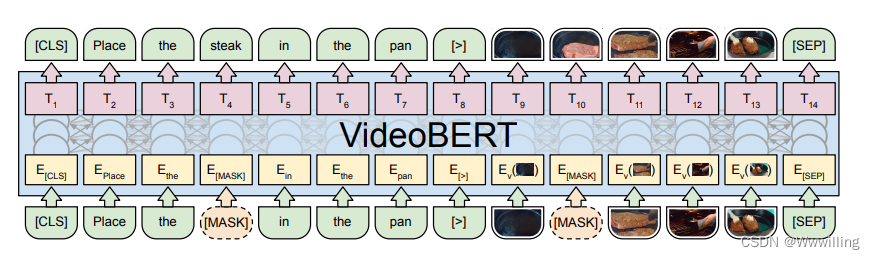
【Transformer论文】VideoBERT:视频和语言表示学习的联合模型
文献题目:VideoBERT: A Joint Model for Video and Language Representation Learning代码:https://github.com/ammesatyajit/VideoBERT
摘要
自我监督学习对于利用 YouTube 等平台上可用的大量未标记数据变得越来越重要。尽管大多数现有方法都学习低级…
【Transformer论文】使用 Transformer 网络的会话感知项目组合推荐
文献题目:Session-aware Item-combination Recommendation with Transformer Network
摘要
在本文中,我们详细描述了我们的 IEEE BigData Cup 2021 解决方案:基于 RL 的 RecSys(Track 1:Item Combination Prediction…
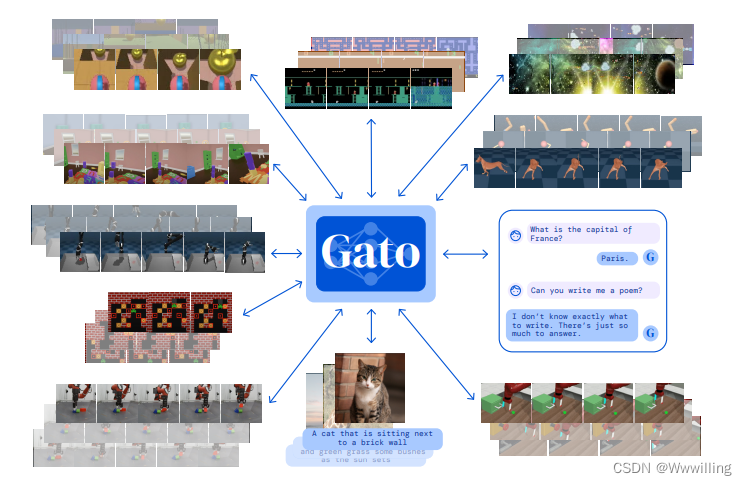
【Transformer论文】通用代理
文章题目:A Generalist Agent
摘要
受大规模语言建模进展的启发,我们应用了类似的方法来构建超越文本输出领域的单一通才代理。 代理,我们称之为 Gato,作为一种多模式、多任务、多实施的通才策略工作。 具有相同权重的相同网络可…
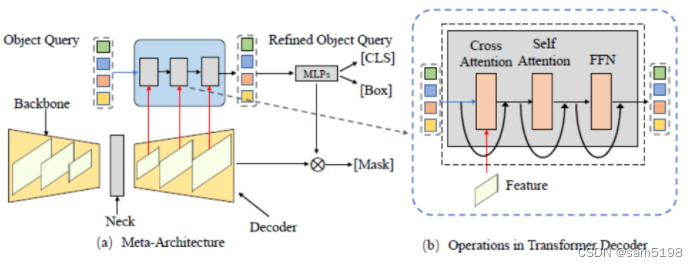
基于Transformer视觉分割综述
基于Transformer视觉分割综述
SAM (Segment Anything )作为一个视觉的分割基础模型,在短短的 3 个月时间吸引了很多研究者的关注和跟进。如果你想系统地了解 SAM 背后的技术,并跟上内卷的步伐,并能做出属于自己的 SAM…
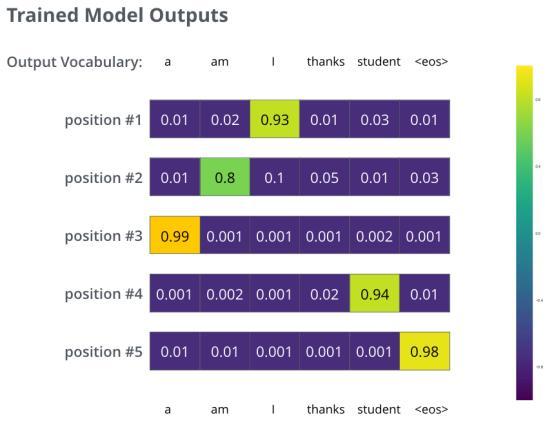
Transformer理解实现
注意力机制是一种在现代深度学习模型中无处不在的方法,它有助于提高神经机器翻译应用程序性能的概念。在本文中,我们将介绍Transformer这种模型,它可以通过注意力机制来提高训练模型的速度。在特定任务中,Transformer的表现优于Go…
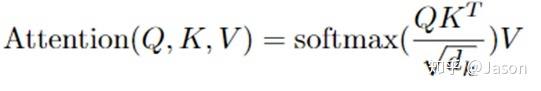
transformer通俗理解
Transformer是一个利用注意力机制来提高模型训练速度的模型。trasnformer可以说是完全基于自注意力机制的一个深度学习模型,因为它适用于并行化计算,和它本身模型的复杂程度导致它在精度和性能上都要高于之前流行的RNN循环神经网络。
那什么是transform…

LLMs训练的算力优化Computational challenges of training LLMs
当您尝试训练大型语言模型时,您仍然经常遇到的最常见问题之一是内存不足。如果您曾尝试在Nvidia GPU上训练或甚至只是加载模型,那么这个错误消息可能看起来很熟悉。
CUDA,即Compute Unified Device Architecture的缩写,是为Nvid…
微调codebert、unixcoder、grapghcodebert完成漏洞检测代码
文件结构如下所示: mode.py # Copyright (c) Microsoft Corporation.
# Licensed under the MIT License.
import torch
import torch.nn as nn
import torch
from torch.autograd import Variable
import copy
from torch.nn import CrossEntropyLoss, MSELosscl…
简单实现Transformer(Pytorch)
相关文章: 加性注意(原理)加性注意(复现)乘性注意(原理)乘性注意(复现) 1 理论
该模型的特点:完全基于注意力机制,完全摒弃了递归和卷积。
它是一种模型架构,避免了递归,而是完全依赖于注意力机制来绘制输入和输出之…
LSTM已死,Transformer当立(LSTM is dead. Long Live Transformers! ):上
回想一下在Seq2seq模型中,如何使用Attention。这里简要回顾一下【1】介绍的方法2(并以此为基础展开对Transformer的讨论)。
下图中包含一个encoder(左)和一个decoder(右)。对于decoder来说,给定一个输入,得到输出,如何进一步得到context vector 呢?
我们需要根据和…
【Transformer从零开始代码实现 pytoch版】(五)总架构类的实现
Transformer总架构 在实现完输入部分、编码器、解码器和输出部分之后,就可以封装各个部件为一个完整的实体类了。
【Transformer从零开始代码实现 pytoch版】(一)输入部件:embeddingpositionalEncoding
【Transformer从零开始代…
【亲测】Swin-Transformer 自定义数据集图像分类
Swin-Transformer是当前热门的深度学习框架,适用于多种视觉任务,相关的原理,网上有很多资源,大家可自行查看,这里主要介绍其在图像分类方面的代码调试经验,方便各位快速上手实验。Swin-Transformer代码链接…
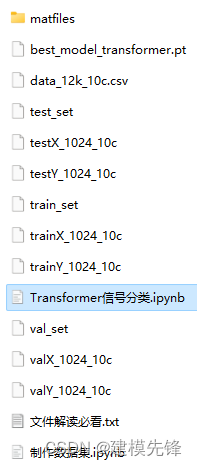
Pytorch-Transformer轴承故障一维信号分类(三)
目录
前言
1 数据集制作与加载
1.1 导入数据
第一步,导入十分类数据
第二步,读取MAT文件驱动端数据
第三步,制作数据集
第四步,制作训练集和标签
1.2 数据加载,训练数据、测试数据分组,数据分batch…
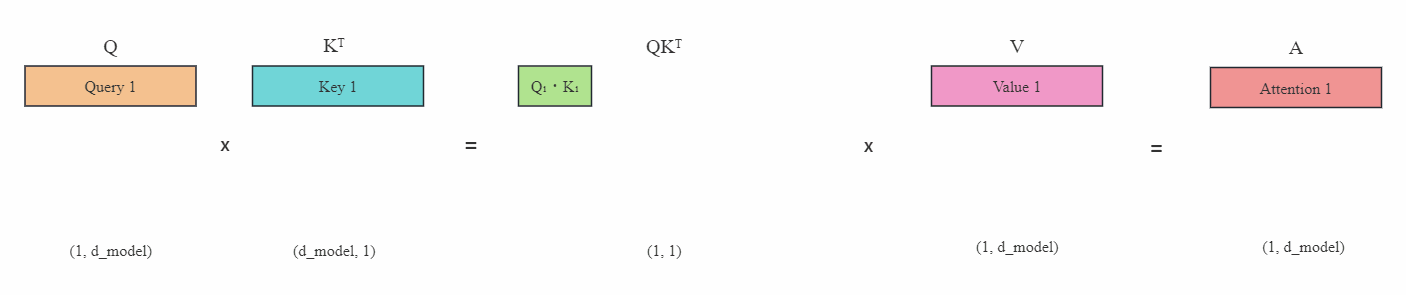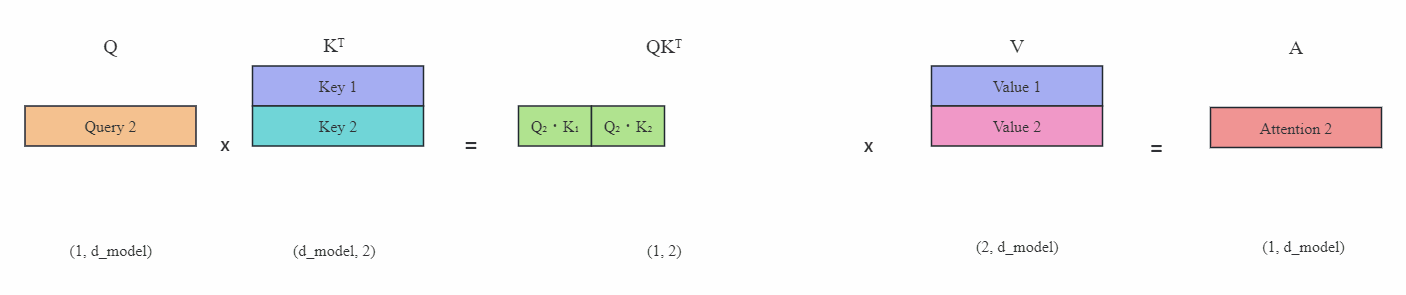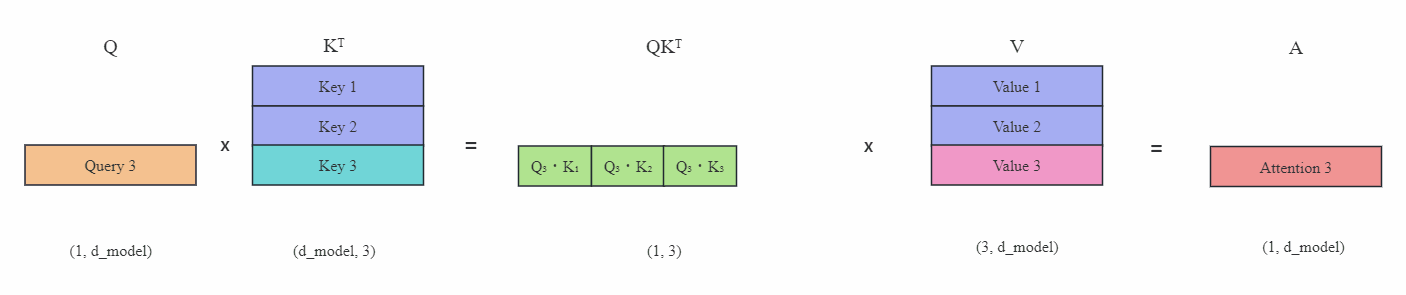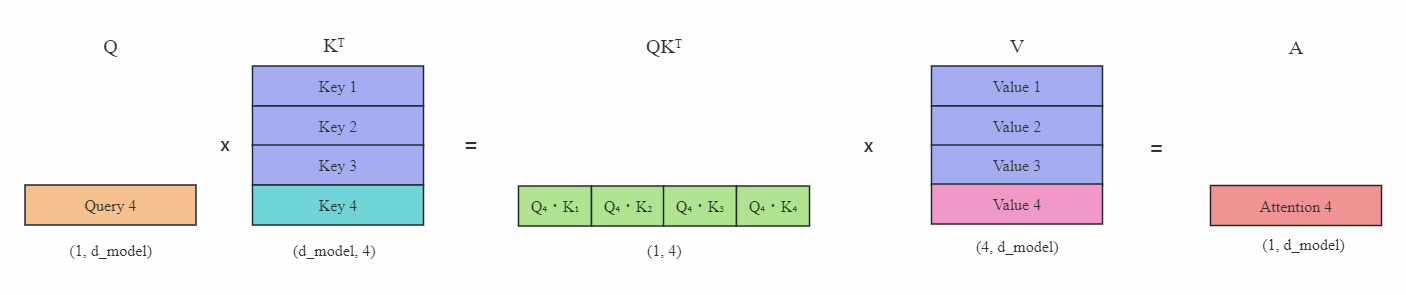
Transformer从菜鸟到新手(六)
引言
上篇文章介绍了如何在多GPU上分布式训练,本文介绍大模型常用的一种推理加速技术——KV缓存。
KV Cache
KV缓存(KV Cache)是在大模型推理中常用的一种技巧。我们知道在推理阶段,Transformer也只能像RNN一样逐个进行预测,也称为自回归。…
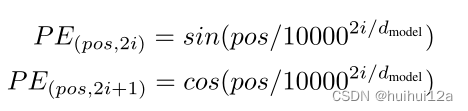
Transformer:Attention is All You Need
【Transformer论文逐段精读【论文精读】】 https://www.bilibili.com/video/BV1pu411o7BE/?share_sourcecopy_web&vd_source30e93e9c70e5a43ae75d42916063bc3b论文地址:[1706.03762] Attention Is All You Need (arxiv.org)Transformer第一个完全依靠自我注意来…
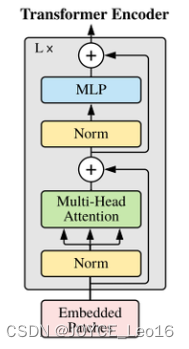
Transformer模型中前置Norm与后置Norm的区别
主要介绍原始Transformer和Vision Transformer中的Norm层不同位置的区别。 文章目录 前言 不同位置的作用 总结 前言
在讨论Transformer模型和Vision Transformer (ViT)模型中归一化层位置的不同,我们首先需要理解归一化层(Normalization)在…

深聊性能测试,从入门到放弃之:Locust性能自动化(七)HAR-files→locustfiles自动转换 :Transformer的使用
Transformer 使用1、引言2、安装及调用2.1 介绍2.2 安装2.3 使用2.3.1 保存HAR files2.3.2 命令行工具2.3.3 作为库被调用3、 创建HAR-file3.1 简介3.2 录制场景3.3 保存HAR3.4 特定场景3.4.1 制定权重3.4.2 分层方案3.4.3 忽略特定URL1、引言
在使用Locust时, 都会…
TRB 2024论文分享:基于生成对抗网络和Transformer模型的交通事件检测混合模型
TRB(Transportation Research Board,美国交通研究委员会,简称TRB)会议是交通研究领域知名度最高学术会议之一,近年来的参会人数已经超过了2万名,是参与人数和国家最多的学术盛会。TRB会议几乎涵盖了交通领域…
36k字从Attention解读Transformer及其在Vision中的应用(pytorch版)
文章目录 0.卷积操作1.注意力1.1 注意力概述(Attention)1.1.1 Encoder-Decoder1.1.2 查询、键和值1.1.3 注意力汇聚: Nadaraya-Watson 核回归1.2 注意力评分函数1.2.1 加性注意力1.2.2 缩放点积注意力1.3 自注意力(Self-Attention)1.3.1 自注意力的定义和计算1.3.2 自注意…
【HuggingFace文档学习】Bert的token分类与句分类
BERT特性:
BERT的嵌入是位置绝对(position absolute)的。BERT擅长于预测掩码token和NLU,但是不擅长下一文本生成。
1.BertForTokenClassification
一个用于token级分类的模型,可用于命名实体识别(NER)、部分语音标记…
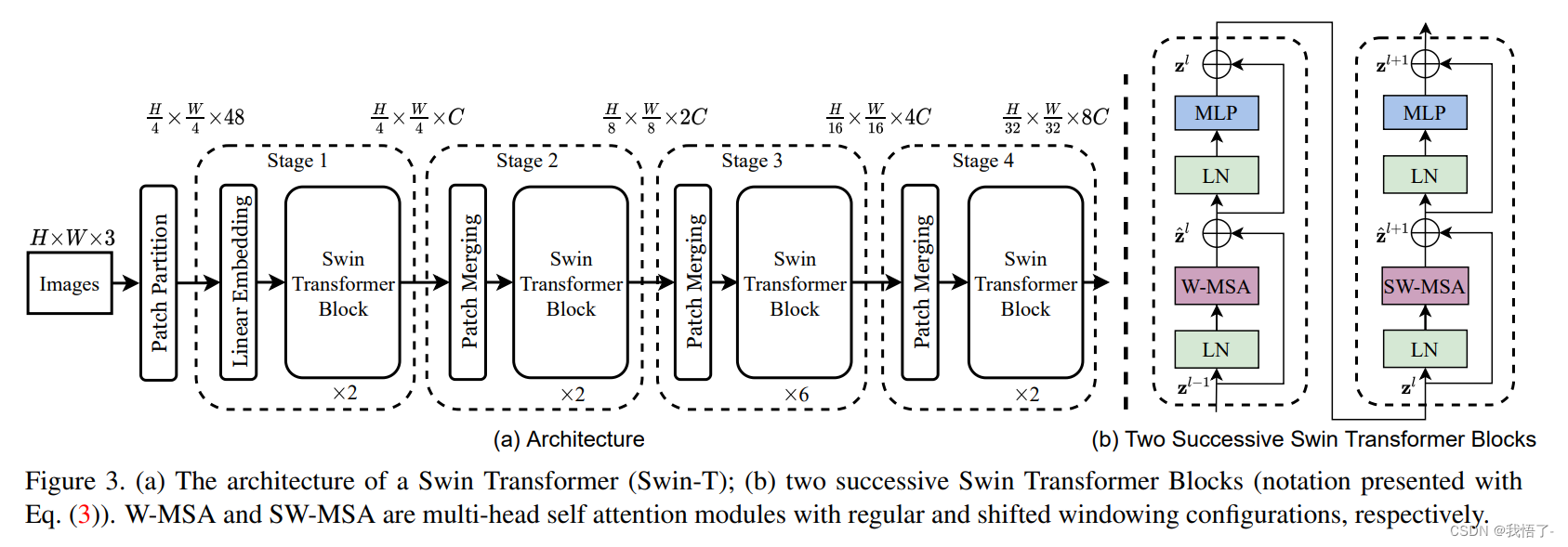
目标检测算法改进系列之Backbone替换为Swin Transformer
Swin Transformer简介
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》作为2021 ICCV最佳论文,屠榜了各大CV任务,性能优于DeiT、ViT和EfficientNet等主干网络,已经替代经典的CNN架构,成为了计算机…
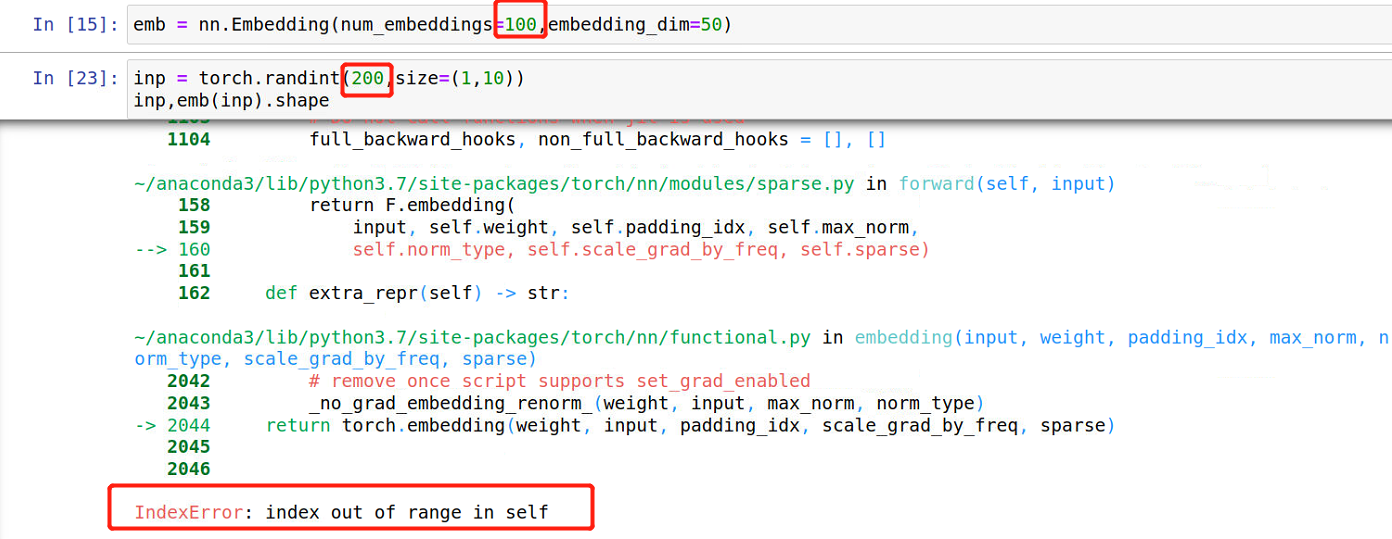
NLP | 简单学习一下NLP中的transformer的pytorch代码
经典transformer的学习文章转自微信公众号【机器学习炼丹术】作者:陈亦新(已授权)联系方式: 微信cyx645016617欢迎交流,共同进步 文章目录代码细讲transformerEmbeddingEncoder_MultipleLayersEncoder完整代码代码细讲
transform…
详细介绍如何微调 T5 Transformer 模型:用于构建 Stack Overflow 标签生成器的 Text2Text 传输转换器-含源码
在不断发展的自然语言处理 (NLP) 领域,T5(文本到文本传输转换器)模型已成为一种多功能模型。针对特定任务对该模型进行微调可以释放其全部潜力,使其成为人工智能爱好者和专业人士的一项关键技能。本文深入研究了T5 Transformer 模型的微调,特别是针对基于 Stack Overflow …
transformer 4 RuntimeError: Expected tensor for argument #1 ‘indices‘ to have scalar type Long
在使用transformer 4.0时,报错误提示RuntimeError: Expected tensor for argument #1 indices to have scalar type Long; but got torch.IntTensor instead (while checking arguments for embedding)。该问题主要时由于tensor的类型导致的,解决方法是在…
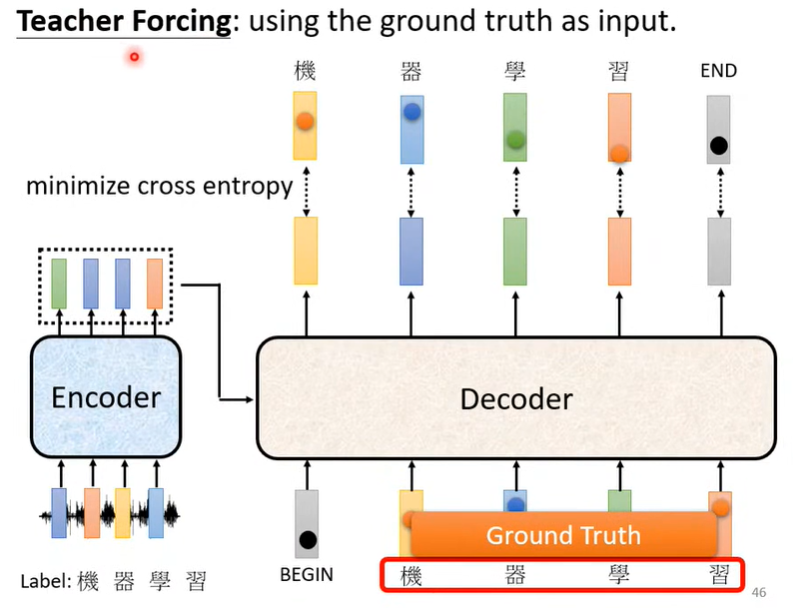
Self-attention Transformer
参考资料:
《机器学习》李宏毅
1 Self-attention
当模型输入为长度不定的向量序列时(如一段文字、一段语音、图模型),要求模型输出为等长的向量序列(序列标注)时,可以使用 Self-attention
S…
EMA和自动混合精度(AMP)
EMA:指数移动平均,用于优化权重更新
参考自:https://blog.csdn.net/Newt_Scamander/article/details/122268929
AMP:自动混合精度,用于加快模型训练,其思想在于使得模型处理数据的时候,自动控制数据在tor…

pytorch图片分割原理
自从transformer应用到cv领域以后,对图片的分割需求便越加重了,但是图像分割说起来容易,实际操作起来还是有很多地方不懂(主要还是code能力太弱)。
我们知道,对张量的处理一般又两种,一种是vie…
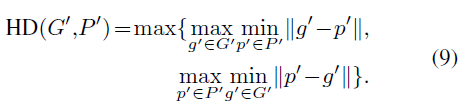
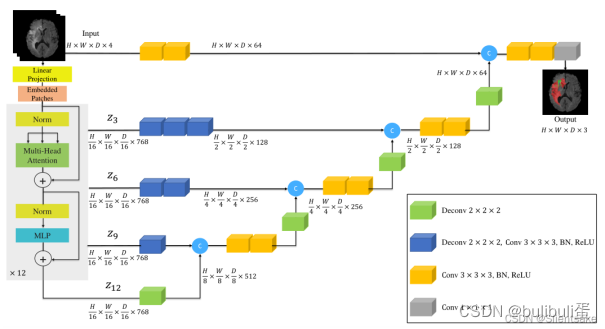
UNETR:用于三维医学图像分割的Transformer
论文链接:https://arxiv.org/abs/2103.10504
代码链接: https://monai.io/research/unetr
机构:Vanderbilt University, NVIDIA 最近琢磨不出来怎么把3d体数据和文本在cnn中融合,因为确实存在在2d里面用的transformer用在3d里面…
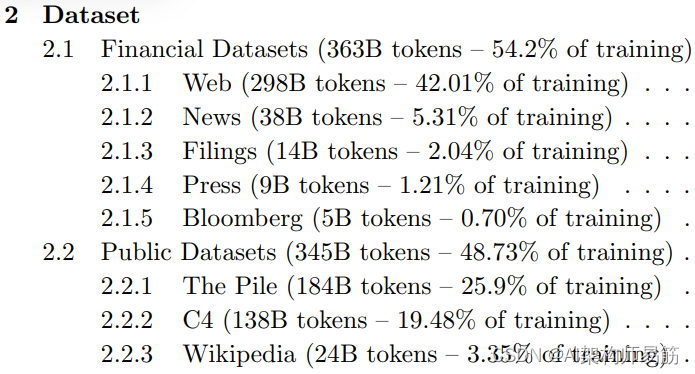
LLMs参考资料第一周以及BloombergGPT特定领域的训练 Domain-specific training: BloombergGPT
1. 第1周资源
以下是本周视频中讨论的研究论文的链接。您不需要理解这些论文中讨论的所有技术细节 - 您已经看到了您需要回答讲座视频中的测验的最重要的要点。
然而,如果您想更仔细地查看原始研究,您可以通过以下链接阅读这些论文和文章。
1.1 Trans…
DETR纯代码分享(六)detr.py
一、导入模块
"""
DETR model and criterion classes.
"""
import torch
import torch.nn.functional as F
from torch import nnfrom util import box_ops
from util.misc import (NestedTensor, nested_tensor_from_tensor_list,accuracy, ge…

自然语言处理:Transformer与GPT
Transformer和GPT(Generative Pre-trained Transformer)是深度学习和自然语言处理(NLP)领域的两个重要概念,它们之间存在密切的关系但也有明显的不同。
1 基本概念
1.1 Transformer基本概念
Transformer是一种深度学…
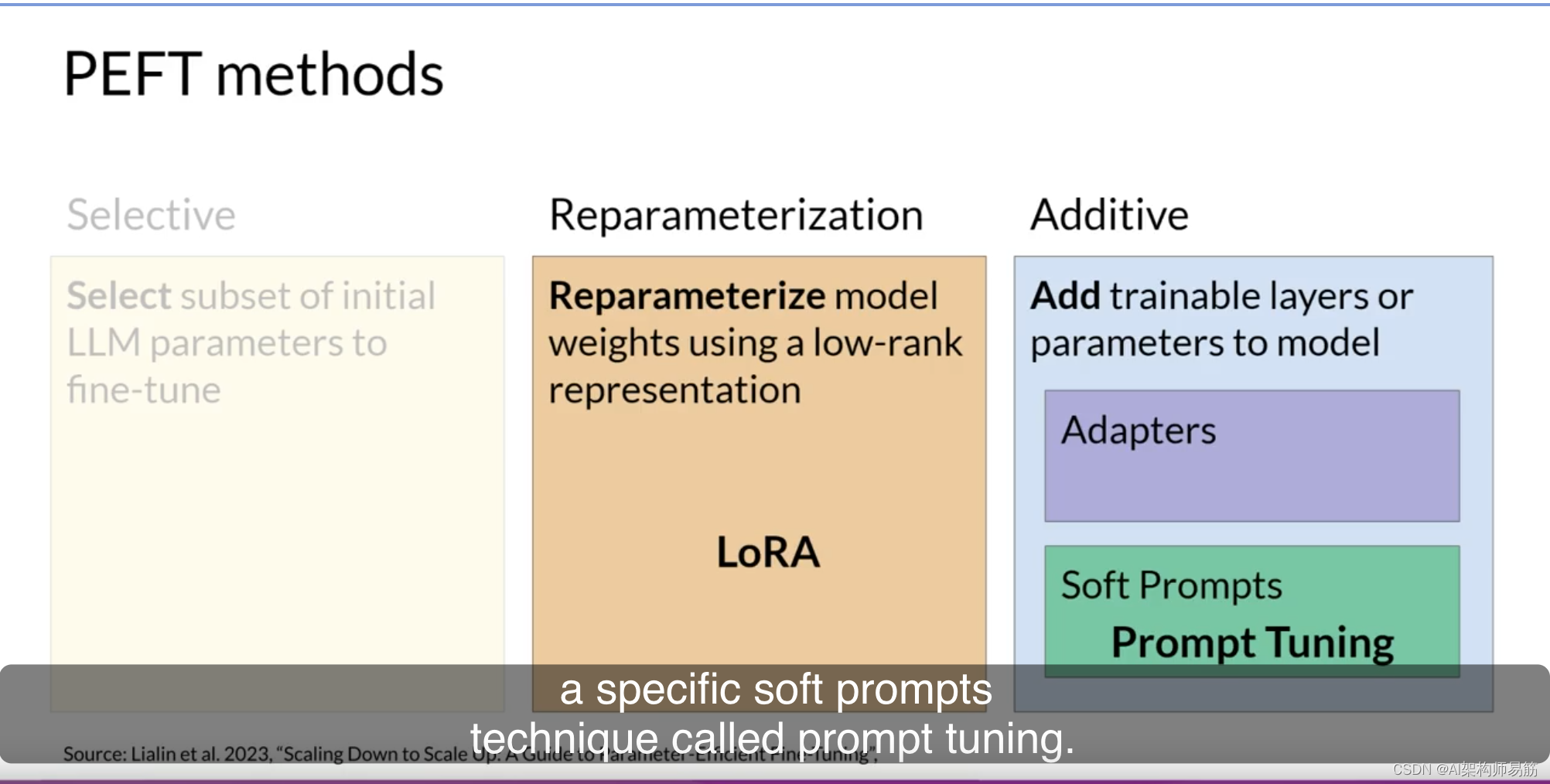
LLMs参数高效微调(PEFT) Parameter efficient fine-tuning (PEFT)
正如你在课程的第一周所看到的,训练LLMs需要大量的计算资源。完整的微调不仅需要内存来存储模型,还需要在训练过程中使用的各种其他参数。
即使你的计算机可以容纳模型权重,最大模型的权重现在已经达到几百GB,你还必须能够为优化…

图像分割(三)—— Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
swin-unetsAbstractIntroductionMethod3.1 Architecture overview3.2 Swin Transformer blockAbstract
在过去的几年中,卷积神经网络(CNNs)在医学图像分析中取得了里程碑。特别是基于u型结构和跳跃连接的深度神经网络在各种医学图像任务中得到了广泛的应用。然而&a…
第三十九周:文献阅读+Transformer
目录
摘要
Abstract
文献阅读:CNN与LSTM在水质预测中的应用
现有问题
提出方法
相关模型
CNN
LSTM
CNN-LSTM神经网络模型
模型框架
CNN-LSTM神经网络
研究实验
数据集
模型评估指标
数据预处理
实验设计与结果
研究贡献
Transformer
Encoder-Dec…
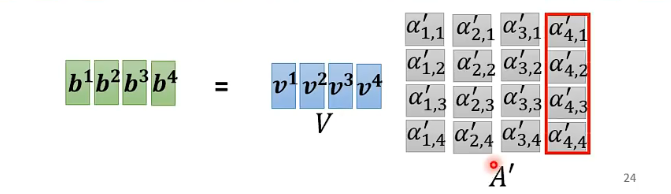
神经网络 || 注意力机制的算法图示和推导
文章目录1 注意力机制是什么?2 多输入怎么处理?3 self-attention的图示4 自己整理一下self-attention的算法过程1 注意力机制是什么?
注意力模型,最近几年在深度学习各个领域都有应用。注意力机制是深度学习常用的一个小技巧&…

【深度学习 | Transformer】释放注意力的力量:探索深度学习中的 变形金刚,一文带你读通各个模块 —— Positional Encoding(一)
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…
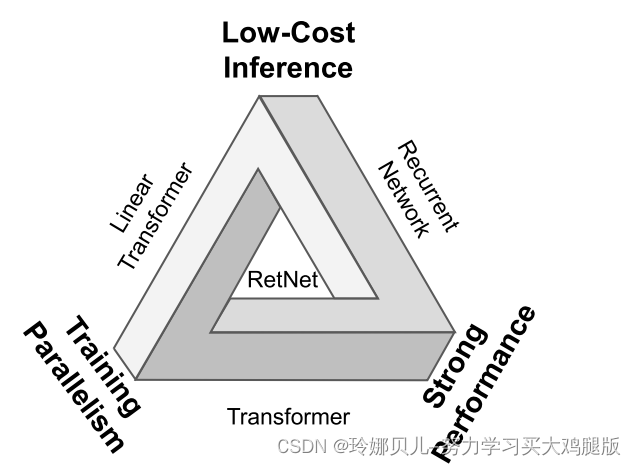
Retentive Network: A Successor to Transformer for Large Language Models
论文链接:
https://arxiv.org/pdf/2307.08621.pdf
代码链接:
https://github.com/microsoft/unilm/tree/master/retnet
引言
transformer的问题就是计算成本太高 RetNet使“不可能三角形”成为可能,同时实现了训练并行性,良好…
Transformer 位置编码
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…

《动手学深度学习 Pytorch版》 10.7 Transformer
自注意力同时具有并行计算和最短的最大路径长度这两个优势。Transformer 模型完全基于注意力机制,没有任何卷积层或循环神经网络层。尽管 Transformer 最初是应用于在文本数据上的序列到序列学习,但现在已经推广到各种现代的深度学习中,例如语…
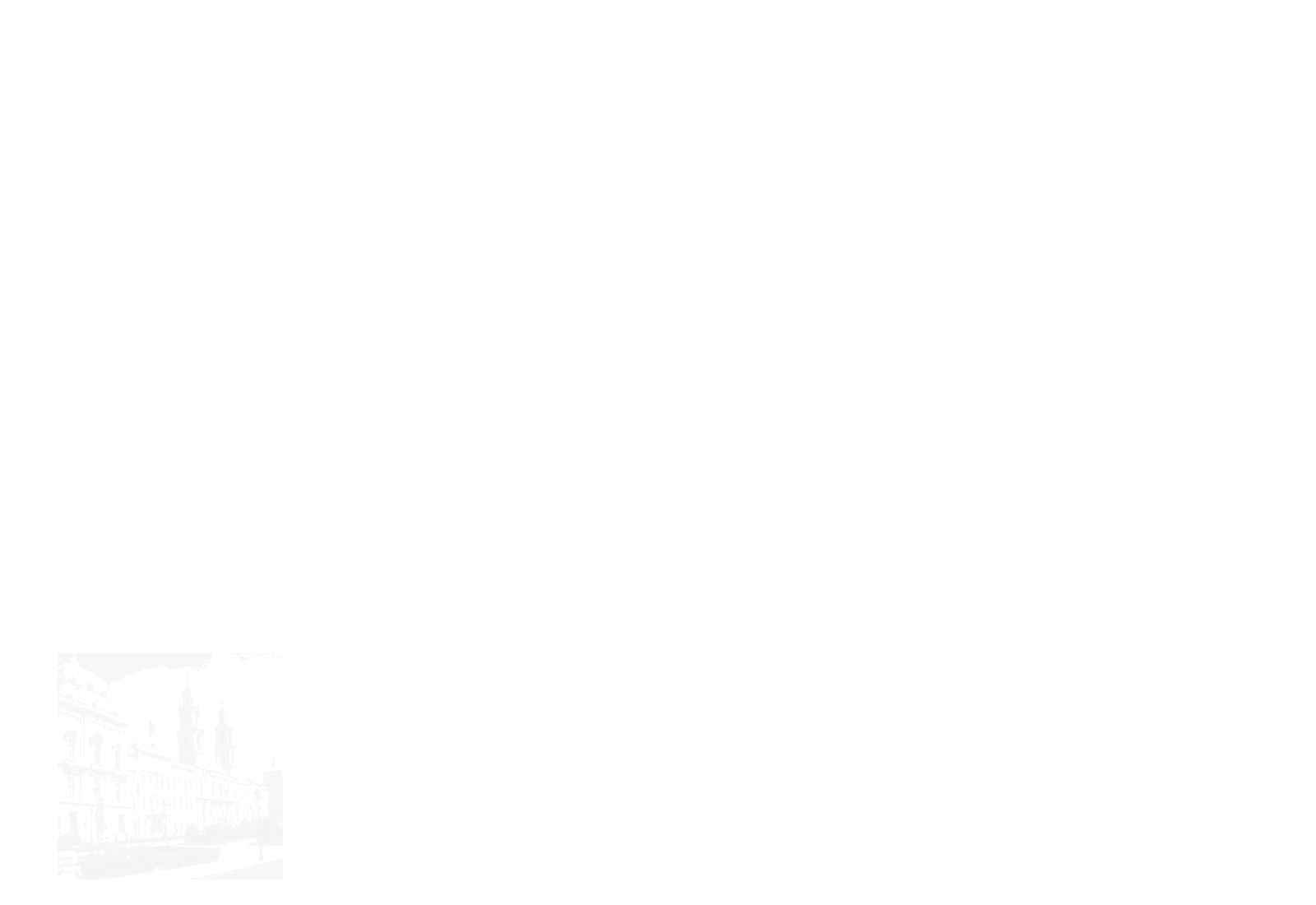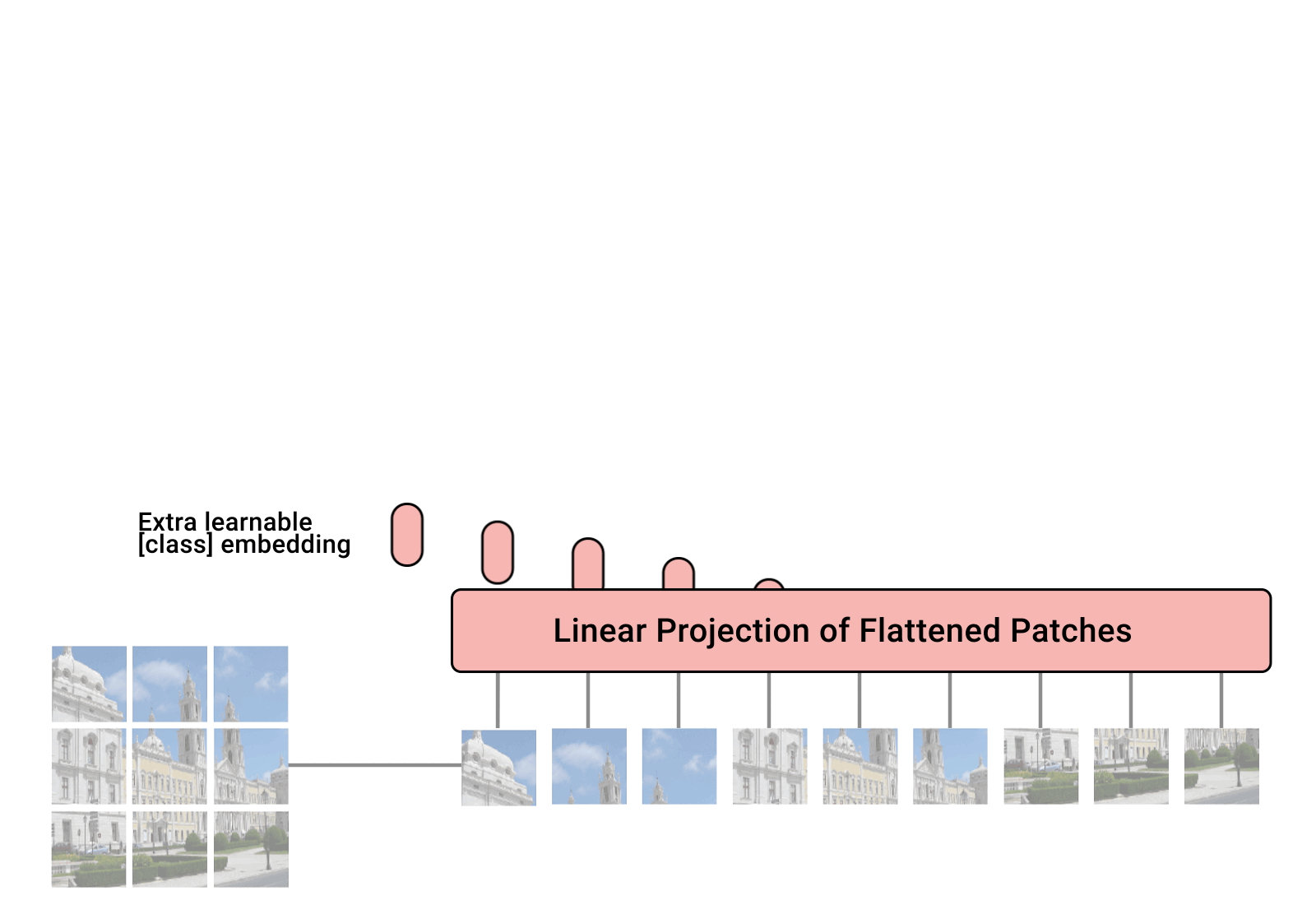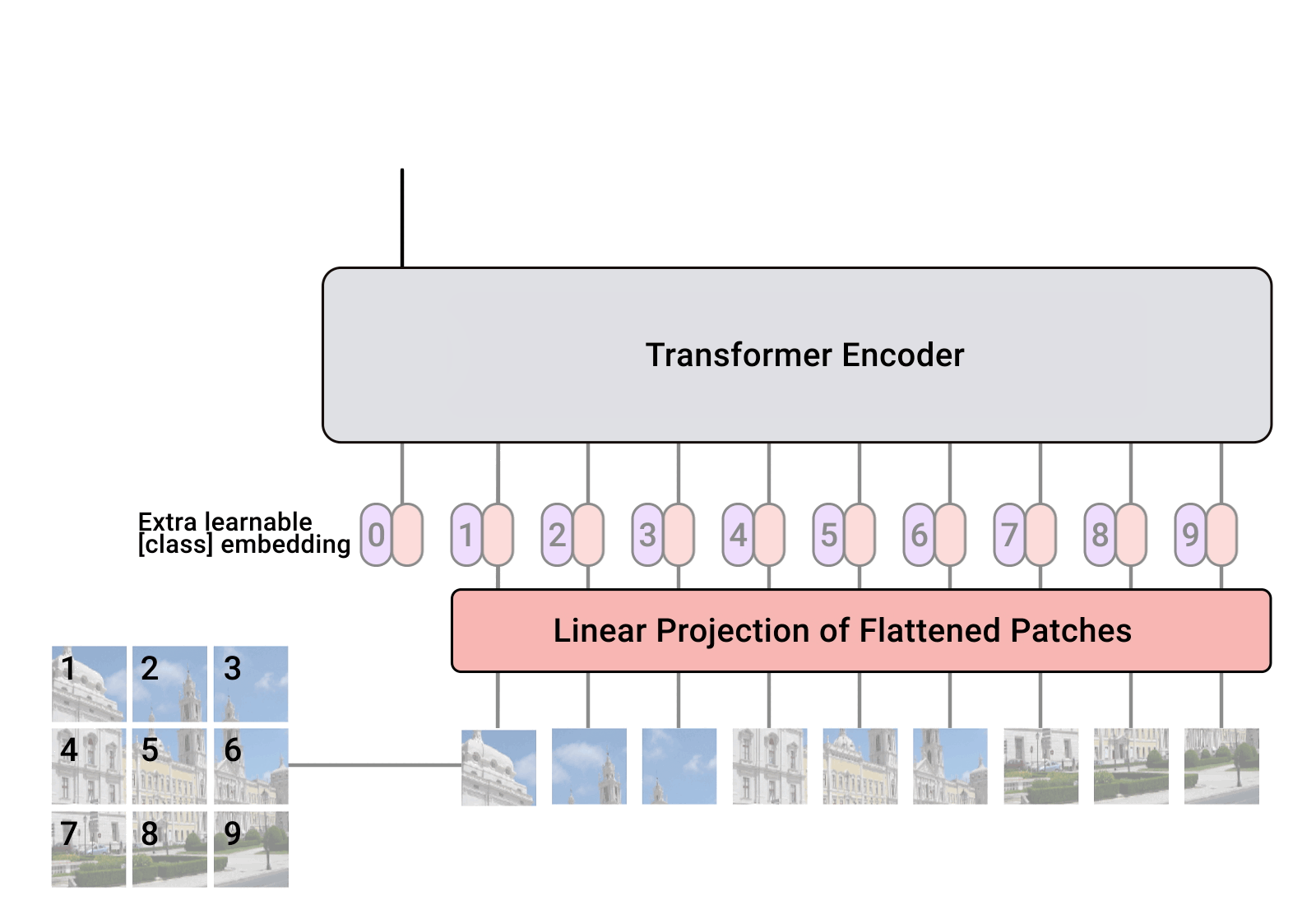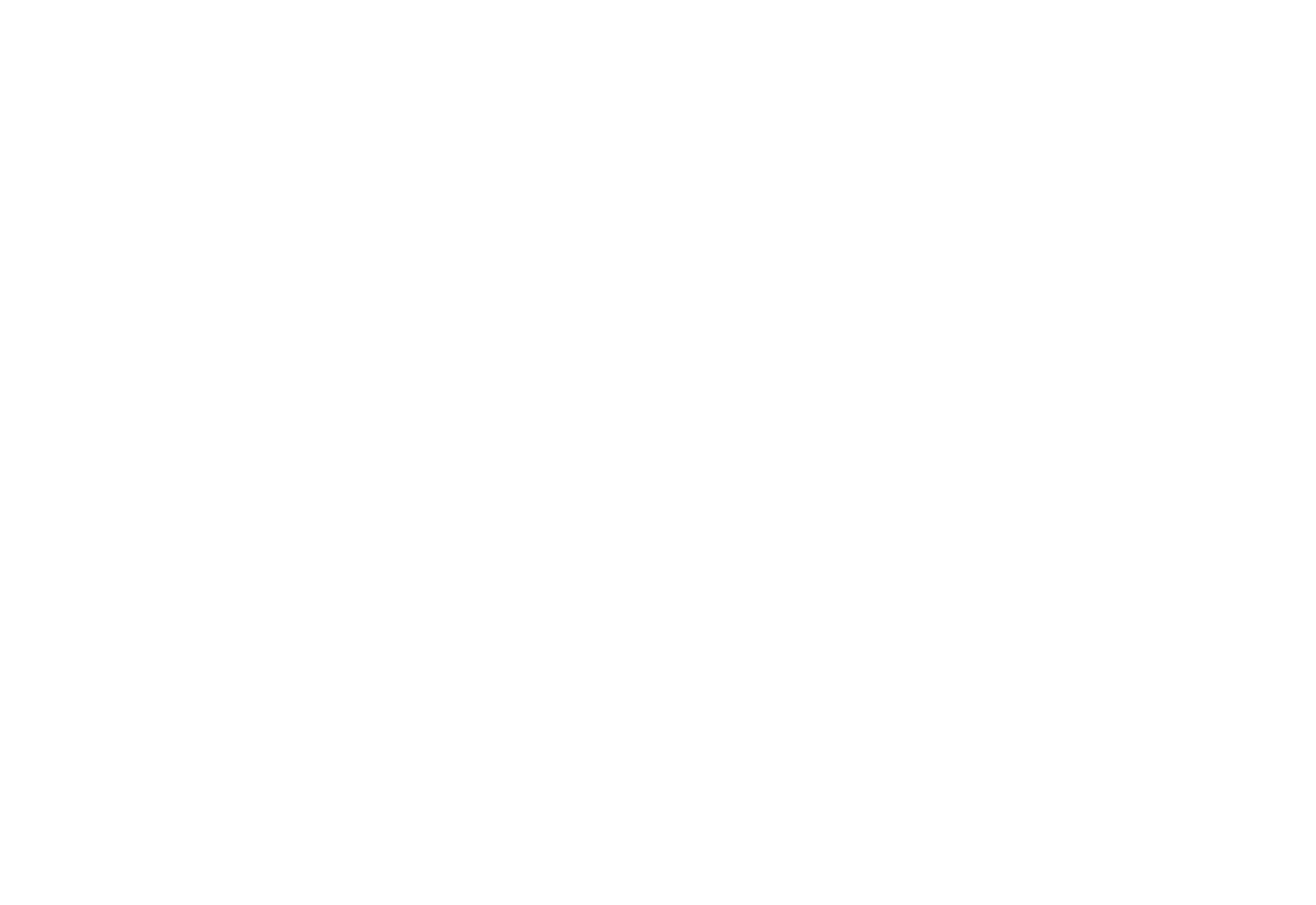
机器学习笔记 - 在 Vision Transformer 中可视化注意力
2022 年,视觉变换器(ViT) 成为卷积神经网络(CNN) 的有力竞争对手,后者现已成为计算机视觉领域的最先进技术,并广泛应用于许多图像识别应用中。在计算效率和准确性方面,ViT 模型超过了当前最先进的 (CNN) 几乎四倍。
一、视觉转换器 (ViT) 如何工作? 视觉转换器模型的性能…
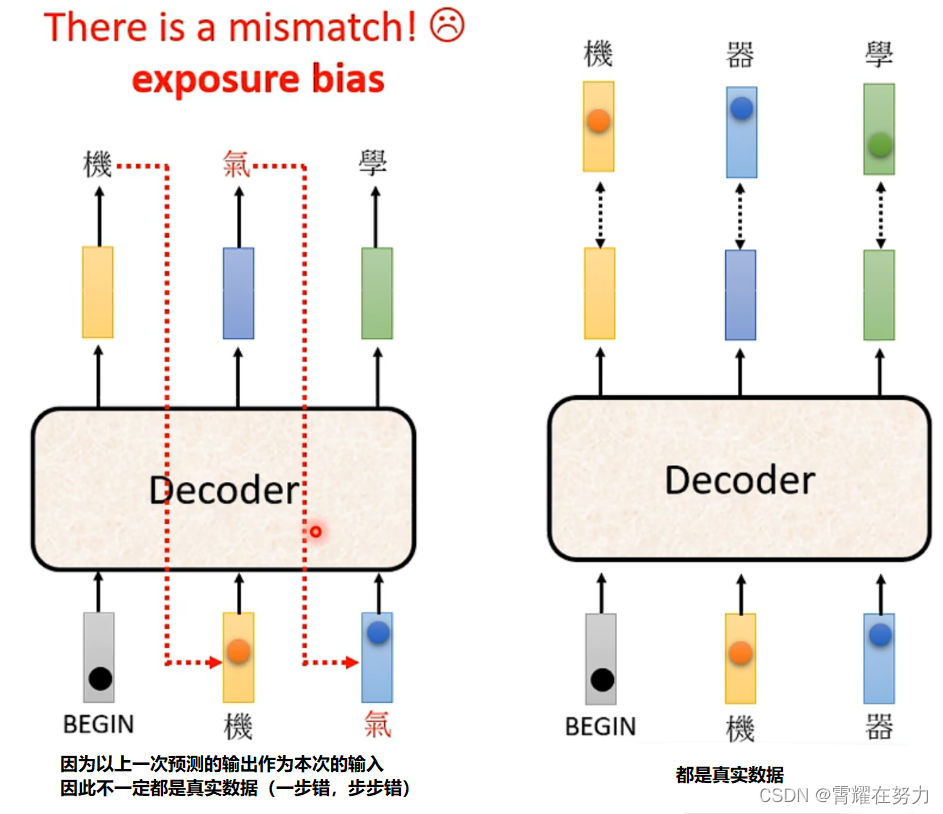
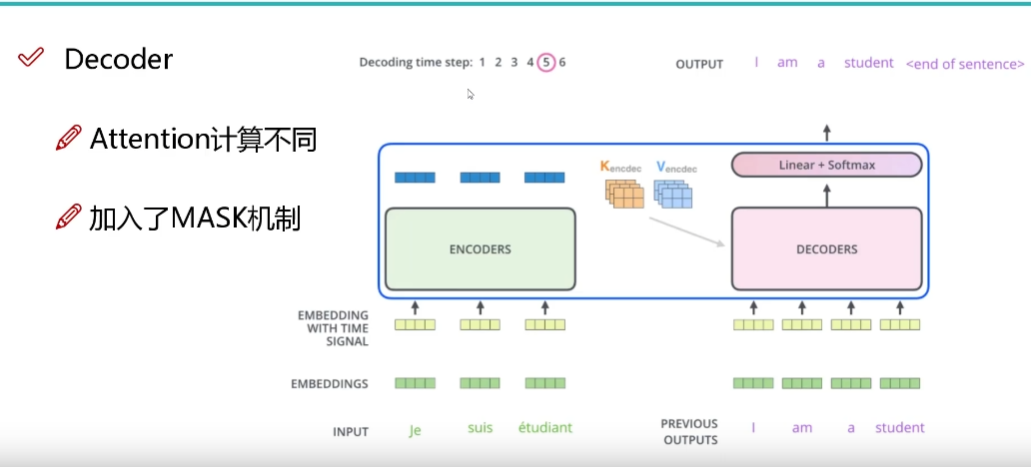
Decoder如何工作、Transformer如何训练、以及exposure bias问题
一、Decoder工作部分(以一个例子介绍工作流程,以及Decoder输出结果是什么样的)Decoder是如何工作的(这也是Decoder与Encoder之间的连接)?Decoder的工作主要涉及到交互注意力,所谓交互注意力是指…

时间序列预测模型实战案例(八)(Informer)BestPaper论文模型Informer代码实战讲解
论文地址->Informer论文地址PDF点击即可阅读
代码地址-> 论文官方代码地址点击即可跳转下载GIthub链接 本文介绍
本篇博客带大家看的是Informer模型进行时间序列预测的实战案例,它是在2019年被提出并在ICLR 2020上被评为Best Paper,可以说Inform…
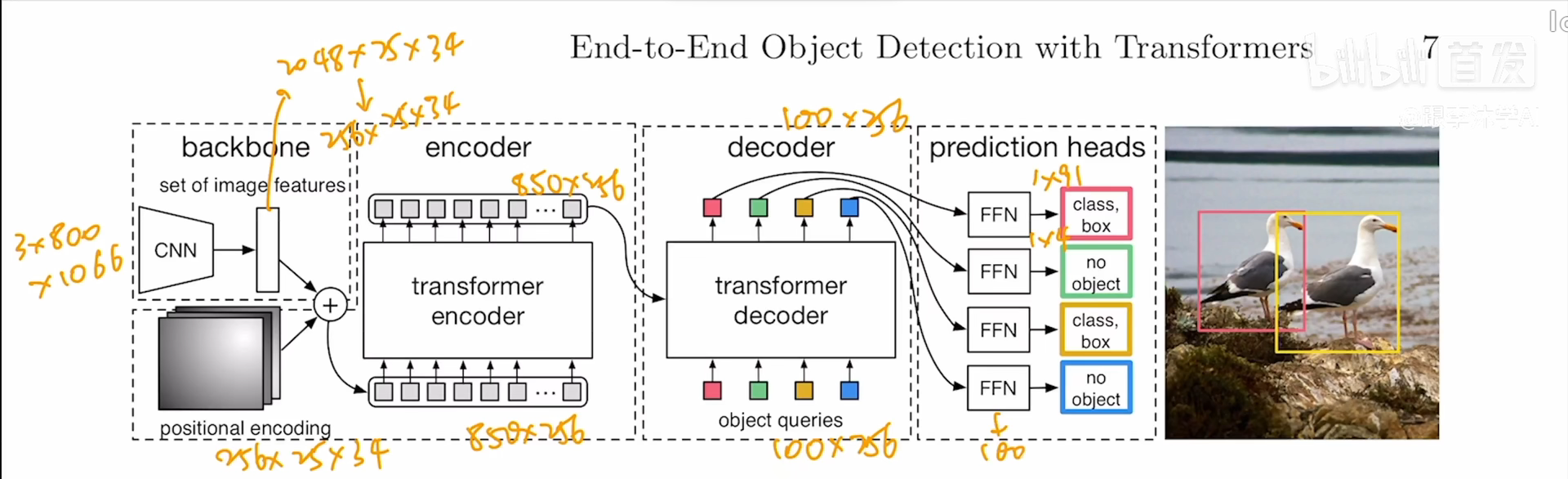
目标检测DETR:End-to-End Object Detection with Transformers
NMS
对一个目标生成了多个检测窗口,但是事实上这些窗口中大部分内容都是重复的,找到目标检测最优的窗口
选取多个检测窗口中分数最高的窗口,剔除掉其他同类型的窗口
anchor generator
首先在该点生成scale512, aspect ratio{1:2ÿ…
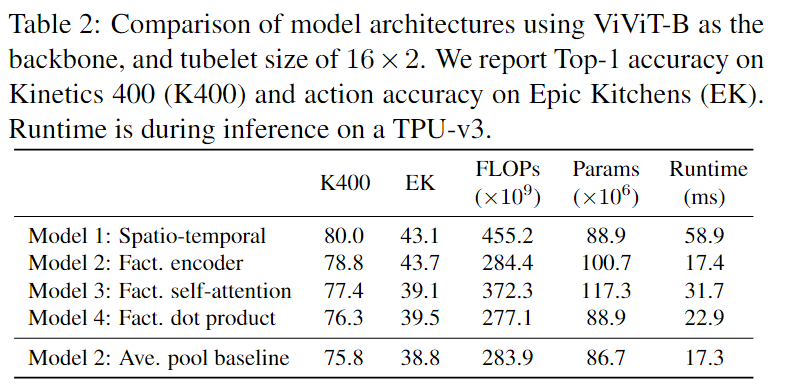
【Code Reading】Transformer in vision and video
文章目录 1. vit2. Swin-t3. vit_3D4. TimeSformer First🚀🚀5. vivit 1. vit
详细解释 在论文的Table1中有给出三个模型(Base/ Large/ Huge)的参数,在源码中除了有Patch Size为16x16的外还有32x32的。其中的Layers就…
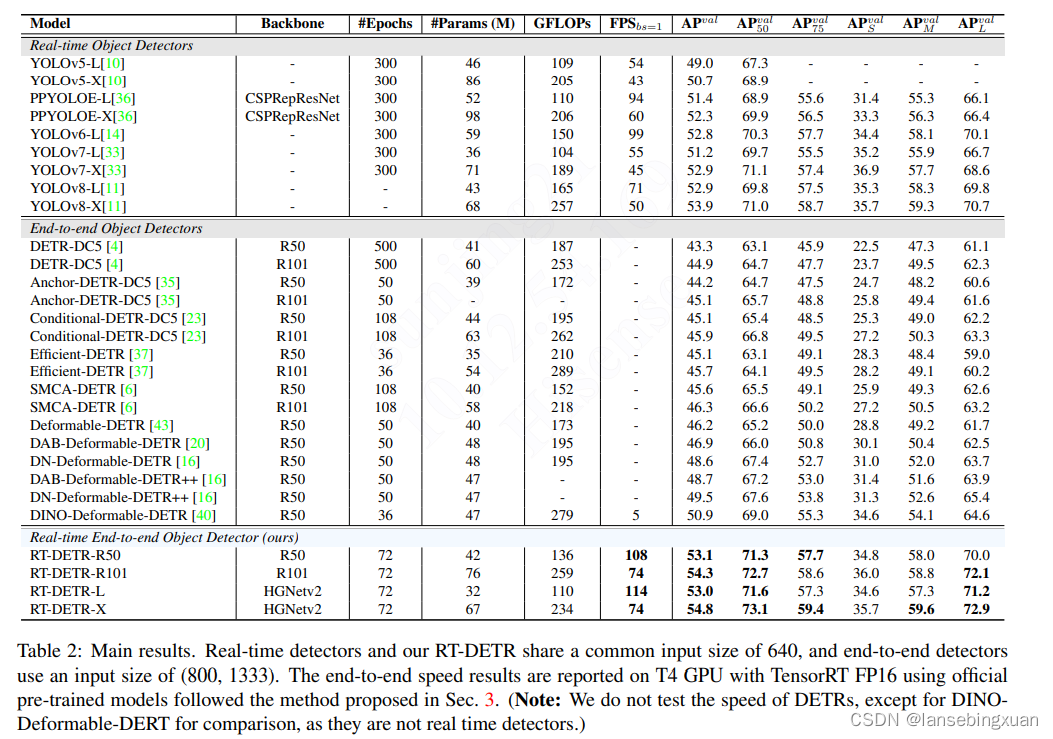
DETR系列:RT-DETR(一) 论文解析
论文:《DETRs Beat YOLOs on Real-time Object Detection》 2023.4
DETRs Beat YOLOs on Real-time Object Detection:https://arxiv.org/pdf/2304.08069.pdf
源码地址:https://github.com/PaddlePaddle/PaddleDetection/tree/develop/conf…
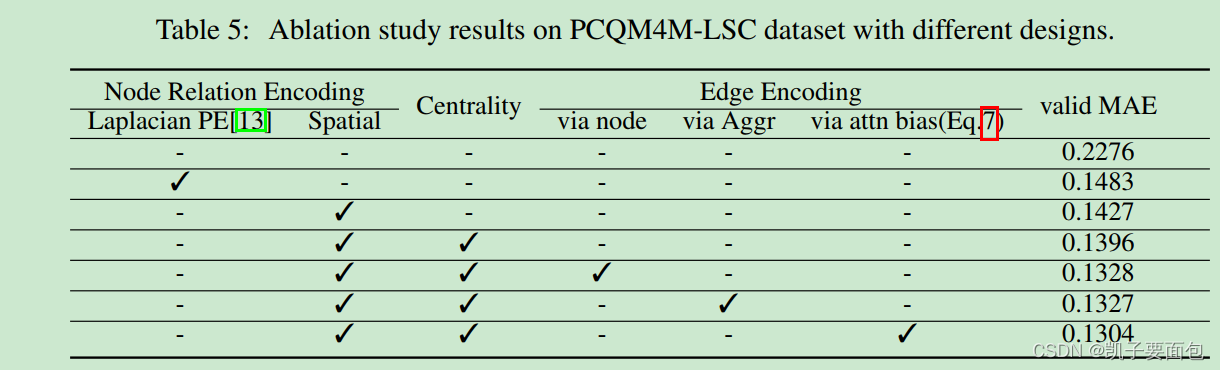
《Do Transformers Really Perform Bad for Graph Representation?》论文笔记
引言
论文提出 Graphormer 对“图数据结构”进行表征学习,Graphormer 是基于标准 Transformer 模型结构, 通过加入 Centrality Encoding、Spatial Encoding 、Edge Encoding 技术编码图结构信息, Centrality Encoding 主要用于编码节点的重要…

何凯明最新一作:Masked Autoencoders Are Scalable Vision Learners
Masked Autoencoders Are Scalable Vision Learners 何凯明大神最新一作,mask输入图像的随机patch,并重建移除的像素。 主要提出两点: 1.提出一种非对称的编码器-解码器 2.mask高比例的输入图像patch将变成一个不错且有意义的自监督任务 摘要…

文献阅读:DeepNet: Scaling Transformers to 1,000 Layers
文献阅读:DeepNet: Scaling Transformers to 1,000 Layers 1. 文章简介2. 核心技术点 1. DeepNet整体结构2. 参数初始化考察3. DeepNorm考察 3. 实验考察 1. 可行性考察2. 有效性考察 4. 结论 & 思考 文献链接:https://arxiv.org/abs/2203.00555
1…

Transformer模型简介
简介
Transformer 是 Google 团队在 17 年 6 月提出的 NLP 经典之作, 由 Ashish Vaswani 等人在 2017 年发表的论文 Attention Is All You Need 中提出。
Transformer 在机器翻译任务上的表现超过了 RNN,CNN,只用 encoder-decoder 和 atten…
自然语言处理---Transformer机制详解之BERT GPT ELMo模型的对比
1 BERT、GPT、ELMo的不同点 关于特征提取器: ELMo采用两部分双层双向LSTM进行特征提取, 然后再进行特征拼接来融合语义信息.GPT和BERT采用Transformer进行特征提取.很多NLP任务表明Transformer的特征提取能力强于LSTM, 对于ELMo而言, 采用1层静态token embedding 2层LSTM, 提取…
LLMs多任务指令微调Multi-task instruction fine-tuning
多任务微调是单任务微调的扩展,其中训练数据集包括多个任务的示例输入和输出。在这里,数据集包含指导模型执行各种任务的示例,包括摘要、评论评分、代码翻译和实体识别。
您在这个混合数据集上训练模型,以便它可以同时提高模型在…

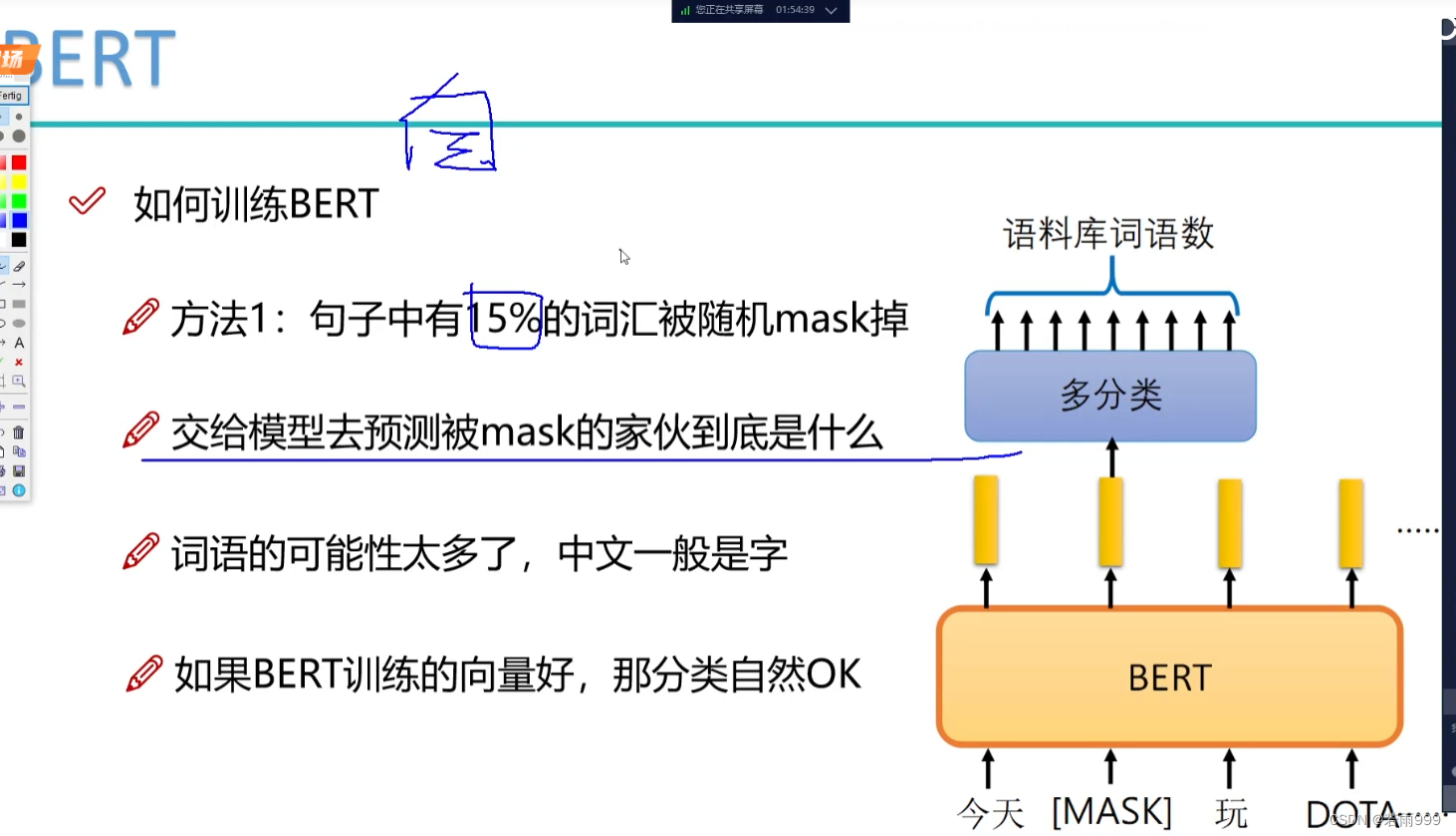
bert中为什么要这么msdk(80% mask, 10% 随机替换,10% 保持原词)
bert在训练阶段不是将15%的词汇MASK掉,从而采用自监督的方式训练模型,那我直接将这15%mask掉不就好了吗,为什么又要进行80% mask,10% 随机替换,10% 保持原词呢?起初我看到的时候也比较迷惑,下面…

Transformer and Pretrain Language Models3-1
content
transformer
attention mechanism
transformer structure pretrained language models
language modeling
pre-trained langue models(PLMs)
fine-tuning approaches
PLMs after BERT
applications of masked LM
frontiers of PLMs …
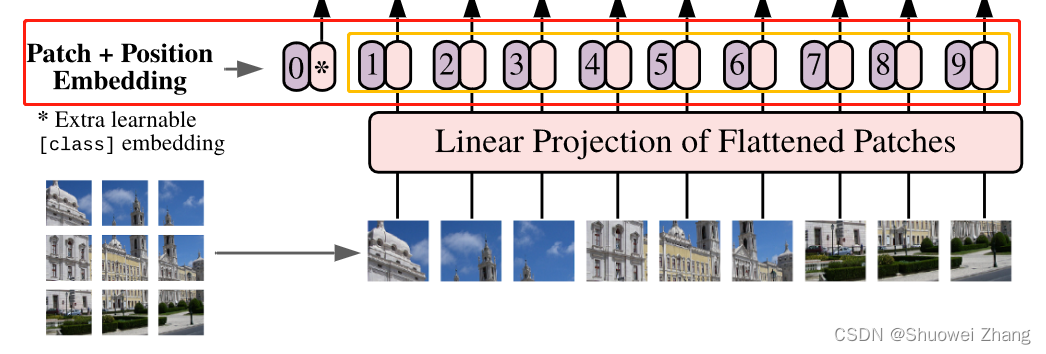
ViT论文Pytorch代码解读
ViT论文代码实现 论文地址:https://arxiv.org/abs/2010.11929 Pytorch代码地址:https://github.com/lucidrains/vit-pytorch ViT结构图 调用代码
import torch
from vit_pytorch import ViTdef test():v ViT(image_size 256, patch_size 32, num_cl…
ModuleNotFoundError: No module named ‘SwissArmyTransformer‘
小问题,直接pip install pip install SwissArmyTransformer
但是,安装之后却还是提示,屏幕上依然标红 ModuleNotFoundError: No module named SwissArmyTransformer 查找环境目录发现, 这是因为新版的SwissArmyTransformer中&…

使用Swin-Transformer-Semantic-Segmentation训练自己的数据(语义分割,自己做数据)
使用Swin-Transformer-Semantic-Segmentation训练自己的数据系统配置代码链接针对MMCV 选择系统Windows环境要求:ubuntu 18.04安装swin segmentation制作VOC 数据集代码部分修改开始训练恭喜Swin Transformer拿到2021 ICCV Best Paper!MSRA再一次拿到Bes…

Uniformer: Unified Transformer for Efficient Spatial-Temporal Representation Learning
Unified Transformer for Efficient Spatial-Temporal Representation Learning1. Motivation2. Method2.1 MHRA:2.2 DPE2.3 FFN1. Motivation
高维视频具有大量的局部冗余和复杂的全局依赖关系,而该研究主要是由3D卷积神经网络和视觉Transformer驱动。…

图像分割(二)—— Segmenter: Transformer for Semantic Segmentation
Segmenter: Transformer for Semantic SegmentationAbstract1. IntroductionOur approach: Segmenter3.1. Encoder3.2. DecoderAbstract
图像分割往往在图像 patch 的级别上模棱两可,并需要上下文信息达成标签一致。本文介绍了一种用于语义分割的 transformer 模型…
R语言:ca和MASS包实现对应分析并绘图解释
文章目录 对应分析R语言求解案例ca包codeMASScode对应分析的问题对应分析 对应分析(correspondence analysis)是用于寻求列联表的行和列之间联系的一种低维图形表示法,它可以从直觉上揭示出同一分类变量的各个类别之间的差异,以及不同分类变量各个类别之间的对应关系。对应…

Transformer实战-系列教程1:Transformer算法解读
现在最火的AI内容,chatGPT、视觉大模型、研究课题、项目应用现在都是Transformer大趋势了
1、传统的RNN Transformer是基于RNN改进提出的,RNN不同于CNN、MLP是一个需要逐个计算的结构来进行分类回归的任务,它的每一个循环单元不仅仅要接受当…
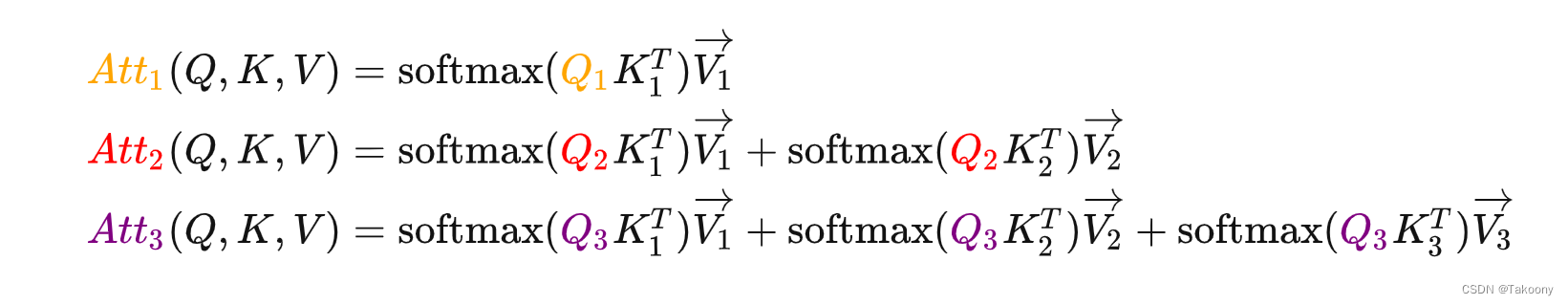
transformer之KV Cache
一、为什么要研究KV Cache 非常有效的加速推理速度,效果如下所示: import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
NAME_OR_PATH r***************
device "cuda" if torch.cu…

论文总结:3D Talking Face With Personalized Pose Dynamics
论文解决的问题:大多数现有的3D人脸生成方法只能生成静态头部姿势的3D面部,只有少数几篇文章关注头部姿势的生成,但这些文章也忽略了个体属性。 解决方法:框架由两个独立模块组成:PoseGAN和PGFace。给定输入音频,PoseGAN首先为3D头部生成一个头部姿势序列,然后PGFace利用…
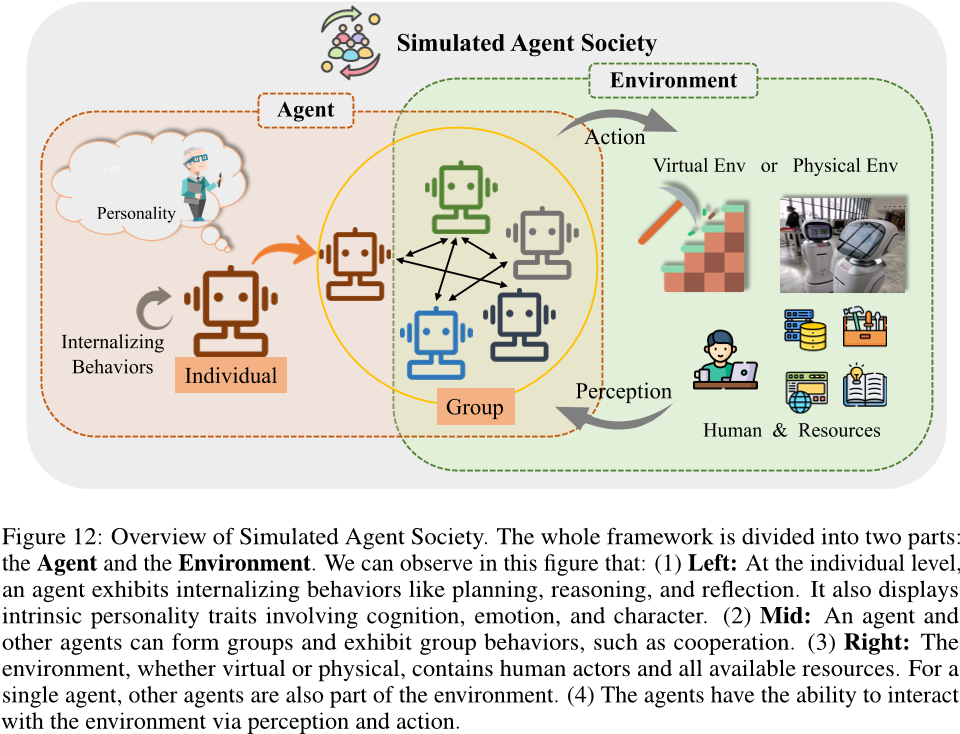
The Rise and Potential of Large Language Model Based Agents: A Survey 中文翻译
大型语言模型代理的崛起与潜力:综述
摘要
长期以来,人类一直追求与或超越人类水平的人工智能(AI),而人工智能代理被视为实现这一目标的有希望的方式。人工智能代理是感知环境、做出决策并采取行动的人工实体。已经有…
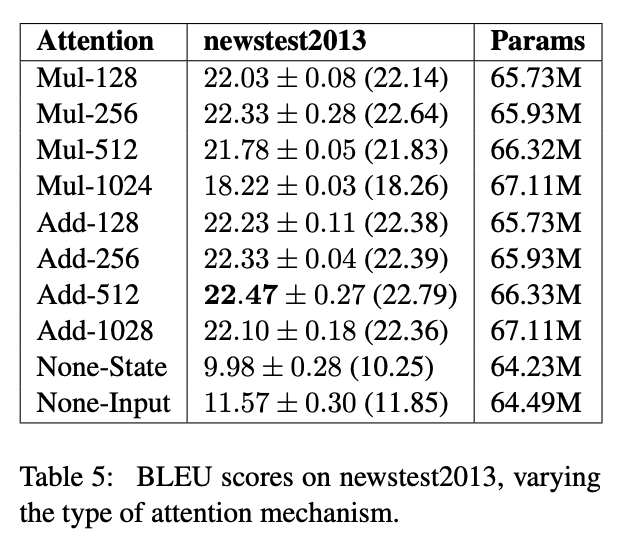
解析Transformer模型
原文地址:https://zhanghan.xyz/posts/17281/
进入Transformer
RNN很难处理冗长的文本序列,且很容易受到所谓梯度消失/爆炸的问题。RNN是按顺序处理单词的,所以很难并行化。 用一句话总结Transformer:当一个扩展性极佳的模型和一…
CAVER: Cross-Modal View-Mixed Transformer for Bi-Modal Salient Object Detection
目录
一、论文阅读笔记:
1、摘要:
2、主要贡献点:
3、方法:
3.1 网络的总体框架图:
3.2 Transformer-based Information Propagation Path (TIPP)
3.3 Intra-Modal/Cross-Scale Self-Attention (IMSA/CSSA)
Q1…
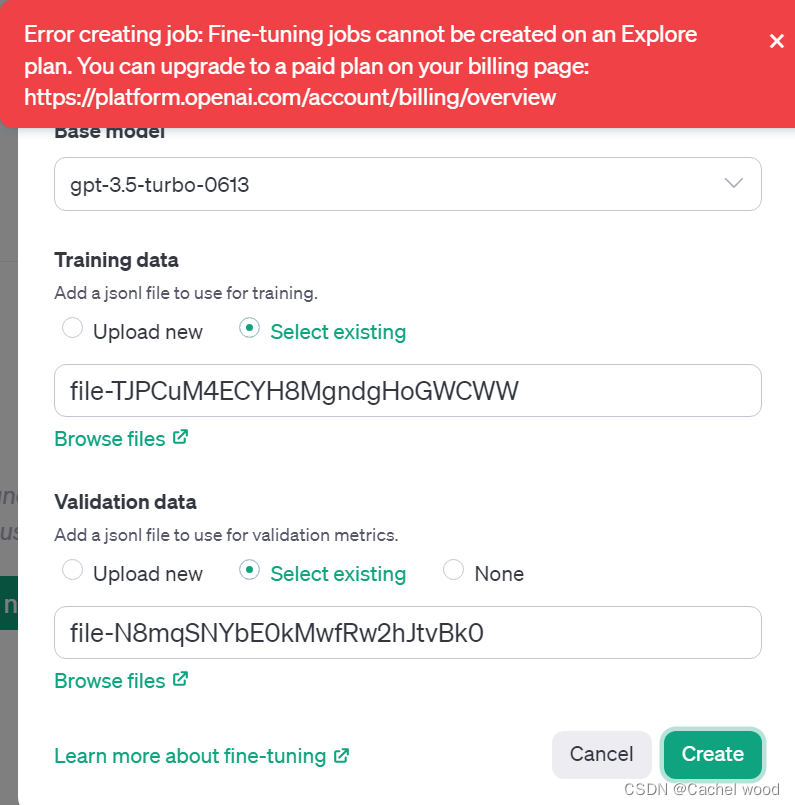
OpenAI开放gpt-3.5turbo微调fine-tuning测试教程
文章目录 openai微调 fine-tuning介绍openai微调地址jsonl格式数据集准备点击上传文件 openai微调 fine-tuning介绍
openai微调地址
网址:https://platform.openai.com/finetune jsonl格式数据集准备
使用Chinese-medical-dialogue-data数据集git clone进行下载 …
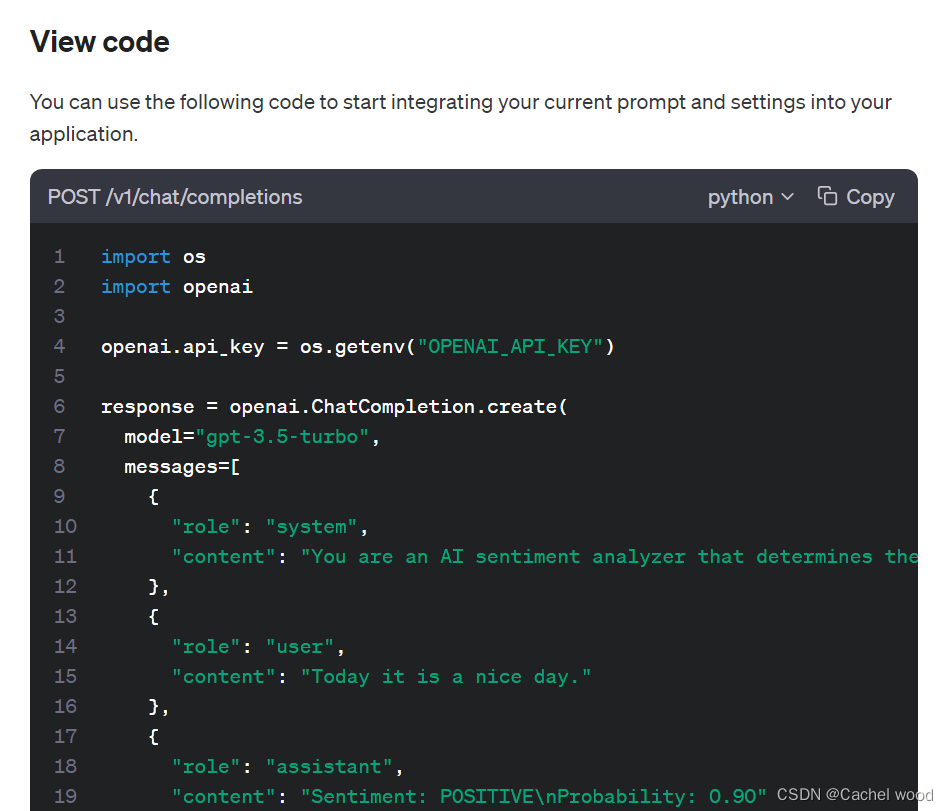
python openai playground使用教程
文章目录 playground介绍Playground特点模型设置和参数选择四种语言模型介绍 playground应用构建自己的playground应用playground python使用 playground介绍
OpenAI Playground是一个基于Web的工具,旨在帮助开发人员测试和尝试OpenAI的语言模型,如GPT-…
【自然语言处理】Transformer-XL 讲解
Transformer-XL
首先需要明确,Transformer-XL(XL 是 extra long 的简写)只是一个堆叠了自注意力层的 BPTT 语言模型,并不是 Transformer 原始论文中提到的编码器-解码器架构,也不是原始 Transformer 中的编码器部分或者解码器部分,根据其大致实现可以将其理解为丢弃 cro…
简单有趣的变形金刚网络(VIT) Vision Transformer(网络结构详解+详细注释代码+核心思想讲解)——pytorch实现
论文题目: An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale 原论文下载链接:https://arxiv.org/abs/2010.11929原论文对应源代码:mirrors / google-research / vision_transformer GitCode Transformer最先应用于在NIP领域,并且取得了巨大的…
基于transformer的心脑血管心脏病疾病预测
视频讲解:基于transformer的心脑血管疾病预测 完整数据代码分享_哔哩哔哩_bilibili
数据展示: 完整代码:
# pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple/
# pip install optuna -i https://pypi.tuna.tsinghua.edu.cn/simple/
import numpy as np
…
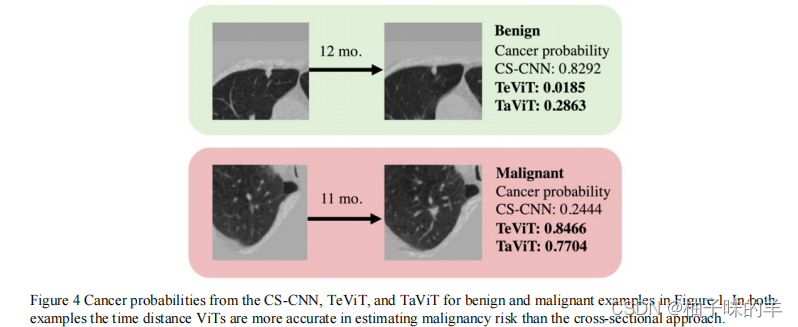
文献阅读(50)—— Transformer 用于肺癌诊断预测
文献阅读(50)—— Transformer 用于肺癌诊断预测 文章目录 文献阅读(50)—— Transformer 用于肺癌诊断预测先验知识/知识拓展文章结构背景文章方法1. 文章核心网络结构2. Time Encoding ViT (TeViT)3. Tim…
【YOLOv8/YOLOv7/YOLOv5系列算法改进NO.56】引入Contextual Transformer模块(为本人sci期刊创新点之一)
文章目录 前言一、解决问题二、基本原理三、添加方法四、总结前言
作为当前先进的深度学习目标检测算法YOLOv8,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv8的如何改进进行详细…
LLMs 缩放指令模型Scaling instruct models FLAN(Fine-tuned LAnguage Net,微调语言网络)
本论文介绍了FLAN(Fine-tuned LAnguage Net,微调语言网络),一种指导微调方法,并展示了其应用结果。该研究证明,通过在1836个任务上微调540B PaLM模型,同时整合Chain-of-Thought Reasoning&#…
案例系列:Movielens_预测用户对电影的评分_基于行为序列Transformer的推荐系统
文章目录 简介数据集设置准备数据下载并准备数据框将电影评分数据转换为序列 定义元数据为训练和评估创建 tf.data.Dataset创建模型输入编码输入特征创建一个二叉搜索树模型运行训练和评估实验结论 描述: 使用行为序列Transformer(BST)模型在…

【Transformer系列】关于Transformer的若干问题FAQ解析
一、参考资料
Transformer的细节到底是怎么样的?Transformer 18问
答案解析(1)—史上最全Transformer面试题:灵魂20问帮你彻底搞定Transformer 关于Transformer的若干问题整理记录 Transformer的细节与技巧
二、FAQ
Q:什么是Transformer&…
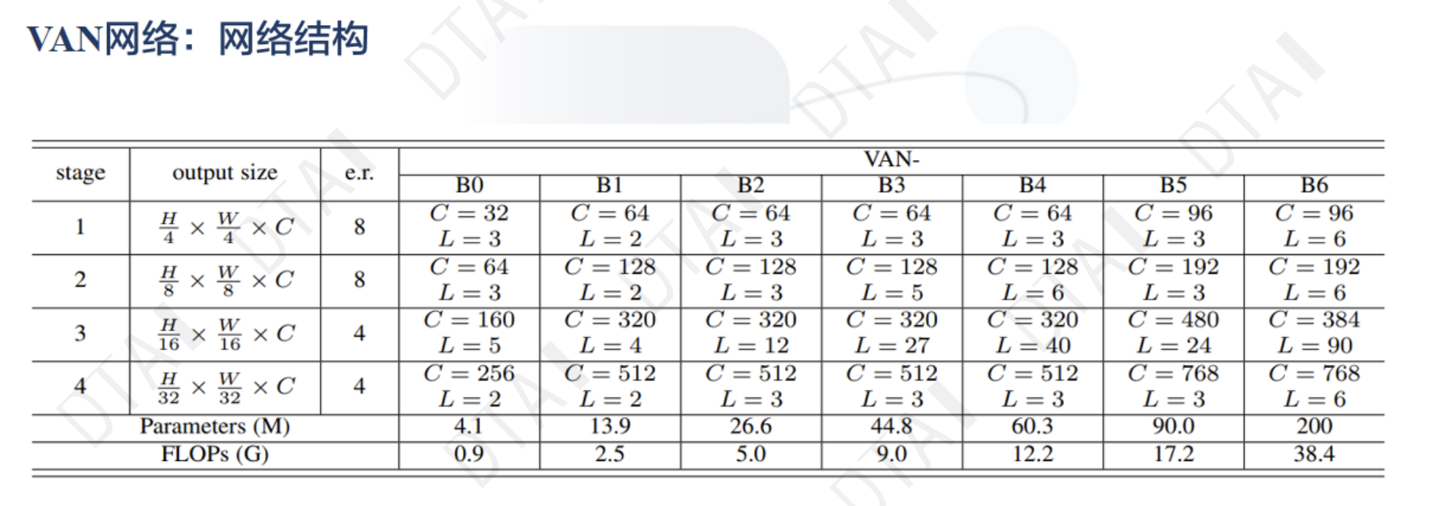
Transformer在视觉的应用
文章目录 Vison TransformerSwin TransformerVisual Attention Network Vison Transformer
transformer 在 cv 中最重要的算法
Linear Projection of Flattened Patches 对于标准的Transformer模块,要求输入的是token(向量)序列ÿ…
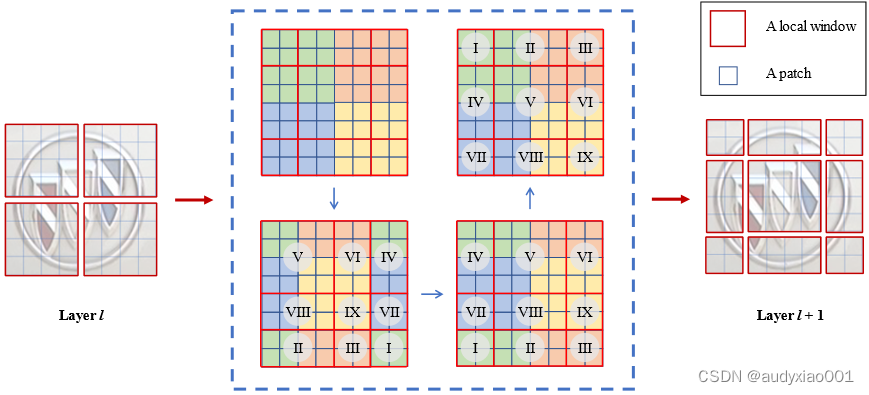
TRB 2024论文分享:一种基于Swin Transformer的车标识别新方法
TRB(Transportation Research Board,美国交通研究委员会,简称TRB)会议是交通研究领域知名度最高学术会议之一,近年来的参会人数已经超过了2万名,是参与人数和国家最多的学术盛会。TRB会议几乎涵盖了交通领域…
第一课:Transformer
第一课:Transformer 文章目录 第一课:Transformer1、学习总结:什么是语言模型?大语言模型(LLM)技术演变史注意力机制Transformer结构课程ppt及代码地址 2、学习心得:3、经验分享:4、…
15 Transformer 框架概述
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html 1000*0.04=40–>10 …

DeiT:使用Attention蒸馏Transformer
题目:Training data-efficient image transformers & distillation through attention
【GiantPandaCV导语】Deit是一个全Transformer的架构,没有使用任何的卷及操作。其核心是将蒸馏方法引入VIT的训练,引入了一种教师-学生的训练策略&a…

Transformer and Pretrain Language Models3-2
transformer structure注意力机制的各种变体
第二种变体:
如果两个向量的维度不一样,我们就需要在中间加上一个权重矩阵,来实现他们之间的相乘,然后最后得到一个标量
第三种变体:
additive attention
它和前面的有…
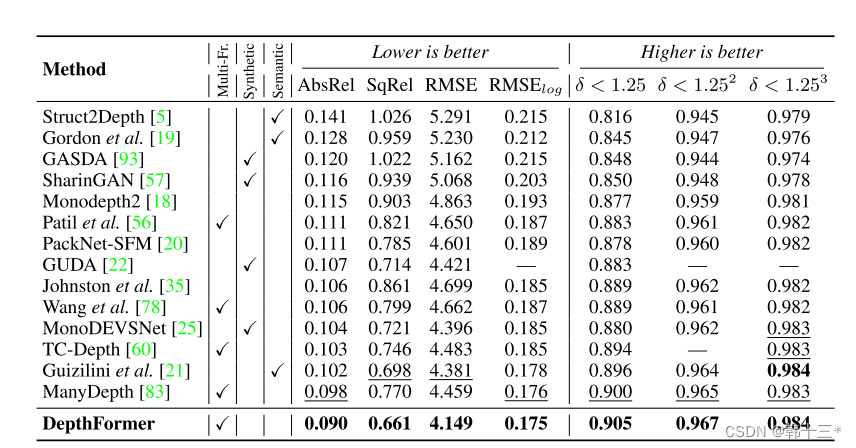
基于transformer的多帧自监督深度估计 Multi-Frame Self-Supervised Depth with Transformers
Multi-Frame Self-Supervised Depth with Transformers基于transformer的多帧自监督深度估计0 Abstract 多帧深度估计除了学习基于外观的特征外,也通过特征匹配利用图像之间的几何关系来改善单帧估计。我们采用深度离散的核极抽样来选择匹配像素,并通过一…
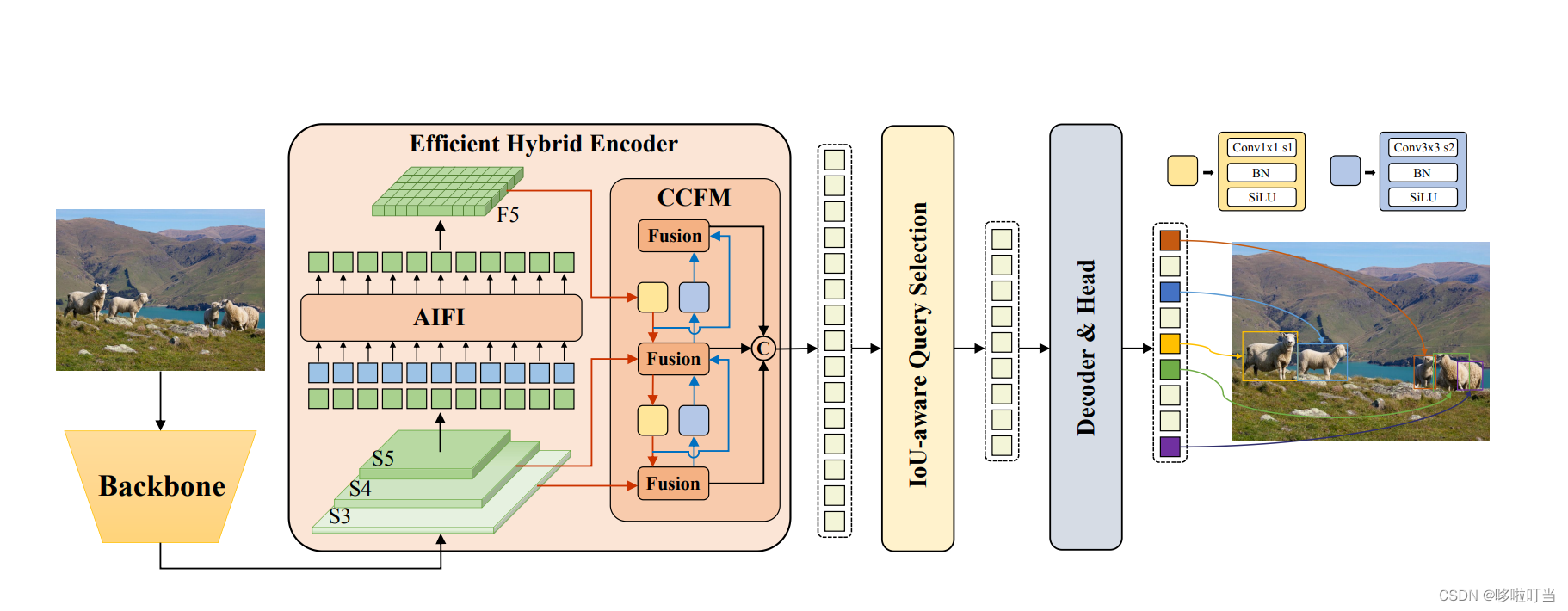
DETR解读,将Transformer带入CV
论文出处
[2005.12872] End-to-End Object Detection with Transformers (arxiv.org)
一个前置知识
匈牙利算法:来源于二部图匹配,计算最小或最大匹配
算法操作:在n*n的矩阵中 减去行列最小值,更新矩阵(此时行或者…
transformer系列5---transformer显存占用分析
Transformer显存占用分析 1 影响因素概述2 前向计算临时Tensor显存占用2.1 self-attention显存占用2.2 MLP显存占用 3 梯度和优化器显存占用3.1 模型训练过程两者显存占用3.2 模型推理过程两者显存占用 1 影响因素概述
模型训练框架:例如pytorch框架的cuda context…
机器学习笔记 - 对象/目标检测技术发展史概览
一、简述 物体检测算法的发展已经取得了长足的进步,从早期的计算机视觉开始,通过深度学习达到了很高的准确度。 我们首先回顾早期传统的目标检测方法:Viola-Jones 检测器、HOG 检测器和基于部件的方法,它们在该领域发展之初就被广泛使用。 然后,逐渐转向基于两阶段和一阶段…
TensorFlow的transformer类模型文件转换为pytorch
在进行transformer类模型的训练或开发时,我们会在GitHub、huggingface等平台上下载已有的模型文件。个人习惯用pytorch框架进行代码编写,然而很多时候在下载模型文件时,会遇到TensorFlow的模型,这是就涉及到转换的问题。
首先说一…

transfomer中Decoder和Encoder的base_layer的源码实现
简介
Encoder和Decoder共同组成transfomer,分别对应图中左右浅绿色框内的部分. Encoder: 目的:将输入的特征图转换为一系列自注意力的输出。 工作原理:首先,通过卷积神经网络(CNN)提取输入图像的特征。然…

transfomer的位置编码
什么是位置编码
在transformer的encoder和decoder的输入层中,使用了Positional Encoding,使得最终的输入满足: input_embeddingpositional_encoding 这里,input_embedding的shape为[n,b,embed_dim],positional_encoding和input_…
图像分割(七) —— Transformer and CNN Hybrid Deep Neural Network
Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-High-Resolution Remote Sensing ImageryAbstractMethodA. ArchitectureB. Swin Transformer-Based EncoderC. CNN-Based DecoderAbstract
本文提出了一种变压器和卷积神经网络(…

深入了解Transformer:从编码器到解码器的神经网络之旅
深入了解Transformer:从编码器到解码器的神经网络之旅
0.引言
自2017年问世以来,Transformer模型在自然语言处理(NLP)领域引发了一场革命。它的独特设计和高效性能使其成为了解决复杂语言任务的关键工具。
1.Transformer的核心…

YOLOv8优化策略:检测头结构全新创新篇 | RT-DETR检测头助力,即插即用
🚀🚀🚀本文改进:RT-DETR检测头助力YOLOv8检测,保持v8轻量级的同时提升检测精度 🚀🚀🚀YOLOv8改进专栏:http://t.csdnimg.cn/hGhVK
学姐带你学习YOLOv8,从入门到创新,轻轻松松搞定科研; 1.RT-DETR介绍 论文: https://arxiv.org/pdf/2304.08069.pdf
摘要:…
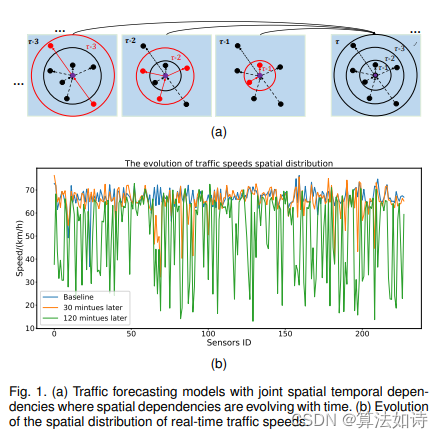
Transformer模型 | 基于Spatial-Temporal Transformer的城市交通流预测
交通预测已成为智能交通系统的核心组成部分。然而,由于交通流的高度非线性特征和动态的时空依赖性,及时准确的交通预测,尤其是长时交通流预测仍然是一个开放性的挑战。在这篇文章中,作者提出了一种新的时空Transformer网络(STTNs)模型,该模型联合利用了动态有向的空间依…

【李宏毅机器学习】Transformer 内容补充
视频来源:10.【李宏毅机器学习2021】自注意力机制 (Self-attention) (上)_哔哩哔哩_bilibili
发现一个奇怪的地方,如果直接看ML/DL的课程的话,有很多都是不完整的。开始思考是不是要科学上网。
本文用作Transformer - Attention is all you…
Elasticsearch:从头开始解释带有 Transformer 的生成式 AI 架构
作者:ARIS PAPADOPOULOS
这篇长篇文章解释了生成式人工智能的工作原理,从基础一直到注重直觉的生成式 transformer 架构。 这篇长篇文章解释了生成式人工智能的工作原理,从基础一直到生成式 transformer 架构。 重点是直觉,而不是…

【RT-DETR改进】SIoU、GIoU、CIoU、DIoU、AlphaIoU等二十余种损失函数
一、本文介绍
这篇文章介绍了RT-DETR的重大改进,特别是在损失函数方面的创新。它不仅包括了多种IoU损失函数的改进和变体,如SIoU、WIoU、GIoU、DIoU、EIOU、CIoU,还融合了“Alpha”思想,创造了一系列新的损失函数。这些组合形式的…

为什么Transformer模型中使用Layer Normalization(Layer Norm)而不是Batch Normalization(BN)
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…

RWKV论文燃爆!将RNN崛起进行到底!可扩百亿级参数,与Transformer表现相当!
深度学习自然语言处理 原创作者:鸽鸽 万众期待的RWKV论文来啦! 这股RNN崛起的“清流”,由民间开源组织发起,号称是第一个可扩展到百亿级参数的非transformer架构! RWKV结合了RNN和Transformer的优势:一方面…

Transformer升级之路:一种全局长度外推的新思路
©PaperWeekly 原创 作者 | 苏剑林 单位 | 追一科技 研究方向 | NLP、神经网络 说到 Transformer 无法处理超长序列的原因,大家的第一反应通常都是 Self Attention 的二次复杂度。但事实上,即便忽略算力限制,常规的 Transformer 也无法处…
RWKV – transformer 与 RNN 的强强联合
在 NLP (Natural Language Processing, 自然语言处理) 领域,ChatGPT 和其他的聊天机器人应用引起了极大的关注。每个社区为构建自己的应用,也都在持续地寻求强大、可靠的开源模型。自 Vaswani 等人于 2017 年首次提出 Attention Is All You Need 之后&am…
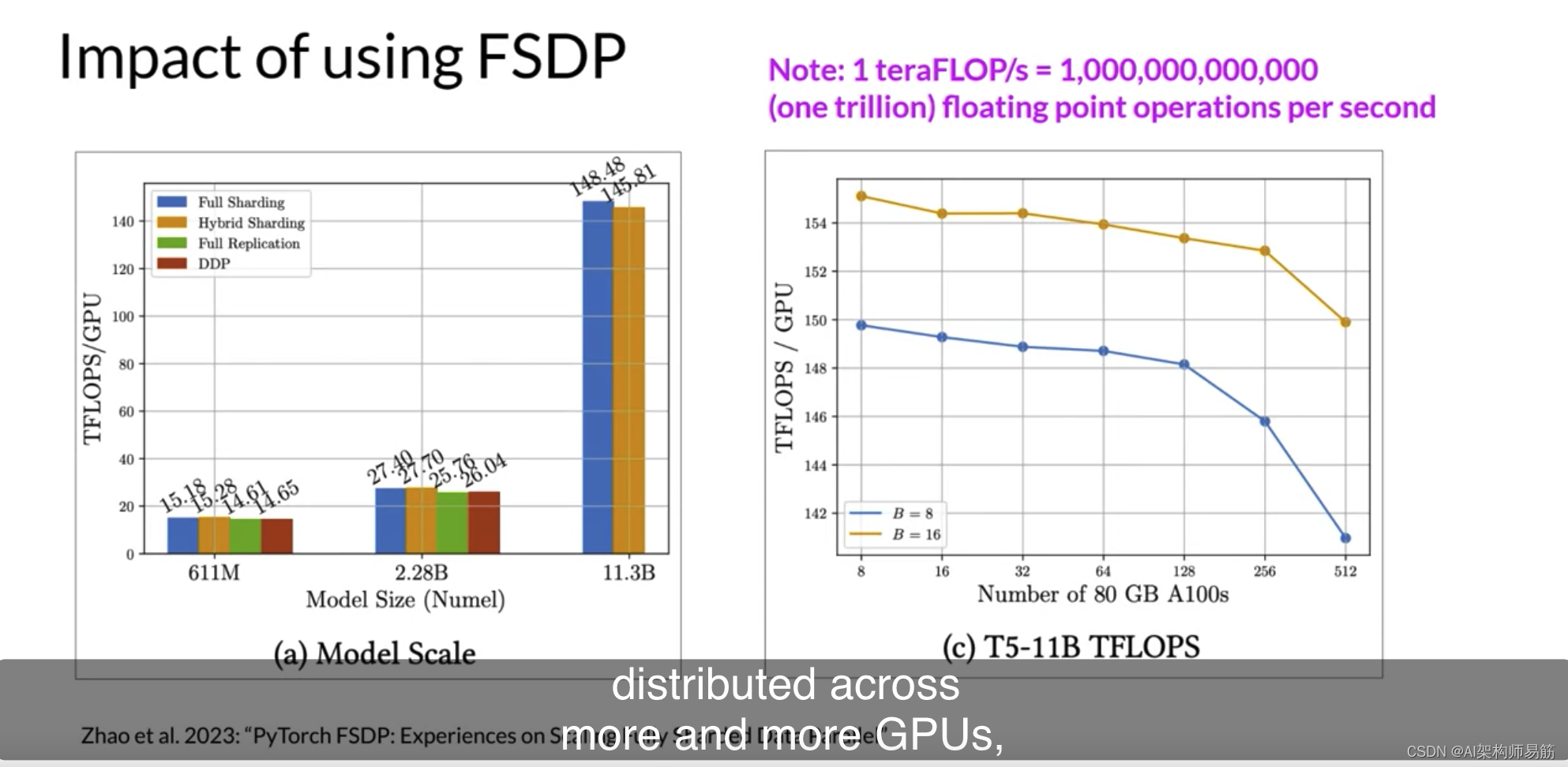
LLMs高效的多 GPU 计算策略Efficient multi-GPU compute strategies
很有可能在某个时候,您需要将模型训练工作扩展到超过一个GPU。在上一个视频中,我强调了当您的模型变得太大而无法适应单个GPU时,您需要使用多GPU计算策略。但即使您的模型确实适合单个GPU,使用多个GPU加速训练也有好处。即使您正在…
![[论文分享] jTrans: Jump-Aware Transformer for Binary Code Similarity](https://img-blog.csdnimg.cn/f72e9f084be64fc2b7141c6be203e0a5.png)
[论文分享] jTrans: Jump-Aware Transformer for Binary Code Similarity
jTrans: Jump-Aware Transformer for Binary Code Similarity [ISSTA 2022]
二进制代码相似性检测(Binary code similarity detection, BCSD)在漏洞检测、软件构件分析、逆向工程等领域具有重要应用。最近的研究表明,深度神经网络(DNNs)可以理解二进制代码的指令或…
【时序分析】TimeGPT:首个时间序列分析基础大模型
TimeGPT:首个时间序列分析基础大模型 1. 论文解读1.1 研究背景1.2 TimeGPT详解1.2.1 时间序列预测问题基础1.2.2 TimeGPT架构1.2.3 训练数据集1.2.4 训练TimeGPT1.2.5 不确定性量化1.2.6 实验结果1.2.6.1 Zero-shot 推断1.2.6.2 Fine Tuning1.2.6.3 时间对比1.2.7 讨论2. Time…

【论文解读】Point Transformer
Point Tranformer 摘要引言方法实验结论 摘要
自注意网络已经彻底改变了自然语言处理,并在图像分析任务(如图像分类和对象检测)方面取得了令人印象深刻的进展。受这一成功的启发,我们研究了自注意网络在三维点云处理中的应用。我…
3D- vista:预训练的3D视觉和文本对齐Transformer
论文:https://arxiv.org/abs/2308.04352
代码: GitHub - 3d-vista/3D-VisTA: Official implementation of ICCV 2023 paper "3D-VisTA: Pre-trained Transformer for 3D Vision and Text Alignment"
摘要
三维视觉语言基础(3D- vl)是一个新兴领域&…
PVT(Pyramid Vision Transformer)学习记录
引言与启发
自从ViT之后,关于vision transformer的研究呈井喷式爆发,从思路上分主要沿着两大个方向,一是提升ViT在图像分类的效果;二就是将ViT应用在其它图像任务中,比如分割和检测任务上,这里介绍的PVT&a…
Transformer (Attention Is All You Need) 论文精读笔记
Transformer(Attention Is All You Need)
Attention Is All You Need
参考:跟李沐学AI-Transformer论文逐段精读【论文精读】
摘要(Abstract)
首先摘要说明:目前,主流的序列转录(序列转录:给…

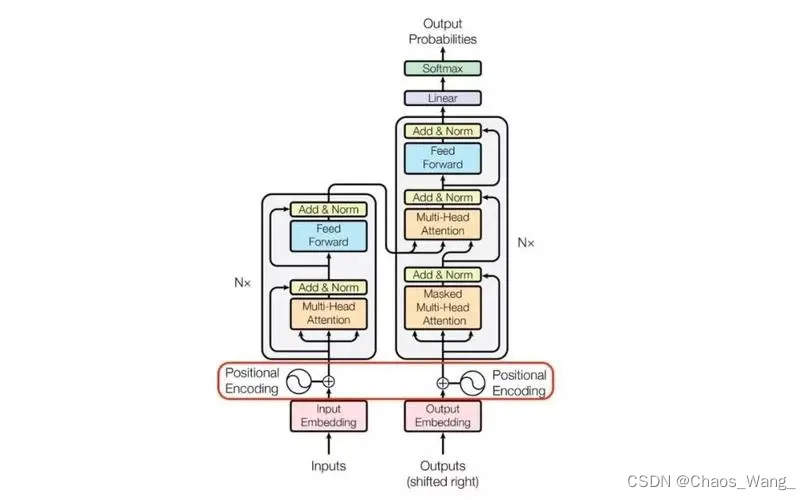
The Annotated Transformer
我们不生产水,我们只是大自然的搬运工!
原文地址: The Annotated Transformer The Annotated Transformer The Annotated TransformerPrelimsBackgroundPart 1: Model ArchitectureOverall ArchitectureEncoder and Decoder StacksEncoderDecoderAttent…
vit细粒度图像分类(一)CADF学习笔记
1.摘要:
目的 基于Transformer架构的网络在图像分类中表现出优异的性能。然而,注意力机制往往只关注图像中的显著性特征,而忽略了其他区域的次级显著信息,基于自注意力机制的Transformer也是如此。为了获取更多的有效信息&#…

DETR纯代码分享(九)transformer.py
一、定义DETR Transformer用于DETR模型
"""
DETR Transformer class.Copy-paste from torch.nn.Transformer with modifications:* positional encodings are passed in MHattention* extra LN at the end of encoder is removed* decoder returns a stack of …
大模型的实践应用3-大模型的基础架构Transformer模型,掌握Transformer就掌握了大模型的灵魂骨架
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用3-大模型的基础架构Transformer模型,掌握Transformer就掌握了大模型的灵魂骨架。Transformer是一种基于自注意力机制的深度学习模型,由Vaswani等人在2017年的论文《Attention is All You Need》中提出。它最初被设计用…
pandas教程:Reading and Writing Data in Text Format (以文本格式读取和写入数据)
文章目录 Chapter 6 Data Loading, Storage, and File Formats(数据加载,存储,文件格式)6.1 Reading and Writing Data in Text Format (以文本格式读取和写入数据)1 Reading Text Files in Pieces(读取一部分文本&…
自然语言处理24-T5模型的介绍与训练过程,利用简单构造数据训练微调该模型,体验整个过程
大家好,我是微学AI,今天给大家介绍一下自然语言处理24-T5模型的介绍与训练过程,利用简单构造数据训练微调该模型,体验整个过程。在大模型ChatGPT发布之前,NLP领域是BERT,T5模型为主导,T5(Text-to-Text Transfer Transformer)是一种由Google Brain团队在2019年提出的自然…
注意力机制和Transformer
注意力机制和Transformer
机器翻译是NLP领域中最重要的问题之一,也是Google翻译等工具的基础。传统的RNN方法使用两个循环网络实现序列到序列的转换,其中一个网络(编码器)将输入序列转换为隐藏状态,而另一个网络&…
【无标题】Transformer机制
这篇文章写得很详细,记录一下:
Transformer是什么?看完这篇你就醍醐灌顶_fs1341825137的博客-CSDN博客前言由谷歌团队提出的预训练语言模型BERT近年来正在各大自然语言处理任务中屠榜(话说学者们也挺有意思的,模型名都…
Illumination Adaptive Transformer
Abstract.
现实世界中具有挑战性的照明条件(低光、曝光不足和曝光过度)不仅会产生令人不快的视觉外观,还会影响计算机视觉任务。现有的光自适应方法通常单独处理每种情况。更重要的是,它们中的大多数经常在 RAW 图像上运行或过度…

《Shortening passengers’ travel time A dynamic metro train scheduling approach using deep reinforcem》
本文目录1. 摘要2. AutoDwell系统架构2.1 离线学习程序2.2 在线部署程序3. AutoDwell3.1 列车特征提取器3.2 乘客特征提取器3.2.1 换乘站学习器3.2.2 普通站学习3.2.3 结论性循环网络3.3 融合组件3.4 算法优化1. 摘要
城市地铁已成为现代城市最重要的公共交通工具,…

生成专题3 | StyleGAN2对AdaIN的修正
文章转自微信公众号:机器学习炼丹术作者:陈亦新(欢迎交流共同进步)联系方式:微信cyx645016617学习论文:Analyzing and Improving the Image Quality of StyleGAN 文章目录3.1 AdaIN3.2 AdaIN的问题3.3 weig…

transformer在计算机视觉中的应用
Transformer 在计算机视觉中的应用
论文地址: https://arxiv.org/abs/1706.03762 Vision Transformer
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 代码地址: https://github.com/google-research/vision_transfor…

简单理解Transformer注意力机制
这篇文章是对《动手深度学习》注意力机制部分的简单理解。
生物学中的注意力
生物学上的注意力有两种,一种是无意识的,零一种是有意识的。如下图1,由于红色的杯子比较突出,因此注意力不由自主指向了它。如下图2,由于…
Restormer Efficient Transformer for High-Resolution Image Restoration
文章目录 Restormer代码训练和测试运行记录文章及代码地址环境安装下载数据集运行Demo训练测试 Restormer代码训练和测试运行记录
文章及代码地址
文章名称:Restormer: Efficient Transformer for High-Resolution Image Restoration(CVPR 2022&#x…
Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT
前言 我在写上一篇博客《22下半年》时,有读者在文章下面评论道:“july大神,请问BERT的通俗理解还做吗?”,我当时给他发了张俊林老师的BERT文章,所以没太在意。
直到今天早上,刷到CSDN上一篇讲B…
Yolov5轻量化:EMO,结合 CNN 和 Transformer 的现代倒残差移动模块设计,性能优于EdgeViT、Mobile-former等网络
论文: https://arxiv.org/pdf/2301.01146.pdf 🏆🏆🏆🏆🏆🏆Yolo轻量化模型🏆🏆🏆🏆🏆🏆 重新思考了 MobileNetv2 中高效的倒残差模块 Inverted Residual Block 和 ViT 中的有效 Transformer 的本质统一,归纳抽象了 MetaMobile Block 的一般概念。受这…

CvT: 如何将卷积的优势融入Transformer
【GiantPandaCV导语】与之前BoTNet不同,CvT虽然题目中有卷积的字样,但是实际总体来说依然是以Transformer Block为主的,在Token的处理方面引入了卷积,从而为模型带来的局部性。最终CvT最高拿下了87.7%的Top1准确率。
引言
CvT架…

李宏毅2021春季机器学习课程笔记7: Seq2seq Transformer
文章目录1. Seq2seq2. Encoder2.1 Block2. Decoder2.1 Autoregressive(AT)2.2 Non-autoregressive(NAT)2.3 Cross attention4. Training4.1 Copy Mechanism4.2 Guided Attention4.3 Beam Search4.4 Cross entropy & BLEU scor…
Eformer: Edge Enhancement based Transformer for Medical Image Denoising
Eformer:医学图像去噪Abstract1. Introduction2. Relate3.2 Transformer based Encoder-Decoder3.3. Downsampling & Upsampling3.4. Residual Learning3.5 Optimization3.6. Overall Network Architecture4. Results and DiscussionsAbstract
本文提出的Eform…

GPT-2(Transformer Decoder)的TensorFlow实现(附源码)
文章目录 一、GPT2实现步骤二、源码 一、GPT2实现步骤 机器学习模型的开发实现步骤一般都包含以下几个部分: 1. 遵照模型的网络架构,实现每一层(Layer/Block)的函数; 2. 将第1步中的函数组合在一起,…
深入理解深度学习——Transformer:编码器(Encoder)部分
分类目录:《深入理解深度学习》总目录 Transformer中的编码器不止一个,而是由一组 N N N个编码器串联而成。一个编码器的输出作为下一个编码器的输入。在下图中有 N N N个编码器,每一个编码器都从下方接收数据,再输出给上方。以此…

IQT:使用Transformer进行感知图像质量评估(CVPRW)
目录📝论文下载地址🔨代码下载地址👨🎓论文作者📦模型讲解[背景介绍][Transformer][图像质量评估/IQA][衡量图像质量评估指标的准确性][模型解读][总体结构][特征提取backbone][Transformer编码器][Transformer解码器…

近80%企业首选——亚马逊云科技为中国企业出海保驾护航
随着全球数字化进程的不断加速,中国出海“大航海时代”已然到来。从#万企组团出国抢订单#到#苏州赴日包机抢单20亿元#,中国企业对海外市场的优势已经一步步建立了起来。
从卖小商品、卖鞋的“世界工厂”,到现在产业升级后的卖汽车、卖服务、…
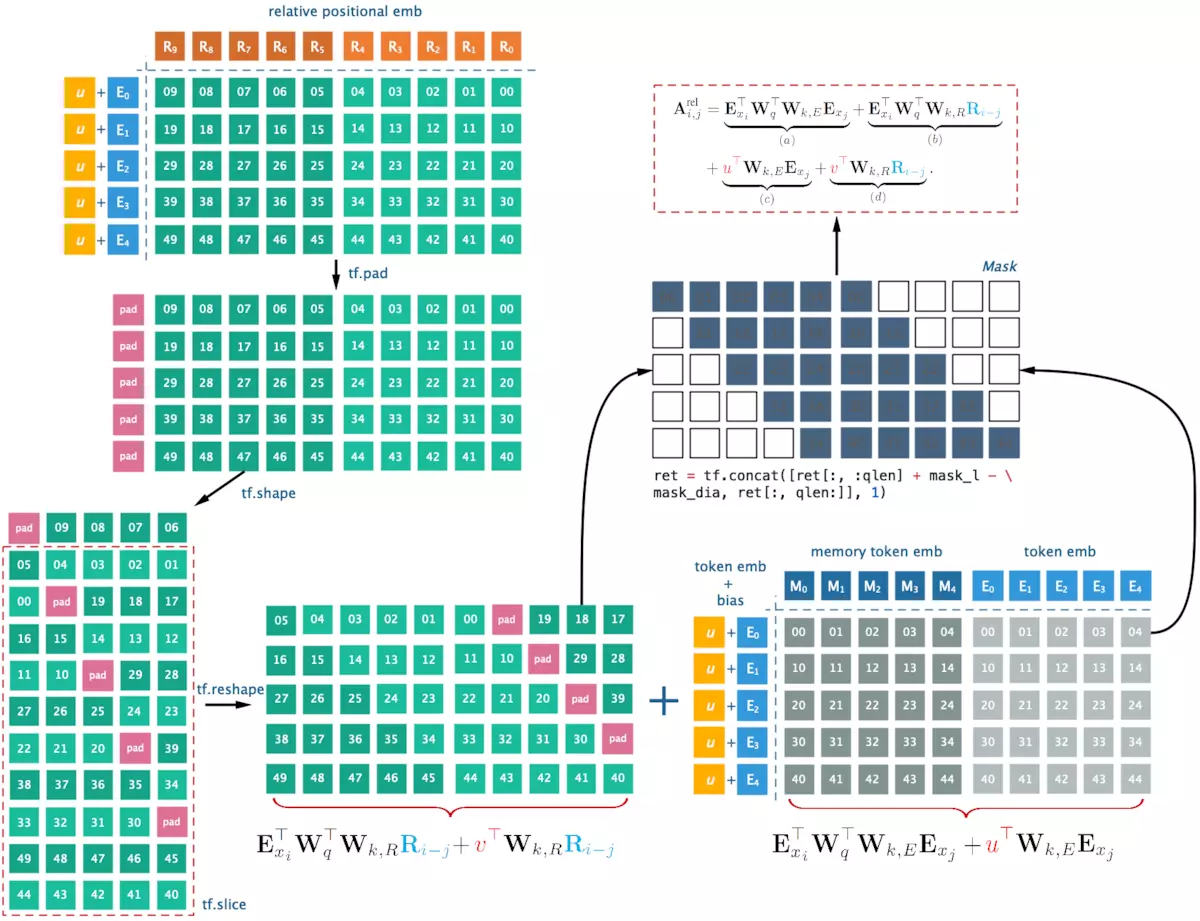
相对位置编码(二) Relative Positional Encodings - Transformer-XL
1. Motivation
在Transformer-XL中,由于设计了segments,如果仍采用transformer模型中的绝对位置编码的话,将不能区分处不同segments内同样相对位置的词的先后顺序。
比如对于segmenti����&…

【NLP模型】文本建模(2)TF-IDF关键词提取原理
一、说明 tf-idf是个可以提取文章关键词的模型;他是基于词频,以及词的权重综合因素考虑的词价值刻度模型。一般地开发NLP将包含三个层次单元:最大数据单元是语料库、语料库中有若干文章、文章中有若干词语。这样从词频上说,就有词…
【Research】深度学习音乐生成
前言
音乐生成是音乐信息检索(MIR)的一个研究领域,旨在创造新的音乐。为了理解和比较音乐创作系统,理解人类如何感知、学习和创作音乐是至关重要的。由于不同的原因,不同的人对音乐的感知是不同的。人类音乐创作的工作流程主要由作曲家的文化背景、对音乐的理解和原创性决…
transformer的学习记录【完整代码+详细注释】(系列五)
文章目录1 解码器部分介绍2 解码器层2.1 解码作用2.2 解码器层的代码分析2.3 解码器层类的代码3 解码器3.1 解码器代码4 到目前为止完整的代码第一节:transformer的架构介绍 输入部分的实现 链接:https://editor.csdn.net/md/?articleId124648718 第二…
transformer的学习记录【完整代码+详细注释】(系列四)
文章目录1 子层连接结构1.1 子层连接结构的代码1.2 完整的代码就不放了,放在下一节2 编码器层2.1 编码器层的作用2.2 代码分析2.3 编码器层的代码3 编码器3.1 代码实现3.2 编码器的输出3 到目前为止的完整的代码3.1 输出第一节:transformer的架构介绍 输…

transformer的学习记录【完整代码+详细注释】(系列二)
文章目录1 编码器部分实现1.1 掩码张量1.1.1 用 np.triu 生产上三角矩阵1.1.2 生成掩码张量的代码1.1.3 掩码张量可视化展示1.1.4 掩码张量学习总结1.2 注意力机制1.2.1 注意力机制 vs 自注意力机制1.2.2 注意力机制代码解读1.2.3 masked_fill 函数介绍1.2.3 注意力机制的实现代…
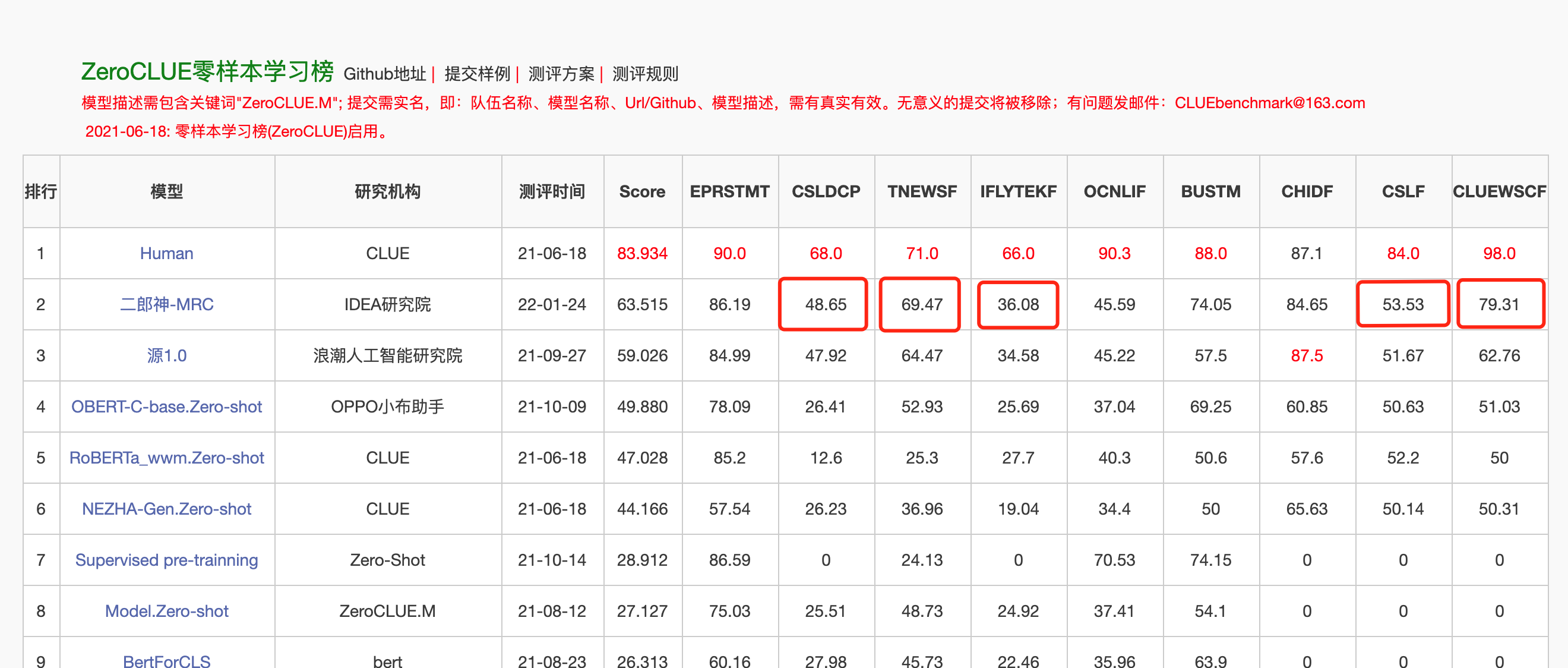
封神榜科技成果 - 国产训练大模型
封神榜科技成果 Fengshenbang 1.0: 封神榜开源计划1.0中英双语总论文,旨在成为中文认知智能的基础设施。 BioBART: 由清华大学和IDEA研究院一起提供的生物医疗领域的生成语言模型。(BioNLP 2022) UniMC: 针对zero-shot场景下基于标签数据集的统一模型。(EMNLP 2022)…
深入理解深度学习——Transformer:解码器(Decoder)部分
分类目录:《深入理解深度学习》总目录
相关文章: 注意力机制(Attention Mechanism):基础知识 注意力机制(Attention Mechanism):注意力汇聚与Nadaraya-Watson核回归 注意力机制&…
微调Hugging Face中图像分类模型
前言
本文主要针对Hugging Face平台中的图像分类模型,在自己数据集上进行微调,预训练模型为Google的vit-base-patch16-224模型,模型简介页面。代码运行于kaggle平台上,使用平台免费GPU,型号P100,笔记本地址…

timm使用swin-transformer
1.安装
pip install timm2.timm中有多少个预训练模型
#timm中有多少个预训练模型
model_pretrain_list timm.list_models(pretrainedTrue)
print(len(model_pretrain_list), model_pretrain_list[:3])3加载swin模型一般准会出错
model_ft timm.create_model(swin_base_pat…
改进YOLOv7系列:首发最新结合多种X-Transformer结构新增小目标检测层,让YOLO目标检测任务中的小目标无处遁形
💡该教程包含大量的原创首发改进方式, 所有文章都是原创首发改进内容🚀 降低改进难度,改进点包含最新最全的Backbone部分、Neck部分、Head部分、注意力机制部分、自注意力机制部分等完整教程🚀💡本篇文章基于 基于 YOLOv7、YOLOv7-Tiny 等网络 首发最新结合多种X-Trans…
一文看懂Transformer(详解)
文章目录Transformer前言网络结构图:EncoderInput EmbeddingPositional Encoderself-attentionPadding maskAdd & NormFeed ForwardDecoderinputmasked Multi-Head Attentiontest时的Decoder预测Transformer
前言
Transformer最初是用于nlp领域的翻译任务。
…

消除视觉Transformer与卷积神经网络在小数据集上的差距
摘要:本文通过多种操作构建混合模型,增强视觉Transformer捕捉空间相关性的能力和其进行通道多样性表征的能力,弥补了Transformer在小数据集上从头训练的精度与传统的卷积神经网络之间的差距。本文分享自华为云社区《[NeurIPS 2022] 消除视觉T…
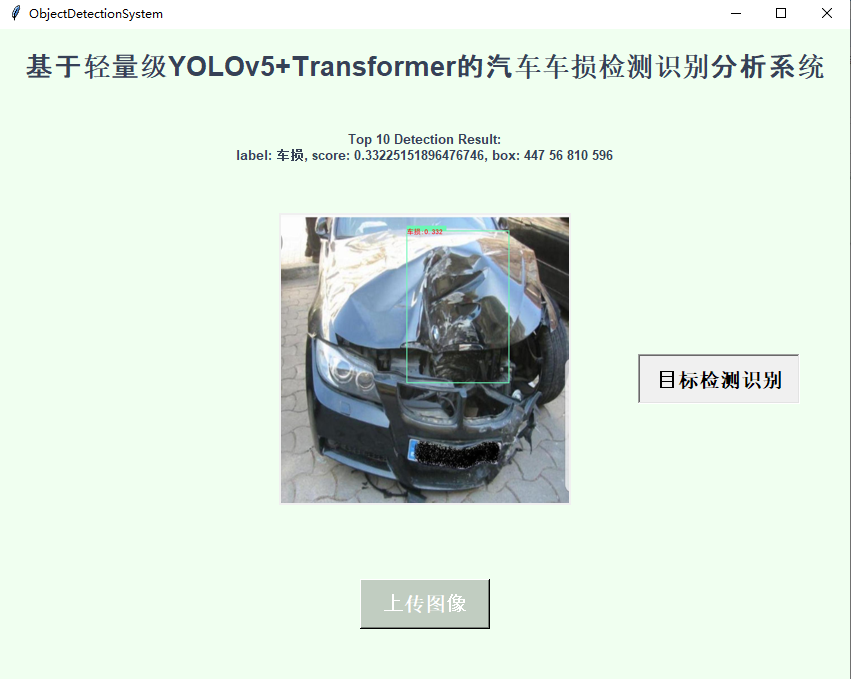
基于轻量级YOLOv5+Transformer的汽车车损检测识别分析系统
将传统NLP领域提出来的Transformer技术与yolo目标检测模型融合已经成为一种经典的做法,早在之前的很多论文里面就有这种组合应用的出现了,本文主要是借鉴前文的思路,开发基于yolov5transformer的汽车车损检测识别模型,首先看下效果…

RoFormer: Enhanced Transformer with Rotary Position Embedding论文解读
RoFormer: Enhanced Transformer with Rotary Position Embedding 论文:RoFormer: Enhanced Transformer with Rotary Position Embedding (arxiv.org)
代码:ZhuiyiTechnology/roformer: Rotary Transformer (github.com)
期刊/会议:未发表…
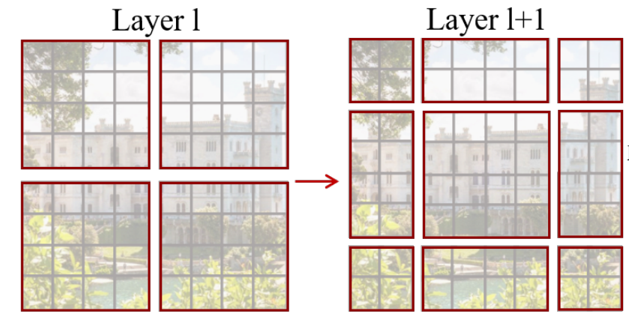
Transformer:开启CV研究新时代
来源:投稿 作者:魔峥 编辑:学姐 起源回顾
有关Attention的论文早在上世纪九十年代就提出了。
在2012年后的深度学习时代,Attention再次被翻了出来,被用在自然语言处理任务,提高RNN模型的训练速度。但是由…
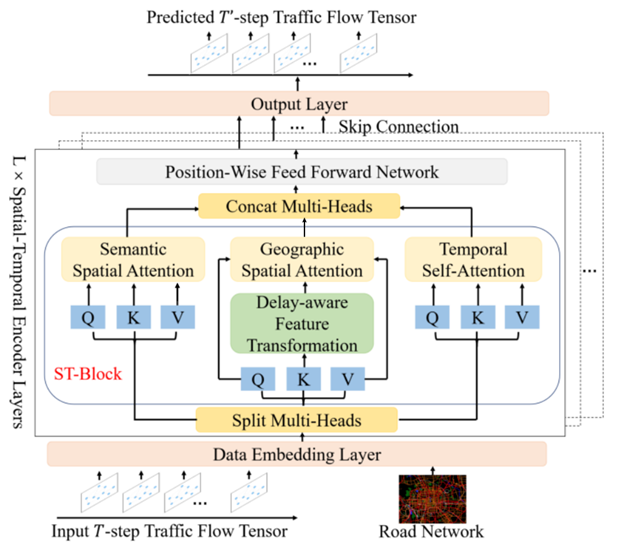
基于Transformer的交通预测模型部分汇总【附源代码】
交通预测一直是一个重要的问题,它涉及到交通运输系统的可靠性和效率。随着人工智能的发展,越来越多的研究者开始使用深度学习模型来解决这个问题。其中,基于Transformer的交通预测模型在近年来备受关注,因为它们具有优秀的建模能力…
Transformer在CV上的应用-论文总结
年份会议/期刊标题内容领域架构图2017NIPSAttention is all you need(Transformer)贡献:提出了一种新的简单的网络架构Transformer,它完全基于注意力机制,完全不需要递归和卷积。 做法:Encoder and Decoder Stacks,self-attention…
深度学习注意力机制(MHA)的训练(Eigen)
简介
本文使用Eigen3在Transformer模型中实现多头注意力的前向传播和反向传播。具体来说,这个eigenMHA (eigenDNN)【源码:https://github.com/jundaf2/eigenMHA】所对应了大致如下的cuDNN的api的功能:
cudnnCreateAttnDescriptor()cudnnSet…
【Transformer】Self-Attention Multi-Head Attention 等解析
【Transformer】Self-Attention 、Multi-Head Attention、位置编码、Mask等解析 文章目录【Transformer】Self-Attention 、Multi-Head Attention、位置编码、Mask等解析1. 介绍2. 模型2.1 Self-Attention2.2 Multi-Head Attention2.3 Self-Attention与Multi-Head Attention 对…
一文理解Transformer整套流程
【备注】部分图片引至他人博客,详情关注参考链接
【PS】query 、 key & value 的概念其实来源于推荐系统。基本原理是:给定一个 query,计算query 与 key 的相关性,然后根据query 与 key 的相关性去找到最合适的 value。举个例…

Graph Transformer系列论文阅读
文章目录research1.《Do Transformers Really Perform Bad for Graph Representation》【NeurIPS 2021 Poster】2.《Relational Attention: Generalizing Transformers for Graph-Structured Tasks》【ICLR2023-spotlight】survey推荐一个汇总Graph Transformer论文的项目&…
TRIQ:用于图像质量评估的Transformer(ICIP)
目录📝论文下载地址🔨代码下载地址👨🎓论文作者📦模型讲解[背景介绍][Transformer][图像质量评估/IQA][模型解读][总体结构][通用TRIQ模型][TRIQ的Transformer][结果分析]📝论文下载地址 [论文地址]
&am…
【NLP相关】Transformer模型:从Seq2Seq到自注意力机制(Transformer原理、公式推导和案例)
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…

Transformer - Skip connection-解读
Transformer - Skip connection理解
skip connection是一种广泛应用于提高深度神经网络性能和收敛性的技术,它通过神经网络层传播的线性分量,缓解了非线性变化难以收敛的情况。在Transformer中,patch如果较小,就会出现spurious g…

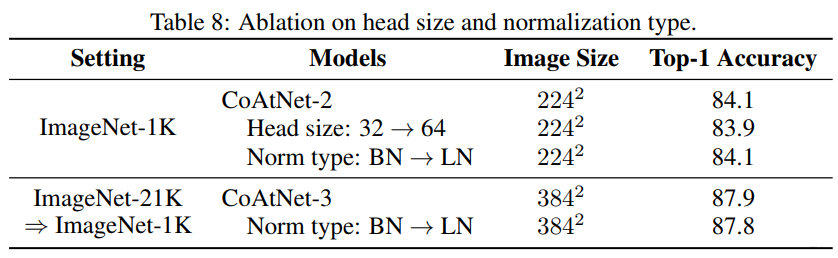
CoAtNet: 90.88% Paperwithcode榜单第一,层层深入考虑模型设计
【GiantPandaCV导语】CoAtConvolution Attention,paperwithcode榜单第一名,通过结合卷积与Transformer实现性能上的突破,方法部分设计非常规整,层层深入考虑模型的架构设计。 引言
Transformer模型的容量大,由于缺乏…

CeiT:训练更快的多层特征抽取ViT
【GiantPandaCV导语】来自商汤和南洋理工的工作,也是使用卷积来增强模型提出low-level特征的能力,增强模型获取局部性的能力,核心贡献是LCA模块,可以用于捕获多层特征表示。
引言
针对先前Transformer架构需要大量额外数据或者额…

CNN、Transformer、MLP的经验性分析
A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP
【GiantPandaCV导语】ViT的兴起挑战了CNN的地位,随之而来的是MLP系列方法。三种架构各有特点,为了公平地比较几种架构,本文提出了统一化的框架SPACH来对比…
人工智能课程笔记:注意力机制 Transformer
文章目录 1.注意力机制2.Transformer模型3.Swin Transformer模型4.预训练语言模型4.1.ELMo模型4.2.GPT模型4.3.BERT模型 1.注意力机制
注意力机制应用于RNN网络的原理:加入了注意力机制的RNN网络会在接下来进行预测时重点关注序列中的一部分,重点基于关…

初识Transformer
参考:【NLP】Transformer模型原理详解 - 知乎 从RNN到“只要注意力”——Transformer模型 - 知乎 Attention机制提出后,加入attention的Seq2seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合RNN和attention的模型。之后goog…
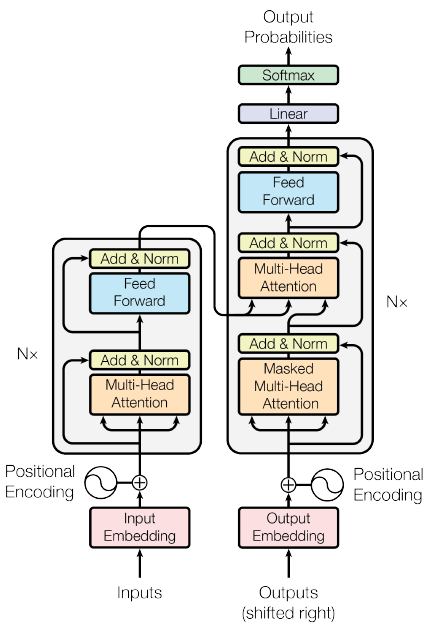
机器翻译——Seq2Seq模型到attention机制到Transformer
文章目录1 理论部分2 Seq2Seq (15-16年比较流行)2 基于attention的Seq2Seq3 Transformer1 理论部分
Seq2Seq模型Attention Seq2SeqTransformer
2 Seq2Seq (15-16年比较流行)
如下图所示,Encoder和Decoder部分&…

深度学习笔记之Transformer(二)关于注意力分数的总结
深度学习笔记之Transformer——关于注意力分数的总结 引言回顾: Nadaraya-Watson \text{Nadaraya-Watson} Nadaraya-Watson核回归再回首: Seq2seq \text{Seq2seq} Seq2seq中的注意力机制注意力机制的泛化表示加性注意力机制缩放点积注意力机制 引言
上一…
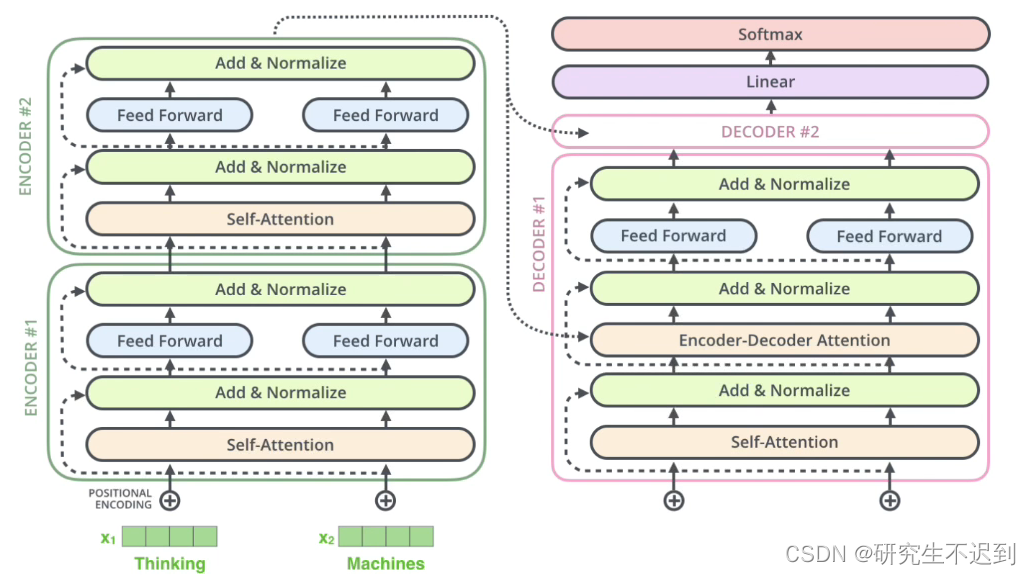
transformer的学习记录【完整代码+非常详细】(系列一)
文章目录1 transformer架构介绍1.1 简单介绍输入部分1.2 简单介绍输出部分1.3 简单介绍编码器部分1.4 简单介绍解码器部分2 输入部分实现2.1 Embedding 的介绍2.1.1 采用随机初始化2.1.2 采用word2vec2.1.3 采用随机初试化的实战代码2.2 位置编码器实现2.3 输出位置矩阵2.4 总结…

李宏毅transformer讲解;B站内测“搜索AI助手”功能
🦉 AI新闻
🚀 B站内测“搜索AI助手”功能
摘要:据反馈,B站正在内测“搜索 AI 助手”功能。用户在搜索框内输入问句或在搜索词中添加“?”即可体验此新功能。截图显示,该功能会为用户的搜索提供一个生成的答案&#…

SeqTrack: Sequence to Sequence Learning for Visual Object Tracking
摘要
在本文中,我们提出了一种新的序列到序列学习框架的视觉跟踪,称为SeqTrack。它将视觉跟踪转换为一个序列生成问题,它以自回归的方式预测对象边界盒。这与之前的Siamese跟踪器和transformer跟踪器不同,它们依赖于设计复杂的磁…
【人工智能与深度学习】注意力机制和Transformer
【人工智能与深度学习】注意力机制和Transformer 注意力机制自我注意力 (I)硬注意力软注意力自我注意力 (II)高性能键-值存储查询,键和值[The Transformer](https://www.youtube.com/watch?v=f01J0Dri-6k&t=2114s)编码器-解码器结构编码模块自我注意力Add, Norm1D-卷积解…

简要介绍 | 深度学习中的自注意力机制:原理与挑战
注1:本文系“简要介绍”系列之一,仅从概念上对深度学习中的自注意力机制进行非常简要的介绍,不适合用于深入和详细的了解。 注2:"简要介绍"系列的所有创作均使用了AIGC工具辅助 深度学习中的自注意力机制:原…

pytorch笔记:transformer 和 vision transformer
来自B站视频,API查阅,TORCH.NN
seq2seq 可以是 CNN,RNN,transformer nn.Transformer 关键源码:
encoder_layer TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout,activation, layer_norm_eps, ba…

论文阅读 - SegFormer
文章目录 1 概述2 模型说明2.1 总体结构2.2 Hierarchical Transformer Encoder2.3 Lightweight All-MLP Decoder 3 SegFormer和SETR的比较参考资料 1 概述
图像分割任务和图像分类任务是非常相关的,前者是像素级别的分类,后者是图像级别的分类。基于分类…

YOLOv5-7.0添加BottleNet transformer
YOLOv5主干特征提取网络为CNN网络,CNN具有平移不变性和局部性,缺乏全局建模长距离建模的能力,引入自然语言领域的Transformer可以形成CNNTransFormer架构,充分结合两者的优点,提高目标检测效果。
1. BoTNet
论文地址…
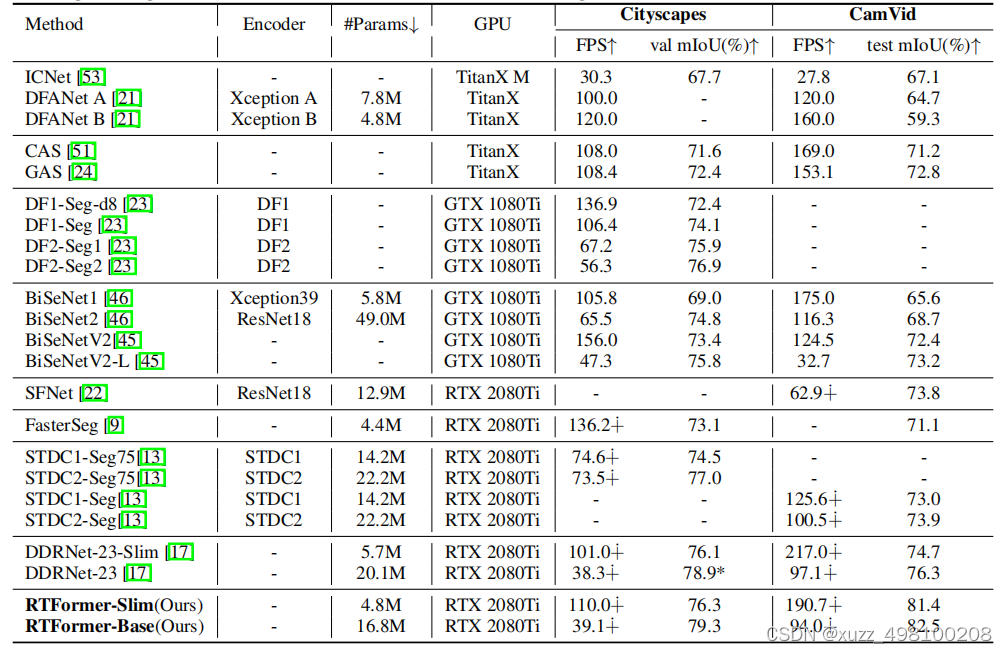
语义分割之RTFormer介绍
语义分割之RTFormer介绍
论文链接:https://arxiv.org/abs/2210.07124 代码地址:https://github.com/PaddlePaddle/PaddleSeg
ViT以来,Transformer作为特征提取器在语义分割领域证明了自己,但是由于Transformer的核心 muti-self-…

【跟着代码读论文】ViT(2021 ICLR)An image is worth 16x16 words: Transformers for image recognition at scale
论文: An image is worth 16x16 words: Transformers for image recognition at scale.
Github code(PyTorch Implementation):https://github.com/lucidrains/vit-pytorch 目录
Model Overview
Github Code Usage
Procedure …

Hugging Face 中文预训练模型使用介绍及情感分析项目实战
Hugging Face 中文预训练模型使用介绍及情感分析项目实战
Hugging Face 一直致力于自然语言处理NLP技术的平民化(democratize),希望每个人都能用上最先进(SOTA, state-of-the-art)的NLP技术,而非困窘于训练资源的匮乏"
其中,transformer库提供了NLP领域大量…

transformer库使用
Transformer库简介
是一个开源库,其提供所有的预测训练模型,都是基于transformer模型结构的。
Transformer库
我们可以使用 Transformers 库提供的 API 轻松下载和训练最先进的预训练模型。使用预训练模型可以降低计算成本,以及节省从头开…
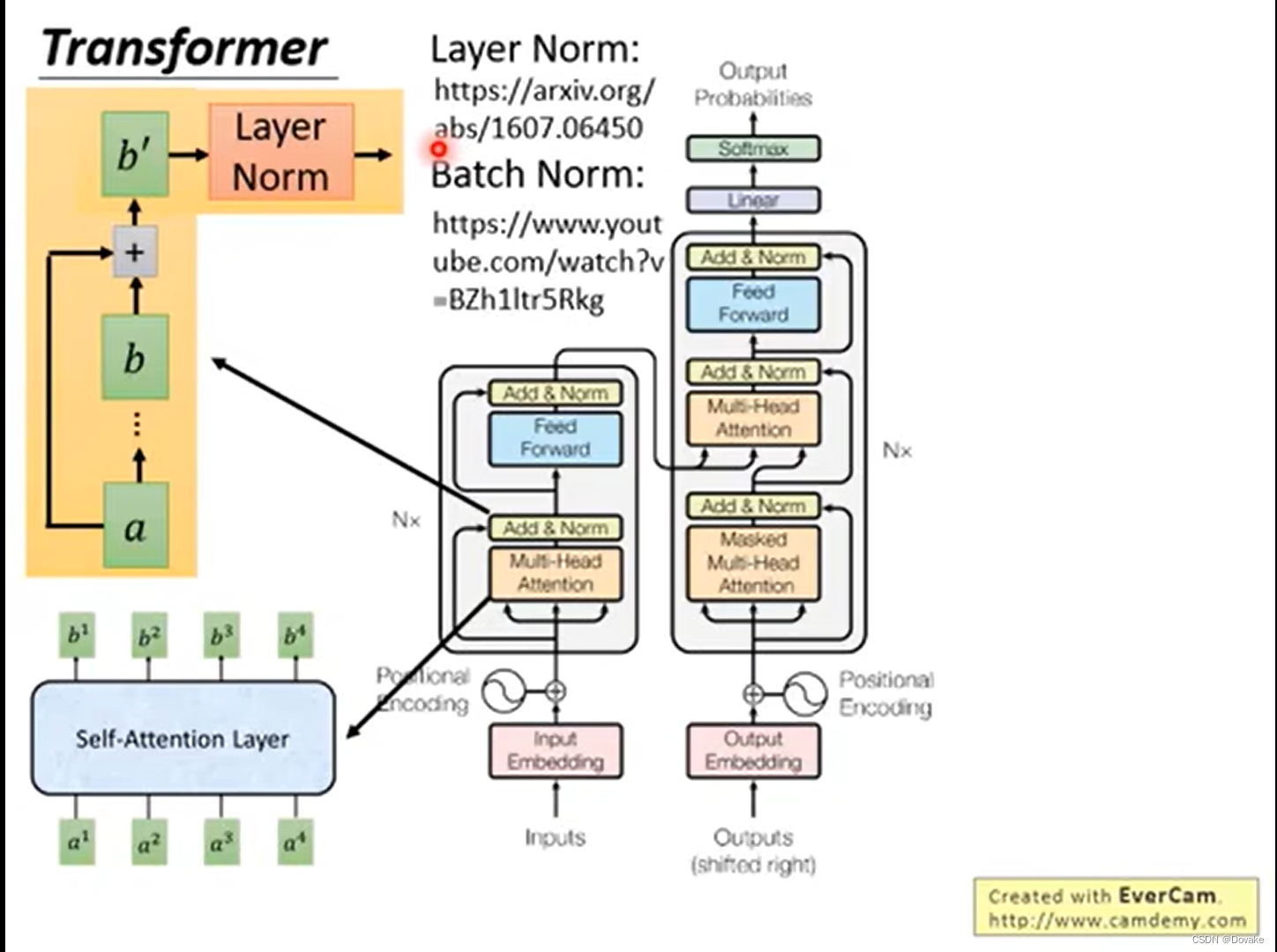
Transformer结构解读
咱们还是照图讨论,transformer结构图如下,本文主要讨论Encoder部分:图一一、首先说一下Encoder的输入部分:在NLP领域,个人理解,这个inputs就是我们的句子分词之后的词语,比如“我,喜…
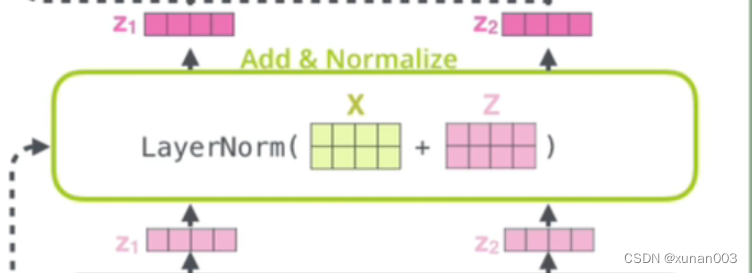
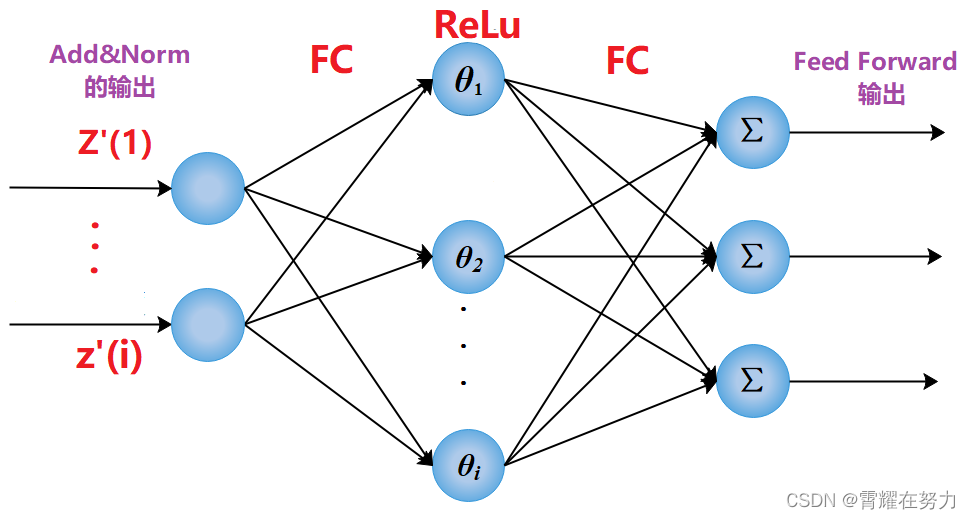
Transformer结构解读(Multi-Head Attention、AddNorm、Feed Forward)
咱们还是照图讨论,transformer结构图如下,本文主要讨论Encoder部分,从低端输入inputs开始,逐个结构进行:图一一、首先说一下Encoder的输入部分:在NLP领域,个人理解,这个inputs就是我…
Transformer的位置编码笔记(positional encoding)
一、为什么Transformer需要对输入进行位置编码因为Transformer的输入并没有内涵位置信息,同样的词在不同位置,或者同一个序列以不同顺序输入,对应的词间都会得到相同的注意力权重和输出,但是在NLP领域,词的顺序会极大地…

中文生成模型T5-Pegasus详解与实践
我们在前一篇文章《生成式摘要的四篇经典论文》中介绍了Seq2seq在生成式研究中的早期应用,以及针对摘要任务本质的讨论。
如今,以T5为首的预训练模型在生成任务上表现出超出前人的效果,这些早期应用也就逐渐地淡出了我们的视野。本文将介绍T…
【TimeSerias】Transformer
Sequence
1. rnn 和 cnn RNN 很难并行化CNN很难捕捉较远的信息
2. Self-attention 拿每个query q去对每个 key k做attention 计算输出
Self-attition 矩阵计算 qiWqaikiWkqiviWvaiQWqAKWkAVWvA(1.1)\begin{align*} q^i & W^q a^i \\ k^i & W^k q^i \\ v^i & W…

几何感知Transformer用于3D原子系统建模
基于机器学习的方法在预测分子能量和性质方面表现出很强的能力。分子能量至少与原子、键、键角、扭转角和非键原子对有关。以前的Transformer模型只使用原子作为输入,缺乏对上述因素的显式建模。为了减轻这种限制,作者提出了Moleformer,这是一…

【Transformer】自注意力机制Self-Attention | 各种网络归一化Normalization
1. Transformer 由来 & 特点
1.1 从NLP领域内诞生
"Transformer"是一种深度学习模型,首次在"Attention is All You Need"这篇论文中被提出,已经成为自然语言处理(NLP)领域的重要基石。这是因为Transfor…

DeepViT:Towards Deeper Vision Transform
论文笔记【1】-- DeepViT: Towards Deeper Vision Transformer CVPR 2021 DeepViT: Towards Deeper Vision Transformer DeepViT论文 DeepViT Code DeepViT:Can we further improve performance of ViTs by making it deeper, just like CNNs?——Re-attentio…
【Timm】create_model全面详实概念理解及实践篇
【Timm】搭建Vision Transformer系列实践,终于见面了,Timm库!
不久前,探究如何构建基于vision transformer的模型,发现,更多重点应该是放在如何有效利用现有库调用及构建模型,这篇就主要记录调…
认识Transformer:入门知识
视频链接: https://www.youtube.com/watch?vugWDIIOHtPA&listPLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index60 文章目录 Self-Attention layerMulti-head self-attentionPositional encodingSeq2Seq with AttentionTransformerUniversal Transformer Seq2Seq …

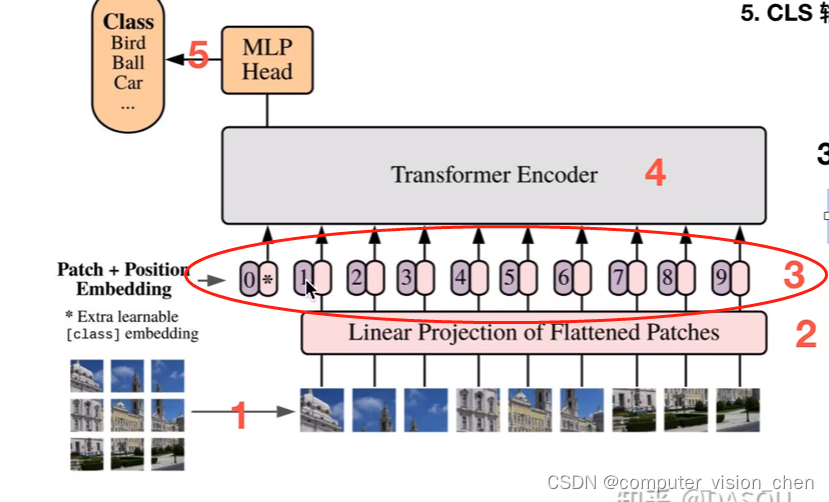
【DASOU视频记录】VIT (Vision Transformer) 模型论文+代码(源码)从零详细解读,看不懂来打我
文章目录 来源ViT和Transformer的关系朴素思路问题 ViT思路patch整体流程CLS位置编码编码器例子 代码 来源
b站视频
ViT和Transformer的关系
Vision Transformer(简称ViT)是Transformer在CV领域的应用ViT只使用了Transformer的编码器部分
朴素思路
…

Text-to-SQL小白入门(二)——Transformer学习
摘要
本文主要针对NLP任务中经典的Transformer模型的来源、用途、网络结构进行了详细描述,对后续NLP研究、注意力机制理解、大模型研究有一定帮助。
1. 引言
在上一篇《Text-to-SQL小白入门(一)》中,我们介绍了Text-to-SQL研究…
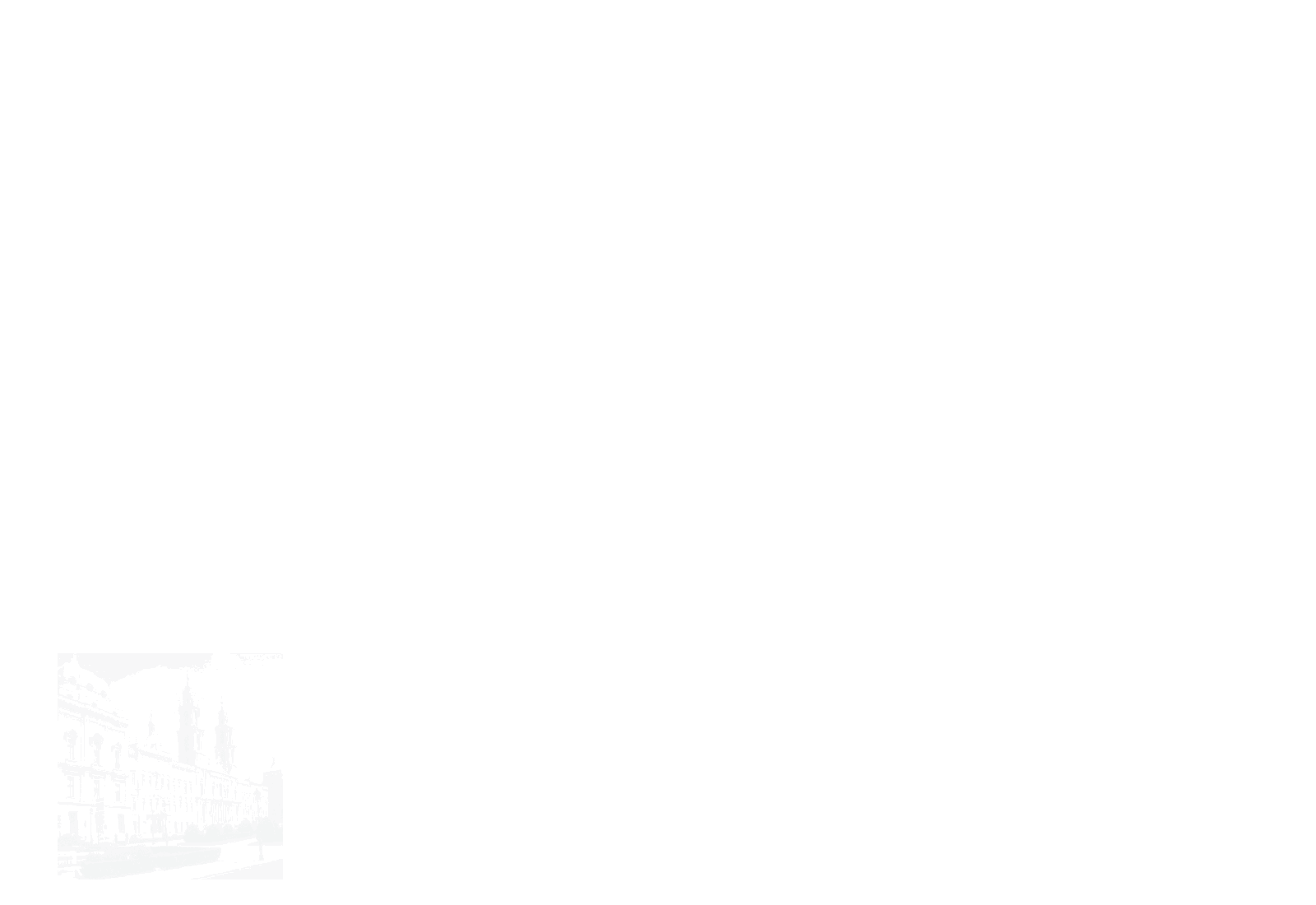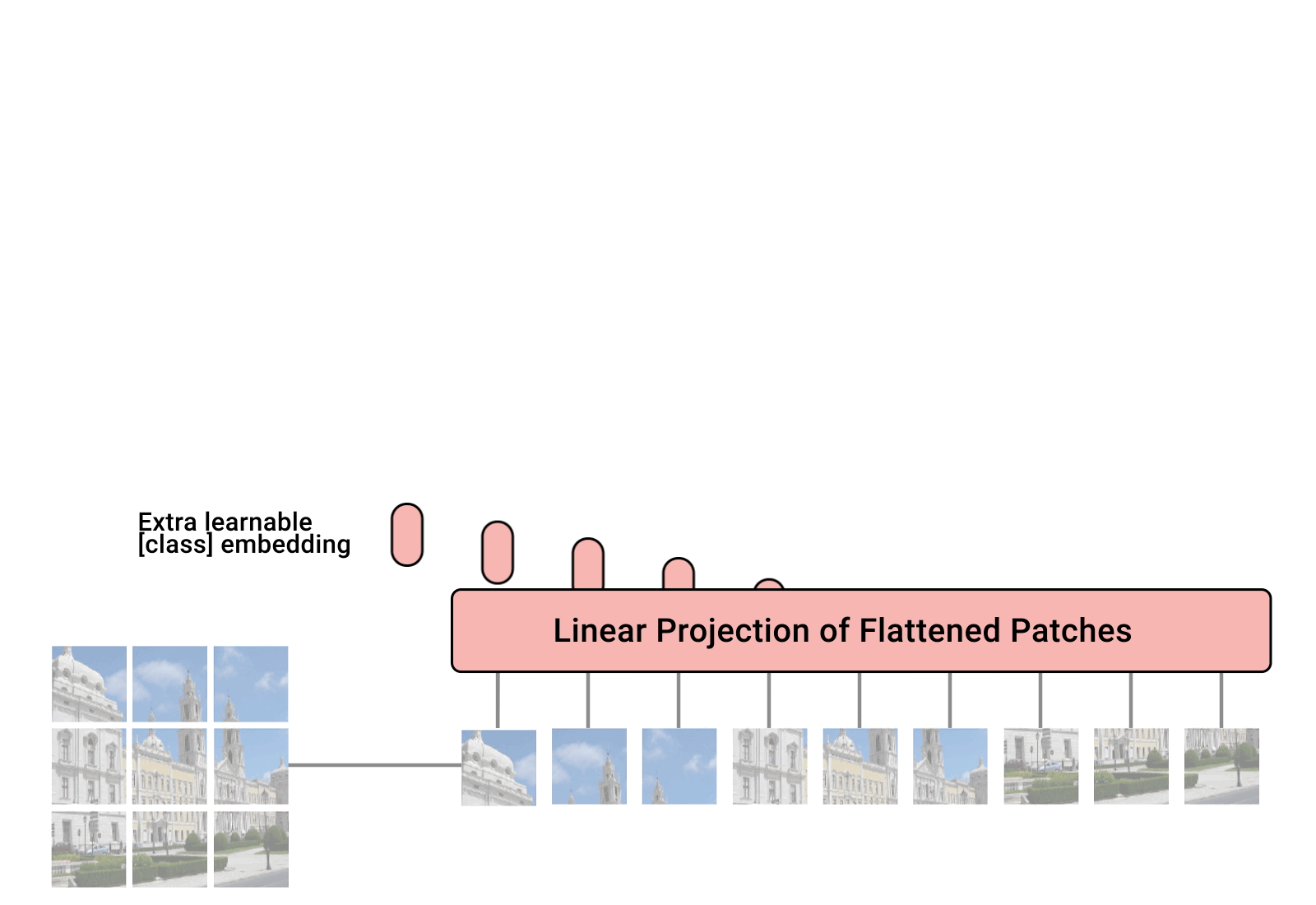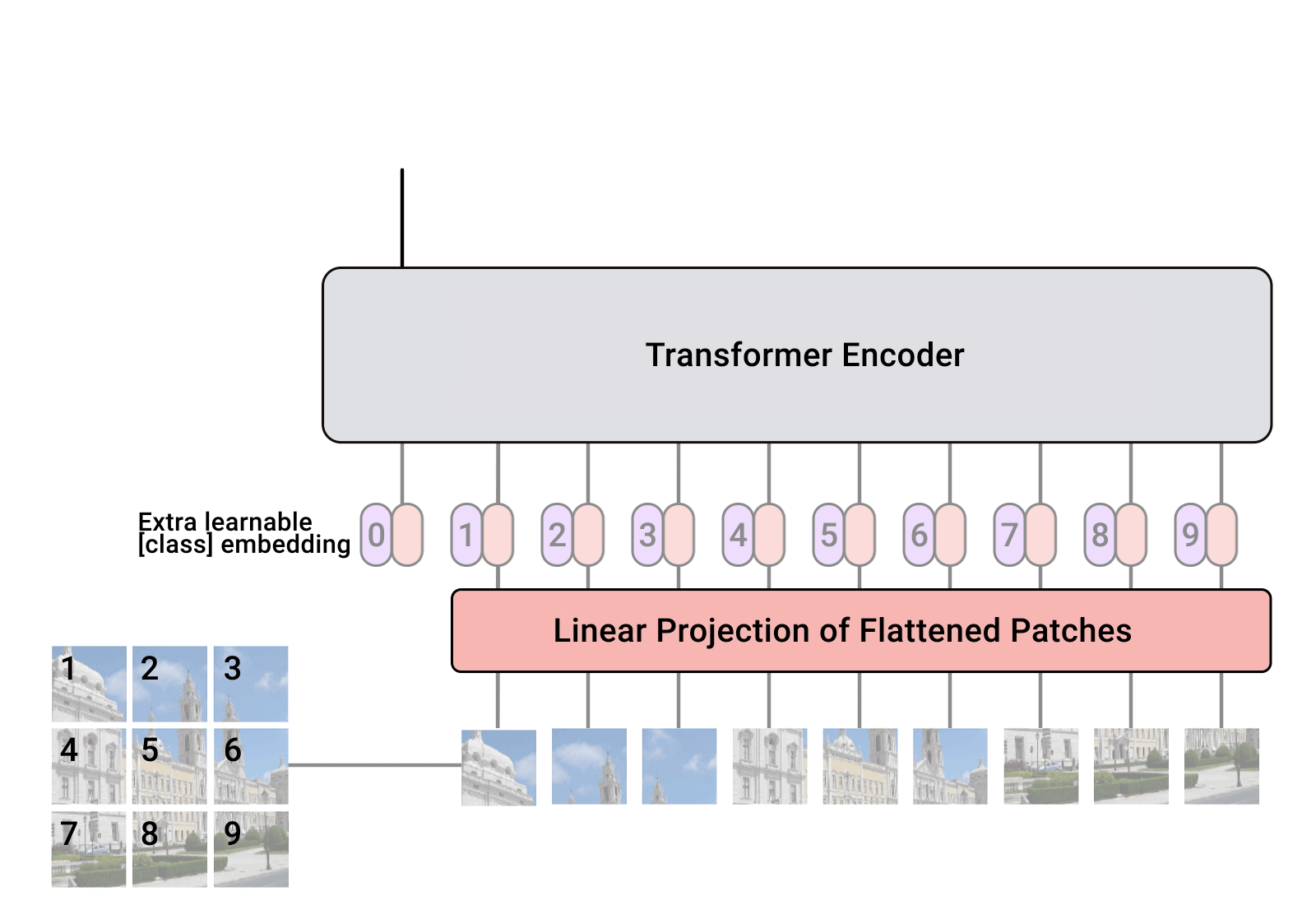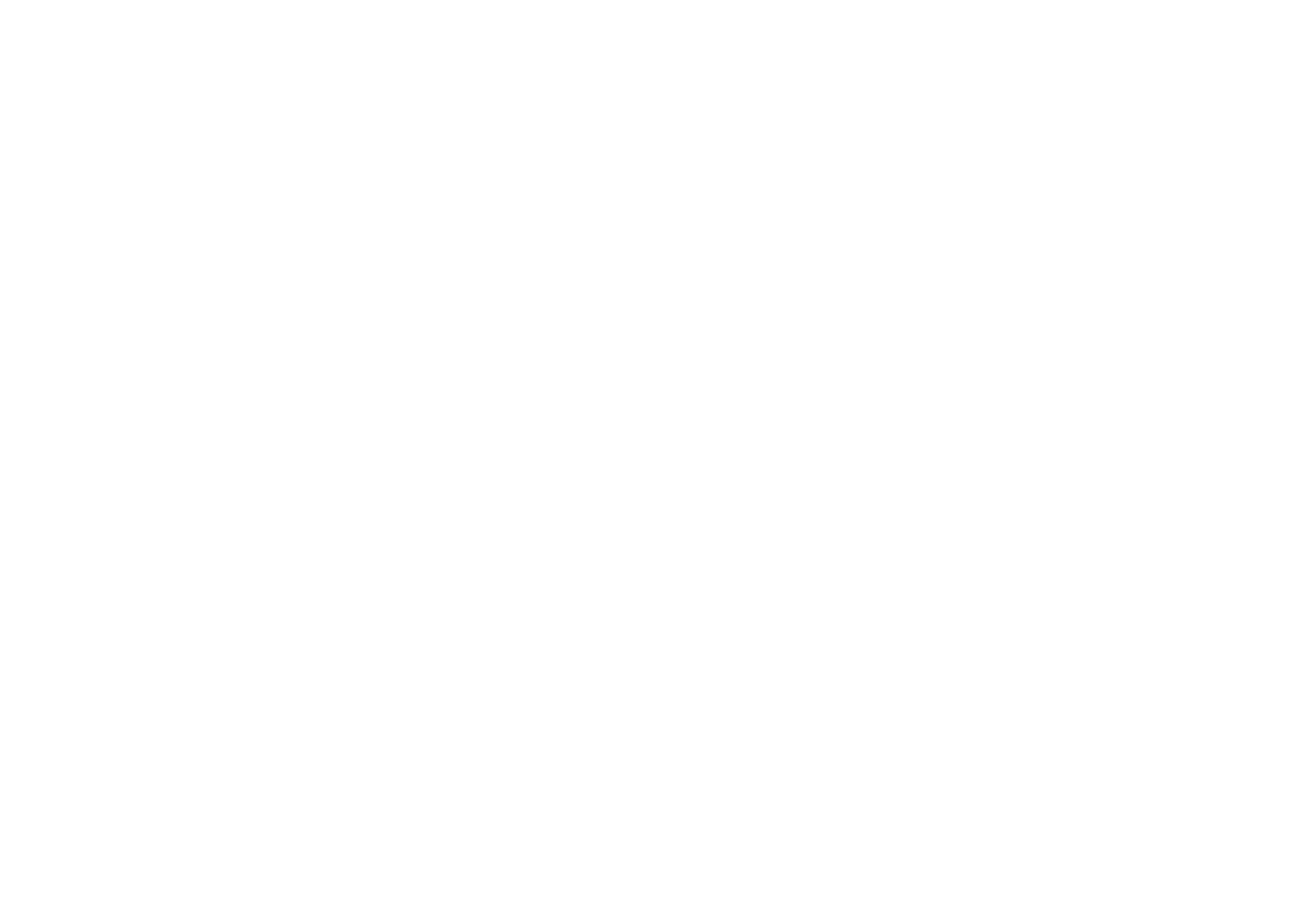
附代码 Vision Transformer(VIT)模型解读
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
该论文主要介绍了如何仅仅使用Trnsformers来进行图像分类。 Transformers lack some of the inductive biases inherent to CNNs, such as translation equivariance and locality, and therefor…

Swin Transformer中torch.roll()详解
torch.roll()这个函数看官方解释很懵,直接对照可视化来理解 参考:torch.roll 函数的理解
torch.roll(x, shifts(40, 40), dims(1, 2)) 这里img的shape是[1,56,56,96],即[B,H,W,C]格式。 dim1,shift40指的就是数据沿着H维度,将数据朝正反向滚…
Swin Transformer——细节详解
Swin Transformer——细节详解
划分窗口与合并窗口
举例: 默认情况下window_size7 划分窗口:将输入数据shape[4, 224, 224, 196]的数据reshape成[4*num_windows, 7, 7, 196] 合并窗口:将输入数据shape[4*num_windows, 7, 7, 196]的数据resh…
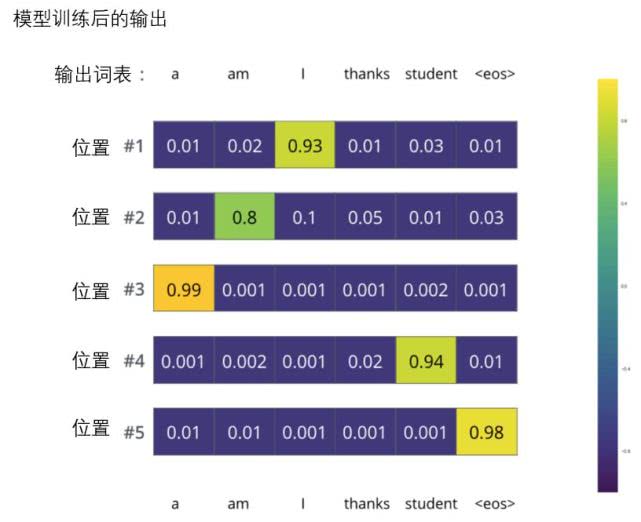
图解Transformer(完整版)
作者: 龙心尘 时间:2019年1月 出处:https://blog.csdn.net/longxinchen_ml/article/details/86533005
审校:百度NLP、龙心尘 翻译:张驰、毅航、Conrad 原作者:Jay Alammar 原链接:https://jala…

Vis-TOP:视觉Transformer叠加处理器
摘要
近年来,Transformer[23]在自然语言处理(NLP)领域取得了良好的效果,并开始向计算机视觉(CV)领域拓展。优秀的型号如Vision Transformer[5]和Swin Transformer[17]已经出现。同时,Transformer模型平台扩展到嵌入式设备,以满足…
swing transformer中修改mmdetection预训练的mask-rcnn使类别数适应custom dataset
由于mmdetection封装程度较高,直接更改builder过程比较麻烦,所以recommend这种预处理的方式,先将模型权重文件处理好
import torchdef main():#gen coco pretrained weightnum_classes 6model_coco torch.load("./checkpoint/cascade…
swin-transformer安装mmcv-full
首先swin-T要求mmcv版本不能高于1.4.0,所以一些安装就不能像mmcv官网安装的那么随意,首先是查看自己的cuda,安装torch。在安装torch前,应该先参看此种cudatorch组合下是否有mmcv-full1.4.0的安装包。比如 https://download.openmm…

Ghost-free High Dynamic Range Imaging withContext-aware Transformer
Abstract
高动态范围(HDR)去鬼算法旨在生成具有真实感细节的无鬼HDR图像。 受感受野局部性的限制,现有的基于CNN的方法在大运动和严重饱和度的情况下容易产生重影伪影和强度畸变。 本文提出了一种新的上下文感知视觉转换器(CA-VIT)用于高动态…
YOLOv8改进Swin Transformer V2升级版本:在基础SwinTransformer v2 结构的基础上进行多种改进结构, 强大的视觉主干
💡本篇内容:YOLOv8改进Swin Transformer V2升级版本:在基础SwinTransformer v2 结构的基础上进行多种改进结构, 强大的视觉主干
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:二次创新,YOLOv8专属…
Transformer是什么,Transformer应用
目录
Transformer应用
Transformer是什么 Transformer应用:循环神经网络
语言翻译:注重语句前后顺序
RNN看中单个特征;
CNN:看中特征之间时序性
模型关注不同位置的能力
Transformer是什么
Transformer是一个利用注意力机制来提高模型训练速度的模型。关于注意力机…
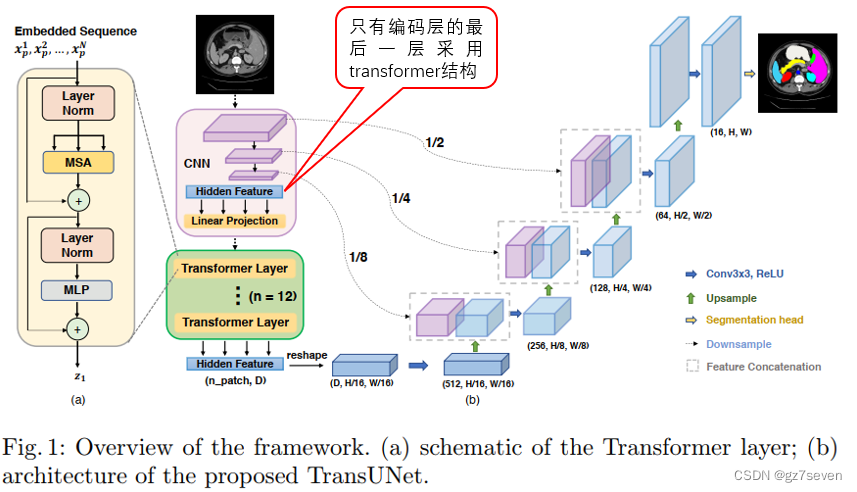
图像分割unet系列------TransUnet详解
图像分割unet系列------TransUnet详解 1、TransUnet结构2、我关心的问题3、总结与展望TransUnet发表于2021年,它是对UNet非常重要的改进,专为医学图像分割任务设计,特别用于在医学图像中分割器官或病变等解剖结构。 1、TransUnet结构 TransUNet在U-Net模型的基础上引入了混合…

使用 Transformer 和 Amazon OpenSearch Service 构建基于列的语义搜索引擎
在数据湖中,对于数据清理和注释、架构匹配、数据发现和跨多个数据来源进行分析等许多操作,查找相似的列有着重要的应用。如果不能从多个不同的来源准确查找和分析数据,就会严重拉低效率,不论是数据科学家、医学研究人员、学者&…
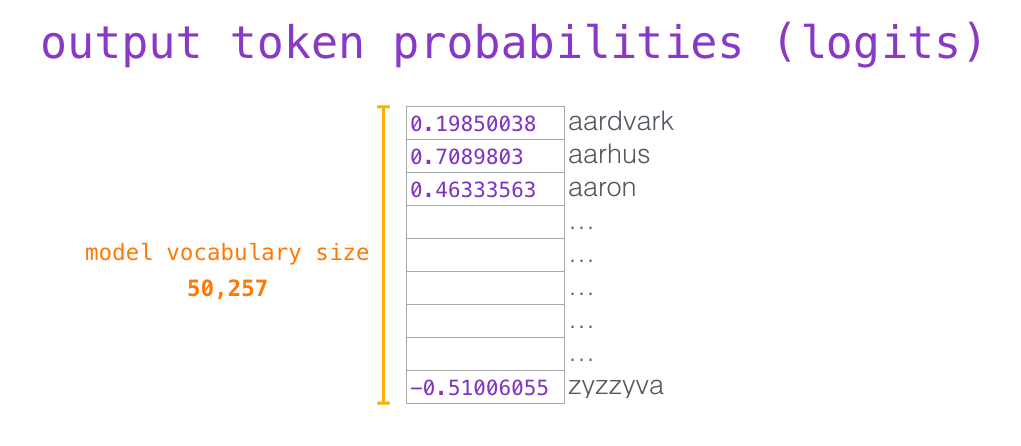
GPT2计算流程详解
GPT-2 就像传统的语言模型一样,一次只输出一个单词(token)。这种模型之所以效果好是因为在每个新单词产生后,该单词就被添加在之前生成的单词序列后面,这个序列会成为模型下一步的新输入。这种机制叫做自回归ÿ…
Attention is all you need 官方 tensorflow 1.x 实现
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py 1,搭建cuda10.0环境,
2,安装tensorflow 1.14.0
3,安装python3的 tensor2tensor 包 4,示例代码:
impor…
Transformer系列模型笔记
1.word2vec
1.1 CBOW(词袋模型)
根据上下出现的单词预测中间的单词,包括输入层、投影层、输出层。输入层包括上下出现单词的向量化表示;投影层是把输入层的向量累加求和后做映射;输出层(计算语料库中所有单词的概率,计算量大&am…
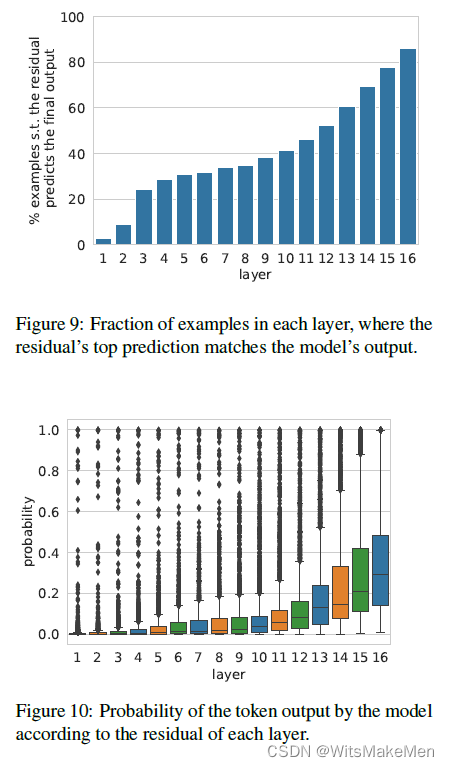
Transformer是否真正理解了自然语言的语义信息,还是单纯的模式识别
论文引用 此篇阅读笔记与思考主要针对以下两篇论文:
Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data
Transformer Feed-Forward Layers Are Key-Value Memories
本文将讨论第一篇论文所引发的思考(第一篇论文的详细解…

【论文学习】Transformer-XL
目录简介模型Vanilla Transformerrecurrence mechanism相对位置编码pytorch实现——batch_size为第一维度参考资料简介
RNN及其变体是训练语言模型(Language Modeling)的经典结构,其优点就是能够学习到序列之间的依赖关系,缺点&a…

深入理解BERT Transformer ,不仅仅是注意力机制
作者: 龙心尘 时间:2019年3月 出处:https://blog.csdn.net/longxinchen_ml/article/details/89058309
大数据文摘与百度NLP联合出品 作者:Damien Sileo 审校:百度NLP、龙心尘 编译:张驰、毅航
为什么BERT…

用可视化解构BERT,我们从上亿参数中提取出了6种直观模式
作者: 龙心尘 时间:2019年1月 出处:https://blog.csdn.net/longxinchen_ml/article/details/89036531
大数据文摘联合百度NLP出品 审校:百度NLP、龙心尘 编译:Andy,张驰 来源:towardsdatascien…
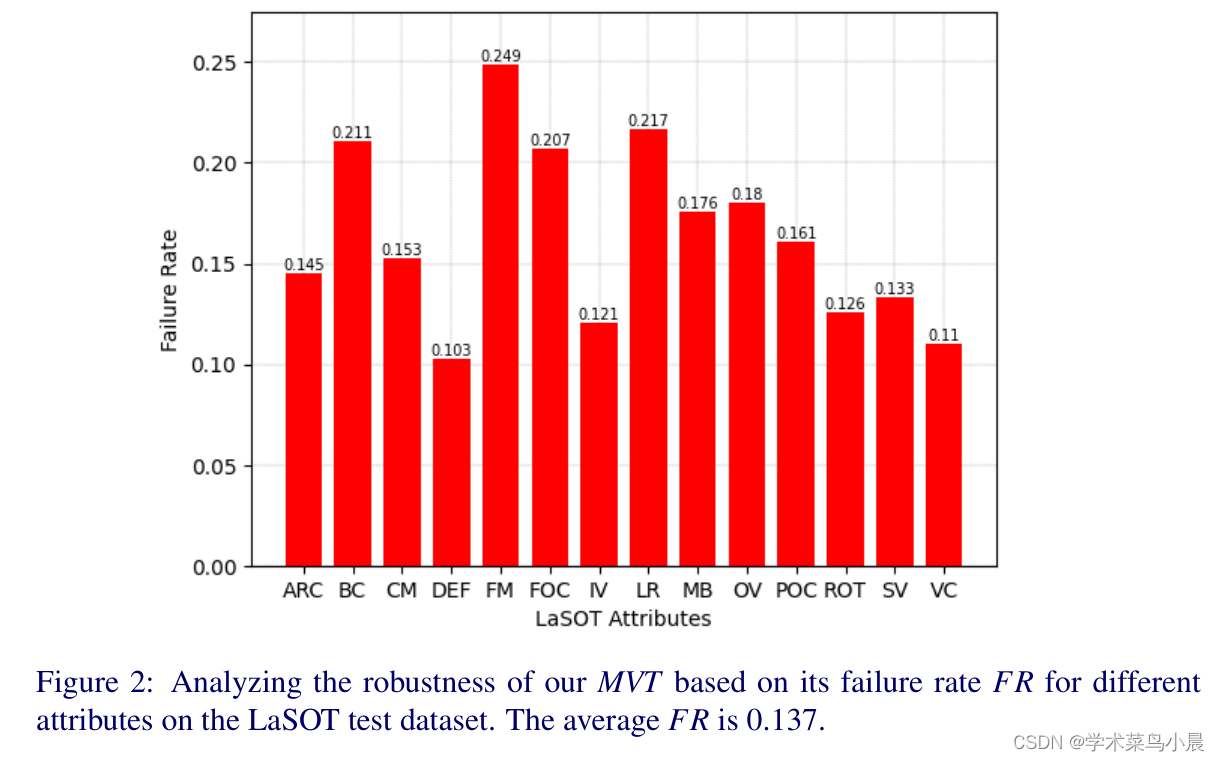
目标跟踪:Mobile Vision Transformer-based Visual Object Tracking
论文作者:Goutam Yelluru Gopal,Maria A. Amer
作者单位:Concordia University
论文链接:https://arxiv.org/pdf/2309.05829v1.pdf
项目链接:https://github.com/goutamyg/MVT
内容简介:
1)方向&#…
【Spring Boot】使用Spring Boot进行transformer的部署与开发
Transformer是一个用于数据转换和处理的平台,使用Spring Boot可以方便地进行Transformer的部署与开发。
以下是使用Spring Boot进行Transformer部署与开发的步骤:
创建Spring Boot项目
可以使用Spring Initializr创建一个简单的Spring Boot项目。在创…

NLP-D30-自注意力机制Transformer
—0526在啃黄瓜,已经看了一会沐沐叻。
1、Trandformer
看着看着简直要喷黄瓜了hhhhhhhh。 Tranformer也挺简单的,我一张ppt就讲完了。 不过这张ppt做的挺好的hhhh
-------0600看完了transformer,但对应代码还没看,看了多头的代…
在PyTorch里面利用transformers的Trainer微调预训练大模型
背景
transformers提供了非常便捷的api来进行大模型的微调,下面就讲一讲利用Trainer来微调大模型的步骤
第一步:加载预训练的大模型
from transformers import AutoModelForSequenceClassificationmodel AutoModelForSequenceClassification.from_pr…
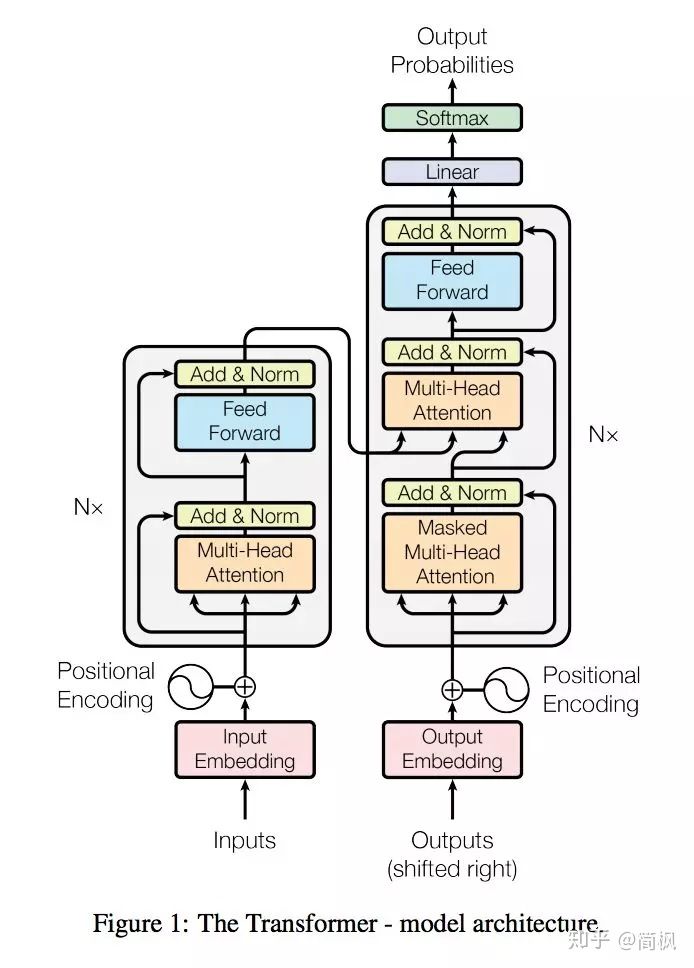
深度学习11:Transformer
目录
什么是 Transformer?
Encoder
Decoder
Attention
Self-Attention
Context-Attention
什么是 Transformer(微软研究院笨笨)
RNN和Transformer区别
Universal Transformer和Transformer 区别 什么是 Transformer? …
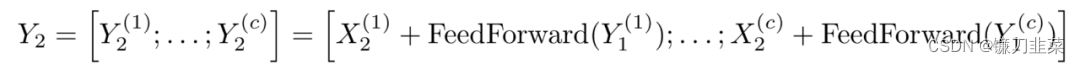
【NLP】手把手使用PyTorch实现Transformer以及Transformer-XL
手把手使用PyTorch实现Transformer以及Transformer-XL Abstract of Attention is all you need使用PyTorch实现Transformer1. 构建Encoder-Decoder模型1.1 导入依赖库1.2 创建Encoder-Decoder类1.3 创建Generator类 2. 构建Encoder2.1 定义复制模块的函数2.2 创建Encoder2.3 构…
Hugging Face--Transformers
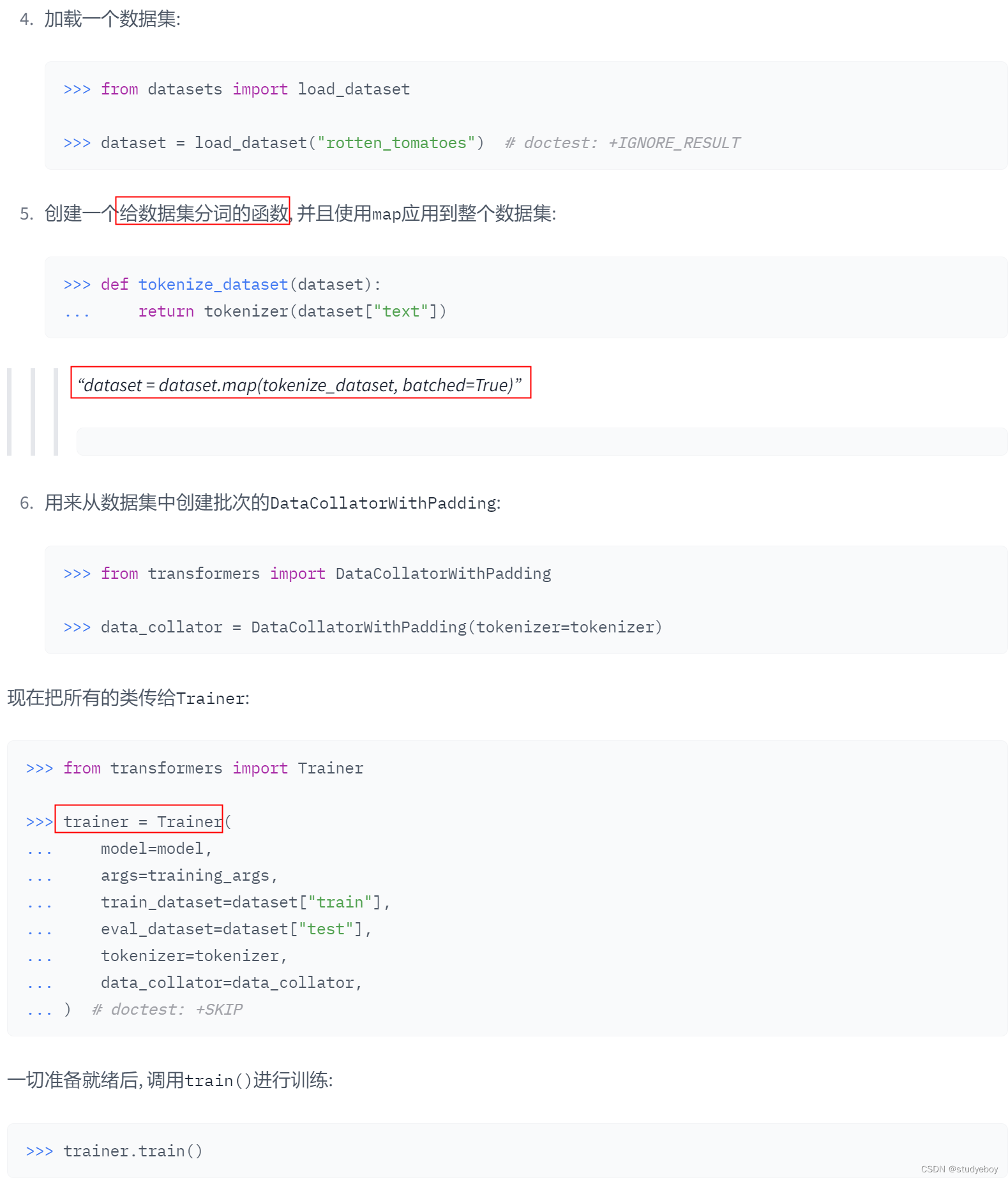
pipeline 在这里插入图片描述
AutoClass
AutoClass 是一个能够通过预训练模型的名称或路径自动查找其架构的快捷方式. 你只需要为你的任务选择合适的 AutoClass 和它关联的预处理类。
AutoTokenizer AutoModel 保存模型 自定义模型构建 Trainer - PyTorch优化训练循环 参考资…
hugging face inference API返回内容太短的问题
hugging face的inference api返回的内容默认很短,可以通过参数max_new_tokens进行设置:
Detailed parameters
When sending your request, you should send a JSON encoded payload. Here are all the options
All parametersinputs (required):a str…

ICCV 2023 | 利用双重聚合的Transformer进行图像超分辨率
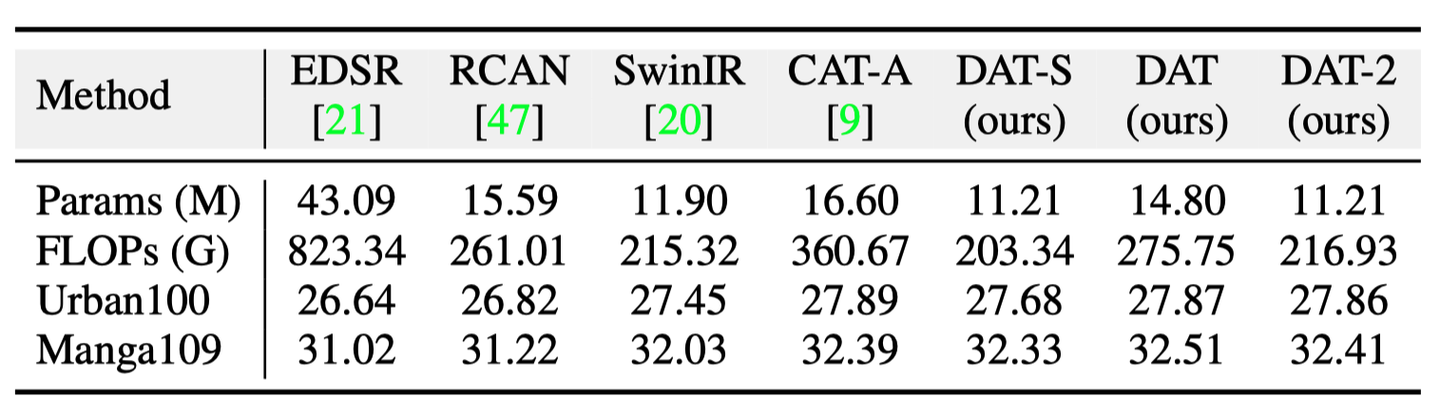
导读 本文提出一种同时利用图像空间和通道特征的 Transformer 模型,DAT(Dual Aggregation Transformer),用于图像超分辨(Super-Resolution,SR)任务。DAT 以块间和块内的双重方式,在空…

Self-Attention Transformer完全指南:像Transformer的创作者一样思考
本文从RNN到self-attention,再到Transformer来讲清楚整个算法。
近半年来有大量同学来找我问Transformer的一些细节问题,例如Transformer与传统seq2seq RNN的区别、self-attention层的深入理解、masked self-attention的运作机制;以及各种Tr…
Hugging Face 实战系列 总目录
PyTorch 深度学习 开发环境搭建 全教程
Transformer:《Attention is all you need》
Hugging Face简介 1、Hugging Face实战-系列教程1:Tokenizer分词器(Transformer工具包/自然语言处理) Hungging Face实战-系列教程1:Tokenize…

ChatGLM Pytorch从0编写Transformer算法
预备工作 # !pip install http://download.pytorch.org/whl/cu80/torch-0.3.0.post4-cp36-cp36m-linux_x86_64.whl numpy matplotlib spacy torchtext seaborn import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math, copy, tim…
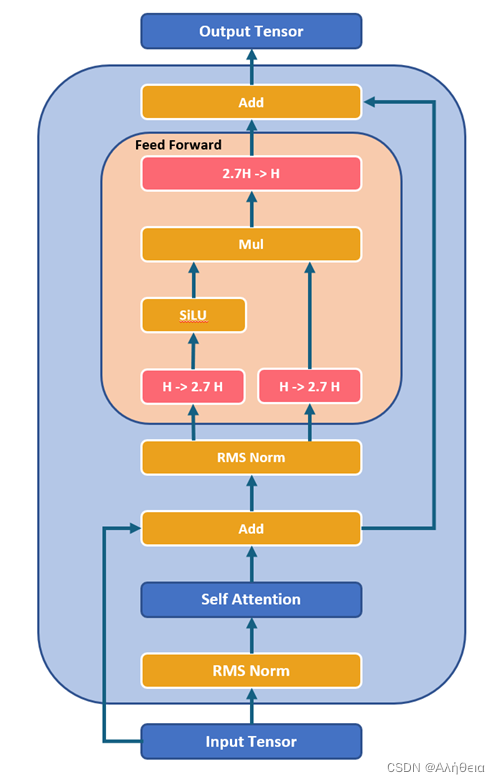
LLM各层参数详细分析(以LLaMA为例)
网上大多分析LLM参数的文章都比较粗粒度,对于LLM的精确部署不太友好,在这里记录一下分析LLM参数的过程。 首先看QKV。先上transformer原文 也就是说,当h(heads) 1时,在默认情况下, W i Q W_i^…
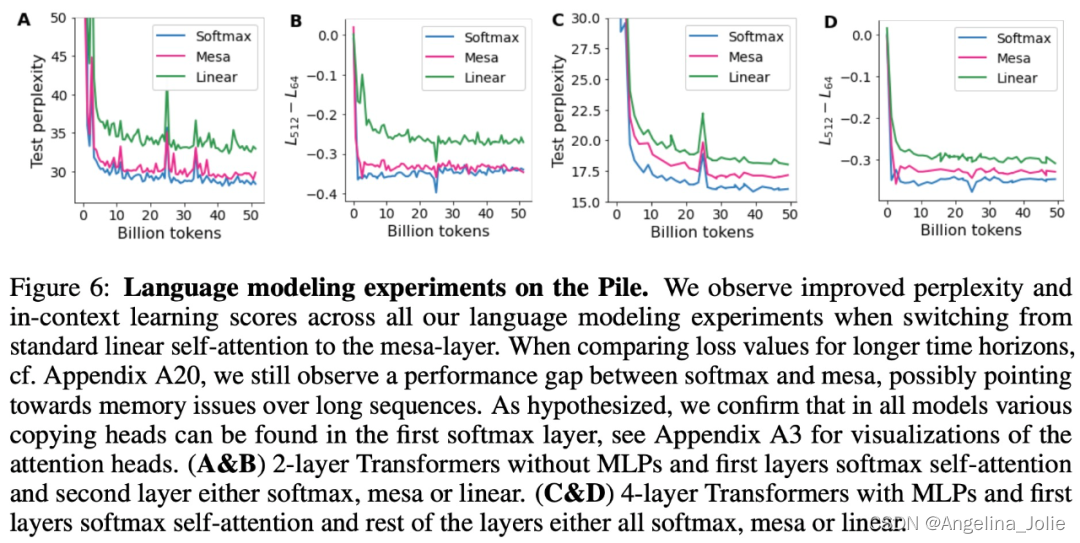
Transformer的上下文学习能力
《Uncovering mesa-optimization algorithms in Transformers》
论文链接:https://arxiv.org/abs/2309.05858
为什么 transformer 性能这么好?它给众多大语言模型带来的上下文学习 (In-Context Learning) 能力是从何而来?在人工智能领域里&…
Hugging Face实战-系列教程3:文本2分类
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在notebook中进行 本篇文章配套的代码资源已经上传 下篇内容: Hugging Face实战-系列教程4:padding与attention_mask
输出我…
【Image captioning】 Collaborative Transformer for Image Captioning实现流程
Dual-Level Collaborative Transformer for Image Captioning实现流程(原始代码的readme)
作者:安静到无声 个人主页 目录 Dual-Level Collaborative Transformer for Image Captioning实现流程(原始代码的readme)实验设置数据准备训练评价参考致谢推荐专栏论文地址:https:/…
An Efficient Memory-Augmented Transformer for Knowledge-Intensive NLP Tasks
本文是LLM系列文章,针对《An Efficient Memory-Augmented Transformer for Knowledge 一种用于知识密集型NLP任务的高效内存增强转换器 摘要1 引言2 相关工作3 高效内存增强Transformer4 EMAT的训练流程5 实验6 分析7 结论局限性 摘要
获取外部知识对于许多自然语言…
基于transformer一步一步训练一个多标签文本分类的BERT模型
Bert(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,由Google在2018年提出。Bert模型在自然语言处理领域取得了重大突破,被广泛应用于各种NLP任务,如文本分类、命名实体识别、问答系统等。
Bert模型的核心思想是通…
论文阅读:SERE: Exploring Feature Self-relation for Self-supervised Transformer
Related Work
Self-supervised 学习目的是在无人工标注的情况下通过自定制的任务(hand-crafted pretext tasks)学习丰富的表示。
Abstract
使用自监督学习为卷积网络(CNN)学习表示已经被验证对视觉任务有效。作为CNN的一种替代…
【ViT(Vision Transformer)】(二) 阅读笔记
简介
ViT是2020年Google团队提出的将Transformer应用在图像分类的模型,虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好)&#x…
【论文+代码】1706.Transformer简易学习笔记
Transformer 论文: 1706.attention is all you need! 唐宇迪解读transformer:transformer2021年前,从NLP活到CV的过程 综述:2110.Transformers in Vision: A Survey 代码讲解1: Transformer 模型详解及代码实现 - 进击的程序猿 - 知乎 代码讲…
esbuild中文文档-语法转换(Transformation - Supported、Target)
文章目录 语法转换 Transformation配置支持的语法 Supported构建目标 Target 结语 哈喽,大家好!我是「励志前端小黑哥」,我带着最新发布的文章又来了! 老规矩,小手动起来~点赞关注不迷路! esbuild简单介绍 …
![[异构图-论文阅读]Heterogeneous Graph Transformer](https://img-blog.csdnimg.cn/e8c4750d1ade4944b74a82cb7a93be59.png)
[异构图-论文阅读]Heterogeneous Graph Transformer
这篇论文介绍了一种用于建模Web规模异构图的异构图变换器(HGT)架构。以下是主要的要点:
摘要和引言 (第1页) 异构图被用来抽象和建模复杂系统,其中不同类型的对象以各种方式相互作用。许多现有的图神经网络(GNNs)主要针对同构图设计,无法有效表示异构结构。HGT通过设计…

【transformer】自注意力源码解读和复杂度计算
Self-attention A t t e n t i o n ( Q , K , V ) s o f t m a x ( Q K T d k ) V Attention(Q,K,V) softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)softmax(dk QKT)V
其中, Q Q Q为查询向量, K K K和 V V V为键向量和值向量,…

Activating More Pixels in Image Super-Resolution Transformer(HAT)超分
摘要
基于Transformer的方法在低级视觉任务(如图像超分辨率)上表现出令人印象深刻的性能。然而,我们发现这些网络只能通过归因分析利用有限的输入信息空间范围。这意味着Transformer的潜力在现有网络中仍未得到充分利用。为了激活更多输入像…
深度学习原理学习小结 - Self-Attention/Transformer
文章目录深度学习原理学习小结 - Self-Attention/TransformerSelf-Attention基本原理引入核心概念计算方法Transformer基本原理知识补充编码器(Encoder)与 解码器(Decoder)Transformer关键代码解读多头注意力Transfomer深度学习原…
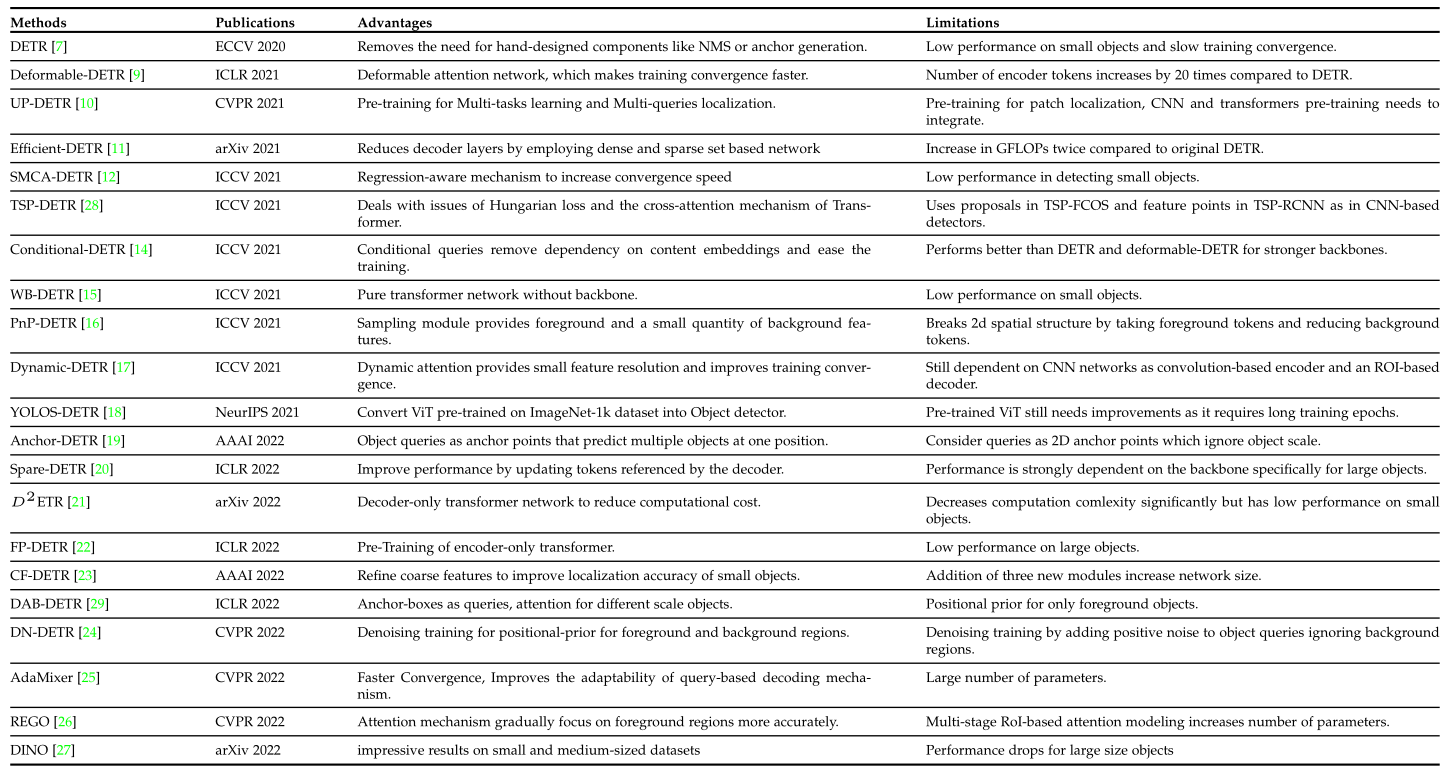
【计算机视觉】DETR 系列的最新综述!
论文地址:
https://arxiv.org/pdf/2306.04670.pdf项目地址:
https://github.com/mindgarage-shan/trans_object_detection_surveyTransformer在自然语言处理(NLP)中的惊人表现,让研究人员很兴奋地探索它们在计算机视觉任务中的应用。与其他…

OneFormer: One Transformer to Rule Universal Image Segmentation论文笔记
论文https://arxiv.org/pdf/2211.06220.pdfCodehttps://github.com/SHI-Labs/OneFormer 文章目录 1. Motivation2. 方法2.1 与Mask2Former的相同之处2.2 OneFormer创新之处2.3 Task Conditioned Joint Training2.4 Query Representations2.4 Task Guided Contrastive Queries 3…

读书笔记:多Transformer的双向编码器表示法(Bert)-1
多Transformer的双向编码器表示法
Bidirectional Encoder Representations from Transformers,即Bert; 本笔记主要是对谷歌Bert架构的入门学习:
介绍Transformer架构,理解编码器和解码器的工作原理;掌握Bert模型架构…

Attention is all you need ---Transformer
大语言模型已经在很多领域大显身手,其应用包括只能写作、音乐创作、知识问答、聊天、客服、广告文案、论文、新闻、小说创作、润色、会议/文章摘要等等领域。在商业上模型即产品、服务即产品、插件即产品,任何形态的用户可触及的都可以是产品,…
大语言模型之一 Attention is all you need ---Transformer
大语言模型已经在很多领域大显身手,其应用包括只能写作、音乐创作、知识问答、聊天、客服、广告文案、论文、新闻、小说创作、润色、会议/文章摘要等等领域。在商业上模型即产品、服务即产品、插件即产品,任何形态的用户可触及的都可以是产品,…
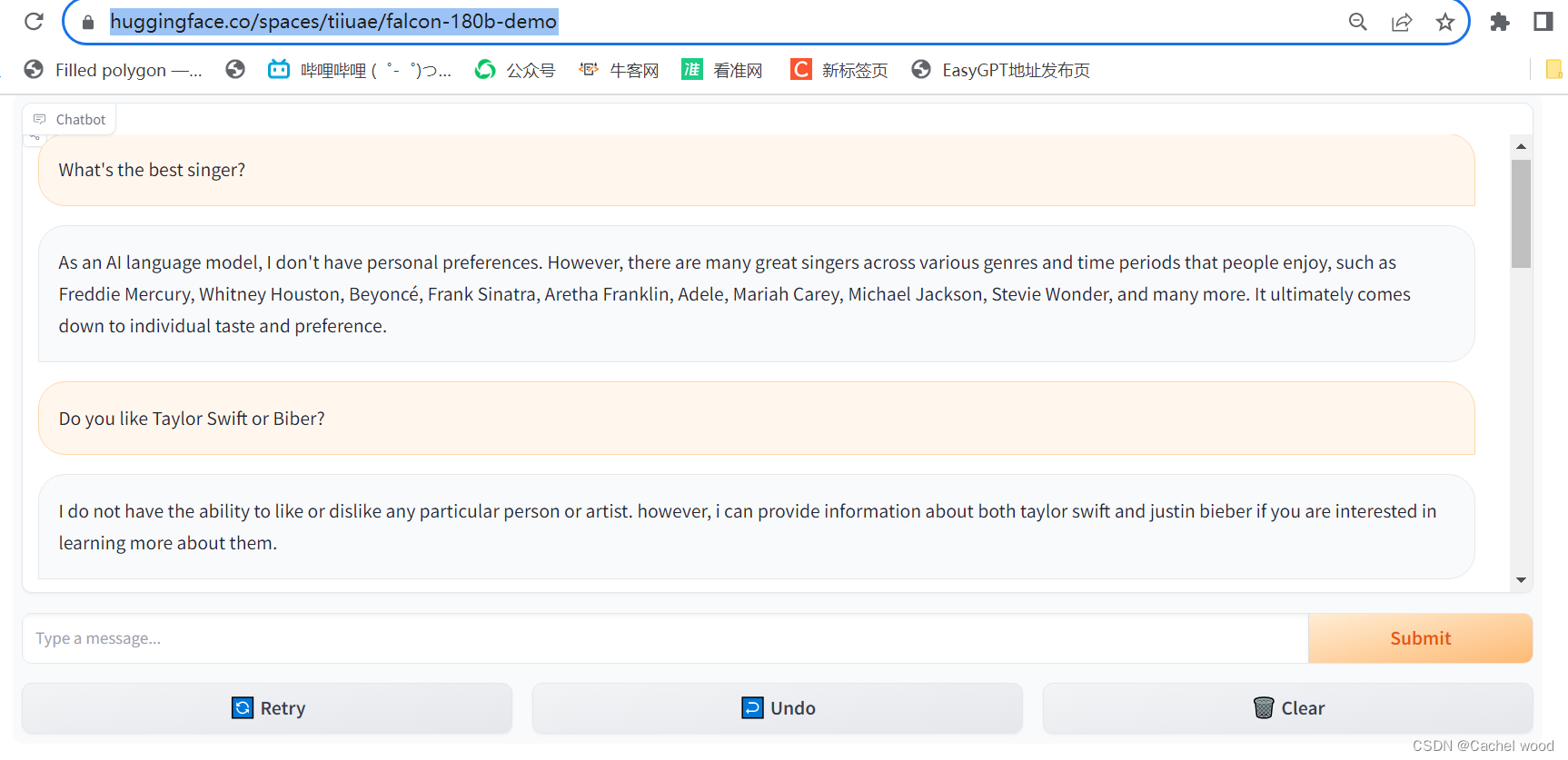
180B参数的Falcon登顶Hugging Face,最好开源大模型使用体验
文章目录 使用地址使用体验test1:简单喜好类问题使用地址
https://huggingface.co/spaces/tiiuae/falcon-180b-demo
使用体验 相比Falcon-7b,Falcon-180b拥有1800亿的参数量,在智能问答领域做到了Top 1。在回答问题的深度和广度上都明显优于只有70亿参数量的Falcon-7b,并…
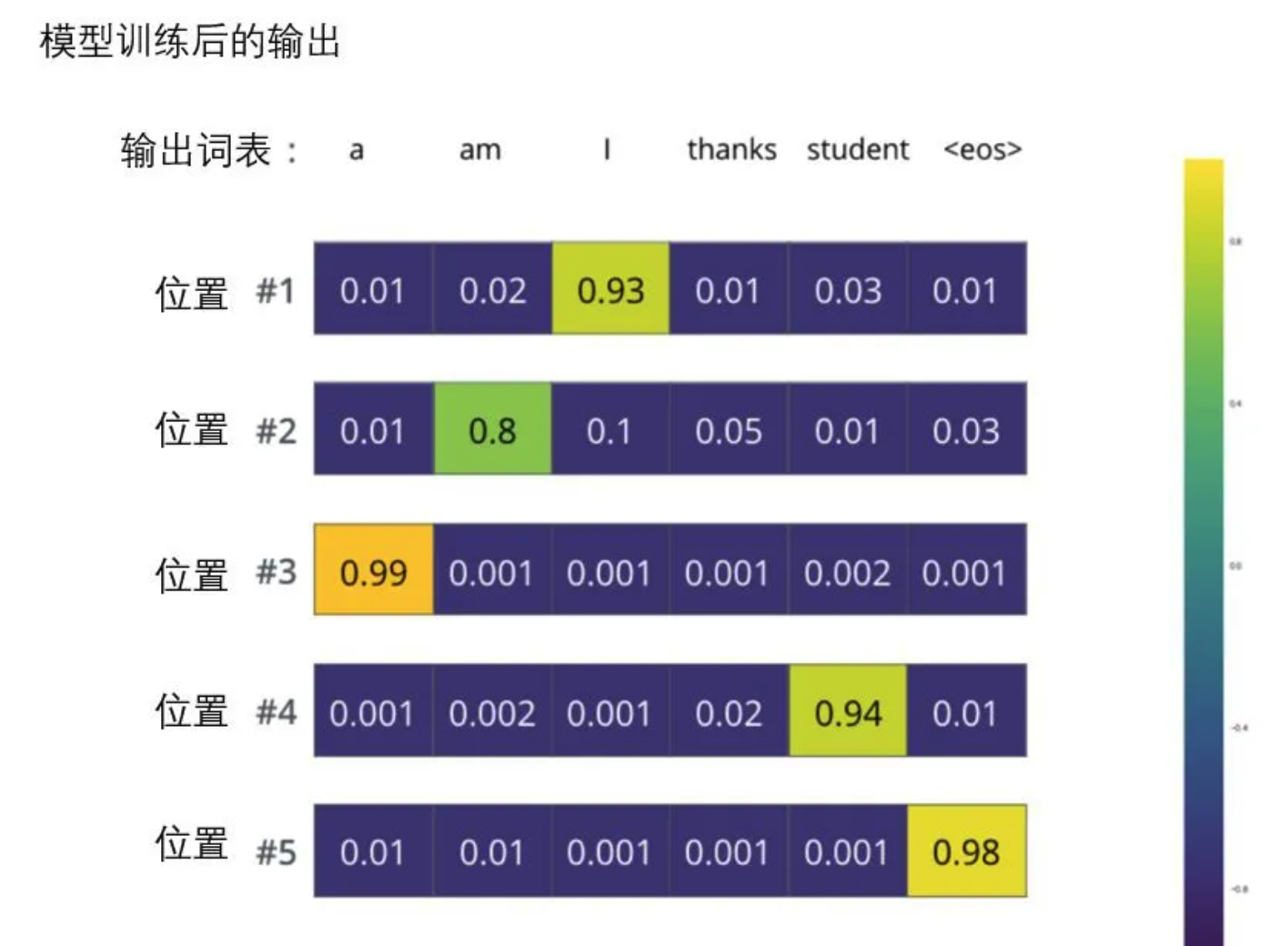
transformer 总结(超详细-初版)
相关知识链接
attention1attention2
引言
本文主要详解 transformer 的算法结构以及理论解释,代码实现以及具体实现时候的细节放在下一篇来详述。 下面就通过上图中 transformer 的结构来依次解析
输入部分(Encode 侧)
input 输出主要包含 两个部分:…
Transformer貌似也是可以使用state递归解码和训练的
import paddle
import numpy as npclass HeadLoss(paddle.nn.Layer):def __init__(self):super(HeadLoss, self).__init__()
人工智能AI知多少?
摘要
人工智能(Artificial Intelligence,简称AI)是一项前沿技术,正在快速发展并渗透到各个领域。然而,对于大多数人来说,人工智能仍然是一个陌生而复杂的概念。本文旨在对人工智能进行扫盲,介绍其基本概念、应用领域以及当前热门的人工智能模型。通过具体的例子,读者将…
HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出
今天跟大家分享华南理工大学和阿里巴巴联合提出的将ViT模型用于下游任务的高效微调方法HSN,该方法在迁移学习、目标检测、实例分割、语义分割等多个下游任务中表现优秀,性能接近甚至在某些任务上超越全参数微调。 论文标题:Hierarchical Side…
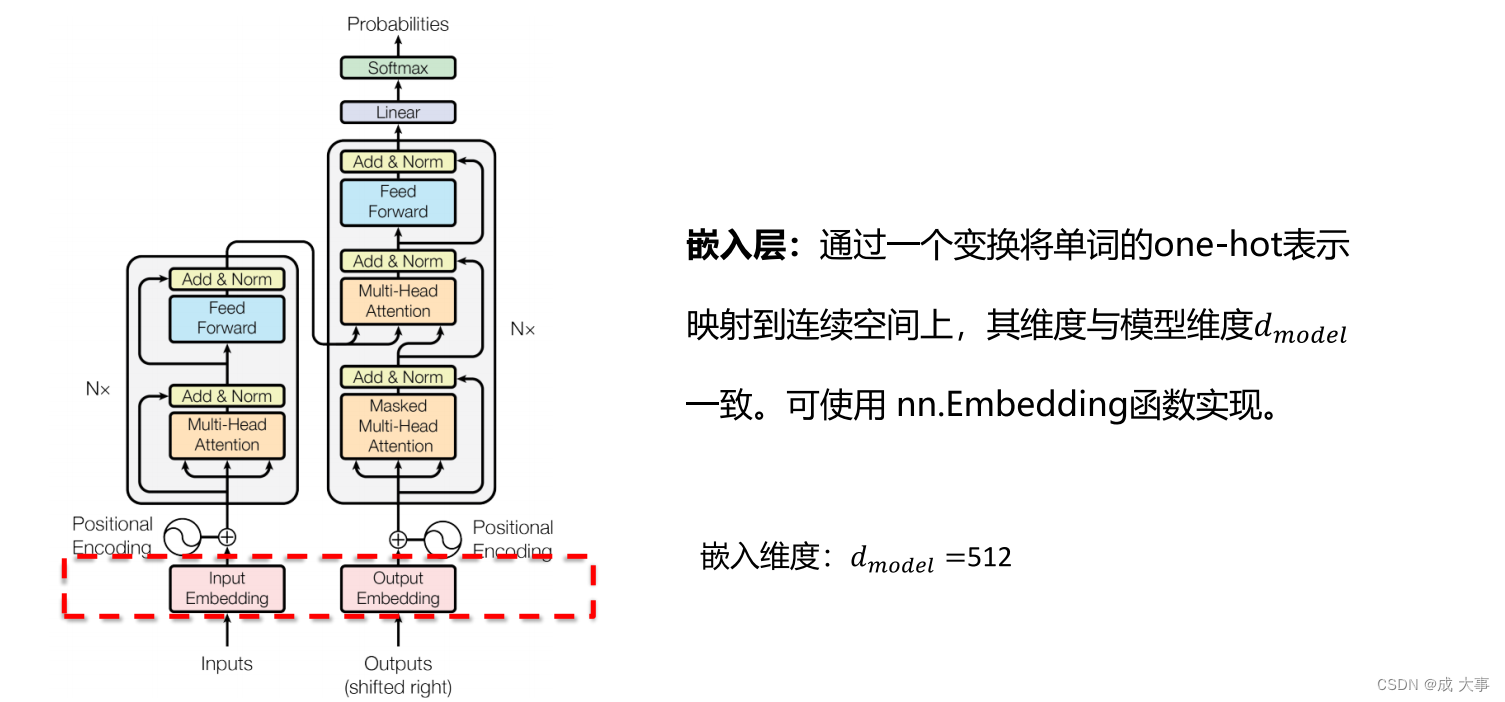
手动实现Transformer
Transformer和BERT可谓是LLM的基础模型,彻底搞懂极其必要。Transformer最初设想是作为文本翻译模型使用的,而BERT模型构建使用了Transformer的部分组件,如果理解了Transformer,则能很轻松地理解BERT。
一.Transformer模型架构 1…
计算机视觉与深度学习-Transformer-【北邮鲁鹏】
目录 引入基本组成编码器多头自注意力机制(Multi-Head Self-Attention)多头自注意力的计算过程头数与维度关系前馈神经网络(Feed-Forward Neural Network) 编码器中的ADD&NORM加法操作(Addition)归一化…

【Transformer系列】深入浅出理解ViT(Vision Transformer)网络模型
一、参考资料
极智AI | 详解 ViT 算法实现 MobileViT模型简介 ECCV 2022丨力压苹果MobileViT,这个轻量级视觉模型新架构火了 ECCV 2022丨轻量级模型架构火了,力压苹果MobileViT(附代码和论文下载) 再读VIT,还有多少细…

Transformer 中 Positional Encoding 实现
参考博文:
https://www.cnblogs.com/nickchen121/p/16470736.html
解决问题
位置编码的主要目的是确保模型能够理解序列中的元素之间的相对位置和顺序,从而更好地捕捉到语义信息。在Transformer模型中,位置编码通常与词嵌入(w…
transformer_01
一、传统RNN存在的问题 1.序列前序太长,每个xi要记住前面的特征,而且一直在学,没有忘记,可能特征不能学的太好
2.串行,层越多越慢,难以堆叠很多层;
3.只能看到过去,不能看到未来 搞…
基于YOLOv8的安全帽检测系统(2):Gold-YOLO,遥遥领先,助力行为检测 | 华为诺亚NeurIPS23
目录 1.Yolov8介绍
2.安全帽数据集介绍
3.Gold-YOLO
4.训练结果分析 1.Yolov8介绍 Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的(SOTA)模型,它建立在先前YOLO成功基础上…
R语言:主成分分析PCA
文章目录 主成分分析处理步骤数据集code 主成分分析
主成分分析(或称主分量分析,principal component analysis)由皮尔逊(Pearson,1901)首先引入,后来被霍特林(Hotelling,1933)发展…
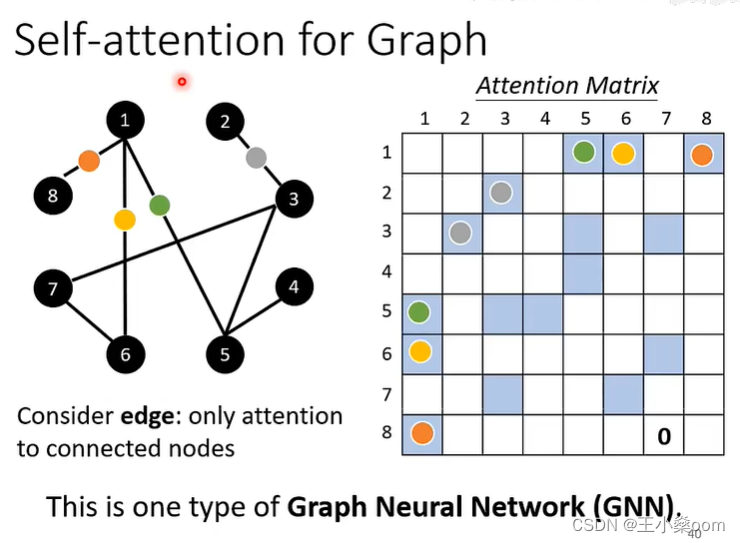
Transformer学习-self-attention
这里写自定义目录标题 Self-attentionMulti-head self-attention用self-attention解决其他问题 Self-attention
用Wq、Wk、Wv分别乘输入向量得到q、k、v向量 用每个q向量乘所有的k向量得到对应项的attention,即用每项的query向量去匹配所有的key向量,得…
逐行代码学习ChatGLM2-6B大模型SFT微调,项目中的ptune/main.py文件
项目地址
#!/usr/bin/env python
# codingutf-8
"""
Fine-tuning the library models for sequence to sequence.
下面给出了一个命令行运行微调main.py的例子#1.激活环境#2.执行torchrun
#--standalone 这个标志指定使用“standalone”模式运行分布式训练。这…
![[paper] Attention is all you need 论文浅析](https://img-blog.csdnimg.cn/9acd5671f1ad405b86087e19568eac3d.png)
[paper] Attention is all you need 论文浅析
Base
Title: 《Attention Is All You Need》 2023
paper:arxiv
Github: None
Abstract
This paper proposed a new simple network architecture, the Transformer based solely on attention mechanisms. Model Architecture
模型包括 encoder-decoder struc…

【CVPR 2023】 All are Worth Words: A ViT Backbone for Diffusion Models
All are Worth Words: A ViT Backbone for Diffusion Models, CVPR 2023
论文:https://arxiv.org/abs/2209.12152
代码:https://github.com/baofff/U-ViT
解读:U-ViT: A ViT Backbone for Diffusion Models - 知乎 (zhihu.com)
All are W…
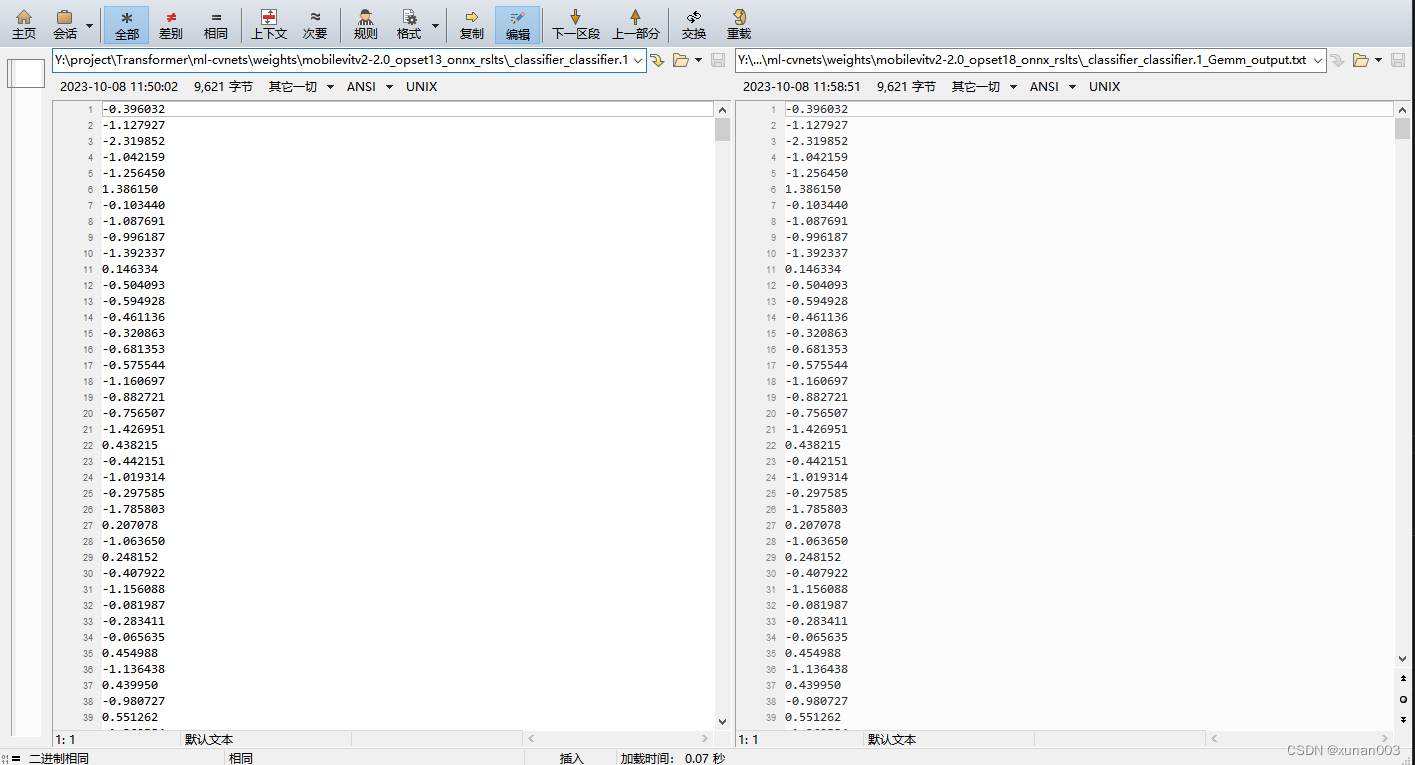
MobileViT v2导出onnx模型时遇Col2Im算子无法导出问题
相关error log索引
onnxruntime.capi.onnxruntime_pybind11_state.InvalidGraph: [ONNXRuntimeError] : 10 : INVALID_GRAPH : This is an invalid model. In Node, ("/classifier/classifier.0/ReduceMean", ReduceMean, "", -1) : ("/layer_5/laye…
自然语言处理---Transformer机制详解之BERT模型特点
1 BERT的优点和缺点
1.1 BERT的优点
通过预训练, 加上Fine-tunning, 在11项NLP任务上取得最优结果.BERT的根基源于Transformer, 相比传统RNN更加高效, 可以并行化处理同时能捕捉长距离的语义和结构依赖.BERT采用了Transformer架构中的Encoder模块, 不仅仅获得了真正意义上的b…
LLM 系列之 Transformer 组件总结
本系列为LLM 学习博客,会一一记录各个模块解读。 以下内容参考:大语言模型综述 https://github.com/RUCAIBox/LLMSurvey
主流架构
大语言模型,主要的核心组件是Transformer。不同的模型选择的架构不一样,目前主流架构有:
编码器…
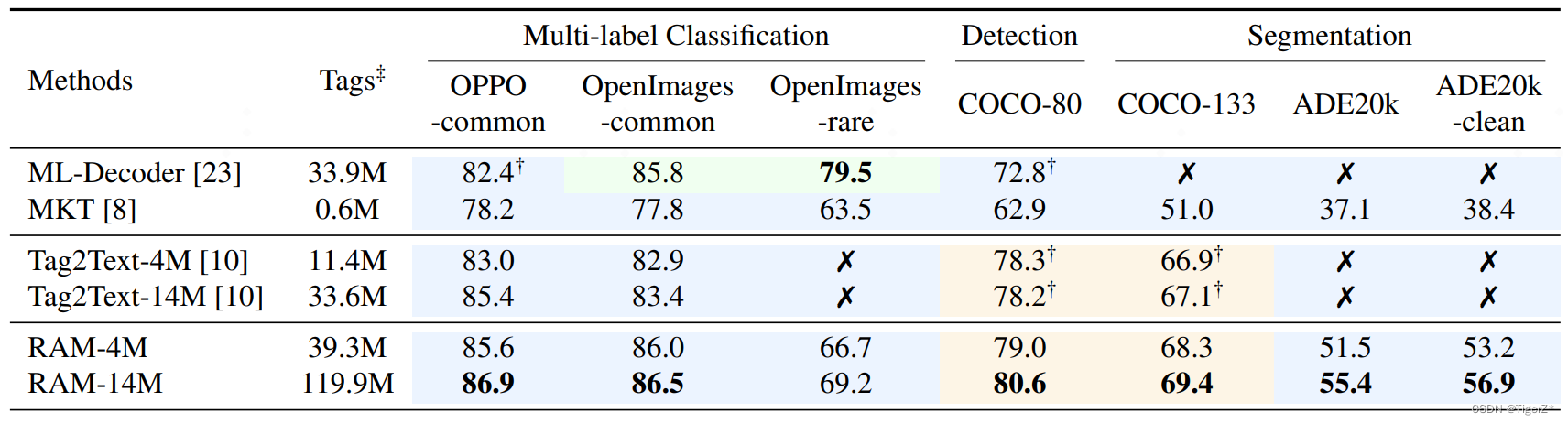
RAM(recognize anything)—— 论文详解
一、概述
1、是什么 RAM 论文全称 Recognize Anything: A Strong Image Tagging Model。区别于图像领域常见的分类、检测、分割,他是标记任务——即多标签分类任务(一张图片命中一个类别),区分于分类(一张图片命中一个…
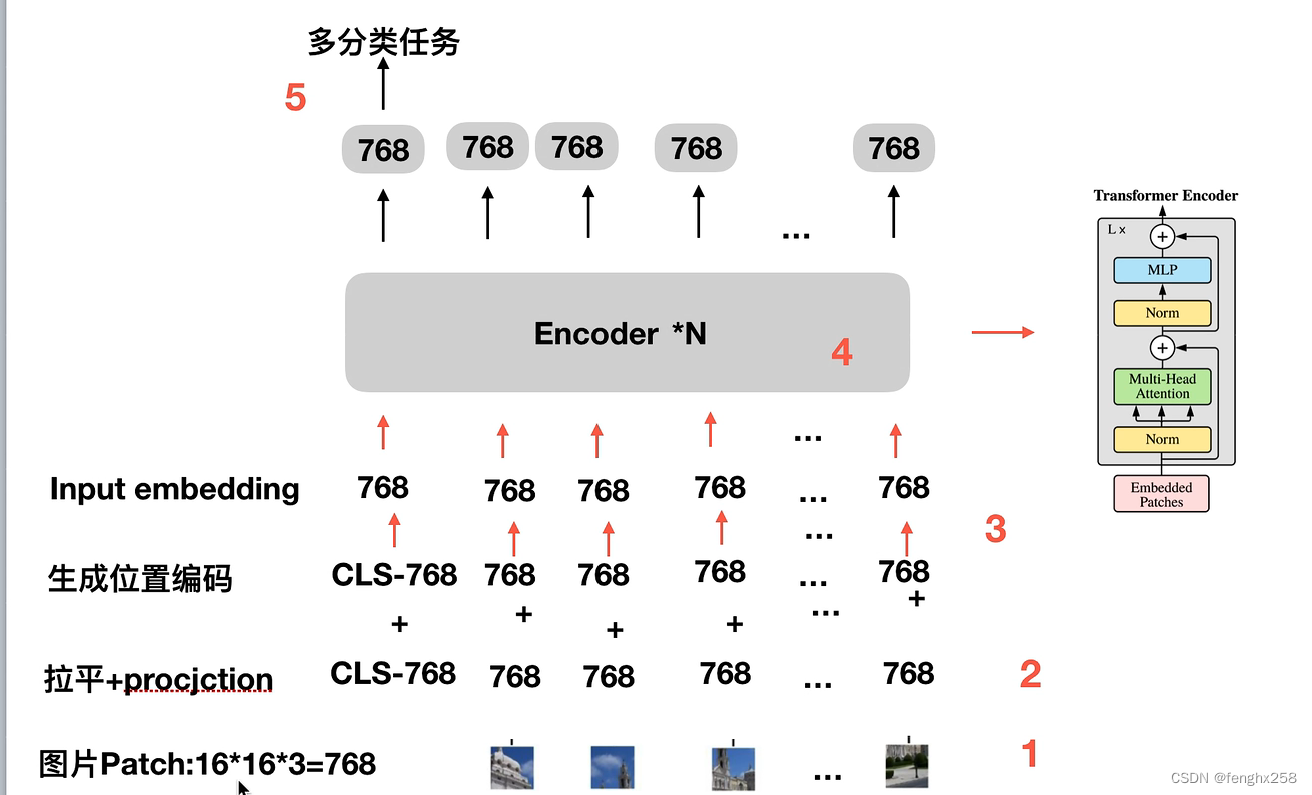
VIT(Vision Transformer)学习(一)- 基础模型理解
如果想了解细一点,可以直接照着第二个链接学习,第二个有哔哩哔哩和csdn,而且讲的更细
如果粗略了解,可以跟着第一个学习
VIT (Vision Transformer) 模型论文代码(源码)从零详细解读,看不懂来打我_哔哩哔哩_bilibili…

由浅到深 : Self-Attention (自注意力机制)
Self-Attention
看到下面的第一个saw是动词,第二个saw是名词。 因为第一个saw和第二个saw在形式上没有任何差别。如果任务是进行词性的判断,把上面的词直接输入给神经网络,那么它肯定不能够正确分析。 想要正确分析词性,那么该…
「解析」Attention机制
Attention函数的本质可以被描述为一个 Query 到 Key-Value对 的映射,这个映射的目的:为了给重要的部分分配更多的概率权重。
计算过程主要分为以下三步:
通过点乘、加法等其他办法计算 Q:query 和 每个K:key 之间的相似度 s i m ( Q , K i…
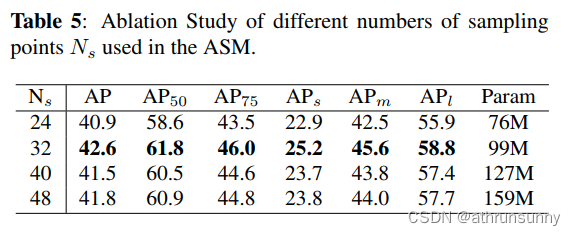
FoLR:Focus on Local Regions for Query-based Object Detection论文学习笔记
论文地址:https://arxiv.org/abs/2310.06470 自从DETR问询式检测器首次亮相以来,基于查询的方法在目标检测中引起了广泛关注。然而,这些方法面临着收敛速度慢和性能亚优等挑战。值得注意的是,在目标检测中,自注意力机制…
Transformer模型 | iTransformer时序预测
Transformer 模型在自然语言处理和计算机视觉领域取得了巨大的成功,并成为了基础模型。然而,最近一些研究开始质疑基于Transformer的时间序列预测模型的有效性。这些模型通常将同一时间戳的多个变量嵌入到不可区分的通道中,并在这些时间标记上应用注意力机制来捕捉时间依赖关…
人工智能三要素之算法Transformer
1. 人工智能三要数之算法Transformer
人工智能的三个要素是算法、数据和计算资源。Transformer 模型作为一种机器学习算法,可以应用于人工智能系统中的数据处理和建模任务。 算法: Transformer 是一种基于自注意力机制的神经网络模型,用于处理序列数据的…
注意力机制、Transformer模型、生成式模型、目标检测算法、图神经网络、强化学习、深度学习模型可解释性与可视化方法等详解
采用“理论讲解案例实战动手实操讨论互动”相结合的方式,抽丝剥茧、深入浅出讲解注意力机制、Transformer模型(BERT、GPT-1/2/3/3.5/4、DETR、ViT、Swin Transformer等)、生成式模型(变分自编码器VAE、生成式对抗网络GAN、扩散模型…
transformer模型训练结构解析(加深理解)
运行项目的一些感受: 很多时候,一个整体的深度学习项目的程序的执行流程是需要理一理的,往往是多个模块层层包含嵌套,然后执行的顺序也是在多个python功能模块间跳转,有时候在某个程序文件里的短短一行代码(…
LangChain+LLM实战---BERT主要的创新之处和注意力机制中的QKV
BERT主要的创新之处
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,由Google在2018年提出。它的创新之处主要包括以下几个方面:
双向性(Bidirectional&…
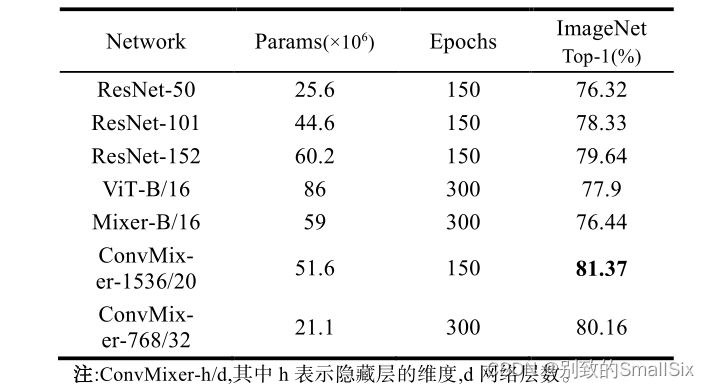
Transformer在计算机视觉领域的研究综述
论文地址:https://kns.cnki.net/kcms/detail/11.2127.TP.20221009.1217.003.html
目录
摘 要
1. Transformer 基本结构
1.1 位置编码
(1) 绝对位置编码
(2) 相对位置编码
1.2 自注意力机制
(1) 多头注意力
(2) 局部注意力
(3) 稀疏注意力机制
1.3 前馈神…
[论文阅读]Ghost-free High Dynamic Range Imaging with Context-aware Transformer
多帧高动态范围成像(High Dynamic Range Imaging, HDRI/HDR)旨在通过合并多幅不同曝光程度下的低动态范围图像,生成具有更宽动态范围和更逼真细节的图像。如果这些低动态范围图像完全对齐,则可以很好地融合为HDR图像,但…

《Attention Is All You Need》阅读笔记
论文标题
《Attention Is All You Need》
XXX Is All You Need 已经成一个梗了,现在出现了很多叫 XXX Is All You Need 的文章,简直标题党啊,也不写方法,也不写结果,有点理解老师扣论文题目了。
作者
这个作者栏太…

深度学习中Transformer的简单理解
Transformer
网络结构
Transformer也是由编码器和解码器组成的。 每一层Encoder编码器都由很多层构成的,编码器内又是self-attention和前馈网络构成的。Self-attention是用来做加权平均,前馈网络用来组合。 但是decoder有点不同,多了一层En…

【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer
相关博客 【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer 【自然语言处理】【大模型】MPT模型结构源码解析(单机版) 【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版) 【自然语言处理】【大模型】BLOOM模型结构源码解析(…

Transformer模型原理
NLP预训练模型的架构大致可以分为三类:
1. Encoder-Decoder架构(T5),seq2seq模型,RNN、LSTM网络 2. BERT:自编码语言模型,预测文本随机掩码 3. GPT: 自回归语言模型,预测…
入门 transformer 的步骤,也算是 attention is all you need 简介
1. 学习步骤 针对原始论文 attention is all you need 中的翻译业务场景,
第一步,了解词嵌入的概念和大概方法
第二步,针对 attention is all you need 中的算法,先记忆算法的精确数学计算流程,倾向于不求甚解其语言…

Transformer:开源机器学习项目,上千种预训练模型 | 开源日报 No.66
huggingface/transformers
Stars: 113.5k License: Apache-2.0
这个项目是一个名为 Transformers 的开源机器学习项目,它提供了数千种预训练模型,用于在文本、视觉和音频等不同领域执行任务。该项目主要功能包括:
文本处理:支持…
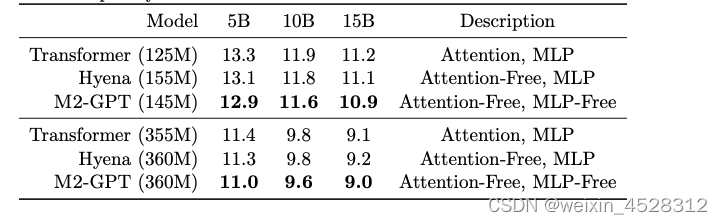
Monarch Mixer:一种性能比Transformer更强的网络架构
六年前,谷歌团队在arXiv上发表了革命性的论文《Attention is all you need》。作为一种优势的机器学习网络架构,Transformer技术迅速席卷全球。Transformer一直是现代基础模型背后的主力架构,并且在不同的应用程序中取得了令人印象深刻的成功…
pandas教程:Interacting with Web APIs API和数据库的交互
文章目录 6.3 Interacting with Web APIs (网络相关的API交互)6.4 Interacting with Databases(与数据库的交互) 6.3 Interacting with Web APIs (网络相关的API交互)
很多网站都有公开的API,通过JSON等格式提供数据流。有很多方法可以访问这些API,这里…

MobileViT v3论文超详细解读(翻译+精读)
前言
今天读一下MobileViT v3的论文《MOBILEVITV3: MOBILE-FRIENDLY VISION TRANS- FORMER WITH SIMPLE AND EFFECTIVE FUSION OF LOCAL, GLOBAL AND INPUT FEATURES》这篇论文的实验部分写得还是很不错的,很值得我们借鉴。 论文原文: https://arxiv.…
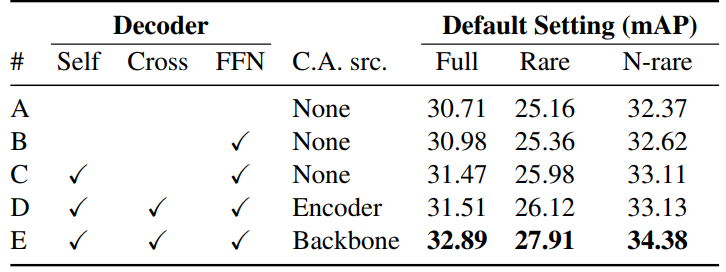
ICCV 2023|PViC:构建交互谓词视觉上下文,高效提升HOI Transformer检测性能
文章链接:https://arxiv.org/abs/2308.06202 代码仓库:https://github.com/fredzzhang/pvic 在今年的计算机视觉顶会上,基于视觉Transformer(ViT)的工作仍然占有非常重要的地位。目前最受研究者青睐的,莫过…
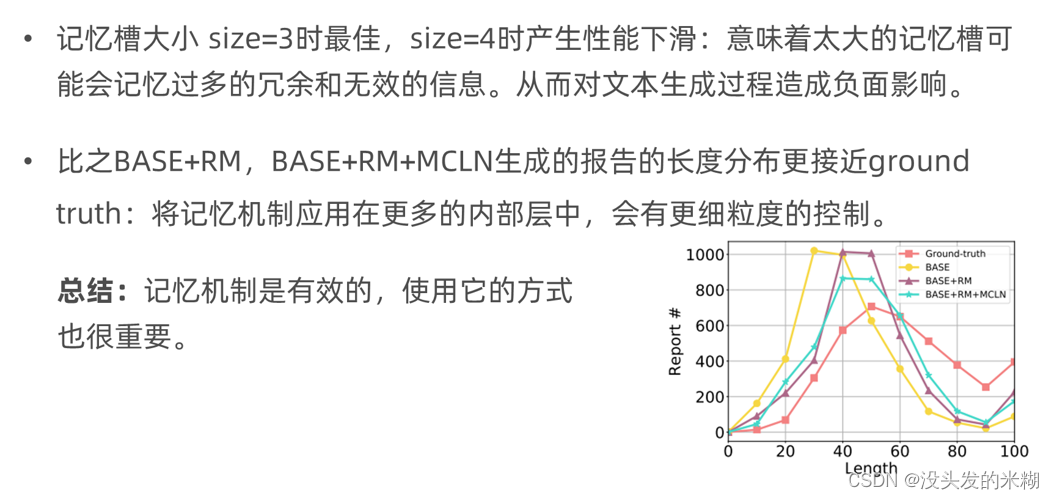
【论文阅读】Generating Radiology Reports via Memory-driven Transformer (EMNLP 2020)
资料链接
论文原文:https://arxiv.org/pdf/2010.16056v2.pdf 代码链接(含数据集):https://github.com/cuhksz-nlp/R2Gen/
背景与动机 这篇文章的标题是“Generating Radiology Reports via Memory-driven Transformer”…
RT-DETR代码学习笔记(DETRs Beat YOLOs on Real-time Object Detection)
论文地址:https://arxiv.org/abs/2304.08069 代码地址:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite 基于Transformer的端到端检测器(DETR)已经取…

transfomer模型——简介,代码实现,重要模块解读,源码,官方
一、什么是transfomer
Transformer是一种基于注意力机制(attention mechanism)的神经网络架构,最初由Vaswani等人在论文《Attention Is All You Need》中提出。它在自然语言处理(NLP)领域取得了巨大成功,特…
邻里注意Transformer(CVPR2023)
Neighborhood Attention Transformer 摘要1、介绍2、相关工作2.1 新的卷积基线 3、方法3.1 邻居注意力3.2 Tiled NA and NATTEN3.3 邻居注意力Transformer 4、结论 代码
摘要
我们提出邻居注意力(NA),第一个有效和可伸缩的滑动窗口的视觉注意机制。 NA是一种像素级…

Accelerate 0.24.0文档 二:DeepSpeed集成
文章目录 一、 DeepSpeed简介二、DeepSpeed集成(Accelerate 0.24.0)2.1 DeepSpeed安装2.2 Accelerate DeepSpeed Plugin2.2.1 ZeRO Stage-22.2.2 ZeRO Stage-3 with CPU Offload2.2.3 accelerate launch参数 2.3 DeepSpeed Config File2.3.1 ZeRO Stage-…

Transformer中WordPiece/BPE等不同编码方式详解以及优缺点
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…

Decoder-Only、Encoder-Only和Encoder-Decoder架构的模型区别、优缺点以及使用其架构的模型示例
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…

SpectralGPT: Spectral Foundation Model 论文翻译1
遥感领域的通用大模型 2023.11.13在CVPR发表
原文地址:[2311.07113] SpectralGPT: Spectral Foundation Model (arxiv.org)
摘要
基础模型最近引起了人们的极大关注,因为它有可能以一种自我监督的方式彻底改变视觉表征学习领域。虽然大多数基础模型…
文档向量化工具(二):text2vec介绍
目录
前言
text2vec开源项目
核心能力
文本向量表示模型
本地试用
安装依赖
下载模型到本地(如果你的网络能直接从huggingface上拉取文件,可跳过)
运行试验代码 前言 在上一篇文章中介绍了,如何从不同格式的文件里提取…
详解Transformer在时序预测中的Encoder和Decoder过程:以负荷预测为例
目录 I. 前言II. Transformer2.1 Encode2.2 Decode2.2.1 Teacher Forcing训练2.2.2 测试 III. 实验结果 I. 前言
前面已经写了很多关于时间序列预测的文章:
深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)PyTorch搭建LSTM实现…
ViT Vision Transformer超详细解析,网络构建,可视化,数据预处理,全流程实例教程
关于ViT的分析和教程,网上又虚又空的东西比较多,本文通过一个实例,将ViT全解析。
包括三部分内容,网络构建;orchview.draw_graph 将网络每一层的结构与输入输出可视化;数据预处理。附完整代码
网络构建
…
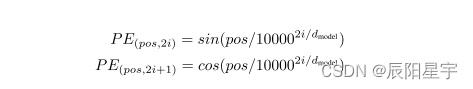
【Transformer从零开始代码实现】(一)输入部件:embedding+positionalEncoding
Transformer总架构图 输入相关组件
输入部分:
源文本嵌入层位置编码器目标文本嵌入层位置编码器
(1)Embedding
首先,需要对输入的内容进行向量化。
1)先导示例
nn.Embedding示例:
# 10代表嵌入的数…
4.Swin Transformer目标检测——训练数据集
1.centos7 安装显卡驱动、cuda、cudnn-CSDN博客
2.安装conda python库-CSDN博客
3.Cenots Swin-Transformer-Object-Detection环境配置-CSDN博客
步骤1:准备待训练的coco数据集
下载地址:https://download.csdn.net/download/malingyu/88519420
htt…

使用双动态令牌混合器学习全局和局部动态以进行视觉识别
TransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Visual Recognition 1、问题与解决2、引言3、方法3.1 双动态令牌混合器(D- Mixer)3.2 IDConv(Input-dependent Depthwise Convolution)3.3 Overlapping Spatial Reduction Attention …
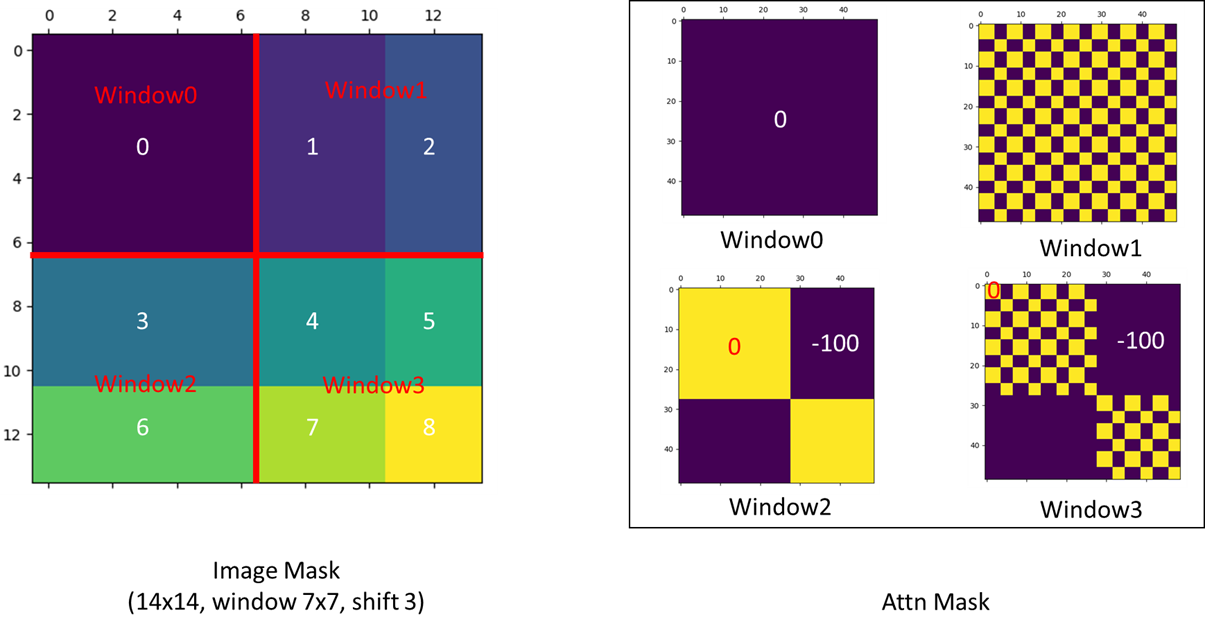
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》阅读笔记
论文标题
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》
Swin 这个词貌似来自后面的 Shifted WindowsShifted Windows:移动窗口Hierarchical:分层
作者
微软亚洲研究院出品
初读
摘要 提出 Swin Transformer 可以…
基于Transformer架构的ChatGPT:三步带你了解它的工作原理
作者:Insist-- 个人主页:insist--个人主页 梦想从未散场,传奇永不落幕,博主会持续更新优质网络知识、Python知识、Linux知识以及各种小技巧,愿你我共同在CSDN进步 目录
一、Transformer架构
1. 自注意力层
2. 前馈神…
Transformer 模型设计的灵感
Transformer 模型的设计确实是通过深刻理解序列处理和注意力机制的基础上,结合了并行计算的优势,取得了显著的性能提升。以下是一些关于 Transformer 模型设计灵感的要点: 对序列处理的重新思考: 传统的序列到序列模型,…
Python电能质量扰动信号分类(三)基于Transformer的一维信号分类模型
目录
引言
1 数据集制作与加载
1.1 导入数据
1.2 制作数据集
2 Transformer分类模型和超参数选取
2.1 定义Transformer分类模型
2.2 定义模型参数
3 Transformer模型训练与评估
3.1 模型训练
3.2 模型评估
代码、数据如下: 往期精彩内容:
电…
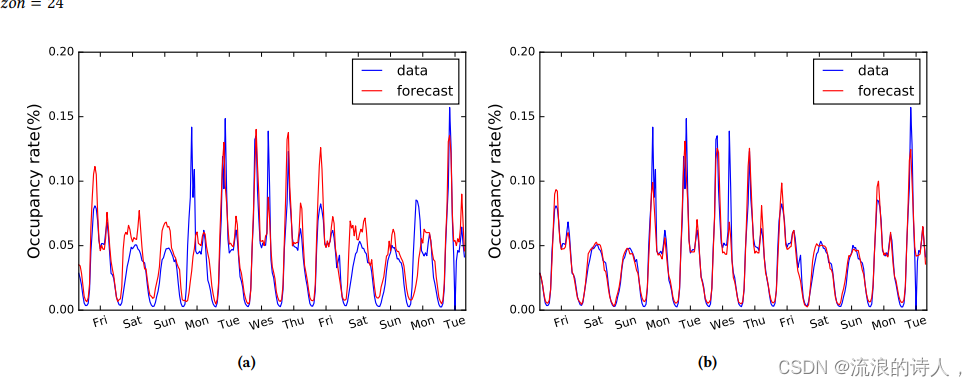
Modeling Long- and Short-Term Temporal Patterns with DeepNeural Networks
This paper was pulished at SIGIR’18, July 2018, Ann Arbor, MI, USA
一、简介
LSTNet是一种用于时间序列预测的深度学习模型,其全称为Long- and Short-term Time-series Networks。LSTNet结合了长短期记忆网络(LSTM)和一维卷积神经网络…

RT-DETR算法优化改进:Backbone改进 | Next-vit,用于现实工业场景的下一代视觉 Transformer
💡💡💡本文独家改进:Next-ViT助力RT-DETR ,替换backbone,具有部署友好机制的强大卷积块和变换块,即NCB和NTB。Next-ViT堆栈NCB和NTB 构建先进的CNN-Transformer混合架构。
推荐指数:五星
RT-DETR魔术师专栏介绍:
https://blog.csdn.net/m0_63774211/category_12…
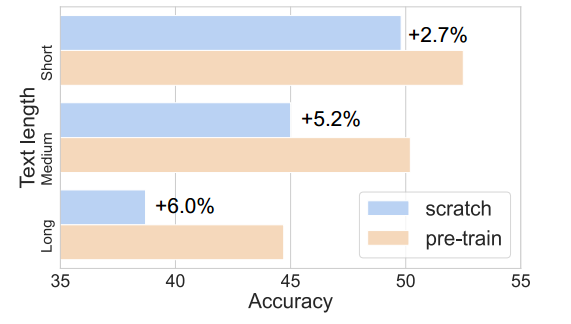
ICCV 23丨3D-VisTA:用于 3D 视觉和文本对齐的预训练Transformer
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://arxiv.org/abs/2308.04352
开源代码:http://3d-vista.github.io
摘要:
3D视觉语言标定(3D-VL)是一个新兴领域,旨在将…
使用 Hugging Face Transformer 微调 BERT
微调 BERT有助于将其语言理解能力扩展到更新的文本领域。BERT 的与众不同之处在于它能够掌握句子的上下文关系,理解每个单词相对于其邻居的含义。我们将使用 Hugging Face Transformers 训练 BERT,还将教 BERT 分析 Arxiv 的摘要并将其分类为 11 个类别之一。 为什么微调 BER…
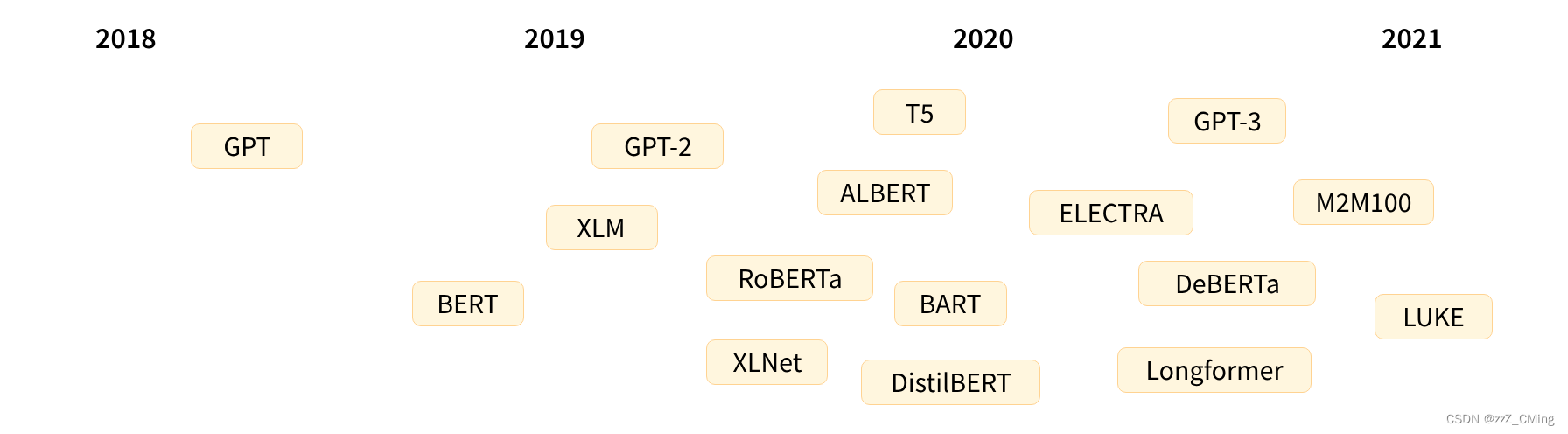
transformer学习资料
一、NLP 自然语言处理
NLP 是机器学习在语言学领域的研究,专注于理解与人类语言相关的一切。NLP 的目标不仅是要理解每个单独的单词含义,而且也要理解这些单词与之相关联的上下文之间的意思。
常见的NLP 任务列表:
对整句的分类࿱…

SpectralGPT: Spectral Foundation Model 论文翻译2
遥感领域的通用大模型 2023.11.13在CVPR发表
原文地址:[2311.07113] SpectralGPT: Spectral Foundation Model (arxiv.org)
实验
在本节中,我们将严格评估我们的SpectralGPT模型的性能,并对其进行基准测试SOTA基础模型:ResN…
【nlp】3.3 Transformer论文复现:2. 编码器部分(掩码张量、多头注意力机制、前馈全连接层)
Transformer论文复现:2. 编码器部分(掩码张量、多头注意力机制、前馈全连接层) 2 编码器复现2.1 编码器介绍2.2 掩码张量2.2.1 掩码张量介绍2.2.2 掩码张量的作用2.2.3 生成掩码张量的代码实现2.2.4 掩码张量的可视化2.2.5 掩码张量总结2.3 注意力机制2.3.1 注意力计算规则的…
【nlp】3.4 Transformer论文复现:2. 编码器部分(规范化层、子层连接结构、编码器层)
3.4 Transformer论文复现:2. 编码器部分(规范化层、子层连接结构、编码器层) 2.6 规范化层2.6.1 规范化层的作用2.6.2 规范化层的代码实现2.6.3 规范化层总结2.7 子层连接结构2.7.1 子层连接结构2.7.2 子层连接结构的代码实现2.7.3 子层连接结构总结2.8 编码器层2.8.1 编码器…
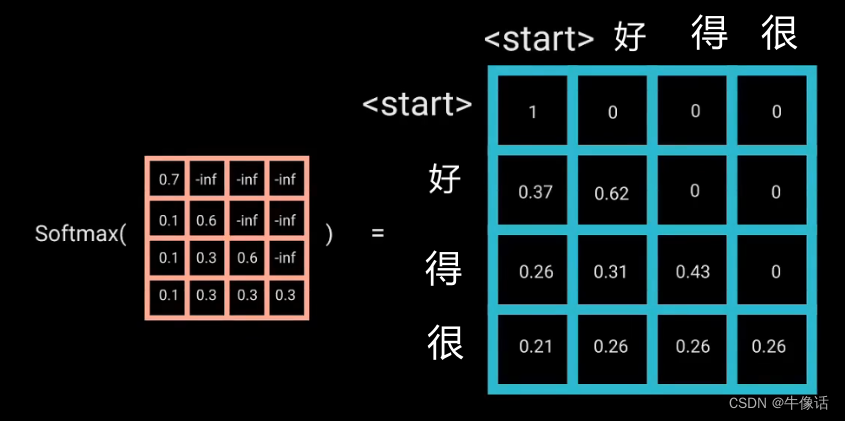
Transformer——decoder
上一篇文章,我们介绍了encoder,这篇文章我们将要介绍decoder Transformer-encoder
decoder结构: 如果看过上一篇文章的同学,肯定对decoder的结构不陌生,从上面框中可以明显的看出: 每个Decoder Block有两个…
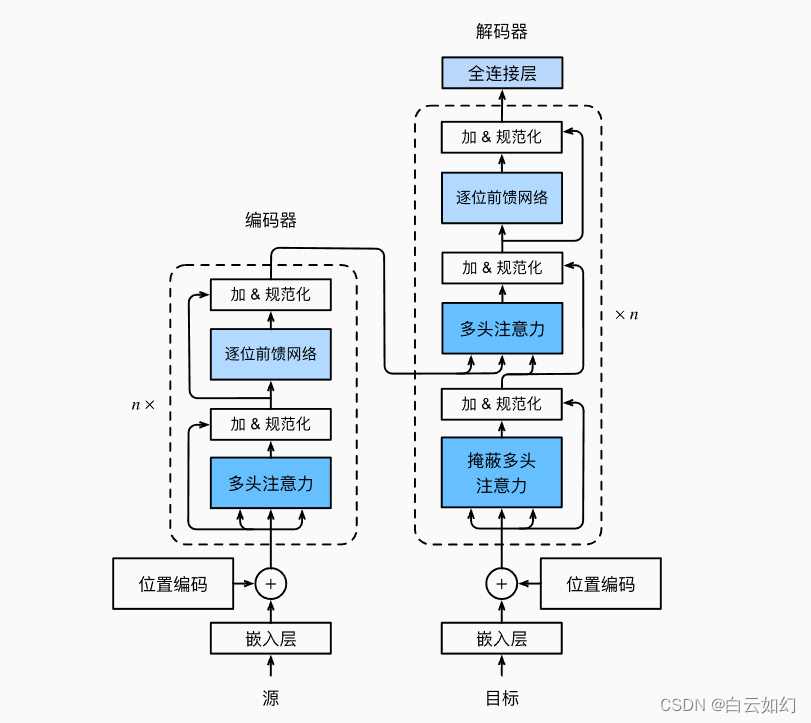
人工智能-注意力机制之Transformer
Transformer
比较了卷积神经网络(CNN)、循环神经网络(RNN)和自注意力(self-attention)。值得注意的是,自注意力同时具有并行计算和最短的最大路径长度这两个优势。因此,使用自注意力…

计算机视觉算法——基于Transformer的目标检测(DN DETR / DINO / Sparser DETR / Lite DETR)
计算机视觉算法——基于Transformer的目标检测(DN DETR / DINO) 计算机视觉算法——基于Transformer的目标检测(DN DETR / DINO)1. DN DETR1.1 Stablize Hungarian Matching1.2 Denoising1.3 Attention Mask 2. DINO2.1 Contrasti…

RAM++(recognize anything++)—— 论文详解
一、概述
1、是什么 RAM(RAM plus plus)论文全称 《Open-Set Image Tagging with Multi-Grained Text Supervision》。区别于图像领域常见的分类、检测、分割,他是标记任务——多标签分类任务(一张图片命中一个类别)&…
深度学习之图像分类(十五)DINAT: Dilated Neighborhood Attention Transformer理论精简摘要(二)
Dilated Neighborhood Attention Transformer摘要 局部注意力机制:例如滑动窗口Neighborhood Attention(NA)或Swin Transformer的Shifted Window Self Attention。
优点:尽管在降低自注意力二次复杂性方面表现出色,
…
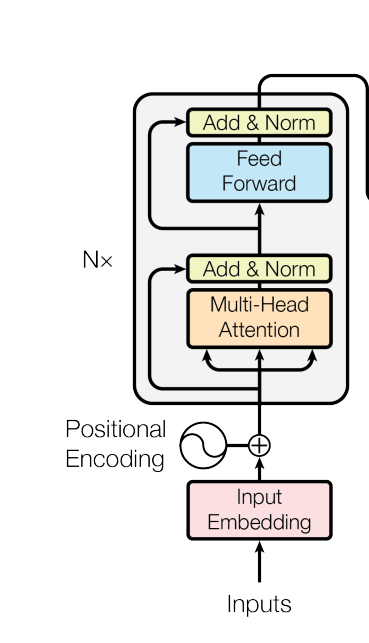
transformer训练与推理
以下transformer基于中译英任务 数据集原本的目标语言标签dec添加完padding后, 如果在dec前面加一个S构成了dec_input,而如果在dec后面加一个E构成了dec_output(输出的标签)
attention
有两种,self attention(encoder里面的是源语言输入句子…
![[论文阅读]VoxSet——Voxel Set Transformer](https://img-blog.csdnimg.cn/direct/3ac5184eebf3409ab1b15a933c212f63.png)
[论文阅读]VoxSet——Voxel Set Transformer
VoxSet
Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds 论文网址:VoxSet 论文代码:VoxSet
简读论文
这篇论文提出了一个称为Voxel Set Transformer(VoxSeT)的3D目标检测模型,主要有以下几个亮点: 提出了基于…
ros来保存图像和保存记录视频的方法---gmsl相机保存视频和图片
1,保存图片
rosrun image_view image_view image:=/myimg_topic这个命令只是用来查看图像的,它并不会保存图像。如果你想要保存图像,你需要使用image_saver节点,并指定保存路径。例如: 下面指令就可以了,可以用
rosrun image_view image_saver image:=/myimg_topic _fi…
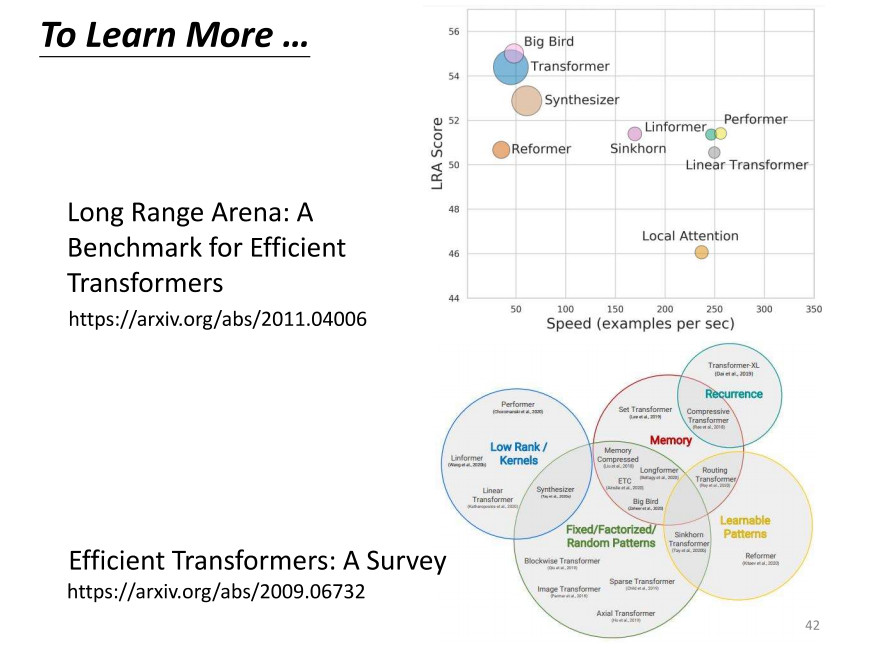
注意力机制及Transformer-3GPT版
#pic_center R 1 R_1 R1 R 2 R^2 R2 目录 知识框架No.1 自注意力机制(self-attention)一、输入的种类以及表示1、输入是a vector2、输入是a set of vectors(一段文字)3、输入是a set of vectors(一段音频)4、输入是a set of vectors(一段图谱)5、输入是a set of vectors(一个…
【模型报错记录】‘PromptForGeneration‘ object has no attribute ‘can_generate‘
通过这个连接中的方法解决: “PromptForGeneration”对象没有属性“can_generate” 期刊 #277 thunlp/OpenPrompt GitHub的 问题描述:在使用model.generate() 的时候报错:PromptForGeneration object has no attribute can_generate 解决方法…

SpectralGPT: Spectral Foundation Model 论文翻译3
遥感领域的通用大模型 2023.11.13在CVPR发表
原文地址:[2311.07113] SpectralGPT: Spectral Foundation Model (arxiv.org)
E.消融研究 在预训练阶段,我们对可能影响下游任务表现的各种因素进行了全面研究。这些因素包括掩蔽比、ViT patch大小、数据规…
Swin Transformer实战图像分类(Windows下,无需用到Conda,亲测有效)
目录
前言
一、从官网拿到源码,然后配置自己缺少的环境。
针对可能遇到的错误:
二、数据集获取与处理
2.1 数据集下载
2.2 数据集处理
三、下载预训练权重
四、修改部分参数配置
4.1 修改config.py
4.2 修改build.py
4.3 修改units.py
4.4 修…
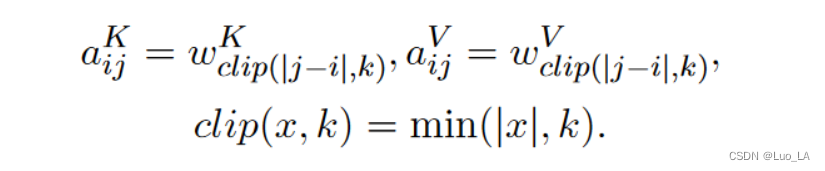
【论文笔记】A Transformer-based Approach for Source Code Summarization
A Transformer-based Approach for Source Code Summarization 1. Introduction2. Approach2.1 ArchitectureSelf-AttentionCopy Attention 2.2 Position Representations编码绝对位置编码成对关系 1. Introduction
生成描述程序功能的可读摘要称为源代码摘要。在此任务中&…
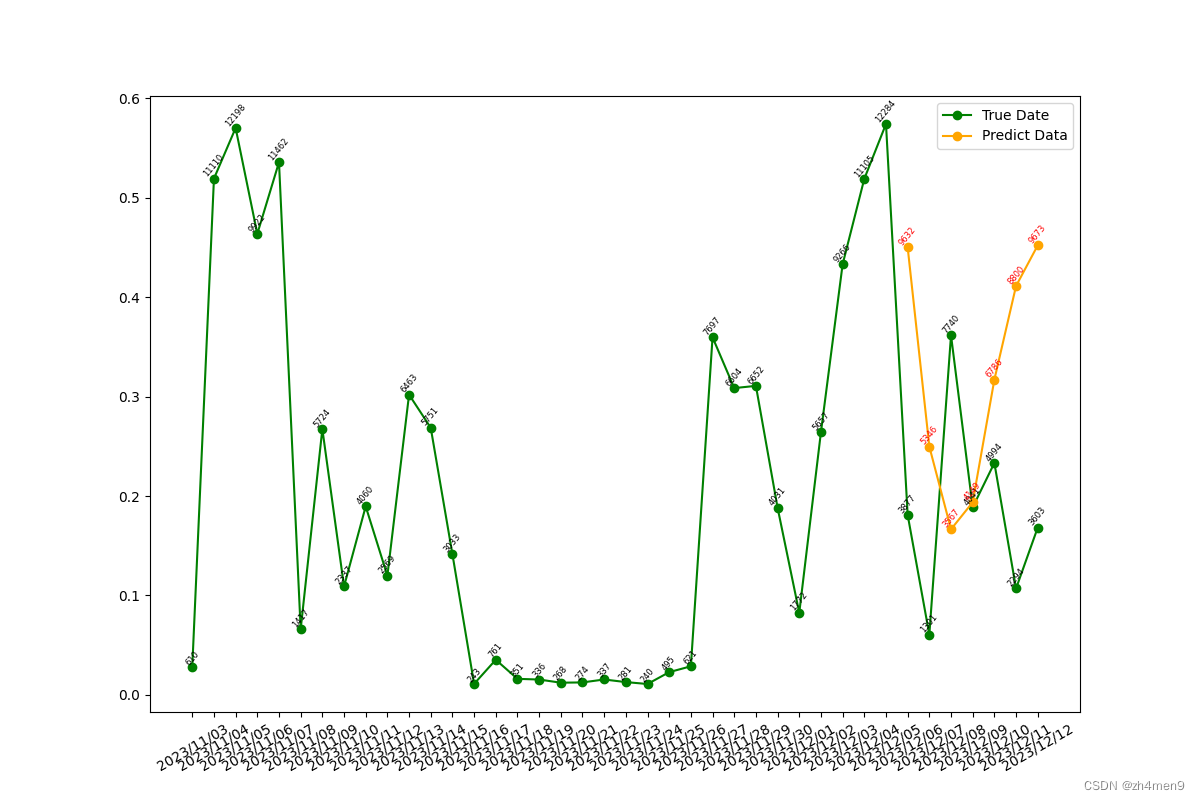
Transformer预测销售量
🤖 专栏《人工智能》 📖 博客说明: 本专栏记录我个人学习和实践人工智能相关算法的心得与内容,一同探索人工智能的奇妙世界吧! 🚀 零、说明
心血来潮,想利用Transformer做一个销售量预测的内容…
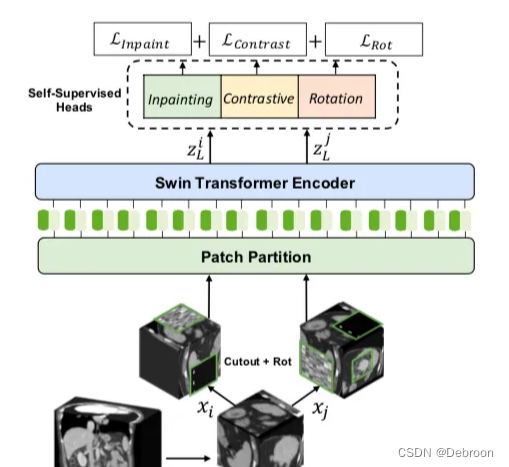
Swin UNetR:把 UNet 和 Swin Transformer 结合
Swin UNetR:把 UNet 和 Swin Transformer 结合 网络结构使用指南 前置知识:Swin Transformer:将卷积网络和 Transformer 结合 Swin UNetR 结合 Swin Transformer 的上下文建模能力和 U-Net 的像素级别预测能力,提高语义分割任务的…
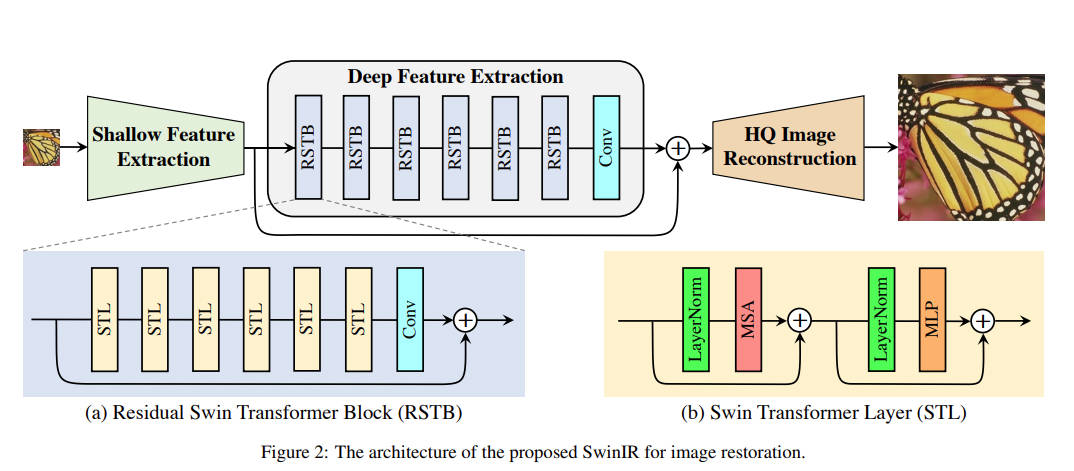
SwinIR: Image Restoration Using Swin Transformer
SwinIR
简介
论文地址:SwinIR: Image Restoration Using Swin Transformer
代码:SwinIR
本文提出了一个基于swin transformer的图像超分模型swinIR。其中SwinIR分为三部分:浅层特征提取、深层特征提取和高质量图像重建模块。
现阶段问…
Python轴承故障诊断 (六)基于EMD-Transformer的故障分类
目录
前言
1 经验模态分解EMD的Python示例
2 轴承故障数据的预处理
2.1 导入数据
2.2 制作数据集和对应标签
2.3 故障数据的EMD分解可视化
2.4 故障数据的EMD分解预处理
3 基于EMD-Transformer的轴承故障诊断分类
3.1 训练数据、测试数据分组,数据分batch …

【经验分享】gemini-pro和gemini-pro-vision使用体验
Gemini Gemini已经对开发者开放了Gemini Pro的使用权限,目前对大家都是免费的,每分钟限制60条,至少这比起CloseAI的每个账户5刀限速1min3条要香的多,目前已于第一时间进行了体验 一句话总结,google很大方,但…

破解密码 LLM(代码LLM如何从 RNN 发展到 Transformer)
舒巴姆阿加瓦尔 一、说明 近年来,随着 Transformer 的引入,语言模型发生了显着的演变,它彻底改变了我们执行日常任务的方式,例如编写电子邮件、创建文档、搜索网络甚至编码方式。随着研究人员在代码智能任务中应用大型语言模型&am…
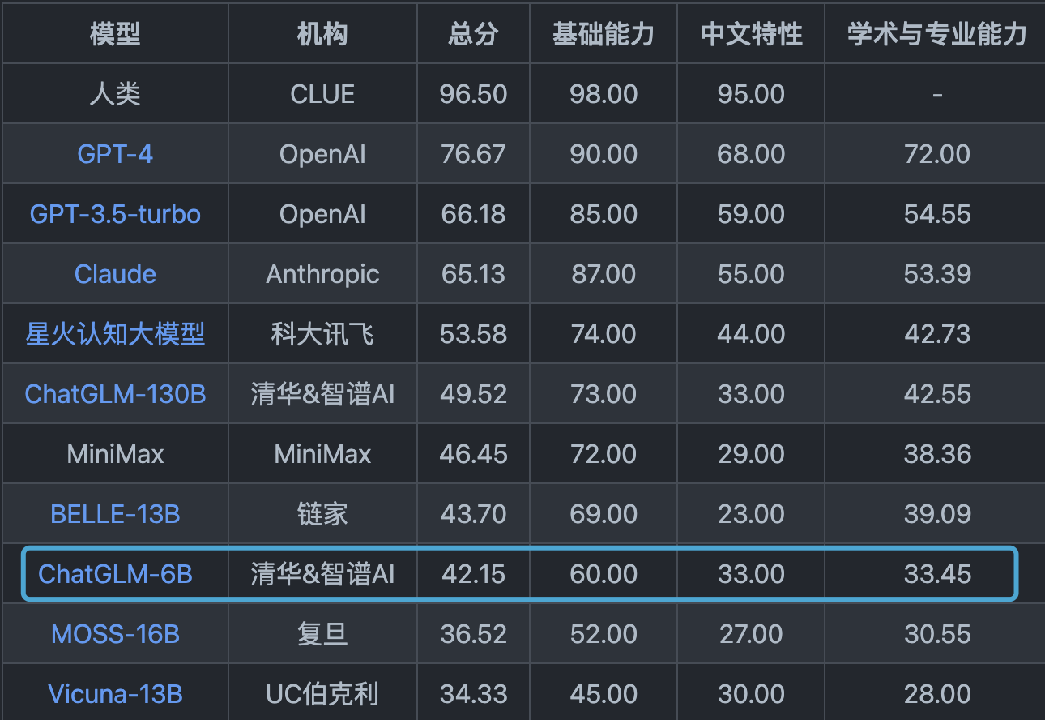
【LLM】大语言模型的前世今生
An Overview of LLMs
LLMs’ status quo
NLP Four Paradigm A timeline of existing large language models 看好OpenAI、Meta 和 LLaMA。
Typical Architectures Casual Decoder eg. GPT3、LLaMA… 在前两篇文章大家也了解到GPT的结构了,在训练模型去预测下一个…

NLP_搭建GPT核心组件Transformer
文章目录 Transformer架构剖析编码器-解码器架构各种注意力的应用Transformer中的自注意力Transformer中的多头自注意力Transformer中的编码器-解码器注意力Transformer中的注意力掩码和因果注意力 编码器的输入和位置编码编码器的内部结构编码器的输出和编码器-解码器的连接解…
NLP_Transformer架构
文章目录 Transformer架构剖析编码器-解码器架构各种注意力的应用Transformer中的自注意力Transformer中的多头自注意力Transformer中的编码器-解码器注意力Transformer中的注意力掩码和因果注意力 编码器的输入和位置编码编码器的内部结构编码器的输出和编码器-解码器的连接解…
Transformer实战-系列教程21:DETR 源码解读8 损失计算:(SetCriterion类)
🚩🚩🚩Transformer实战-系列教程总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 点我下载源码 DETR 算法解读 DETR 源码解读1(项目配置/CocoDetection类/ConvertCocoP…

【LLM】Prompt Engineering
Prompt Engineering
CoTCoT - SCToTGoT
CoT: Chain-of-Thought 通过这样链式的思考,Model输出的结果会更准确 CoT-SC: Self-Consistency Improves Chain of Thought Reasoning in Language Models
往往,我们会使用Greedy decode这样的策略,…
应用Transformer和CNN进行计算机视觉任务各自的优缺点
Transformer 和 CNN(卷积神经网络)是用于计算机视觉任务的两种不同的深度学习架构,各自具有一些优点和局限性。
一、Transformer:
优点:
全局信息关系建模: Transformer 通过自注意力机制(self-attentio…
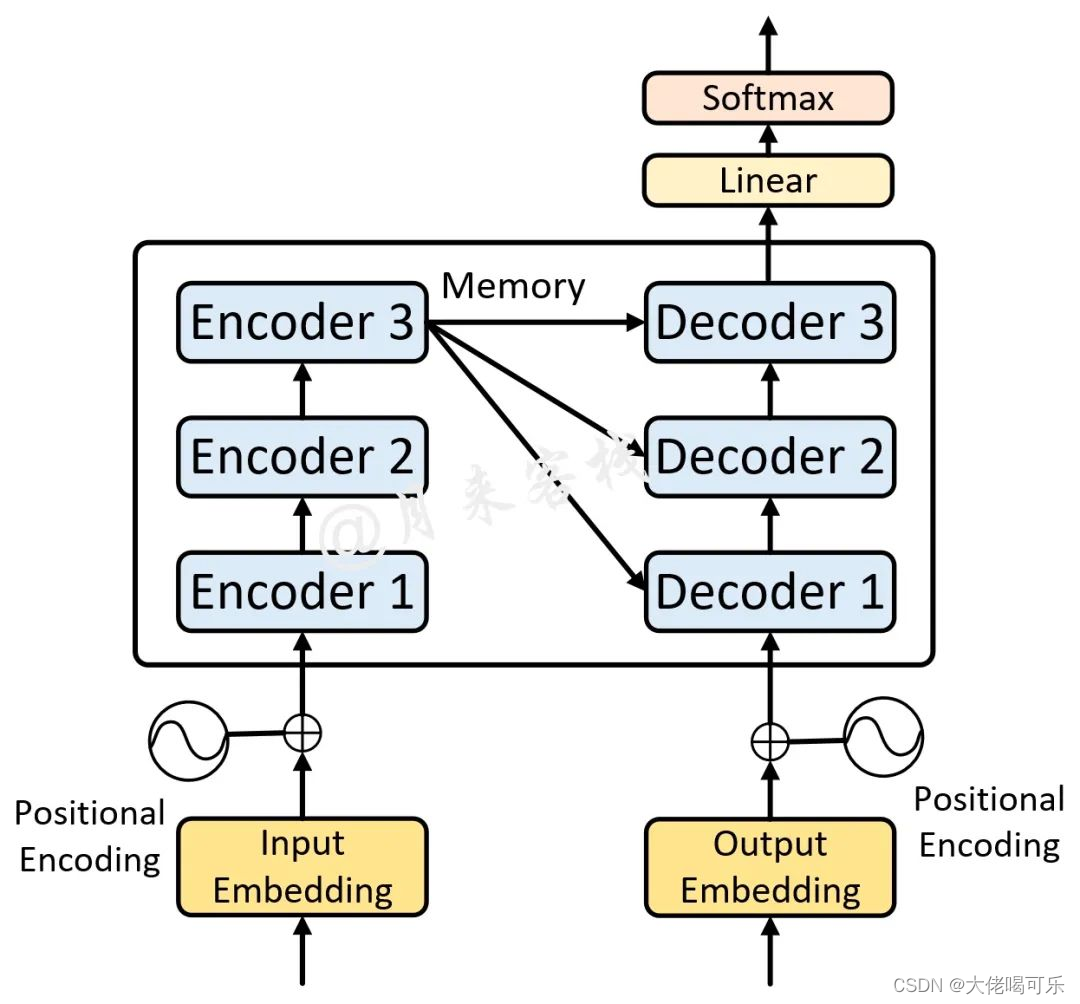
【Transformer框架代码实现】
Transformer Transformer框架注意力机制框架导入必要的库Input Embedding / Out EmbeddingPositional EmbeddingTransformer EmbeddingScaleDotProductAttention(self-attention)MultiHeadAttention 多头注意力机制EncoderLayer 编码层Encoder多层编码块/前馈网络层…
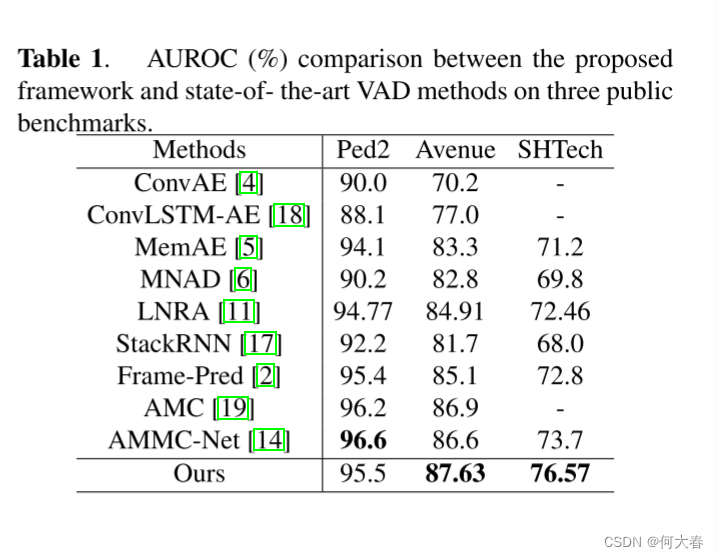
用于无监督视频异常检测的合成伪异常:一种简单有效的基于掩码自动编码器的框架 论文阅读
SYNTHETIC PSEUDO ANOMALIES FOR UNSUPERVISED VIDEO ANOMALY DETECTION: A SIMPLE YET EFFICIENT FRAMEWORK BASED ON MASKED AUTOENCODER ABSTRACT1. INTRODUCTION2. METHODS3. EXPERIMENTS AND RESULTS4. CONCLUSION阅读总结: 论文标题:SYNTHETIC PSE…
transformers生成式对话机器人
生成式对话机器人是一种人工智能技术,它通过学习大量自然语言数据,模拟人类进行开放、连贯和创造性的对话。这种类型的对话系统并不局限于预定义的回答集,而是能够根据上下文动态生成新的回复内容。其核心组件和技术包括:
1、神经…
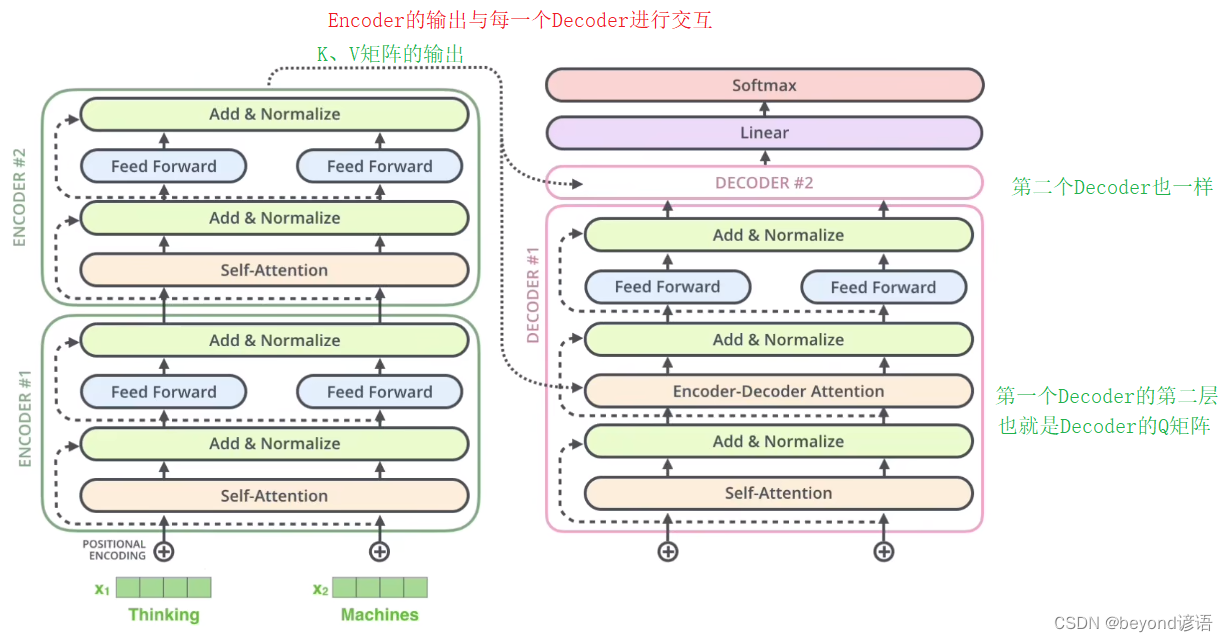
Transformer简略了解
Transformer出自论文:《Attention Is All You Need》 该论文的提出,对RNN循环神经网络产生了冲击,席卷了自然语言处理(NLP)领域,后续的GPT4.0版本也是根据其进行训练优化的
一、Transformer主体架构 可以简化分为Encoders和Decod…
transformer进行文本分析的模型代码
这段代码定义了一个使用Transformer架构的PyTorch神经网络模型。Transformer模型是一种基于注意力机制的神经网络架构,最初由Vaswani等人在论文“Attention is All You Need”中提出。它在自然语言处理任务中被广泛应用,例如机器翻译。
让我们逐步解释这…
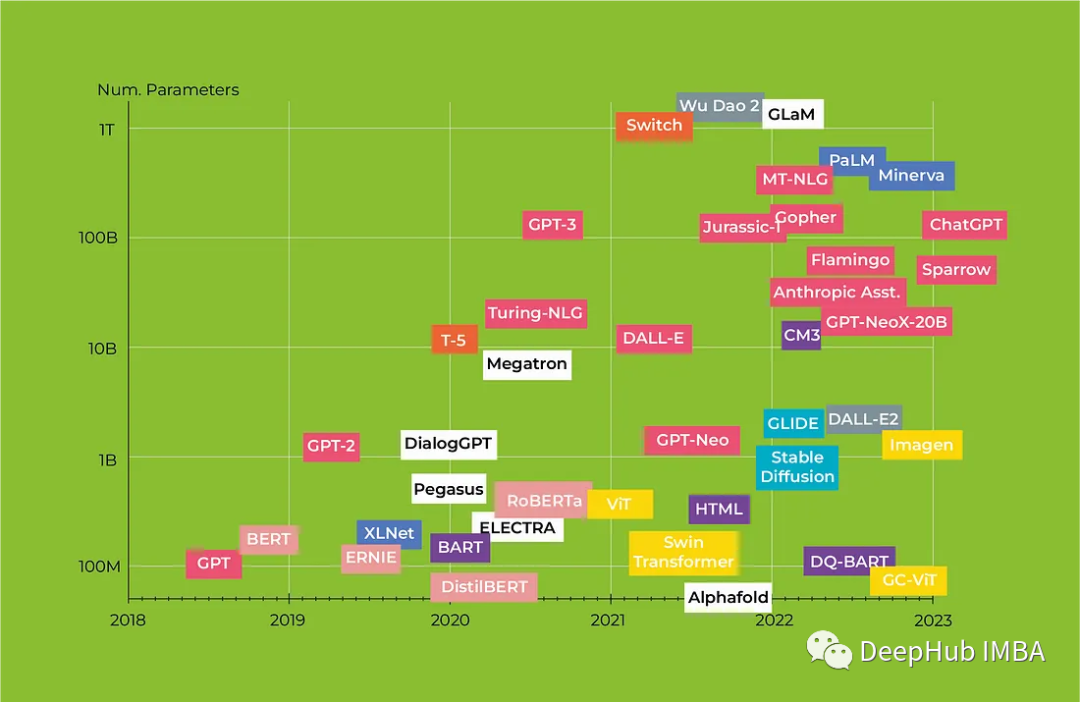
Transformers 2023年度回顾 :从BERT到GPT4
人工智能已成为近年来最受关注的话题之一,由于神经网络的发展,曾经被认为纯粹是科幻小说中的服务现在正在成为现实。从对话代理到媒体内容生成,人工智能正在改变我们与技术互动的方式。特别是机器学习 (ML) 模型在自然语言处理 (NLP) 领域取得…
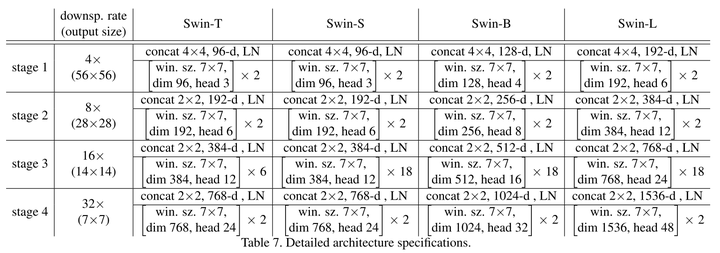
Swin Transformer 学习笔记(附代码)
论文地址:https://arxiv.org/pdf/2103.14030.pdf
代码地址: GitHub - microsoft/Swin-Transformer: This is an official implementation for "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows".
1.是什么&#x…
1、理解Transformer:革新自然语言处理的模型
目录
一、论文题目
二、背景与动机
三、卖点与创新
四、解决的问题
五、具体实现细节
0. Transformer 架构的主要组件
1. 注意力、自注意力(Self-Attention)到多头注意力(Multi-Head Attention)
注意力到底是做什么的&…
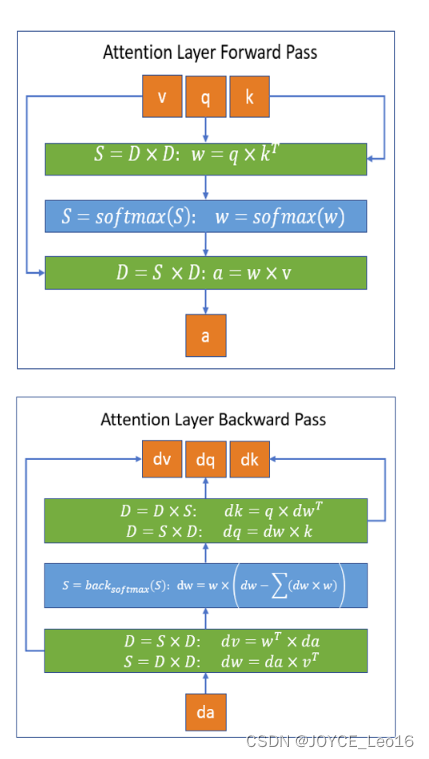
深度学习中的稀疏注意力
稀疏注意力 文章目录 一、稀疏注意力的特点 1. 单头注意力(Single-Head Attention) 2. 多头注意力(Multi-Head Attention) 3. 稀疏注意力(Sparse Attention) 二、稀疏注意力的示意图 三、与Flash Attention…

DETR tensor去除推理过程无用辅助头+fp16部署再次加速+解决转tensorrt 输出全为0问题的新方法
特别说明:参考官方开源的DETR代码、TensorRT官方文档,如有侵权告知删,谢谢。 完整代码、测试脚本、测试图片、模型文件 点击下载
1、转tensorrt 输出全为 0 老问题回顾 在用 TensorRT 部署 DETR 检测模型时遇到:转tensorrt 输出全…
读书笔记:多Transformer的双向编码器表示法(Bert)-3
多Transformer的双向编码器表示法
Bidirectional Encoder Representations from Transformers,即Bert;
第3章 Bert实战
学习如何使用预训练的BERT模型:
如何使用预训练的BERT模型作为特征提取器;探究Hugging Face的Transforme…
Open3D 与 Point Cloud 处理
点云基础3D数据结构点云采集方法点云处理框架点云操作 Open3D基础操作 点云基础
3D数据结构 点云(Point Cloud): 点云是由一组离散的点构成的三维数据集合,每个点都包含了坐标信息 (x, y, z) 、颜色 (RGB)、类别 (cls)、强度值等…
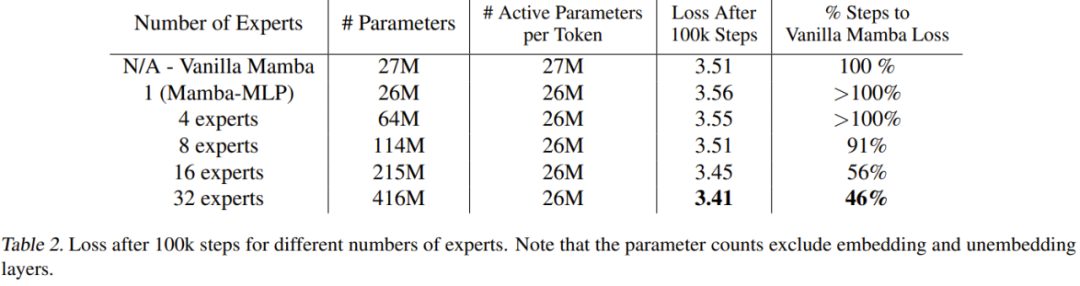
状态空间模型(SSM)是近来一种备受关注的 Transformer 替代技术
状态空间模型(SSM)是近来一种备受关注的 Transformer 替代技术,其优势是能在长上下文任务上实现线性时间的推理、并行化训练和强大的性能。而基于选择性 SSM 和硬件感知型设计的 Mamba 更是表现出色,成为了基于注意力的 Transform…

第二十七章 解读Transformer_车道线检测中的Transformer(车道线感知)
前言 近期参与到了手写AI的车道线检测的学习中去,以此系列笔记记录学习与思考的全过程。车道线检测系列会持续更新,力求完整精炼,引人启示。所需前期知识,可以结合手写AI进行系统的学习。 SE简单实现
class SELayer(nn.Module):d…
Transformer入门学习
摘要:记录一下自己在10月份参加DataWhale组队学习transformer的所得。这篇博客主要关于transformer基本原理的学习和一个输入序列转换的简单demo,并补充了一些transformer在CV领域的variants,希望本次组队学习能帮助自己快速入门,…
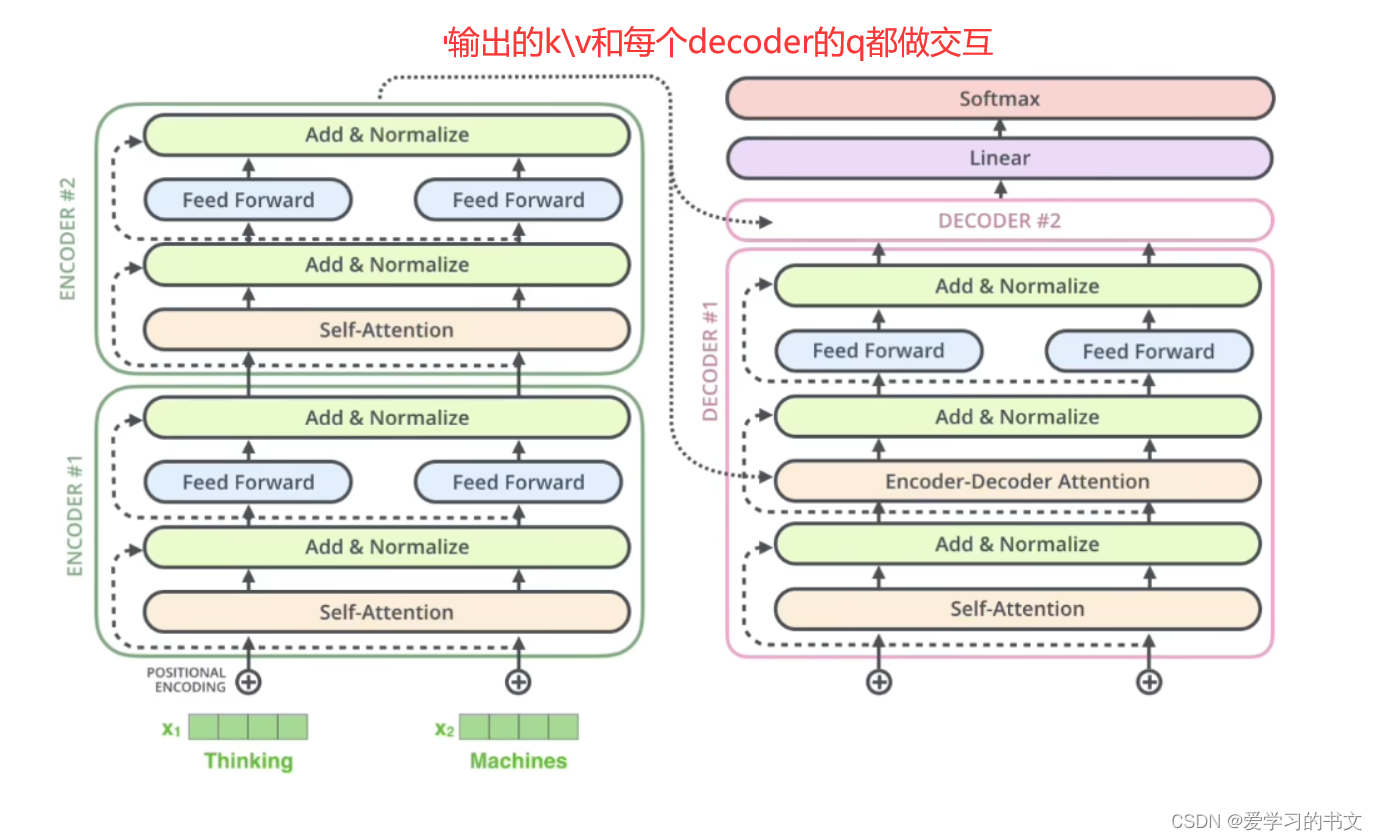
【DASOU视频记录】Transformer从零详细解读
文章目录 来源transformer的全局理解位置编码多头注意力机制残差Batch NormalLayer NormalDecoder 来源
b站链接
transformer的全局理解
输入中文,输出英文 细化容易理解的结构,就是先编码,再解码 进一步细化的结构,就是多个编…

Conformer阅读笔记
论文:《Conformer: Convolution-augmented Transformer for Speech Recognition》
摘要
基于transformer和卷积神经网络cnn的模型在ASR上已经达到了较好的效果,都要优于RNN的效果。Transformer能够捕获长序列的依赖和基于内容的全局交互信息࿰…

Advancing Transformer Transducer for Speech Recognition on Large-Scale Dataset》
本文是观看上海交通大学陈谐老师在《人机语音通信》课程的讲座的笔记,原视频链接,本文参考[3] [4]。
1 Model Overview: Transformer Transducer
语音识别发展背景: 首先是GMM-HMM:混合高斯模型作声学模型,n-gram作为…

Attention is all you need -- 阅读笔记
这篇文章是2017年发表在NIPS会议上的论文,也是Transformer的开山之作。最先应用是在NLP领域的机器翻译任务上,由于其简单的结构、强悍的表现,经过几年的发展,越来越多的领域开始使用基于Transformer的深度学习网络。下面是我自己的…
Transformer和attention资料
(1)注意力的理解心得_注意力机制加在cnn的什么位置_Fly-Pluche的博客-CSDN博客
(2)https://www.zhihu.com/question/291446237/answer/2571450742
(3) 【Attention九层塔】注意力机制的九重理解 - 知乎
(4) 注意力的理解心得 - 掘金
(5)深度学习中的各种注意力机…
LeViT-UNet:transformer 编码器和CNN解码器的有效整合
levi - unet[2]是一种新的医学图像分割架构,它使用transformer 作为编码器,这使得它能够更有效地学习远程依赖关系。levi - unet[2]比传统的U-Nets更快,同时仍然实现了最先进的分割性能。
levi - unet[2]在几个具有挑战性的医学图像分割基准…

动手实现一遍Transformer
最近乘着ChatGpt的东风,关于NLP的研究又一次被推上了风口浪尖。在现阶段的NLP的里程碑中,无论如何无法绕过Transformer。《Attention is all you need》成了每个NLP入门者的必读论文。惭愧的是,我虽然使用过很多基于Transformer的模型&#x…

Attention Free Transformer(AFT)
Attention Free Transformer(AFT)
paper: An Attention Free Transformer
date: 2021-05
org: Apple
1 Motivation
原本基于dot product self attention Transformer的时间复杂度和空间复杂度都很高。提出了一个新的AFT层来降低transformer的计算量。 2 Method
2.1 Multi…

LGFormer:LOCAL TO GLOBAL TRANSFORMER FOR VIDEO BASED 3D HUMAN POSE ESTIMATION
基于视频的三维人体姿态估计的局部到全局Transformer
作者:马海峰 *,陆克 * †,薛健 *,牛泽海 *,高鹏程† * 中国科学院大学工程学院,北京100049 鹏程实验室,深圳518055
来源:202…
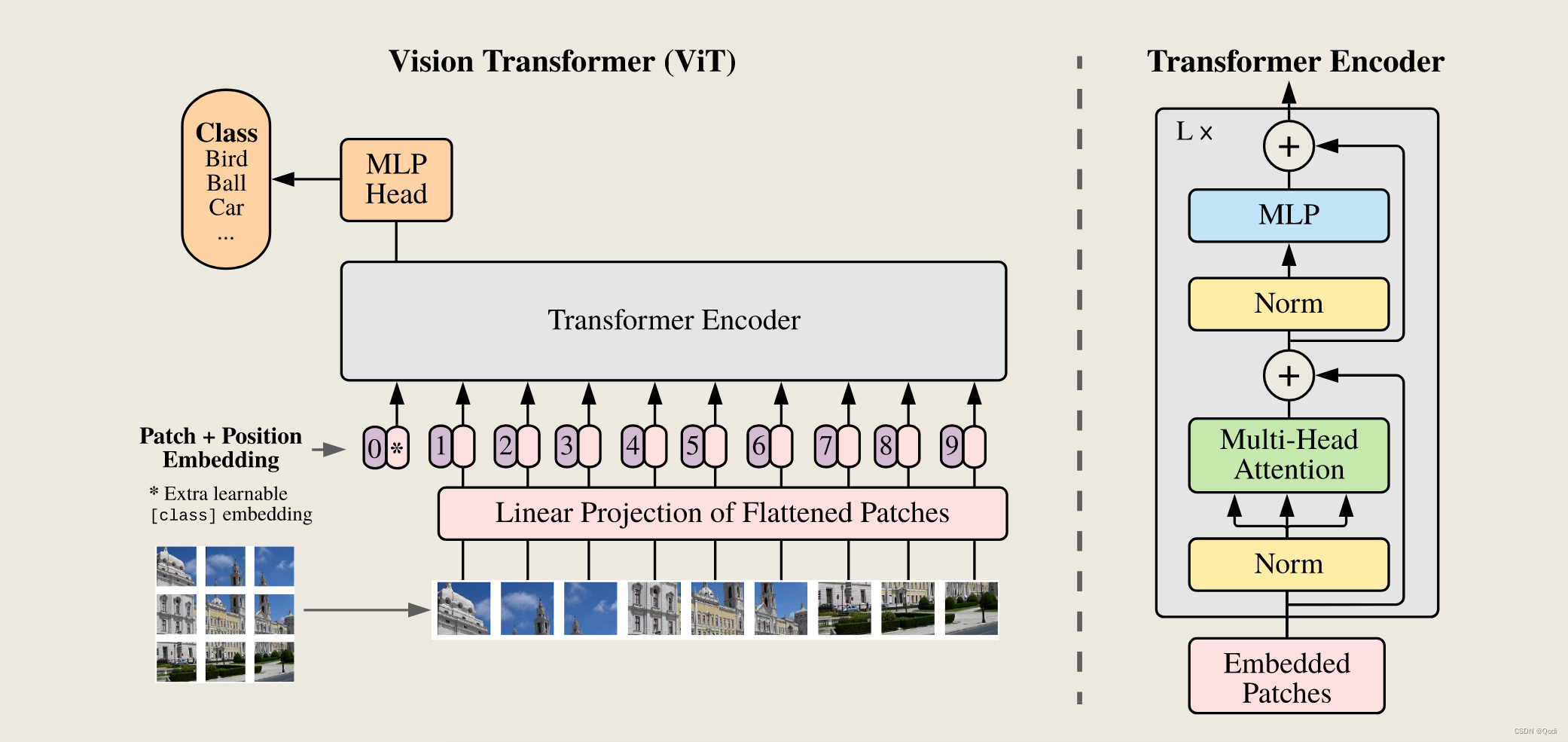
VIT 论文精读 | transformer架构引入CV的开创性工作
目录 1. 背景
2. 方法
2.1 怎么把2D图像变成1D序列输入到transformer中
像素?
先提取特征图?
打成多个patch
2.2 transformer和卷积网络比较
2.3 结构 1. 背景
VIT是基于transformer的在图像分类大放异彩的变体,transformer是VIT的亲…
Transformer的一点理解,附一个简单例子理解attention中的QKV
Transformer用于目标检测的开山之作DETR,论文作者在附录最后放了一段简单的代码便于理解DETR模型。
DETR的backbone用的是resnet-50去掉了最后的AdaptiveAvgPool2d和Linear这两层。
self.backbone nn.Sequential(*list(resnet50(pretrainedTrue).children())[:-2…
机器学习笔记 - 从2D数据合成3D数据
一、3D 数据简介 人们一致认为,从单一角度合成 3D 数据是人类视觉的一项基本功能,这对计算机视觉算法来说极具挑战性。但随着 LiDAR、RGB-D 相机(RealSense、Kinect)和 3D 扫描仪等 3D 传感器的可用性和价格的提高,3D 采集技术的最新进展取得了巨大飞跃。 与广泛使用的 2D…
Transformer预测 | Pytorch实现基于Transformer 的锂电池寿命预测(CALCE数据集)
文章目录 效果一览文章概述模型描述程序设计参考资料效果一览 文章概述 Pytorch实现基于Transformer 的锂电池寿命预测,环境为pytorch 1.8.0,pandas 0.24.2 随着充放电次数的增加,锂电池的性能逐渐下降。电池的性能可以用容量来表示,故寿命预测 (RUL) 可以定义如下: SOH(t…
神经网络算法 —— 一文搞懂Transformer !!
文章目录 前言 一、Transformer的本质 1. Transformer架构 2. Encoder-Decoder(编码器-解码器) 二、Transformer的原理 1. Multi-Head Attention(多头自注意力) 2. Scaled Dot-Product Attention(缩放点积注意力&#…
类ChatGPT逐行代码解读(1/2):从零起步实现Transformer、ChatGLM-6B
前言
最近一直在做类ChatGPT项目的部署 微调,关注比较多的是两个:一个LLaMA,一个ChatGLM,会发现有不少模型是基于这两个模型去做微调的,说到微调,那具体怎么微调呢,因此又详细了解了一下微调代…

DEBERTA: DECODING-ENHANCED BERT WITH DIS- ENTANGLED ATTENTION glue榜首论文解读
一、概览 二、详细内容
abstract a. 两个机制来improve bert和 roberta ⅰ. disentangled attention mechanism ⅱ. enhanced mask decoder b. fine-tuning阶段 ⅰ. virtual adversarial training -> 提升泛化 c. 效果 ⅰ. 对nlu和nlg下游任务,提升都比较大 ⅱ.…

YOLOv8独家改进: Inner-IoU基于辅助边框的IoU损失,高效结合 GIoU, DIoU, CIoU,SIoU 等 | 2023.11
💡💡💡本文独家改进:Inner-IoU引入尺度因子 ratio 控制辅助边框的尺度大小用于计算损失,并与现有的基于 IoU ( GIoU, DIoU, CIoU,SIoU )损失进行有效结合
推荐指数:5颗星 新颖指数:5颗星
💡💡💡Yolov8魔术师,独家首发创新(原创),适用于Yolov5…
关于Vision Transformer的复现其环境配置
安装tqdm库、matplotlib库、fvcore库
tqdm/tqdm: A Fast, Extensible Progress Bar for Python and CLI 使用fvcore计算Pytorch中模型的参数数量以及FLOPs
安装TensorBoard
直接 pip install tensorboard Pytorch 1.9.0 Tensorboard 2.5.0可视化工具使用记录
在Pytorc…
FLatten Transformer:使用聚焦线性注意力的ViT
文章目录 摘要1、简介2、相关工作2.1 Vision Transformer2.2 线性注意力3. 预备知识3.1. 视觉Transformer和自注意力3.2. 线性注意力4. 聚焦线性注意力4.1.聚焦能力4.2. 特征多样性4.3. 聚焦线性注意力模块5. 实验5.1. ImageNet-1K分类5.2. 语义分割5.3. 目标检测5.4. 与其他线…

45 深度学习(九):transformer
文章目录 transformer原理代码的基础准备位置编码Encoder blockmulti-head attentionFeed Forward自定义encoder block Deconder blockEncoderDecodertransformer自定义loss 和 学习率mask生成函数训练翻译 transformer
这边讲一下这几年如日中天的新的seq2seq模式的transform…

Scale- and shift-invariant losses
[Paper]|[研读]|[loss]
Scale and shift-invariant loss 目录
动机
损失函数
结果 动机:
已知:训练过程中,混合多个数据集,能够提高单眼深度估计的效果。但是:数据集之间的不兼容性,如来源不同、未知和…
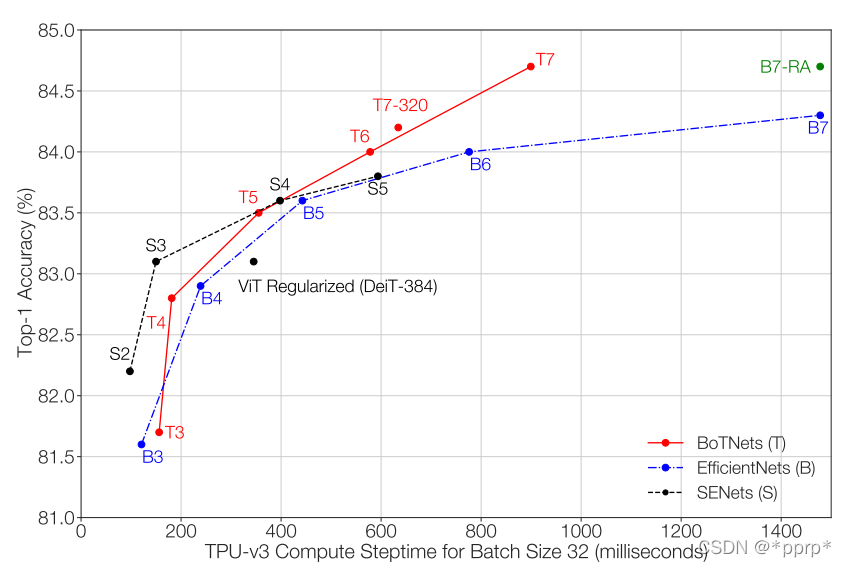
BoTNet:Bottleneck Transformers for Visual Recognition
【GiantPandaCV导语】基于Transformer的骨干网络,同时使用卷积与自注意力机制来保持全局性和局部性。模型在ResNet最后三个BottleNeck中使用了MHSA替换3x3卷积。属于早期的结合CNNTransformer的工作。简单来讲Non-LocalSelf AttentionBottleNeck BoTNet
引言
本文…
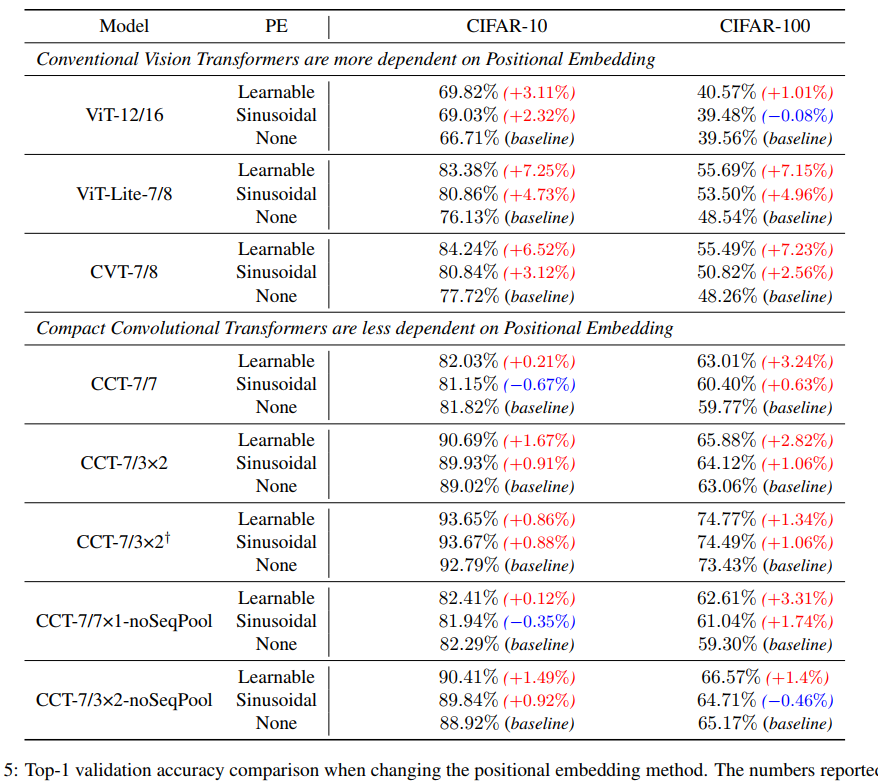
Compact-Transformer:缓解数据不足带来的问题
【GiantPandaCV导语】本文致力于解决ViT在小型数据集上性能不够好的问题,这个问题非常实际,现实情况下如果确实没有大量数据集,同时也没有合适的预训练模型需要从头训练的时候,ViT架构性能是不如CNN架构的。这篇文章实际上并没有引…
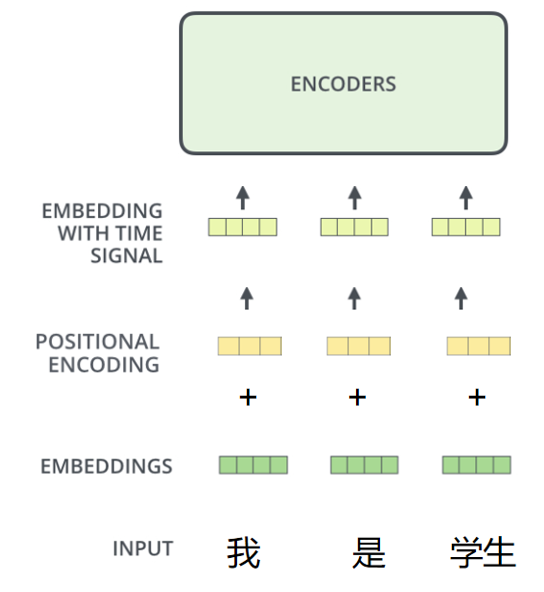
Transformer-《Attention Is All You Need》
目录
0.Transformer介绍
1.self-attention 和Multi-heads self-attention
1.1 self-attention(自注意力机制)
1.2 Multi-heads self-attention(多头自注意力机制)
2.网络结构
2.1 encoder(编码器)
2…
玩转ChatGPT:Transformer分类模型
一、写在前面
之前,我们介绍了Sklearn包以及Boost辈的各种分类模型,这些模型都很经典了,实际上也很强大,比如说Xgboost。
然而,近期随着ChatGPT的大火,其底层框架Transformer也逐渐火了,现在大…
![深度学习进阶篇[7]:Transformer模型长输入序列、广义注意力、FAVOR+快速注意力、蛋白质序列建模实操。](https://img-blog.csdnimg.cn/img_convert/15d0de3275239031b89367901bf89247.jpeg)
深度学习进阶篇[7]:Transformer模型长输入序列、广义注意力、FAVOR+快速注意力、蛋白质序列建模实操。
【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等 专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化…

当可变形注意力机制引入Vision Transformer
【GiantPandaCV导语】通过在Transformer基础上引入Deformable CNN中的可变性能力,在降低模型参数量的同时提升获取大感受野的能力,文内附代码解读。
引言
Transformer由于其更大的感受野能够让其拥有更强的模型表征能力,性能上超越了很多CN…

ViT细节与代码解读
最近看到两篇解读ViT很好的文章,备忘记录一下:
先理解细节
1:再读VIT,还有多少细节是你不知道的
再理解代码
1:ViT源码阅读-PyTorch - 知乎
18.自监督视觉`transformer`模型DINO
文章目录 自监督视觉`transformer`模型DINO总体介绍DINO中使用的SSL和KD方法multicrop strategy损失函数定义`teacher`输出的中心化与锐化模型总体结构及应用reference欢迎访问个人网络日志🌹🌹知行空间🌹🌹 自监督视觉transformer模型DINO
总体介绍 论文:1.Emerging …
gradio使用transformer模块demo介绍2:Images Computer Vision
文章目录 图像分类 Image Classification图像分割 Image Segmentation图像风格变换 Image Transformation with AnimeGAN3D模型 3D models 图像分类 Image Classification
import gradio as gr
import torch
import requests
from torchvision import transformsmodel torch.…
目标检测算法改进系列之Backbone替换为VanillaNet
VanillaNet简介
简介:VanillaNet是一种在设计中融入优雅的神经网络架构,通过避免高深度,shortcut和自注意力等复杂操作,VanillaNet简单而强大。每一层都经过精心制作,紧凑而直接,在训练后对非线性激活函数…
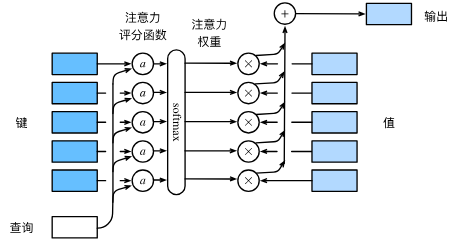
Transformer-2. 注意力分数
上一节记录了注意力机制的基础,这一节主要做几个实现,沐神说qkv在不同任务中的角色不一,所以后续内容才会搞懂qkv是啥玩意。
上节使用了高斯核来对查询和键之间的关系建模。 高斯核指数部分可以视为注意力评分函数(attention sco…
PriorLane: A Prior Knowledge Enhanced Lane Detection ApproachBased on Transformer
Abstract 在本文中,我们采用了一种仅限变压器的车道检测方法,因此它可以受益于 vision transformer 的蓬勃发展,并通过微调在大数据集上完全预训练的权重,在CULane和TuSimple基准上实现了最先进的(SOTA)性能…
Transformer-XL模型简单介绍
目录
一、前言
二、整体概要
三、细节描述 3.1 状态复用的块级别循环
3.2 相对位置编码
四、论文链接 一、前言 以自注意力机制为核心的 Transformer 模型是各种预训练语言模型中的主要组成部分。自注意力机制能够构建序列中各个元素之间的上下文关联程度,挖掘…
sklearn——转换器(Transformer)与预估器(estimator)
sklearn——转换器(Transformer)与预估器(estimator) 文章目录sklearn——转换器(Transformer)与预估器(estimator)转换器 Transformerfit 与 fit_transform 与 transform值得注意的…
使用taichi 写了一个任意平台任意显卡推理的Linear
这东西就是在于任意的显卡都能加速任意模型 当然如何有人使用taichi写一个卷积那么计算机视觉也能任意显卡加速人工智能 如果还有人写了个深度学习训练框架那么恭喜AMD,ARM 等任何芯片厂商乐疯
import taichi as ti
import numpy as np
ti.init(archti.vulkan)clas…
Transformer 估算 101
本文主要介绍用于估算 transformer 类模型计算量需求和内存需求的相关数学方法。 引言 其实,很多有关 transformer 语言模型的一些基本且重要的信息都可以用很简单的方法估算出来。不幸的是,这些公式在 NLP 社区中鲜为人知。本文的目的是总结这些公式&am…
OpenMMlab导出swim-transformer模型并使用onnxruntime和tensorrt推理
导出onnx文件
通过mmpretrain 导出swin-transformer的onnx文件非常容易,注意需设置 opset_version12这里是一个坑,刚开始设置的opset_version11后续转换trtengine的时候会有问题。
import torch
from mmpretrain import get_model, inference_modelmod…
工具系列:TimeGPT_(8)使用不规则时间戳进行时间序列预测
文章目录 介绍不规则时间戳的单变量时间预测不规则时间戳的外生变量时间预测 介绍
在处理时间序列数据时,时间戳的频率是一个关键因素,可以对预测结果产生重大影响。像每日、每周或每月这样的常规频率很容易处理。然而,像工作日这样的不规则…

Talk | 北京大学博士生汪海洋:通向3D感知大模型的前置方案
本期为TechBeat人工智能社区第559期线上Talk。 北京时间12月28日(周四)20:00,北京大学博士生—汪海洋的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “通向3D感知大模型的前置方案”,介绍了他的团队在3D视觉大模型的前置方…
transformer的学习记录【完整代码+详细注释】(系列六)
文章目录1 输出部分介绍1.1 代码分析1.2 输出部分的实现1.3 到目前为止完整的代码2 模型构建(编码器-解码器)2.1 编码器-解码器实现代码2.2 加在上一节完整代码的后面3 完整的Transformer4 最终搭建的模型的代码第一节:transformer的架构介绍…
transformer的学习记录【完整代码+详细注释】(系列七)
文章目录1 模型基本测试运行——copy任务2 介绍优化器和损失函数2.1 优化器和损失函数的代码2.2 介绍 标签平滑函数2.2.1 理论知识2.2.2 具体的参数以及代码展示2.3 训练和预测第一节:transformer的架构介绍 输入部分的实现 链接:https://editor.csdn.n…
transformer的学习记录【完整代码+详细注释】(系列三)
文章目录1 前馈全连接层1.1 前馈全连接层的代码1.2 包括前面学习内容的完整代码2 规范化层2.1 规范化层的作用2.2 规范化层的讲解2.3 实现规范化层的代码2.4 完整代码第一节:transformer的架构介绍 输入部分的实现 链接: https://editor.csdn.net/md/?…
股票价格预测 | 融合CNN和Transformer以提升股票趋势预测准确度
一 本文摘要
股票价格往往很难预测,因为我们很难准确建模数据点之间的短期和长期时间关系。卷积神经网络(CNN)擅长找出用于建模短期关系的局部模式。然而,由于其有限的观察范围,CNN无法捕捉到长期关系。相比之下,Transformer可以学习全局上下文和长期关系。本文提出了一…
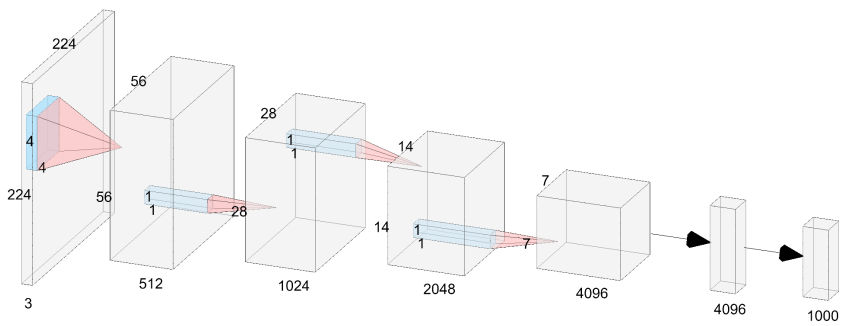
AI大模型落地不远了!首个全量化Vision Transformer的方法FQ-ViT(附源代码)
点击蓝字 关注我们 关注并星标 从此不迷路 计算机视觉研究院 公众号ID|计算机视觉研究院 学习群|扫码在主页获取加入方式 论文地址:https://arxiv.org/pdf/2111.13824.pdf 项目代码:https://github.com/megvii-research/FQ-ViT 计…
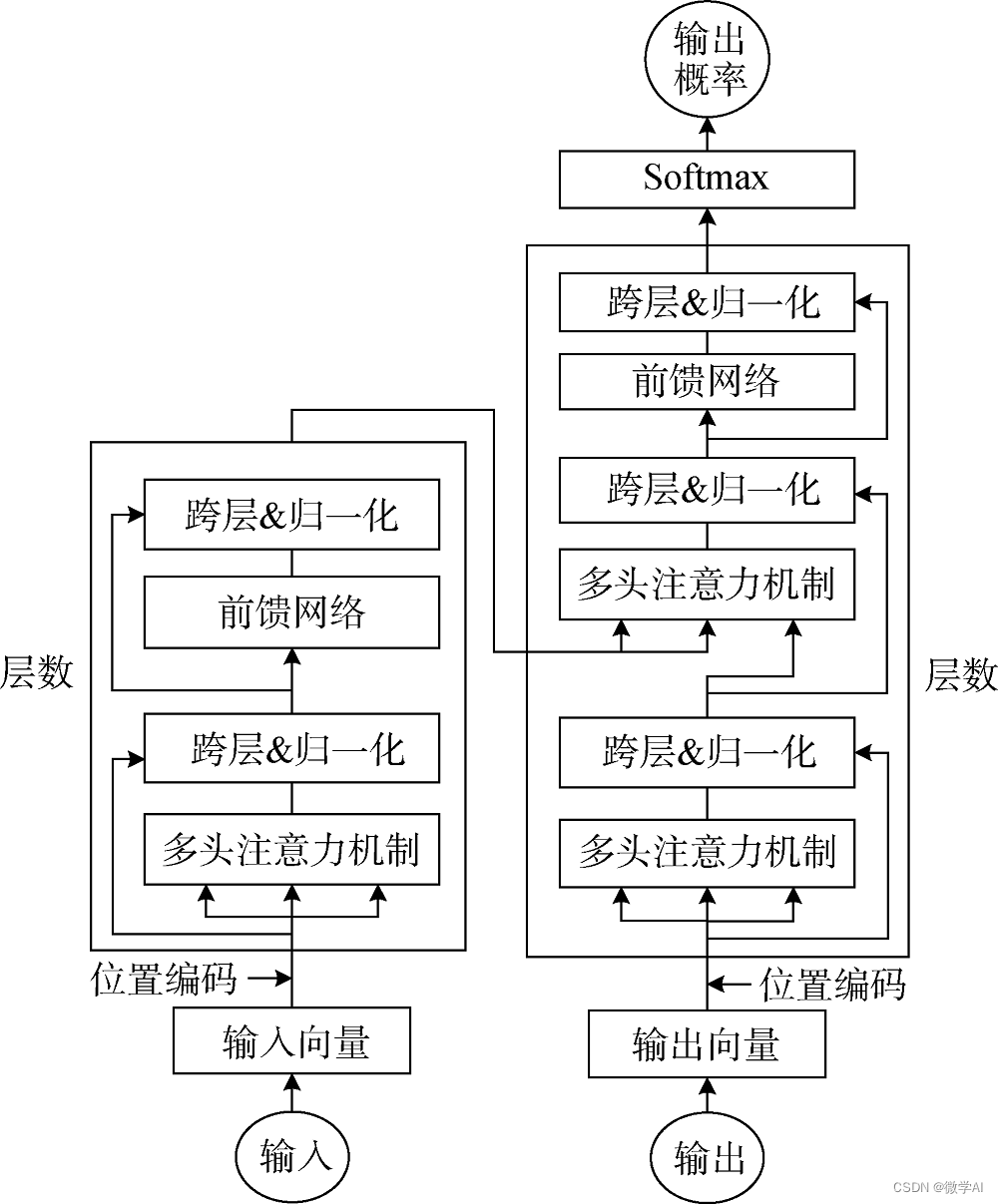
深度学习实战59-NLP最核心的模型:transformer的搭建与训练过程详解,手把手搭建与跑通
大家好,我是微学AI,今天给大家介绍一下深度学习实战59-NLP最核心的模型:transformer的搭建与训练过程详解,手把手搭建与跑通。transformer是一种基于自注意力机制的深度学习模型,由Vaswani等人在2017年的论文《Attention is All You Need》中提出。它最初被设计用来处理序…
MATLAB算法实战应用案例精讲-【图像处理】Transformer
目录
前言 算法原理
什么是transformer呢?
self-attention
输入和位置编码
编码器
Softmax

论文阅读-Transformer-based language models for software vulnerability detection
「分享了一批文献给你,请您通过浏览器打开 https://www.ivysci.com/web/share/biblios/D2xqz52xQJ4RKceFXAFaDU/ 您还可以一键导入到 ivySCI 文献管理软件阅读,并在论文中引用 」 本文主旨:本文提出了一个系统的框架来利用基于Transformer的语…
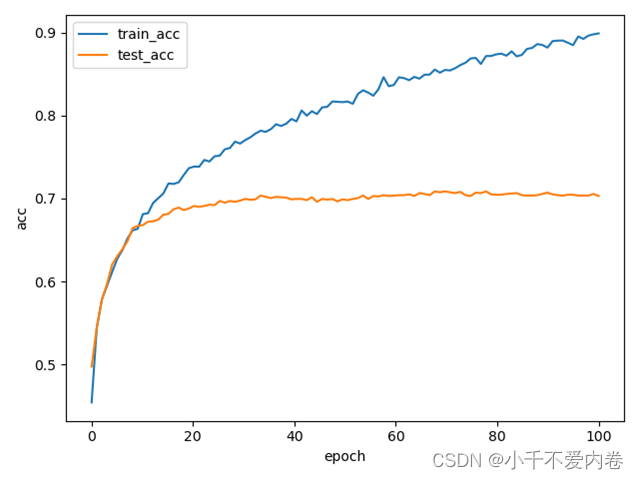
基于TextCNN、LSTM与Transformer模型的疫情微博情绪分类
基于TextCNN、LSTM与Transformer模型的疫情微博情绪分类
任务概述
微博情绪分类任务旨在识别微博中蕴含的情绪,输入是一条微博,输出是该微博所蕴含的情绪类别。在本次任务中,我们将微博按照其蕴含的情绪分为以下六个类别之一:积…
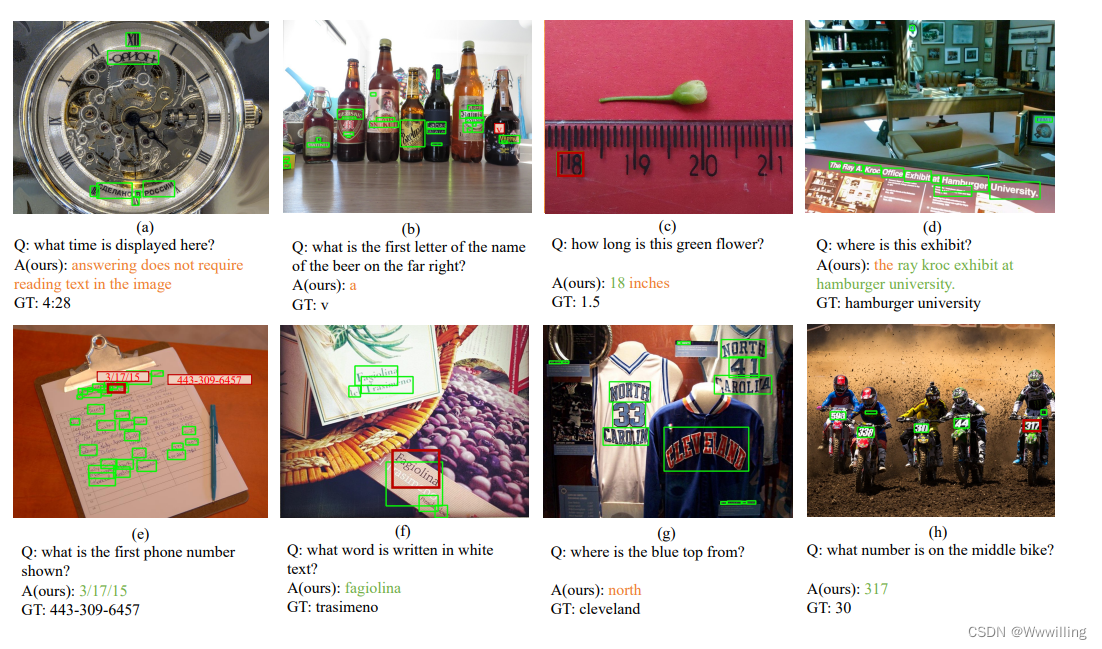
【Transformer论文】简单并不容易:TextVQA 和 TextCaps 的简单强基线
文献题目:Simple is not Easy: A Simple Strong Baseline for TextVQA and TextCaps
摘要
OCR(光学字符识别)工具可以识别的日常场景中出现的文本包含重要信息,例如街道名称、产品品牌和价格。两项任务——基于文本的视觉问答和…
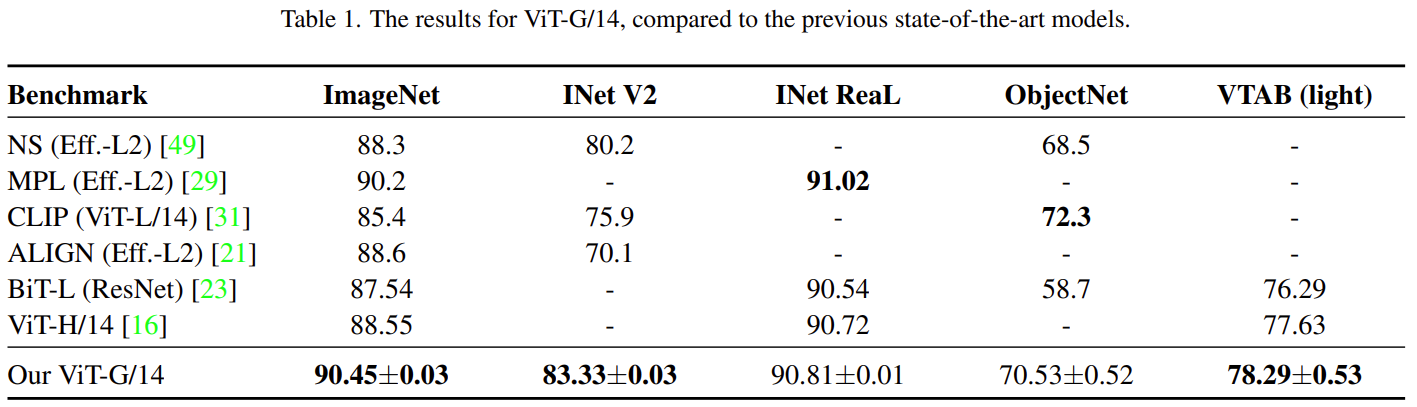
【计算机视觉 | ViT-G】谷歌大脑提出 ViT-G:缩放视觉 Transformer,高达 90.45% 准确率
文章目录 一、简介二、如何做到的?三、扩展数据四、「head」 的解耦权重衰减五、通过移除 [class] token 节省内存六、实验结果6.1 将计算、模型和数据一起扩展6.2 ViT-G/14 结果 论文地址为: https://arxiv.org/pdf/2106.04560.pdf一、简介
视觉 Trans…

Pytorch从零开始实现Vision Transformer (from scratch)
Pytorch从零开始实现Vision Transformer 前言一、Vision Transformer架构介绍1. Patch Embedding2. Multi-Head Attention3. Transformer BlockFeed Forward 二、预备知识1. Einsum2. Einops 三、Vision Transformer代码实现0. 导入库1. Patch Embedding2. Residual & Norm…
transformers 的使用
一.配置环境
在 抱抱脸 网址 上发布了很多已经训练好的模型,基本上大量的NLP模型都在,一开始是发布 transformers 的开源库,但后来连接了开发者和使用者。 https://huggingface.co/
在安装 transformers 前,需要先安装Flax&…

vision transformer的计算复杂度
文章目录 Vision transformerSwin transformerConvolutional vision Transformer Vision transformer 假设每个图像有 h ∗ w h*w h∗w 个patch,维度是 C C C
输入的图像 X X X ( 大小为 h w ∗ C hw* C hw∗C ),和三个系数矩阵相乘 ( 大小为 C ∗…
transformer的dataset下载失败load_dataset(“glue“,“mrpc“)
下载的时候会报错https://huggingface.co/datasets/glue/resolve/main/glue.py这个路径无法下载,但是浏览器是可以打开的 所以,先去官网手动下载文件 然后让模型去读取,默认是会读取TRANSFORMERS_CACHE中的内容,不过在c盘&#x…
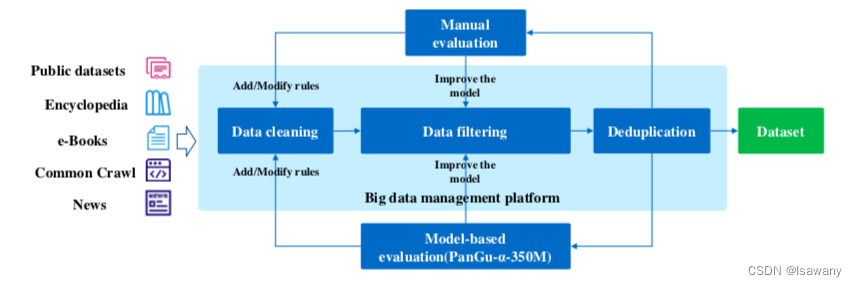
论文笔记--PANGU-α
论文笔记--PANGU-α: LARGE-SCALE AUTOREGRESSIVE PRETRAINED CHINESE LANGUAGE MODELS WITH AUTO-PARALLEL COMPUTATION 1. 文章简介2. 文章概括3 文章重点技术3.1 Transformer架构3.2 数据集3.2.1 数据清洗和过滤3.2.2 数据去重3.2.3 数据质量评估 4. 文章亮点5. 原文传送门6…
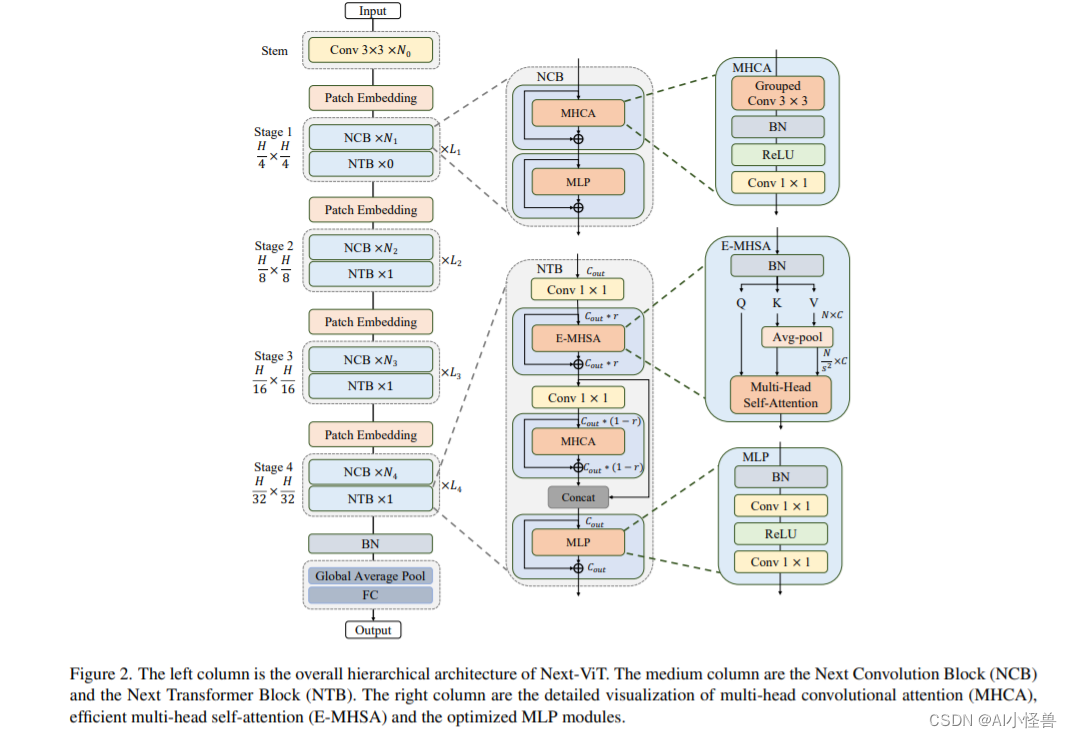
Yolov8涨点神器:创新卷积块NCB和创新Transformer 块NTB,助力检测,提升检测精度
🏆🏆🏆🏆🏆🏆Yolov8魔术师🏆🏆🏆🏆🏆🏆 ✨✨✨魔改网络、复现前沿论文,组合优化创新
🚀🚀🚀小目标、遮挡物、难样本性能提升
🍉🍉🍉定期更新不同数据集涨点情况 本博客将具有部署友好机制的强大卷积块和变换块,即NCB和NTB,引入到yolo…

Transformer【ViT】
参考 导师!博主的复现太细了。做个记录。
层神经网络学习小记录67——Pytorch版 Vision Transformer(VIT)模型的复现详解
计算机视觉中的transformer模型创新思路总结_Tom Hardy的博客-CSDN博
Vision Transformer详解
ViT
前处理
网络结…

【计算机视觉】浅谈计算机视觉中的Transformer
浅谈计算机视觉中的Transformer 摘要:1. Transformer网络结构2. 计算机视觉中的Transformer2.1 图像分类2.2 目标检测 3. 典型实验典型实验详解:实验目的:实验设置:数据集:模型配置:训练策略:评…

【ICML 2023】Hiera详解:一个简单且高效的分层视觉转换器
【ICML 2023】Hiera详解:一个简单且高效的分层视觉转换器 0. 引言1. 模型介绍2. Hiera介绍2.1 为什么提出Hiera?2.2 Hiera 中的 Mask2.3 空间结构的分离和填充到底如何操作2.4 为什么使用Mask Unit Attn 3. 简化版理解4. 总结 0. 引言
虽然现在各种各样…

想要更好地理解大模型架构?从计算参数量快速入手
编者按:要理解一种新的机器学习架构(以及其他任何新技术),最有效的方法就是从头开始实现它。然而,还有一种更简单的方法——计算参数数量。 通过计算参数数量,读者可以更好地理解模型架构,并检查…
NLP领域的知识体系构建及成长之路
前言
博主准备去C9读CS博士了,其中的路有多难走,只有我自己知道,anyway,感谢那个不曾放弃的自己
由于以后可能会接触到大模型相关的知识,所以现在想迫切的构建一下自己的知识体系,之前也只是对于CV领域比…
Transformer详解,中文版架构图
2.2.1 “编码器-解码器”架构 Seq2Seq 思想就是将网络的输入输出分别看作不同的序列,然后实现序列到序列 的映射,其经典实现结构就是“编码器-解码器”框架。编码器-解码器框架如图 2.7 所 示。 图2.7 编码器-解码器的基本框架 在 Seq2Seq 思想应用于自然…
MedViT:一种用于广义医学图像分类的鲁棒Vision Transformer
文章目录 MedViT: A Robust Vision Transformer for Generalized Medical Image Classification摘要本文方法Locally Feed-Forward Network 实验实验结果 MedViT: A Robust Vision Transformer for Generalized Medical Image Classification
摘要
卷积神经网络(cnn)在现有医…

OneFormer:规则通用图像分割的一个Transformer
文章目录 OneFormer: One Transformer to Rule Universal Image Segmentation摘要本文方法实验结果 OneFormer: One Transformer to Rule Universal Image Segmentation
摘要
通用图像分割并不是一个新概念。过去统一图像分割的尝试包括场景解析、全景分割,以及最…

Transformer回归预测
一、Attention is all you need——李沐论文精读Transformer
论文地址: https://arxiv.org/pdf/1706.03762.pdf Transformer论文逐段精读【论文精读】 卷积神经网络对较长的序列难以建模,因为他每次看一个比较小的窗口,如果两个像素隔得比较…
[算法前沿]--022-Pytorch从0编写Transformer算法
文章目录 预备工作背景模型架构Encoder部分和Decoder部分EncoderDecoderAttention模型中Attention的应用基于位置的前馈网络Embeddings and Softmax位置编码完整模型训练批处理和掩码Training Loop训练数据和批处理硬件和训练时间Optimizer正则化标签平滑实例<

【入门】上了大学,最好了解一点计算机视觉
作者|kaye 编辑|3D视觉开发者社区 作为一个刚入门计算机视觉的小白,简单记录一下这几天看的论文和博客的收获,算是一篇小笔记。
一、定义
计算机视觉技术是指通过计算机来模拟人类视觉观察和分析图像的视觉过程。它要求计算机在人工智能的过程中能够拥…
【Transformers】第 8 章:使用高效的 Transformer
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎 📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃 🎁欢迎各位→点赞…
Transformer Encoder-Decoer 结构回顾
有关于Transformer、BERT及其各种变体的详细介绍请参照笔者另一篇博客:最火的几个全网络预训练模型梳理整合(BERT、ALBERT、XLNet详解)。
本文基于对T5一文的理解,再重新回顾一下有关于auto-encoder、auto-regressive等常见概念&…
自动驾驶:BEV开山之作LSS(lift,splat,shoot)原理代码串讲
自动驾驶:BEV开山之作LSS(lift,splat,shoot)原理代码串讲前言Lift参数创建视锥CamEncodeSplat转换视锥坐标系Voxel Pooling总结前言 目前在自动驾驶领域,比较火的一类研究方向是基于采集到的环视图像信息,去构建BEV视角…

论文阅读:MPViT : Multi-Path Vision Transformer for Dense Prediction
中文标题:基于多路视觉Transformer的密集预测 提出问题
创新点
提出了一种具有多路径结构的多尺度嵌入方法,以同时表示密集预测任务的精细和粗糙特征。全局到局部的特征交互(GLI),以同时利用卷积的局部连通性和转换器…
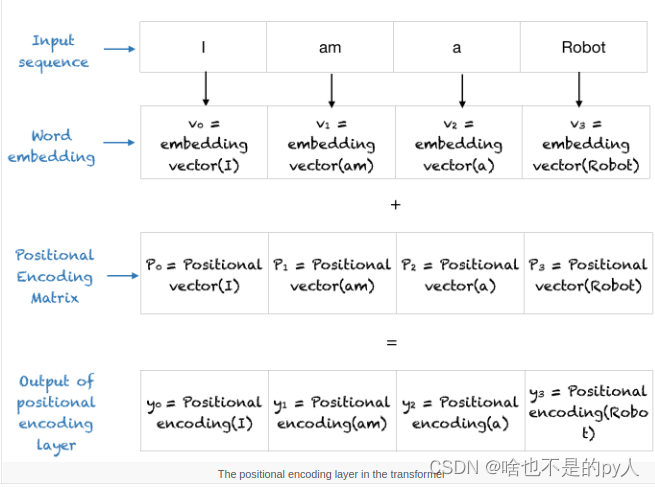
Transformer Tutorials 最全入门详细解释(一)
目录
.0 背景 0.1 RNN
0.2 seq2seq(别名Encoder-Decoder)
0.3 Attention(注意力机制) .1 Transformer
1.1 什么是Transformer
1.2 Encoder-Decoder
1.3 self-attention
1.4 Multi-Head attention 1.5 output
.2 位置编码
2.1 Positional Encod…
transformer的理解思路
整理transformer容易理解(可能质量不会太好,但肯定容易理解)的一些文章 1.embeding https://chriszou.com/2019/06/29/embedding-explained/ 通俗的方式解释了,embeding是什么东西
2.位置编码 英文https://www.youtube.com/watch?vdichIcUZfOw 英文htt…
自然语言模型发展历程 及 Transformer GPT Bert简介
目录自然语言模型发展历程2003 年 Bengio 提出神经网络语言模型 NNLM,统一了 NLP 的特征形式——Embedding;2013 年 Mikolov 提出词向量 Word2vec,延续 NNLM 又引入了大规模预训练(Pretrain)的思路;2017 年…

论文笔记|ECCV2022:Self-Promoted Supervision for Few-Shot Transformer
论文地址:https://arxiv.org/abs/2203.07057 代码链接:https://github.com/DongSky/few-shot-vit 这篇论文在2022年发表在ECCV上,论文的题目是用于小样本Transformer的self-promoted supervision(自我推荐监督)
1 Mot…
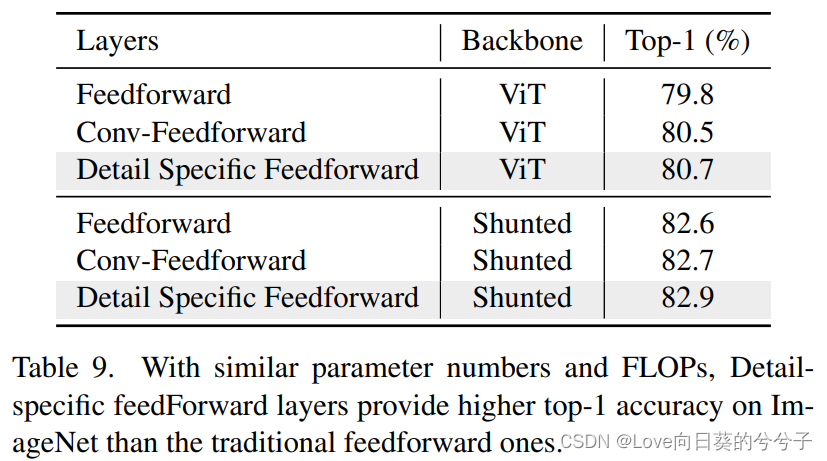
《Shunted Transformer: Shunted Self-Attention》CVPR 2022 oral
论文链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Ren_Shunted_Self-Attention_via_Multi-Scale_Token_Aggregation_CVPR_2022_paper.pdf 代码链接:https://github.com/OliverRensu/Shunted-Transformer
1. 动机
视觉转换器(ViT)模型…

Transformer应用之构建聊天机器人(一)
一、概述
聊天机器人的基本功能是系统根据用户当前的输入语句,生成相应的语句并输出给用户,用户和聊天机器人之间的一问一答构成了一个utterance,多个utterance就构成了一段对话。目前流行的聊天机器人都是基于Transformer的架构来做的&…
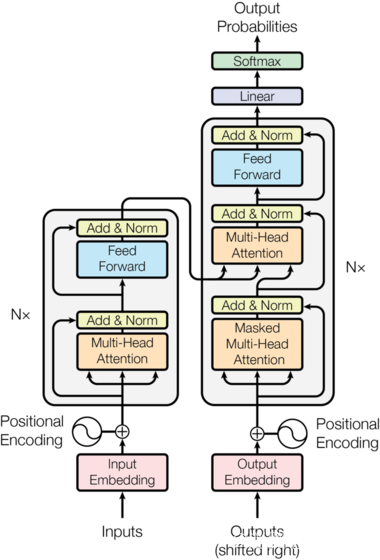
Transformer 代码详细解析
Transformer 代码详细解析 文章目录 Transformer 代码详细解析一、Transformer 背景介绍1.1 Transformer 的诞生1.2 Transformer 的优势1.3 Transformer 的市场 二、Transformer架构解析2.1 认识 Transformer 架构2.1.1 Transformer模型的作用2.1.2 Transformer 总体架构图 2.2…
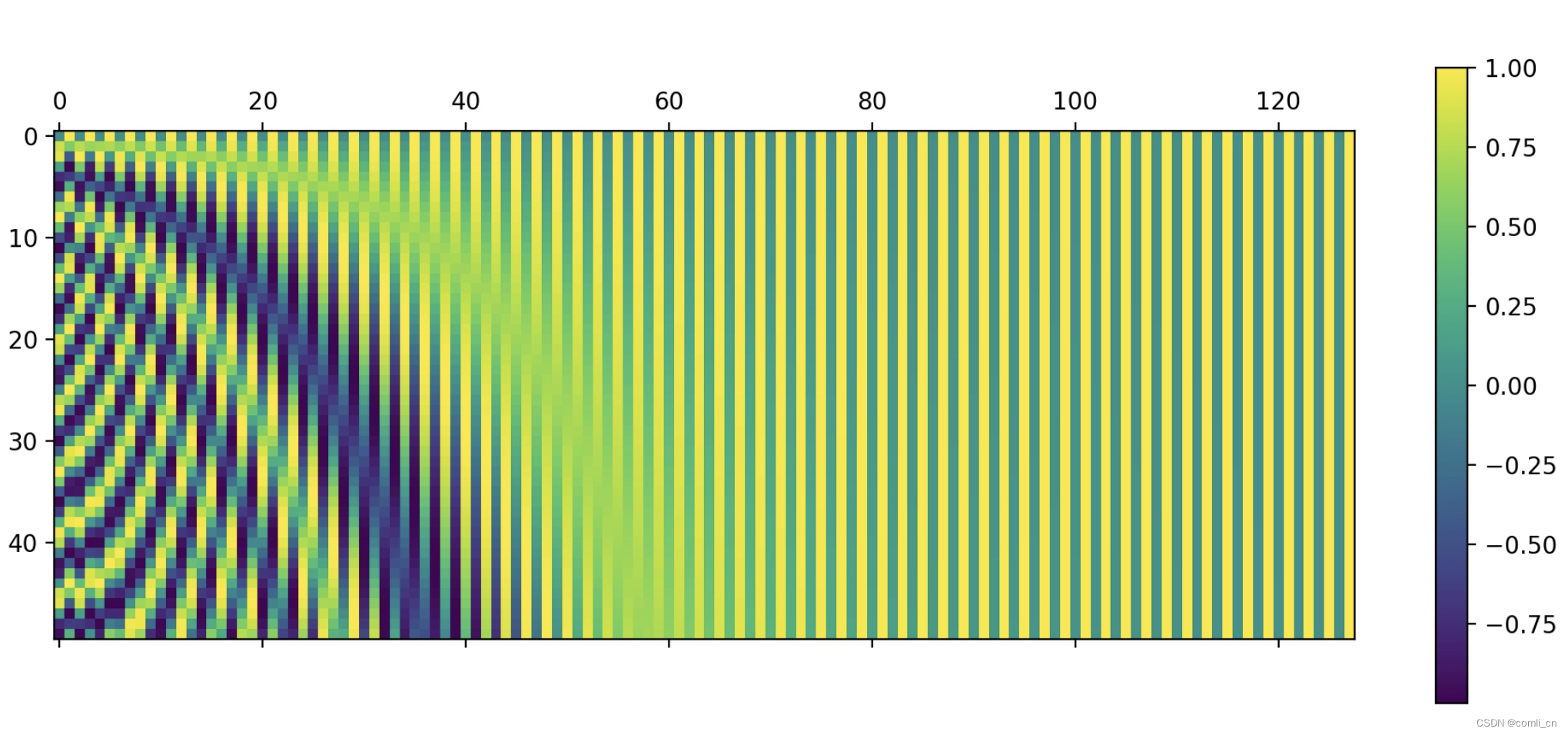
Transformer的位置编码
1. 什么是位置编码,为什么要使用位置编码
简单来说位置编码就是给一个句子中的每个token一个位置信息,通过位置编码可以明确token的前后顺序关系。
对任何语言来说,句子中词汇的顺序和位置都是非常重要的。它们定义了语法,从而定…

Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
动机:
为啥挑这篇文章,因为效果炸裂,各种改款把各种数据集霸榜了:语义分割/分类/目标检测,前10都有它 Swin Transformer, that capably serves as a general-purpose backbone for computer vision. 【CC】接着VIT那…

论文阅读:Video Action Transformer Network
目录
Objective (Task)
Motivation
Proposed Method
Trunk: I3D
Region Proposal Network(RPN): Faster R-CNN
Action Transformer Head
Dataset
Submission Format
Result & Analysis
Action classification with GT person boxes
Localization performance (a…
视觉transformer面试题:vit
输入端适配
通过patch0与每个patch计算value来整合信息 最后分类
因为transformer的输入输出维度是一致的,transformer block的任何一个输出 无法进行很好的分类
为什么不使用输出patch相加求平均?patch 可能是1616的数量,然后哪怕256256的大小&#…

Swintransformer模型的优化
SwinTransformer模型优化 文章目录 SwinTransformer模型优化1.SwinTransformer概述2.性能瓶颈分析3.模型优化3.1.transpose消除3.2.更好的layergroup3.1.1.SliceOp3.1.2.SqueezeOp3.1.3.weight切分 4.优化效果 1.SwinTransformer概述
自从Transformer在NLP任务上取得突破性的进…

Transformer(一)简述(注意力机制,NLP,CV通用模型)
目录
1.Encoder
1.1简单理解Attention
1.2.什么是self-attention 1.3.怎么计算self-attention 1.4.multi-headed 1.5.位置信息表达 2.decorder(待补充)
参考文献 1.Encoder
1.1简单理解Attention
比方说,下图中的热度图中我们希望专注于…
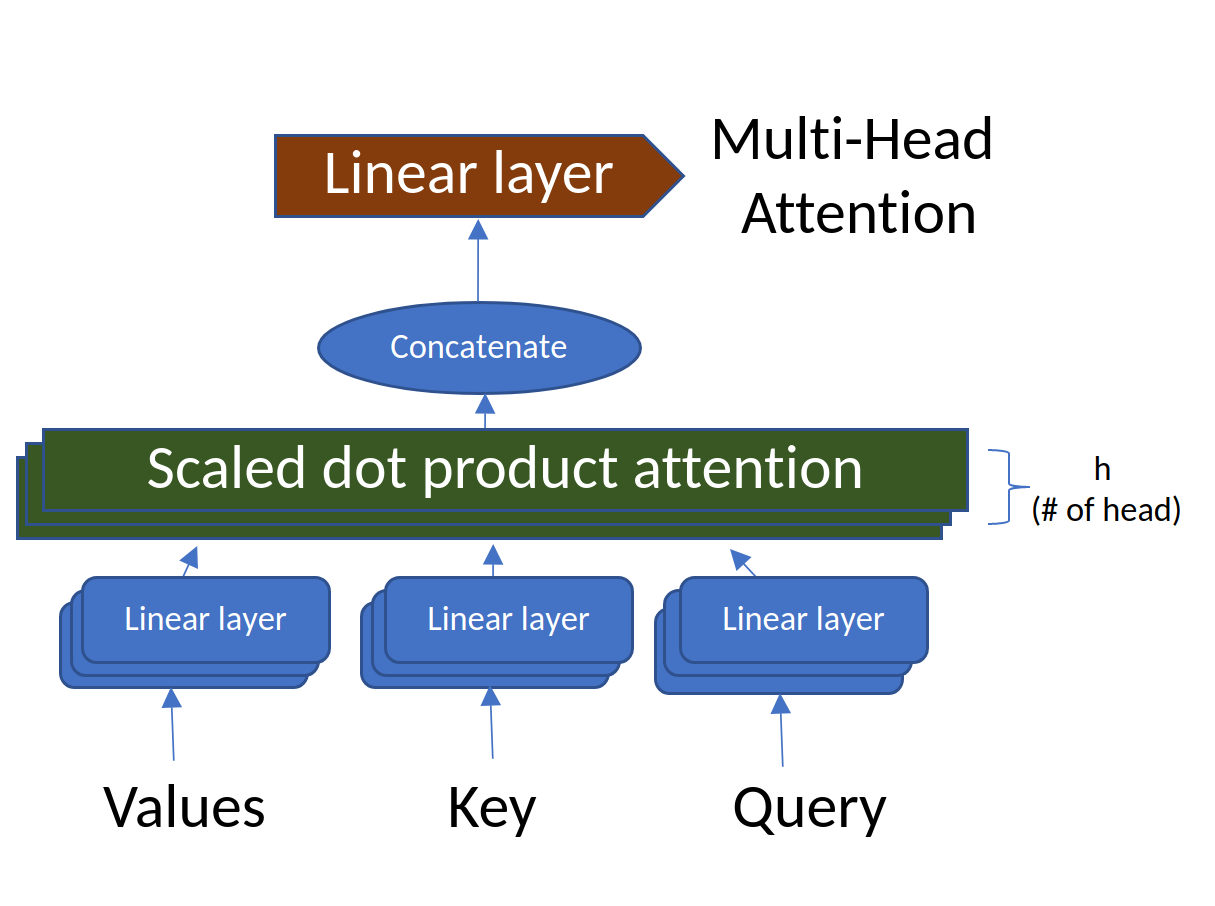
【变形金刚01】attention和transformer所有信息
图1.来源:Arseny Togulev在Unsplash上的照片 一、说明 这是一篇 长文 ,几乎讨论了人们需要了解的有关注意力机制的所有信息,包括自我注意、查询、键、值、多头注意力、屏蔽多头注意力和转换器,包括有关 BERT 和 GPT 的一些细节。因…

代码详解——Transformer
文章目录 整体架构Modules.pyScaledDotProductAttention SubLayers.pyMultiHeadAttentionPositionwiseFeedForward Layers.pyEncoderLayerDecoderLayer Models.pyget_pad_maskget_subsequent_maskPositionalEncodingEncoderDecoderTransformer 整体架构 源码地址(py…
![[论文笔记]Glancing Transformer for Non-Autoregressive Neural Machine Translation](https://img-blog.csdnimg.cn/995ccaae14124f42815d92b9eb6676c7.png)
[论文笔记]Glancing Transformer for Non-Autoregressive Neural Machine Translation
引言
这是论文Glancing Transformer for Non-Autoregressive Neural Machine Translation的笔记。
传统的非自回归文本生成速度较慢,因为需要给定之前的token来预测下一个token。但自回归模型虽然效率高,但性能没那么好。 这篇论文提出了Glancing Transformer,可以只需要一…

『论文精读』Data-efficient image Transformers(DeiT)论文解读
『论文精读』Data-efficient image Transformers(DeiT)论文解读 文章目录 一. DeiT简介二. 知识蒸馏(knowledge distillation)2.1. KLDivloss2.2. 蒸馏温度 τ \tau τ2.3. distillation in transformer 三. better hyperparameter四. data augmentation五. label smoothing参…
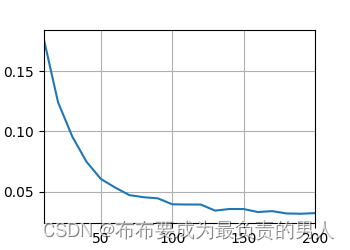
机器学习深度学习——transformer(机器翻译的再实现)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——自注意力和位置编码(数学推导代码实现) 📚订阅专栏:机器…
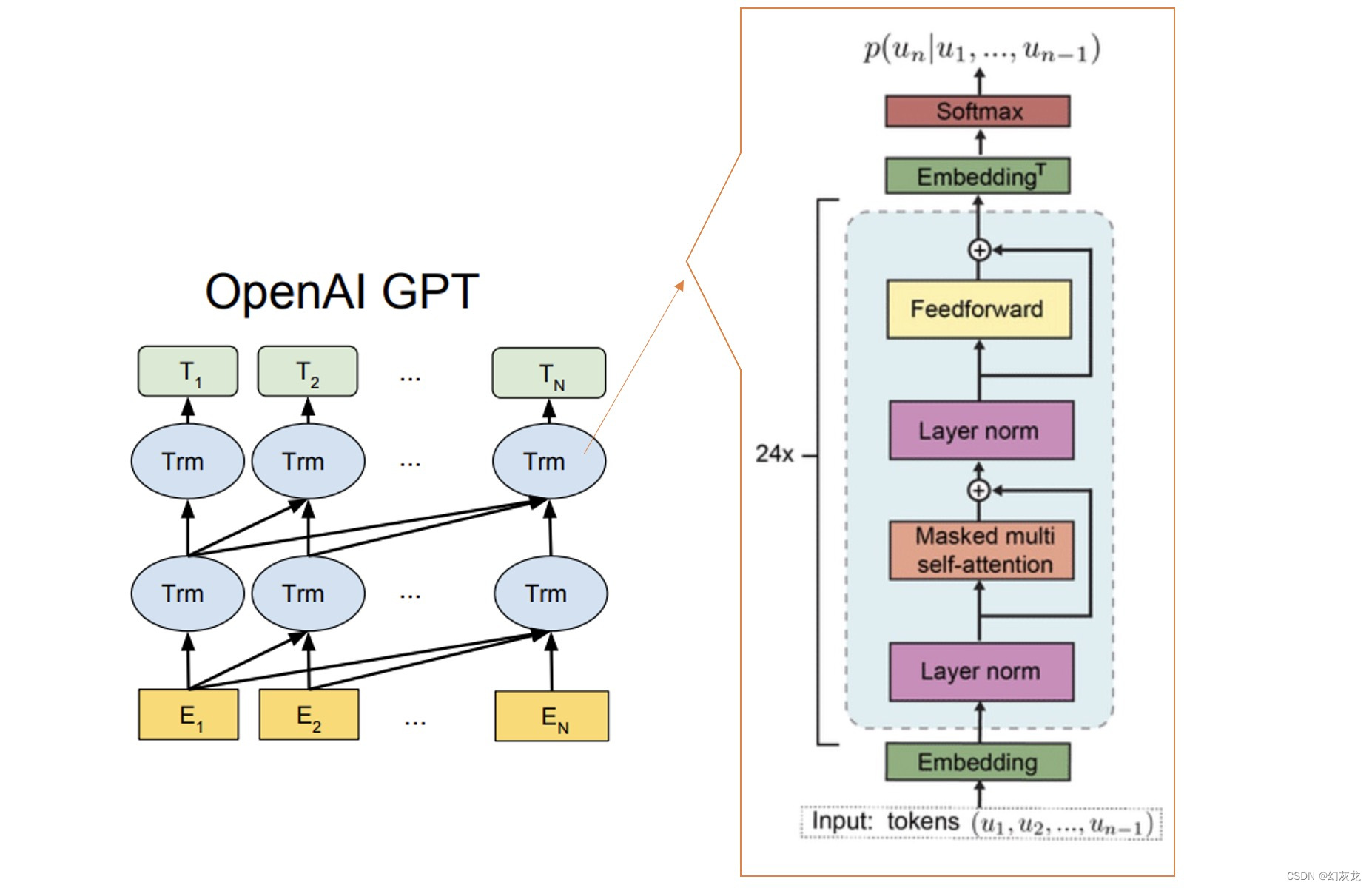
让chatGPT使用Tensor flow Keras组装Bert,GPT,Transformer
让chatGPT使用Tensor flow Keras组装Bert,GPT,Transformer implement Transformer Model by Tensor flow Kerasimplement Bert model by Tensor flow Kerasimplement GPT model by Tensor flow Keras 本文主要展示Transfomer, Bert, GPT的神经网络结构之间的关系和差异。网络上…
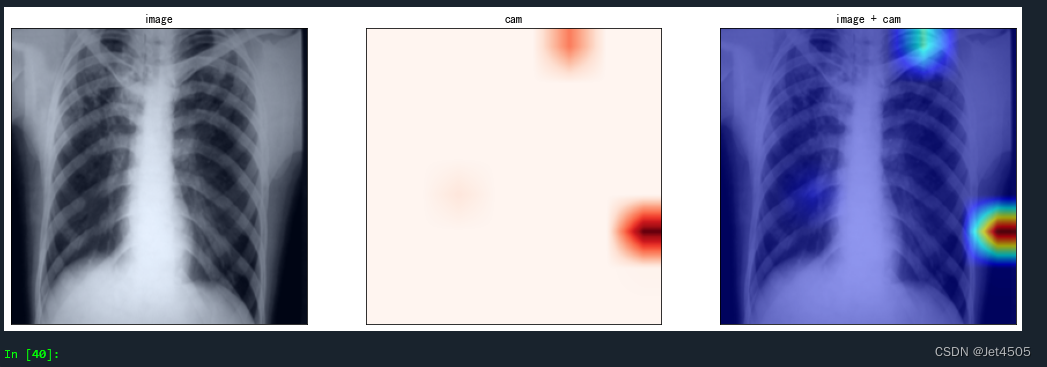
第58步 深度学习图像识别:Transformer可视化(Pytorch)
一、写在前面
(1)pytorch_grad_cam库
这一期补上基于基于Transformer框架可视化的教程和代码,使用的是pytorch_grad_cam库,以Bottleneck Transformer模型为例。
(2)算法分类
pytorch_grad_cam库中包含的…

第八周.直播.Transformer in Graph
文章目录注意力基础知识论文带读摘要论文结构3.1 Structural Encodings in Graphormer3.1.1Centrality Encoding3.1.2 Spatial Encoding3.1.3 Edge Encoding in the Attention本文内容整理自深度之眼《GNN核心能力培养计划》公式输入请参考:
在线Latex公式注意力基础…

【Timm】搭建Vision Transformer系列实践,终于见面了,Timm库!
前言:工具用不好,万事都烦恼,原本真的就是很简单的一个思路实现,偏偏绕了一圈又一圈,今天就来认识认识Timm库吧!
目录
1.百度飞桨提供的-从零开始学视觉Transformer
2.资源:视觉Transformer优…

(DINO) Emerging Properties in Self-Supervised Vision Transformers——自监督ViT的新属性和几点思考
论文地址 ,仅学习参考 目录
摘要
实验结果
Self-distillation with no labels (本文实验架构-自监督ViT)
DINO的消融实验
总结
研究现状
方法
相关工作
几点思考 摘要 文章初心 :探究自监督下的ViT是否出现新的属性 发…

PyTorch入门(六)使用Transformer模型进行中文文本分类
在文章PyTorch入门(五)使用CNN模型进行中文文本分类中,笔者介绍了如何在PyTorch中使用CNN模型进行中文文本分类。本文将会使用Transformer模型实现中文文本分类。 本文将会使用相同的数据集。文本预处理已经在文章PyTorch入门(…

看了这篇你还不懂BERT,那你就过来打死我吧
目录
1. Word Embedding. 1
1.1 基于共现矩阵的词向量... 1
1.2 基于语言模型的词向量... 2
2. RNN/LSTM/GRU.. 5
2.1 RNN.. 5
2.2 LSTM 通过门的机制来避免梯度消失... 6
2.3 GRU 把遗忘门和输入门合并成一个更新门... 6
3. seq2seq模型... 8
3.1 朴素的seq2seq模型.…
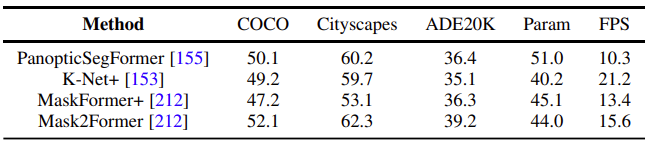
【计算机视觉】最新综述:南洋理工和上海AI Lab提出基于Transformer的视觉分割综述
文章目录 一、导读二、摘要三、内容解读3.1 研究动机3.2 这篇综述的特色,以及与以往的Transformer综述有什么区别?3.3 Transformer-Based 分割和检测方法总结与对比3.4 相关研究领域的方法总结与对比3.5 不同方法的实验结果对比3.6 未来可以进行的方向 一…
G1D32-计算二项式系数Transformer
一、计算二项式系数
好像也没啥好说的~
二、Transformer
其实忘记的不是transformer,而是seq2seq。好吧,那就一起来复习一下hhh
(一)seq2seq
1、what
这个任务任务啊,就是序列到序列嘛
2、how
一般用encoder和…

ICCV2021 Learning Spatio-Temporal Transformer for Visual Tracking
ICCV2021 Learning Spatio-Temporal Transformer for Visual Tracking
论文实现:学习用于视觉跟踪的时空转换器
摘要 在本文中,我们提出了一种以编码器-解码器转换器为关键组件的新跟踪架构。 编码器对目标对象和搜索区域之间的全局时空特征依赖性进行…

附代码 Swin Transformer
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 论文解读
参考链接:https://blog.csdn.net/qq_37541097/article/details/121119988?spm1001.2014.3001.5501 代码链接:https://github.com/microsoft/Swin-Transformer 论文…
详解Transformer中的Encoder
一.Transformer架构 左半边是Encoder,右半边是Decoder。
二.Vision Transformer
Vision Transformer取了Transformer的左半边。包含
Input EmbeddingPositional Encoding多头注意力机制 Add & Norm(前馈网络)Feed Forward Add & Norm
2.1 Input Embe…

深度学习笔记之Transformer(四)铺垫:LayerNormalization
深度学习笔记之Transformer——LayerNormalization 引言回顾:批标准化问题描述问题处理 层标准化批标准化无法处理的问题 引言
在介绍 Transformer \text{Transformer} Transformer模型架构之前,首先介绍 Transformer \text{Transformer} Transformer的…
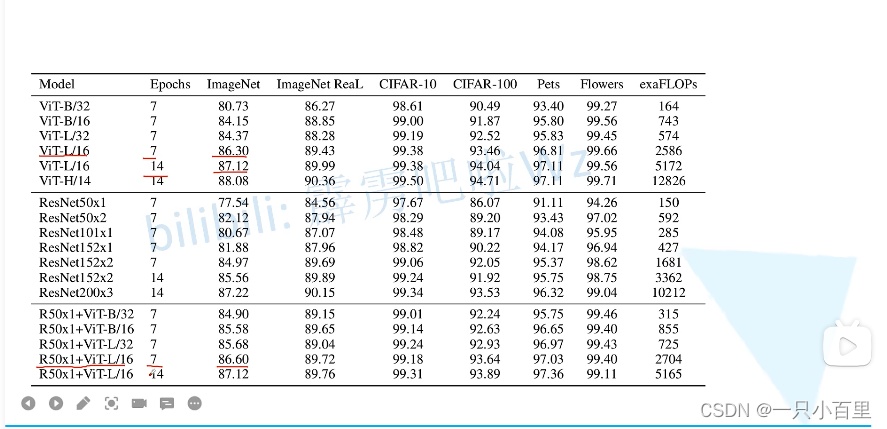
vision transformer 详解
文章链接:https://arxiv.org/abs/2010.11929 代码地址:GitHub - google-research/vision_transformer Pytorch实现代码: https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/vision_tran…
ATTransUNet:一种增强型混合Transformer结构用于超声图像分割
ATTransUNet 期刊分析摘要贡献方法整体框架1.Adaptive Token Extraction Module2.Feature Reprojection Mechanism3.Selective Feature Reinforcement Module 实验1.对比实验2.消融实验2.1 Ablation of the Number of Tokens and Transformer layers2.2 Ablation of the Featur…

TransNetR:用于多中心分布外测试的息肉分割的基于transformer的残差网络
TransNetR Transformer-based Residual Network for Polyp Segmentation with Multi-Center Out-of-Distribution Testing 阅读笔记
1. 论文名称
《TransNetR Transformer-based Residual Network for Polyp Segmentation with Multi-Center Out-of-Distribution Testing》 用…

Nougat:一种用于科学文档OCR的Transformer 模型
随着人工智能领域的不断进步,其子领域,包括自然语言处理,自然语言生成,计算机视觉等,由于其广泛的用例而迅速获得了大量的普及。光学字符识别(OCR)是计算机视觉中一个成熟且被广泛研究的领域。它有许多用途,…
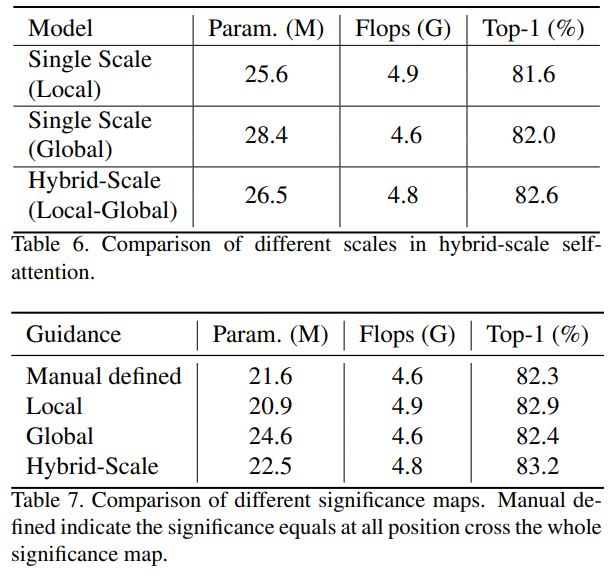
SG-Former:具有进化Token重新分配的自引导Transformer
文章目录 摘要1、简介2、相关研究3、方法3.1、概述3.2、自引导注意力3.3、混合尺度注意力3.4、Transformer块3.5、Transformer架构变体 4、实验4.1、ImageNet-1K的分类4.2、目标检测和实例分割4.3、ADE20K上的语义分割4.4、消融实验 5、结论 摘要
https://arxiv.org/pdf/2308.…
PyTorch翻译官网教程-FAST TRANSFORMER INFERENCE WITH BETTER TRANSFORMER
官网链接
Fast Transformer Inference with Better Transformer — PyTorch Tutorials 2.0.1cu117 documentation
使用 BETTER TRANSFORMER 快速的推理TRANSFORMER
本教程介绍了作为PyTorch 1.12版本的一部分的Better Transformer (BT)。在本教程中,我们将展示如…
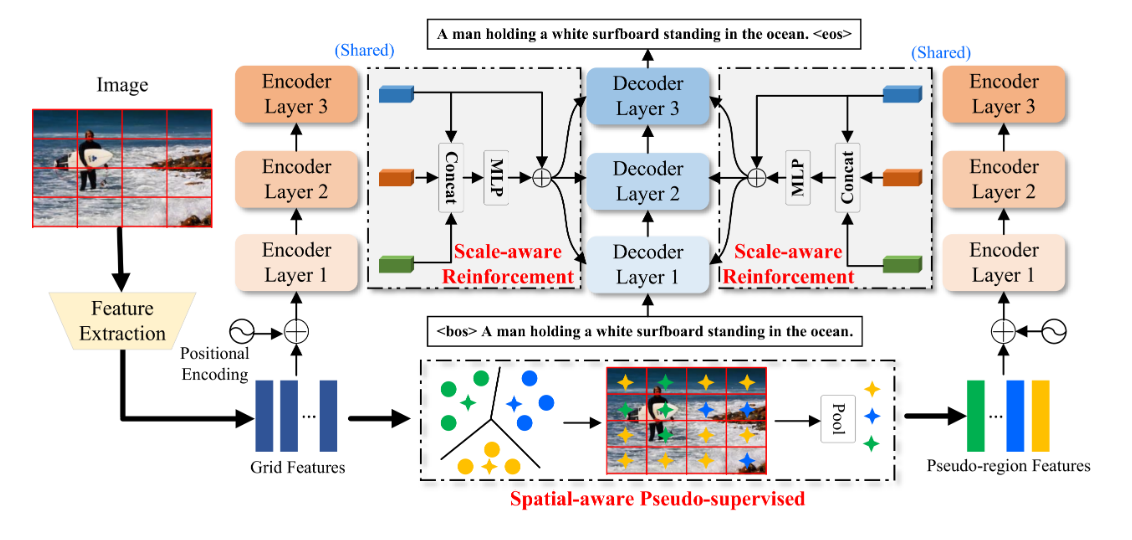
【Image captioning】S2 Transformer for Image Captioning 实现流程
S2 Transformer for Image Captioning 实现流程
作者:安静到无声 个人主页 目录 S2 Transformer for Image Captioning 实现流程环境设置数据准备训练评价离线评估在线评估参考文献和引用参考引用致谢推荐专栏环境设置
克隆此存
ChatGPT3 Transformer 的多模态全能语言模型
"Transformer 的多模态全能语言模型" 指的是一种融合了多种输入模态(如文本、图像、声音等)的语言模型,具有广泛的应用能力,可以理解和生成多种类型的信息。
"Transformer的多模态全能语言模型" 包含了多个…
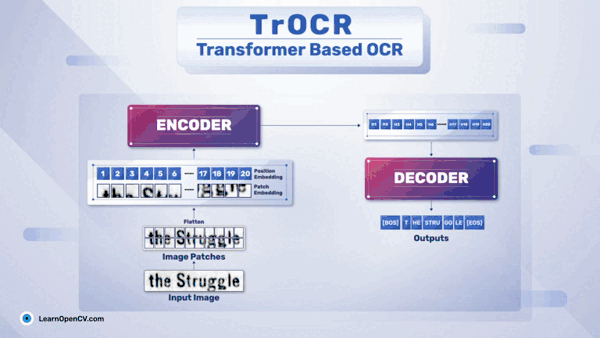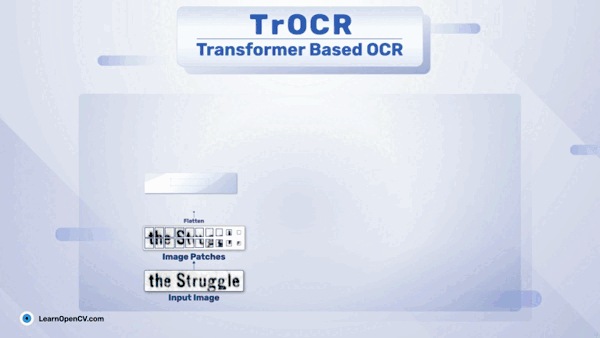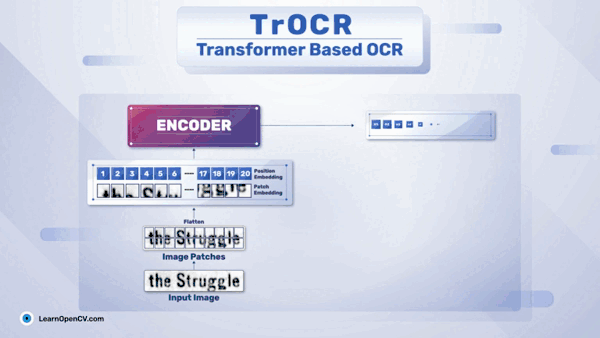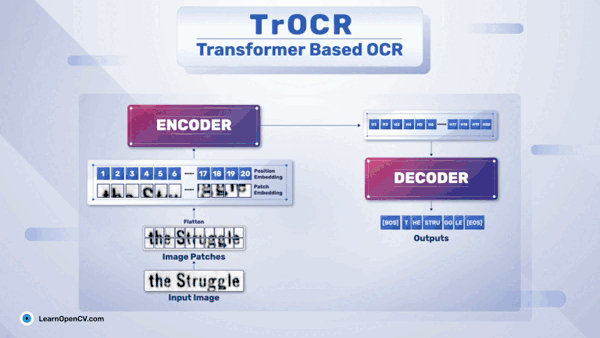
TrOCR – 基于 Transformer 的 OCR 入门指南
多年来,光学字符识别 (OCR) 出现了多项创新。它对零售、医疗保健、银行和许多其他行业的影响是巨大的。尽管有着悠久的历史和多种最先进的模型,研究人员仍在不断创新。与深度学习的许多其他领域一样,OCR 也看到了变压器神经网络的重要性和影响。如今,我们拥有像TrOCR(Tran…

对Transformer中的Attention(注意力机制)的一点点探索
摘要:本文试图对 Transformer 中的 Attention 机制进行一点点探索。并就 6 个问题深入展开。 ✅ NLP 研 1 选手的学习笔记 简介:小王,NPU,2023级,计算机技术 研究方向:文本生成、摘要生成 文章目录 一、为啥…
吴恩达gradio课程:基于开源LLM(large language model)的聊天应用chatbot
文章目录 内容简介构建应用程序使用gradio在线体验接下来结合llm模型使用gradio构建一个完整的应用程序内容简介 Falcon 40B是当前最好的开源语言模型之一。使用text-generation库调用Falcon 40B的问答API接口。首先仅仅在代码中与模型聊天,后续通过Gradio构建聊天界面。Gradio…
Harvard transformer NLP 模型 openNMT 简介入门
项目网址: OpenNMT - Open-Source Neural Machine Translation logo: 一,从应用的层面先跑通 Harvard transformer
GitHub - harvardnlp/annotated-transformer: An annotated implementation of the Transformer paper.
git clone https…

【Transformer系列】深入浅出理解Attention和Self-Attention机制
一、参考资料
课件:10_Transformer_1.pdf 视频:Transformer模型(1/2): 剥离RNN,保留Attention
二、Attention without RNN
Attention模型可以看到全局的信息。 本章节以 Seq2Seq( (encoder decoder)) 模型为例&…
使用pytorch 的Transformer进行中英文翻译训练
下面是一个使用torch.nn.Transformer进行序列到序列(Sequence-to-Sequence)的机器翻译任务的示例代码,包括数据加载、模型搭建和训练过程。
import torch
import torch.nn as nn
from torch.nn import Transformer
from torch.utils.data im…
LLM架构自注意力机制Transformers architecture Attention is all you need
使用Transformers架构构建大型语言模型显著提高了自然语言任务的性能,超过了之前的RNNs,并导致了再生能力的爆炸。
Transformers架构的力量在于其学习句子中所有单词的相关性和上下文的能力。不仅仅是您在这里看到的,与它的邻居每个词相邻&…
【ECCV2022】Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
论文:https://arxiv.org/abs/2105.05537
代码:https://github.com/HuCaoFighting/Swin-Unet
解读:Swin-UNet:基于纯 Transformer 结构的语义分割网络 -…
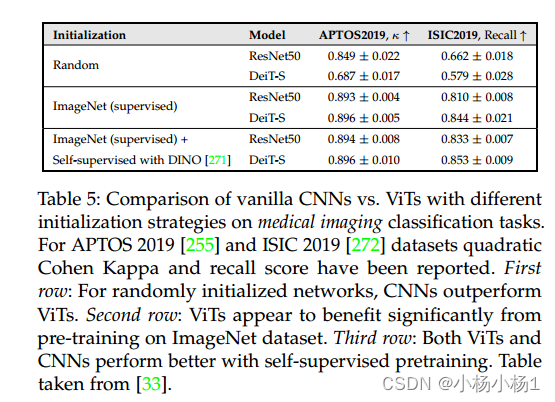
Transformer在医学影像中的应用综述-分类
文章目录 COVID-19 Diagnosis黑盒模型可解释的模型 肿瘤分类黑盒模型可解释模型 视网膜疾病分类小结 总体结构 COVID-19 Diagnosis
黑盒模型
Point-of-Care Transformer(POCFormer):利用Linformer将自注意的空间和时间复杂度从二次型降低到线性型。POCFormer有200…
十八、深度学习模型30年演化史
1、模型分类 深度学习是解决问题的一系列模型与方法,但深度学习模型不是深度学习领域中唯一的研究方向,且不一定是最重要的研究方向。除了模型之外,比较重要的还有优化算法、损失函数、采样方法等。 1.1 DNN 深度神经网络(Deep Neural Networks, 以下简称DNN)是…
esbuild中文文档-基础配置项(General options - Rebuild)
文章目录 重建(Rebuild)结语 哈喽,大家好!我是「励志前端小黑哥」,我带着最新发布的文章又来了! 老规矩,小手动起来~点赞关注不迷路! esbuild简单介绍
esbuild为了突破了JavaScript…

ERINE系列论文解读
ERNIE3.0论文解读 -潘登同学的NLP笔记 文章目录ERNIE3.0论文解读 -潘登同学的NLP笔记从ERNIE 1.0开始知识集成模型架构数据规模预训练任务到ERNIE 2.0预训练任务模型结构与Bert的比较再到ERNIE3.0模型总览预训练任务实验结果fine-tune实验从ERNIE 1.0开始
ERINE 1.0的核心思想…

LLM 生成式配置的推理参数温度 top k tokens等 Generative configuration inference parameters
在这个视频中,你将了解一些方法和相关的配置参数,这些参数可以用来影响模型在下一个词生成时的最终决策方式。如果你在Hugging Face网站或AWS的游乐场中使用过LLMs,你可能已经看到了这些控制选项,用来调整LLM的行为。每个模型都暴…
![[论文分享]VOLO: Vision Outlooker for Visual Recognition](https://img-blog.csdnimg.cn/66aca6a3aea648df8876cc9df3b44d8d.png)
[论文分享]VOLO: Vision Outlooker for Visual Recognition
VOLO: Vision Outlooker for Visual Recognition
概述
视觉 transformer(ViTs)在视觉识别领域得到了广泛的探索。由于编码精细特征的效率较低,当在 ImageNet 这样的中型数据集上从头开始训练时,ViT 的性能仍然不如最先进的 CNN。…
Huggingface训练Transformer
在之前的博客中,我采用SFT(监督优化训练)的方法训练一个GPT2的模型,使得这个模型可以根据提示语进行回答。具体可见博客召唤神龙打造自己的ChatGPT_gzroy的博客-CSDN博客
Huggingface提供了一个TRL的扩展库,可以对tra…
PMET: Precise Model Editing in a Transformer
本文是LLM系列的文章,针对《PMET: Precise Model Editing in a Transformer》的翻译。 PMET:Transformer中的精确模型编辑 摘要1 引言2 相关工作3 方法4 实验5 结论 摘要
模型编辑技术以相对较低的成本修改了大型语言模型中的一小部分知识,…
SVFormer:走进半监督动作识别的视觉 Transformer
出品人:Towhee 技术团队 顾梦佳 半监督学习(SSL)的动作识别是一个关键的视频理解任务,然而视频标注的高成本加大了该任务的难度。目前相关的方法主要研究了卷积神经网络,较少对于视觉 Transformers(ViT&…
STTran: Spatial-Temporal Transformer for Dynamic Scene Graph Generation
文章目录 0 Abstract1 Introduction2 Related Work3 Method3.1 Transformer3.2 Relationship Representation3.3 Spatio-Temporal Transformer3.3.1 Spatial Encoder3.3.2 Frame Encoding3.3.3 Temporal Decoder 3.4 Loss Function3.5 Graph Generation Strategies 4 Experimen…

swin-Transformer论文详解
swin-Transformer论文详解 – 潘登同学的深度学习笔记 文章目录swin-Transformer论文详解 -- 潘登同学的深度学习笔记前言网络架构Swin transformer Block巧妙的Mask实验前言
swin-Transformer作为CVPR 21的最佳论文,在几乎所有下游任务都表现地很出色;…

transformer机制
transformer机制 – 潘登同学的深度学习笔记 文章目录transformer机制 -- 潘登同学的深度学习笔记应用了残差思想的self-Attention Encoder加入位置信息Position Embeddingtransformer模型详解Decoder的第一层self-AttentionDecoder的第二层self-Attention理解为啥第二层不需要…

【内推码:NTAMW6c】 MAXIEYE智驾科技2024校招启动啦
MAXIEYE智驾科技2024校招启动啦【内推码:NTAMW6c】
【招聘岗位超多!!公司食堂好吃!!】
算法类:感知算法工程师、SLAM算法工程师、规划控制算法工程师、目标及控制算法工程师、后处理算法工程师
软件类&a…
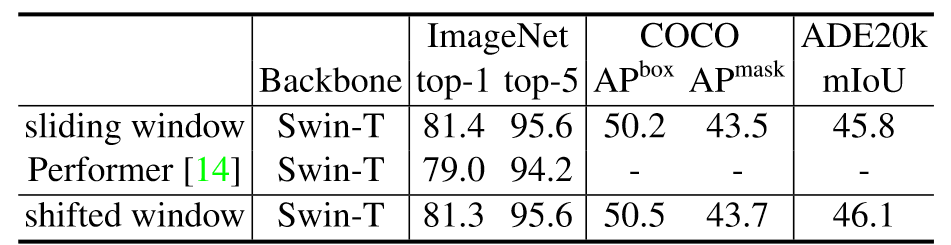
【论文精读】Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 前言Abstract1. Introduction2. Related Work3. Method3.1. Overall Architecture3.2. Shifted Window based Self-AttentionSelf-attention in non-overlapped windowsShifted window partitioning …

transformer实现词性标注
1、self-attention
1.1、self-attention结构图 上图是 Self-Attention 的结构,在计算的时候需要用到矩阵 Q(查询), K(键值), V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量 x组成的矩阵 X) 或者上一个 Encoder block 的输出。而 Q, K, V…
吴恩达gradio课程:diffusion 文生图(Image to Text)模型
文章目录 内容简介主要的Block元素构建应用程序界面改进内容简介 使用了基于Diffusion模型的图像生成技术,可以从文本描述中生成图像。 通过简单的Python代码调用模型接口,只需要提供文本提示即可生成图像。 使用Gradio构建了一个简洁的网页界面,可以自定义文本提示来生成图像。…
The Annotated Transformer(Attention Is All You Need)
"Attention is All You Need"[1] 一文中提出的Transformer网络结构最近引起了很多人的关注。Transformer不仅能够明显地提升翻译质量,还为许多NLP任务提供了新的结构。虽然原文写得很清楚,但实际上大家普遍反映很难正确地实现。
所以我们为此…
Spatial Transformer Networks-空间注意力机制
文章目录 前言网络结构 - Spatial Transformer Networks仿射变换spatial transformerLocalisation NetworkParameterised Sampling GridDifferentiable Image SamplingSpatial Transformer Networks对比实验MNIST数据集Street View House Numbers,SVHN数据集Fine-Grained Clas…
Mask Transfiner实例分割算法运行环境的搭建
目录一、算法原理二、算法代码运行(跑预训练模型)1、虚拟机中创建Ubuntu系统2、Ubuntu系统安装Anaconda环境(1)下载(2)安装3、Ubuntu系统安装Pycharm(1)下载(2࿰…
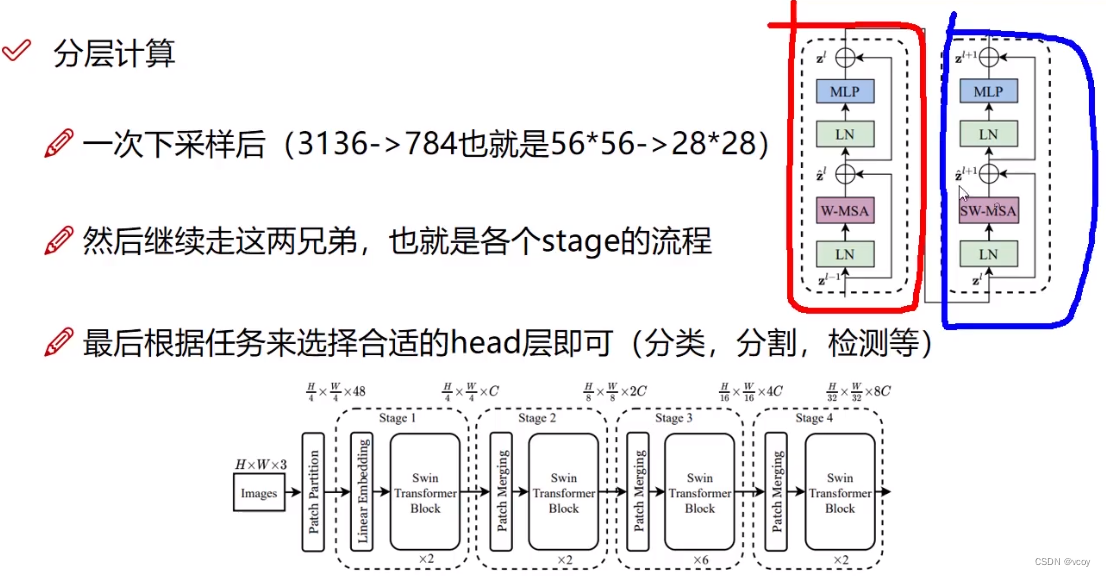
transformer源码
1.传统RNN网络 每一层都需要上一层执行完才能执行 1.1 自注意力 在一句话中找到it_指代的是什么,它的上下文语境是什么? self-attetion计算 1.2 multi-header机制 1.3 堆叠多层self-attention,相当于再一次卷积 1.4 位置信息编码 1.5 残…
Lite transformer
图片以及思想来源请参考论文 Lite Transformer with Long-Short Range Attention 瓶颈结构(bottleneck)是否真的有效
注意力机制被广泛应用在诸多领域,包括自然语言处理,图像处理和视频处理。它通过计算所有输入元素的点积来建模…
【继RNN之后的一项技术】Transfomer 学习笔记
谷歌团队在17年的神作,论文17年6月发布 https://arxiv.org/abs/1706.03762 被NIPS2017收录,目前引用量已经逼近3w。 以下内容参考李沐老师的课程《动⼿学深度学习(Pytorch版)》
简介
注意力 自主性:有目的的搜索某样东西(键&…
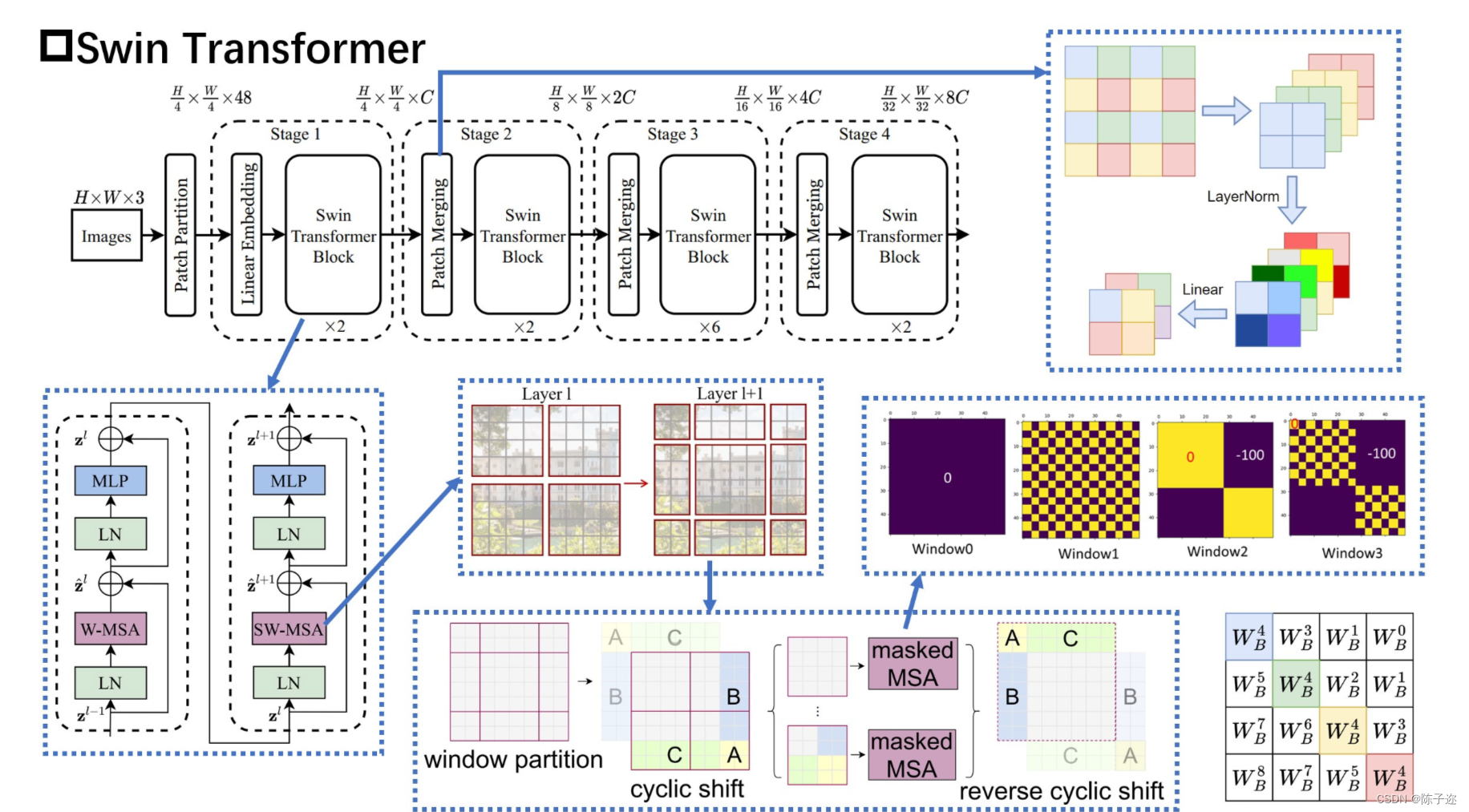
YOLOv5、YOLOv8改进:C3STR(Swin Transformer)
目录
1.介绍
2. YOLOv5、YOLOv8改进
2.1 common.py配置
2.2 yolo.py配置
2.3 yaml配置文件 1.介绍
视觉领域正在见证从 CNN 到 Transformers 的建模转变,纯 Transformer 架构在主要视频识别基准测试中达到了最高准确度。这些视频模型都建立在 Transformer 层之…
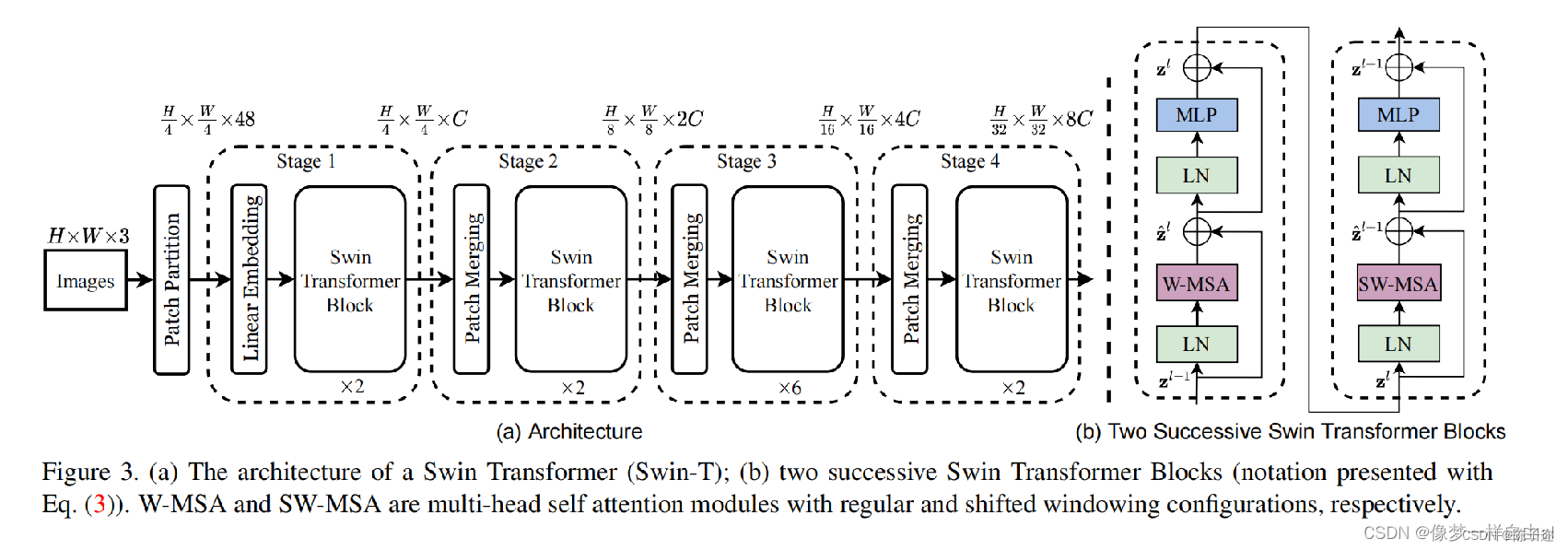
YOLOv5、YOLOv8改进:Swin Transformer-V2
1.介绍
论文地址:https://arxiv.org/abs/2111.09883 综述
该论文作者提出了缩放 Swin Transformer 的技术 多达 30 亿个参数,使其能够使用多达 1,536 个图像进行训练1,536 分辨率。通过扩大容量和分辨率,Swin Transformer 在四个具有代表性…
基于vision transformer的图像分类
一、网络构建 import torch
from torch import nn
from functools import partial# --------------------------------------- #
# (1)patch embeddingimg_size224 : 输入图像的宽高
patch_size16 : 每个patch的宽高,也是卷积核的…

第十章(6):Transformer模型中的参数共享:减少参数量和计算量的优化策略
Transformer模型中的参数共享:减少参数量和计算量的优化策略
作者:安静到无声 个人主页 目录 Transformer模型中的参数共享:减少参数量和计算量的优化策略推荐专栏 在传统的Transformer模型中,每一层都具有相同的结构,…

使用Pytorch从零实现Vision Transformer
在这篇文章中,我们将基于Pytorch框架从头实现Vision Transformer模型,并附录完整代码。
Vision Transformer(ViT)是一种基于Transformer架构的深度学习模型,用于处理计算机视觉任务。它将图像分割成小的图像块(patches),然后使用Transformer编码器来处理这些图像块。V…
YOLOv8改进Swin Transformer:在基础SwinTransformer结构的基础上进行多种改进结构,集成Transformer和CNN的优势
💡本篇内容:YOLOv8改进Swin Transformer:在基础SwinTransformer结构的基础上进行多种改进结构
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:YOLOv8专属
论文理论部分 + 原创最新改进 YOLOv8 代码…
HuggingFace Transformers教程(1)--使用AutoClass加载预训练实例
知识的搬运工又来啦
☆*: .。. o(≧▽≦)o .。.:*☆
【传送门>原文链接:】https://huggingface.co/docs/transformers/autoclass_tutorial 🚗🚓🚕🛺🚙🛻🚌Ƕ…
![[动手学深度学习]注意力机制Transformer学习笔记](https://img-blog.csdnimg.cn/8aee35168bb24f20a7d7ec9d978ec8ba.png)
[动手学深度学习]注意力机制Transformer学习笔记
动手学深度学习(视频):68 Transformer【动手学深度学习v2】_哔哩哔哩_bilibili
动手学深度学习(pdf):10.7. Transformer — 动手学深度学习 2.0.0 documentation (d2l.ai)
李沐Transformer论文逐段精读&a…
交通物流模型 | 基于双向时空自适应Transformer的城市交通流预测
城市交通流预测是智能交通系统的基石。现有方法侧重于时空依赖建模,而忽略了交通预测问题的两个内在特性。首先,不同预测任务的复杂性在不同的空间(如郊区与市中心)和时间(如高峰时段与非高峰时段)上分布不均匀。其次,对过去交通状况的回忆有利于对未来交通状况的预测。基于…
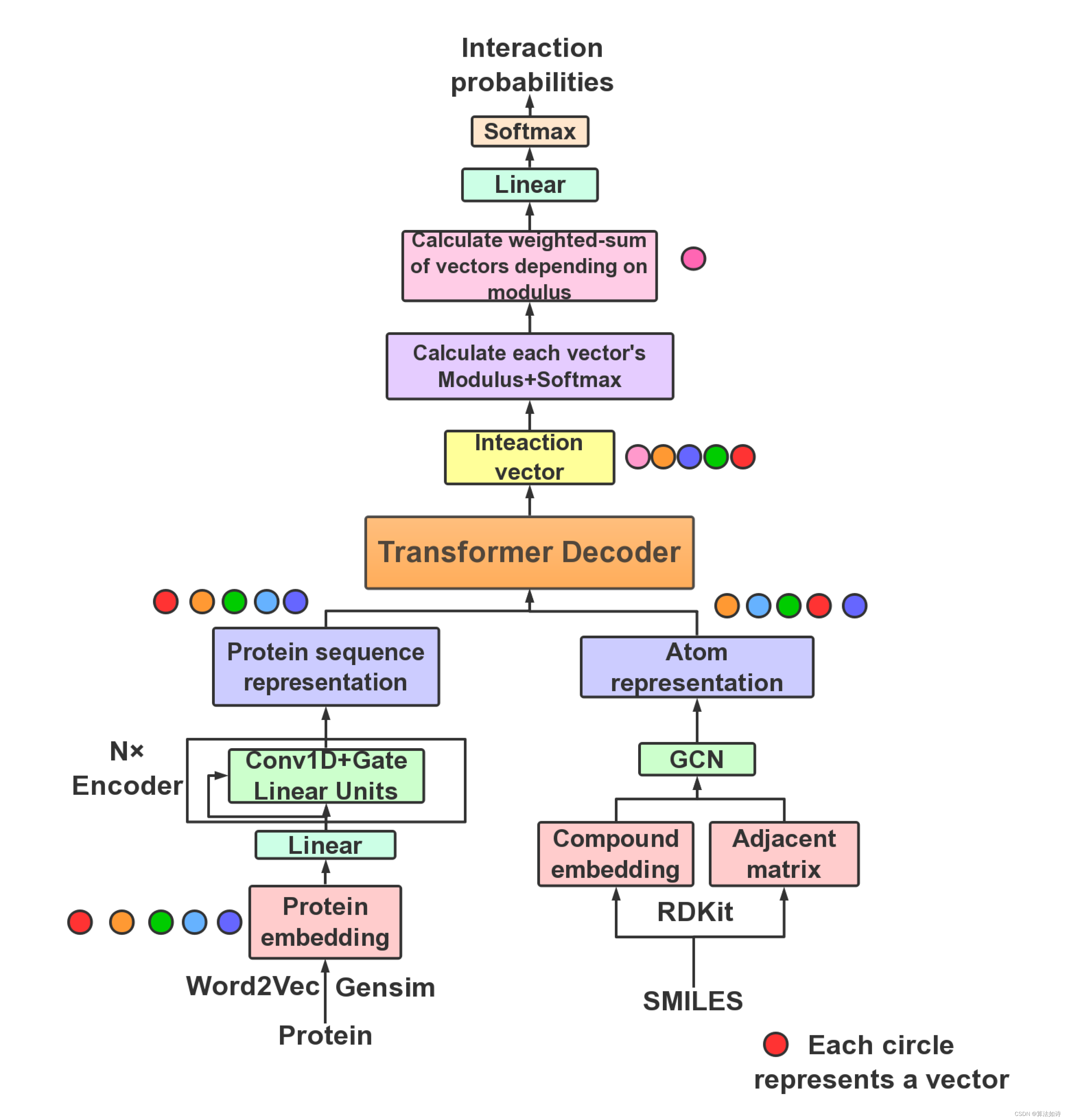
Transformer模型 | Python实现TransformerCPI模型(pytorch)
文章目录 效果一览文章概述程序设计参考资料效果一览 文章概述 Python实现TransformerCPI模型(tensorflow) Dependencies:
python 3.6 pytorch >= 1.2.0 numpy RDkit = 2019.03.3.0 pandas Gensim >=3.4.0
程序设计
import torch
import numpy as np
import random
…

从零开始的Transformers第二篇:代码解析transformer架构
代码解析transformer架构 总体解析输入部分词向量Input Embedding 位置编码编码器自注意力机制掩码多头自注意力机制Feed ForwardLayer Norm残差链接Encoder Layer 解码器输出头总体模型所有代码 总体解析 上面是 transformer 的论文中的架构图,从上面拆分各个模块的…
使用矢量坐标对自然语言建模
模型下载地址 数据集地址 导航 建模代码使用生成代码多个文件累计建模或者增量建模代码随机拼接建模代码
"""
矢量二维坐标建模字符
"""
import numpy as np
import pandas as pd
from tqdm import tqdmdef first_rand_xy()
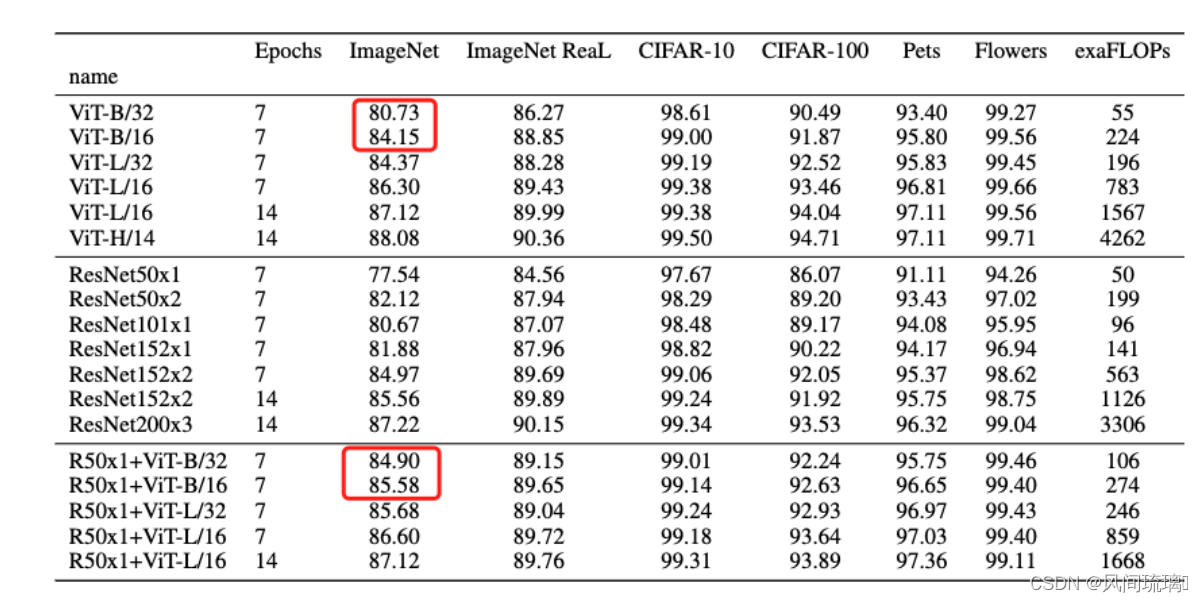
Pytorvh之Vision Transformer图像分类
文章目录 前言一、Transformer1.Transformer概览2.Self-Attention3.Multi-head Attention4.Position-wise Feed-Forward Networks(位置前馈网络)5.残差连接和层归一化6.Positional Encodings(位置编码) 二、Vision Transformer1.Vision Transformer概览2.Embedding层结构&#…
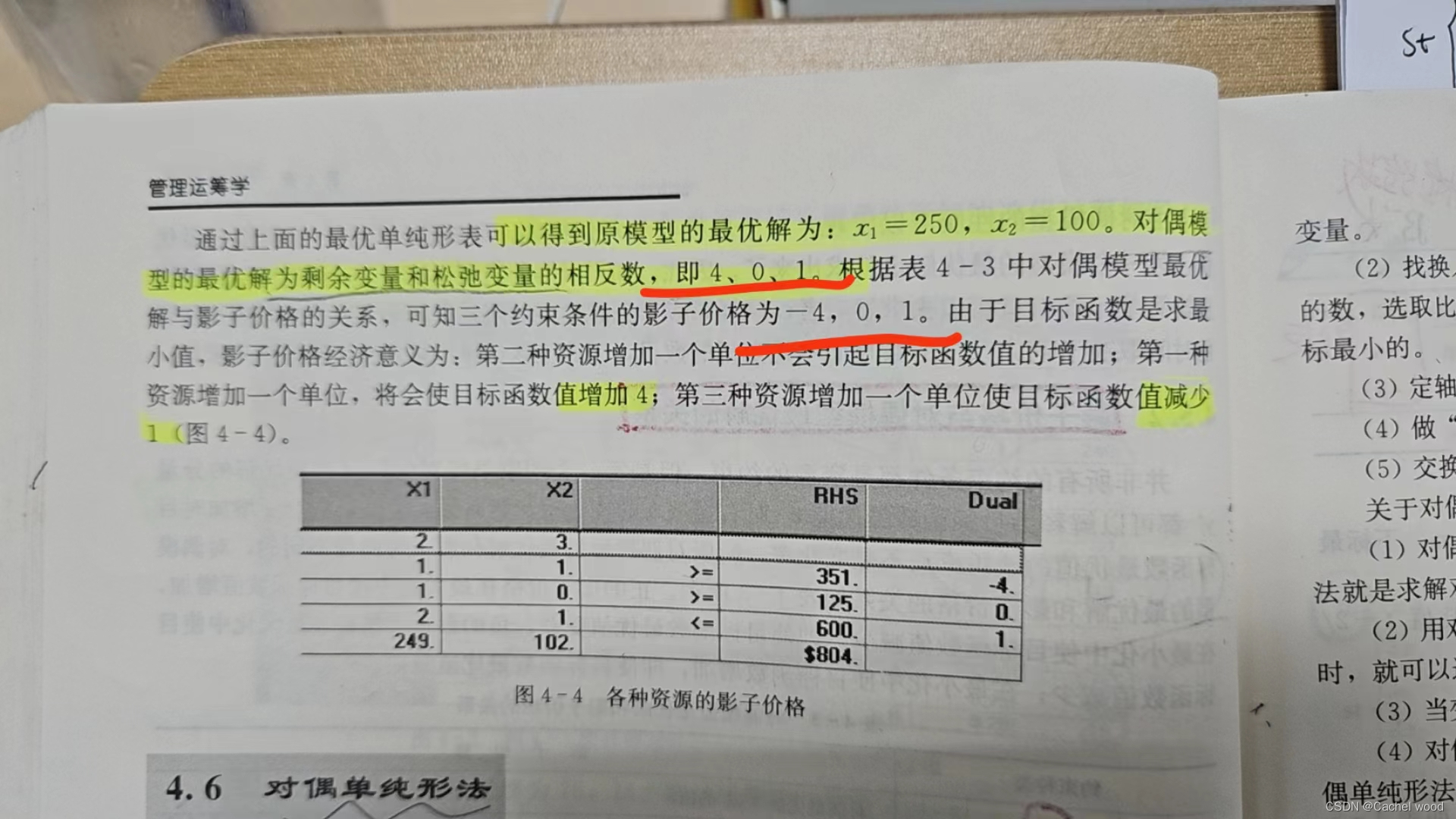
运筹学:影子价格(shadow price)和对偶价格(dual price)
文章目录 对偶问题的解影子价格对偶价格对偶价格与影子价格的关系总结例题 对偶问题的解 影子价格
影子价格是一个经济学意义上的解释,因为不同的解读,目前对于影子价格准确的定义较为混乱。下面下来举几个例子:
the shadow price associat…
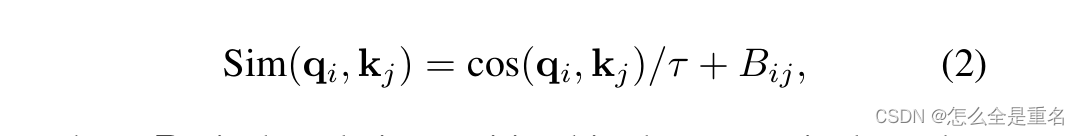
Swin Transformer V2 Scaling Up Capacity and Resolution(CVPR2022)
文章目录 AbstractIntroduction不稳定性问题下游任务需要的高分辨率问题解决内存问题- Related WorksLanguage networks and scaling upVision networks and scaling upTransferring across window / kernel resolution Swin Transformer V2Swin Transformer简介Scaling Up Mod…
Transformer模型 | 用于目标检测的视觉Transformers训练策略
基于视觉的Transformer在预测准确的3D边界盒方面在自动驾驶感知模块中显示出巨大的应用,因为它具有强大的建模视觉特征之间远程依赖关系的能力。然而,最初为语言模型设计的变形金刚主要关注的是性能准确性,而不是推理时间预算。对于像自动驾驶这样的安全关键系统,车载计算机…
HuggingFace 国内下载 阿里云盘下载速度20MB/s
文章目录 效果展示思路阿里云盘API工具 aligo安装aligoaligo教程实战 保存模型到阿里云盘海外服务器下载模型装包aligo的上传代码 国内下载其他方式 效果展示
Huggingface被屏蔽了,根本下载不了。
阿里云盘下载速度最高可达20MB/s,平均17MB/s左右。【注…

19 Transformer 解码器的两个为什么(为什么做掩码、为什么用编码器-解码器注意力)
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html Transformer 的编码器和…

Talk | 香港科技大学博士生叶汉荣:面向2D/3D场景理解的多任务学习
本期为TechBeat人工智能社区第540期线上Talk! 北京时间10月25日(周三)20:00,香港科技大学博士生—叶汉荣的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “面向2D/3D场景理解的多任务学习”,分享了他的团队在多任…
深度学习第四阶段:NLP第二章 Transformer学习笔记
引言1:什么是注意力机制
参考我的一篇文章:https://blog.csdn.net/weixin_42110638/article/details/134011134?csdn_share_tail%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22134011134%22%2C%22source%22%3A%22weixin…
LangChain+LLM实战---BERT和注意力机制中的QKV
BERT主要的创新之处
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,由Google在2018年提出。它的创新之处主要包括以下几个方面:
双向性(Bidirectional&…
DETR纯代码分享(四)misc.py
一、导入部分主要用于引入所需的库和模块
import os
import subprocess
import time
from collections import defaultdict, deque
import datetime
import pickle
from packaging import version
from typing import Optional, Listimport torch
import torch.distributed as…

【多光谱与高光谱图像融合:金字塔混洗Transformer】
PSRT: Pyramid Shuffle-and-Reshuffle Transformer for Multispectral and Hyperspectral Image Fusion
(PSRT:用于多光谱与高光谱图像融合的金字塔混洗Transformer)
Transformer在计算机视觉中受到了很多关注。由于Transformer具有全局自关…
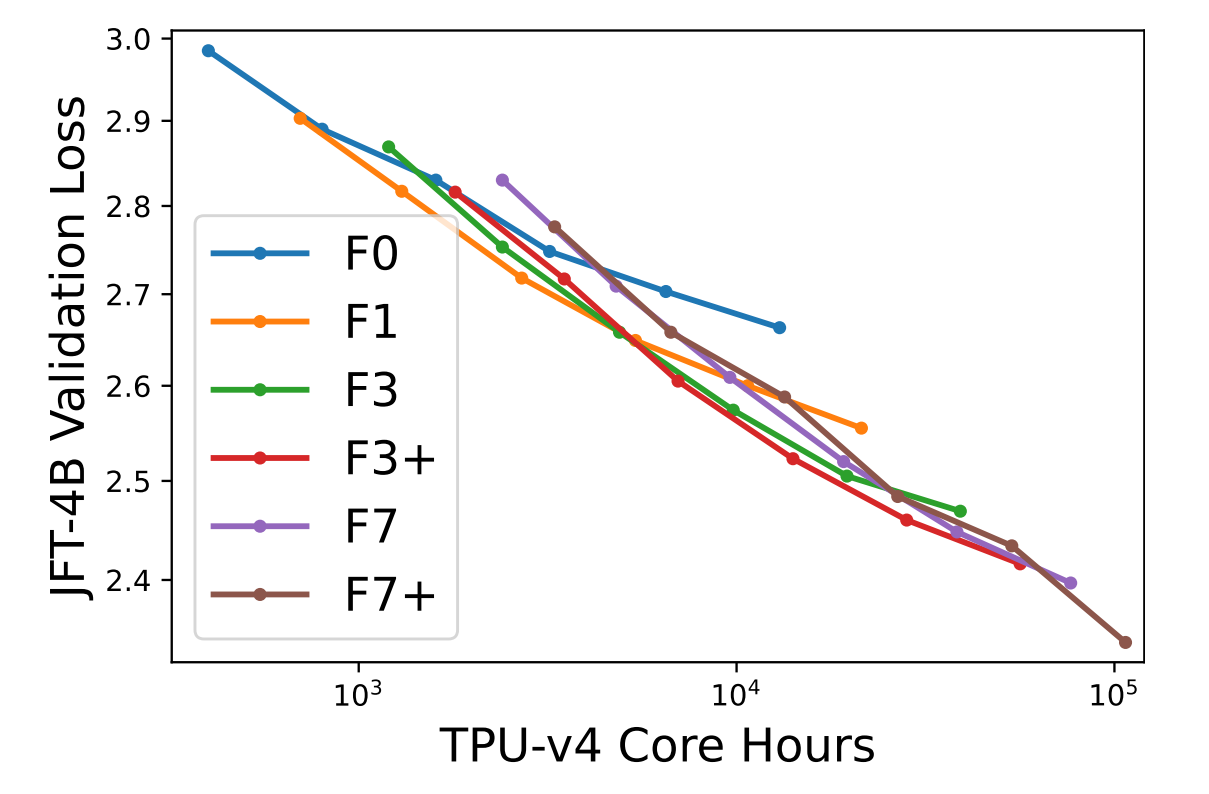
图像分类任务ViT与CNN谁更胜一筹?DeepMind用实验证明
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
今天跟大家分享DeepMind发表的一篇技术报告,通过实验得出,CNN与ViT的架构之间虽然存在差异,但同等计算资源的预…
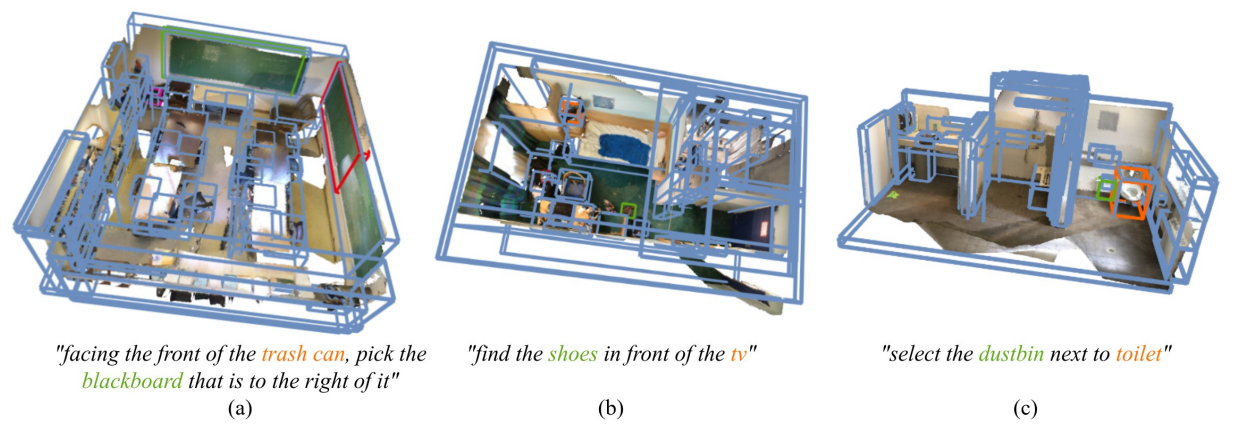
ECCV 22丨BUTD-DETR:图像和点云的语言标定Transformer
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://arxiv.org/abs/2112.08879[1]
主页链接:https://github.com/nickgkan/butd\_detr[2]
摘要:
在二维和三维场景中,大多数模型的任务都是将指涉…
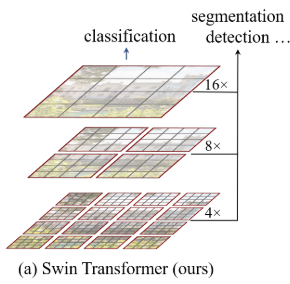
17.基干模型Swin-Transformer解读
文章目录 SWin-Transformer解读1.基础介绍关于Shifted Window based Self-Attention相对位置偏置网络整体结构和层级特征欢迎访问个人网络日志🌹🌹知行空间🌹🌹 SWin-Transformer解读
1.基础介绍
Swin-Transformer是2021年03月微软亚洲研究院提交的论文中提出的,比V…
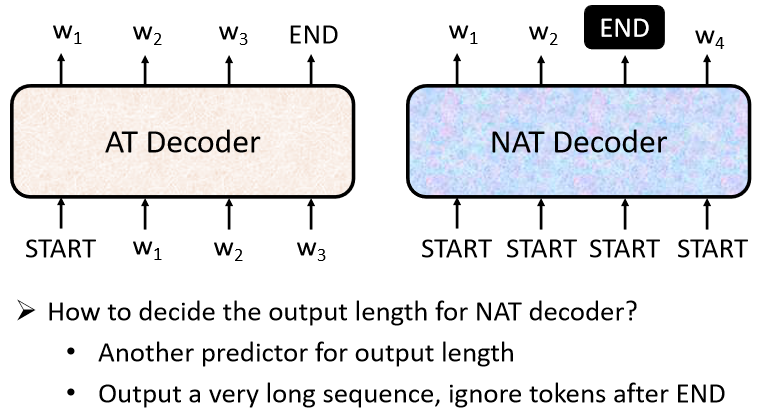
2022最新版-李宏毅机器学习深度学习课程-P32 Transformer
一、 seq2seq 1. 含义
输入一个序列,机器输出另一个序列,输出序列长度由机器决定。
文本翻译:文本至文本; 语音识别:语音至文本; 语音合成:文本至语音; 聊天机器人&#…
llava1.5模型安装、预测、训练详细教程
引言
本博客介绍LLava1.5多模态大模型的安装教程、训练教程、预测教程,也会涉及到hugging face使用与wandb使用。
源码链接:点击这里
demo链接:点击这里
论文链接:点击这里
一、系统环境
ubuntu 20.04 gpu: 2*3090 cuda:11.6
二、LLava环境安装
1、代码下载…
LangChain+LLM实战---部署本地大模型(基于Langchain)
原文:Training Your Own LLM using privateGPT
作者:Wei-Meng Lee 了解如何在不向提供者公开私有数据的情况下训练自己的语言模型 使用公共AI服务(如OpenAI的ChatGPT)的主要问题之一是将您的私人数据暴露给提供商的风险。对于商业用途,这仍然…

文献阅读:LONGNET: Scaling Transformers to 1,000,000,000 Tokens
文献阅读:LONGNET: Scaling Transformers to 1,000,000,000 Tokens 1. 文章简介2. 方法原理 1. 方法思路2. Dilated Attention 1. 具体原理2. 多头实现3. 复杂度分析 3. 训练方法 3. 实验结果4. 结论 & 思考5. 参考链接 文献链接:https://arxiv.org…
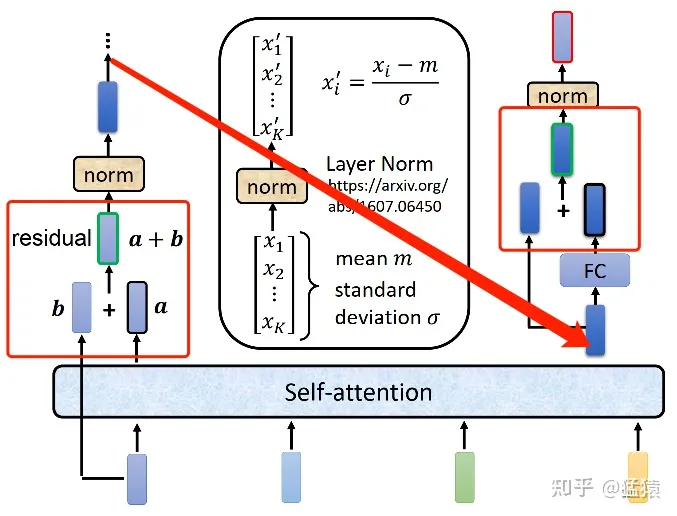
Transformer(二)—— ResNet(残差网络)
Transformer(二)—— ResNet(残差网络) 一、背景1.1 梯度消失/爆炸1.2 网络退化(Degradation) 二、思路2.1 为什么需要更深的网络2.2 理想中的深网络表现 三、实践和实验效果3.1 构造恒等映射:残差学习(res…
论文阅读:LOGO-Former: Local-Global Spatio-Temporal Transformer for DFER(ICASSP2023)
文章目录 摘要动机与贡献具体方法整体架构输入嵌入生成LOGO-Former多头局部注意力多头全局注意力 紧凑损失正则化 实验思考总结 本篇论文
LOGO-Former: Local-Global Spatio-Temporal Transformer for Dynamic Facial Expression Recognition发表在ICASSP(声学顶会…
【Transformer从零开始代码实现 pytoch版】(二)Encoder编码器组件:mask+attention+feed forward+addnorm
Encoder组件
编码器部分:
由N个编码器层堆叠而成每个编码器层由两个子层连接结构组成第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接 (1)Mask…

【Transformer系列】深入浅出理解Transformer网络模型(综合篇)
一、参考资料
The Illustrated Transformer 图解Transformer(完整版) Attention Is All You Need: The Core Idea of the Transformer transformer 总结(超详细-初版) Transformer各层网络结构详解!面试必备!(附代码实现) 大语言…
读书笔记:多Transformer的双向编码器表示法(Bert)-2
多Transformer的双向编码器表示法
Bidirectional Encoder Representations from Transformers,即Bert;
第2章 了解Bert模型(掩码语言模型构建和下句预测)
文本嵌入模型Bert,在许多自然语言处理任务上表现优秀&#…

时间序列预测实战(十四)Transformer模型实现长期预测并可视化结果(附代码+数据集+原理介绍)
论文地址->Transformer官方论文地址
官方代码地址->暂时还没有找到有官方的Transformer用于时间序列预测的代码地址
个人修改地址-> Transformer模型下载地址CSDN免费
一、本文介绍
这篇文章给大家带来是Transformer在时间序列预测上的应用,这种模型最…
未来之路:大模型技术在自动驾驶的应用与影响
本文深入分析了大模型技术在自动驾驶领域的应用和影响,万字长文,慢慢观看~
文中首先概述了大模型技术的发展历程,自动驾驶模型的迭代路径,以及大模型在自动驾驶行业中的作用。接着,详细介绍了大模型的基本定义、基础功…
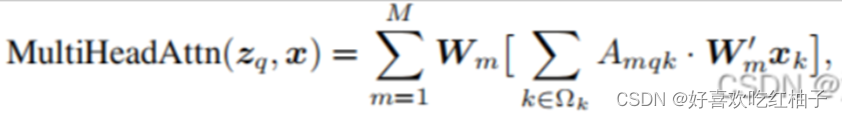
注意力机制(Attention)、自注意力机制(Self Attention)和多头注意力(Multi-head Self Attention)机制详解
目录 参考一、Attention注意力机制原理计算过程 二、自注意力机制2.1 自注意力关键!!2.2 实现步骤1. 获取 K Q V2. MatMul3. scale softmax归一化4. MalMul 2.3 自注意力机制的缺陷 三、多头自注意力机制3.1 简介3.2 实现步骤3.3 公式 参考
感谢我的互…

TrOCR模型微调【基于transformer的光学字符识别】
TrOCR(基于 Transformer 的光学字符识别)模型是性能最佳的 OCR 模型之一。 在我们之前的文章中,我们分析了它们在单行打印和手写文本上的表现。 然而,与任何其他深度学习模型一样,它们也有其局限性。 TrOCR 在处理开箱…
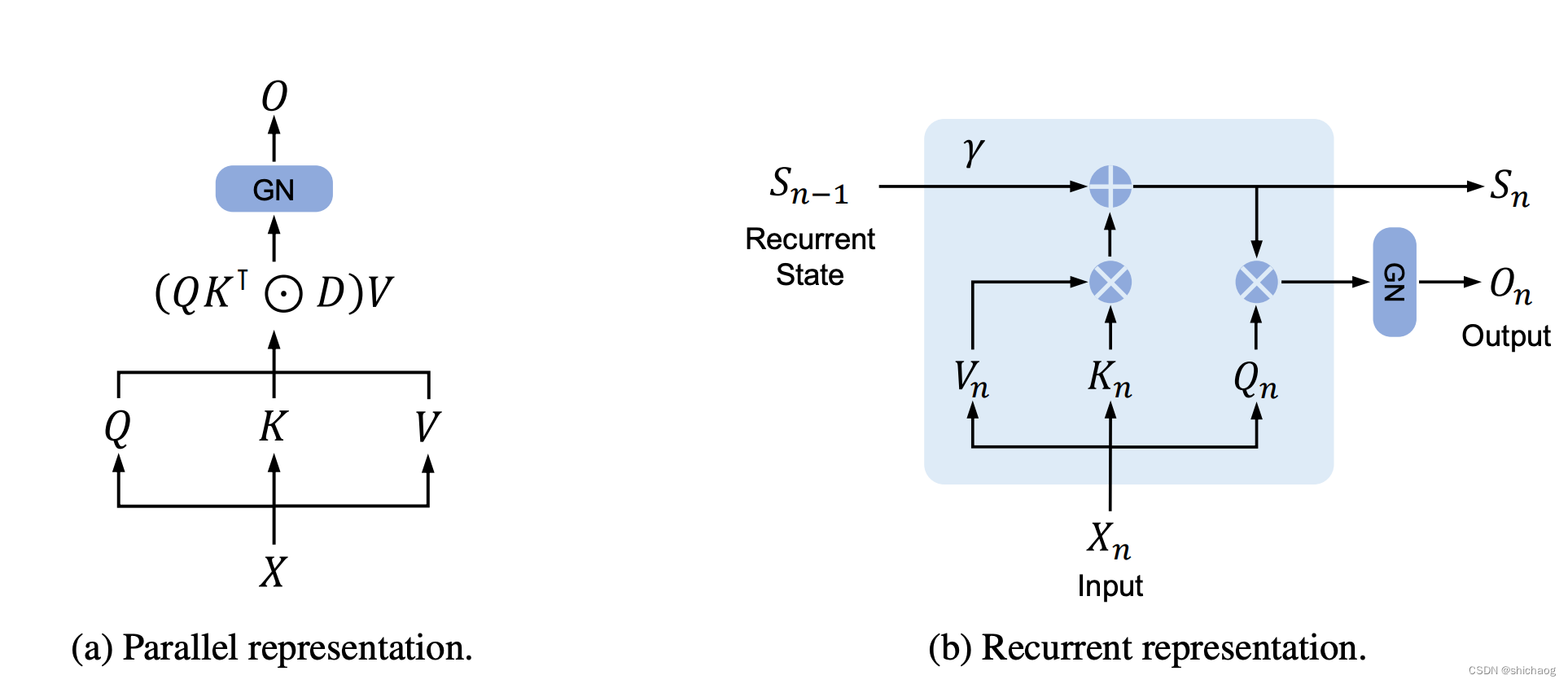
大语言模型之十一 Transformer后继者Retentive Networks (RetNet)
在《大语言模型之四-LlaMA-2从模型到应用》的LLama-2推理图中可以看到,在输入“你好!”时,是串行进行的,即先输入“你”这个token,然后是“好”,再然后是“!”token,前一个token需要…
【学习笔记】多模态综述
多模态综述 前言1. CLIP & ViLT2. ALBEF3. VLMO4. BLIP5. CoCa6. BeiTv3总结参考链接 前言
本篇学习笔记虽然是多模态综述,本质上是对ViLT后多模态模型的总结,时间线为2021年至2022年,在这两年,多模态领域的模型也是卷的飞起…
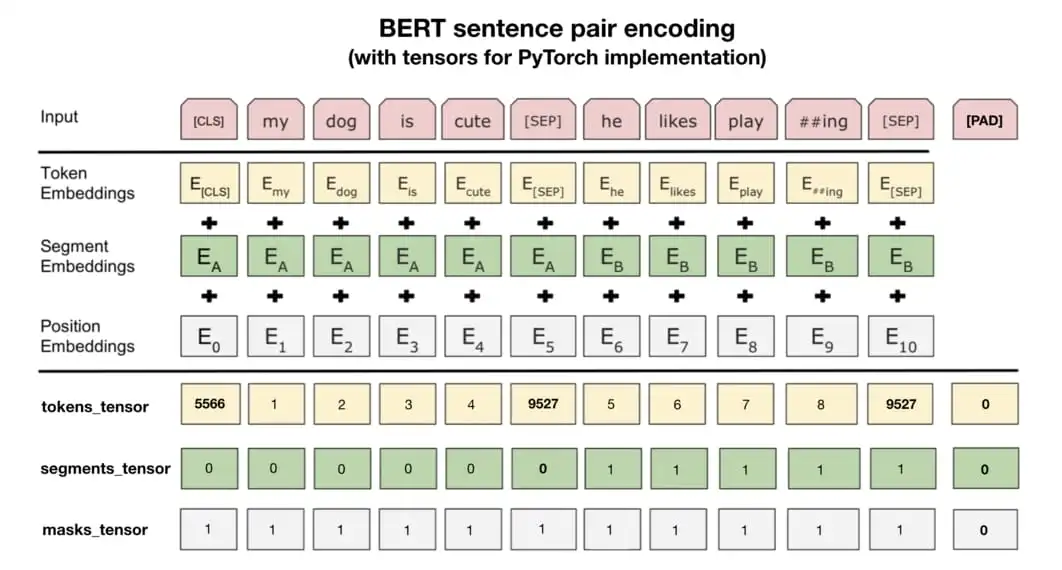
BERT: 面向语言理解的深度双向Transformer预训练
参考视频: BERT 论文逐段精读【论文精读】_哔哩哔哩_bilibili 背景
BERT算是NLP里程碑式工作!让语言模型预训练出圈!
使用预训练模型做特征表示的时候一般有两类策略:
1. 基于特征 feature based (Elmo)…
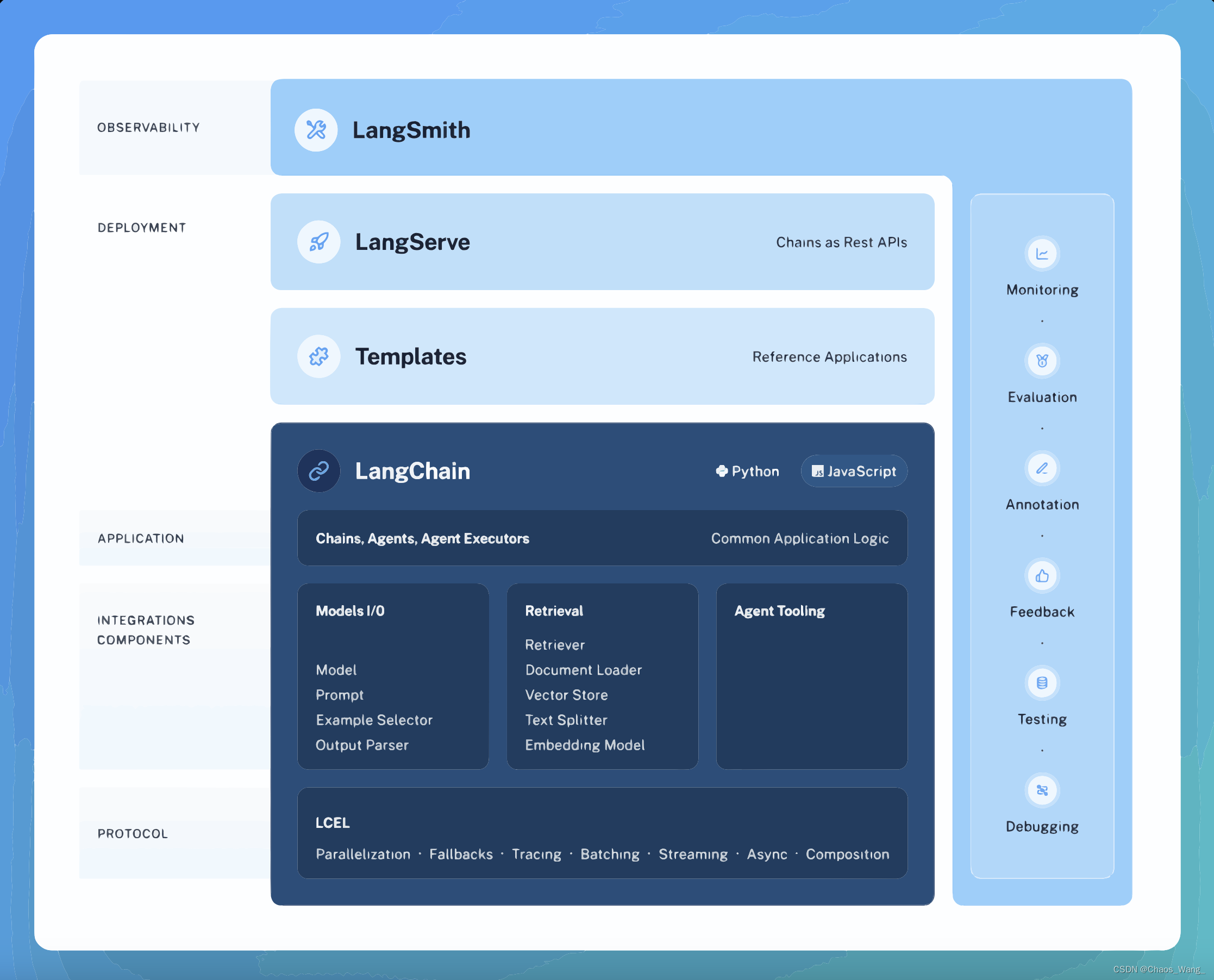
LangChain库简介
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…
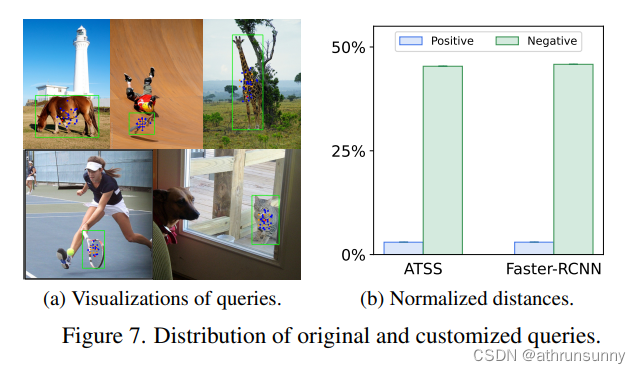
Co-DETR:DETRs与协同混分配训练论文学习笔记
论文地址:https://arxiv.org/pdf/2211.12860.pdf 代码地址: GitHub - Sense-X/Co-DETR: [ICCV 2023] DETRs with Collaborative Hybrid Assignments Training 摘要
作者提出了一种新的协同混合任务训练方案,即Co-DETR,以从多种标…
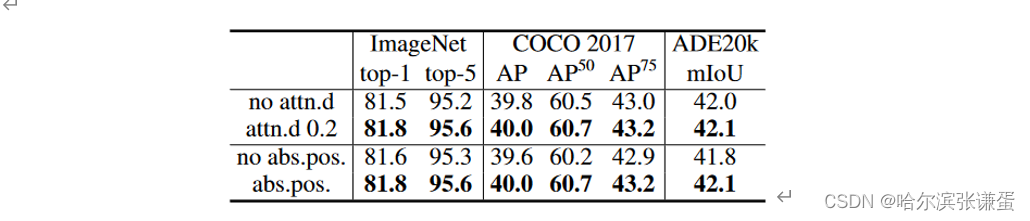
深度学习之图像分类(十四)CAT: Cross Attention in Vision Transformer详解
IPSA和CPSA的处理流程、维度变换细节 FLOPs的计算方法、以及flops和划分的patch数目以及patch的维度计算关系 IPSA如何进行local attention、CPSA如何进行globe attention CAT的代码详细注释---需要学习完Transformer TNT、swin transformer、crossViT
CAT: Cross Atten…

大一统模型 Universal Instance Perception as Object Discovery and Retrieval 论文阅读笔记
Universal Instance Perception as Object Discovery and Retrieval 论文阅读笔记 一、Abstract二、引言三、相关工作实例感知通过类别名进行检索通过语言表达式的检索通过指代标注的检索 统一的视觉模型Unified Learning ParadigmsUnified Model Architectures 四、方法4.1 Pr…
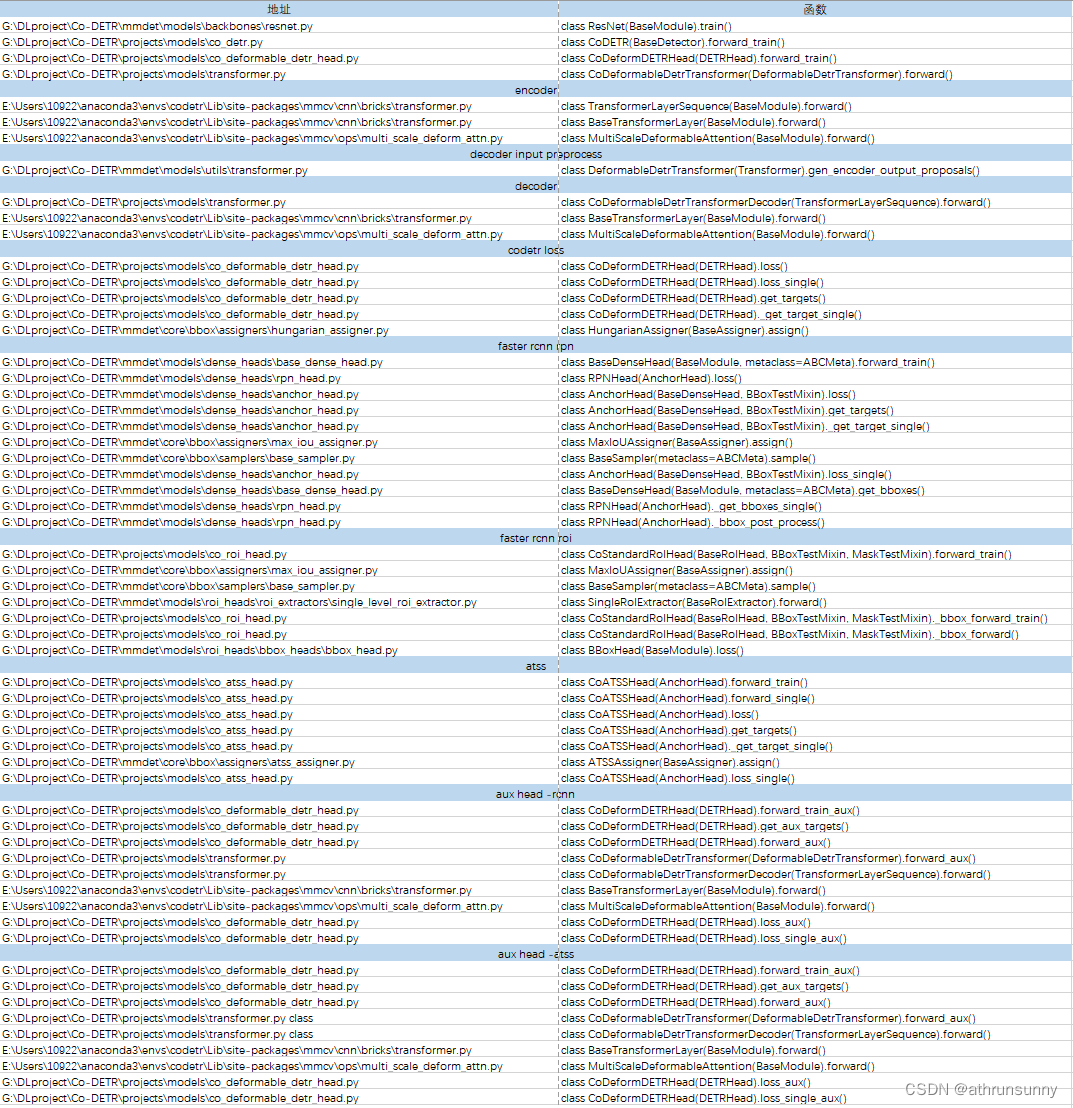
Co-DETR:DETRs与协同混合分配训练代码学习笔记
关于论文的学习笔记:Co-DETR:DETRs与协同混合分配训练论文学习笔记-CSDN博客 作者提出了一种新的协同混合任务训练方案,即Co-DETR,以从多种标签分配方式中学习更高效的基于detr的检测器。这种新的训练方案通过训练ATSS和Faster RCNN等一对多标…
详解RT-DETR网络结构/数据集获取/环境搭建/训练/推理/验证/导出/部署
论文地址:RT-DETR论文地址
代码地址:RT-DETR官方下载地址 目录
一、本文介绍
二、RT-DETR的网络结构
2.1、模型概览
2.2、高效混合编码器
2.3、IoU感知查询选择
2.4、 可扩展的RT-DETR
三、RT-DERT的环境搭建
四、免费数据集获取
五、获取RT-D…
RT-DETR论文阅读笔记(包括YOLO版本训练和官方版本训练)
论文地址:RT-DETR论文地址
代码地址:RT-DETR官方下载地址 大家如果想看更详细训练、推理、部署、验证等教程可以看我的另一篇博客里面有更详细的介绍 内容回顾:详解RT-DETR网络结构/数据集获取/环境搭建/训练/推理/验证/导出/部署 目录
一…
多模态大模型总结1(2021和2022年)
常用损失函数
ITC (image-text contrasctive loss)
CLIP中采用的对比损失,最大化配对文本对的余弦相似度,最小化非配对文本对的余弦相似度,采用交叉熵损失实现
MLM (masked language modeling࿰…
BEV+Transformer架构加速“上车”,智能驾驶市场变革开启
BEVTransformer成为了高阶智能驾驶领域最为火热的技术趋势。
近日,在2023年广州车展期间,不少车企及智能驾驶厂商都发布了BEVTransformer方案。其中,极越01已经实现了“BEVTransformer”的“纯视觉”方案的量产,成为国内唯一量产…
【nlp】4.4 Transformer库的使用(管道模式pipline、自动模式auto,具体模型BertModel)
Transformer库的使用 1 了解Transformers库2 Transformers库三层应用结构3 管道方式完成多种NLP任务3.1 文本分类任务3.2 特征提取任务3.3 完型填空任务3.4 阅读理解任务3.5 文本摘要任务3.6 NER任务4 自动模型方式完成多种NLP任务4.1 文本分类任务4.2 特征提取任务4.3 完型填空…
深入理解Transformer,兼谈MHSA(多头自注意力)、LayerNorm、FFN、位置编码
Attention Is All You Need——集中一下注意力
Transformer其实不是完全的Self-Attention结构,还带有残差连接、LayerNorm、类似1维卷积的Position-wise Feed-Forward Networks(FFN)、MLP和Positional Encoding(位置编码…

AIGC系列之:Vision Transformer原理及论文解读
目录
相关资料
模型概述
Patch to Token
Embedding
Token Embedding
Position Embedding
ViT总结 相关资料
论文链接:https://arxiv.org/pdf/2010.11929.pdf
论文源码:https://github.com/google-research/vision_transformer
PyTorch实现代码…
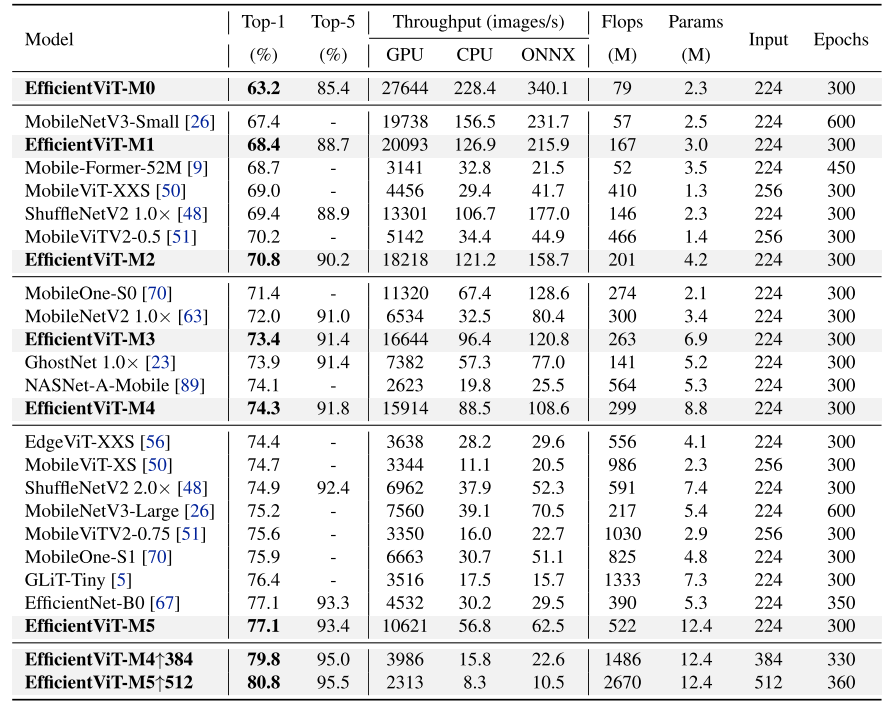
EfficientViT:具有级联群体注意力的内存高效Transformer
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention 1、介绍2、使用 Vision Transformer 加快速度2.1 内存效率2.2 计算效率2.3 参数效率 3、Efficient Vision Transformer3.1 EfficientViT 构建模块3.3 EfficientViT 网络架构 4、实验5、结论 …

用于图像分类任务的经典神经网络综述
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活&…
Co-DETR:DETRs与协同混合分配训练论文学习笔记
论文地址:https://arxiv.org/pdf/2211.12860.pdf 代码地址: GitHub - Sense-X/Co-DETR: [ICCV 2023] DETRs with Collaborative Hybrid Assignments Training 摘要
作者提出了一种新的协同混合任务训练方案,即Co-DETR,以从多种标…
用通俗的方式讲解Transformer:从Word2Vec、Seq2Seq逐步理解到GPT、BERT
直到今天早上,刷到CSDN一篇讲BERT的文章,号称一文读懂,我读下来之后,假定我是初学者,读不懂。
关于BERT的笔记,其实一两年前就想写了,迟迟没动笔的原因是国内外已经有很多不错的资料࿰…
5 时间序列预测入门:LSTM+Transformer
0 引言 论文地址:https://arxiv.org/abs/1706.03762 1 Transformer Transformer 模型是一种用于处理序列数据的深度学习模型,主要用于解决自然语言处理(NLP)任务。它在许多 NLP 任务中取得了重大突破,如机器翻译、文本…
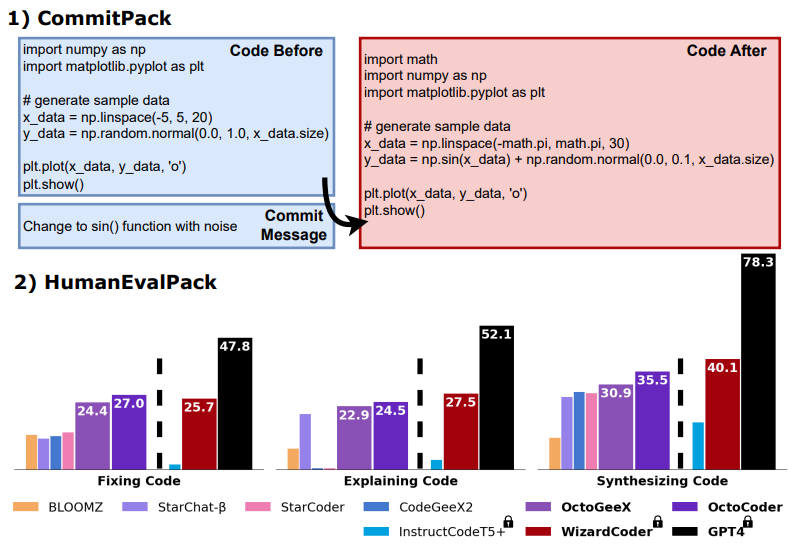
48个代码大模型汇总,涵盖原始、改进、专用、微调4大类
代码大模型具有强大的表达能力和复杂性,可以处理各种自然语言任务,包括文本分类、问答、对话等。这些模型通常基于深度学习架构,如Transformer,并使用预训练目标(如语言建模)进行训练。
在对大量代码数据的…
YOLOv8改进 | 2023 | DWRSeg扩张式残差助力小目标检测 (附修改后的C2f+Bottleneck)
论文地址:官方论文地址
代码地址:该代码目前还未开源,我根据论文内容进行了复现内容在文章末尾。 一、本文介绍
本文内容给大家带来的DWRSeg中的DWR模块来改进YOLOv8中的C2f和Bottleneck模块,主要针对的是小目标检测,…
![[论文阅读]CT3D——逐通道transformer改进3D目标检测](https://img-blog.csdnimg.cn/direct/6448668c9e2d4c8a8b021533d303ea9b.png)
[论文阅读]CT3D——逐通道transformer改进3D目标检测
CT3D
论文网址:CT3D 论文代码:CT3D
简读论文
本篇论文提出了一个新的两阶段3D目标检测框架CT3D,主要的创新点和方法总结如下:
创新点:
(1) 提出了一种通道注意力解码模块,可以进行全局和局部通道聚合,生成更有效的解码权重。
(2) 提出了建议到点嵌…
Transformer代码实例中各张量的维度是多少
一下是一个Transformer代码实例:
def sample(self, batch_size, max_length140, con_token_list [is_JNK3, is_GSK3, high_QED, good_SA]):"""Sample a batch of sequencesArgs:batch_size : Number of sequences to samplemax_length: Maximum le…
![[transformer]论文实现:Attention Is All You Need](https://img-blog.csdnimg.cn/367669a39f874e1994a156cf9fb88fbc.png)
[transformer]论文实现:Attention Is All You Need
Attention Is All You Need 一、完整代码二、论文解读2.1 模型架构2.2 位置编码2.3 残差连接和层归一化2.4 注意力机制2.5 前馈神经网络 三、过程实现3.1 安装包和导包3.2 数据准备3.3 词嵌入和位置编码3.4 注意力机制3.5 前馈神经网络3.6 编码器3.7 解码器3.8 Transformer3.9 …

Learning reliable modal weight with transformer for robust RGBT tracking
论文:《Learning reliable modal weight with transformer for robust RGBT tracking》 针对问题:局部线性匹配容易丢失语义信息 解决方法:为了增强特征表示和深化语义特征,分别设计了一种基于改进的Resnet-50的模态权值分配策略…
【Transformer从零开始代码实现 pytoch版】各个部件详细分析代码合集
构建合集
【Transformer从零开始代码实现 pytoch版】(一)输入部件:embeddingpositionalEncoding
【Transformer从零开始代码实现 pytoch版】(二)Encoder编码器组件:mask attention feed forward add&a…
python图神经网络,注意力机制、Transformer模型、目标检测算法、强化学习等
近年来,伴随着以卷积神经网络(CNN)为代表的深度学习的快速发展,人工智能迈入了第三次发展浪潮,AI技术在各个领域中的应用越来越广泛
本文重点为:注意力机制、Transformer模型(BERT、GPT-1/2/3/…

Accelerate 0.24.0文档 三:超大模型推理(内存估算、Sharded checkpoints、bitsandbytes量化、分布式推理)
文章目录 一、内存估算1.1 Gradio Demos1.2 The Command 二、使用Accelerate加载超大模型2.1 模型加载的常规流程2.2 加载空模型2.3 分片检查点(Sharded checkpoints)2.4 示例:使用Accelerate推理GPT2-1.5B2.5 device_map 三、bitsandbytes量…

Attention Transformer
来源老师课件,方便以后复习。 课参考链接: http://jalammar.github.io/illustrated-transformer/
之前的知识链接: 【知识链接】WGAN Transformer Vit Swin-Transformer Swin-Unet Res-Vit TransUNet MAE Bra ADDA 打分函数: 多头…

全连接层及其注意力attention的参数量和计算量分析
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活&…

Attention机制学习
写在前面 注意力机制是一个很不错的科研创新点方向,但是没有系统记录过学习过程,这里记录科研中遇到的各种注意力机制。 1. Attention机制解释
本质上来说用到attention的任务都有Query,Key,Value三个关键components,…
风速预测(四)基于Pytorch的EMD-Transformer模型
目录
前言
1 风速数据EMD分解与可视化
1.1 导入数据
1.2 EMD分解
2 数据集制作与预处理
2.1 先划分数据集,按照8:2划分训练集和测试集
2.2 设置滑动窗口大小为7,制作数据集
3 基于Pytorch的EMD-Transformer模型预测
3.1 数据加载&am…
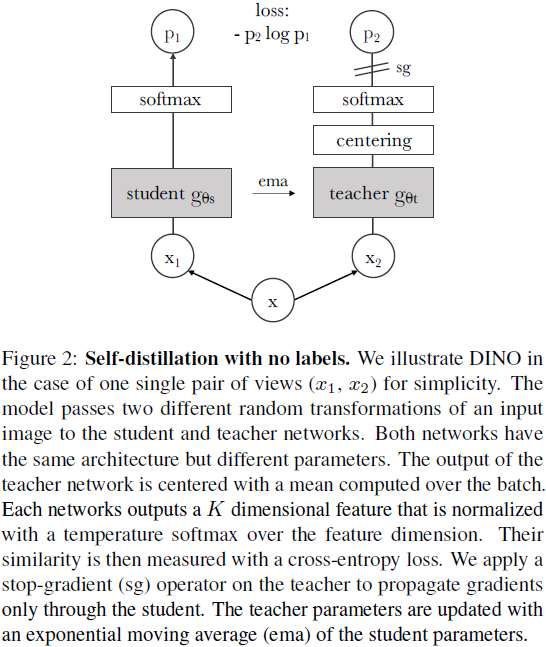
(2021|ICCV,DINO,ViT,自监督学习,知识蒸馏)自监督视觉 Transformer 的新特性
Emerging Properties in Self-Supervised Vision Transformers
公纵号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
1. 简介
2. 相关工作
3. 方法
3.1. 自监督学习与知识蒸馏 …

Swin-Transformer 在图像识别中的应用
1. 卷积神经网络简单介绍
图像识别任务主要利用神经网络对图像进行特征提取,最后通过全连接层将特征和分类个数进行映射。传统的网络是利用线性网络对图像进行分类,然而图像信息是二维的,一般来说,图像像素点和周围邻域像素点相关…
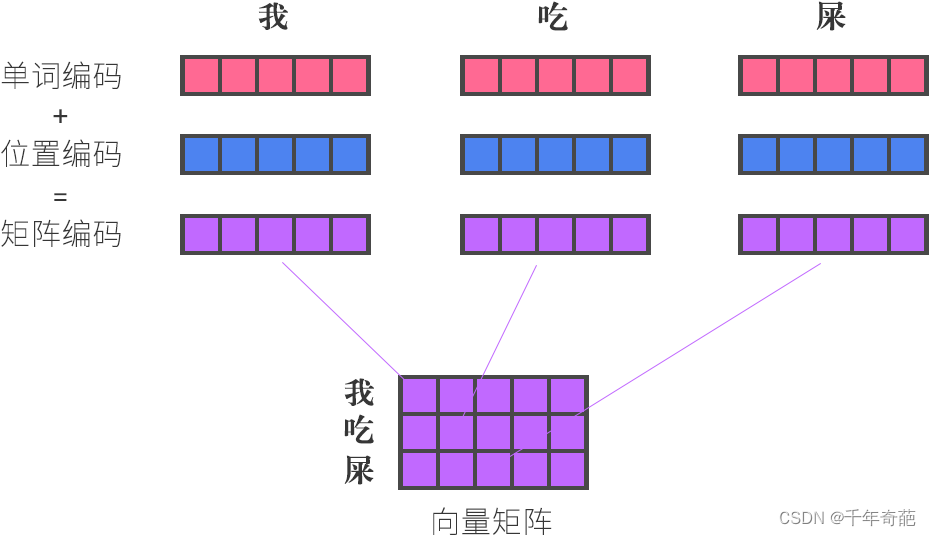
Ai 算法之Transformer 模型的实现: 一 、Input Embedding模块和Positional Embedding模块的实现
一 文章生成模型简介
比较常见的文章生成模型有以下几种:
RNN:循环神经网络。可以处理长度变化的序列数据,比如自然语言文本。RNN通过隐藏层中的循环结构来传递时间序列中的信息,从而使当前的计算可以参照之前的信息。但这种模型…

图像识别完整项目之Swin-Transformer,从获取关键词数据集到训练的完整过程
0. 前言
图像分类的大部分经典神经网络已经全部介绍完,并且已经作了测试 代码已经全部上传到资源,根据文章名或者关键词搜索即可 LeNet :pytorch 搭建 LeNet 网络对 CIFAR-10 图片分类
AlexNet : pytorch 搭建AlexNet 对花进行分…
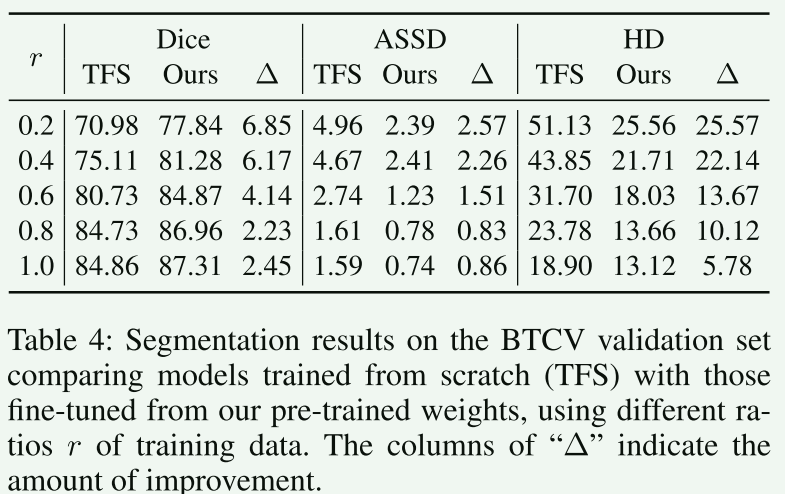
【论文阅读笔记】Pre-trained Universal Medical Image Transformer
Luo L, Chen X, Tang B, et al. Pre-trained Universal Medical Image Transformer[J]. arXiv preprint arXiv:2312.07630, 2023.【代码开源】
【论文概述】
本文介绍了一种名为“预训练通用医学图像变换器(Pre-trained Universal Medical Image Transformer&…

深度学习的十大核心算法
引言
深度学习是人工智能领域中最热门和最具影响力的分支之一。其核心在于通过构建复杂的神经网络模型,从大量的数据中自动学习并提取出有用的特征,从而实现各种高级的任务,如图像识别、自然语言处理等。本文将介绍深度学习中的十大核心算法…
论文解读:Informer-AAAI2021年最佳论文
论文背景
应用背景
训练的是历史数据,但预测的是未来的数据,但是历史数据和未来数据的分布不一定是一样的,所以时间序列应用于股票预测往往不太稳定
动作预测: 基于之前的视频中每一帧动作,预测下一帧这个人要做什么…
视频姿态估计:DeciWatch
DeciWatch: A Simple Baseline for 10 Efficient 2D and 3D Pose Estimation解析 摘要1. 简介2. Related Work2.1 高效的人体姿态估计2.2 Motion Completion(运动补全)3. Method3.1 问题定义和概述3.2 获取采样姿势3.3 Denoising the Sampled Poses(去噪采样的姿态)3.4 Rec…
Cross-Drone Transformer Network for Robust Single Object Tracking论文阅读笔记
Cross-Drone Transformer Network for Robust Single Object Tracking论文阅读笔记
Abstract
无人机在各种应用中得到了广泛使用,例如航拍和军事安全,这得益于它们与固定摄像机相比的高机动性和广阔视野。多无人机追踪系统可以通过从不同视角收集互补的…

工具系列:TimeGPT_(1)获取token方式和初步使用
文章目录 介绍获取Token用法数据的重要要求使用DateTime索引推断频率。 介绍
Nixtla的TimeGPT是一种用于时间序列数据的生成式预训练预测模型。TimeGPT可以在没有训练的情况下,仅使用历史值作为输入,为新的时间序列生成准确的预测。TimeGPT可以用于各种…
工具系列:TimeGPT_(6)同时预测多个时间序列
TimeGPT提供了一个强大的多系列预测解决方案,它涉及同时分析多个数据系列,而不是单个系列。该工具可以使用广泛的系列进行微调,使您能够根据自己的特定需求或任务来定制模型。
# Import the colab_badge module from the nixtlats.utils pac…
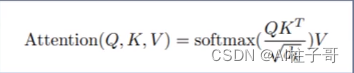
【AI】计算机视觉VIT文章(Transformer)源码解析
论文:Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020
源码的Pytorch版:https://github.com/lucidrains/vit-pytorch
0.前言 …
Keras实现Transformer
# 导入所需的库
import numpy as np
from keras.models import Model
from keras.layers import Input, Dense, Embedding, MultiHeadAttention
from keras.optimizers import Adam# 定义模型参数
vocab_size 10000 # 词汇表大小
embedding_dim 256 # 嵌入维度
num_heads …
对 Vision Transformers 及其基于 CNN-Transformer 的变体的综述
A survey of the Vision Transformers and its CNN-Transformer based Variants 摘要1、介绍2、vit的基本概念2.1 patch嵌入2.2 位置嵌入2.2.1 绝对位置嵌入(APE)2.2.2 相对位置嵌入(RPE)2.2.3卷积位置嵌入(CPE) 2.3 注意力机制2.3.1多头自我注意(MSA) 2.4 Transformer层2.4.1 …

【HuggingFace Transformer库学习笔记】基础组件学习:Tokenizer
基础组件——Tokenizer (1)模型加载
from transformers import AutoTokenizersen "弱小的我也有大梦想!"
# 从HuggingFace加载,输入模型名称,即可加载对于的分词器
tokenizer AutoTokenizer.from_pretrained("m…
【NeurIPS 2023】PromptIR: Prompting for All-in-One Blind Image Restoration
PromptIR: Prompting for All-in-One Blind Image Restoration, NeurIPS 2023
论文:https://arxiv.org/abs/2306.13090
代码:https://github.com/va1shn9v/promptir
解读:即插即用系列 | PromptIR:MBZUAI提出一种基…
深度学习中的Transformer机制
Transformer 是一种深度学习模型结构,最初由Vaswani等人于2017年提出,用于自然语言处理任务,尤其是机器翻译。Transformer 引入了自注意力机制(self-attention mechanism),这是其在处理序列数据时的关键创新…

llama.cpp部署通义千问Qwen-14B
llama.cpp是当前最火热的大模型开源推理框架之一,支持了非常多的LLM的量化推理,生态比较完善,是个人学习和使用的首选。最近阿里开源了通义千问大语言模型,在众多榜单上刷榜了,是当前最炙手可热的开源中文大语言模型。…
![[RoFormer]论文实现:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING](https://img-blog.csdnimg.cn/direct/3225793bcde54836b6d438d3c796f44b.png)
[RoFormer]论文实现:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
文章目录 一、完整代码二、论文解读2.1 注意力机制2.2 绝对位置编码2.3 相对位置编码2.4 旋转位置编码Long-term decayAdaption for linear attention 2.5 模型效果 三、过程实现四、整体总结 论文:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING …
GPU深度学习性能的三驾马车:Tensor Core、内存带宽与内存层次结构
编者按:近年来,深度学习应用日益广泛,其需求也在快速增长。那么,我们该如何选择合适的 GPU 来获得最优的训练和推理性能呢? 今天,我们为大家带来的这篇文章,作者的核心观点是:Tensor…

Pytorch CIFAR10图像分类 Swin Transformer篇
Pytorch CIFAR10图像分类 Swin Transformer篇 文章目录 Pytorch CIFAR10图像分类 Swin Transformer篇4. 定义网络(Swin Transformer)Swin Transformer整体架构Patch MergingW-MSASW-MSARelative position biasSwin Transformer 网络结构Patch EmbeddingP…
玩转Omniverse | 将FBX文件导入Omniverse View,以及step等3D格式如何转换为USD文件的过程
1,参考这个过程,玩转Omniverse | 将FBX文件导入Omniverse View 2,实际操作: 在omniverse中安装usd explorer 打开usd explorer 选择step,然后右键选择convert to USD,点击确认,稍等一会就会转换…
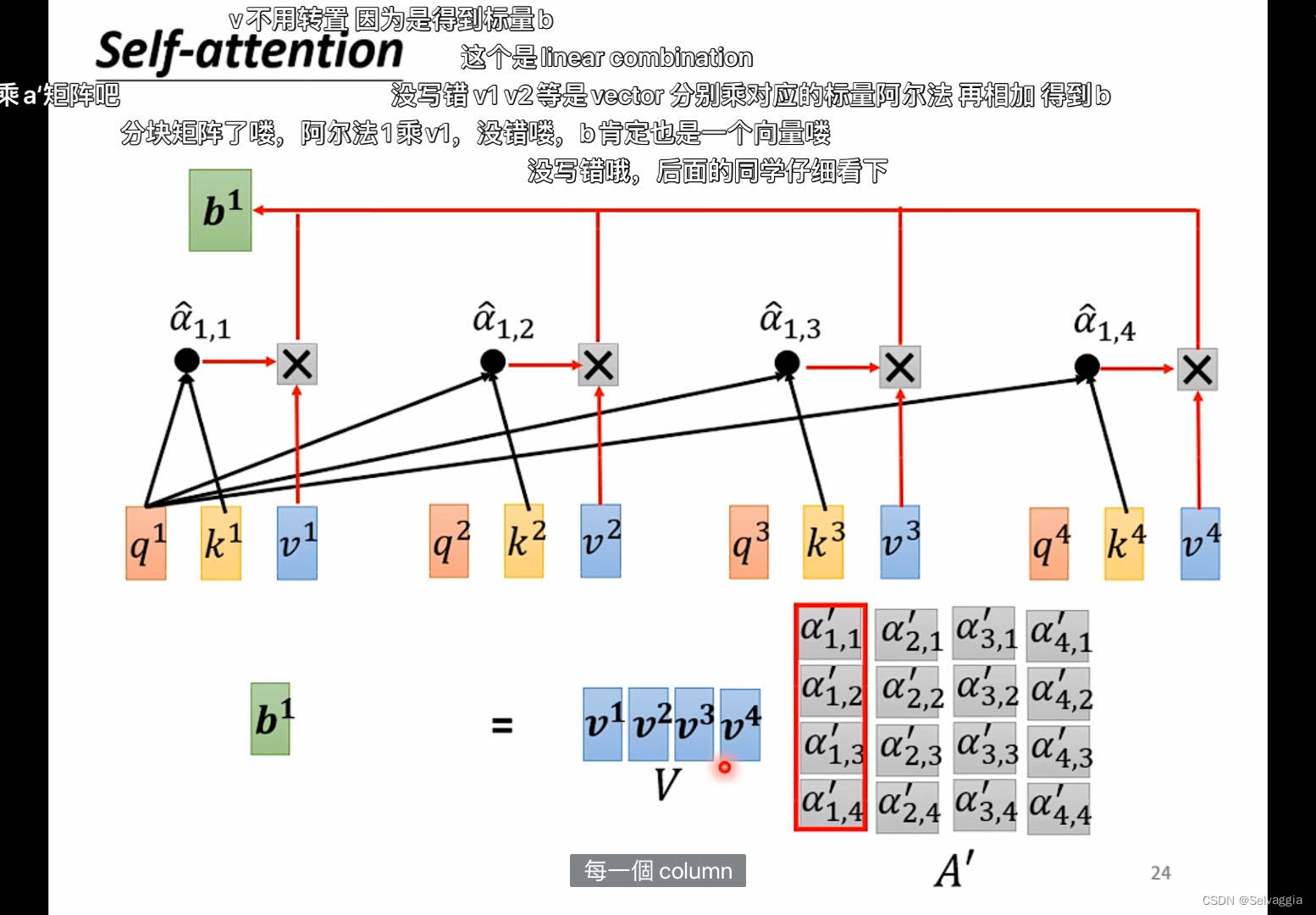
【无标题】读transformer
这里写目录标题 transformerabstractconclusionintroductionbackground注意力机制mlptransformer和RNN传递序列信息embedding之后维度越大的向量归一化后其单个值就越小,乘个根号512position encoding加入时序信息 transformer
abstract
编码器和解码器的架构 处理…
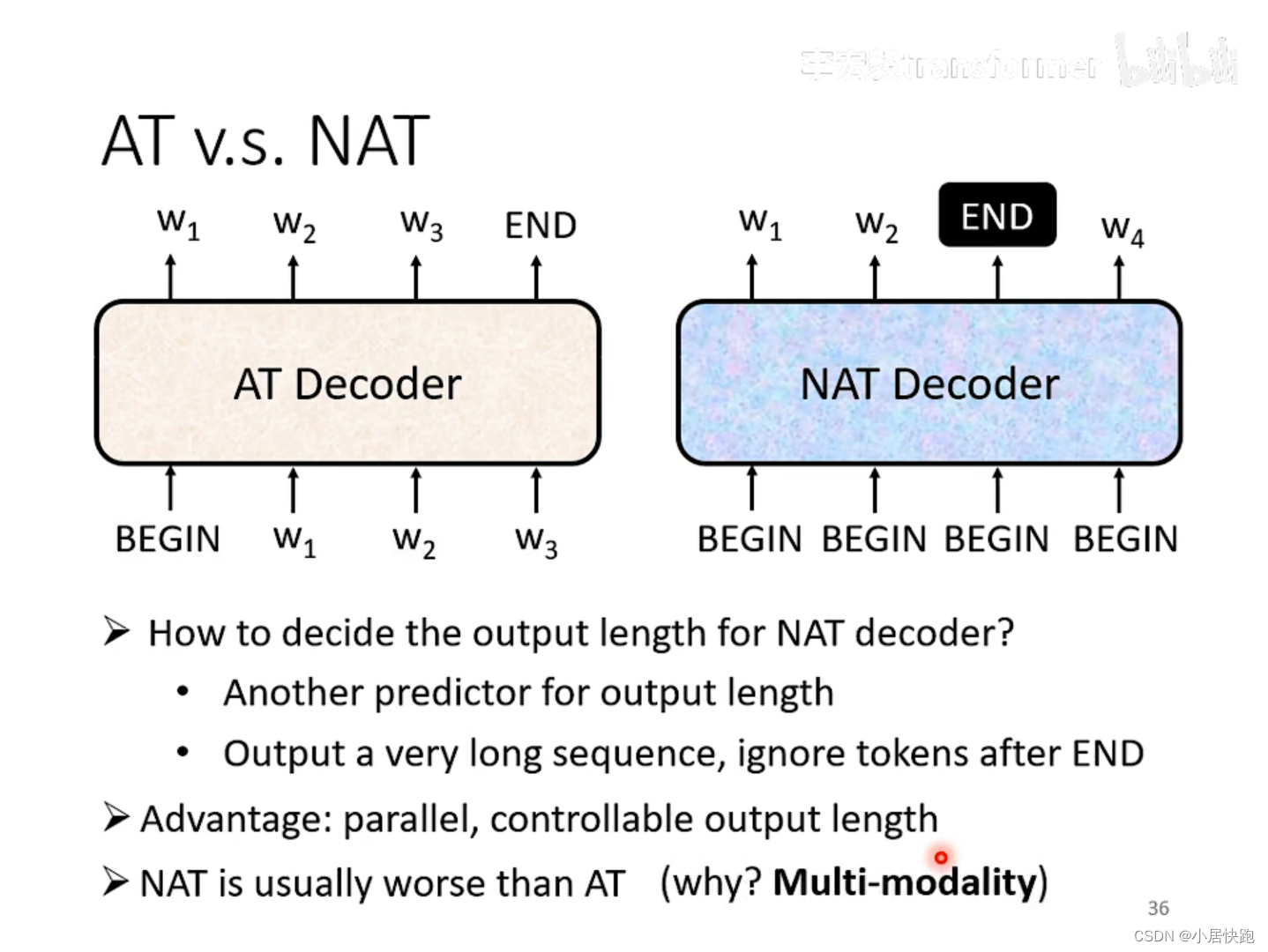
transformer模型结构|李宏毅机器学习21年
来源:https://www.bilibili.com/video/BV1Bb4y1L7FT?p4&vd_sourcef66cebc7ed6819c67fca9b4fa3785d39 文章目录 概述seq2seqtransformerEncoderDecoderAutoregressive(AT)self-attention与masked-self attentionmodel如何决定输出的长度…
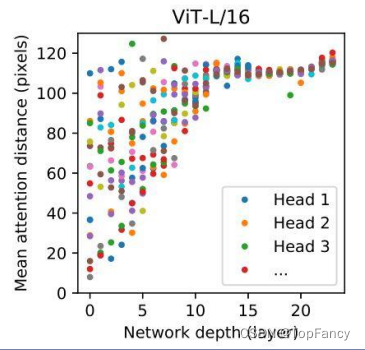
【AI】VIT Transformer论文学习笔记
论文:Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020 1.文章背景
计算机视觉当前最热门的两大基础模型就是Transformer和CNN了。
Transf…
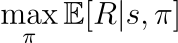
第 9 部分 — 内存增强 Transformer 网络:数学见解
一、说明 在顺序数据处理领域,传统的 Transformer 架构擅长处理短期依赖性,但在需要大量内存和长序列上下文保留的任务中表现不佳。在这篇综合博客中,我打算探索一种新颖的混合方法,将 Transformer 与显式长期记忆模块集成在一起。…
Transformer实战-系列教程18:DETR 源码解读5(BackboneBase类/Backbone类)
🚩🚩🚩Transformer实战-系列教程总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 点我下载源码 DETR 算法解读 DETR 源码解读1(项目配置/CocoDetection类) …
Transformer面试十问
1 Scaled Dot-Product Attention中为什么要除以 d k \sqrt{d_k} dk ?
1. 从纯数学上考虑:对于输入均值为0,方差为1的分布,点乘后结果其方差为dk,所以需要缩放一下。下图为原论文注释。 2. 从神经网络上考虑:防止在计算点积…
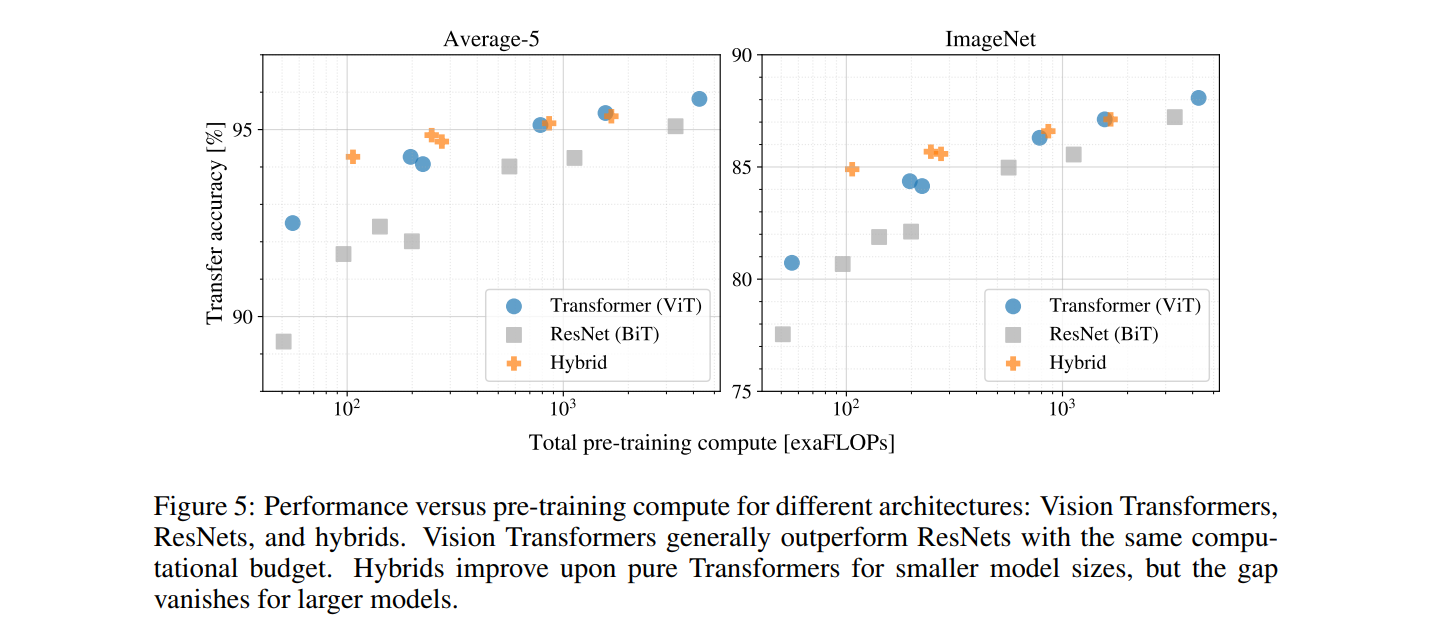
ViT: transformer在图像领域的应用
文章目录 1. 概要2. 方法3. 实验3.1 Compare with SOTA3.2 PRE-TRAINING DATA REQUIREMENTS3.3 SCALING STUDY3.4 自监督学习 4. 总结参考 论文:
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 代码:https://github.com…

TRS 2024 论文阅读 | 基于点云处理和点Transformer网络的人体活动连续识别
注1:本文系“无线感知论文速递”系列之一,致力于简洁清晰完整地介绍、解读无线感知领域最新的顶会/顶刊论文(包括但不限于 Nature/Science及其子刊; MobiCom, Sigcom, MobiSys, NSDI, SenSys, Ubicomp; JSAC, 雷达学报 等)。 本次介绍的论文是:<IEEE Transactions on Radar …
Bert基础(一)--transformer概览
1、简介
当下最先进的深度学习架构之一,Transformer被广泛应用于自然语言处理领域。它不单替代了以前流行的循环神经网络(recurrent neural network, RNN)和长短期记忆(long short-term memory, LSTM)网络,并且以它为基础衍生出了诸如BERT、GPT-3、T5等…
大语言模型LLM中Transformer模型的调用过程与步骤
在LLM(Language Model)中,Transformer是一种用来处理自然语言任务的模型架构。下面是Transformer模型中的调用过程和步骤的简要介绍:
数据预处理:将原始文本转换为模型可以理解的数字形式。这通常包括分词、编码和填充…

遥感影像目标检测:从CNN(Faster-RCNN)到Transformer(DETR)
我国高分辨率对地观测系统重大专项已全面启动,高空间、高光谱、高时间分辨率和宽地面覆盖于一体的全球天空地一体化立体对地观测网逐步形成,将成为保障国家安全的基础性和战略性资源。未来10年全球每天获取的观测数据将超过10PB,遥感大数据时…
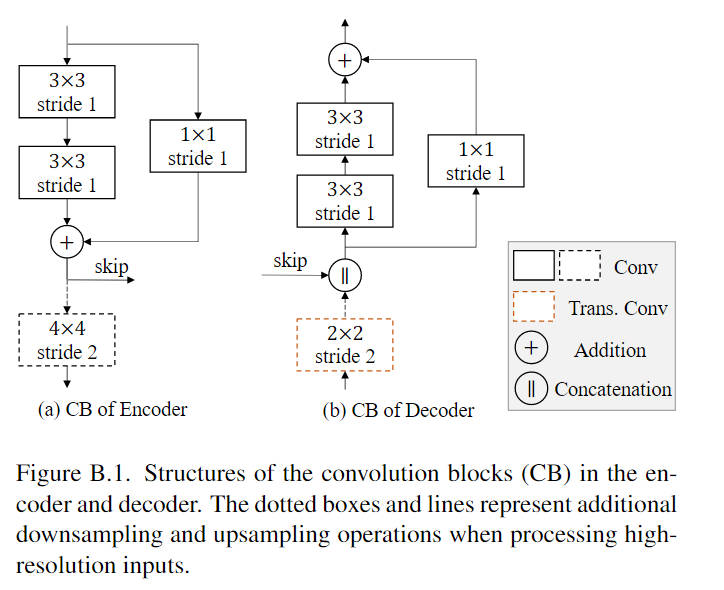
EDT:On Efficient Transformer-Based Image Pre-training for Low-Level Vision
EDT:On Efficient Transformer-Based Image Pre-training for Low-Level Vision
论文地址:On Efficient Transformer-Based Image Pre-training for Low-Level Vision
代码地址:fenglinglwb/EDT: On Efficient Transformer-Based Image Pre…

Group DETR:分组一对多匹配是加速DETR收敛的关键学习笔记
论文地址:https://arxiv.org/pdf/2207.13085.pdf 代码地址:GitHub - Atten4Vis/ConditionalDETR: This repository is an official implementation of the ICCV 2021 paper "Conditional DETR for Fast Training Convergence". (https://arxiv…

微表情检测(四)----SL-Swin
SL-Swin: A Transformer-Based Deep Learning Approach for Macro- and Micro-Expression Spotting on Small-Size Expression Datasets
在本文中,我们致力于解决从视频中检测面部宏观和微观表情的问题,并通过使用深度学习方法分析光流特征提出了引人注…
【期末考复习向】transformer的运作机制
1.transformer的encoder运作 transformer的encoder部分包括了输入和处理2大部分。首先是输入部分inputs,这里初始的inputs是采用独热向量进行表示的,随后经过word2vec等操作把独热向量(采用独热向量的好处就是可向量是正交的,可以…
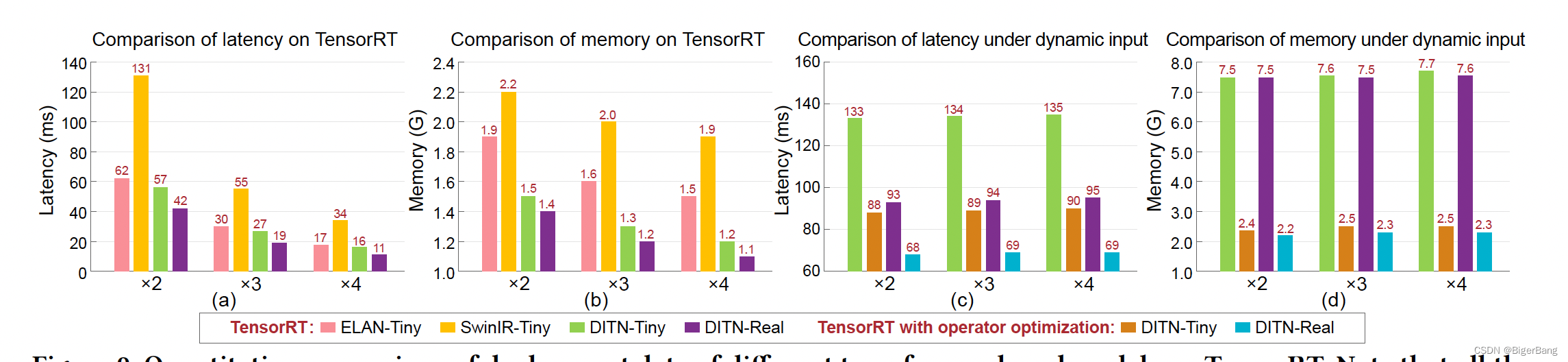
ACM-MM2023 DITN详解:一个部署友好的超分Transformer
目录 1. Introduction2. Method2.1. Overview2.2. UFONE2.3 真实场景下的部署优化 3. 结果 Paper: Unfolding Once is Enough: A Deployment-Friendly Transformer Unit for Super-Resolution
Code: https://github.com/yongliuy/DITN
1. Introduction CNN做超分的缺点 由于卷…
![[Longformer]论文实现:Longformer: The Long-Document Transformer](https://img-blog.csdnimg.cn/direct/04e433a9e1f94c85874b0d1f527ecd1c.png)
[Longformer]论文实现:Longformer: The Long-Document Transformer
文章目录 一、完整代码二、论文解读2.1 介绍2.2 Longformer注意力模式注意力计算 2.3 自回归语言模型注意力模式训练结果 2.4 预训练和微调注意力模式位置编码预训练结果 2.5 Longformer-Encoder-Decoder (LED) 三、整体总结 论文:Longformer: The Long-Document Tr…
![[Linformer]论文实现:Linformer: Self-Attention with Linear Complexity](https://img-blog.csdnimg.cn/direct/9ac734dcb9d64d79924e717dc861c59b.png)
[Linformer]论文实现:Linformer: Self-Attention with Linear Complexity
文章目录 一、完整代码二、论文解读2.1 介绍2.2 Self-Attention is Low Rank2.3 模型架构2.4 结果 三、整体总结 论文:Linformer: Self-Attention with Linear Complexity 作者:Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, Hao Ma 时间&#…
论文阅读笔记AI篇 —— Transformer模型理论+实战 (二)
论文阅读笔记AI篇 —— Transformer模型理论实战(二) 第二遍阅读(通读)2.1 Background2.2 Model Architecture2.2.1 Encoder and Decoder Stacks2.2.2 Scaled Dot-Product Attention2.2.3 Multi-Head Attention 2.3 Why Self-Atte…

Transformer简单理解
目录 一、CNN存在的问题:二.Transformer整理架构分析:1.Linear Projection of Flattened Patches层形成Patch:2.对每个Patch进行位置编码Position Embedding:3.Transformer Encoder: 三.公式解读: 一、CNN存在的问题&a…
transfomer中Multi-Head Attention的源码实现
简介
Multi-Head Attention是一种注意力机制,是transfomer的核心机制,就是图中黄色框内的部分.
Multi-Head Attention的原理是通过将模型分为多个头,形成多个子空间,让模型关注不同方面的信息。每个头独立进行注意力运算,得到一个注意力权…

【HuggingFace Transformer库学习笔记】基础组件学习:Datasets
基础组件——Datasets datasets基本使用 导入包
from datasets import *加载数据
datasets load_dataset("madao33/new-title-chinese")
datasetsDatasetDict({train: Dataset({features: [title, content],num_rows: 5850})validation: Dataset({features: [titl…
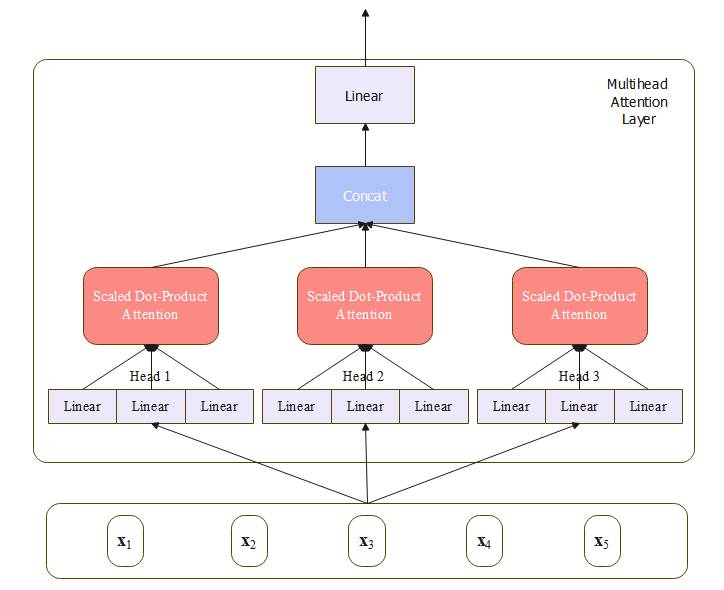
Transformer从菜鸟到新手(二)
引言
这是Transformer的第二篇文章,上篇文章中我们了解了分词算法BPE,本文我们继续了解Transformer中的位置编码和核心模块——多头注意力。
位置编码
我们首先根据BPE算法得到文本切分后的子词标记,然后经过输入嵌入层将每个标记转换为对…

Transformer架构和对照代码详解
1、英文架构图
下面图中展示了Transformer的英文架构,英文架构中的模块名称和具体代码一一对应,方便大家对照代码、理解和使用。 2、编码器
2.1 编码器介绍 从宏观⻆度来看,Transformer的编码器是由多个相同的层叠加⽽ 成的,每个…
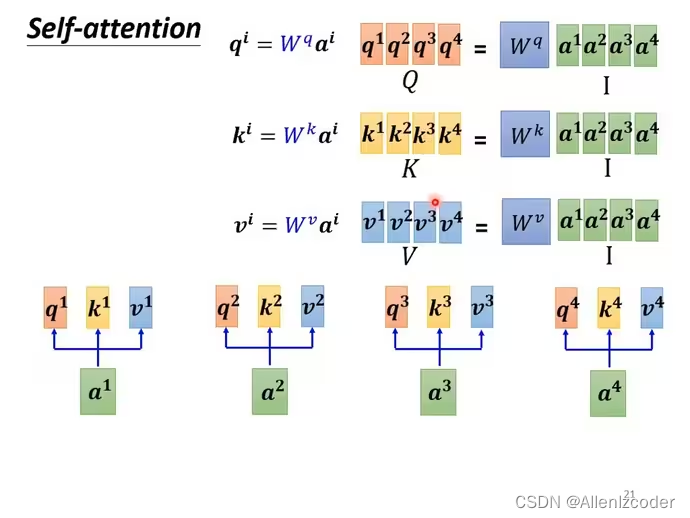
self-attention(上)李宏毅
B站视频链接
word embedding
https//www.youtube.com/watch?vX7PH3NuYW0Q self-attention处理整个sequence,FC专注处理某一个位置的资讯,self-attention和FC可以交替使用。
transformer架构 self-attention的简单理解 a1-a4可能是input也可以作为中…
nlp中的transformer中的mask
由于在实现多头注意力时需要考虑到各种情况下的掩码,因此在这里需要先对这部分内容进行介绍。在Transformer中,主要有两个地方会用到掩码这一机制。第1个地方就是在上一篇文章用介绍到的Attention Mask,用于在训练过程中解码的时候掩盖掉当前…
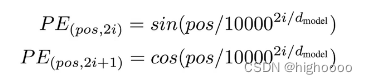
论文阅读 Attention is all u need - transformer
文章目录 1 摘要1.1 核心 2 模型架构2.1 概览2.2 理解encoder-decoder架构2.2.1 对比seq2seq,RNN2.2.2 我的理解 3. Sublayer3.1 多头注意力 multi-head self-attention3.1.1 缩放点乘注意力 Scaled Dot-Product Attention3.1.2 QKV3.1.3 multi-head3.1.4 masked 3.…
一文读懂「Prompt Engineering」提示词工程
在了解提示过程之前,先了解一下什么是提示prompt,见最后附录部分 一、什么是Prompt Engingering?
提示工程(Prompt Engingering),也被称为上下文提示(In-Context Prompting),指的是通过结构化文本等方式来完善提示词,引导LLM输出我们期望的结果。通过提示词工程可以…
51-8 GPT,GPT2,GPT3 论文精读
2020年的时候有一篇博客冲到了Hack News的第一名。Hack News是在技术圈里面应该是影响力最大的一个新闻汇聚网站,所有人都可以分享自己喜欢的文章,然后观众对这些文章进行点赞或者是评论。Hack News根据你点赞的个数和评论来进行排名,这篇文章…
Transformer学习(一)
文章目录 transformer介绍为什么处理长序列时会出现梯度消失和梯度爆炸的问题transformer为什么可以用在图像处理上? transformer介绍 Transformer 是一种在深度学习中广泛使用的模型结构,最初由 Vaswani 等人在 “Attention is All You Need” 一文中提…
Superpoint Transformer for 3D Scene Instance Segmentation
Abstract
现有的大多数方法通过扩展用于3D物体检测或3D语义分割的模型来实现3D实例分割。然而,这些非直接的方法存在两个缺点:1) 不精确的边界框或不令人满意的语义预测限制了整体3D实例分割框架的性能。2) 现有方法需要一个耗时的中间聚合步骤。为了解决这些问题,本文提出…

51-12 多模态论文串讲—BLIP 论文精读
视觉语言预训练VLP模型最近在各种多模态下游任务上获得了巨大的成功,目前还有两个主要局限性:
(1) 模型角度: 大多数方法要么采用encoder模型,要么采用encoder-decoder模型。然而,基于编码器的模型不太容易直接转换到文本生成任务࿰…

Grounding DINO:开放集目标检测,将基于Transformer的检测器DINO与真值预训练相结合
文章目录 背景知识补充CLIP (Contrastive Language-Image Pre-training):打破文字和图像之间的壁垒DINO(Data-INterpolating Neural Network):视觉 Transformer 的自监督学习Stable Diffusion:从文本描述中生成详细的图像Open-set Detector开…

51-11 多模态论文串讲—VLMo 论文精读
VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts (NeurIPS 2022)
VLMo 是一种多模态 Transformer 模型,从名字可以看得出来它是一种 Mixture-of-Modality-Experts (MoME),即混合多模态专家。怎么理解呢?主流 …
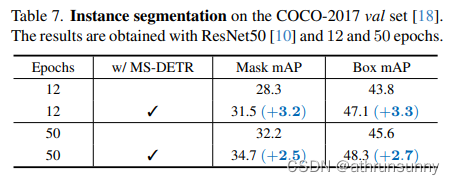
MS-DETR: Efficient DETR Training with Mixed Supervision论文学习笔记
论文地址:https://arxiv.org/pdf/2401.03989.pdf 代码地址(中稿后开源):GitHub - Atten4Vis/MS-DETR: The official implementation for "MS-DETR: Efficient DETR Training with Mixed Supervision" 摘要 DETR 通过迭代…
阅读笔记 | REFORMER: THE EFFICIENT TRANSFORMER
阅读论文: Kitaev, Nikita, Łukasz Kaiser, and Anselm Levskaya. “Reformer: The efficient transformer.” arXiv preprint arXiv:2001.04451 (2020). 背景与动机
这篇论文发表较早,主要关注Transformer的效率问题。标准的Transformer模型在许多自然…
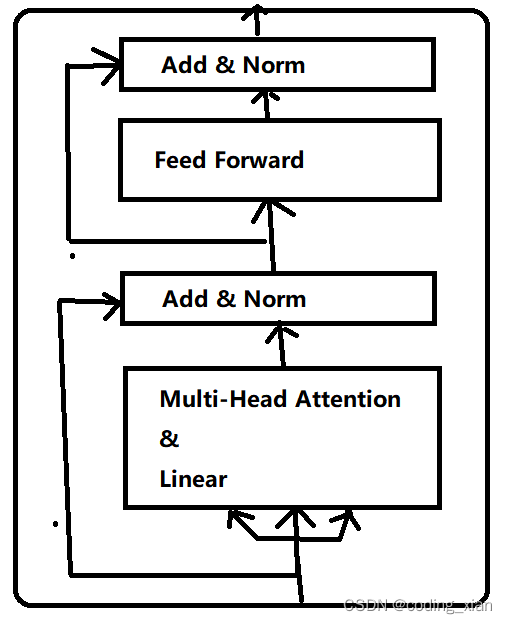
Bert Encoder和Transformer Encoder有什么不同
前言:本篇文章主要从代码实现角度研究 Bert Encoder和Transformer Encoder 有什么不同?应该可以帮助你: 深入了解Bert Encoder 的结构实现深入了解Transformer Encoder的结构实现 本篇文章不涉及对注意力机制实现的代码研究。 注:…

Hardware-Aware-Transformers开源项目笔记
文章目录 Hardware-Aware-Transformers开源项目笔记开源项目背景知识nas进化算法进化算法代码示例 开源项目Evolutionary Search1 生成延迟的数据集2 训练延迟预测器3 使延时约束运行搜索算法4. 训练搜索得到的subTransformer5. 根据重训练后的submodel 得到BLEU精度值 代码结构…
大模型关键技术:上下文学习、思维链、RLHF、参数微调、并行训练、旋转位置编码、模型加速、大模型注意力机制优化、永久记忆、LangChain、知识图谱、多模态
大模型关键技术 大模型综述上下文学习思维链 CoT奖励建模参数微调并行训练模型加速永久记忆:大模型遗忘LangChain知识图谱多模态大模型系统优化AI 绘图幻觉问题从 GPT1 - GPT4 拆解GPTs 对比主流大模型技术点旋转位置编码层归一化激活函数注意力机制优化 大模型综述…
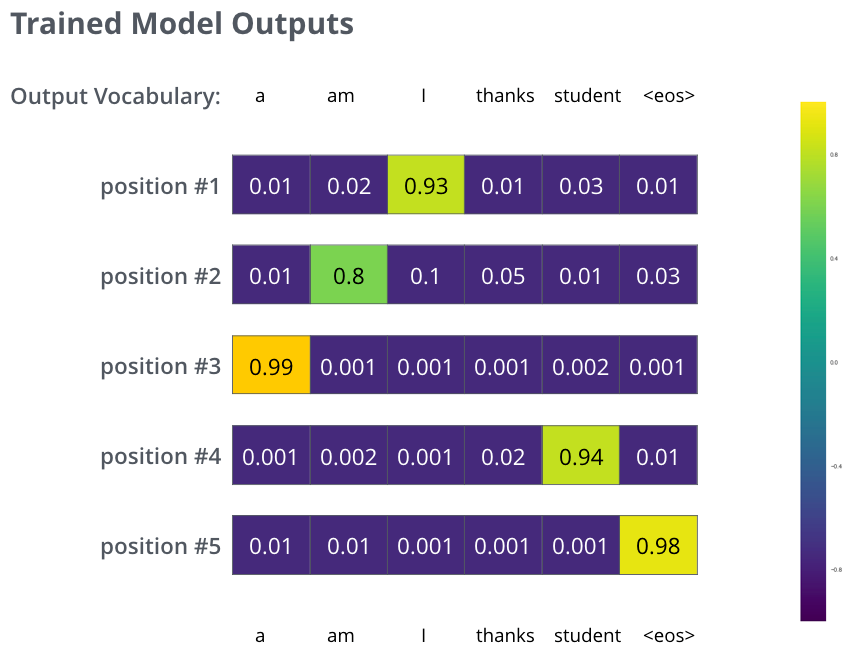
大语言模型系列-Transformer
文章目录 前言一、Attention二、Transformer结构三、Transformer计算过程1. 编码器(Encoder)1)Self-Attention层2)Multi-Head-Attention层3)Add & Norm层 2. 解码器(Decoder)1)M…
![[全连接神经网络]Transformer代餐,用MLP构建图像处理网络](https://img-blog.csdnimg.cn/direct/c615052855514723a7b63921995f89eb.png)
[全连接神经网络]Transformer代餐,用MLP构建图像处理网络
一、MLP-Mixer 使用纯MLP处理图像信息,其原理类似vit,将图片进行分块(patch)后展平(fallten),然后输入到MLP中。理论上MLP等价于1x1卷积,但实际上1x1卷积仅能结合通道信息而不能结合空间信息。根据结合的信息不同分为channel-mixi…

【NLP】关于Transformer模型的一些认知
目录
一. Transformer模型简介
二. Transformer模型的架构
1. 编码器:
2. 解码器:
三. Transformer模型中残差连接层的作用
四. Transformer模型中, 输入部分的位置编码(PisitionalEncoding)矩阵为什么要使用三角函数对奇数…
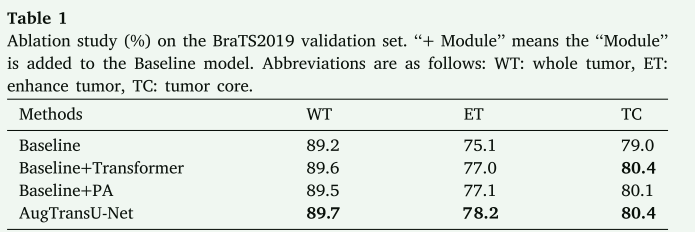
【论文阅读】Augmented Transformer network for MRI brain tumor segmentation
Zhang M, Liu D, Sun Q, et al. Augmented transformer network for MRI brain tumor segmentation[J]. Journal of King Saud University-Computer and Information Sciences, 2024: 101917. [开源] IF 6.9 SCIE JCI 1.58 Q1 计算机科学2区
【核心思想】
本文提出了一种新型…
LLaMA-2 下载demo使用
LLaMA-2 下载&demo使用 1. LLaMA-2 下载&demo使用1.1 meta官网1.2 huggingface1.3 其他源1.4 huggingface下载模型和数据加速 1. LLaMA-2 下载&demo使用
1.1 meta官网
llama2下载
在meta的官网 Meta website 进行下载申请(注意地区不要选择China会被…

NLP论文阅读记录 - 2022 W0S | 基于Longformer和Transformer的提取摘要层次表示模型
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 A Hierarchical Representation Model Based on Longformer and …
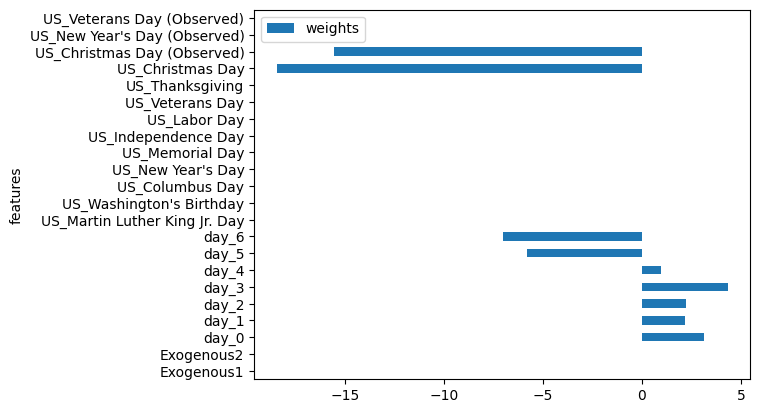
工具系列:TimeGPT_(2)使用外生变量时间序列预测
文章目录 TimeGPT使用外生变量时间序列预测导入相关工具包预测欧美国家次日电力价格案例 TimeGPT使用外生变量时间序列预测
外生变量在时间序列预测中非常重要,因为它们提供了可能影响预测的额外信息。这些变量可以包括假日标记、营销支出、天气数据或与你正在预测…
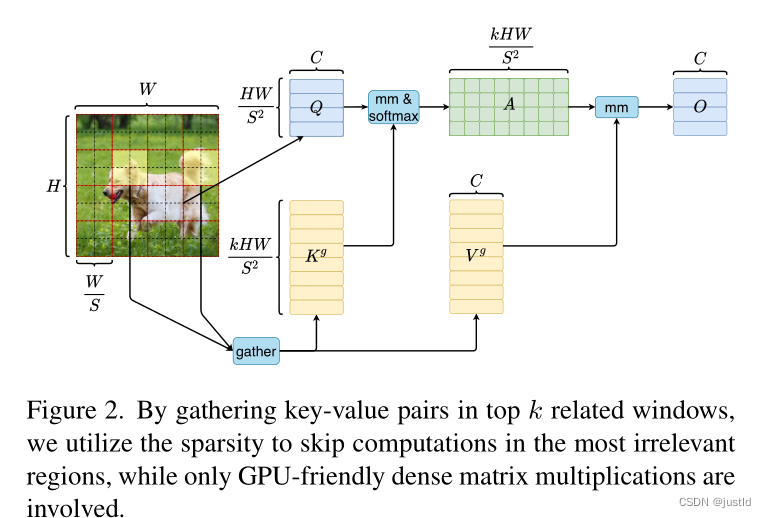
【论文笔记】BiFormer: Vision Transformer with Bi-Level Routing Attention
论文地址:BiFormer: Vision Transformer with Bi-Level Routing Attention
代码地址:https://github.com/rayleizhu/BiFormer
vision transformer中Attention是极其重要的模块,但是它有着非常大的缺点:计算量太大。
BiFormer提…

Transformer原理与代码实现
Transformer原理与代码实现 概览 一、嵌入层 Embedding 二、位置编码 Positional Encoding 三、(整合)Transformer嵌入层 Transformer Embedding 四、带缩放的点积注意力机制 Scaled Dot-Product Attention 五、多头注意力 Multi-Head Attention 六…

一文读懂「生成式AI,AIGC」
一、什么是AIGC? 二、技术层面发展 AIGC要素:算力 算法 数据 AIGC发展重点
AIGC产业链路 AIGC未来方向 三、产业层面发展
AIGC产业融资 AIGC场景应用
四、AIGC应用分析 AI 游戏 eg:网易伏羲
AI 广告营销 eg:
AI 影…
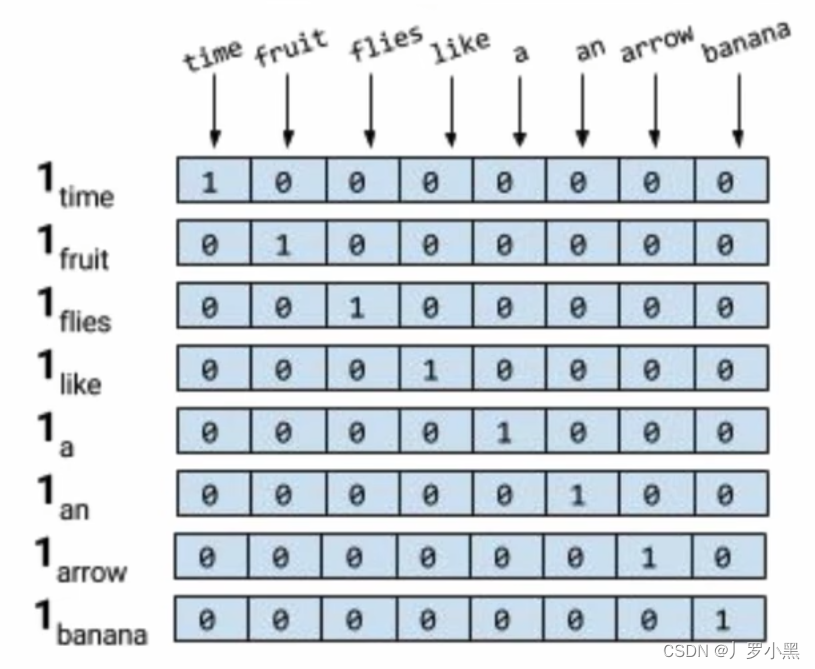
Transformer的前世今生 day02(神经网络语言模型
神经网络语言模型
使用神经网络的方法,去完成语言模型的两个问题,下图为两层感知机的神经网络语言模型:
以下为预备概念
感知机
线性模型可以用下图来表示:输入经过线性层得到输出 线性层 / 全连接层 / 稠密层:假…

注意力机制 self-attention 的原理探究
一、点积的认识
向量的点积可以表示相似性的原因在于它衡量了两个向量之间的方向是否相似。当两个向量的方向趋于一致时,它们的点积会更大;当两个向量的方向趋于相互垂直时,它们的点积会接近于0。这种性质使得点积在衡量向量之间的相似性和相…
2024年1月15日Arxiv最热论文推荐:斯坦福LLM精准微调新框架、GPT不愿承认回答错误、速度快15倍的3D全景分割新突破
本文整理了今日发表在ArXiv上的AI论文中最热门的TOP5。
论文解读、论文热度排序、论文标签、中文标题、推荐理由和论文摘要均由赛博马良平台上的智能体 「AI论文解读达人」提供。
如需查看其他热门论文,欢迎移步赛博马良 ^_^
TOP1
APAR: LLMs Can Do Auto-Paral…
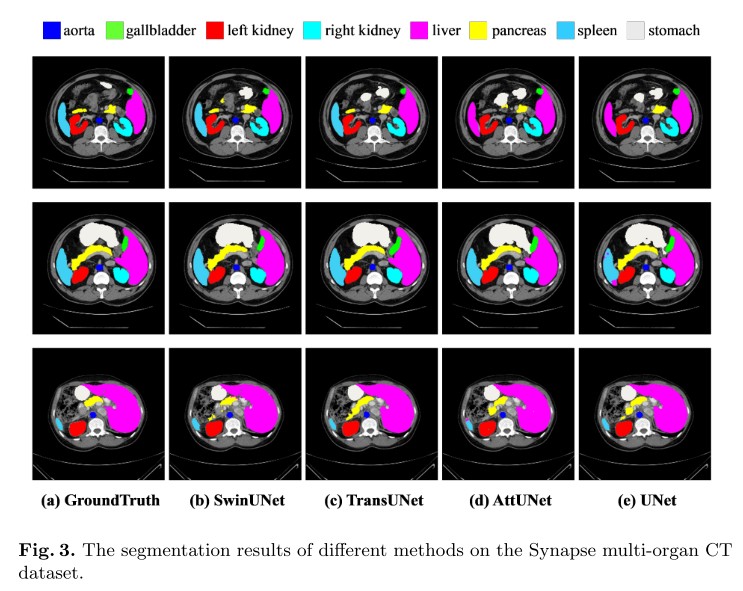
【论文阅读笔记】Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
1.介绍
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation Swin-Unet:用于医学图像分割的类Unet纯Transformer
2022年发表在 Computer Vision – ECCV 2022 Workshops Paper Code
2.摘要
在过去的几年里,卷积神经网络ÿ…
51-16 FusionAD 用于自动驾驶预测与规划任务的多模态融合论文精读
今天要分享的是基于BEV的多模态、多任务、端到端自动驾驶模型FusionAD,其专注于自动驾驶预测和规划任务。这项工作首次发表于2023年8月2日,性能超越了2023 CVPR最佳论文UniAD模型。论文题目是FusionAD: Multi-modality Fusion for Prediction and Planni…
Transformer跨模态领域的全面SOTA应用
✔️Transformer 确实在多个领域都取得了巨大的成功,并成为了许多任务的 SOTA(State-of-the-Art)模型。以下是一些领域中 Transformer 的应用:
👉自然语言处理(NLP):Transformer 模…
51-17 视频理解串讲— MViT 论文精读
继TimeSformer模型之后,咱们再介绍两篇来自Facebook AI的论文,即Multiscale Vision Transformers以及改进版MViTv2: Improved Multiscale Vision Transformers for Classification and Detection。
由于本司大模型组最近组织阅读的论文较多,…
VLM 系列——Llava——论文解读
一、概述
1、是什么 Llava 全称《Visual Instruction Tuning》,是一个多模态视觉-文本大语言模型,可以完成:图像描述、视觉问答、根据图片写代码(HTML、JS、CSS),潜在可以完成单个目标的视觉定位、名画名人等识别(问答、描述)。支持单幅图片输入(可以作为第一个或…
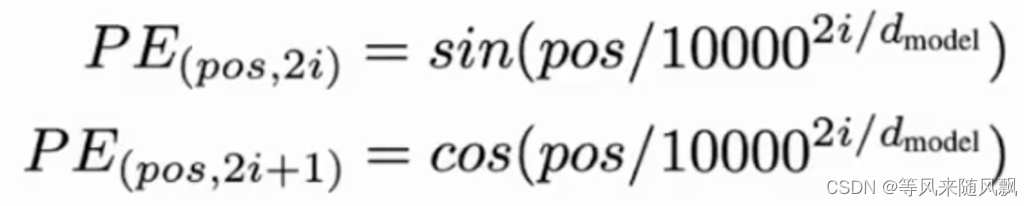
transformer_位置编码代码笔记
transformer_位置编码代码笔记
transformer输入的序列中,不同位置的相同词汇可能会表达不同的含义,通过考虑位置信息的不同来区分序列中不同位置的相同词汇。
位置编码有多种方式,此处仅记录正余弦位置编码
正余弦位置编码公式如下&#x…

基于Transformer结构的扩散模型综述
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活&…
LLM(5) | Encoder 和 Decoder 架构
LLM(5) | Encoder 和 Decoder 架构 文章目录 LLM(5) | Encoder 和 Decoder 架构0. 目的1. 概要2. encoder 和 decoder 风格的 transformer (Encoder- And Decoder-Style Transformers)原始的 transformer (The original transformer)编码器 (Encoders)解码器 (Decoders)编码器和…
论文精读 Co-DETR(Co-DINO、Co-Deformable-DETR)
DETRs with Collaborative Hybrid Assignments Training
基于协作混合分配训练的DETRs
论文链接:2211.12860.pdf (arxiv.org)
源码链接:https://github.com/Sense-X/Co-DETR 总结: Co-DETR基于DAB-DETR、Deformable-DETR和DINO网络进行了实…

LSTR: 基于Transformer的车道形状预测
LSTR: 基于Transformer的车道形状预测 项目背景与意义LSTR的特性和功能最新更新即将推出的功能模型资源库数据准备设置环境训练和评估引用许可证贡献致谢 在计算机视觉领域,车道检测是自动驾驶和智能交通系统中的关键技术之一。我们推出了一种名为LSTR的车道形状预测…
VLM 系列——MoE-LLaVa——论文解读
一、概述
1、是什么 moe-Llava 是Llava1.5 的改进 全称《MoE-LLaVA: Mixture of Experts for Large Vision-Language Models》,是一个多模态视觉-文本大语言模型,可以完成:图像描述、视觉问答,潜在可以完成单个目标的视觉定位、名画名人等识别(问答、描述),未知是否能偶…

从头开始构建和训练 Transformer(上)
1、导 读
2017 年,Google 研究团队发表了一篇名为《Attention Is All You Need》的论文,提出了 Transformer 架构,是机器学习,特别是深度学习和自然语言处理领域的范式转变。
Transformer 具有并行处理功能,可以实现…
点云transformer算法: FlatFormer 论文阅读笔记
代码:https://github.com/mit-han-lab/flatformer论文:https://arxiv.org/abs/2301.08739[FlatFormer.pdf]
Flatformer是对点云检测中的 backbone3d部分的改进工作,主要在探究怎么高效的对点云应用transformer 具体的工作如下:一…

【Transformer-Hugging Face 06/10】 数据预处理实例
目录 一、说明二、自然语言处理2.1 Pad2.2 截断2.3 构建张量 三、TensorFlow四、处理语音五、计算机视觉六、填充七、Multimodal 一、说明 在数据集上训练模型之前,需要将其预处理为预期的模型输入格式。无论您的数据是文本、图像还是音频,都需要将它们…
51-15 视频理解串讲—TimeSformer论文精读
今天读的论文题目是Is Space-Time Attention All You Need for Video Understanding?
Facebook AI提出了一种称为TimeSformer视频理解的新架构,这个架构完全基于transformer,不使用卷积层。它通过分别对视频的时间和空间维度应用自注意力机制ÿ…
![论文解析[11] CAT: Cross Attention in Vision Transformer](https://img-blog.csdnimg.cn/5430cf7c7ac040dda1be2310141e623a.png)
论文解析[11] CAT: Cross Attention in Vision Transformer
发表时间:2021 论文地址:https://arxiv.org/abs/2106.05786v1 文章目录摘要3 方法3.1 总体结构3.1.1 Inner-Patch Self-Attention Block3.1.2 Cross-Patch Self-Attention Block3.1.3 Cross Attention based Transformer结论摘要
使用图像patch来替换tr…
【DeepLearning-5】基于Transformer架构的自定义神经网络类
类定义
class UserDefined(nn.Module):
UserDefined 是一个自定义的神经网络类,继承自PyTorch的 nn.Module 基类。
构造函数 __init__
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout0.):
__init__ 方法是类的构造函数,用于初始…

深度学习(6)---Transformer
文章目录 一、介绍二、架构2.1 Multi-head Attention2.2 Encoder(编码器)2.3 Decoder(解码器) 三、Encoder和Decoder之间的传递四、Training五、其他介绍5.1 Copy Mechanism5.2 Beam Search 一、介绍 1. Transformer是一个Seq2Seq(Sequence-to-Sequence)…
VLM 系列——Qwen-VL 千问—— 论文解读
一、概述
1、是什么 Qwen-VL全称《Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond》,是一个多模态的视觉-文本模型,当前 Qwen-VL(20231707)可以完成:图像字幕、视觉问答、OCR、文档理解和视觉定位功能,同…
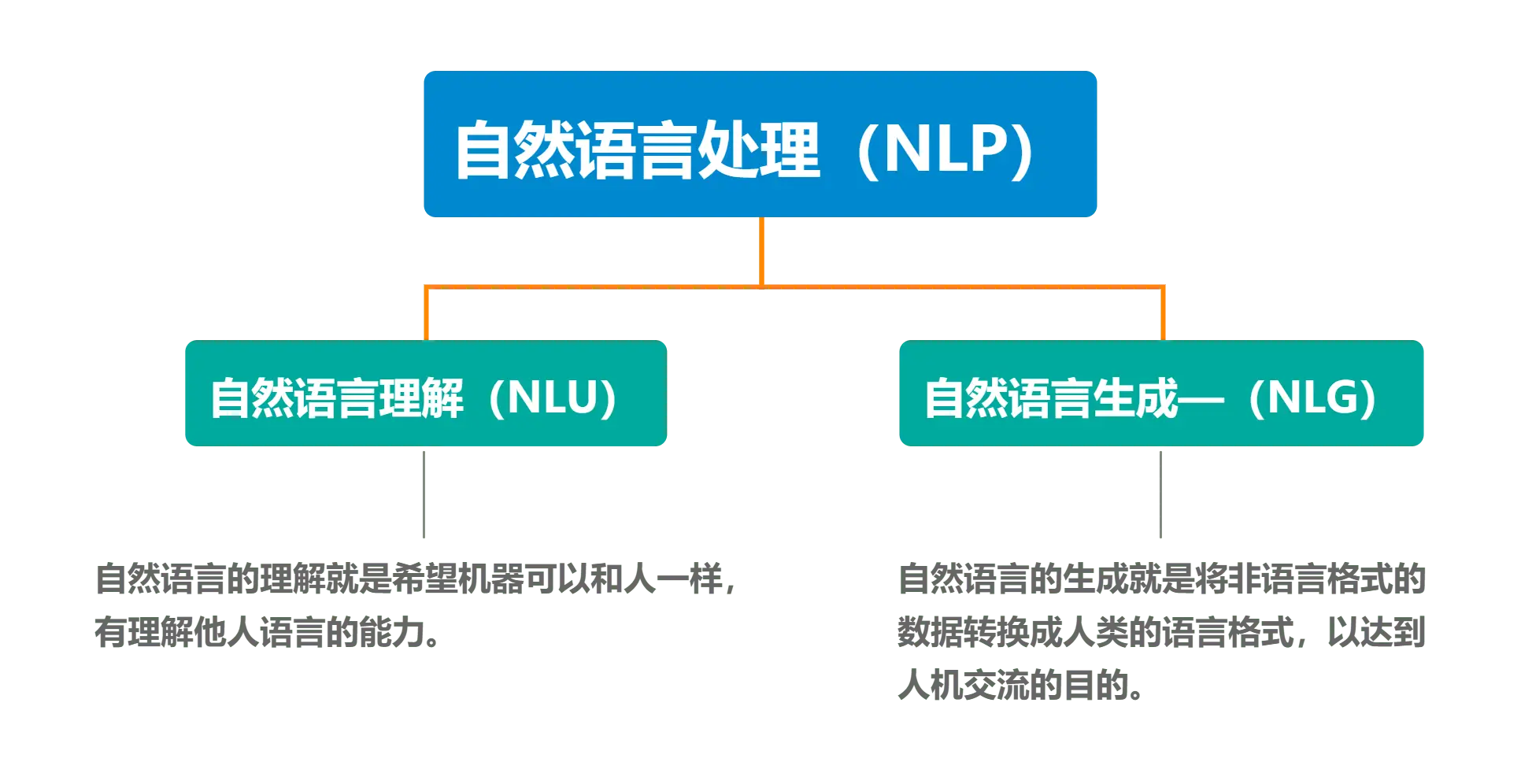
人工智能时代的十大核心技术:重塑未来的无限可能 - 第十章 - 揭秘AI智慧之源,Transformer架构与神奇的注意力机制
在人工智能的浩瀚海洋中,自然语言处理(NLP)一直扮演着至关重要的角色。
近年来,一种名为Transformer的模型架构异军突起,凭借其超凡的表示能力和计算效率,迅速成为NLP领域的领头羊。而在这背后,…
交叉注意力融合时域、频域特征的FFT + CNN-Transformer-CrossAttention轴承故障识别模型
目录
往期精彩内容:
前言
1 快速傅里叶变换FFT原理介绍
第一步,导入部分数据
第二步,故障信号可视化
第三步,故障信号经过FFT可视化
2 轴承故障数据的预处理
2.1 导入数据
2.2 制作数据集和对应标签
3 交叉注意力机制
…

白话 Transformer 原理-以 BERT 模型为例
白话 Transformer 原理-以 BERT 模型为例
第一部分:引入
1-向量
在数字化时代,数学运算最小单位通常是自然数字,但在 AI 时代,这个最小单元变成了向量,这是数字化时代计算和智能化时代最重要的差别之一。
举个例子:银行在放款前,需要评估一个人的信用度;对于用户而…

论文解读:End-to-End Object Detection with Transformers
发表时间:2020 论文地址:https://arxiv.org/pdf/2005.12872.pdf 项目地址:https://github.com/facebookresearch/detr
提出了一种将对象检测视为集合预测问题的新方法。我们的方法简化了检测流程,有效地消除了许多手工设计的组件…

LLM 推理优化探微 (1) :Transformer 解码器的推理过程详解
编者按:随着 LLM 赋能越来越多需要实时决策和响应的应用场景,以及用户体验不佳、成本过高、资源受限等问题的出现,大模型高效推理已成为一个重要的研究课题。为此,Baihai IDP 推出 Pierre Lienhart 的系列文章,从多个维…
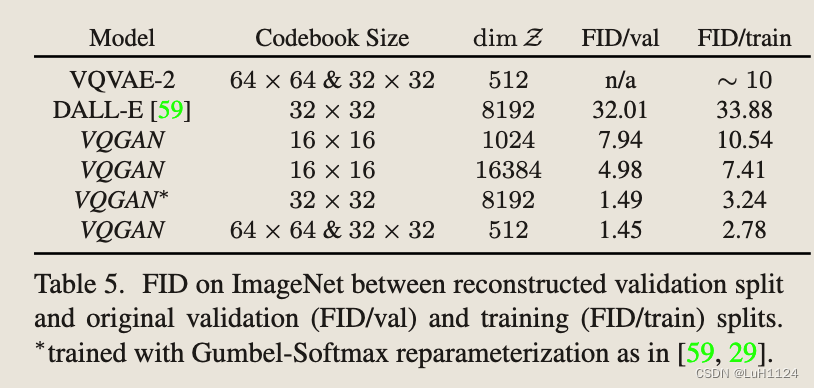
【论文阅读笔记】Taming Transformers for High-Resolution Image Synthesis
Taming Transformers for High-Resolution Image Synthesis 记录前置知识AbstractIntroductionRelated WorkMethodLearning an Effective Codebook of Image Constituents for Use in TransformersLearning the Composition of Images with Transformers条件合成合成高分辨率图…
![[论文阅读]DETR](https://img-blog.csdnimg.cn/direct/fefcccbf4a1541128ea97dbe17b29a1d.png)
[论文阅读]DETR
DETR
End-to-End Object Detection with Transformers 使用 Transformer 进行端到端物体检测 论文网址:DETR 论文代码:DETR
简读论文 这篇论文提出了一个新的端到端目标检测模型DETR(Detection Transformer)。主要的贡献和创新点包括: 将目标检测视为一…
基于FFT + CNN -Transformer时域、频域特征融合的电能质量扰动识别模型
目录
往期精彩内容:
模型整体结构
1 快速傅里叶变换FFT原理介绍
第一步,导入部分数据,扰动信号可视化
第二步,扰动信号经过FFT可视化
2 电能质量扰动数据的预处理
2.1 导入数据
2.2 制作数据集
3 基于FFTCNN-Transform…
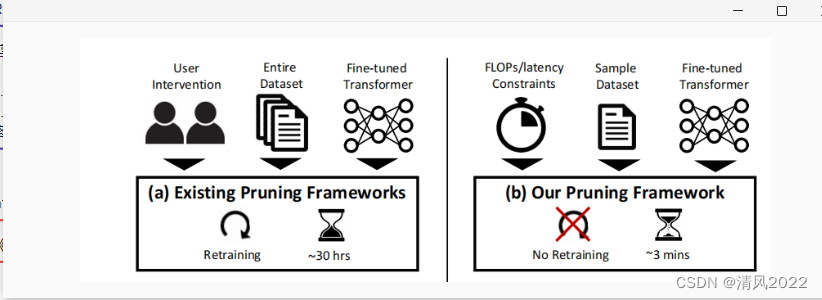
transformer剪枝论文汇总
文章目录 NN Pruning摘要实验 大模型剪枝LLM-PrunerSparseGPT LTPVTPWidth & Depth PruningPatch SlimmingDynamicViTSPViTDynamicBERTViT SlimmingFastFormersNViTUVCPost-training pruning NN Pruning
《Block Pruning For Faster Transformers》 《为更快的transformer…
【人工智能】聊聊Transformer,深度学习的一股清流(13)
嘿,大家好!今天我们来聊一聊深度学习领域的一位“大明星”——Transformer模型。这个模型的提出可不得了,让自然语言处理领域焕发了新生。 在深度学习领域,Transformer模型架构的引入标志着一场革命,它改变了自然语言处…
如何在一个中文大模型上,加入招投标字段标注的数据,搭建一个招投标字段解析的Transformer模型?
ChatGPT方案1 在一个中文大模型上加入招投标字段标注的数据,并搭建招投标字段解析的Transformer模型可以通过以下步骤实现: 收集并标注招投标相关的数据。可以使用现有的数据集,也可以通过爬虫技术获取相关数据,然后进行人工标注。…
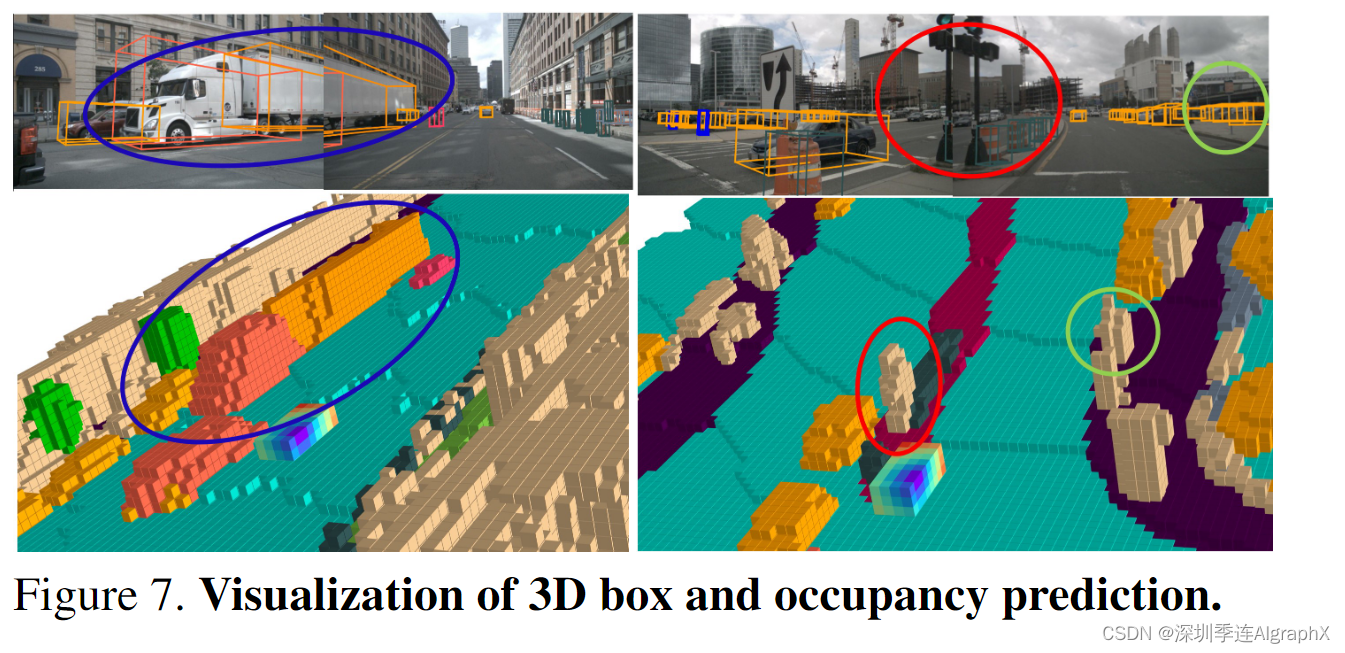
51 -25 Scene as Occupancy 3D占用作为场景表示 论文精读
本文阅读的文章是Scene as Occupancy,介绍了一种将物体表示为3D occupancy的新方法,以描述三维场景,并用于检测、分割和规划。
文章提出了OccNet和OpenOcc两个核心概念。
OccNet 3D占用网络是一种以多视图视觉为中心的方法,通过…
Transformer实现的一个Demo
RT,直接上代码,可以跑通: #encoding:utf-8 import torch
import torch.nn as nn
import numpy as np
import math class Config(object): def __init__(self): self.vocab_size 6 self.d_model 512 self.n_heads 4 assert self.d_model…
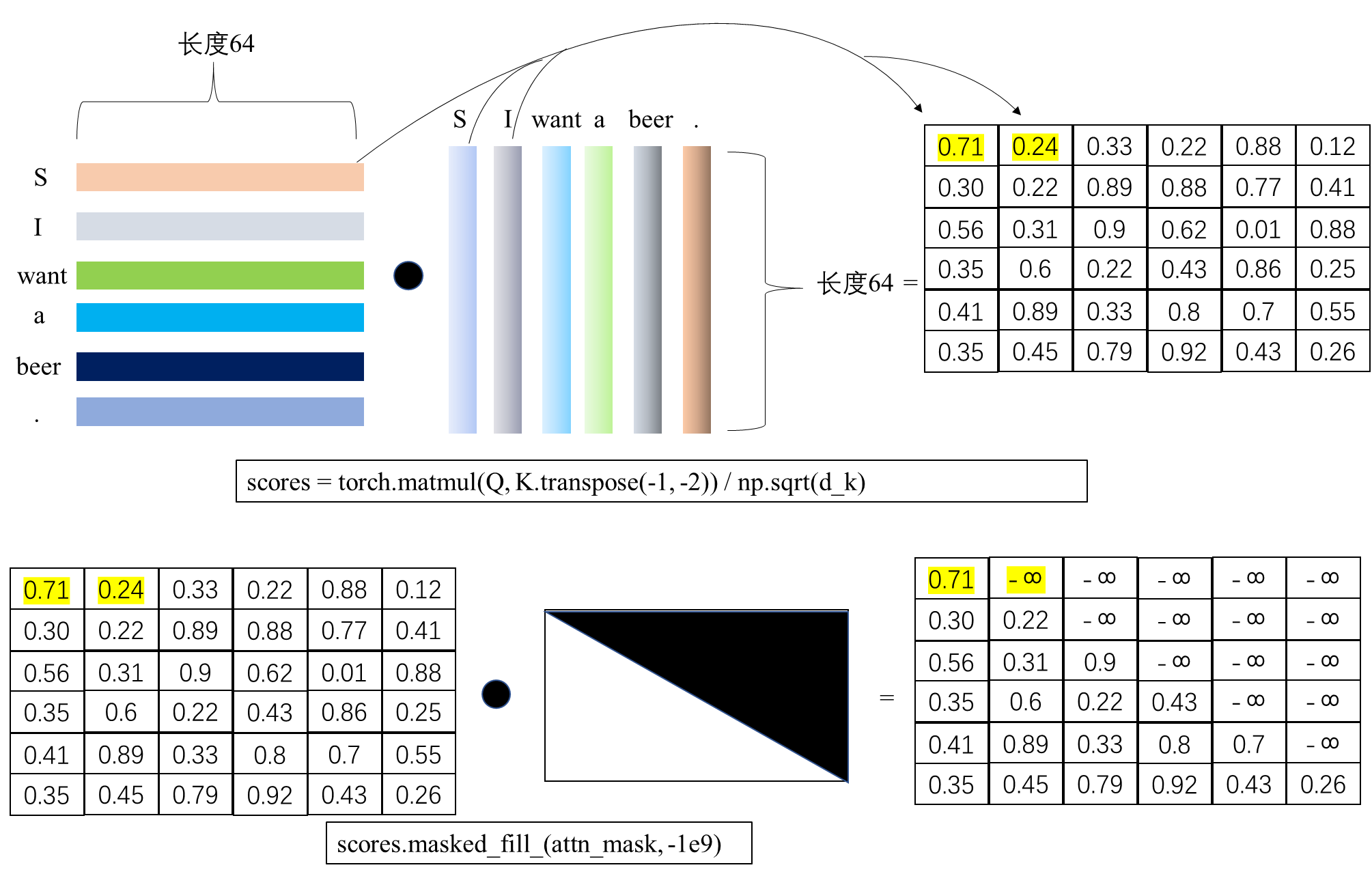
Transformer的PyTorch实现之若干问题探讨(二)
在《Transformer的PyTorch实现之若干问题探讨(一)》中探讨了Transformer的训练整体流程,本文进一步探讨Transformer训练过程中teacher forcing的实现原理。
1.Transformer中decoder的流程
在论文《Attention is all you need》中࿰…
Transformer实战-系列教程9:SwinTransformer 源码解读2(PatchEmbed类/BasicLayer类)
🚩🚩🚩Transformer实战-系列教程总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 点我下载源码 SwinTransformer 算法原理 SwinTransformer 源码解读1(项目配置/SwinTr…
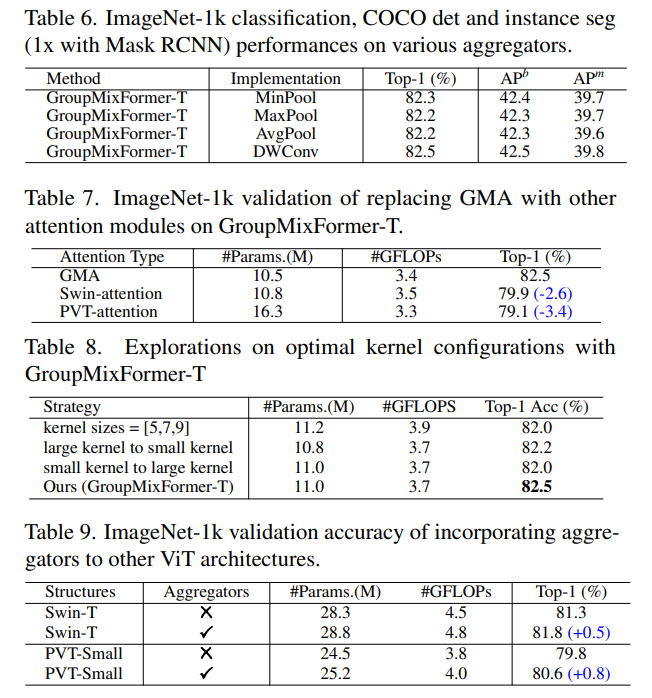
GroupMixFormer:基于Group-Mix注意力的视觉Transformer
文章目录 摘要1、简介2、相关工作2.1、视觉转换器2.2、全面的自注意力建模 3、组混合注意力和GroupMixFormer3.1. 动机:从个体到群体3.2. GMA: 混合组以获得更好的注意力3.3. 架构配置 4、实验4.1、实现细节4.2. 与最先进模型的比较4.3. 消融实验 5、结论 摘要
htt…
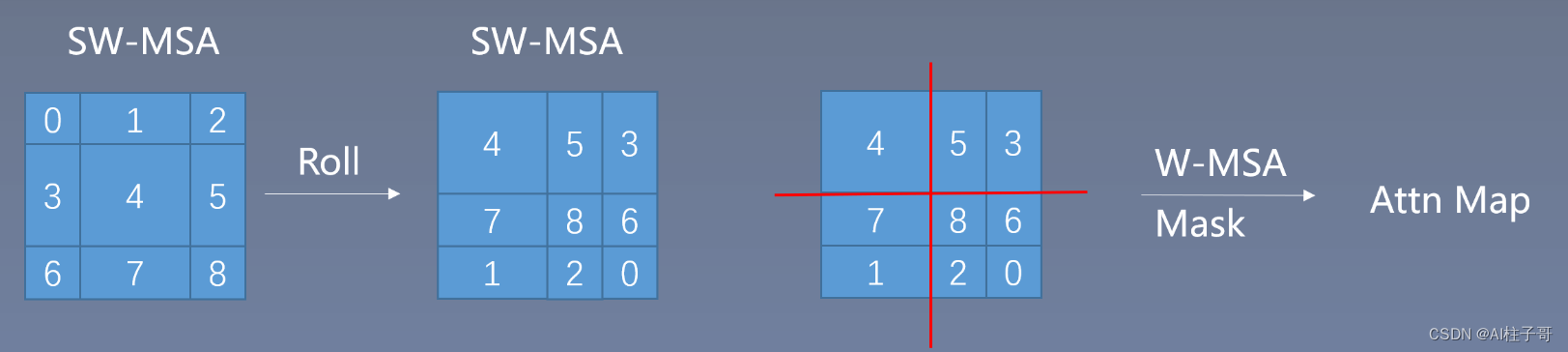
【AI】Swin Transformer源码解析
0. Swin Transformer简介
Swin Transformer指出,CV中的Token(处理单元)的大小不固定,并且数量相较于NLP要多。为解决这两个问题,Swin Transformer不仅使用了分层结构(金字塔结构),同时还提出了一种线性复杂…
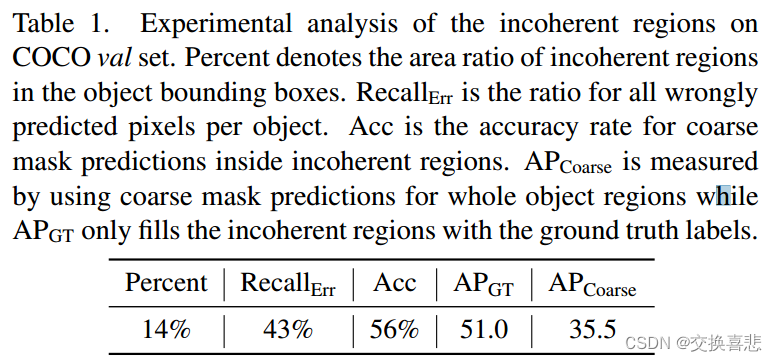
实例分割论文阅读之:《Mask Transfiner for High-Quality Instance Segmentation》
1.摘要
两阶段和基于查询的实例分割方法取得了显著的效果。然而,它们的分段掩模仍然非常粗糙。在本文中,我们提出了一种高质量和高效的实例分割Mask Transfiner。我们的Mask Transfiner不是在规则的密集张量上操作,而是将图像区域分解并表示…
Transformer实战-系列教程11:SwinTransformer 源码解读4(WindowAttention类)
🚩🚩🚩Transformer实战-系列教程总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 点我下载源码 SwinTransformer 算法原理 SwinTransformer 源码解读1(项目配置/SwinTr…
[论文精读]Community-Aware Transformer for Autism Prediction in fMRI Connectome
论文网址:[2307.10181] Community-Aware Transformer for Autism Prediction in fMRI Connectome (arxiv.org)
论文代码:GitHub - ubc-tea/Com-BrainTF: The official Pytorch implementation of paper "Community-Aware Transformer for Autism P…
【Transformer-Hugging Face 05/10】 使用 AutoClass 加载预训练实例
目录 一、说明二、自动分词器三、自动图像处理器四、自动特征提取器五、自动处理器六、自动模型七、在TensorFlow中八、自动骨干网 一、说明 由于有如此多不同的 Transformer 架构,为您的检查点创建一个架构可能具有挑战性。作为 Transformers 核心理念的一部分&am…

王树森《RNN Transformer》系列公开课
本课程主要介绍NLP相关,包括RNN、LSTM、Attention、Transformer、BERT等模型,以及情感识别、文本生成、机器翻译等应用
ShusenWang的个人空间-ShusenWang个人主页-哔哩哔哩视频 (bilibili.com) (一)NLP基础
1、数据处理基础
数…
Transformer实战-系列教程15:DETR 源码解读2(ConvertCocoPolysToMask类)
🚩🚩🚩Transformer实战-系列教程总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 点我下载源码 DETR 算法解读 DETR 源码解读1(项目配置/CocoDetection类) …
基于Transformer的机器学习模型的主动学习
主动学习和基于Transformer的机器学习模型的结合为有效地训练深度学习模型提供了强有力的工具。通过利用主动学习,数据科学家能够减少训练模型所需的标记数据的数量,同时仍然达到高精度。本文将探讨基于Transformer的机器学习模型如何在主动学习环境中使…

【AI视野·今日CV 计算机视觉论文速览 第298期】Fri, 26 Jan 2024
AI视野今日CS.CV 计算机视觉论文速览 Fri, 26 Jan 2024 Totally 71 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Multimodal Pathway: Improve Transformers with Irrelevant Data from Other Modalities Authors Yiyuan Zhang, Xiaohan …

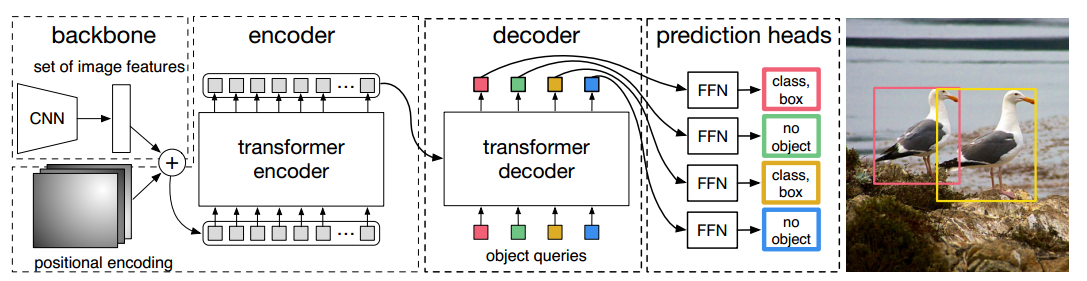
目标检测-Transformer-ViT和DETR
文章目录 前言一、ViT应用和结论结构及创新点 二、DETR应用和结论结构及创新点 总结 前言
随着Transformer爆火以来,NLP领域迎来了大模型时代,成为AI目前最先进和火爆的领域,介于Transformer的先进性,基于Transformer架构的CV模型…

文献阅读:Transformers are Multi-State RNNs
文献阅读:Transformers are Multi-State RNNs 1. 内容简介2. 方法介绍 1. 基础回顾 1. RNN2. Transformer 2. Transformer解构 1. MSRNN2. Transformer 3. TOVA 1. 现有转换策略2. TOVA 3. 实验考察 & 结论 1. 实验设计2. 实验结果 1. LM2. 长文本理解3. 文本生…

刘知远LLM——Transformer与预训练模型
文章目录 注意力机制原理介绍注意力机制的各种变式注意力机制的特点 Transformer结构概述Transformer整体结构 输入层byte pair encodingpositional encoding Transformer BlockEncoder BlockMulti-Head Attention Decoder Block其他tricks总结 预训练语言模型语言建模概述预训…
DDPM 论文总结 Denoising Diffusion Probabilistic Models
Denoising Diffusion Probabilistic Models (DDPM)
作者: Jonathan Ho, Ajay Jain, Pieter Abbeel概述: 论文提出了一种新的生成模型——去噪扩散概率模型(Denoising Diffusion Probabilistic Models, DDPM),受非平衡热力学的启发࿰…
Transformer 的双向编码器表示 (BERT)
一、说明 本文介绍语言句法中,最可能的单词填空在self-attention的表现形式,以及内部原理的介绍。 二、关于本文概述 在我之前的博客中,我们研究了关于生成式预训练 Transformer 的完整概述,关于生成式预训练 Transformer (GPT) 的…
CEEMDAN +组合预测模型(Transformer - BiLSTM+ ARIMA)
目录
往期精彩内容:
前言
1 风速数据CEEMDAN分解与可视化
1.1 导入数据
1.2 CEEMDAN分解
2 数据集制作与预处理
3 基于CEEMADN的 Transformer - BiLSTM 模型预测
3.1 定义CEEMDAN-Transformer - BiLSTM预测模型
3.2 设置参数,训练模型
4 基于A…
强化学习嵌入Transformer(代码实践)
这里写目录标题 ChatGPT的答案GPT4.0 ChatGPT的答案
# 定义Transformer模块
class Transformer(nn.Module):def __init__(self, input_dim, hidden_dim, num_heads, num_layers):super(Transformer, self).__init__()self.encoder_layer nn.TransformerEncoderLayer(d_modeli…
【python、nlp、transformer】transformer学习部分
注:
此博文仅为了解transformer架构,如果使用,建议直接调用库就行了
Transformer的优势
相比之前占领市场的LSTM和GRU模型,Transformer有两个显著的优势:
1. Transformer能够利用分布式GPU进行并行训练,…
『NLP学习笔记』图解 GPT-2(可视化 Transformer 语言模型)
图解 GPT-2(可视化 Transformer 语言模型) 文章目录 一. GPT-2和语言模型1.1. 什么是语言模型1.2 Transformer的语言模型1.3 和BERT的不同1.4 Transformer 组件的演变1.4.1 encoder组件1.4.2 decoder组件1.4.3 只有decoder组件的decoder模块1.5 GPT-2内部结构1.6 GPT-2内部结构…
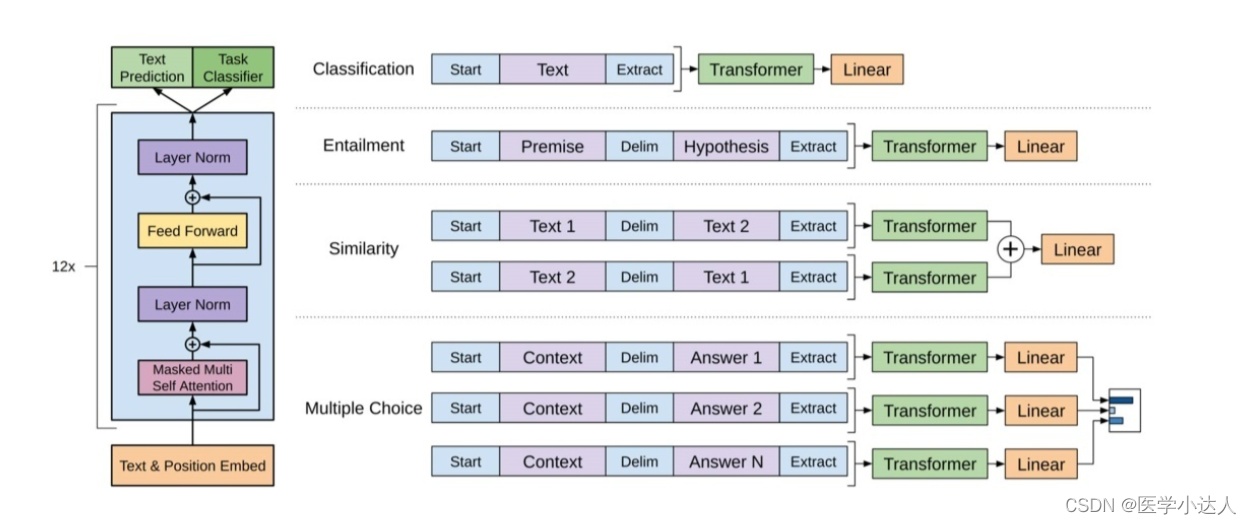
Transformer、Bert、Gpt对比系列,超详细介绍transformer的原理,bert和gpt的区别
一、Transformer架构图
Transformer 是一种用于序列到序列学习的神经网络模型,主要用于自然语言处理任务,如机器翻译、文本摘要等。它在2017年由 Google 提出,采用了注意力机制来对输入序列进行编码和解码。
Transformer 模型由编码器和解码…
Transformer、BERT和GPT 自然语言处理领域的重要模型
Transformer、BERT和GPT都是自然语言处理领域的重要模型,它们之间有一些区别和联系。
区别:
架构:Transformer是一种基于自注意力机制的神经网络架构,用于编码输入序列和解码输出序列。BERT(Bidirectional Encoder R…
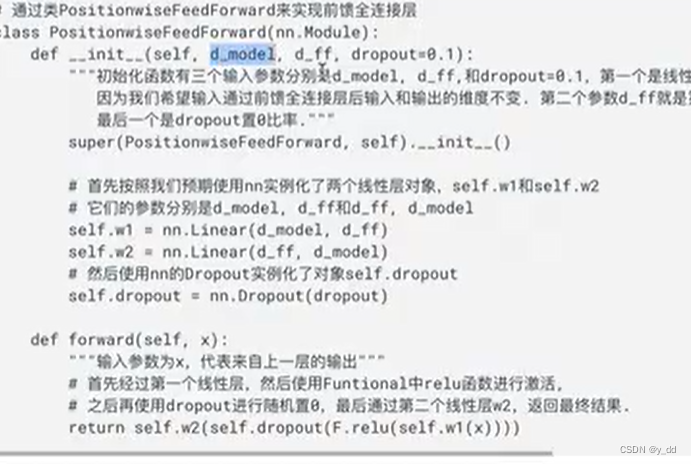
【自然语言处理六-最重要的模型-transformer-上】
自然语言处理六-最重要的模型-transformer-上 什么是transformer模型transformer 模型在自然语言处理领域的应用transformer 架构encoderinput处理部分(词嵌入和postional encoding)attention部分addNorm Feedforward & add && NormFeedforw…
python实现GA-GRU遗传算法优化门控循环单元多变量时间序列预测
GA-GRU遗传算法优化门控循环单元多变量时间序列预测是一个比较复杂的问题,需要一定的编程和数学基础。下面是一个简单的Python实现,供参考:
首先,我们需要导入相关的库:
python import numpy as np import pandas as…
极智AI | 谈谈AI发展第一篇:AI训练框架
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文来谈谈 AI训练框架的发展,是谈谈AI发展系列的第一篇。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码下载,链接:https://t.zsxq.com/0aiNxERDq 时光斗转星移,AI 飞速…

【李沐论文精读】Transformer精读
论文:Attention is All You Need 参考:李沐视频【Transformer论文逐段精读】、Transformer论文逐段精读【论文精读】、李沐视频精读系列 一、摘要 主流的序列转换(sequence transduction)模型都是基于复杂的循环或卷积神经网络,这个模型包含一…
LLM int4算法autoround v0.1即将发布,欢迎试用
概述
AutoRound(https://github.com/intel/auto-round)实现了出色的量化性能,在W4G128上多数场景中接近无损压缩,适用于包括gemma-7B、Mistral-7b、Mixtral-8x7B-v0.1、Mixtral-8x7B-Instruct-v0.1、Phi2、LLAMA2等一系列流行模型…
大语言模型LLM分布式训练:大规模数据集上的并行技术全景探索(LLM系列03)
文章目录 大语言模型LLM分布式训练:大规模数据集上的并行技术全景探索(LLM系列03)1. 引言1.1 大语言模型(LLM)的重要性及其规模化挑战1.2 分布式训练策略的需求 2. 分布式训练基础原理2.1 并行计算的基本概念与分类 3.…

Multi-Head Attention详解
文中大部分内容以及图片来自:https://medium.com/hunter-j-phillips/multi-head-attention-7924371d477a
当使用 multi-head attention 时,通常d_key d_value (d_model / n_heads),其中n_heads是头的数量。研究人员称…
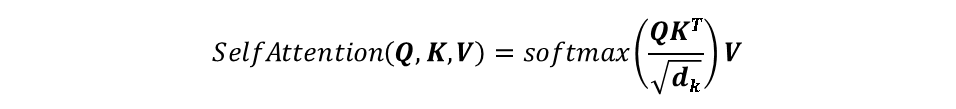
Transformer中的自注意力机制计算过程分析
目录
1 什么是自注意力机制
2 自注意力的计算过程 1 什么是自注意力机制
自注意力机制(Self-Attention)顾名思义就是关注单个序列内部元素之间的相关性,不仅可以用于 seq2seq 的机器翻译模型,还能用于情感分析、内容提取等场景…
手写 Attention 迷你LLaMa2——LLM实战
https://github.com/Yuezhengrong/Implement-Attention-TinyLLaMa-from-scratch
1. Attention
1.1 Attention 灵魂10问
你怎么理解Attention?
Scaled Dot-Product Attention中的Scaled: 1 d k \frac{1}{\sqrt{d_k}} dk 1 的目的是调节内积&…
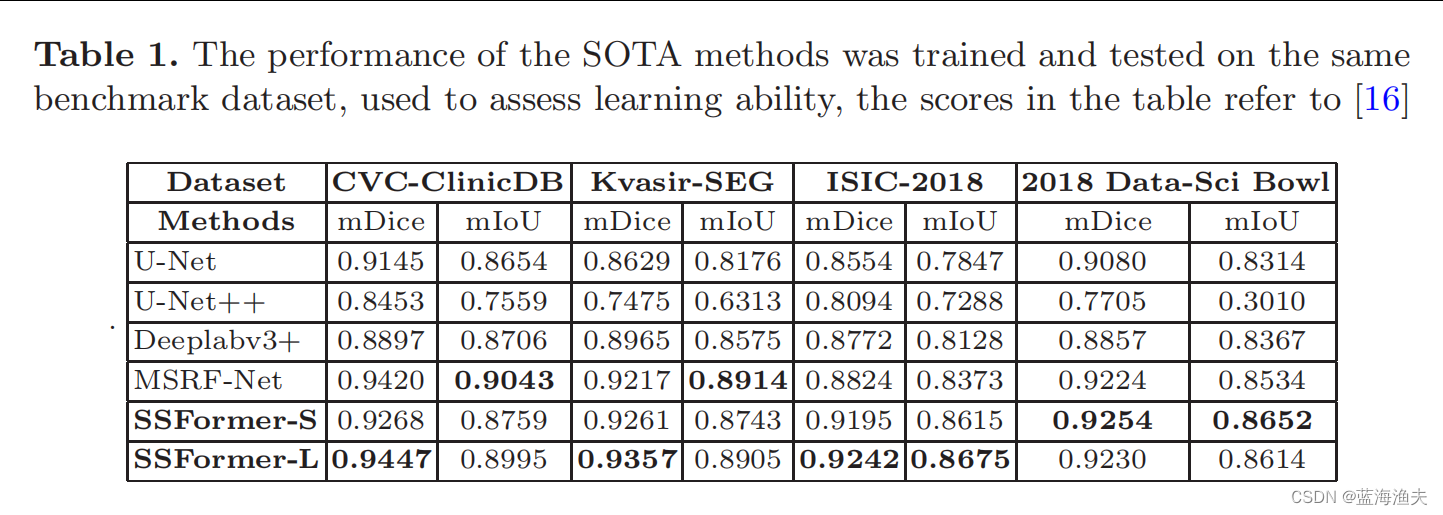
论文阅读 Stepwise Feature Fusion: Local Guides Global
1,另一个ssfomer
我在找论文时发现,把自己的分割模型命名为ssformer的有两个:,一个论文SSformer: A Lightweight Transformer for Semantic Segmentation中提出的一种轻量级Transformer模型,结构如下 这个结构很简单&…
transformer注意力权重系数绘图
参考绘制tsne图,首先将模型中的注意力权重导出,因为我的模型中L2,所以导出两层
# plot_weight
weight_model_layer0 Model(inputsmodel.inputs, outputsmodel.get_layer(transformer_0).output)
weight_output_layer0 weight_model_layer0…
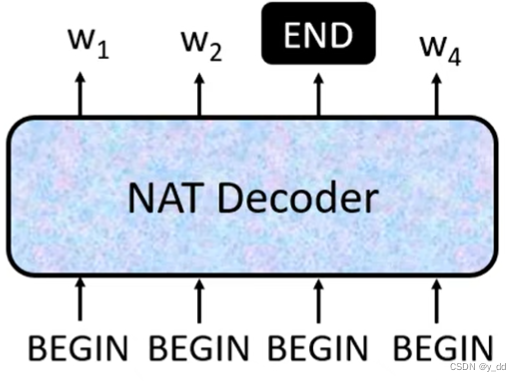
【自然语言处理六-最重要的模型-transformer-下】
自然语言处理六-最重要的模型-transformer-下 transformer decoderMasked multi-head attentionencoder和decoder的连接部分-cross attentiondecoder的输出AT(Autoregresssive)NAT transformer decoder
今天接上一篇文章讲的encoder 自然语言处理六-最重要的模型-transformer-…
Latte:一个类似Sora的开源视频生成项目
前段时间OpenAI发布的Sora引起了巨大的轰动,最长可达1分钟的高清连贯视频生成能力秒杀了一众视频生成玩家。因为Sora没有公开发布,网上对Sora的解读翻来覆去就那么多,我也不想像复读机一样再重复一遍了。
本文给大家介绍一个类似Sora的视频生…
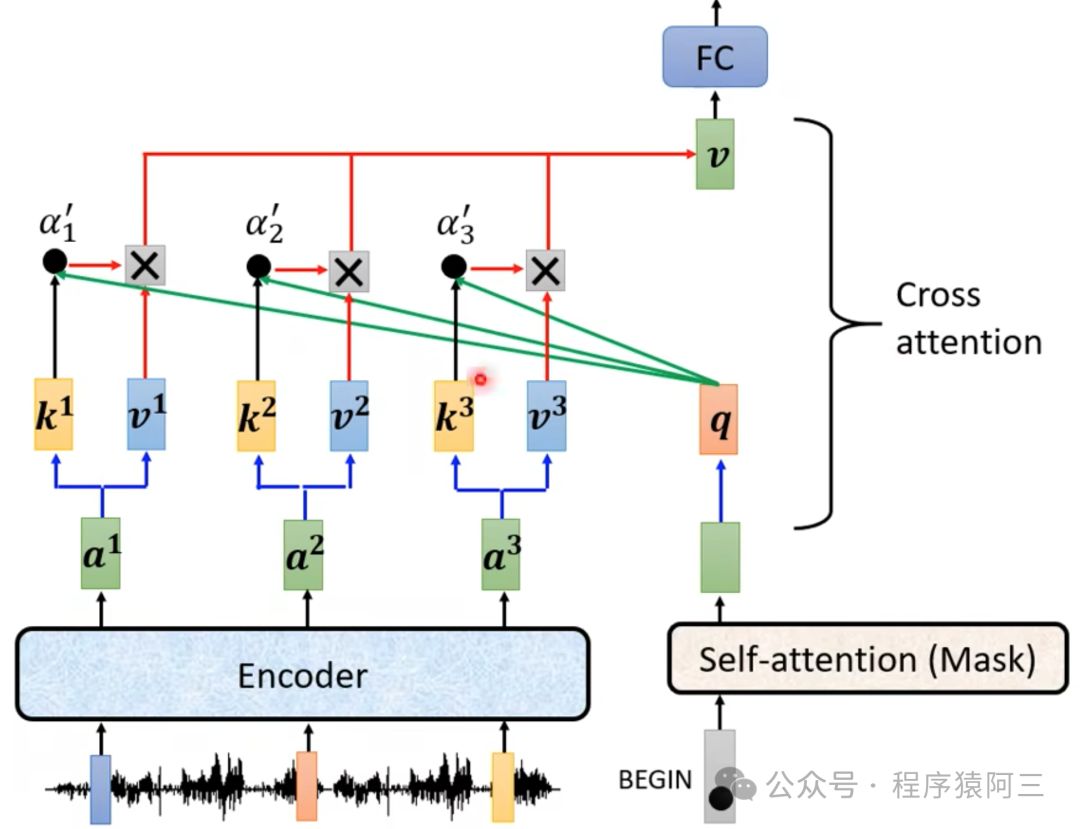
Transformer原理
在《机器学习综述》中大致罗列人工智能常见算法,近些年深度学习发展快速,其中Transformer为甚,其英文的意思是变形金刚,对的就是我们看电影变形金刚的意思。Transformer是大语言模型的基础,比如现在常见的GPT、Bert、P…
Bert基础(一)--自注意力机制
1、简介
当下最先进的深度学习架构之一,Transformer被广泛应用于自然语言处理领域。它不单替代了以前流行的循环神经网络(recurrent neural network, RNN)和长短期记忆(long short-term memory, LSTM)网络,并且以它为基础衍生出了诸如BERT、GPT-3、T5等…
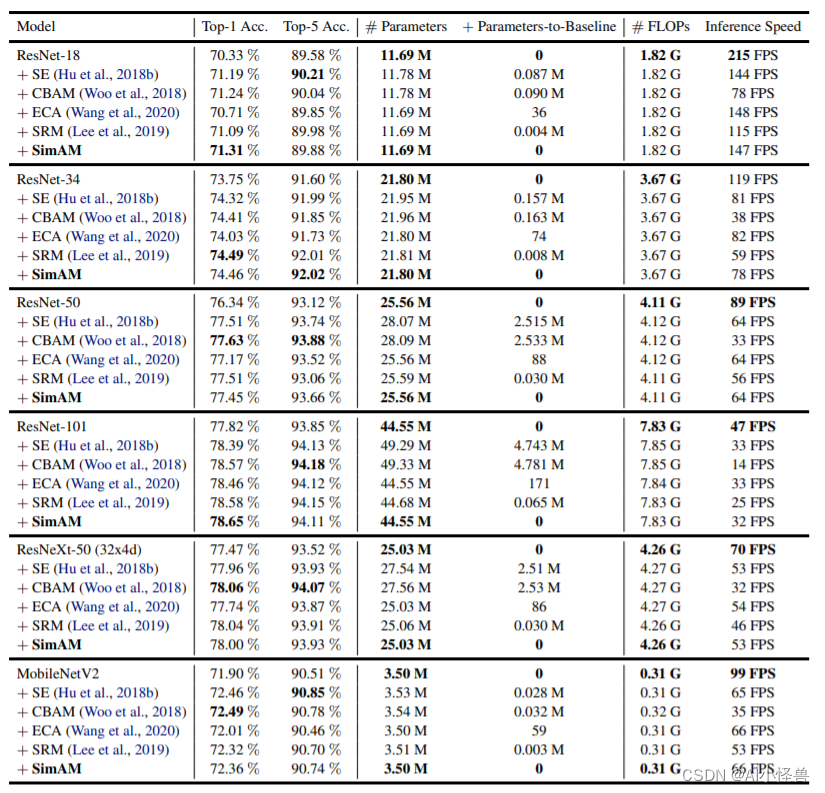
YOLOv9改进策略:注意力机制 | SimAM(无参Attention),效果秒杀CBAM、SE
💡💡💡本文改进内容:SimAM是一种轻量级的自注意力机制,其网络结构与Transformer类似,但是在计算注意力权重时使用的是线性层而不是点积
yolov9-c-CoordAtt summary: 972 layers, 51024476 parameters, 510…
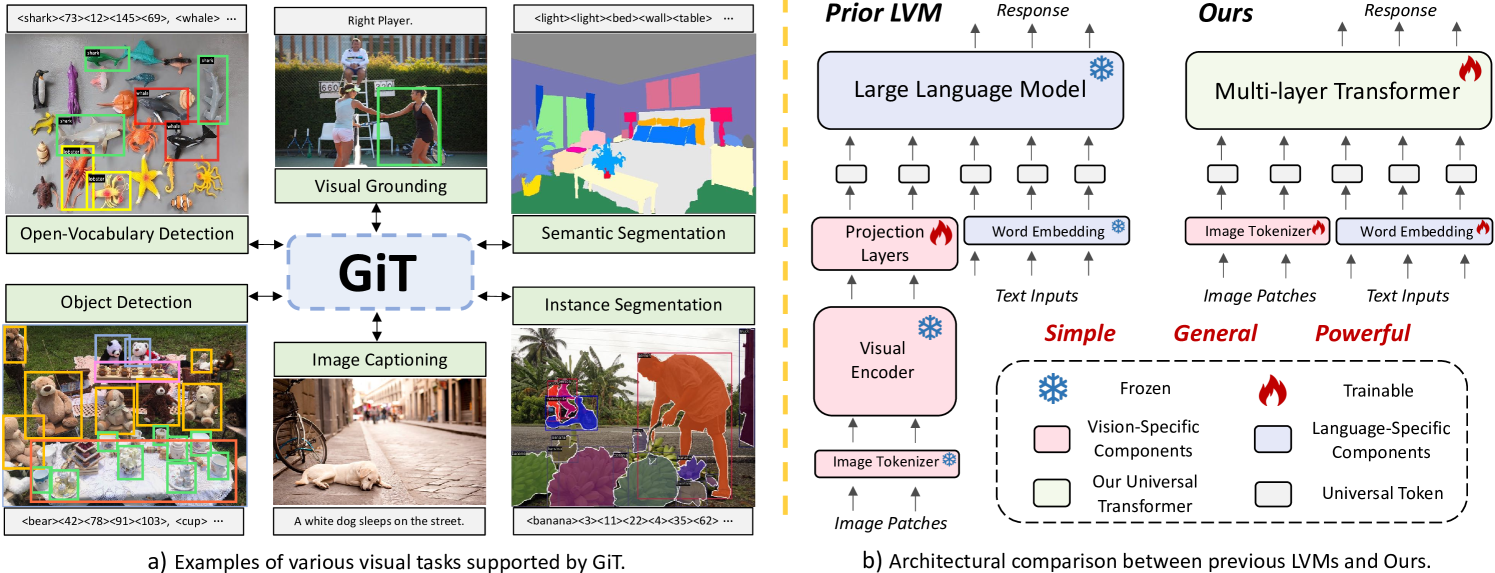
GiT: Towards Generalist Vision Transformer through Universal Language Interface
GiT: Towards Generalist Vision Transformer through Universal Language Interface 相关链接:arxiv github 关键字:Generalist Vision Transformer (GiT)、Universal Language Interface、Multi-task Learning、Zero-shot Transfer、Transformer 摘要 …

探索LLaMA模型:架构创新与Transformer模型的进化之路
引言
在人工智能和自然语言处理领域,预训练语言模型的发展一直在引领着前沿科技的进步。Meta AI(前身为Facebook)在2023年2月推出的LLaMA(Large Language Model Meta AI)模型引起了广泛关注。LLaMA模型以其独特的架构…
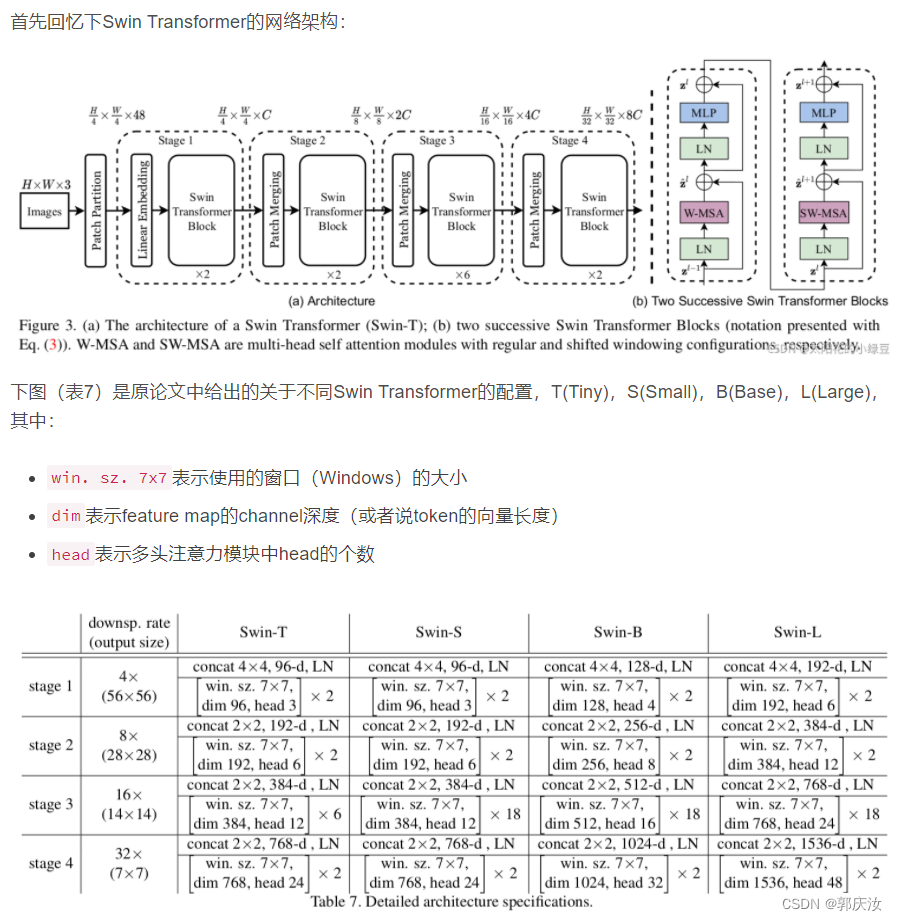
经典网络模型系列——Swin-Transformer详细讲解与代码实现
经典网络模型系列——Swin-Transformer详细讲解与代码实现一、网路模型整体架构二、Patch Partition模块详解三、Patch Merging模块四、W-MSA详解五、SW-MSA详解masked MSA详解六、 Relative Position Bias详解七、模型详细配置参数八、重要模块代码实现:1、Patch P…
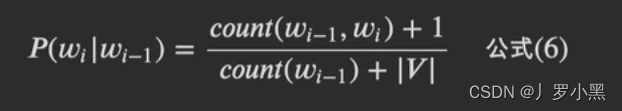
Transformer的前世今生 day01(预训练、统计语言模型)
预训练
在相似任务中,由于神经网络模型的浅层是通用的,如下图: 所以当我们的数据集不够大,不能产生性能良好的模型时,可以尝试让模型B在用模型A的浅层基础上,深层的部分自己生成参数,减小数据集…
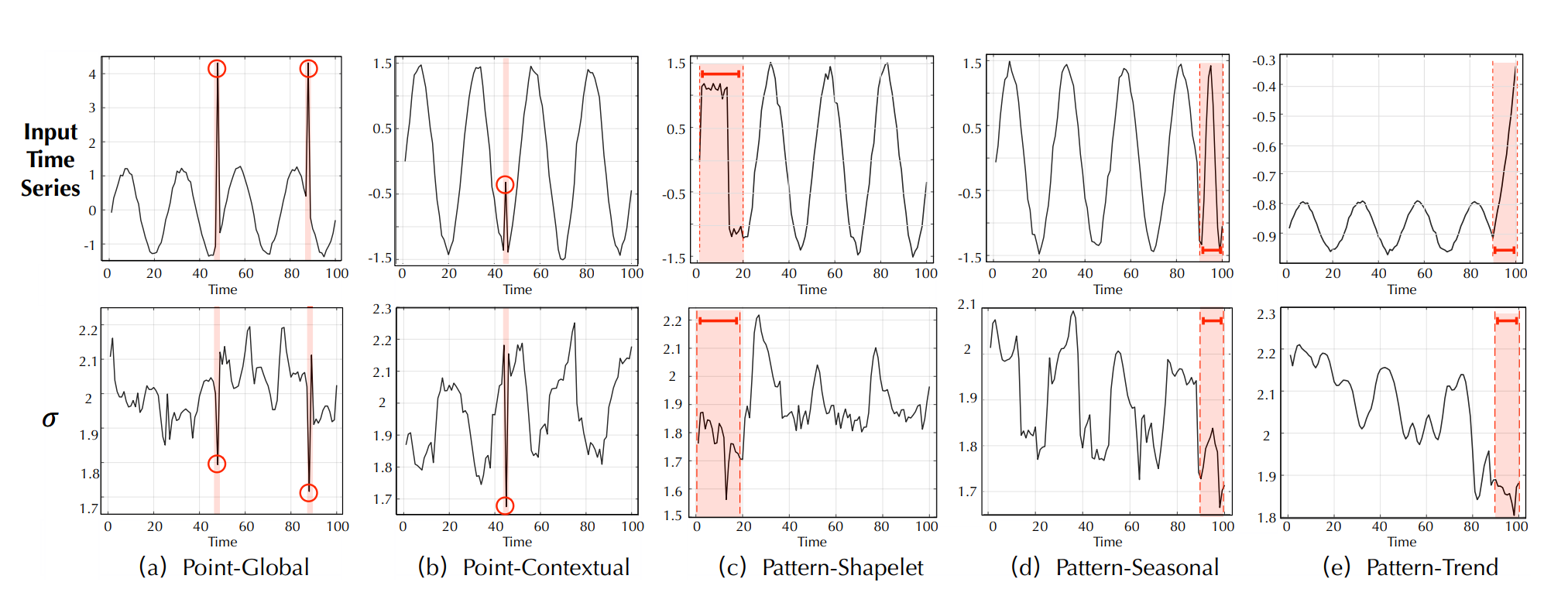
ANOMALY TRANSFORMER: TIME SERIES ANOMALY DETECTION WITH ASSOCIATION DISCREPANCY
论文题目: ANOMALY TRANSFORMER: TIME SERIES ANOMALY DETECTION WITH ASSOCIATION DISCREPANCY 发表会议:ICLR 2022 论文地址:https://openreview.net/pdf?idLzQQ89U1qm_ 论文代码:https://github.com/thuml/Anomaly-Transforme…
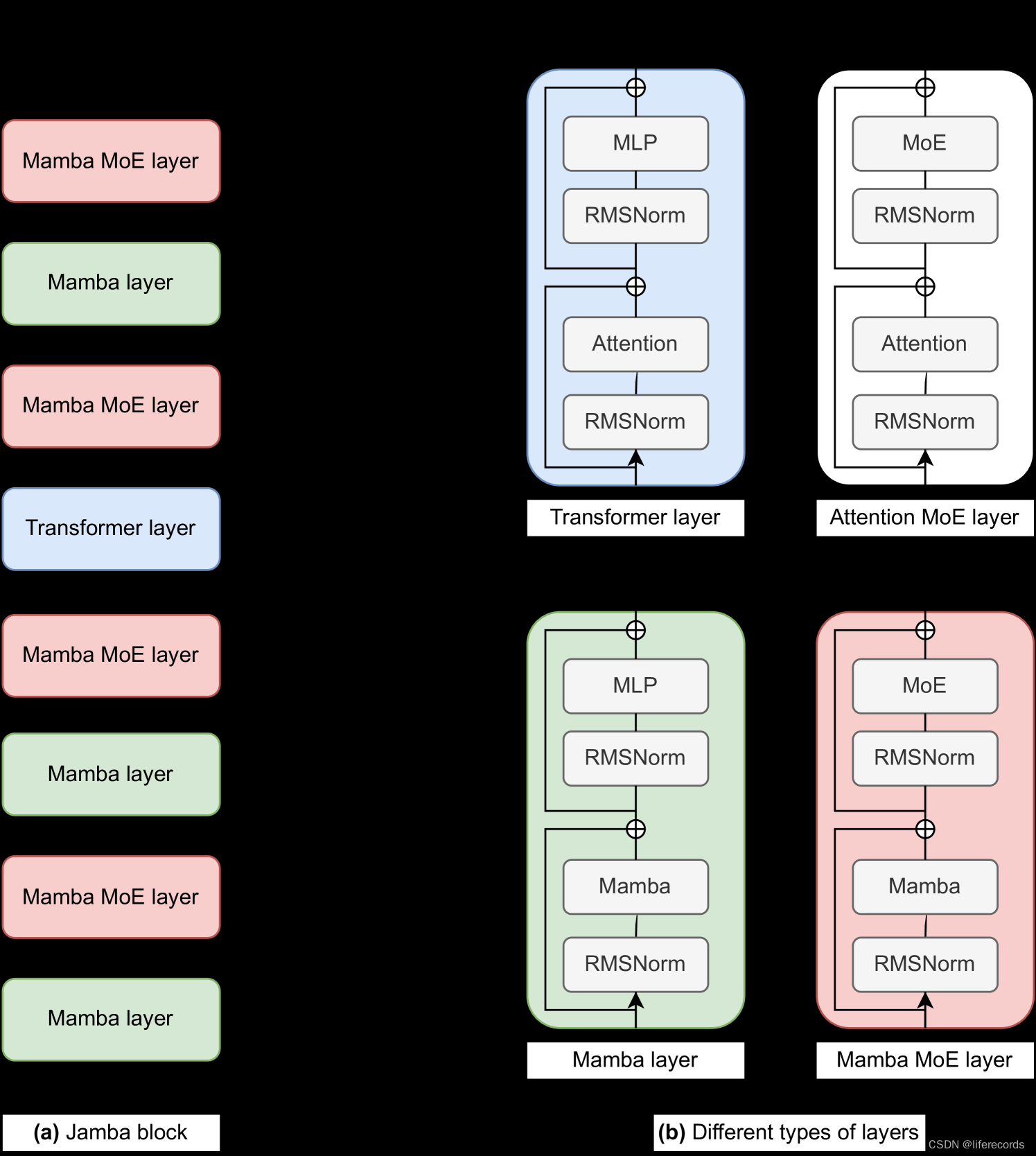
Jamba: A Hybrid Transformer-Mamba Language Model
Jamba: A Hybrid Transformer-Mamba Language Model 相关链接:arXiv 关键字:hybrid architecture、Transformer、Mamba、mixture-of-experts (MoE)、language model 摘要
我们介绍了Jamba,一种新的基于新颖混合Transformer-Mamba混合专家&am…
Transformer学习-最简DEMO实现字符串转置
Transformer学习-最简DEMO实现字符串转置 一.代码二.参考三.输出 背景:调试AI加速卡在Pytorch训练时的精度问题,搭建了一个简单的Transformer,设置随机种子,保证每次重训练loss完全一致,可以直接对比各算子的计算误差 一.代码
import os
import random
import numpy as np
imp…
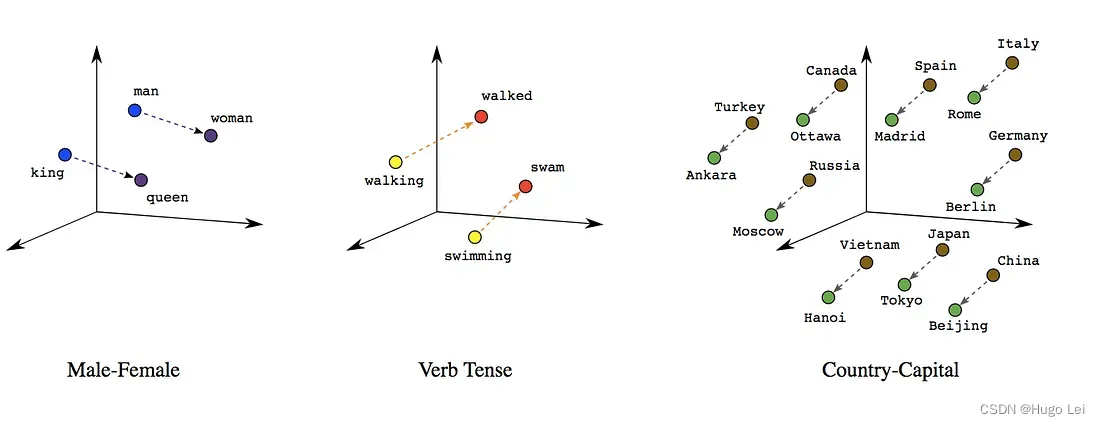
LLM资料:中文embedding库
Highlight(重点提示)
理解LLM,就要理解Transformer,但其实最基础的还是要从词的embedding讲起。
毕竟计算机能处理的只有数字,所以万事开头的第一步就是将要处理的任务转换为数字。 面向中文的开源embedding库在自然…

神经网络学习笔记10——RNN、ELMo、Transformer、GPT、BERT
系列文章目录
参考博客1
参考博客2 文章目录 系列文章目录前言一、RNN1、简介2、模型结构3、RNN公式分析4、RNN的优缺点及优化1)LSTM是RNN的优化结构2)GRU是LSTM的简化结构 二、ELMo1、简介2、模型结构1)输入2)左右双向上下文信…
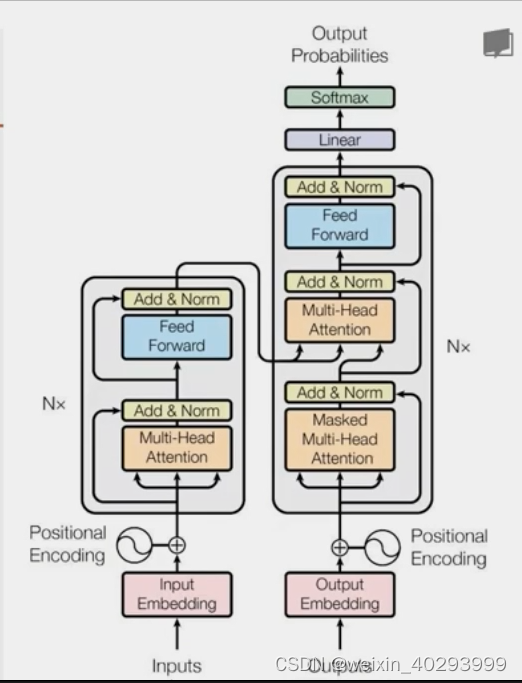
【深度学习】知识点归纳总结-for 面试【自用】
add 和 concat的区别
特征add的时候就是增加特征的信息量,特征concat的时候就是增加特征的数量,注重细节的时候使用add,注重特征数量的时候使用concat,
resnet用的add densenet用的concat
RNN应用
一、关键字提取(…

因果学习篇(2)-Causal Attention for Vision-Language Tasks(文献阅读)
Causal Attention for Vision-Language Tasks
引言 这篇论文是南洋理工大学和澳大利亚莫纳什大学联合发表自2021年的CVPR顶会上的一篇文献,在当前流行的注意力机制中增加了因果推理算法,提出了一种新的注意力机制:因果注意力(CATT)ÿ…
transformer--使用transformer构建语言模型
什么是语言模型?
以一个符合语言规律的序列为输入,模型将利用序列间关系等特征,输出一个在所有词汇上的概率分布.这样的模型称为语言模型.
# 语言模型的训练语料一般来自于文章,对应的源文本和目标文本形如:
src1"Ican do",tgt1…
ChatGPT的原理与应用场景和应用范围
ChatGPT是一种基于人工智能技术的聊天机器人,它可以模拟人类的语言交互,为用户提供自然、便捷的服务。ChatGPT的应用场景非常广泛,可以应用于各种领域,例如客服、教育、医疗、金融等。
一、学习目标 了解ChatGPT的基本原理和技术…
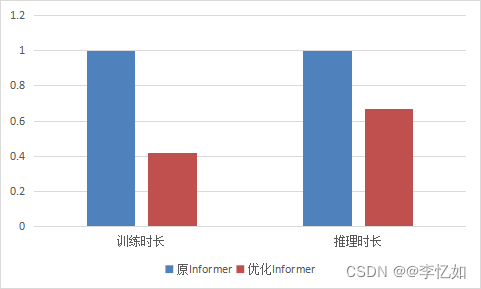
基于Informer的股票价格预测(量化交易综述)
摘要
股票市场是金融市场中不可或缺的组成部分。准确预测股票趋势对于投资者和市场参与者具有重要意义,因为它们可以指导投资决策、优化投资组合以及降低金融风险。而且可以提升国家国际地位以及金融风险控制能力,还可以促进股票市场发展以及资源优化利…

【计算机视觉】CVPR 23 | 视觉 Transformer 全新学习范式!用长尾数据提升ViT性能
文章目录 一、导读二、介绍三、方法四、总结 一、导读
论文地址:
https://arxiv.org/abs/2212.02015代码链接:
https://github.com/XuZhengzhuo/LiVT二、介绍
在机器学习领域中,学习不平衡的标注数据一直是一个常见而具有挑战性的任务。近…
第十章 ShuffleNetv2网络详解
系列文章目录 第一章 AlexNet网络详解
第二章 VGG网络详解
第三章 GoogLeNet网络详解
第四章 ResNet网络详解
第五章 ResNeXt网络详解
第六章 MobileNetv1网络详解
第七章 MobileNetv2网络详解
第八章 MobileNetv3网络详解
第九章 ShuffleNetv1网络详解
第十章…
深入理解深度学习——BERT(Bidirectional Encoder Representations from Transformers):基础知识
分类目录:《深入理解深度学习》总目录 BERT全称为Bidirectional Encoder Representations from Transformers,即来自Transformers的双向编码器表示,是谷歌发表的论文Pre-training of Deep Bidirectional Transformers for Language Understan…
Huggingface中Transformer模型使用
NLP自从Transformer模型出现后,处理方式有大统一的趋势,首先回答几个基础问题:
1、自然语言处理究竟要做一件什么事呢?自然语言处理最终解决的是分类问题,但是它不仅仅输出一个分类的预测结果,关键的在于构…
DataWhale公开课笔记2:Diffusion Model和Transformer Diffusion
Stable Diffusion和AIGC
AIGC是什么
AIGC的全称叫做AI generated content,AlGC (Al-Generated Content,人工智能生产内容),是利用AI自动生产内容的生产方式。
在传统的内容创作领域中,专业生成内容(PGC)…
transformer入门
import torch# pytorch import torch.nn as nn# 模型工具包 import torch.nn.functional as F# 函数运算工具包 from torch.autograd import Variable# 变量处理包 import math import matplotlib.pyplot as pyp import numpy as np import copy # 在深度学习自然语言的学习过程…

改进YOLOv5系列:增加Swin-Transformer小目标检测头
💡统一使用 YOLOv5 代码框架,结合不同模块来构建不同的YOLO目标检测模型。🌟本项目包含大量的改进方式,降低改进难度,改进点包含【Backbone特征主干】、【Neck特征融合】、【Head检测头】、【注意力机制】、【IoU损失函数】、【NMS】、【Loss…

【Transformer 相关理论深入理解】注意力机制、自注意力机制、多头注意力机制、位置编码
目录前言一、注意力机制:Attention二、自注意力机制:Self-Attention三、多头注意力机制:Multi-Head Self-Attention四、位置编码:Positional EncodingReference前言
最近在学DETR,看源码的时候,发现自己对…
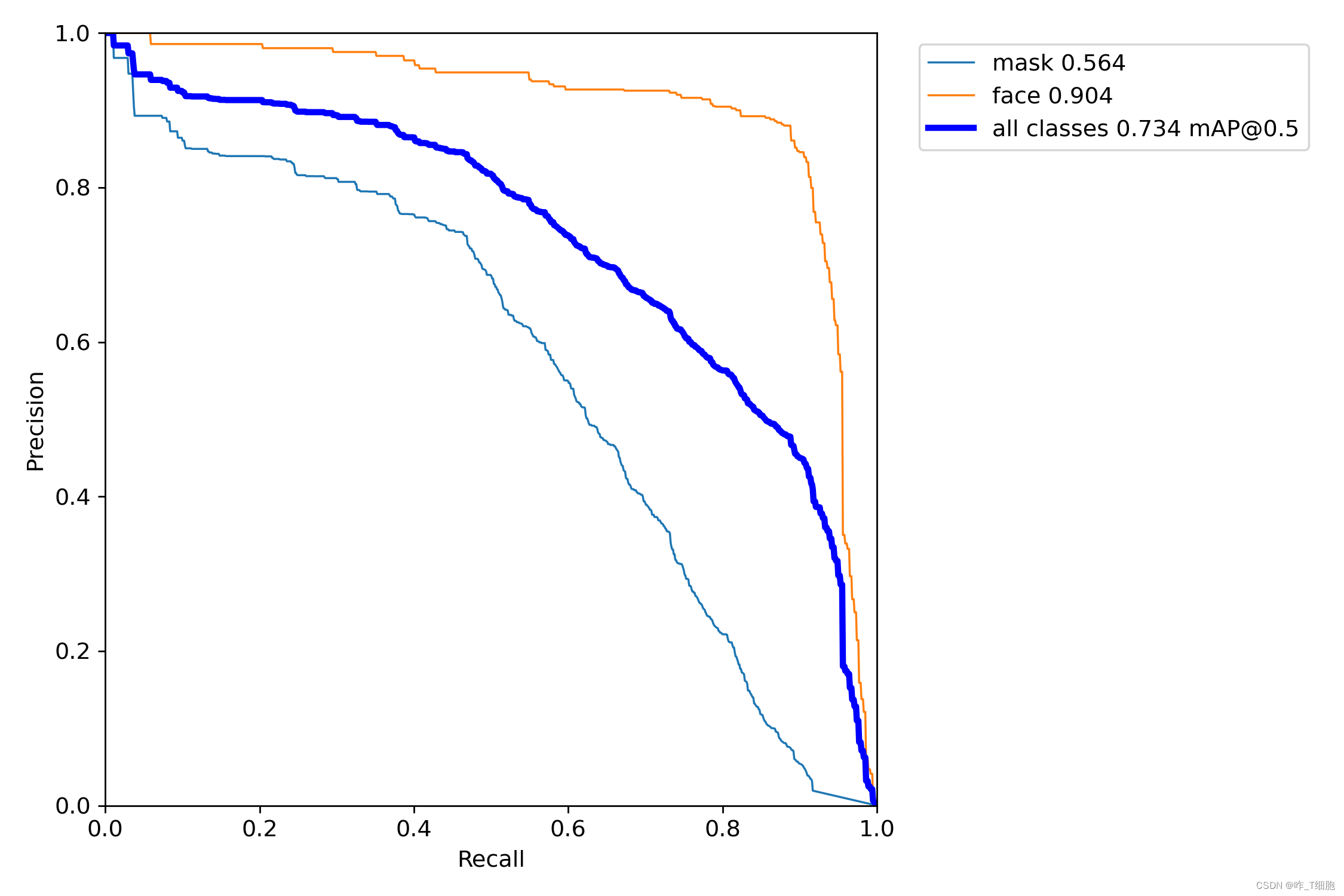
Yolov5:强大到你难以想象──新冠疫情下的口罩检测
初识Yolov5是看到一个视频可以检测街道上所有的行人,并实时框选出来。之后学习了CNN卷积神经网络,在完成一个项目需求时,发现卷积神经网络在切割图像方面仍然不太好用。于是我想到了之前看到的Yolov5,实战后不禁感慨一句ÿ…

MaxViT: Multi-Axis Vision Transformer
论文:https://arxiv.org/abs/2204.01697 代码地址:https://github.com/google-research/maxvit
在本文中,介绍了一种高效且可扩展的注意力模型,称之为多轴注意力,该模型由两个方面组成:分块的局部注意力和…

论文阅读《Restormer: Efficient Transformer for High-Resolution Image Restoration》
论文地址:https://openaccess.thecvf.com/content/CVPR2022/html/Zamir_Restormer_Efficient_Transformer_for_High-Resolution_Image_Restoration_CVPR_2022_paper.html 源码地址:https://github.com/swz30/Restormer 概述 图像恢复任务旨在从受到各种扰动(噪声、模糊、雨滴…

计算机视觉算法——基于Transformer的语义分割(SETR / Segmenter / SegFormer)
计算机视觉算法——基于Transformer的语义分割(SETR / Segmenter / SegFormer)1. SETR1.1 网络结构及特点1.1.1 Decoder1.2 实验2. Segmenter2.1 网络结构及特点2.1.1 Decoder2.2 实验3. SegFormer3.1 网络结构及特点3.1.1 Overlap Patch Merging3.1.2 E…
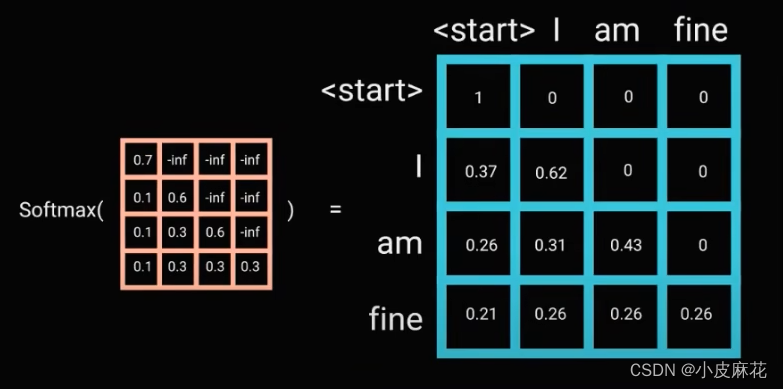
Transformer总结和梳理
Transformer总结和梳理Positional encodingSelf-attentionMulti--head-attentionAdd&NormAdd操作Norm操作FeedForwardMASKPadding MaskedSelf-Attention Masked首先来看一下Transformer结构的结构:Transformer是由Encoder和Decoder两大部分组成,首先…

弄懂Transformer Layer 和Transformer Block的关系后,豁然开朗
一篇论文引发的讨论: Q:Transformer Layer 和Transformer Block是什么意思? A: Transformer Layer表示Transformer层,Transformer Block表示Transformer块。 Q:我不是来学英语的,Transformer La…

Talk | 微软亚洲研究院宋恺涛南大余博涛:面向文本/音乐序列任务的Transformer注意力机制设计
本期为TechBeat人工智能社区第456期线上Talk! 北京时间11月22日(周二)20:00,微软亚洲研究院研究员——宋恺涛与南京大学硕士研究生——余博涛的Talk将准时在TechBeat人工智能社区开播! 他们与大家分享的主题是: “面向文本/音乐序列任务的Tra…

Transformer与看图说话
🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅🏅 一年一度的【博客之星】评选活动已开始啦 作为第一…
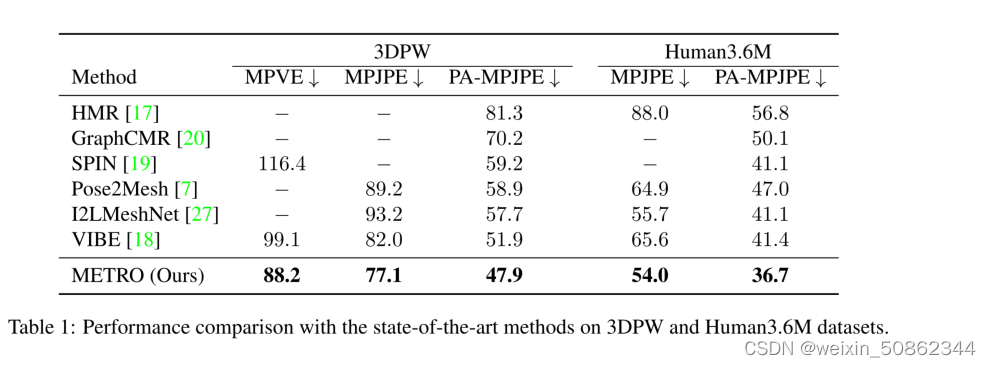
【论文翻译】End-to-End Human Pose and Mesh Reconstruction with Transformers
【cvpr论文】End-to-End Human Pose and Mesh Reconstruction with Transformers (thecvf.com)
【github】microsoft/MeshTransformer: Research code for CVPR 2021 paper "End-to-End Human Pose and Mesh Reconstruction with Transformers" (github.com) 摘要 我…
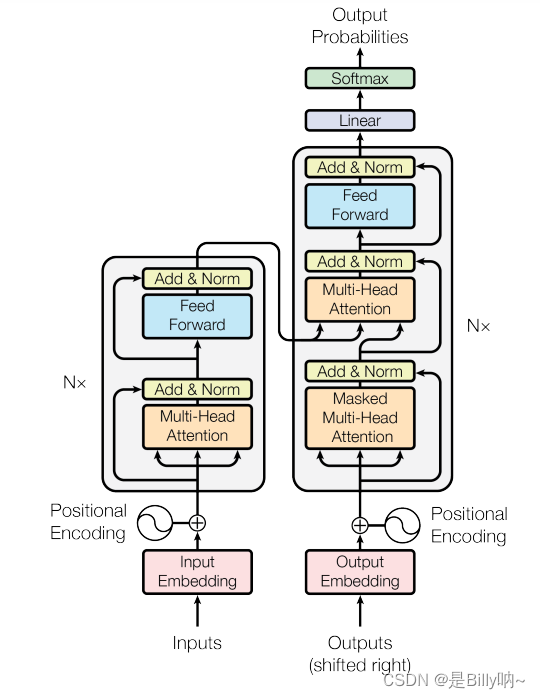
基于Pytorch,从头开始实现Transformer(编码器部分)
Transformer理论部分参考知乎上的这篇文章
Transformer的Attention和Masked Attention部分参考知乎上的这篇文章
Transformer代码实现参考这篇文章,不过这篇文章多头注意力实现部分是错误的,需要注意。
完整代码放到github上了,链接 Trans…
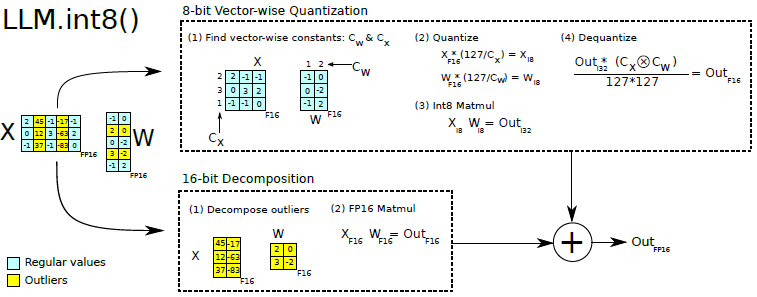
生成式语言大模型压缩技术思考——以ChatGPT为例
ChatGPT引领了生成式语言大模型的应用与技术热潮,首先简单回顾ChatGPT应用范式:将其应用于指定的下游任务时(如知识问答、翻译、编码),ChatGPT需要经历三个阶段的训练(增强人类语境的猜想)&…

【图-注意力笔记,篇章2】Graphormer 和 GraphFormers论文笔记之两篇经典Graph Transformer来入门
Graphormer 和 GraphFormers的论文笔记前情回顾论文信息概览Graphormer论文信息概览论文核心要点介绍三大编码的介绍Centrality EncodingSpatial EncodingEdge Encoding其他一些需要注意的点结果概览及分析GraphFormer论文信息概览论文核心要点介绍背景的了解要点介绍结果概览及…

论文解读:ChangeFormer | A TRANSFORMER-BASED SIAMESE NETWORK FOR CHANGE DETECTION
论文地址:https://arxiv.org/pdf/2201.01293.pdf 项目代码:https://github.com/wgcban/ChangeFormer 发表时间:2022
本文提出了一种基于transformer的siamese网络架构(ChangeFormer),用于一对共配准遥感图…
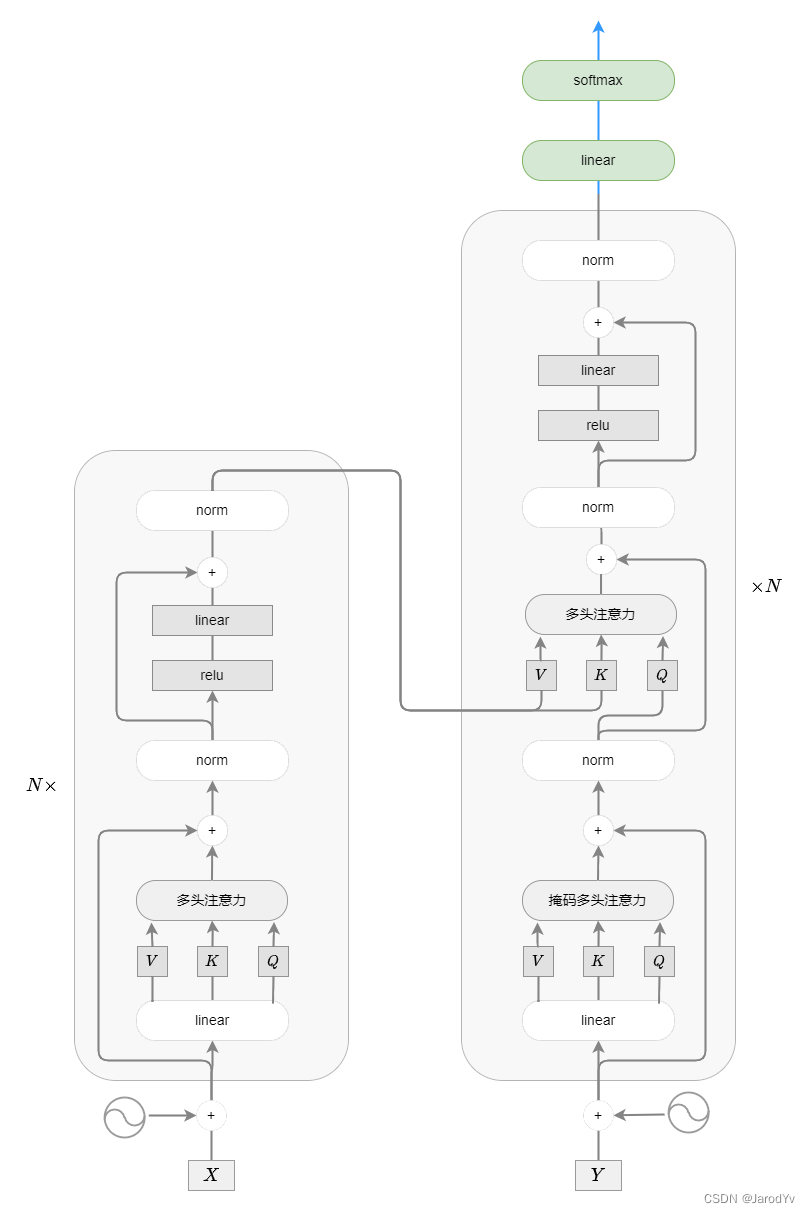
图解NLP模型发展:从RNN到Transformer
图解NLP模型发展:从RNN到Transformer
自然语言处理 (NLP) 是深度学习中一个颇具挑战的问题,与图像识别和计算机视觉问题不同,自然语言本身没有良好的向量或矩阵结构,且原始单词的含义也不像像素值那么确定和容易表示。一般我们需…

Table Transformer做表格检测和识别实践
计算机视觉方面的三大顶级会议:ICCV,CVPR,ECCV.统称ICE CVPR 2022文档图像分析与识别相关论文26篇汇集简介
论文: PubTables-1M: Towards comprehensive table extraction from unstructured documents是发表于CVPR上的一篇论文 作者发布了两个模型&…
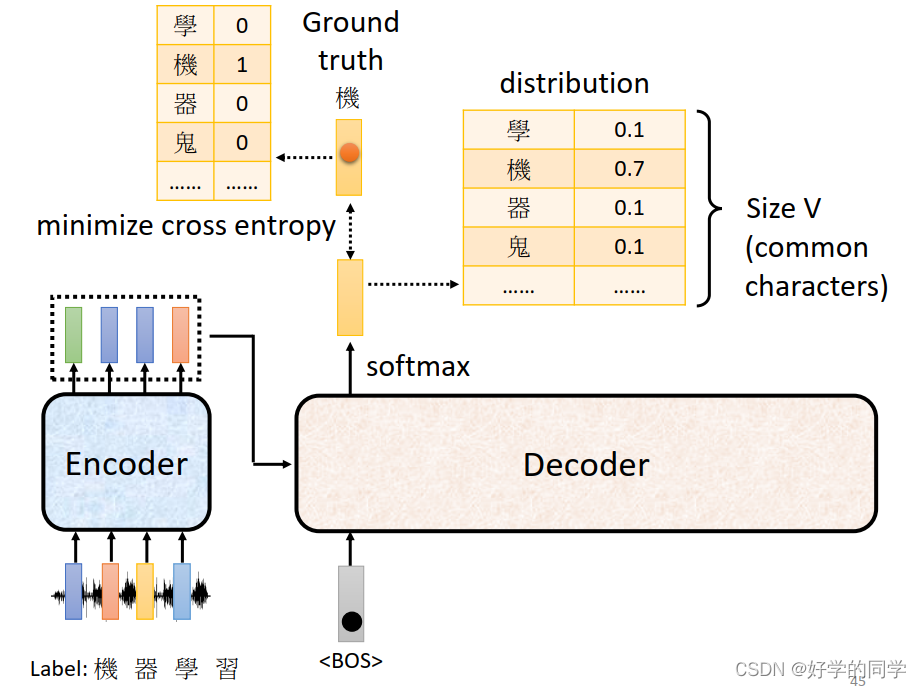
李宏毅2021春季机器学习课程视频笔记14-Transformer
Transformer Transformer实际上就是变形金刚,其与Bert实际类似。其实际上就是一个Sequence-to-Sequence的模型,其输出的长度并不是由人为指定,而是由机器自行确定。 Transformer的基本结构,如上图所示,主要由一个Encod…
transformer在时序预测上如何应用
直接上干货
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers# 定义Transformer模型
def transformer_model(input_shape, num_layers, d_model, num_heads, dff, dropout_rate):inputs layers.Input(shapeinput_shape)# 添加掩码…

工具系列:TimeGPT_(9)模型交叉验证
交叉验证 文章目录 交叉验证外生变量比较不同的模型 时间序列预测中的主要挑战之一是随着时间的推移固有的不确定性和变异性,因此验证所采用的模型的准确性和可靠性至关重要。交叉验证是一种强大的模型验证技术,特别适用于此任务,因为它提供了…

【论文笔记】Attention和Visual Transformer
Attention和Visual Transformer Attention和Transformer为什么需要AttentionAttention机制Multi-head AttentionSelf Multi-head Attention,SMA TransformerVisual Transformer,ViT Attention和Transformer
Attention机制在相当早的时间就已经被提出了&…
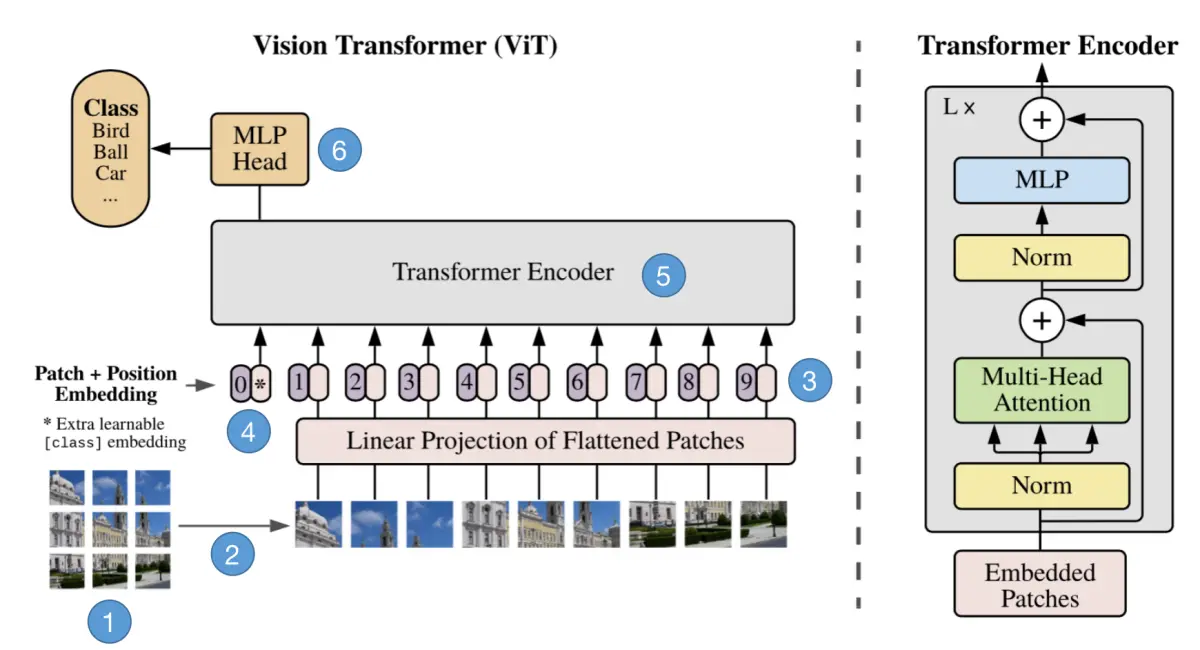
【计算机视觉】Visual Transformer (ViT)模型结构以及原理解析
文章目录 一、简介二、Vision Transformer如何工作三、ViT模型架构四、ViT工作原理解析4.1 步骤1:将图片转换成patches序列4.2 步骤2:将patches铺平4.3 步骤3:添加Position embedding4.4 步骤4:添加class token4.5 步骤5ÿ…
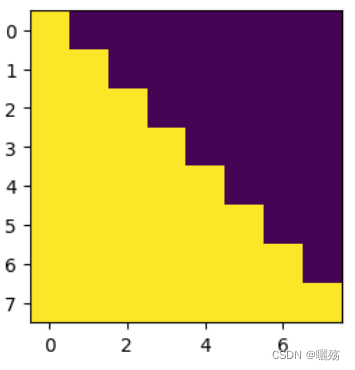
Transformer学习: Transformer小模块学习--位置编码,多头自注意力,掩码矩阵
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 Transformer学习 1 位置编码模块1.1 PE代码1.2 测试PE1.3 原文代码 2 多头自注意力模块2.1 多头自注意力代码2.2 测试多头注意力 3 未来序列掩码矩阵3.1 代码3.2 测试掩码 1 …
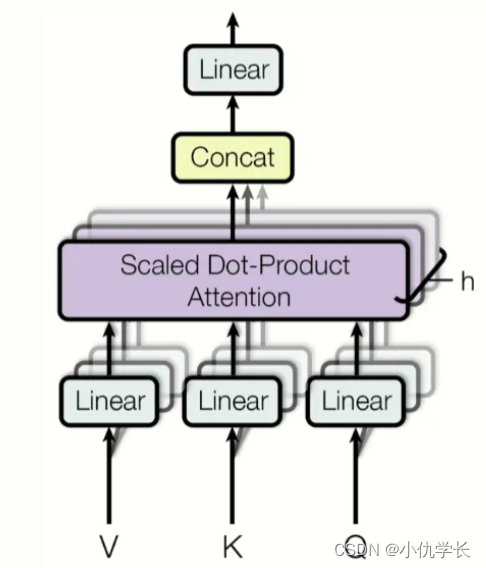
深度学习理论基础(六)Transformer多头注意力机制
目录 一、自定义多头注意力机制1. 缩放点积注意力(Scaled Dot-Product Attention)● 计算公式● 原理 2. 多头注意力机制框图● 具体代码 二、pytorch中的子注意力机制模块 深度学习中的注意力机制(Attention Mechanism)是一种模仿…
【自监督论文阅读笔记】Integrally Pre-Trained Transformer Pyramid Networks (2022)
Abstract 在本文中,我们提出了一个基于掩码图像建模 (MIM) 的整体预训练框架。我们提倡 联合预训练 backbone 和 neck,使 MIM 和下游识别任务之间的迁移差距最小。我们做出了两项技术贡献。首先,我们通过 在预训练阶段 插入特征金字塔 来统一…
论文阅读:Multimodal Graph Transformer for Multimodal Question Answering
文章目录 论文链接摘要1 contribution3 Multimodal Graph Transformer3.1 Background on Transformers3.2 Framework overview 框架概述3.3 Multimodal graph construction多模态图的构建Text graphSemantic graphDense region graph Graph-involved quasi-attention 总结 论文…
Transformer网络原理与实战
Transformer网络原理与实战 1. 什么是Transformer网络2. Transformer网络原理2.1 自注意力机制2.2 多头自注意力机制2.3 Transformer网络的训练 3.Transformer网络实战 1. 什么是Transformer网络
Transformer网络是一种基于自注意力机制的神经网络,由Google于2017年…
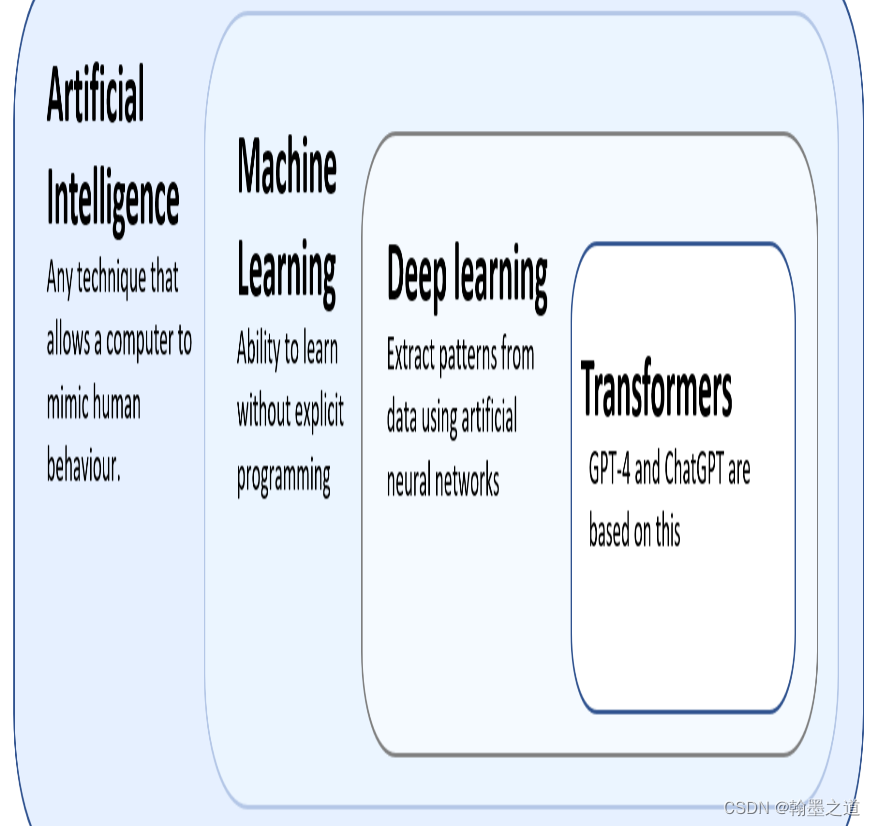
利用GPT开发应用001:GPT基础知识及LLM发展
文章目录 一、惊艳的GPT二、大语言模型LLMs三、自然语言处理NLP四、大语言模型LLM发展 一、惊艳的GPT 想象一下,您可以与计算机的交流速度与与朋友交流一样快。那会是什么样子?您可以创建哪些应用程序?这正是OpenAI正在助力构建的世界&#x…
【论文阅读随笔】RoPE/旋转编码:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
文章目录 1.目的:通过绝对位置编码的方式实现相对位置编码2.理解RoPE,在我看来有几个需要注意的点:3.本文相关复数概念:3.1.复数乘法的几何意义3.2.复数内积 VS. 复数乘法 4.REF: 1.目的:通过绝对位置编码的…

深入探索Transformer时代下的NLP革新
《基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理》主要聚焦于如何使用Python编程语言以及深度学习框架如PyTorch和TensorFlow来构建、训练和调整用于自然语言处理任务的深度神经网络架构,特别是以Transformer为核心模型的架构。
书中详细介绍了Transf…
[论文笔记] Transformer-XL
这篇论文提出的 Transformer-XL 主要是针对 Transformer 在解决 长依赖问题中受到固定长度上下文的限制,如 Bert 采用的 Transformer 最大上下文为 512(其中是因为计算资源的限制,不是因为位置编码,因为使用的是绝对位置编码正余弦编码)。 Transformer-XL 能学习超过固定长…

Transformer中的 Add Norm
Transformer中的 Add & Norm
flyfish
Add
同一个意思 Residual connections,Skip Connections
Norm 包括Post layer normalization和Pre layer normalization Post layer normalization:Transformer 论文中使用的方式,将 Layer norm…

解决方案TypeError: string indices must be integers
文章目录 一、现象:二、解决方案 一、现象:
PyTorch深度学习框架,运行bert-mini,本地环境是torch1.4-gpu,发现报错显示:TypeError: string indices must be integers
后面报字符问题,百度过找…
【论文阅读】swin transformer阅读笔记
在vit以后证明了transformer在视觉任务中的一系列表现
video swin transformer在视频上很好的效果
swin MLP
自监督
掩码自监督
效果很炸裂
swin transformer成了视觉领域一个绕不开的baseline
题目
层级式移动窗口
层级式的特征提取,特征有多尺度的概念
…
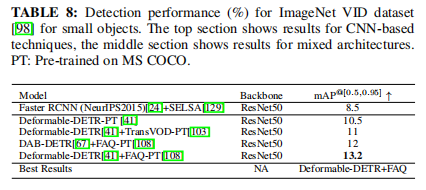
【论文解读】transformer小目标检测综述
目录
一、简要介绍
二、研究背景
三、用于小目标检测的transformer
3.1 Object Representation
3.2 Fast Attention for High-Resolution or Multi-Scale Feature Maps
3.3 Fully Transformer-Based Detectors
3.4 Architecture and Block Modifications
3.6 Improved …
Transformer视频理解学习的笔记
今天复习了Transformer,ViT, 学了SwinTransformer, 还有观看了B站视频理解沐神系列串讲视频上(24.2.26未看完,明天接着看) 这里面更多论文见:https://github.com/mli/paper-reading/
B站视频理解沐神系列串讲视频下(明天接着看&a…
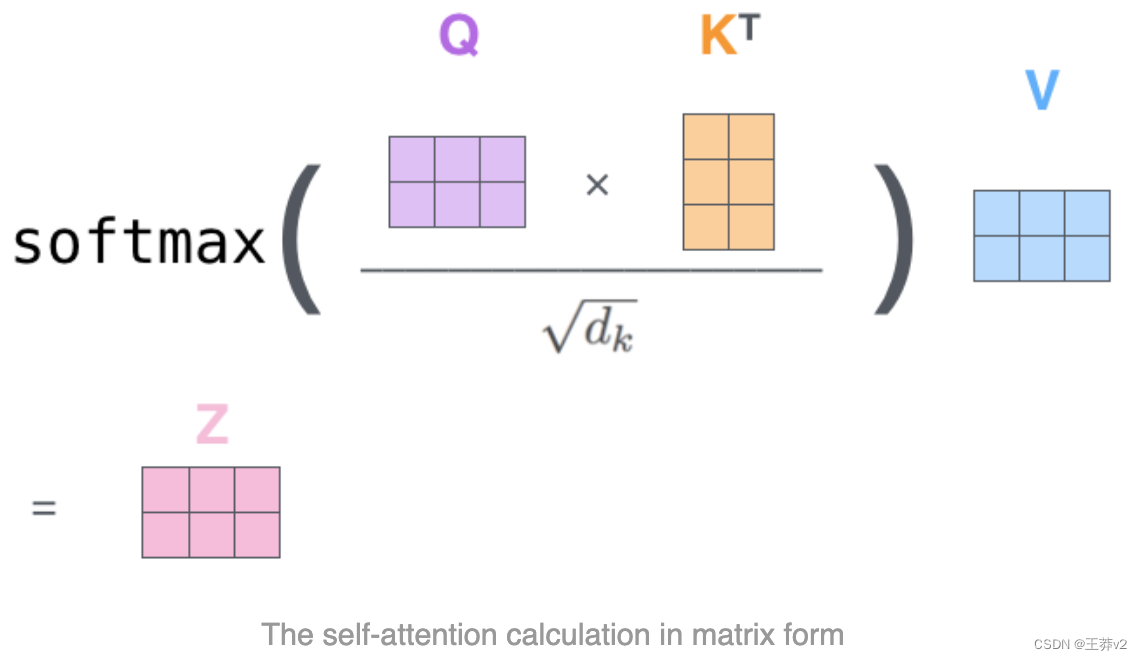
Transformer之self-attention
注意力是一个有助于提高神经机器翻译应用程序性能的概念。在这篇文章中,我们将看看Transformer,一个使用注意力来提高这些模型训练速度的模型。Transformer在特定任务中优于谷歌神经机器翻译模型。最大的好处来自于Transformer如何使自己适合并行化。
在…
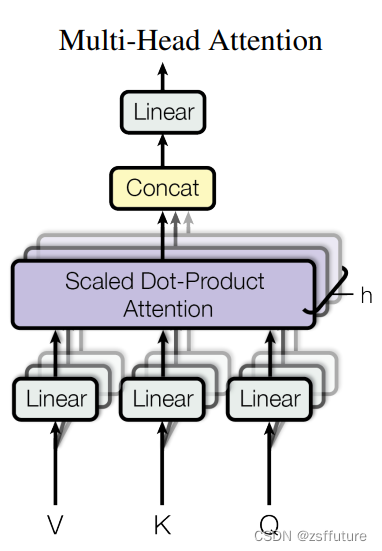
transformer--编码器1(掩码张量、注意力机制、多头注意力机制)
编码器部分:
由N个编码器层堆叠而成每个编码器层由两个子层连接结构组成第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接。第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
掩码张量
什么是掩码张量
掩代表遮掩,码…
新手解锁语言之力:理解 PyTorch 中 Transformer 组件
目录
torch.nn子模块transformer详解
nn.Transformer
Transformer 类描述
Transformer 类的功能和作用
Transformer 类的参数
forward 方法
参数
输出
示例代码
注意事项
nn.TransformerEncoder
TransformerEncoder 类描述
TransformerEncoder 类的功能和作用
Tr…
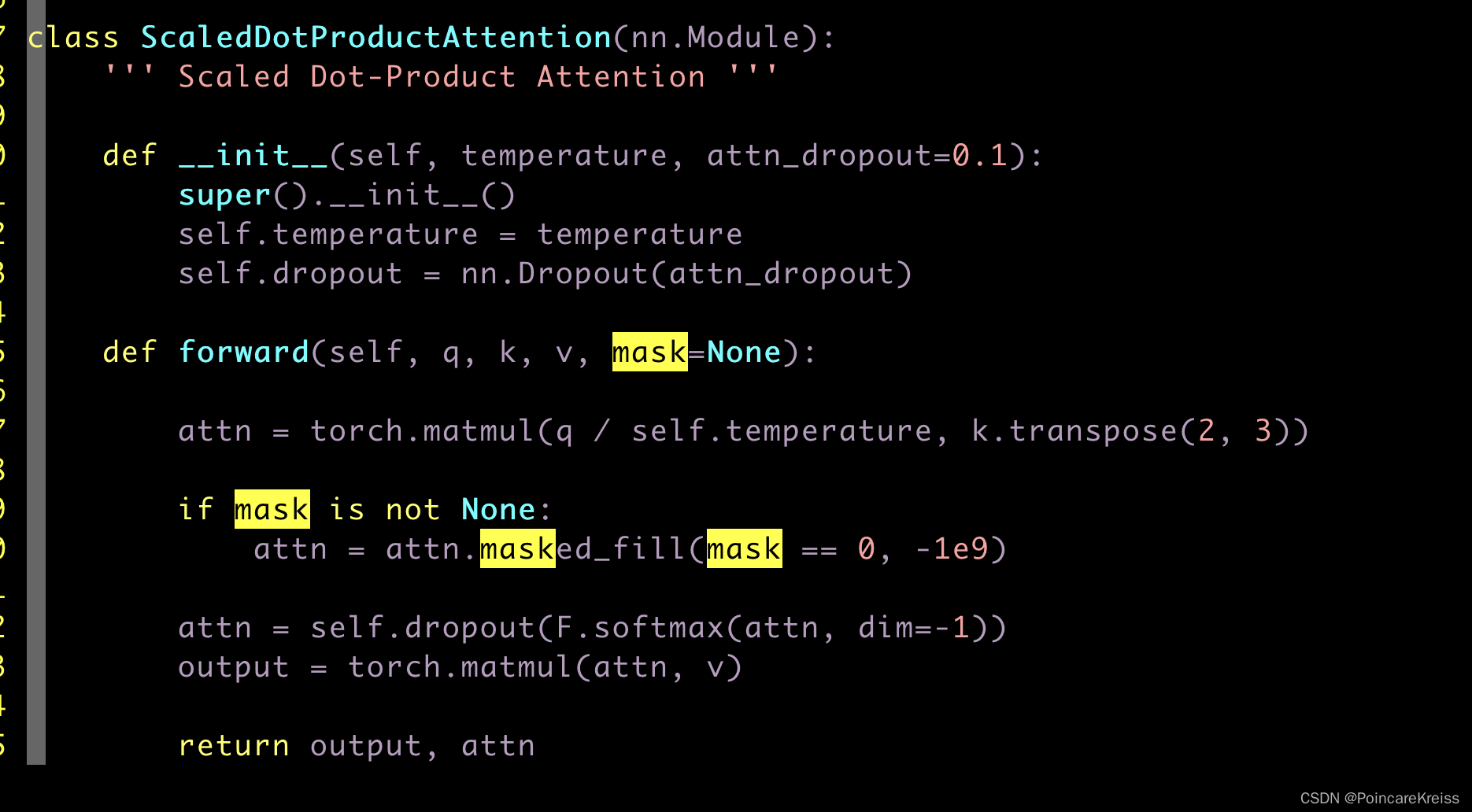
从代码层面理解Transformer
跑通
代码使用的是 https://github.com/jadore801120/attention-is-all-you-need-pytorch,
commit-id 为: 132907d
各模块粗览
Transformer
主要包括一堆参数, 以及encoder和decoder forward的时候主要做了如下操作.
先 pad_mask过encoder过decoder输出logit 从train.py …
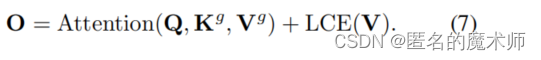
BiFormer 实验记录
代码来自文中地址
目录
一、前向传播过程
1、Path Embedding
2、BiFormer Block
BRA模块
网络结构 一、前向传播过程 1、Path Embedding
见网络结构部分,4倍下采样
2、BiFormer Block 对应
x x self.pos_embed(x) 对应
x x self.drop_path(self.attn(…

Transformer应用之构建聊天机器人(二)
四、模型训练解析
在PyTorch提供的“Chatbot Tutorial”中,关于训练提到了2个小技巧:
使用”teacher forcing”模式,通过设置参数“teacher_forcing_ratio”来决定是否需要使用当前标签词汇来作为decoder的下一个输入,而不是把d…
![深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。](https://img-blog.csdnimg.cn/img_convert/eafad84b81b8503e6075273425866556.png)
深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。
【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等 专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化…
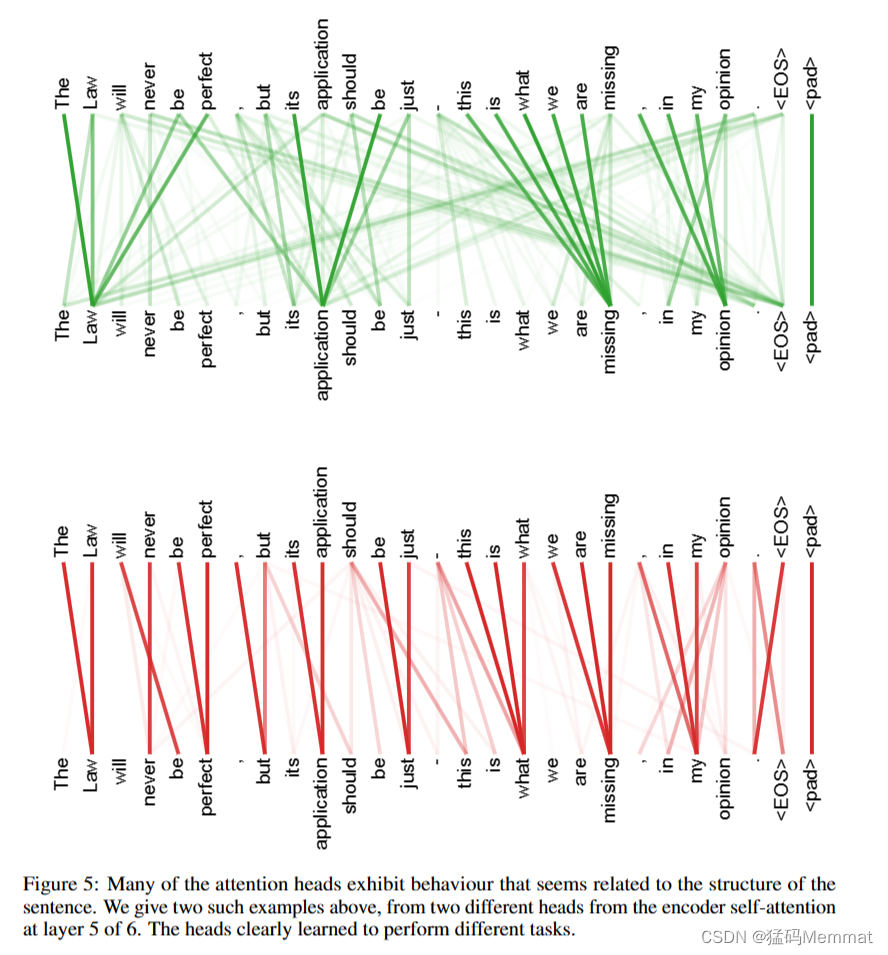
9k字长文理解Transformer: Attention Is All You Need
作者:猛码Memmat 目录 Abstract1 Introduction2 Background3 Model Architecture3.1 Encoder and Decoder Stacks3.2 Attention3.2.1 Scaled Dot-Product Attention3.2.2 Multi-Head Attention3.2.3 Applications of Attention in our Model 3.3 Position-wise Feed…

字节跳动提出高性能 transformer 推理库,获 IPDPS 2023 最佳论文奖
动手点关注 干货不迷路 字节跳动与英伟达, 加州大学河滨分校联合发表的论文 《ByteTransformer: A High-Performance Transformer Boosted for Variable-Length》在第 37 届 IEEE 国际并行和分布式处理大会(IPDPS 2023)中,从 396 篇投稿中脱颖…
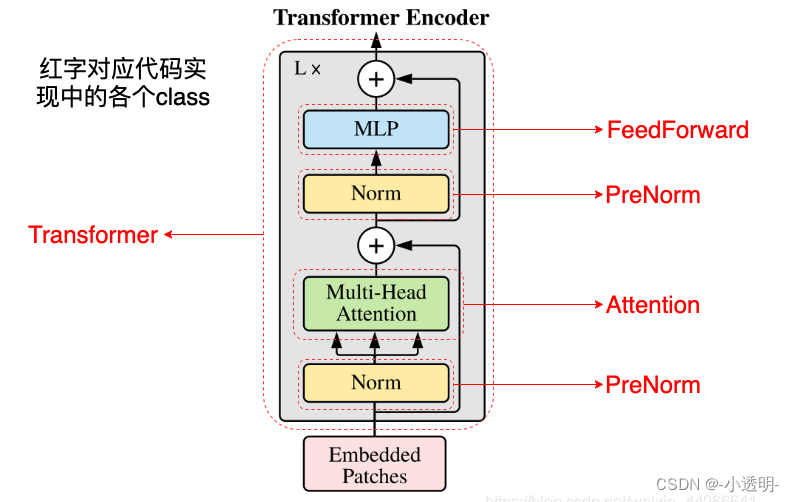
self-attention(transformer)
自注意力机制
在传统的CNN中,都是对感受野内部的事情进行关联后理解。
感受野实际上关乎了模型对全局信息的理解。
而本质上,感受野是一种特殊的注意力机制,也就是说感受野是一种受限的、具有特定参数的注意力。
之前的内容如DANet&#…
【adapter-transformers】:Installation QuickStart(一、安装与快速启动)
【要求】:
adapter-transformers是Huggingface的transformers库的直接替代品。它目前支持Python 3.8和PyTorch 1.12.1。因此必须先安装PyTorch。 一、安装(使用pip)
pip install adapter-transformers
二、快速启动(使用训预练…

ChatGPT底层架构Transformer技术及源码实现(三)
ChatGPT底层架构Transformer技术及源码实现(三)
贝叶斯Bayesian Transformer数学推导论证过程全生命周期详解及底层神经网络物理机制剖析
Gavin大咖微信:NLP_Matrix_Space
从数学的角度来讲,线性转换
其中函数g联合了所有头的操作结果,每个头的产生是采用一个f_att的…
DETR系列:RT-DETR 论文解析
论文:《DETRs Beat YOLOs on Real-time Object Detection》 2023.4
DETRs Beat YOLOs on Real-time Object Detection:https://arxiv.org/pdf/2304.08069.pdf
源码地址:https://github.com/PaddlePaddle/PaddleDetection/tree/develop/conf…
swin-transformer在Jeston Nx部署
源的配置
将原有文件备份一下:
sudo cp /etc/apt/sources.list /etc/apt/sources.list.back将以下阿里源sources.list之后update一下: (备注:不用清华源也可以,之前清华源的更新必须要用到pacman…装pacman弄了很久)…
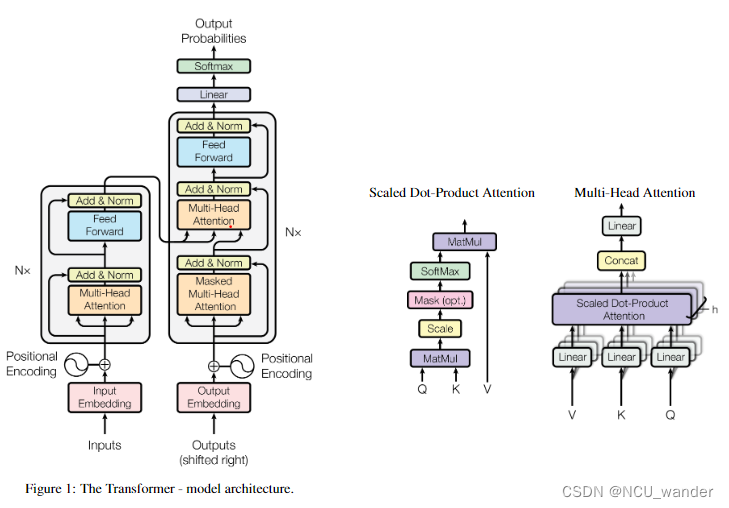
word2vec self-attention transformer diffusion的技术演变
这一段时间大模型的相关进展如火如荼,吸引了很多人的目光;本文从nlp领域入门的角度来总结相关的技术路线演变路线。
1、introduction
自然语言处理(Natural Language Processing),简称NLP。这个领域是通过统计学、数…
Transformer(四)--实现验证:transformer 机器翻译实践
转载请注明出处:https://blog.csdn.net/nocml/article/details/125711025
本系列传送门: Transformer(一)–论文翻译:Attention Is All You Need 中文版 Transformer(二)–论文理解:transformer 结构详解 Transformer(三)–论文实…
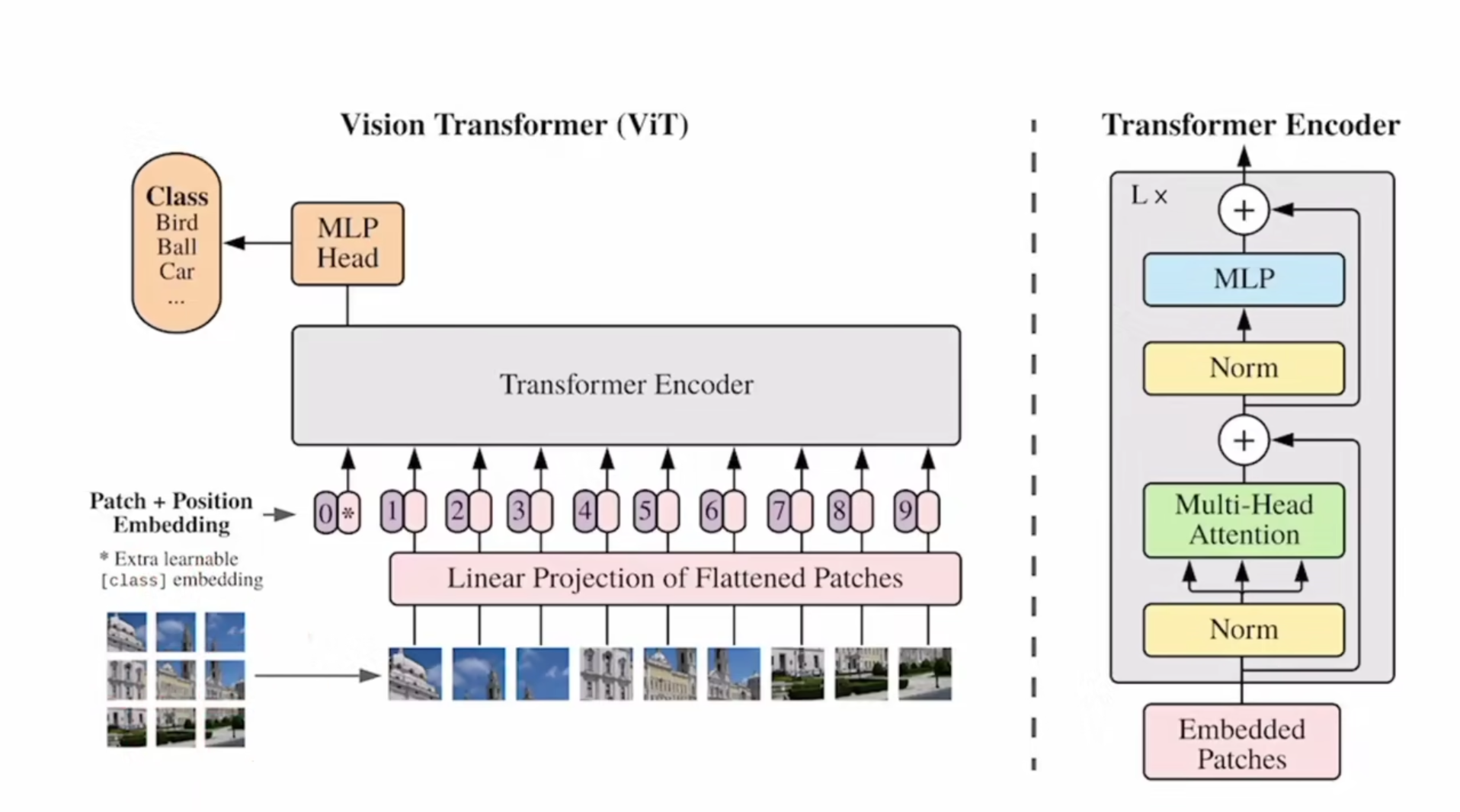
深度学习论文系列--模型细节(持续更新)
AlexNet
图像增强reLu函数Dropout防止过拟合
论文主要思想
更深的卷积神经网络end-to end,端到端的意思就是我只需要把原始的数据(图片、文本等)放进去,不需要做任何的特征提取
ResNet
神经网络深度很深的时候,就…

Hiera:一个没有Bells-and-Whistles的分层视觉转换器
文章目录 Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles摘要本文方法实验结果 Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
摘要
现代层次视觉转换器在追求监督分类性能的过程中增加了一些特定于视觉的组件。虽然…


【论文速递】ACL 2021-CLEVE: 事件抽取的对比预训练
【论文速递】ACL 2021-CLEVE: 事件抽取的对比预训练
【论文原文】:CLEVE: Contrastive Pre-training for Event Extraction
【作者信息】:Wang, Ziqi and Wang, Xiaozhi and Han, Xu and Lin, Yankai and Hou, Lei and Liu, Zhiyuan and Li, Peng and …

Transformer及其子孙后代
三大灵魂模型
Transformer
attention is all you need,现在已经是money is all you need时代了(x
首先介绍自注意力机制 Atention(Q,K,V)softmax(QKTdk)V\operatorname{Atention}(Q,K,V)\operatorname{softmax}(\dfrac{QK^T}{\sqrt{d_k}})VAtenti…
![[自注意力神经网络]Segment Anything(SAM)论文阅读](https://img-blog.csdnimg.cn/81c6d325b3bb4da1985531f67d7cb032.png)
[自注意力神经网络]Segment Anything(SAM)论文阅读
论文地址https://arxiv.org/abs/2304.02643源码地址https://github.com/facebookresearch/segment-anything强烈建议大家试试Demo,效果真的很好:https://segment-anything.com/ 一、概述 本文建立了一个基础图像分割模型,并将其在一个巨大的数…
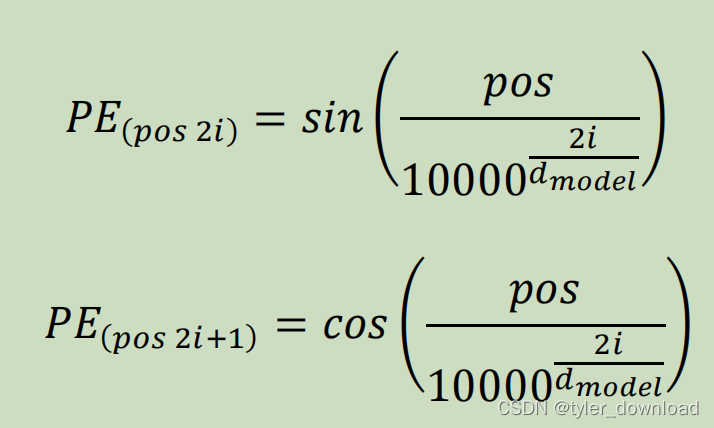
自己动手做chatgpt:解析gpt底层模型transformer的输入处理
前面我们完成了一些基本概念,如果你对深度学习的基本原理还不了解,你可以通过这里获得更多信息,由于深度学习的教程汗牛充栋,因此我在这里不会重复,而是集中精力到chatgpt模型原理的分析,实现和实践上。Cha…
Communications chemisty|德睿智药工作-用于分子性质预测的药物约束异构图Transformer模型
德睿智药的分子性质预测任务
题目: Pharmacophoric-constrained heterogeneous graph transformer model for molecular property prediction
文献来源:COMMUNICATIONS CHEMISTRY | (2023) 6:60 |
代码:https://github.com/stardj/PharmHG…
Hugging Face Transformers Agent
🤗Hugging Face Transformers Agent
就在两天前,🤗Hugging Face 发布了 Transformers Agent——一种利用自然语言从精选工具集合中选择工具并完成各种任务的代理。听着是不是似曾相识? 没错,Hugging Face Transformer…
近期关于Transformer结构有潜力的改进方法总结
目录 0 引言1 Gated Linear Unit (GLU)1.1 思路 2 Gated Attention Unit (GAU)2.1 思路2.2 实验结论2.3 混合注意力 3 FlashAttention3.1 标准Attention的实现3.2 FlashAttention的实现针对目标1针对目标2 4 总结5 参考资料 0 引言
标准Transformer在最新的实际大模型中并没有…

计算机视觉中的Transformer
几十年来,理论物理学家一直在努力提出一个宏大的统一理论。通过统一,指的是将被认为是完全不同的两个或多个想法结合起来,将它们的不同方面证明为同一基础现象。一个例子是在19世纪之前,电和磁被看作是无关的现象,但电…

FLatten Transformer 简化版Transformer
今天在找论文时,看到一篇比较新奇的论文,在这里跟大家分享一下,希望可以给一些人提供一些思路。虽然现在Transformer 比较火,在分割上面也应用的比较多,但是我一直不喜欢用,其中一个原因是结构太复杂了&…
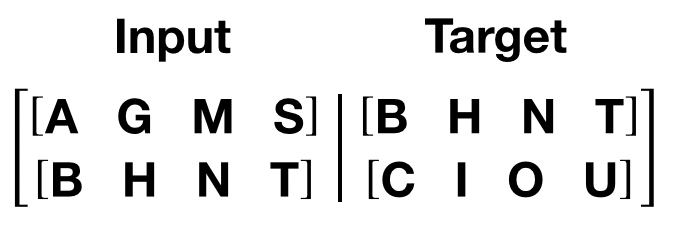
PyTorch翻译官网教程-LANGUAGE MODELING WITH NN.TRANSFORMER AND TORCHTEXT
官网链接
Language Modeling with nn.Transformer and torchtext — PyTorch Tutorials 2.0.1cu117 documentation 使用 NN.TRANSFORMER 和 TORCHTEXT进行语言建模
这是一个关于训练模型使用nn.Transformer来预测序列中的下一个单词的教程。
PyTorch 1.2版本包含了一个基于论…

YOLOv5、YOLOv8改进:MobileViT:轻量通用且适合移动端的视觉Transformer
MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
论文:https://arxiv.org/abs/2110.02178 1简介
MobileviT是一个用于移动设备的轻量级通用可视化Transformer,据作者介绍,这是第一次基于轻量级CNN网络性…
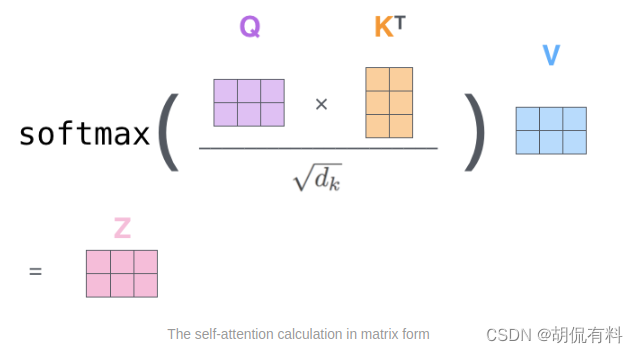
【attention|Tensorformer】从attention走向Transformer
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog
0. 前言
概括 说明: 后续增补
1. 正文
1.0 通俗理解
人类视觉的注意力,简单说就第一眼会注意在一幅图像的重要位置上。 而在程序中&am…
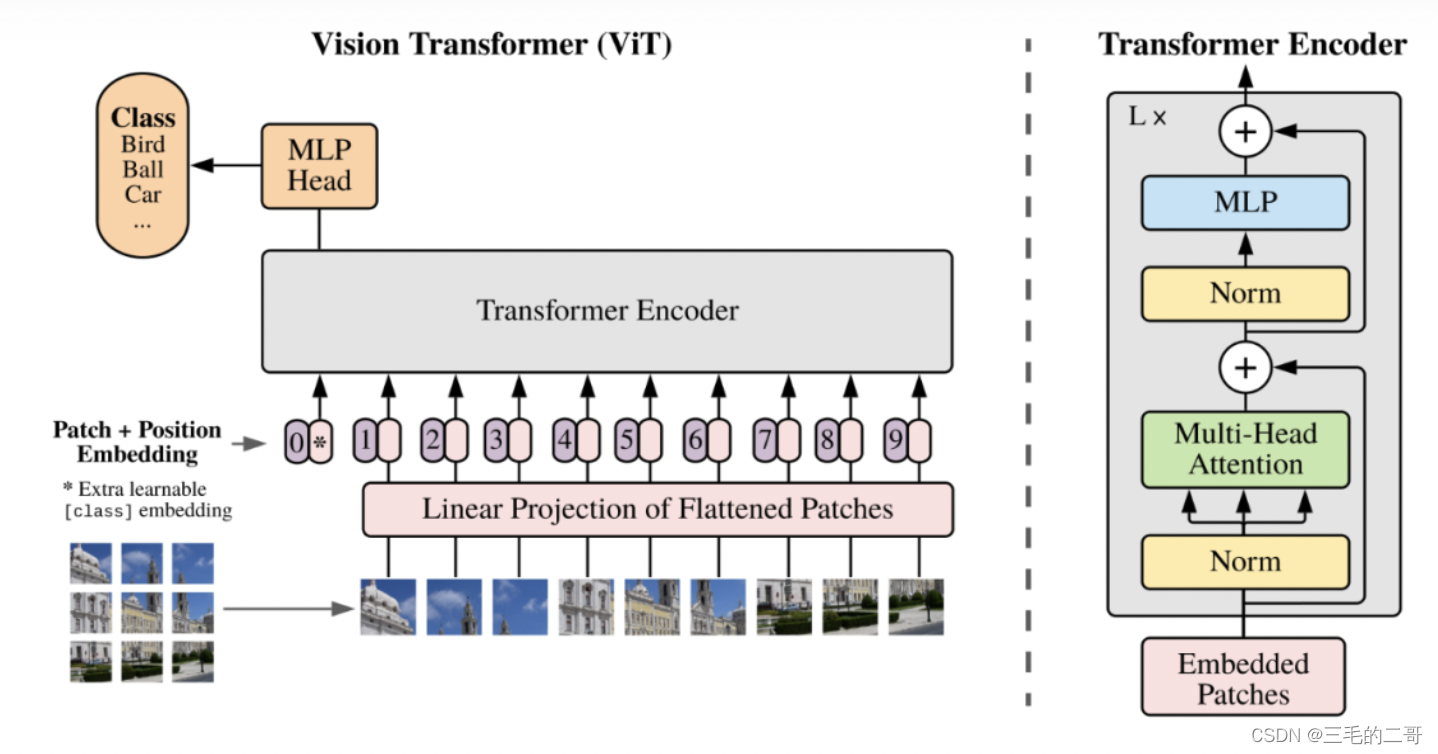
Transformer---ViT:vision transformer
记录一下对transformer方法在计算机视觉任务中的应用方法的理解 参考博客:https://blog.csdn.net/weixin_42392454/article/details/122667271 参考代码:https://gitcode.net/mirrors/Runist/torch_vision_transformer?utm_sourcecsdn_github_accelerator
模型训练流程:
imp…
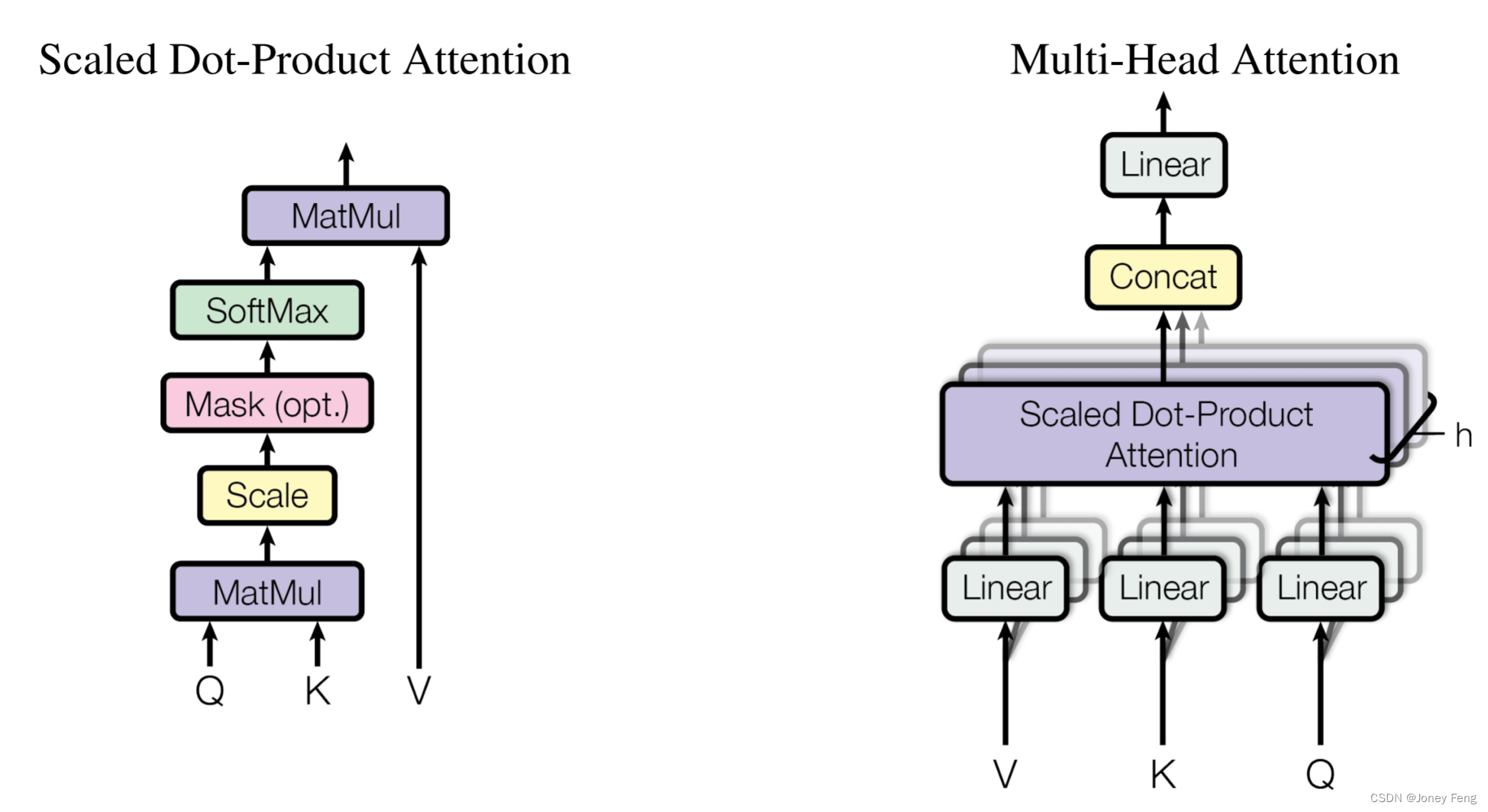
第十三章 Transformer注意力机制
系列文章目录 第一章 AlexNet网络详解
第二章 VGG网络详解
第三章 GoogLeNet网络详解
第四章 ResNet网络详解
第五章 ResNeXt网络详解
第六章 MobileNetv1网络详解
第七章 MobileNetv2网络详解
第八章 MobileNetv3网络详解
第九章 ShuffleNetv1网络详解
第十章…
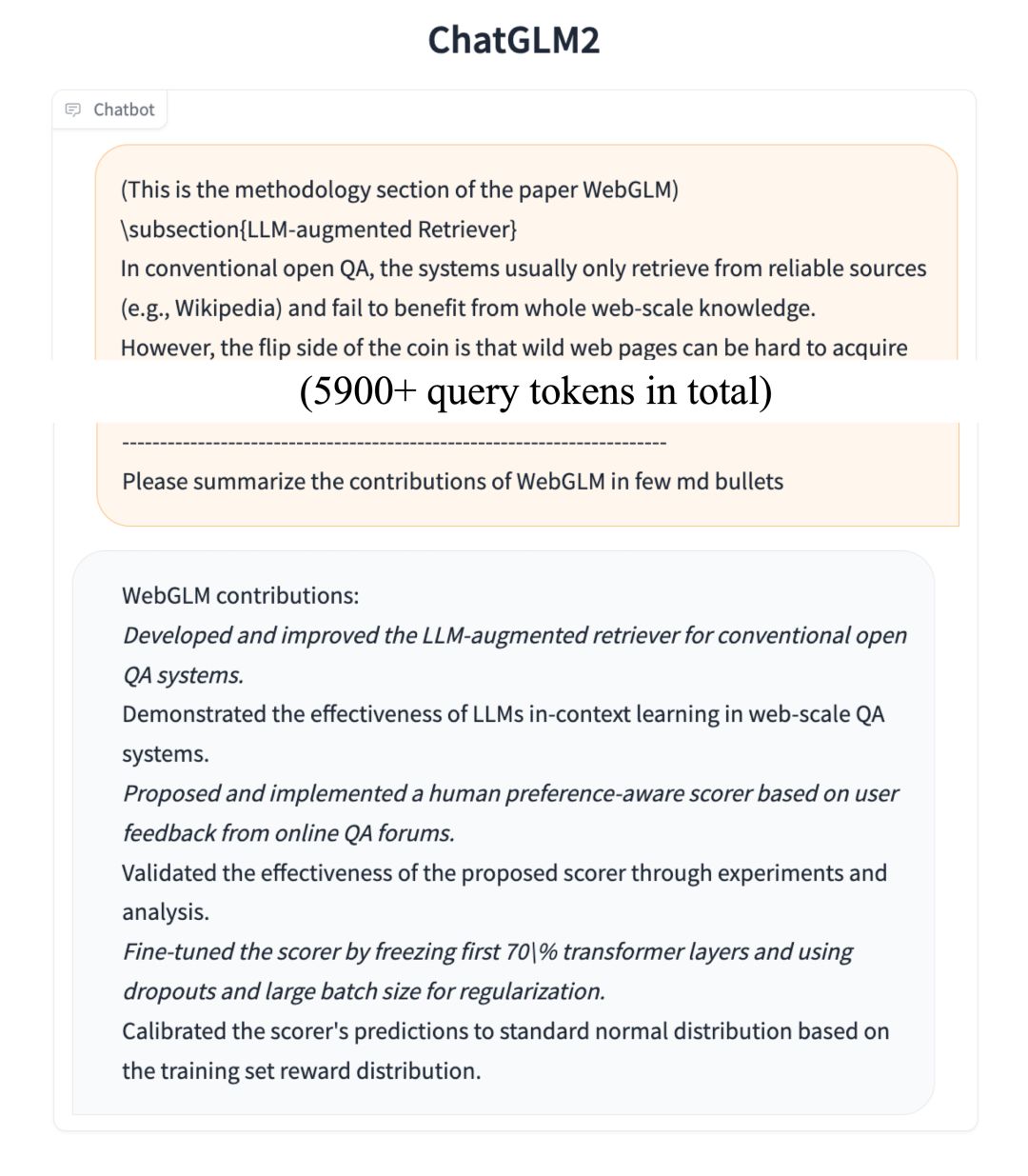
【发布】ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%
自3月14日发布以来, ChatGLM-6B 深受广大开发者喜爱,截至 6 月24日,来自 Huggingface 上的下载量已经超过 300w。 为了更进一步促进大模型开源社区的发展,我们再次升级 ChatGLM-6B,发布 ChatGLM2-6B 。 在主要评估LLM模…
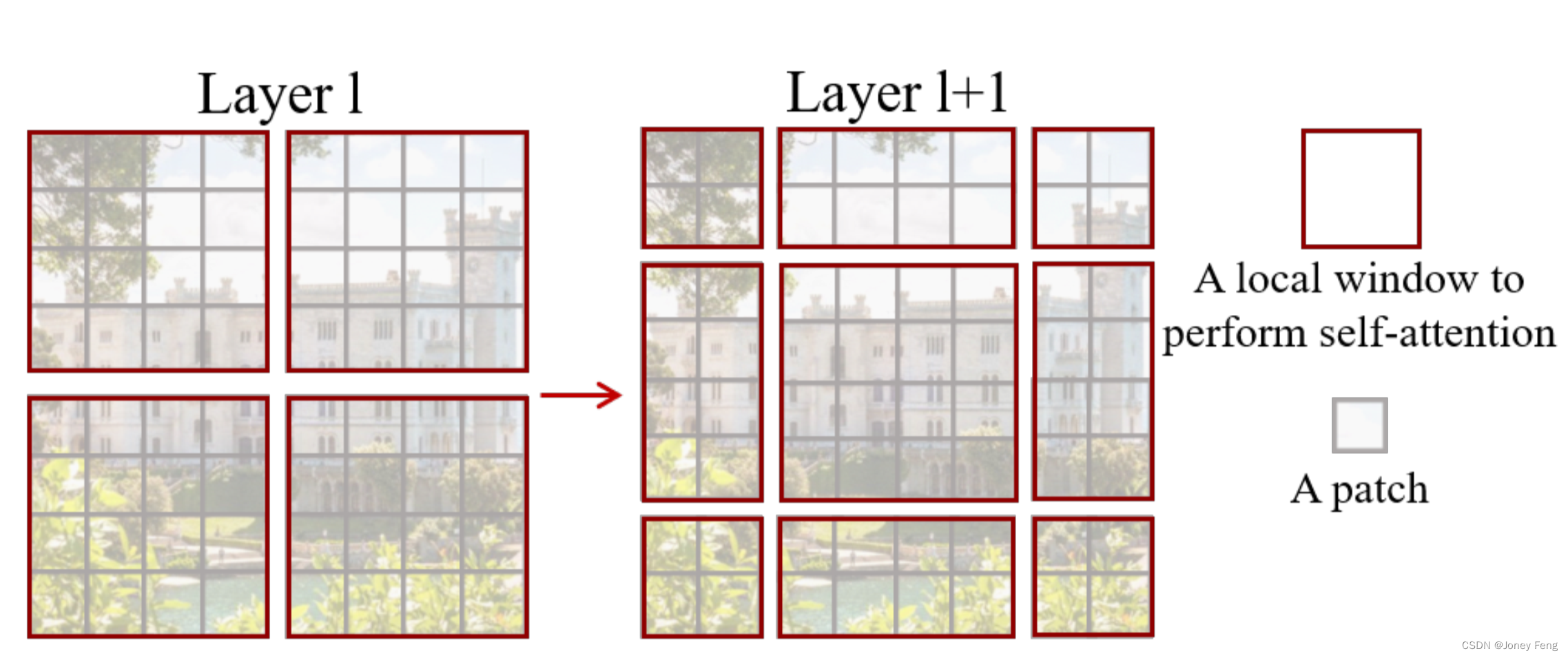
第十五章 Swin-Transformer网络详解
系列文章目录 第一章 AlexNet网络详解
第二章 VGG网络详解
第三章 GoogLeNet网络详解
第四章 ResNet网络详解
第五章 ResNeXt网络详解
第六章 MobileNetv1网络详解
第七章 MobileNetv2网络详解
第八章 MobileNetv3网络详解
第九章 ShuffleNetv1网络详解
第十章…
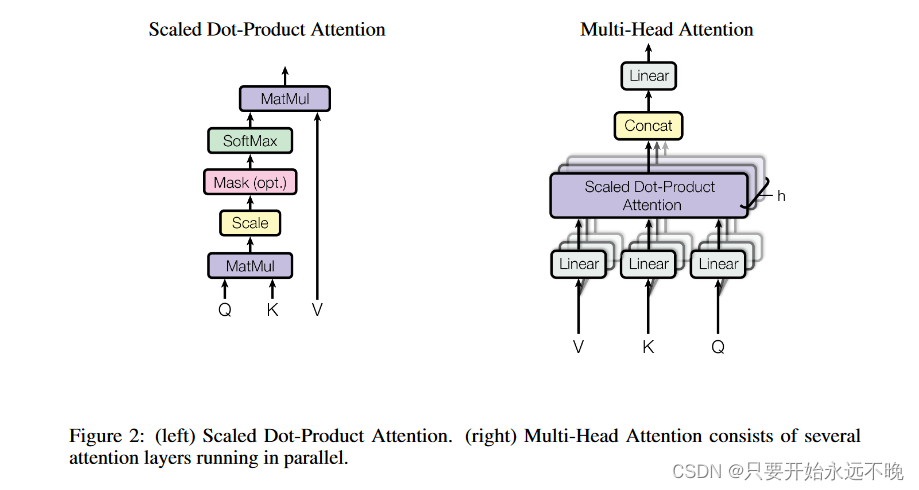
大模型基础之注意力机制和Transformer
【注意力机制】
核心思想:在decoder的每一步,把encoder端所有的向量提供给decoder,这样decoder根据当前自身状态,来自动选择需要使用的向量和信息.
【注意力带来的可解释性】
decoder在每次生成时可以关注到encoder端所有位置的…
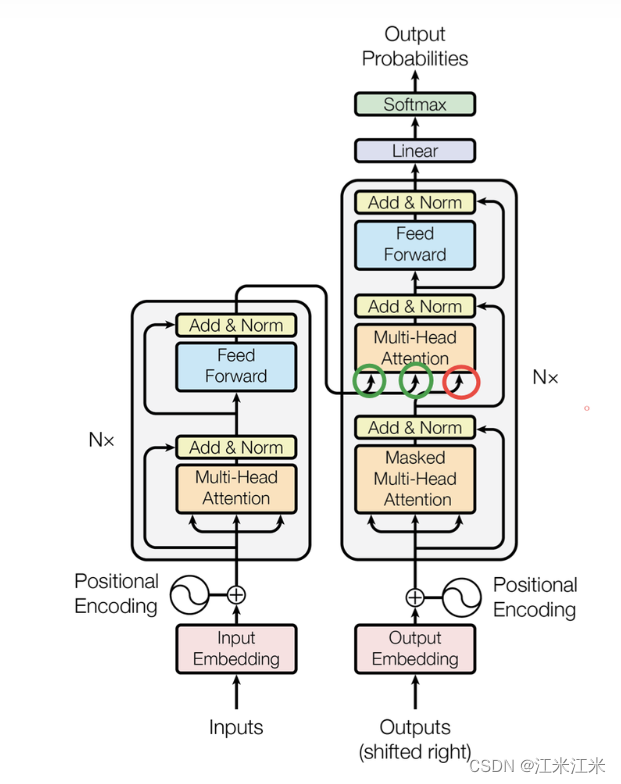
第十一章 原理篇:transformer模型入门
说在前面的话:
找工作面试不是特别顺利。进了目标公司的二面,但是一面面试官问的一些“新技术”问题答得不太好,尤其是transformer相关的。这一点确实是自己的问题,在工作后总是面向业务学习,对很多算法都是处于“听说…

A Mathematical Framework for Transformer Circuits—(二)
A Mathematical Framework for Transformer Circuits Zero-Layer TransformersOne-Layer Attention-Only TransformersThe Path Expansion TrickSplitting Attention Head terms into Query-Key and Output-Value CircuitsOV和QK的独立性(冻结attention模式技巧&…
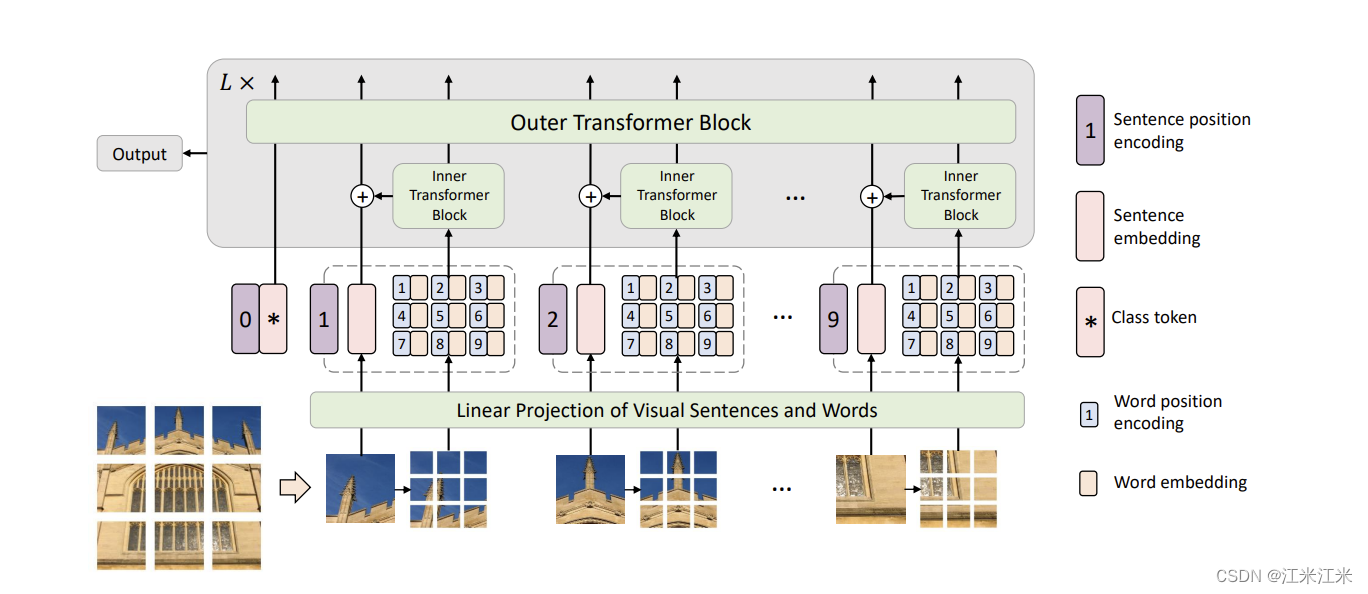
第十二章 原理篇:vision transformer
参考教程: https://arxiv.org/pdf/2010.11929.pdf https://zhuanlan.zhihu.com/p/340149804 【大佬总结的非常好,他的好多篇文章都很值得学习】 文章目录 为什么会使用transformerVIT详解method获得patchpatch embeddingposition embedding 代码实现eino…
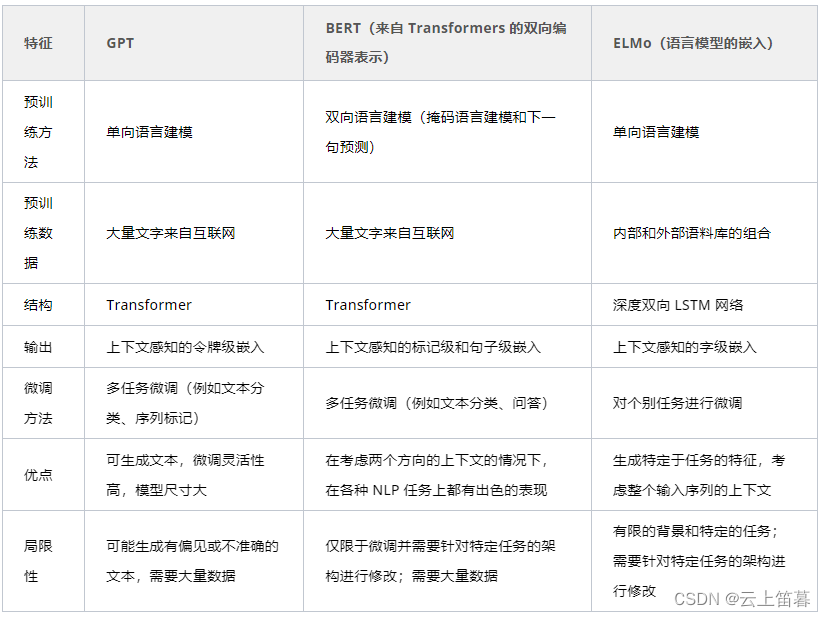
GPT模型训练实践(2)-Transformer模型工作机制
Transformer 的结构如下,主要由编码器-解码器组成,因为其不需要大量标注数据训练和天然支持并行计算的接口,正在全面取代CNN和RNN:
扩展阅读:What Is a Transformer Model? 其中
编码器中包含自注意力层和前馈…

Swin-Transformer-Object-Detection运行环境的搭建
swin transformer的表现就不用多说了,简单记录其目标检测的运行环境搭建过程。 目录创建Pycharm工程github下载源码安装第三方库运行测试代码运行效果问题及参考创建Pycharm工程 现在虚拟环境中只有以下几个包
github下载源码
https://github.com/SwinTransform…

文献阅读:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
文献阅读:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks 1. 内容简介2. 模型结构 1. 数据处理2. 模型结构设计3. 模型训练 3. 实验结果 1. 图文联合任务 1. Visual Question Answering (VQA)2. Visual Reasoning3. Imag…

文献阅读:RoFormer: Enhanced Transformer with Rotary Position Embedding
文献阅读:RoFormer: Enhanced Transformer with Rotary Position Embedding 1. 工作简介2. 常见位置编码方式 1. 绝对位置编码 1. Bert2. Attention Is All You Need 2. 相对位置编码 1. 经典相对位置编码2. XLNet3. T54. DeBerta 3. RoPE方法介绍4. 实验效果考察 …

【Python装饰器】functools.wraps函数保留被装饰函数的元信息
前言
装饰器一般被用于修饰函数,为被修饰的函数增添某些功能,其输入一般为函数,输出为同一个函数,或者另一不同的函数。除注册装饰器外,大多数装饰器会返回与被装饰函数不同的函数对象。另一方面,由于装饰…
Python使用pytorch深度学习框架构造Transformer神经网络模型预测红酒分类例子
1、红酒数据介绍
经典的红酒分类数据集是指UCI机器学习库中的Wine数据集。该数据集包含178个样本,每个样本有13个特征,可以用于分类任务。
具体每个字段的含义如下: alcohol:酒精含量百分比 malic_acid:苹果酸含量&a…

基于transformer的Seq2Seq机器翻译模型训练、预测教程
前言
机器翻译(Machine Translation, MT)是一类将某种语言(源语言,source language)的句子 x x x翻译成另一种语言(目标语言,target language)的句子 y y y 的任务。机器翻译的相关…
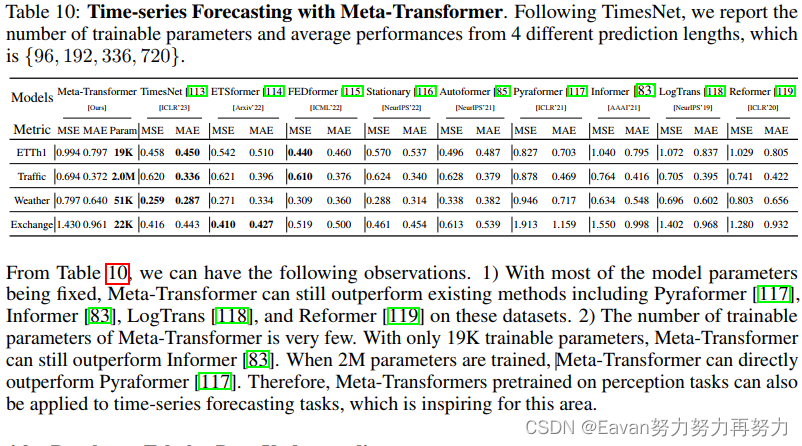
(2023Arxiv)Meta-Transformer: A Unified Framework for Multimodal Learning
论文链接:https://arxiv.org/abs/2307.10802
代码链接:https://github.com/invictus717/MetaTransformer
项目主页:https://kxgong.github.io/meta_transformer/
【注】:根据实验结果来看,每次输入一种数据源进行处…
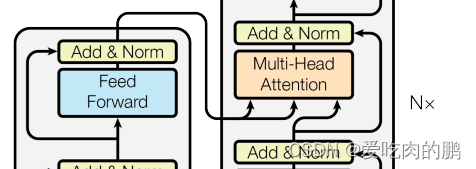
Transformer理论学习
Transformer出自于论文《attention is all you need》。
一些主流的序列模型主要依赖于复杂的循环结构或者CNN,这里面包含了编解码器等。而Transformer主要的结构是基于注意力机制,而且是用多头注意力机制去替换网络中的循环或者CNN(换言之就是transfor…
关于Transformer的理解
关于Transformer, QKV的意义表示其更像是一个可学习的查询系统,或许以前搜索引擎的算法就与此有关或者某个分支的搜索算法与此类似。 Can anyone help me to understand this image? - #2 by J_Johnson - nlp - PyTorch Forums
Embeddings - these ar…
机器学习深度学习——注意力提示、注意力池化(核回归)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——常见循环神经网络结构(RNN、LSTM、GRU) 📚订阅专栏:机器…

【Pytorch:nn.Embedding】简介以及使用方法:用于生成固定数量的具有指定维度的嵌入向量embedding vector
文章目录 1、nn.Embedding2、使用场景 1、nn.Embedding
首先我们讲解一下关于嵌入向量embedding vector的概念 1)在自然语言处理NLP领域,是将单词、短语或其他文本单位映射到一个固定长度的实数向量空间中。嵌入向量具有较低的维度,通常在几…
java_免费文本翻译API_小牛翻译
目录 前言 开始集成API
纯文本翻译接口
双语对照翻译接口
指定术语翻译接口
总结 前言 网络上对百度,有道等的文本翻译API集成的文章比较多,所以集成的第一篇选择了小牛翻译的文本翻译API。 小牛翻译文本翻译API,支持388个语种࿰…
[论文笔记]ON LAYER NORMALIZATION IN THE TRANSFORMER ARCHITECTURE
引言
这是论文ON LAYER NORMALIZATION IN THE TRANSFORMER ARCHITECTURE的阅读笔记。本篇论文提出了通过Pre-LN的方式可以省掉Warm-up环节,并且可以加快Transformer的训练速度。
通常训练Transformer需要一个仔细设计的学习率warm-up(预热)阶段:在训练开始阶段学习率需要设…
GPU安装指南:英伟达A800加速卡常见软件包安装命令
GCC 升级
yum update -y
yum install -y centos-release-scl
yum install -y devtoolset-9source /opt/rh/devtoolset-9/enablegcc -vchmod x NVIDIA-Linux-x86_64-525.105.17.run
sh NVIDIA-Linux-x86_64-525.105.17.run -no-x-checknvidia-smiGPUDirect 通信矩阵:…
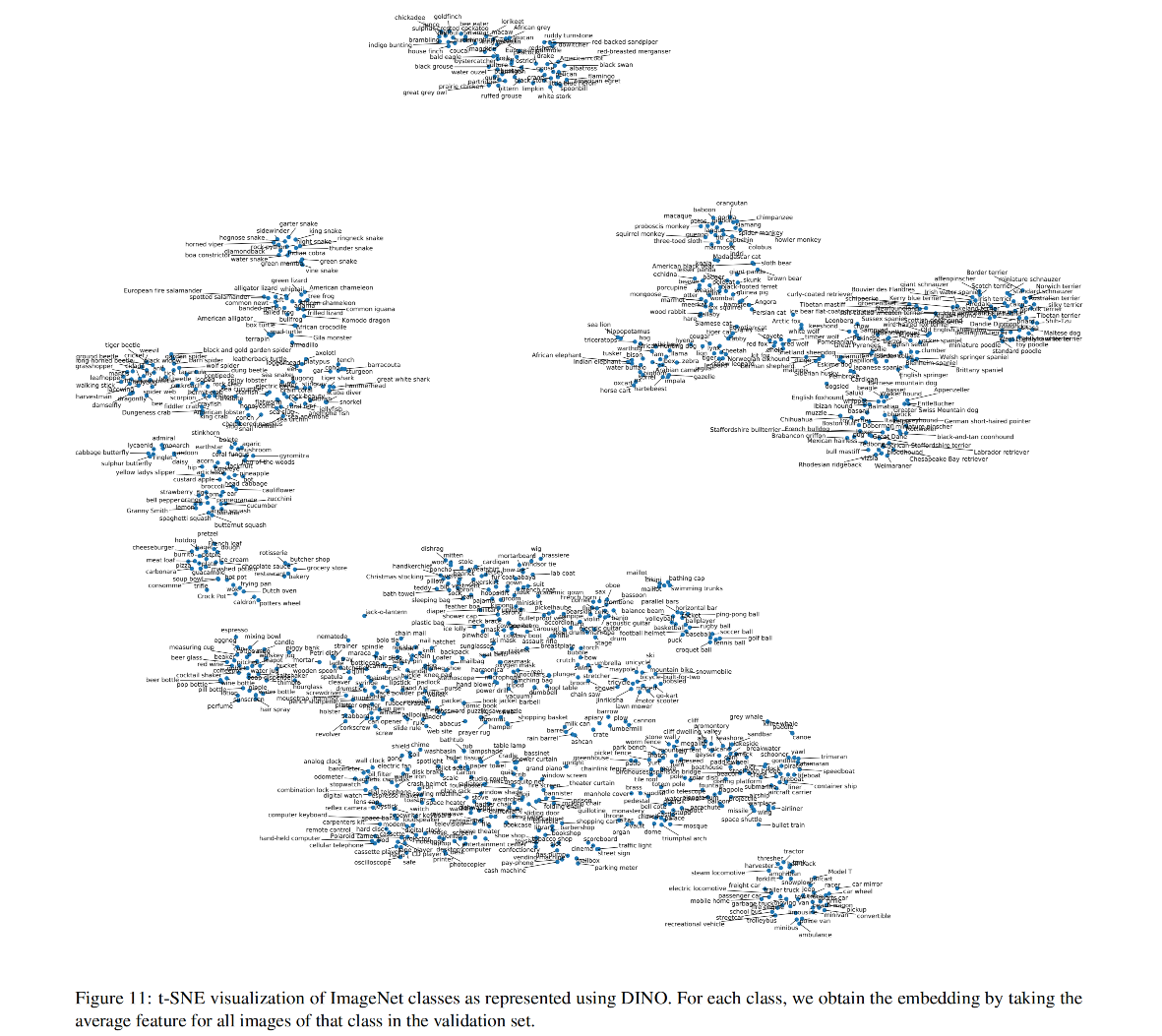
【无监督】5、DINO | 使用自蒸馏和 transformer 来释放自监督学习的超能力(ICCV2021)
文章目录 一、背景二、相关工作三、方法四、效果 论文:Emerging Properties in Self-Supervised Vision Transformers
代码:https://github.com/facebookresearch/dino
出处:ICCV2021 | FAIR
DINO: self-DIstillation with NO …
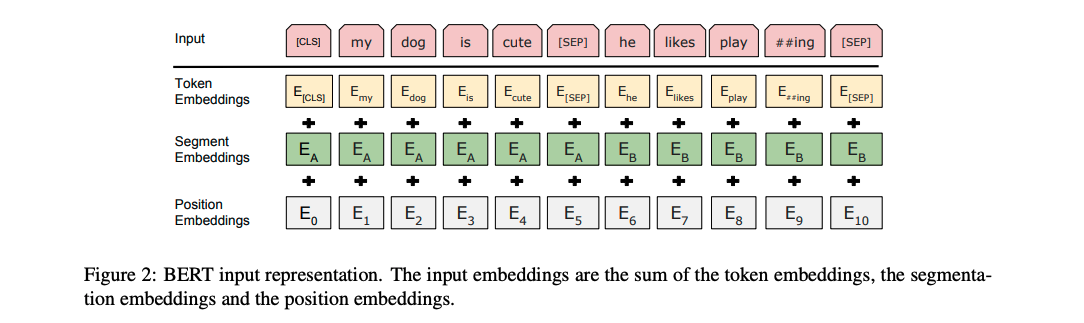
【NLP】1、BERT | 双向 transformer 预训练语言模型
文章目录 一、背景二、方法 论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
出处:Google
一、背景
在 BERT 之前的语言模型如 GPT 都是单向的模型,但 BERT 认为虽然单向(从左到右预测…
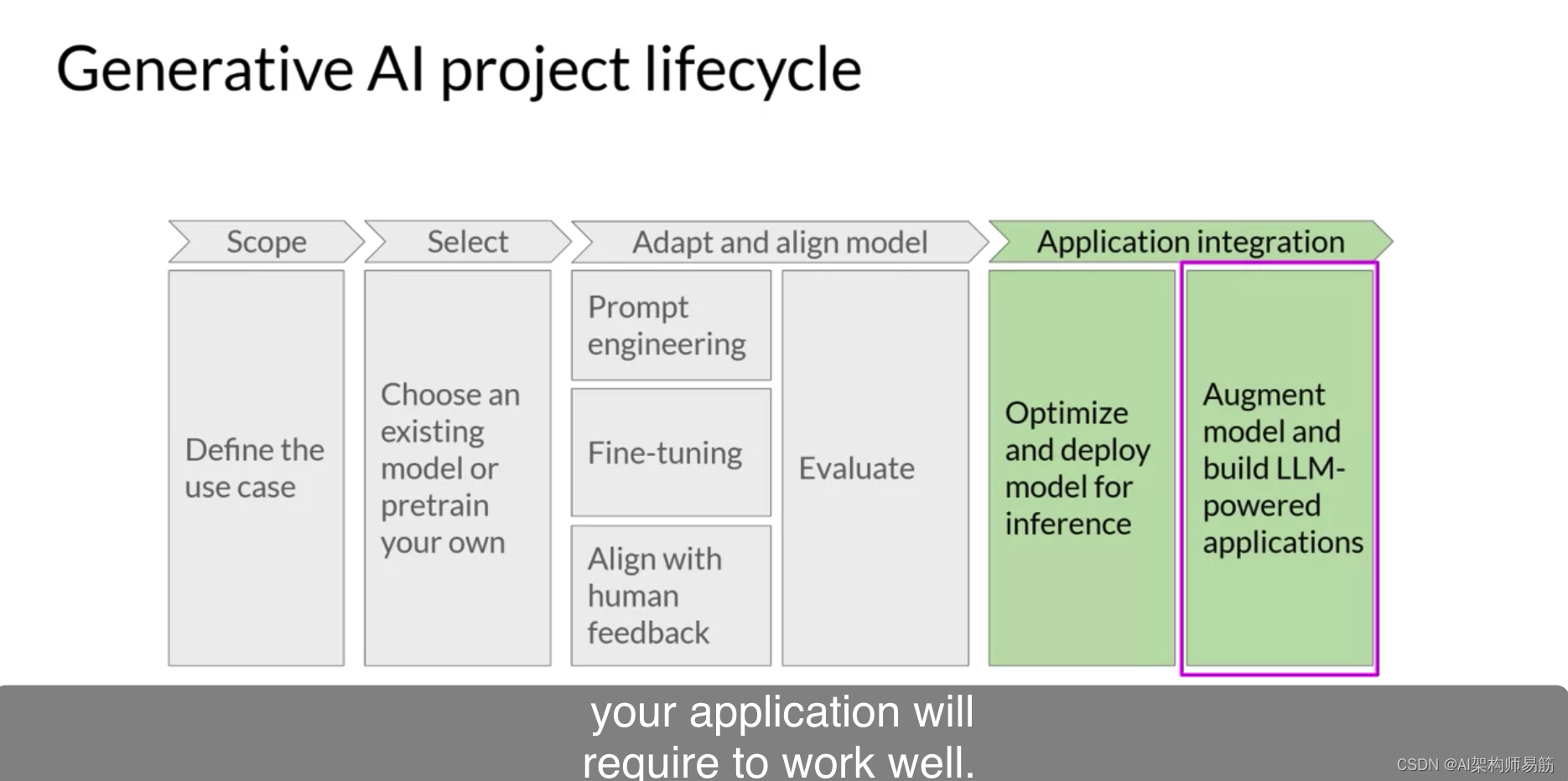
LLM生成式 AI 项目生命周期Generative AI project lifecycle
在本课程的其余部分中,您将学习开发和部署LLM驱动应用所需的技巧。在这个视频中,您将了解一个能帮助您完成此工作的生成式AI项目生命周期。此框架列出了从构思到启动项目所需的任务。到课程结束时,您应该对您需要做的重要决策、可能遇到的困难…

DETR-《End-to-End Object Detection with Transformers》论文精读笔记
DETR(基于Transformer架构的目标检测方法开山之作)
End-to-End Object Detection with Transformers 参考:跟着李沐学AI-DETR 论文精读【论文精读】
摘要
在摘要部分作者,主要说明了如下几点:
DETR是一个端到端&am…
LLMs指令微调 Instruction fine-tuning
上周,您被介绍了生成型AI项目的生命周期。您探索了大型语言模型的示例用例,并讨论了它们能够执行的任务类型。
在本课中,您将了解如何提高现有模型在特定用例下的性能的方法。
您还将了解可用于评估您微调后的LLM性能并量化其相对于您开始…

GDFN模块(restormer)
为了对特征进行变换,常规的前馈神经网络独立地在每个像素位置进行相同的操作。它使用两个1x1卷积层,一个用来扩展特征通道(通常4倍),第二个用来将特征通道减少到原来的输入维度。在隐藏层中加入非线性。
GDFN做了两个…
Hugging Face实战-系列教程3:AutoModelForSequenceClassification文本2分类
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在notebook中进行 本篇文章配套的代码资源已经上传 下篇内容: Hugging Face实战-系列教程4:padding与attention_mask
输出我…
NLP(2)--Transformer
目录
一、Transformer概述
二、输入和输出
三、Encoder
四、Decoder
五、正则化处理
六、对于结构的改进?
七、AT vs NAT
八、Cross-attention 一、Transformer概述 Transformer模型发表于2017年Google团队的Attention is All you need这篇论文,…
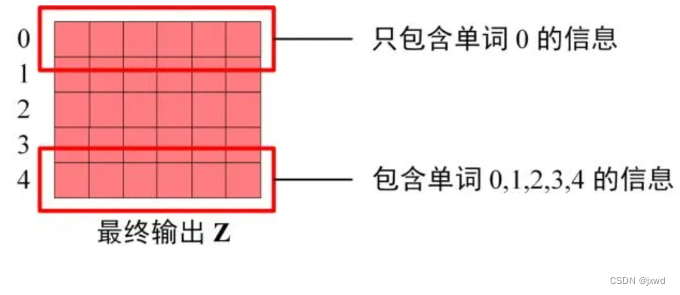
一文讲解Transformer
我们本篇文章来详细讲解Transformer:
首次提出在:Attention is all you need (arxiv.org)
简单来说,Transfomer就是一种Seq2seq结构,它基于多头自注意力机制,解决了传统RNN在计算过程中不能够并行化的问题。即相较于RNN而言&…

180B参数的Falcon登顶Hugging Face,vs chatGPT 最好开源大模型使用体验
文章目录 使用地址使用体验test1:简单喜好类问题test2:知识性问题test3:开放性问题test4:中文支持test5:问题时效性test6:学术问题使用地址
https://huggingface.co/spaces/tiiuae/falcon-180b-demo
使用体验 相比Falcon-7b,Falcon-180b拥有1800亿的参数量
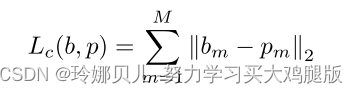
End-to-end 3D Human Pose Estimation with Transformer
基于Transformer的端到端三维人体姿态估计
摘要
基于Transformer的架构已经成为自然语言处理中的常见选择,并且现在正在计算机视觉任务中实现SOTA性能,例如图像分类,对象检测。然而,卷积方法在3D人体姿态估计的许多方法中仍然保…
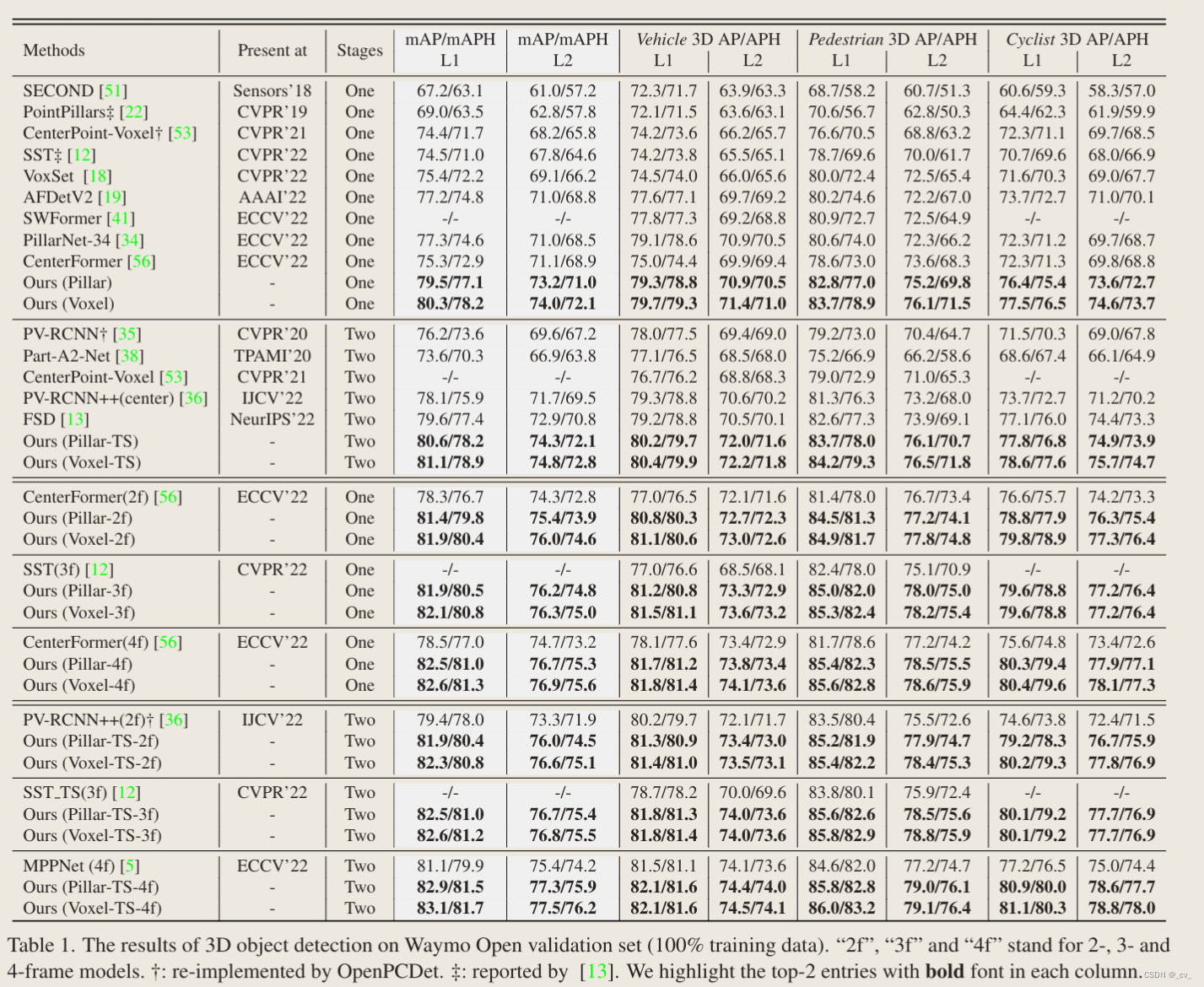
【CVPR 2023】DSVT: Dynamic Sparse Voxel Transformer with Rotated Sets
文章目录 开场白效果意图 重点VoxelNet: End-to-End Learning for Point Cloud Based 3D Object DetectionX-Axis DSVT LayerY-Axis DSVT Layer Dynamic Sparse Window AttentionDynamic set partitionRotated set attention for intra-window feature propagation.Hybrid wind…
transformer系列4---transformer结构计算量统计
transformer计算量 1 术语解释2 矩阵相乘FLOPs3 Transformer的FLOPs估计3.1 MultiHeadAttention3.1.1 Q,K,V计算3.1.2 attention计算3.1.3 MultiHeadAttention输出线性映射3.1.4 MultiHeadAttention总计算量 3.2 MLP3.3 projection输出3.3 计算量累计 1 术语解释 FLOPs…
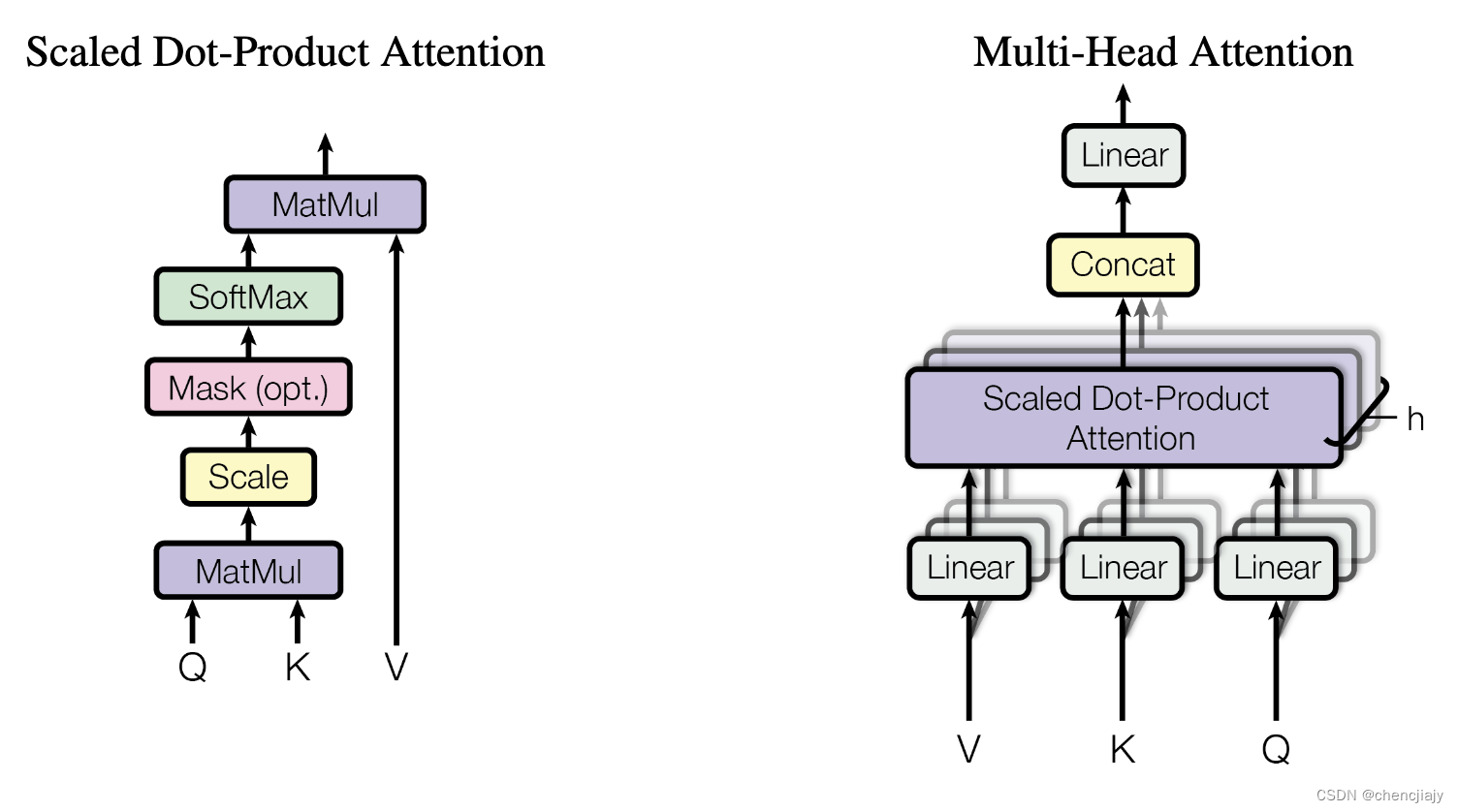
Transformer 相关模型的参数量计算
如何计算Transformer 相关模型的参数量呢? 先回忆一下Transformer模型论文《Attention is all your need》中的两个图。
设Transformer模型的层数为N,每个Transformer层主要由self-attention 和 Feed Forward组成。设self-attention模块的head个数为 …
transformer大语言模型(LLM)部署方案整理
说明
大模型的基本特征就是大,单机单卡部署会很慢,甚至显存不够用。毕竟不是谁都有H100/A100, 能有个3090就不错了。
目前已经有不少框架支持了大模型的分布式部署,可以并行的提高推理速度。不光可以单机多卡,还可以多机多卡。 …
OpenAI开发系列(二):大语言模型发展史及Transformer架构详解
全文共1.8w余字,预计阅读时间约60分钟 | 满满干货,建议收藏! 一、介绍
在2020年秋季,GPT-3因其在社交媒体上病毒式的传播而引发了广泛关注。这款拥有超过1.75亿参数和每秒运行成本达到100万美元的大型语言模型(Large …
双视觉Transformer(Dual Vision Transformer)
摘要
已经提出了几种策略来减轻具有高分辨率输入的自注意机制的计算:比如将图像补丁上的全局自注意过程分解成区域和局部特征提取过程,每个过程都招致较小的计算复杂度。尽管效率良好,这些方法很少探索所有补丁之间的整体交互,因…

【AI视野·今日CV 计算机视觉论文速览 第261期】Thu, 5 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Thu, 5 Oct 2023 Totally 75 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Consistent-1-to-3: Consistent Image to 3D View Synthesis via Geometry-aware Diffusion Models Authors Jianglong Ye, …
attention is all you need 超参数 私自解读
这几个超参数可变,但是也不能变得太多;
语言本身是复杂的,但可以按照多套语法体系来解剖语言现象,所以超参数是有一定可变的范围; 为什么是6层编码器和解码器呢?
人类的语言可以按照六个层次来组织&#…

加速attention计算的工业标准:flash attention 1和2算法的原理及实现
transformers目前大火,但是对于长序列来说,计算很慢,而且很耗费显存。对于transformer中的self attention计算来说,在时间复杂度上,对于每个位置,模型需要计算它与所有其他位置的相关性,这样的计…
[NLP]LLM--transformer模型的参数量
1. 前言
最近,OpenAI推出的ChatGPT展现出了卓越的性能,引发了大规模语言模型(Large Language Model, LLM)的研究热潮。大规模语言模型的“大”体现在两个方面:模型参数规模大,训练数据规模大。以GPT3为例,GPT3的参数量…
Transformer模型 | Python实现基于LSTM与Transfomer的股票预测模型(pytorch)
文章目录 效果一览文章概述LSTM模型原理时间序列模型从RNN到LSTMLSTM预测股票模型实现结语程序设计参考资料效果一览 文章概述
基于LSTM与Transfomer的股票预测模型
股票行情是引导交易市场变化的一大重要因素,若能够掌握股票行情的走势,则对于个人和企业的投资都有巨大的帮…
MDTA模块(Restormer)
From a layer normalized tensor Y ∈ R H ^ W ^ C ^ \mathbf{Y} \in \mathbb{R}^{\hat{H} \times \hat{W} \times \hat{C}} Y∈RH^W^C^, our MDTA first generates query ( Q ) (\mathbf{Q}) (Q), key ( K ) (\mathbf{K}) (K) and value ( V ) (\mathbf{V}) (V) project…
Transformer之傲慢与偏见:主流大语言模型的技术细节揭秘
文章首发地址 目前,主流的大语言模型包括GPT(Generative Pre-trained Transformer)系列、BERT(Bidirectional Encoder Representations from Transformers)、XLNet(eXtreme-Long Transformer)等…

HuggingFace Transformer
NLP简介 HuggingFace简介
hugging face在NLP领域最出名,其提供的模型大多都是基于Transformer的。为了易用性,Hugging Face还为用户提供了以下几个项目:
Transformers(github, 官方文档): Transformers提供了上千个预训练好的模型可以用于不…
Transformer预测 | Pytorch实现基于Transformer的时间序列预测(含单步与多步实验)
文章目录 效果一览文章概述模型描述程序设计单步实验多步实验参考资料效果一览 文章概述 Transformer预测 | Pytorch实现基于Transformer的时间序列预测(含单步与多步实验) Transformer-singlestep.py 包含单步预测模型 Transformer-multistep.py 包含多步预测模型 这是单步预…
重构Transformer神经网络:优化的自注意力机制和前馈神经网络
重构Transformer神经网络:优化的自注意力机制和前馈神经网络 原文代码网络结构推理代码训代码数据处理代码长词表辅助代码原文 标题:重构Transformer神经网络:优化的自注意力机制和前馈神经网络 摘要: 本论文研究了一种改进的Transformer神经网络模型,该模型使用区别于传统…
大模型:如何利用旧的tokenizer训练出一个新的来?
背景:
我们在用chatGPT或者SD的时候,发现如果使用英语写提示词得到的结果比我们使用中文得到的结果要好很多,为什么呢?这其中就有一个叫做tokenizer的东西在作怪。
训练一个合适的tokenizer是训练大模型的基础,我们既…
LATR:3D Lane Detection from Monocular Images with Transformer
参考代码:LATR
动机与主要工作: 之前的3D车道线检测算法使用诸如IPM投影、3D anchor加NMS后处理等操作处理车道线检测,但这些操作或多或少会存在一些负面效应。IPM投影对深度估计和相机内外参数精度有要求,anchor的方式需要一些如…
【AI视野·今日CV 计算机视觉论文速览 第248期】Mon, 18 Sep 2023
AI视野今日CS.CV 计算机视觉论文速览 Mon, 18 Sep 2023 Totally 83 papers 👉上期速览✈更多精彩请移步主页 Interesting:
📚Robust e-NeRF,处理高速且大噪声事件相机流的NERF模型。(from NUS新加坡国立) 稀疏噪声事件与稠密事件数据的区别:…

2022 深度学习 计算机视觉 感知算法 面经整理 八(62 63 64 65 67 68 69 70)
文章目录62 LSTM和GRU有何不同63 CRF 的损失函数是什么,具体怎么算?64 Transformer原理介绍65 BERT介绍下原理66 sigmoid缺点67 Layer Normalization 和 Batch Normalization 的区别68 怎么处理数据不平衡69 什么是梯度消失和梯度爆炸?70 决策…
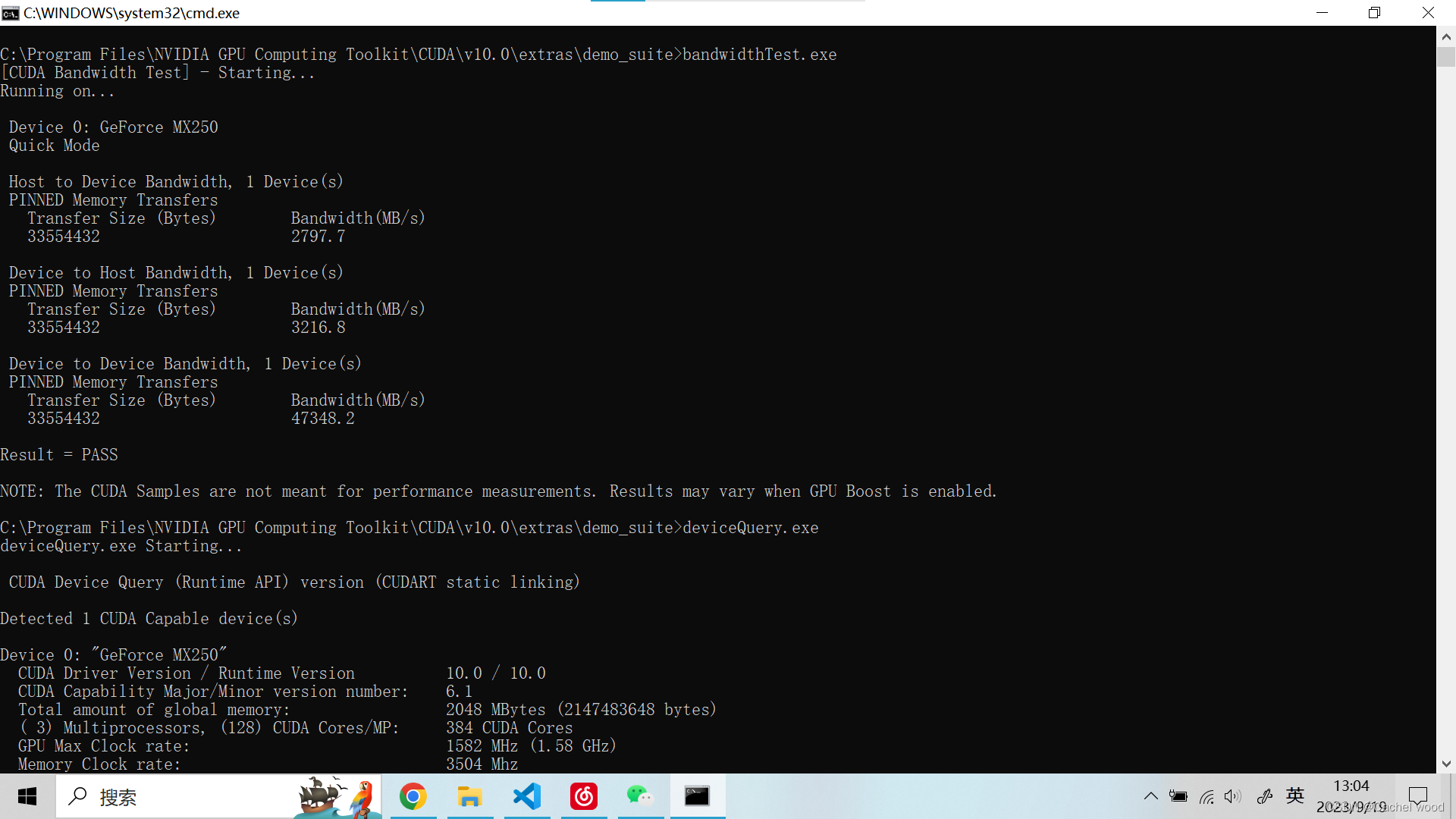
Windows安装cuda和cudnn教程最新版(2023年9月)
文章目录 cudacudnn cuda 查看电脑的cuda最高驱动版本(适用于N卡电脑-Nvidia) winR打开命令行,输入nvidia-smi 右上角cuda -version就是目前支持的最高cuda版本 nvidia官网下载cuda 下载地址:https://developer.nvidia.com/cuda…
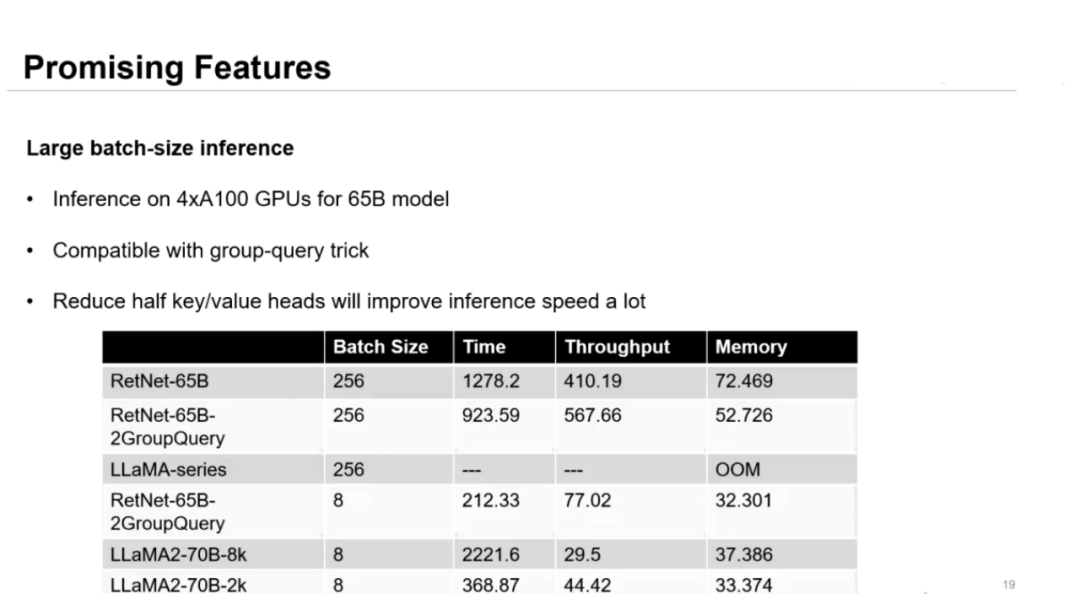
RetNet或成Transformer继承者?通向更快、更强、更经济的基础架构
导读 在计算机科学的发展史上,硬件算力、算法程序与计算数据总是螺旋上升。在硬件相同的条件下,算法的效率和优化程度决定了其利用硬件资源的能力,从而直接影响计算机的算力。因此,为了提升计算机系统带来的综合效益,计…
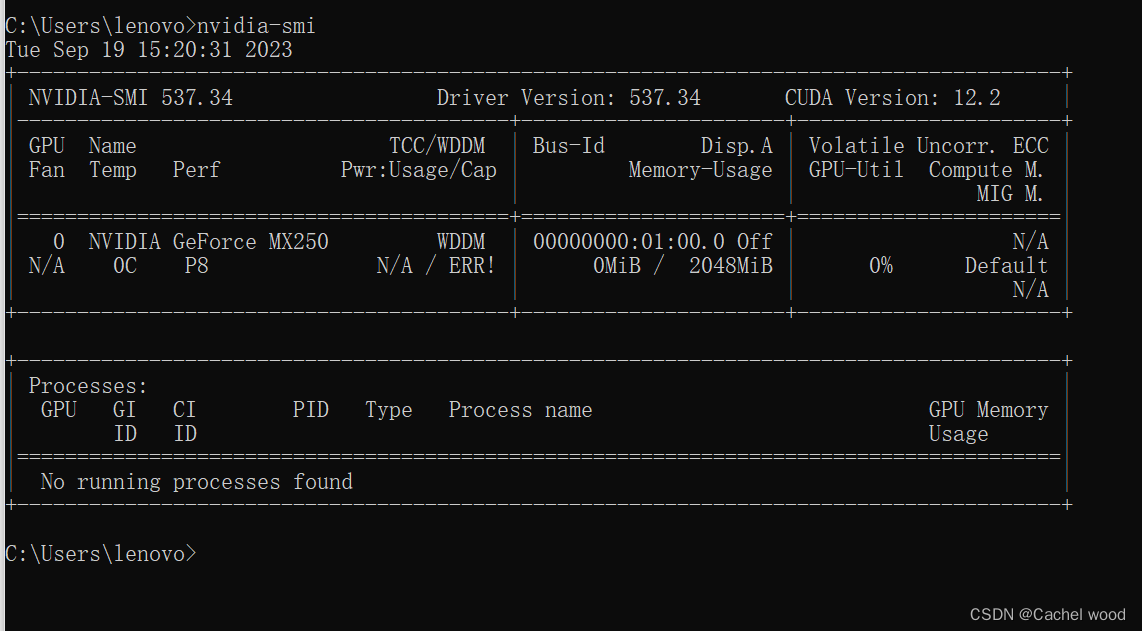
windows英伟达nvidia显卡驱动安装教程
文章目录 查看版本驱动下载驱动安装查看安装结果 查看版本
之前我的电脑预安装了nvidia的显卡驱动,通过nvidia-smi命令发现驱动版本是Driver Version:417.98,CUDA Version:10.0,目前的驱动和CUDA支持的已经是4年前的版…

MobileViT论文记录
论文原文:https://arxiv.org/abs/2110.02178
源码地址(pytorch实现):https://github.com/apple/ml-cvnets
前言
MobileVit是由CNN和Transformer混合架构组成的,它利用了CNN的空间归纳偏置[1]和加速网络收敛的优势&a…
Transformer代码计算过程全解
条件设置
batch_size1
src_len 8 # 源句子的最大长度 根据这个进行padding的填充
tgt_len 7 # 目标输入句子的最大长度 根据这个进行padding的填充
d_model512 # embedding的维度
d_ff2048 # 全连接层的维度
h_head8 # Multi-Head Attention 的…

Transformer 模型详解
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息…

LLM:Transformers模型推理和加速
Pipeline
pipeline() 的作用是使用预训练模型进行推断。
不同类型的任务所下载的默认预训练模型可以在 Transformers 库的源码
[transformers/__init__.py at main huggingface/transformers GitHub]中的 SUPPORTED_TASKS 定义。
参数Parameters
Batch size
推理时没必…

Transformer原理解析及机器翻译的应用
基于Seq2Seq模型的机器翻译
引入Attention的Seq2Seq模型-机器翻译
Transformer
首先,可以思考为什么会需要Transformer? 大部分的机器翻译等序列生成任务都是基于Encoder-Decoder的模式,而Encoder和Decoder一般是由RNN、LSTM、GRU其中一种…
【霹雳吧啦Wz】Transformer中Self-Attention以及Multi-Head Attention详解
文章目录 来源Transformer起源Self-Attention1. 求q、k、v2. 计算 a ^ ( s o f t m a x 那块 ) \hat{a} (softmax那块) a^(softmax那块)3. 乘V,计算结果 Multi-Head Attention位置编码 来源
b站视频 前天啥也不懂的时候点开来一看,各种模型和公式&#…

A Mathematical Framework for Transformer Circuits—Part (1)
A Mathematical Framework for Transformer Circuits 前言Summary of ResultsREVERSE ENGINEERING RESULTSCONCEPTUAL TAKE-AWAYS Transformer OverviewModel SimplificationsHigh-Level ArchitectureVirtual Weights and the Residual Stream as a Communication ChannelVIRTU…
论文精读Transformer: Attention is all you need
1 基础背景2 Motivation3 解决思路3.1 Encoder3.2 Decoder 4 复杂度分析5 结果6 知识补充7 评价 1 基础背景
由Google机器翻译Google Brain团队发表。 论文链接:https://arxiv.org/abs/1706.03762 源码链接:https://github.com/tensorflow/tensor2tenso…

DeepMind: 用ReLU取代Softmax可以让Transformer更快
注意力是人类认知功能的重要组成部分,当面对海量的信息时,人类可以在关注一些信息的同时,忽略另一些信息。当计算机使用神经网络来处理大量的输入信息时,也可以借鉴人脑的注意力机制,只选择一些关键的信息输入进行处理…
self-attention、transformer、bert理解
参考李宏毅老师的视频 https://www.bilibili.com/video/BV1LP411b7zS?p2&spm_id_frompageDriver&vd_sourcec67a2725ac3ca01c38eb3916d221e708 一个输入,一个输出,未考虑输入之间的关系!!!
self-attention…
YOLOv7改进:CBAM注意力机制
目录
1.介绍
1.1、论文的出发点
1.2、论文的主要工作
1.3、CBAM模块的具体介绍
2.YOLOv7改进
2.1yaml 配置文件如下
2.2common.py配置
2.3yolo.py配置 1.介绍
1.1、论文的出发点
cnn基于其丰富的表征能力,极大地推动了视觉任务的完成,为了提高…
AI项目十:Swin Transformer目标检测环境搭建
若该文为原创文章,转载请注明原文出处。
Swin Transformer是做什么的这里不做介绍,主要是记录下学习的全过程,Swin Transformer在搭建和训练的过程中,折腾了很久,主要是在折腾环境。
一、AutoDL租用实例
个人没有GP…

【huggingface】数据集及模型下载并保存至本地
目录 数据集ChnSentiCorppeoples_daily_ner 模型bert-base-chinesehfl/rbt3t5-baseopus-mt-zh-enChinese_Chat_T5_Base 环境:没有代理,无法访问部分国外网络 数据集 正常情况下通过load_dataset加载数据集;save_to_disk保存至本地;…

【代码实现】DETR原文解读及代码实现细节
1 模型总览 宏观上来说,DETR主要包含三部分:以卷积神经网络为主的骨干网(CNN Backbone)、以TRM(Transformer)为主的特征抽取及交互器以及以FFN为主的分类和回归头,如DETR中build()函数所示。DETR最出彩的地方在于&…
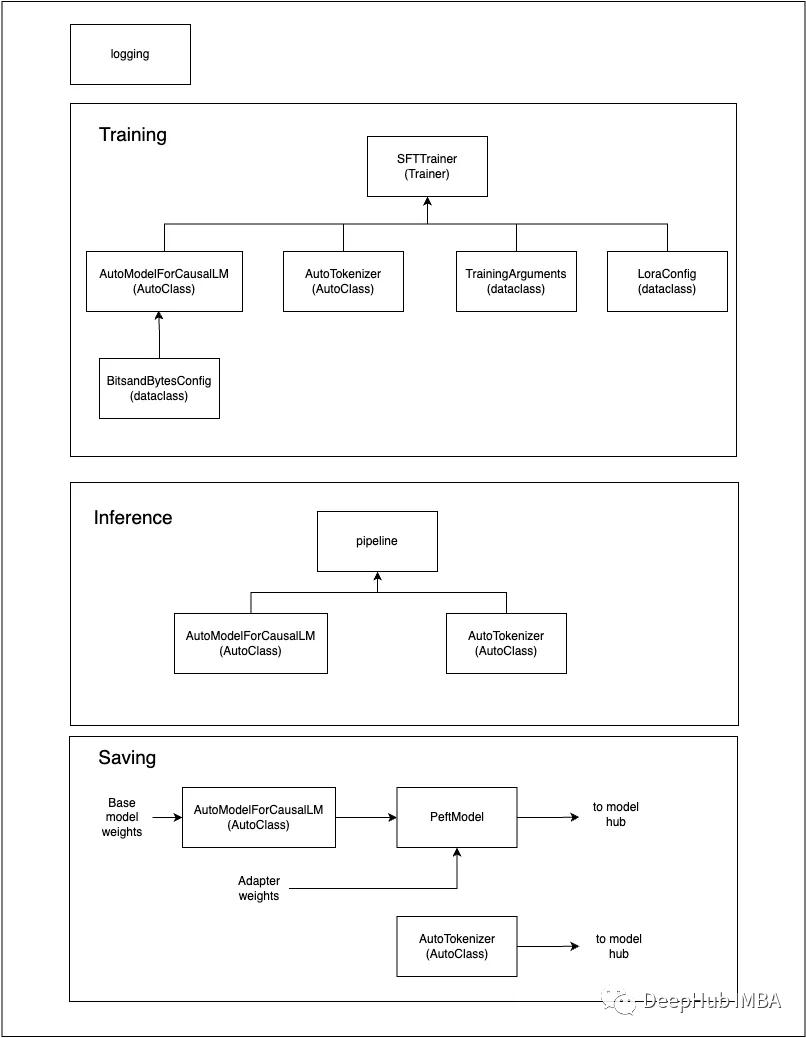
使用QLoRA对Llama 2进行微调的详细笔记
使用QLoRA对Llama 2进行微调是我们常用的一个方法,但是在微调时会遇到各种各样的问题,所以在本文中,将尝试以详细注释的方式给出一些常见问题的答案。这些问题是特定于代码的,大多数注释都是针对所涉及的开源库以及所使用的方法和…
VIT(Vision Transformer)学习-模型理解(一)
VIT (Vision Transformer) 模型论文代码(源码)从零详细解读,看不懂来打我_哔哩哔哩_bilibili
VIT模型架构图 1.图片切分为patch
2. patch转化为embedding
1)将patch展平为一维长度
2)token embedding:将拉平之后的序列映射…
【文档智能】再谈基于Transformer架构的文档智能理解方法论和相关数据集
前言
文档的智能解析与理解成为为知识管理的关键环节。特别是在处理扫描文档时,如何有效地理解和提取表单信息,成为了一个具有挑战性的问题。扫描文档的复杂性,包括其结构的多样性、非文本元素的融合以及手写与印刷内容的混合,都…

Transformer基础知识扫盲(八股知识get
Transformer基础知识扫盲 梯度消失或梯度爆炸原理/原因解决办法 Batch Normalization vs Layer Normalization原理为什么可以解决梯度问题 残差网络/连接RNN -> Attention缺点 Encoder and DecoderAttention原理 & QKV含义attention vs self-attentionmulti-head attent…

基于Python实现电商订单的数据分析
基于Python实现电商订单的数据分析 数据集:技术:功能:创新点:明确需求和目的: 数据集:
项目使用一家全球超市4年内的电商销售订单数据,数据集名为superstore_dataset2011-2015.csv。数据集共有…

机器学习--Transformer 1
Transformer 是一个基于自注意力的序列到序列模型,与基于循环神经网络的序列到序列模型不同,其可以能够并行计算。
一、序列到序列模型
序列到序列模型输入和输出都是一个序列,输入与输出序列长度之间的关系有两种情况。第一种情况下&#…
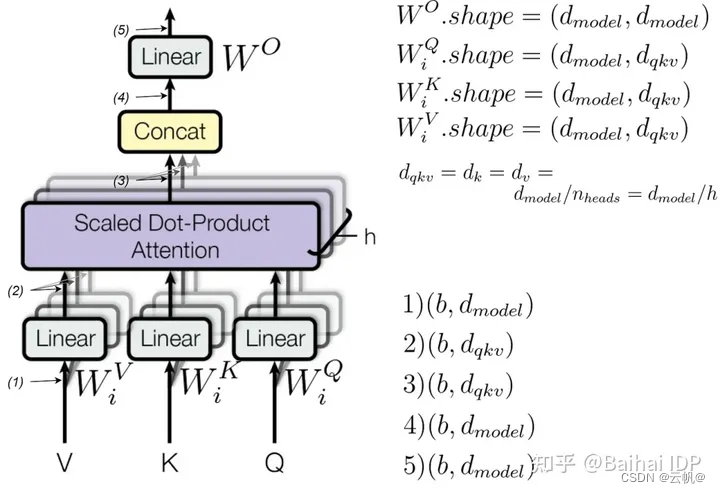
transformer参数推导
一、目录
1.Bert Embedding 参数量计算 2.多头自注意力self_attention 参数计算: d_model* d_model 3*(d_model* d_qkvnum_heads) 3. 全连接层参数量 4.layerNormer 参数量 2hidden 5. 编码器 解码器参数 6. 语言模型head 参数:hidden* vocab
二、实现
参考&…
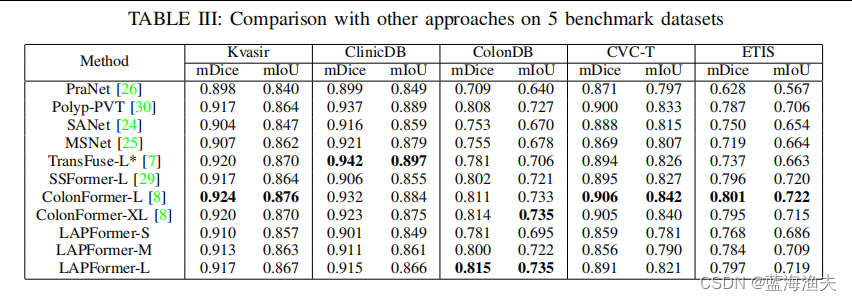
论文阅读:LAPFormer: A Light and Accurate PolypSegmentation Transformer
这是一个基于Transformer的轻量级图像分割模型。作者们使用MiT(Mix Transformer)作为编码器,并为LAPFormer设计了一个新颖的解码器,该解码器利用多尺度特征,并包含特征精炼模块和特征选择模块,以生成精细的…
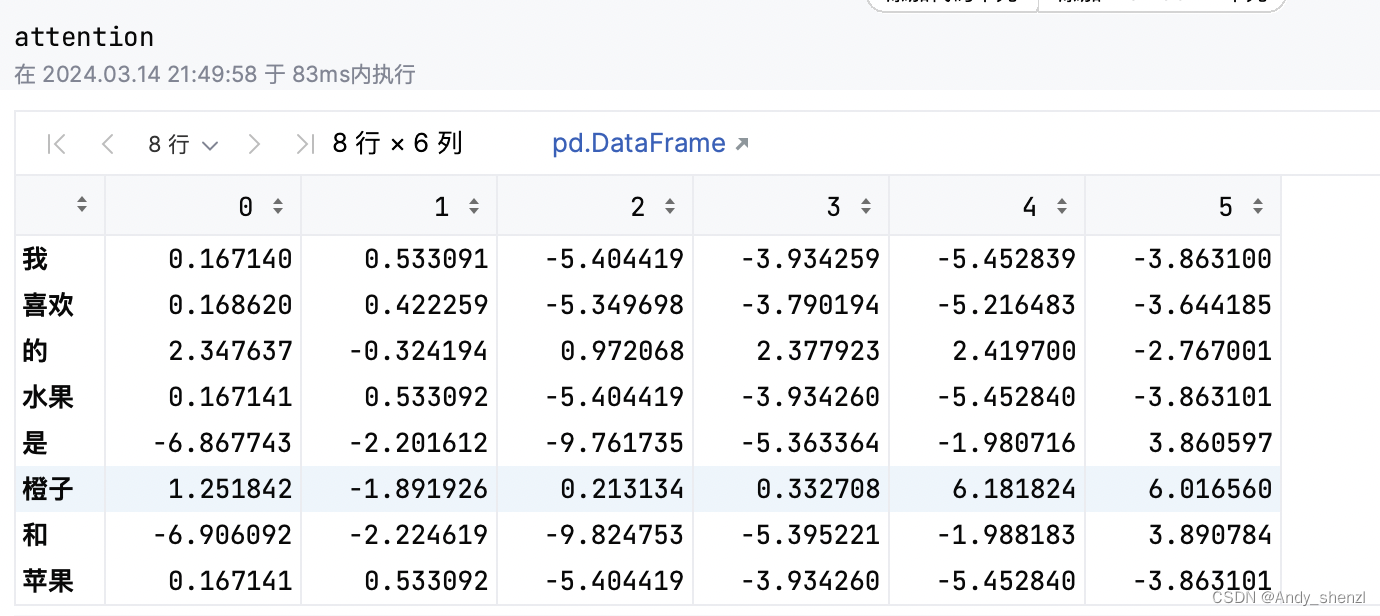
白话transformer(三):Q K V矩阵代码演示
在前面文章讲解了QKV矩阵的原理,属于比较主观的解释,下面用简单的代码再过一遍加深下印象。
B站视频 白话transformer(三) 1、生成数据
我们呢就使用一个句子来做一个测试,
text1 "我喜欢的水果是橙子和苹果&…
python基于DETR(DEtection TRansformer)开发构建钢铁产业产品智能自动化检测识别系统
在前文中我们基于经典的YOLOv5开发构建了钢铁产业产品智能自动化检测识别系统,这里本文的主要目的是想要实践应用DETR这一端到端的检测模型来开发构建钢铁产业产品智能自动化检测识别系统。
DETR (DEtection TRansformer) 是一种基于Transformer架构的端到端目标检…
解决causal_conv1d和mamba_ssm无法安装 -> 直接使用Mamba基础环境docker镜像
介绍 Mamba: Linear-Time Sequence Modeling with Selective State Spaces 论文:https://arxiv.org/abs/2312.00752 Code:https://github.com/state-spaces/mamba 目前 5.3k Star 主要是为了解决pip install causal_conv1d 和mamba_ssm 老是安装出错。 包…

Transformer and Pretrain Language Models3-6
Pretrain Language Models预训练语言模型
content: language modeling(语言模型知识)
pre-trained langue models(PLMs)(预训练的模型整体的一个分类)
fine-tuning approaches GPT and BERT(…
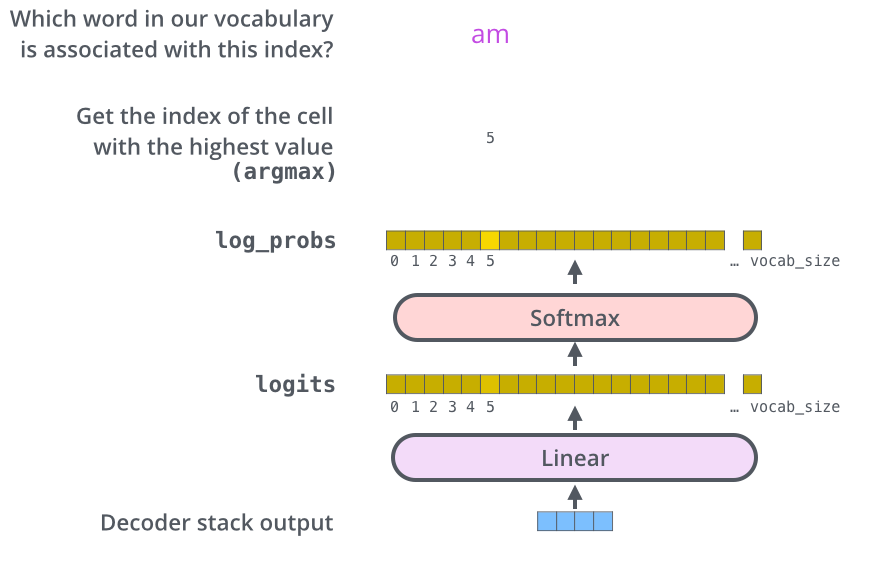
Transformer实战-系列教程2:Transformer算法解读2
🚩🚩🚩Transformer实战-系列教程总目录 有任何问题欢迎在下面留言 Transformer实战-系列教程1:Transformer算法解读1 Transformer实战-系列教程2:Transformer算法解读2
5、Multi-head机制
在4中我们的输入是X&#x…

【论文笔记】Mamba:挑战Transformer地位的新架构
Mamba
Mamba: Linear-Time Sequence Modeling with Selective State Spaces Mamba Mamba摘要背景存在的问题本文的做法实验结果 文章内容Transformer的缺点Structured state space sequence models (SSMs)介绍本文的工作模型介绍State Space ModelsSelective State Space Mod…
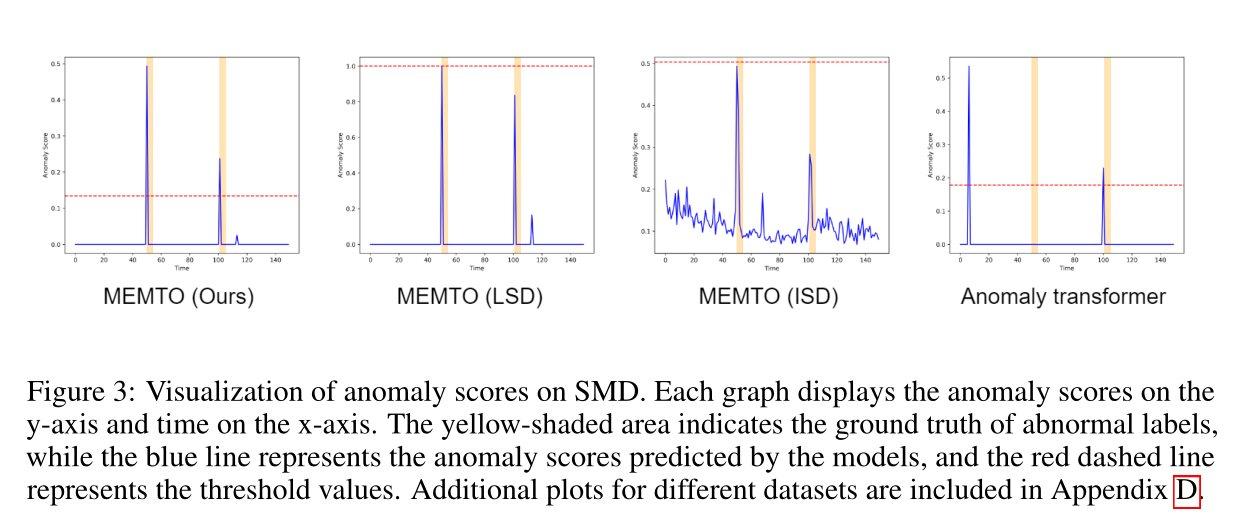
MEMTO: Memory-guided Transformer for Multivariate Time Series Anomaly Detection
目录 一、问题与思路1.1 现存问题1.2 解决思路 二、模型与方法2.1 模型概览2.2 Encoder and decoder2.3 门控存储器模块2.3.1 门控存储器更新阶段2.3.2 查询更新阶段2.3.3 损失函数2.3.4 初始化内存项2.3.5 异常评分2.3.6 阈值设定 三、实验与分析3.1 模型结果3.2 消融实验3.3 …
peft模型微调--Prompt Tuning
模型微调(Model Fine-Tuning)是指在预训练模型的基础上,针对特定任务进行进一步的训练以优化模型性能的过程。预训练模型通常是在大规模数据集上通过无监督或自监督学习方法预先训练好的,具有捕捉语言或数据特征的强大能力。
PEF…
深度学习专家学习计划
深度学习专家学习计划
一、学习背景与目标
作为一名有6年工作经验的Java开发人员,您已具备基本的编程能力和数据处理经验。现计划转岗至深度学习领域,成为深度学习专家。本计划将结合您的工作背景和现有知识,为您制定详细且精确的学习计划,帮助您逐步达到专家水平。
二、…
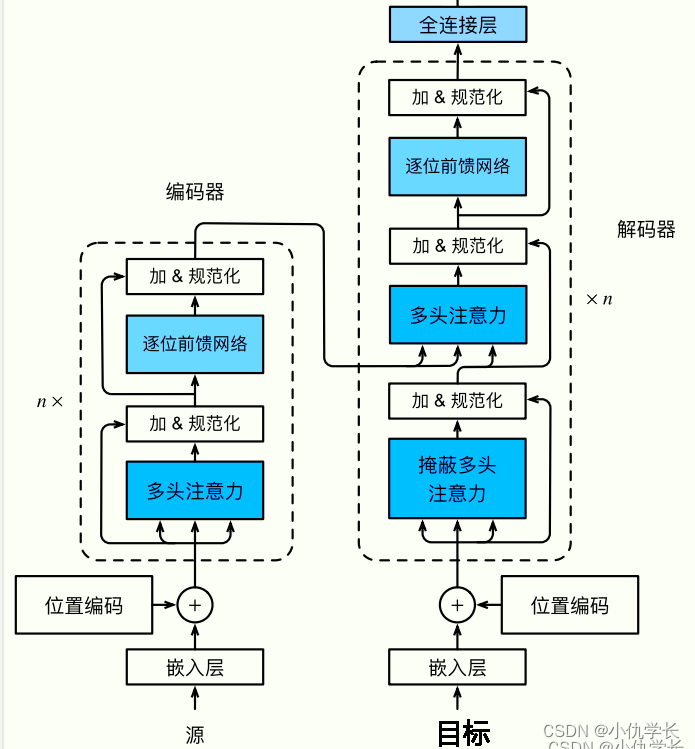
深度学习理论基础(七)Transformer编码器和解码器
目录 前述: Transformer总体结构框图一、编码器encoder1. 编码器作用2. 编码器部分(1)单个编码器层代码(2)编码器总体代码 二、解码器decoder1. 解码器作用2. 解码器部分(1)单个解码器层代码&am…
谁将替代 Transformer?
2017年谷歌发表的论文《Attention Is All You Need》成为当下人工智能的一篇圣经,此后席卷全球的人工智能热潮都可以直接追溯到 Transformer 的发明。
Transformer 由于其处理局部和长程依赖关系的能力以及可并行化训练的特点,一经问世,逐步取代了过去的 RNN(循环神经网络…

【论文简述】WT-MVSNet: Window-based Transformers forMulti-view Stereo(arxiv 2023)
一、论文简述
1. 第一作者:Jinli Liao、Yikang Ding
2. 发表年份:2023
3. 发表期刊:arxiv
4. 关键词:MVS、3D重建、Transformer、极线、几何约束
5. 探索动机:然而,在没有极几何约束的情况下匹配参考图…

Transformer 论文精读——Attention Is All You Need
https://www.bilibili.com/video/BV1pu411o7BE
摘要
序列转录模型是从一个序列生成另一个序列。Transformer 仅利用注意力机制(attention),并且在机器翻译领域取得很好的成功。
结论
Transformer 重要贡献之一提出:multi-head…

Attention原理+向量内积+Transformer中的Scaled Dot-Product Attention
一、Attention原理 将 S o u r c e Source Source中的构成元素想象成是由一系列的 < K e y , V a l u e > <Key,Value> <Key,Value>数据对构成,此时给定 T a r g e t Target Target中的某个元素 Q u e r y Query Query,通过计算 Q u e…
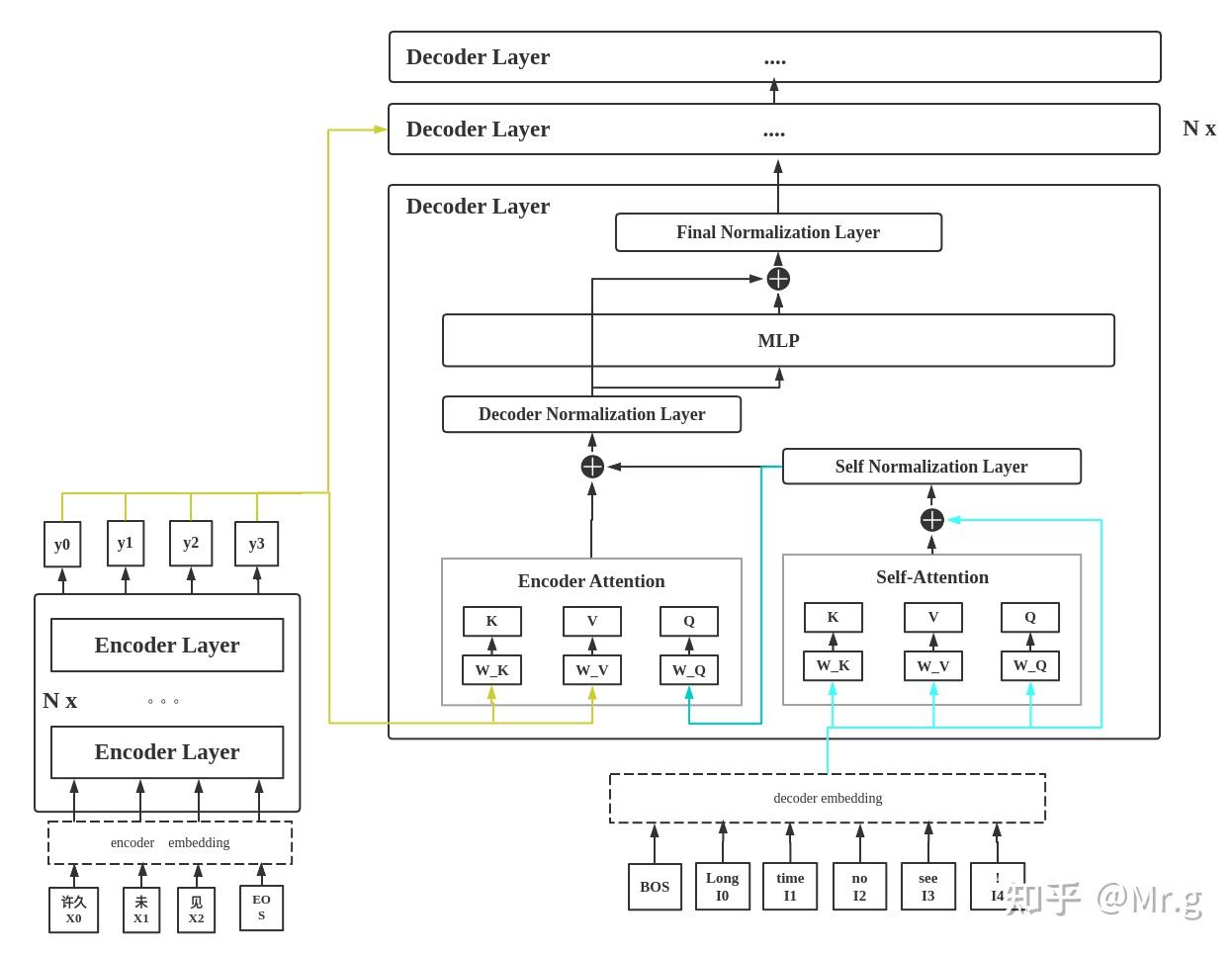
transformer零基础学习
声明:以下文章链接仅用于个人学习与备忘。 基础知识
1:零基础解析教程 [推荐] https://zhuanlan.zhihu.com/p/609271490
2:Transformer 详解 [推荐] https://wmathor.com/index.php/archives/1438/
3:如何从浅入深理解transfor…
Deep Homography with Transformer实验学习记录
1 文献阅读及记录
阅读笔记(arXiv2016)Deep Image Homography Estimation
2 实验
DETR:End-to-End Object Detection with Transformers
End-to-End Object Detection with Transformers[DETR]
VIT vision transformer pytorch代码复现
Vision Tra…

第十三章 原理篇:SWIN-transformer
累了,没写完 面试完了再来写
参考教程: swin-transformer/model.py 文章目录 概述transformer blockswindow_partionW-MSAwindow-reversePatch Merging 概述
在前面介绍了vision transformer的原理,加入transformer的结构后,这种…
huggingface transformers loadset 导入本地文件
点击查看 Huggingface详细入门介绍之dataset库
loadset 导入本地文件
import osfrom datasets import load_datasetdata_home r"D:\数据集路径"
#
data_dict {"train": os.path.join(data_home, "train.json"),"test": os.path.jo…
【图像分类】CNN + Transformer 结合系列.4
介绍两篇利用Transformer做图像分类的论文:CoAtNet(NeurIPS2021),ConvMixer(ICLR2022)。CoAtNet结合CNN和Transformer的优点进行改进,ConvMixer则patch的角度来说明划分patch有助于分类。 CoAtN…

Vision Transformer模型入门
Vision Transformer模型入门 一、Vision Transformer 模型1,Embedding 层结构详解2,Transformer Encoder 详解3,MLP Head 详解 二、ViT-B/16 网络结构三、Hybrid 模型详解四、ViT 模型搭建参数 一、Vision Transformer 模型
总体三个模块&am…
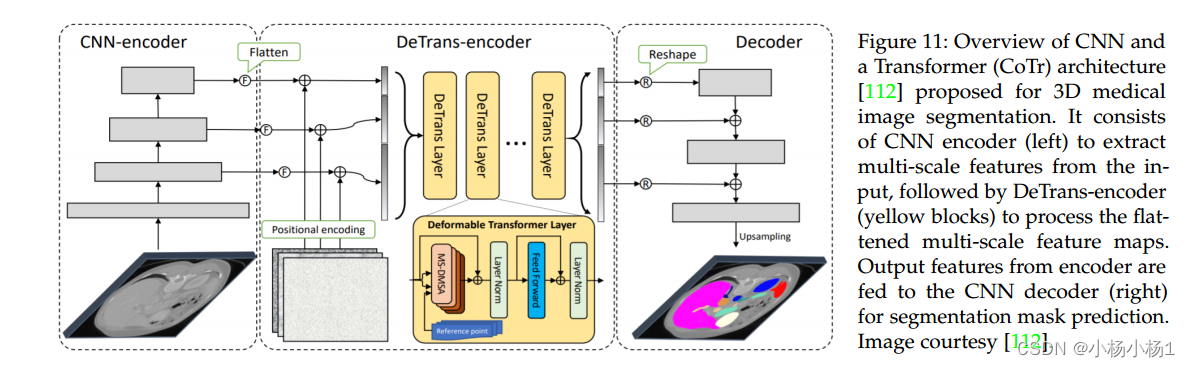
Transformer在医学影像中的应用综述-分割
文章目录 Transformers in Medical Imaging: A Survey摘要方法手工的方法基于卷积的方法基于Transformer的方法影像分割2D3D 多器官分割纯transformer混合Transformer单规模结构transformer在编码器中Transformer在编码器和解码器之间Transformer在编码器和解码器中Transformer…
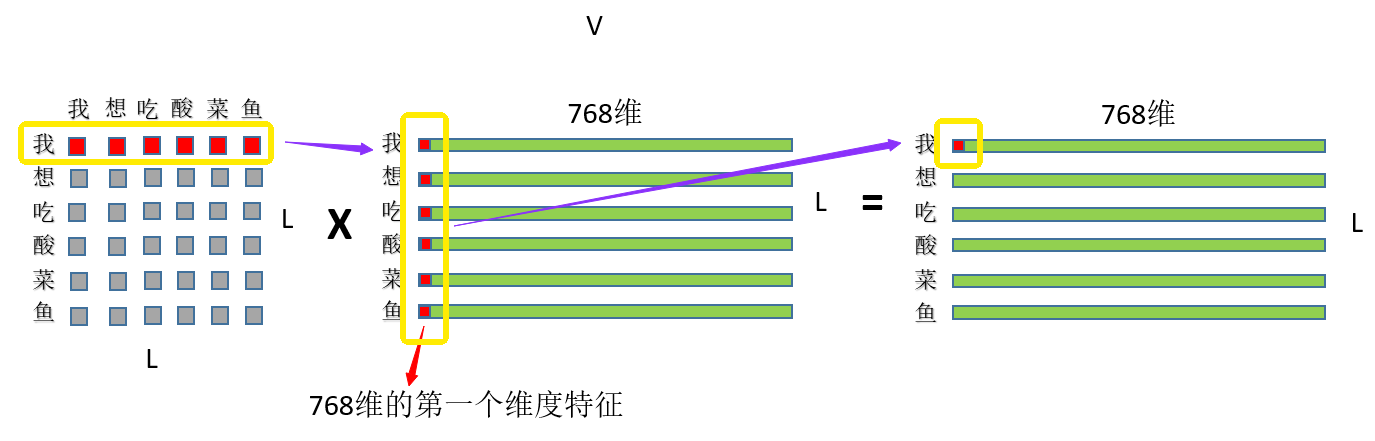
如何理解attention中的Q、K、V?
y直接用torch实现一个SelfAttention来说一说:
1、首先定义三哥线性变换,query,key以及value:
class BertSelfAttention(nn.Module):self.query nn.Linear(config.hidden_size, self.all_head_size)#输入768,输出768…
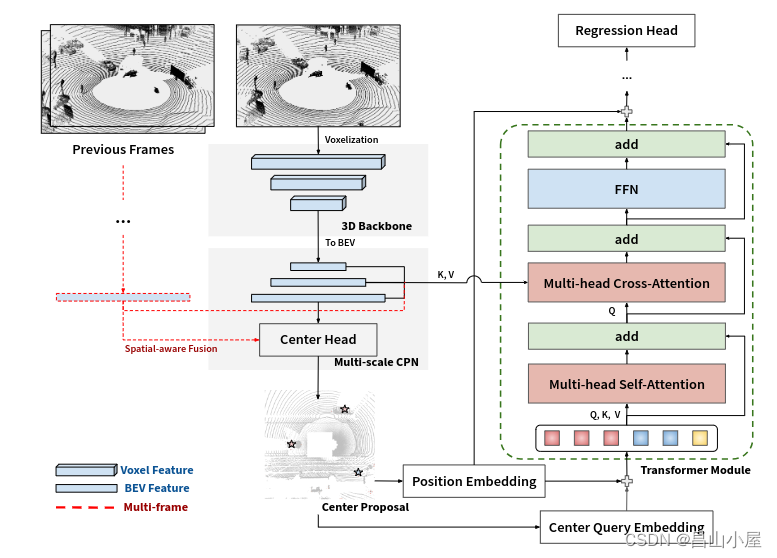
【多模态融合】TransFusion学习笔记(1)
工作上主要还是以纯lidar的算法开发,部署以及系统架构设计为主。对于多模态融合(这里主要是只指Lidar和Camer的融合)这方面研究甚少。最近借助和朋友们讨论论文的契机接触了一下这方面的知识,起步是晚了一点,但好歹是开了个头。下面就借助TransFusion论文…
【状态估计】将Transformer和LSTM与EM算法结合到卡尔曼滤波器中,用于状态估计(Python代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…
自然语言处理---Transformer构建语言模型
语言模型概述
以一个符合语言规律的序列为输入,模型将利用序列间关系等特征,输出一个在所有词汇上的概率分布,这样的模型称为语言模型。 # 语言模型的训练语料一般来自于文章,对应的源文本和目标文本形如: src1 "I can do&…

【TGRS 2023】RingMo: A Remote Sensing Foundation ModelWith Masked Image Modeling
RingMo: A Remote Sensing Foundation Model With Masked Image Modeling, TGRS 2023
论文:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp&arnumber9844015
代码:https://github.com/comeony/RingMo
MindSpore/RingMo-Framework (gitee.com) …
人工智能三要数之算法Transformer
1. 人工智能三要数之算法Transformer
人工智能的三个要素是算法、数据和计算资源。Transformer 模型作为一种机器学习算法,可以应用于人工智能系统中的数据处理和建模任务。 算法: Transformer 是一种基于自注意力机制的神经网络模型,用于处理序列数据的…
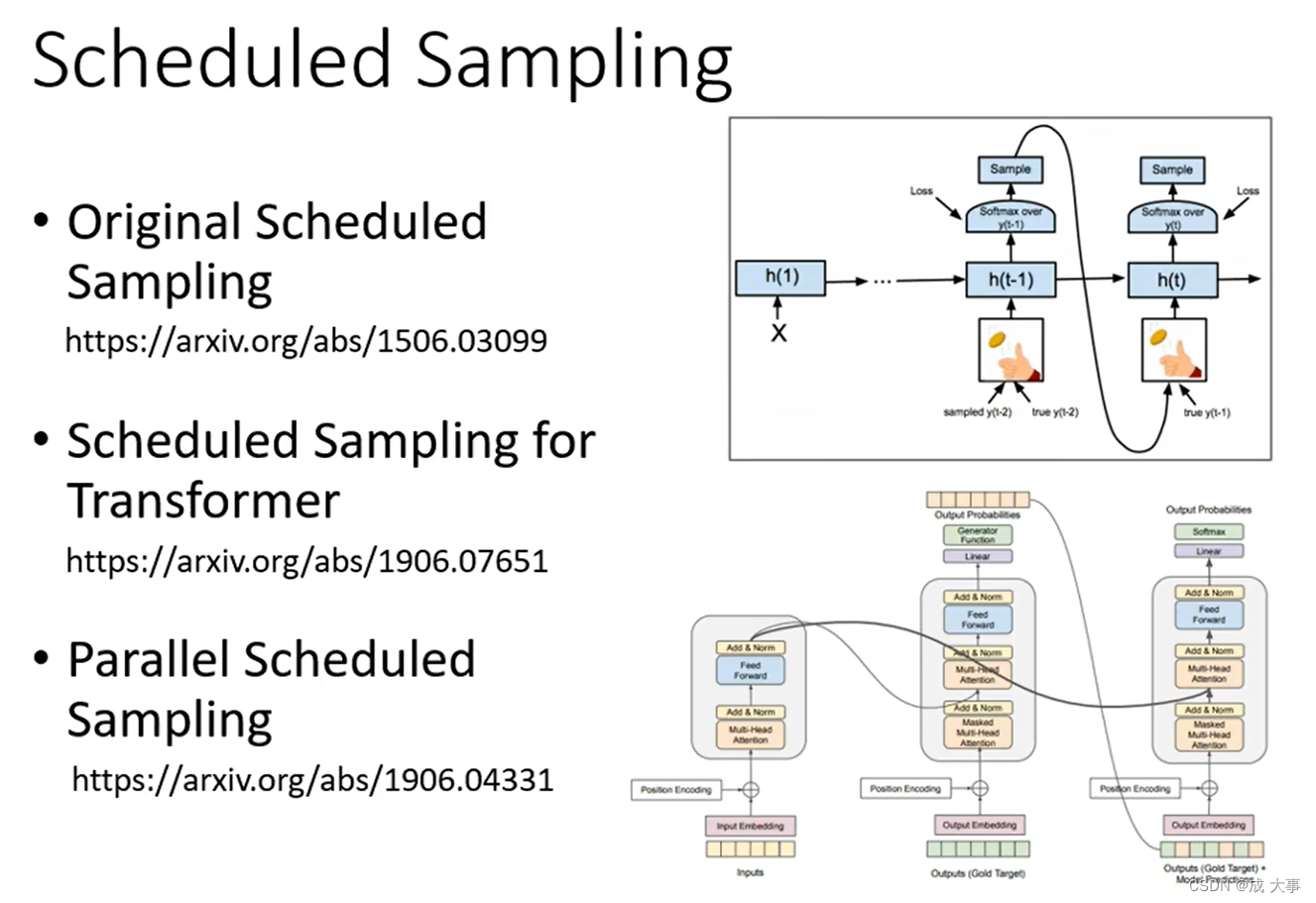
Transformer-深度学习-台湾大学李宏毅-课程笔记
目录 参考Seq2seqSequence-to-sequence(Seq2seq)适用任务语音识别机器翻译语音翻译语音合成聊天机器人自然语言处理硬解任务:文法分析硬解任务:多标签分类硬解任务:目标检测 Sequence-to-sequence(Seq2seq&…
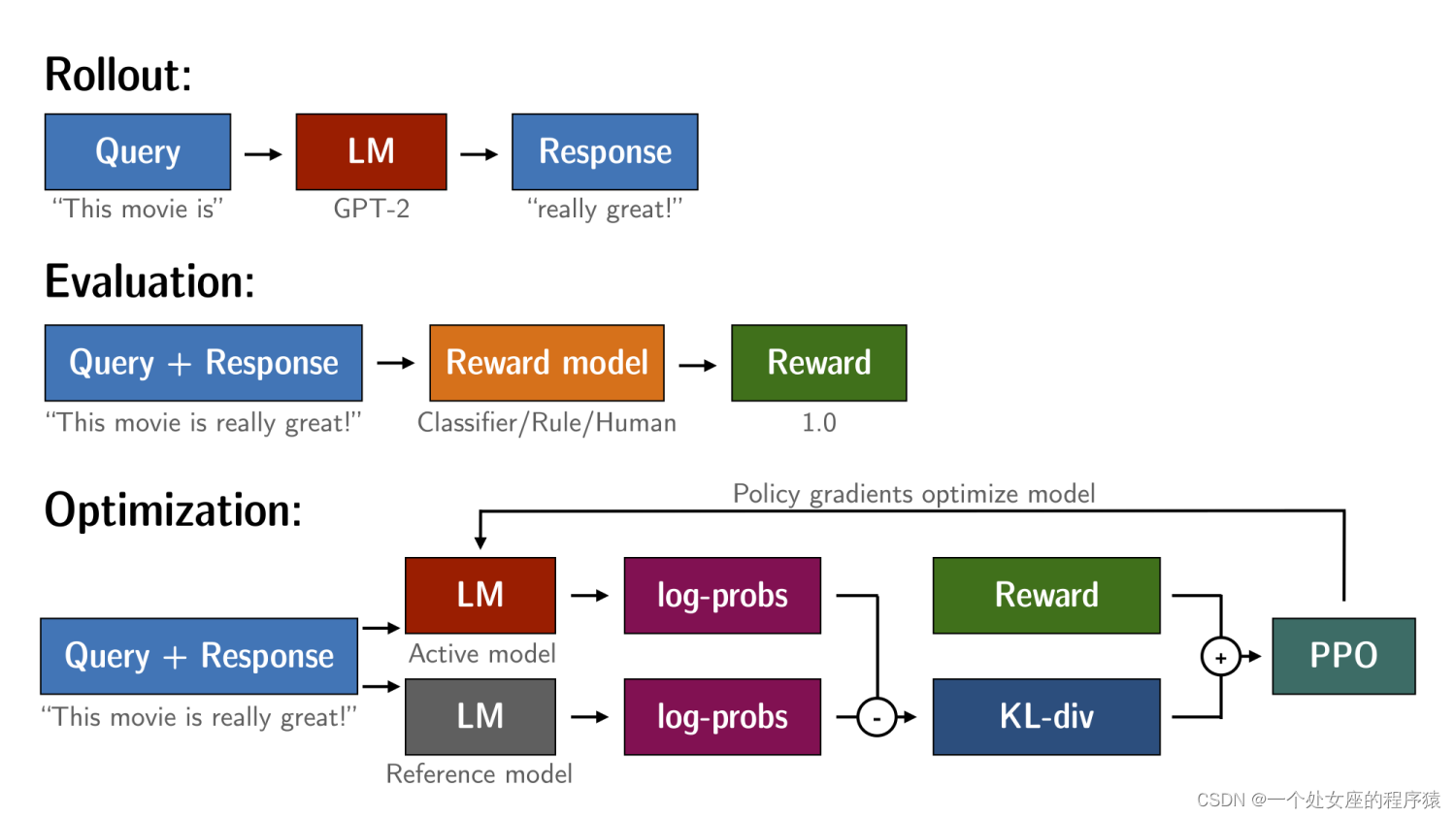
Py之trl:trl(一款采用强化学习训练Transformer语言模型和稳定扩散模型的全栈库)的简介、安装、使用方法之详细攻略
Py之trl:trl(一款采用强化学习训练Transformer语言模型和稳定扩散模型的全栈库)的简介、安装、使用方法之详细攻略 目录
trl的简介
1、亮点
2、PPO是如何工作的:PPO对语言模型微调三步骤,Rollout→Evaluation→Optimization
trl的安装
t…
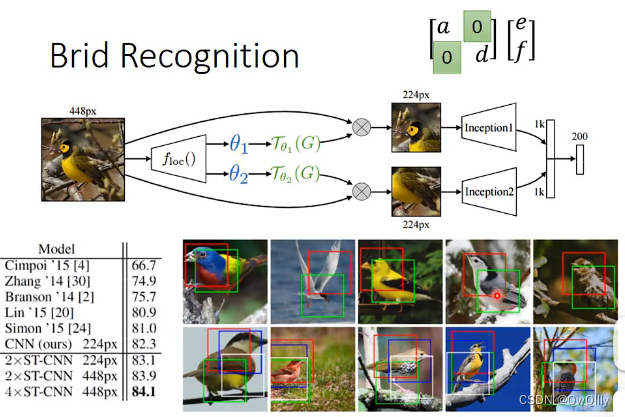
2022最新版-李宏毅机器学习深度学习课程-P25 Spacial Transformer Layer
data augmentation/spacial transformer
CNN 并不能够处理影像放大缩小,或者是旋转的问题。所以在做影像辨识的时候,往往都要做 Data Augmentation,把你的训练数据截一小块出来放大缩小、把图片旋转,CNN 才会做到好的结果。
有一个架构叫 spacial Tran…
python requests爬取税务总局税案通报、税务新闻和政策解读
文章目录 环境配置页面爬取流程税案通报爬取code税务新闻爬取政策解读爬取 环境配置
python:3.7 requests:发出请求,返回页面 beautifulsoup:解析页面 time:及时 warnings:忽视警告
页面
网址࿱…
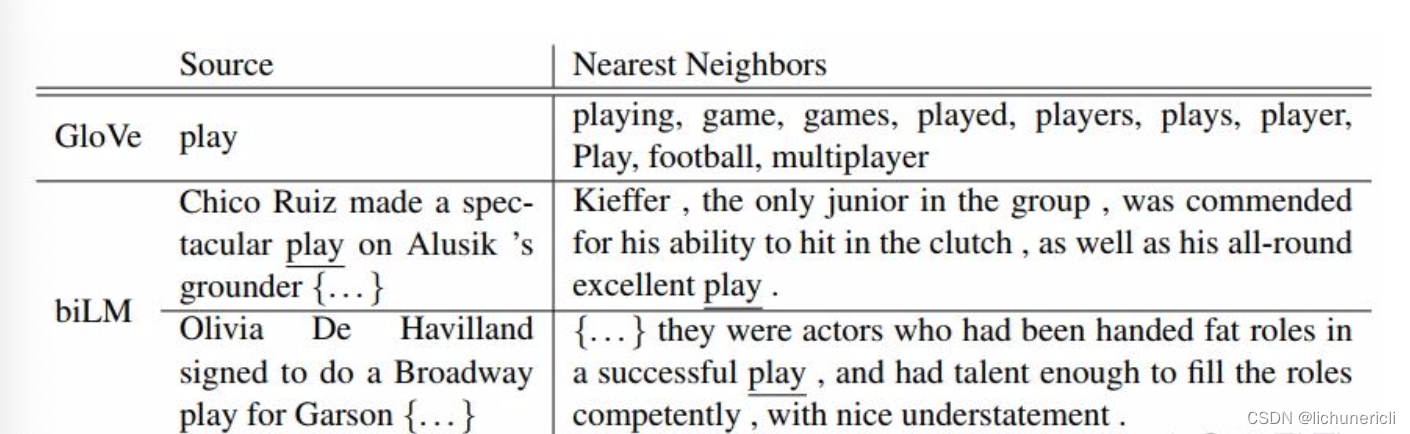
自然语言处理---Transformer机制详解之ELMo模型介绍
1 ELMo简介
ELMo是2018年3月由华盛顿大学提出的一种预训练模型.
ELMo的全称是Embeddings from Language Models.ELMo模型的提出源于论文<< Deep Contextualized Word Representations >>.ELMo模型提出的动机源于研究人员认为一个好的预训练语言模型应该能够包含丰…
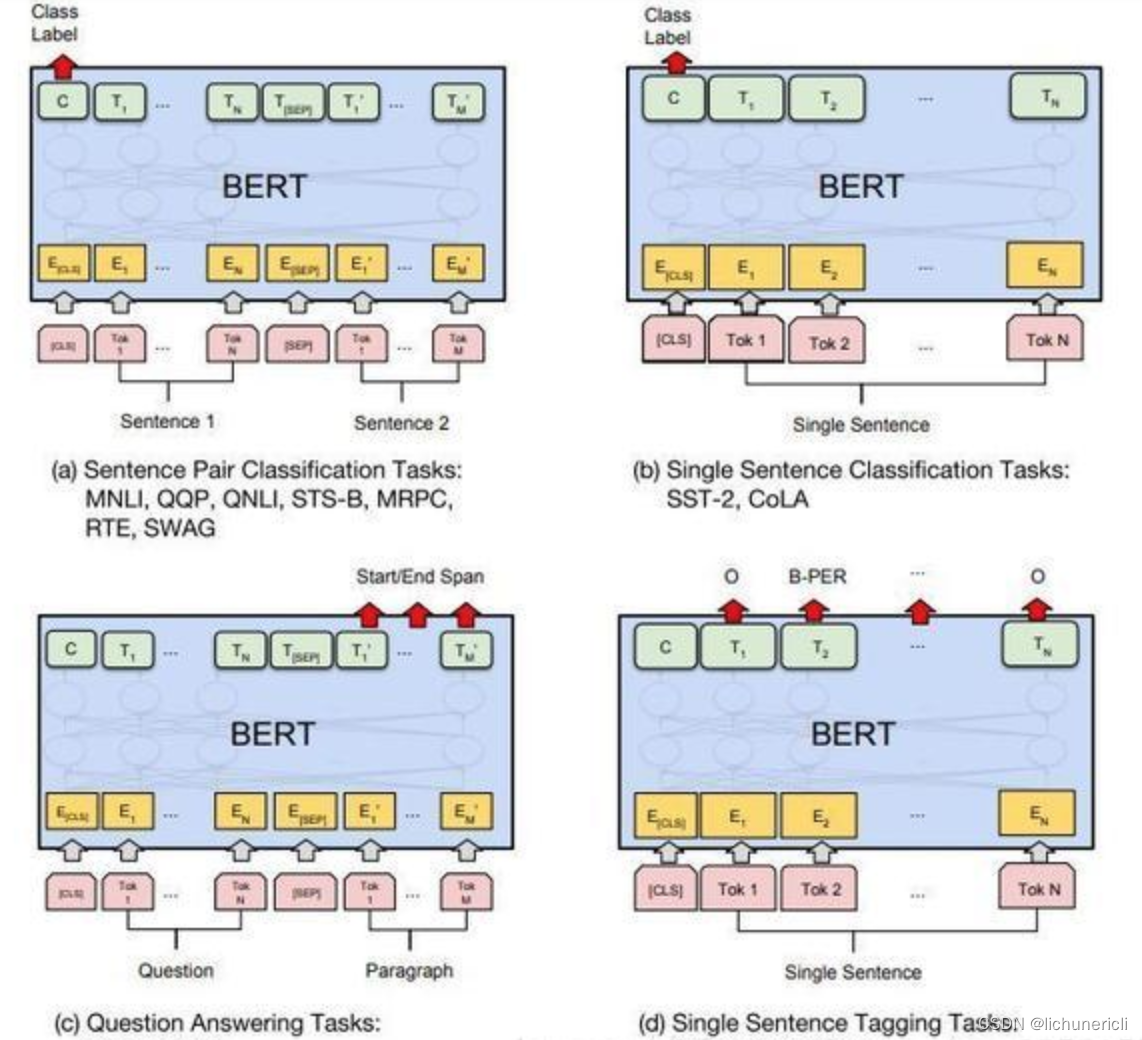
自然语言处理---Transformer机制详解之BERT模型介绍
1 BERT简介
BERT是2018年10月由Google AI研究院提出的一种预训练模型.
BERT的全称是Bidirectional Encoder Representation from Transformers.BERT在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且在11种不…

【动手学深度学习-Pytorch版】Transformer代码总结
本文是纯纯的撸代码讲解,没有任何Transformer的基础内容~ 是从0榨干Transformer代码系列,借用的是李沐老师上课时讲解的代码。 本文是根据每个模块的实现过程来进行讲解的。如果您想获取关于Transformer具体的实现细节(不含代码)可…
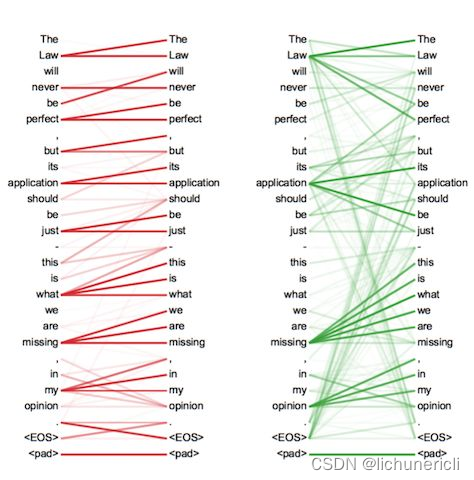
自然语言处理---Transformer机制详解之Multi head Attention详解
1 采用Multi-head Attention的原因
原始论文中提到进行Multi-head Attention的原因是将模型分为多个头, 可以形成多个子空间, 让模型去关注不同方面的信息, 最后再将各个方面的信息综合起来得到更好的效果.多个头进行attention计算最后再综合起来, 类似于CNN中采用多个卷积核的…

自然语言处理---Transformer机制详解之GPT模型介绍
1 GPT介绍
GPT是OpenAI公司提出的一种语言预训练模型.OpenAI在论文<< Improving Language Understanding by Generative Pre-Training >>中提出GPT模型.OpenAI后续又在论文<< Language Models are Unsupervised Multitask Learners >>中提出GPT2模型.…
自然语言处理---Transformer机制详解之Transformer结构
1 Encoder模块
1.1 Encoder模块的结构和作用
经典的Transformer结构中的Encoder模块包含6个Encoder Block.每个Encoder Block包含一个多头自注意力层,和一个前馈全连接层.
1.2 Encoder Block
在Transformer架构中,6个一模一样的Encoder …
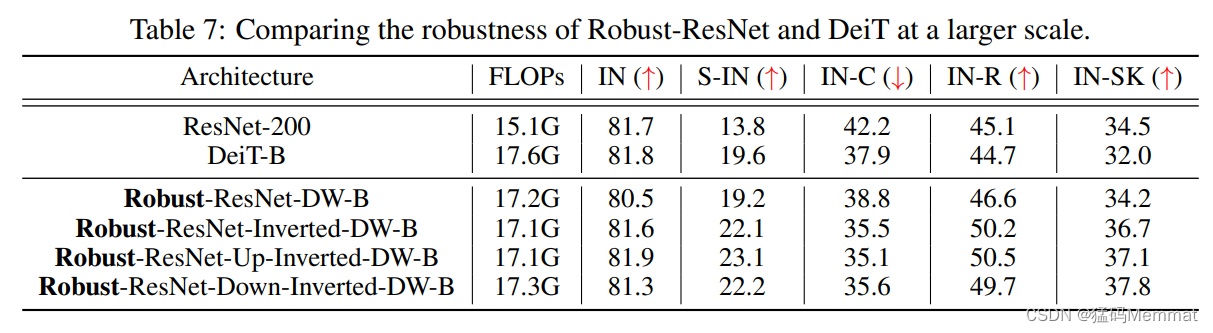
【ICLR23论文】Can CNNs Be More Robust Than Transformers?
文章目录 0 Abstract1 Introduction2 Related Works3 Settings3.1 CNN Block Instantiations3.2 Computational Cost3.3 Robustness Benchmarks3.4 Training Recipe3.5 Baseline Results 4 Component Diagnosis4.1 Patchief Stem4.2 Large Kernel Size4.3 Reducing Activation …
16.ViT模型介绍
Vision Transformer
关于ViT
Transformer自2017年06月由谷歌团队在论文Attention Is All You Need中提出后,给自然语言处理领域带去了深远的影响,其并行化处理不定长序列的能力及自注意力机制表现亮眼。根据以往的惯例,一个新的机器学习方法往往先在NLP领域带来突破,然后…
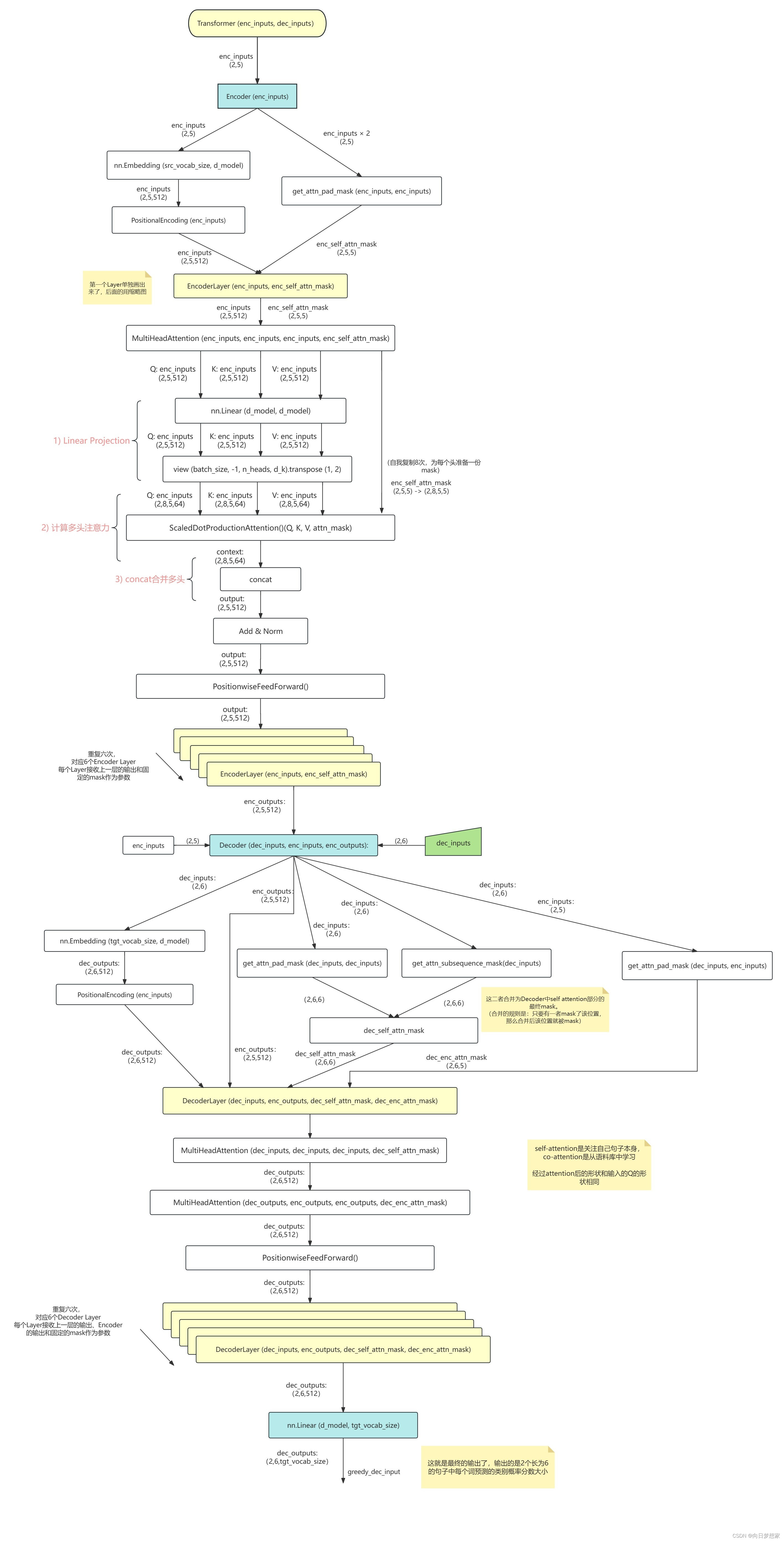
Transformer的最简洁pytorch实现
目录 前言
1. 数据预处理
2. 模型参数
3. Positional Encoding
4. Pad Mask
5. Subsequence Mask
6. ScaledDotProductAttention
7. MultiHeadAttention
8. FeedForward Networks
9. Encoder Layer
10. Encoder
11. Decoder Layer
12. Decoder
13. Transformer
1…
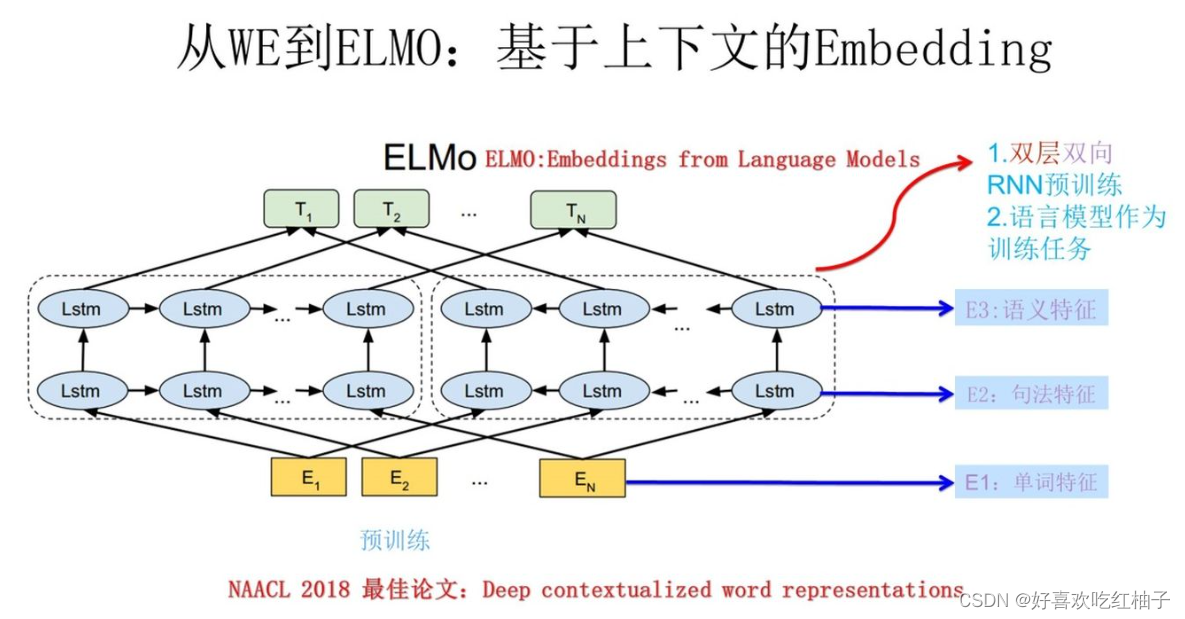
Transformer详解一:transformer的由来和先导知识
目录 参考资料前言一、预训练二、神经网络语言模型(NNLM):预测下一个词one-hot编码的缺陷词向量(word embedding) 三、Word2Vec模型:得到词向量CBOWSkip-gramWord2Vec和NNLM的区别Word2Vec的缺陷 四、ELMO模…
时序预测 | Pytorch实现TCN-Transformer的时间序列预测
时序预测 | Pytorch实现TCN-Transformer的时间序列预测 目录 时序预测 | Pytorch实现TCN-Transformer的时间序列预测效果一览基本介绍程序设计 效果一览 基本介绍 基于TCN-Transformer模型的时间序列预测,可以用于做光伏发电功率预测,风速预测࿰…
时序预测 | Pytorch实现TCN-Transformer的时间序列预测
时序预测 | Pytorch实现TCN-Transformer的时间序列预测 目录 时序预测 | Pytorch实现TCN-Transformer的时间序列预测效果一览基本介绍程序设计 效果一览 基本介绍 基于TCN-Transformer模型的时间序列预测,可以用于做光伏发电功率预测,风速预测࿰…

Transformer时间序列:PatchTST引领时间序列预测进
Transformer时间序列:PatchTST引领时间序列预测进 引言为什么transformer框架可以应用到时间序列呢统计学模型深度学习模型 PatchTSTPatchTST模型架构原理。通道独立性Patchingpatching的优点Transformer编码器 利用表示学习改进PatchTST使用PatchTST模型进行预测初…

迁移学习(含代码示例)
感谢阅读fasttext安装文本分类种类文本分类代码版过程详解获取数据训练测试ValueError:XXX cannot be opened for training!模型测试模型调优增加训练轮数调整学习率增加n-gram特征修改损失计算方式自动超参数调优模型保存与重加载词向量简介词向量模型压缩文件下载解压文件代码…
multiheadattention类原理及源码理解
网络找的一段代码如下:
class MultiHeadedAttention(nn.Module):def __init__(self, h, d_model, dropout0.1):"Take in model size and number of heads."super(MultiHeadedAttention, self).__init__()assert d_model % h 0# We assume d_v always eq…
基于transformer的解码decode目标检测框架(修改DETR源码)
提示:transformer结构的目标检测解码器,包含loss计算,附有源码 文章目录 前言一、main函数代码解读1、整体结构认识2、main函数代码解读3、源码链接二、decode模块代码解读1、decoded的TransformerDec模块代码解读2、decoded的TransformerDecoder模块代码解读3、decoded的De…

(参考写法)Transformer-Based Visual Segmentation:A Survey
基于Transformer的视觉分割综述
南洋理工大学NTU、上海人工智能实验室AI Lab整理300+论文 论文地址:https://arxiv.org/pdf/2304.09854.pdf
代码地址:https://github.com/lxtGH/Awesome-Segmentation-With-Transformer
前言
SAM (Segment Anything )作为一个视觉的分割…
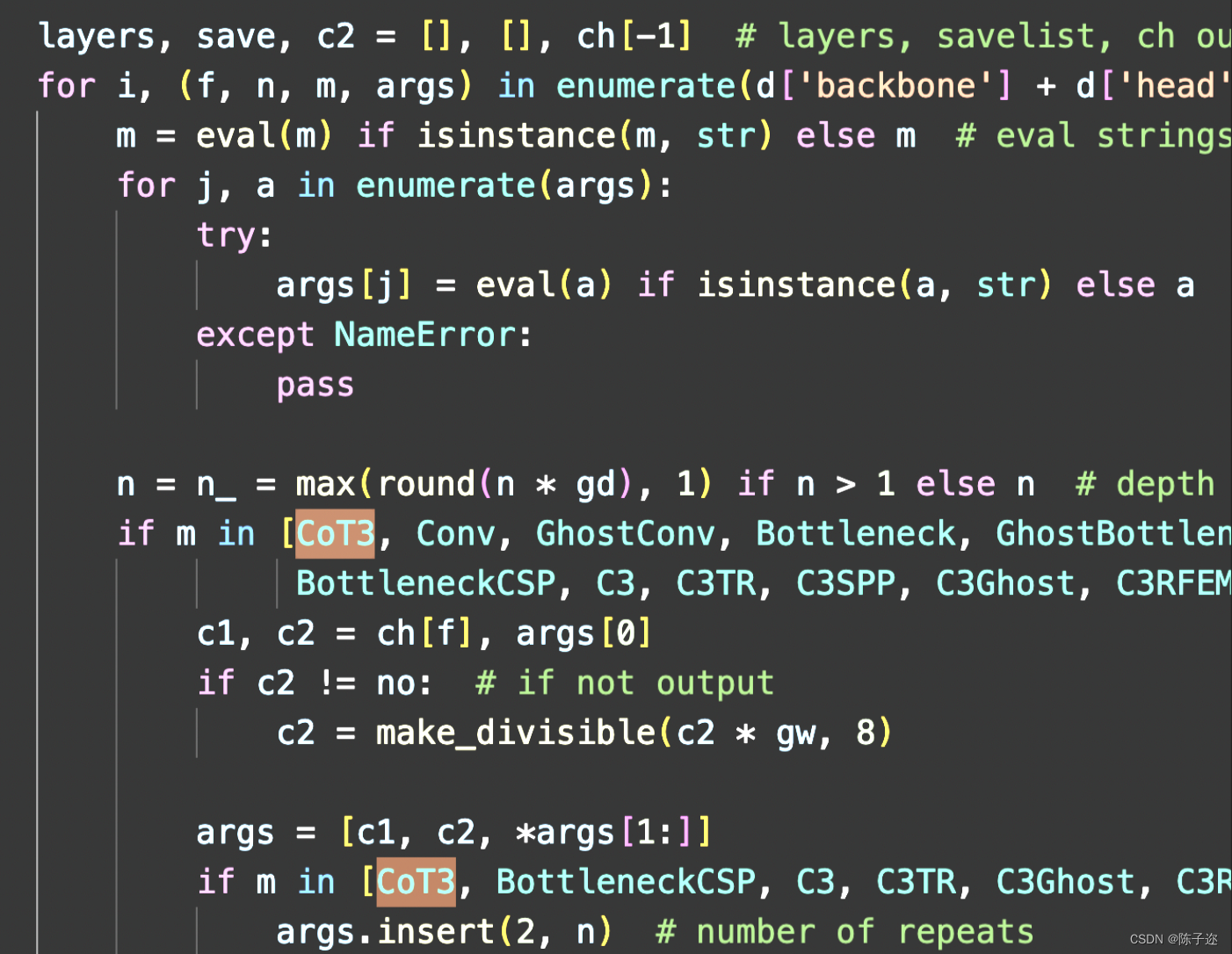
YOLOv5、YOLOv8改进:CotNet Transformer
1.简介
京东AI研究院提出的一种新的注意力结构。将CoT Block代替了ResNet结构中的3x3卷积,在分类检测分割等任务效果都出类拔萃
论文地址:https://arxiv.org/pdf/2107.12292.pdf
源代码地址:https://github.com/JDAI-CV/CoTNet
具有自注意…

MAMBA介绍:一种新的可能超过Transformer的AI架构
有人说,“理解了人类的语言,就理解了世界”。一直以来,人工智能领域的学者和工程师们都试图让机器学习人类的语言和说话方式,但进展始终不大。因为人类的语言太复杂,太多样,而组成它背后的机制,…
【论文笔记】Gemini: A Family of Highly Capable Multimodal Models——细看Gemini
Gemini
【一句话总结,对标GPT4,模型还是transformer的docoder部分,提出三个不同版本的Gemini模型,Ultra的最牛逼,Nano的可以用在手机上。】
谷歌提出了一个新系列多模态模型——Gemini家族模型,包括Ultra…
注意力机制,Transformer相关详解
本文遵循《动手学深度学习pytorch版》的内容组织,从注意力机制开始讲到Transfomer,偏重关键知识理解并附带图解和公式,未加说明时,插图均来自于该书,文本内容较长(9414字),建议收藏慢…
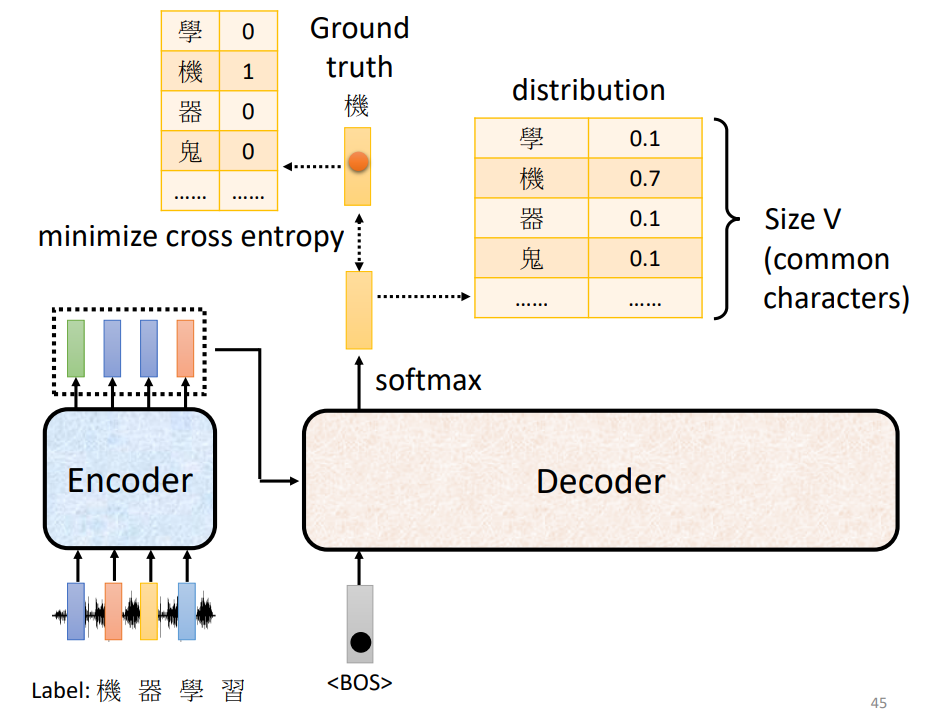
Transformer的学习
文章目录 Transformer1.了解Seq2Seq任务2.Transformer 整体架构3.Encoder的运作方式4.Decoder的运作方式5.AT 与 NAT6.Encoder 和 Decoder 之间的互动7.Training Transformer
1.了解Seq2Seq任务
NLP 的问题,都可以看做是 QA(Question Answering&#x…
自然语言处理---Transformer机制详解之GPT2模型介绍
1 GPT2的架构
从模型架构上看, GPT2并没有特别新颖的架构, 它和只带有解码器模块的Transformer很像.
所谓语言模型, 作用就是根据已有句子的一部分, 来预测下一个单词会是什么. 现实应用中大家最熟悉的一个语言模型应用, 就是智能手机上的输入法, 它可以根据当前输入的内容智…

【Transformer】Transformer and BERT(1)
文章目录 TransformerBERT 太…完整了!同济大佬唐宇迪博士终于把【Transformer】入门到精通全套课程分享出来了,最新前沿方向
学习笔记
Transformer 无法并行,层数比较少 词向量生成之后,不会变,没有结合语境信息的情…
自然语言处理---Transformer机制详解之Decoder详解
1 Decoder端的输入解析
1.1 Decoder端的架构
Transformer原始论文中的Decoder模块是由N6个相同的Decoder Block堆叠而成,其中每一个Block是由3个子模块构成,分别是多头self-attention模块,Encoder-Decoder attention模块,前馈全…
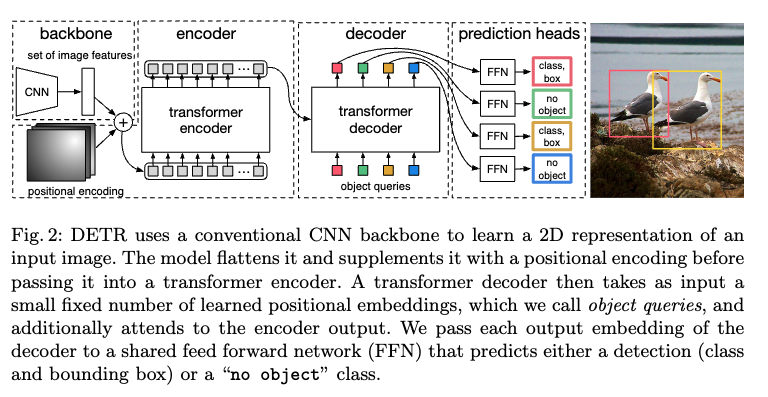
DETR 【目标检测里程碑的任务】
paper with code - DETR 标题
End-to-End Object Detection with Transformers end-to-end 意味着去掉了NMS的操作(生成很多的预测框,nms 去掉冗余的预测框)。因为有了NMS ,所以调参,训练都会多了一道工序,…
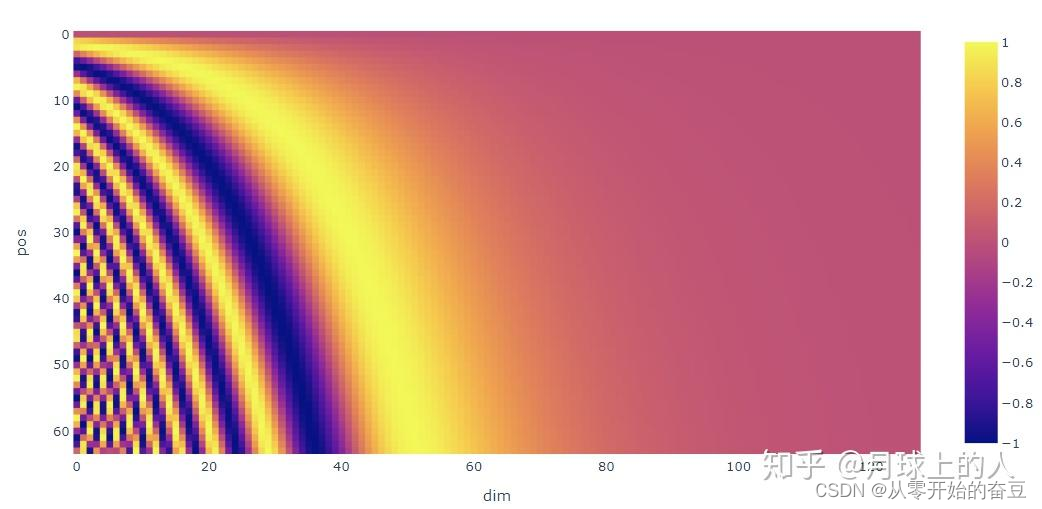
深度学习(八):bert理解之transformer
1.主要结构
transformer 是一种深度学习模型,主要用于处理序列数据,如自然语言处理任务。它在 2017 年由 Vaswani 等人在论文 “Attention is All You Need” 中提出。
Transformer 的主要特点是它完全放弃了传统的循环神经网络(RNN&#x…

RIS 系列 Mask Grounding for Referring Image Segmentation 论文阅读笔记
RIS 系列 Mask Grounding for Referring Image Segmentation 论文阅读笔记 一、Abstract二、引言三、相关工作Architecture Design for RISLoss Design for RISMasked Language Modeling 四、方法4.1 结构4.2 Mask Grounding讨论 4.3 跨模态对齐模块4.4 跨模态对齐损失4.5 损失…
TransNeXt:稳健的注视感知ViT学习笔记
论文地址:https://arxiv.org/pdf/2311.17132.pdf 代码地址: GitHub - DaiShiResearch/TransNeXt: Code release for TransNeXt model 可以直接在ImageNet上训练的分类代码:GitHub - athrunsunny/TransNext-classify
代码中读取数据的部分修改…
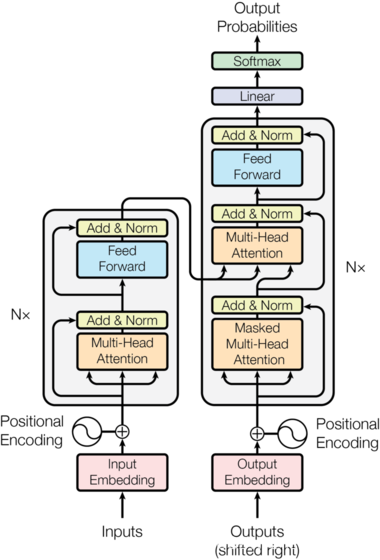
自然语言处理---Transformer模型
Transformer概述 相比LSTM和GRU模型,Transformer模型有两个显著的优势: Transformer能够利用分布式GPU进行并行训练,提升模型训练效率。 在分析预测更长的文本时,捕捉间隔较长的语义关联效果更好。 Transformer模型的作用 基于seq…
图像压缩:Transformer-based Image Compression with Variable Image Quality Objectives
论文作者:Chia-Hao Kao,Yi-Hsin Chen,Cheng Chien,Wei-Chen Chiu,Wen-Hsiao Peng
作者单位:National Yang Ming Chiao Tung University
论文链接:http://arxiv.org/abs/2309.12717v1
内容简介:
1)方向:…

Transformer(seq2seq、self-attention)学习笔记
在self-attention 基础上记录一篇Transformer学习笔记 Transformer的网络结构EncoderDecoder 模型训练与评估 Transformer的网络结构
Transformer是一种seq2seq 模型。输入一个序列,经过encoder、decoder输出结果也是一个序列,输出序列的长度由模型决定…

Transformer英语-法语机器翻译实例
依照Transformer结构来实例化编码器-解码器模型。在这里,指定Transformer编码器和解码器都是2层,都使用4头注意力。为了进行序列到序列的学习,我们在英语-法语机器翻译数据集上训练Transformer模型,如图11.2所示。
da…
CV计算机视觉每日开源代码Paper with code速览-2023.10.27
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:Transformer】(Ne…
深度学习 | Transformer模型及代码实现
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息…
LangChain+LLM实战---Transformer的工作原理
原文:What Are Transformer Models and How Do They Work?
Transformer模型是机器学习中最令人兴奋的新发展之一。它们在论文Attention is All You Need中被介绍。Transformer可以用于写故事、文章、诗歌,回答问题,翻译语言,与人…
时间序列预测模型实战案例(八)(Informer)个人数据集、详细参数、代码实战讲解
论文地址->Informer论文地址PDF点击即可阅读
代码地址-> 论文官方代码地址点击即可跳转下载GIthub链接 本文介绍
本篇博客带大家看的是Informer模型进行时间序列预测的实战案例,它是在2019年被提出并在ICLR 2020上被评为Best Paper,可以说Inform…
Monarch Mixer:介绍一种性能比Transformer更强的网络架构
六年前,谷歌团队在arXiv上发表了革命性的论文《Attention is all you need》。作为一种优势的机器学习网络架构,Transformer技术迅速席卷全球。Transformer一直是现代基础模型背后的主力架构,并且在不同的应用程序中取得了令人印象深刻的成功…
在Linux系统下部署Llama2(MetaAI)大模型教程
Llama2是Meta最新开源的语言大模型,训练数据集2万亿token,上下文长度是由Llama的2048扩展到4096,可以理解和生成更长的文本,包括7B、13B和70B三个模型,在各种基准集的测试上表现突出,最重要的是,…
大模型的实践应用5-百川大模型(Baichuan-13B)的模型搭建与模型代码详细介绍,以及快速使用方法
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用5-百川大模型(Baichuan-13B)的模型搭建与模型代码详细介绍,以及快速使用方法。 Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均…

Swin Transformer V2:扩展容量和分辨率
目标检测是计算机视觉的一个任务,它将指定的输入图像或视频帧转换为对象识别、定位和分类的结果。它非常类似于分类,但添加了定位的元素,它可以确定图像中的特定对象所在的位置。主要用于物体识别、跟踪和车牌识别。
Swin Transformer V2
✅…
YoloV7改进策略:独家原创,LSKA(大可分离核注意力)改进YoloV7,比Transformer更有效,包括论文翻译和实验结果
文章目录 摘要论文:《LSKA(大可分离核注意力):重新思考CNN大核注意力设计》1、简介2、相关工作3、方法4、实验5、消融研究6、与最先进方法的比较7、ViTs和CNNs的鲁棒性评估基准比较8、结论YoloV7官方测试结果改进一:使用LSKA注意力机制重构ELAN模块改进方法测试结果改进二…
pandas教程:Handling Missing Data 处理缺失数据
文章目录 Chapter 7 Data Cleaning and Preparation 数据清洗和准备7.1 Handling Missing Data 处理缺失数据1 Filtering Out Missing Data(过滤缺失值)2 Filling In Missing Data(填补缺失值) Chapter 7 Data Cleaning and Prepa…

解决 SSLError: HTTPSConnectionPool(host=‘huggingface.co‘, port=443)
看我的回答:
https://github.com/huggingface/transformers/issues/17611#issuecomment-1794486960
能问这个问题的都是网络不太好的,你懂的,所以答案全是解决网络的。
得益于这个回答:#17611 (comment)
看了一下代码…
pandas教程:Hierarchical Indexing 分层索引、排序和统计
文章目录 Chapter 8 Data Wrangling: Join, Combine, and Reshape(数据加工:加入, 结合, 变型)8.1 Hierarchical Indexing(分层索引)1 Reordering and Sorting Levels(重排序和层级排序)2 Summa…
pandas教程:Data Transformation 数据变换、删除和替换
文章目录 7.2 Data Transformation(数据变换)1 删除重复值2 Transforming Data Using a Function or Mapping(用函数和映射来转换数据)3 Replacing Values(替换值)4 Renaming Axis Indexes(重命…

YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型
YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型 前言相关介绍前提条件实验环境安装环境项目地址LinuxWindows 制作自己的数据集训练自己的数据集创建自己数据集的yaml文件football.yaml文件内容 进行训练进行验证进行预测 数据集获取参考文献 …

Transforme原理--全局解读
文章目录 作用全局解读 作用
Transformer最初设计用于处理序列数据,特别在NLP(自然语言处理)领域取得了巨大成功
全局解读
Transformer来源于谷歌的一篇经典论文Attention is All you Need
在此使用Transformer在机器翻译中的运用来讲解Transformer。
其中Tran…
YOLOv8-pose关键点检测:Backbone优化 |EMO,结合 CNN 和 Transformer 的现代倒残差移动模块设计 | ICCV2023
💡💡💡本文解决什么问题:面向移动端的轻量化网络模型EMO,它能够以相对较低的参数和 FLOPs 超越了基于 CNN/Transformer 的 SOTA 模型,替换YOLOv8 backbone Yolov8-Pose关键点检测专栏介绍:https://blog.csdn.net/m0_63774211/category_12398833.html
✨✨✨手把手教…
C# Onnx LSTR 基于Transformer的端到端实时车道线检测
目录
效果
模型信息
项目
代码
下载 效果 模型信息
lstr_360x640.onnx
Inputs ------------------------- name:input_rgb tensor:Float[1, 3, 360, 640] name:input_mask tensor:Float[1, 1, 360, 640] -----------------…
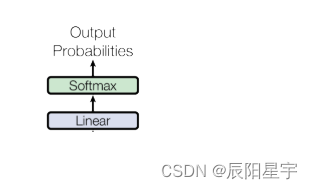
【Transformer从零开始代码实现 pytoch版】(四)输出部件:Linear+softmax
输出部分 线性层softmax层
作用: 通过对上一步经解码器输出的值进行线性变化得到指定维度的输出,也就是转换维度的作用。其中,softmax层的作用是使最后一维的向量中的数字缩放到0-1的概率值域内,并满足他们的和为1。
代码部分
…
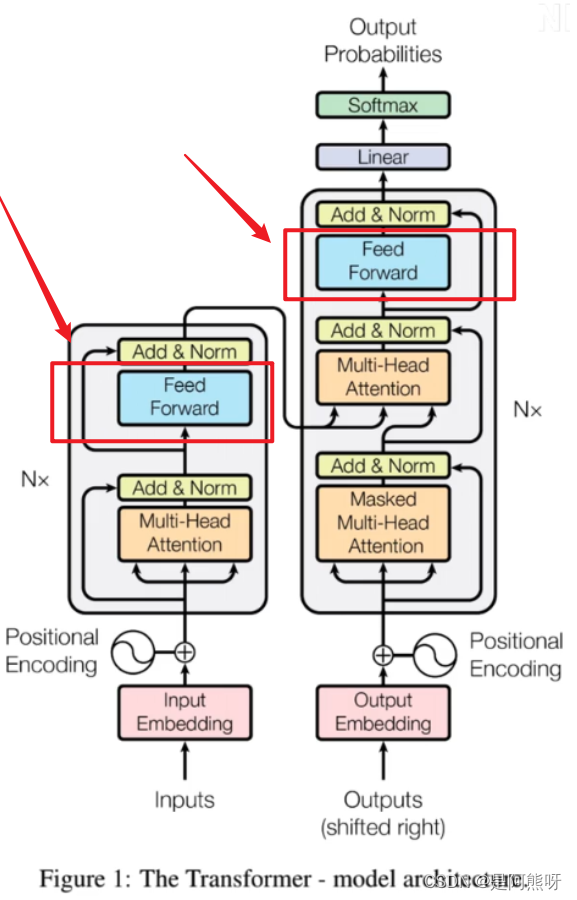
Transformer原理详解
前言:好久没有用了,我已经快忘记了自己还有一个CSDN账号了。 在某位不知名好友的提醒下,终于拾起来了,自己也从大二转变成了研二。 目前研究方向主要为:时间序列预测,自然语言处理,智慧医疗 欢迎…
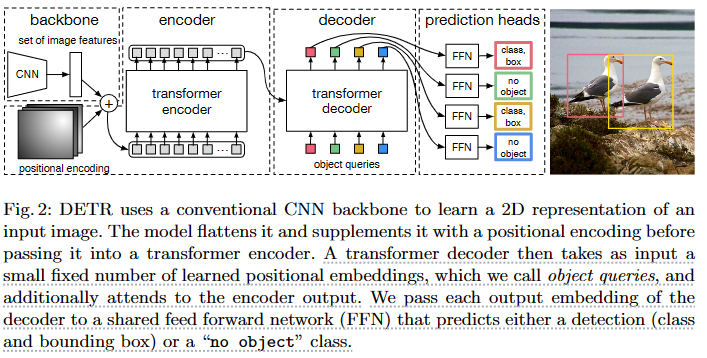
Transformer ZOO
Natural Language Processing
Transformer:Attention is all you need URL(46589)2017.6
提出Attention机制可以替代卷积框架。引入Position Encoding,用来为序列添加前后文关系。注意力机制中包含了全局信息自注意力机制在建模序列数据中的长期依赖关系方面表现出…
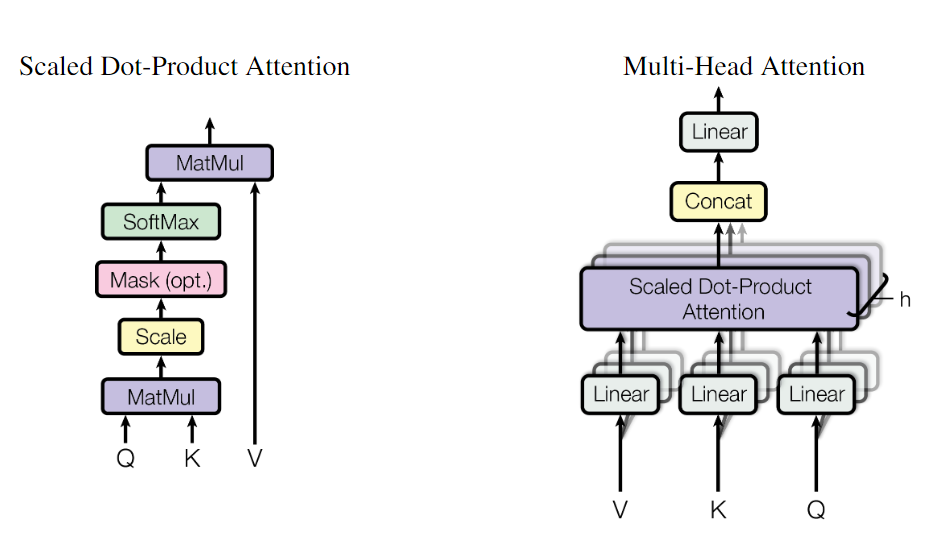
Transformer笔记
Transformer
encoder-decoder架构
Encoder:将输入序列转换为一个连续向量空间中的表示。Encoder通常是一个循环神经网络(RNN)或者卷积神经网络(CNN),通过对输入序列中的每个元素进行编码,得到…
关于这个“这是B站目前讲的最好的【Transformer实战】教程!“视频的目前可以运行的源代码GPU版本
课程链接如下:
2.1认识Transformer架构-part1_哔哩哔哩_bilibili
因为网上可以找到源代码,但是呢,代码似乎有点小错误,我自己改正后,放到了GPU上运行,
代码如下:
# 来自https://www.bilibil…
transform学习资料
一、NLP:自然语言处理
NLP 是机器学习在语言学领域的研究,专注于理解与人类语言相关的一切。NLP 的目标不仅是要理解每个单独的单词,而且能理解这些单词与之相关联的上下文之间的意思。
常见的NLP 任务列表:
对整句的分类&…
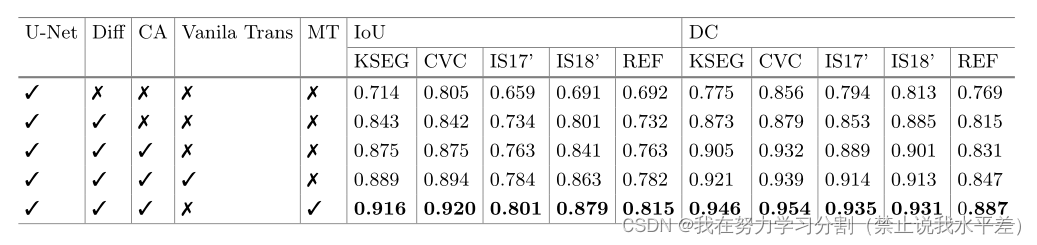
Diffusion Transformer U-Net for MedicalImage Segmentation
用于医学图像分割的扩散变压器U-Net
摘要:
扩散模型在各种发电任务中显示出其强大的功能。在将扩散模型应用于医学图像分割时,存在一些需要克服的障碍:扩散过程调节所需的语义特征与噪声嵌入没有很好地对齐;这些扩散模型中使用的U-Net骨干网对上下文信…

Quantitative Analysis: PIM Chip Demands for LLAMA-7B inference
1 Architecture
如果将LLAMA-7B模型参数量化为4bit,则存储模型参数需要3.3GB。那么,至少PIM chip 的存储至少要4GB。
AiM单个bank为32MB,单个die 512MB,至少需要8个die的芯片。8个die集成在一个芯片上。 提供816bank级别的访存带…

解读OpenAI视频生成模型Sora背后的原理:Diffusion Transformer
Diffusion Models视频生成-博客汇总 前言:OpenAI最近推出的视频生成模型Sora在效果上实现了真正的遥遥领先,很多博主都介绍过Sora,但是深入解读背后原理的博客却非常少。Sora的原理最主要的是核心模型主干《Scalable Diffusion Models with T…

【论文精读】BERT
摘要 以往的预训练语言表示应用于下游任务时的策略有基于特征和微调两种。其中基于特征的方法如ELMo使用基于上下文的预训练词嵌入拼接特定于任务的架构;基于微调的方法如GPT使用未标记的文本进行预训练,并针对有监督的下游任务进行微调。 但上述两种策略…
Transformer实战-系列教程15:DETR 源码解读2(整体架构:DETR类)
🚩🚩🚩Transformer实战-系列教程总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 点我下载源码 DETR 算法解读 DETR 源码解读1(项目配置/CocoDetection类/ConvertCocoP…
51-2 万字长文,深度解读端到端自动驾驶的挑战和前沿
去年初,我曾打算撰写一篇关于端到端自动驾驶的文章,发现大模型在自动驾驶领域的尝试案例并不多。遂把议题扩散了一点,即从大模型开始,逐渐向自动驾驶垂直领域靠近,最后落地到端到端。这样需要阐述的内容就变成LLM基础模…

CP04大语言模型ChatGLM3-6B特性代码解读(2)
CP04大语言模型ChatGLM3-6B特性代码解读(2) 文章目录 CP04大语言模型ChatGLM3-6B特性代码解读(2)构建对话demo_chat.py定义client对象与LLM进行对话 构建工具调用demo_tool.py定义client对象定义工具调用提示词定义main࿰…

时间序列预测实战(二十)自研注意力机制Attention-LSTM进行多元预测(结果可视化,自研结构)
一、本文介绍
本文给大家带来的是我利用我自研的结构进行Attention-LSTM进行时间序列预测,该结构是我专门为新手和刚入门的读者设计,包括结果可视化、支持单元预测、多元预测、模型拟合效果检测、预测未知数据、以及滚动长期预测,大家不仅可…
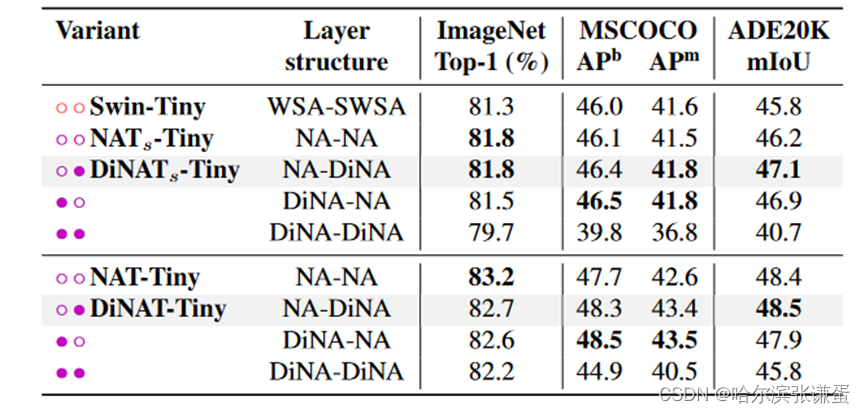
深度学习之图像分类(十五)DINAT: Dilated Neighborhood Attention Transformer详解(一)
Dilated Neighborhood Attention Transformer
Abstract Transformers 迅速成为跨模态、领域和任务中应用最广泛的深度学习架构之一。在视觉领域,除了对普通Transformer的持续努力外,分层Transformer也因其性能和易于集成到现有框架中而受到重视。这些模…

深度学习今年来经典模型优缺点总结,包括卷积、循环卷积、Transformer、LSTM、GANs等
文章目录 1、卷积神经网络(Convolutional Neural Networks,CNN)1.1 优点1.2 缺点1.3 应用场景1.4 网络图 2、循环神经网络(Recurrent Neural Networks,RNNs)2.1 优点2.2 缺点2.3 应用场景2.4 网络图 3、长短…
如何直观的理解Transformer模型
Transformer网络,自2017年由谷歌提出以来,因其在机器翻译上的卓越表现迅速在NLP领域崭露头角,吸引了广泛关注。尽管其复杂的结构对初学者而言可能令人望而生畏,但其背后的工作原理却充满了精彩之处。 Transformer的核心在于其编码…

【论文阅读】(DiTs)Scalable Diffusion Models with Transformers
(DiTs)Scalable Diffusion Models with Transformers 文章目录 (DiTs)Scalable Diffusion Models with Transformers论文概述Diffusion Transformers实验参考文献 引用: [1] Peebles W, Xie S. Scalable diffusion mod…

Transforer逐模块讲解
本文将按照transformer的结构图依次对各个模块进行讲解: 可以看一下模型的大致结构:主要有encode和decode两大部分组成,数据经过词embedding以及位置embedding得到encode的时输入数据
输入部分
embedding就是从原始数据中提取出单词或位置&…
【多模态】ALBEF
ALBEF 论文信息 标题:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation 作者:Junnan Li(Salesforce Research) 期刊:NeurIPS 2021 发布时间与更新时间:2021.07.16 2021.10.07 主题:多模态、预训练、图像、文本、对比学习、知…
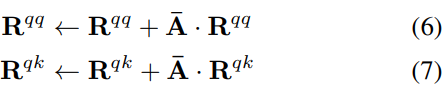
Transformer-MM-Explainability
two modalities are separated by the [SEP] token,the numbers in each attention module represent the Eq. number. E h _h h is the mean, ∇ \nabla ∇A : ∂ y t ∂ A {∂y_t}\over∂A ∂A∂ytfor y t y_t yt which is the model’s out…
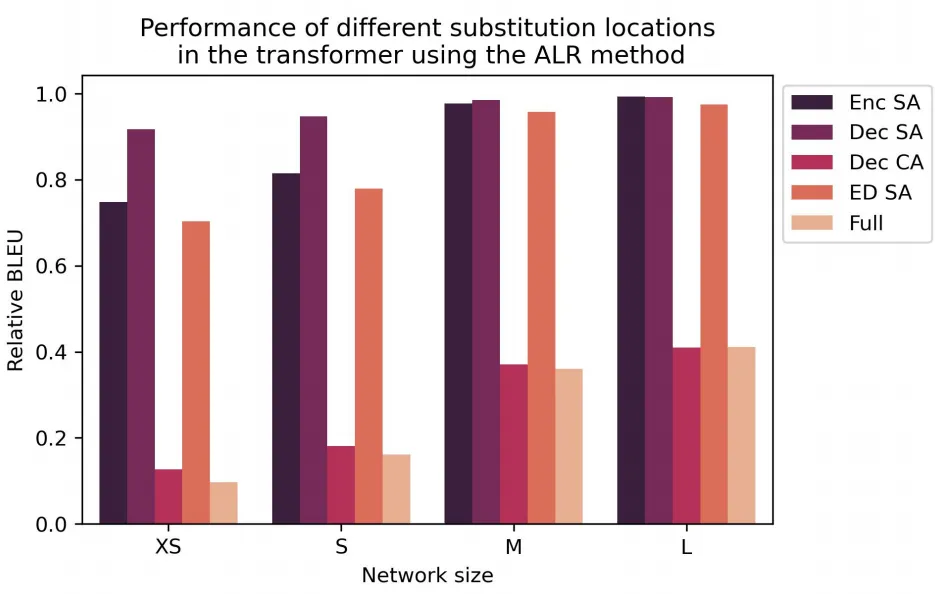
AAAI 2024|ETH轻量化Transformer最新研究,浅层MLP完全替换注意力模块提升性能
论文题目: Rethinking Attention: Exploring Shallow Feed-Forward Neural Networks as an Alternative to Attention Layers in Transformers 论文链接: https://arxiv.org/abs/2311.10642 代码仓库: GitHub - vulus98/Rethinking-attention…

Transformer - Attention is all you need 论文阅读
虽然是跑路来NLP,但是还是立flag说要做个project,结果kaggle上的入门project给的例子用的是BERT,还提到这一方法属于transformer,所以大概率读完这一篇之后,会再看BERT的论文这个样子。
在李宏毅的NLP课程中多次提到了…

BEV+Transformer感知架构共识下,传感器「火药味」再升级
高阶智能驾驶战火愈演愈烈,正带动感知方案卷入新一轮军备竞赛。
根据高工智能汽车研究院最新发布数据显示,2023年1-9月,中国市场(不含进出口)乘用车前装标配(软硬件)NOA交付新车37.73万辆&…
简单易懂的理解 PyTorch 中 Transformer 组件
目录
torch.nn子模块transformer详解
nn.Transformer
Transformer 类描述
Transformer 类的功能和作用
Transformer 类的参数
forward 方法
参数
输出
示例代码
注意事项
nn.TransformerEncoder
TransformerEncoder 类描述
TransformerEncoder 类的功能和作用
Tr…
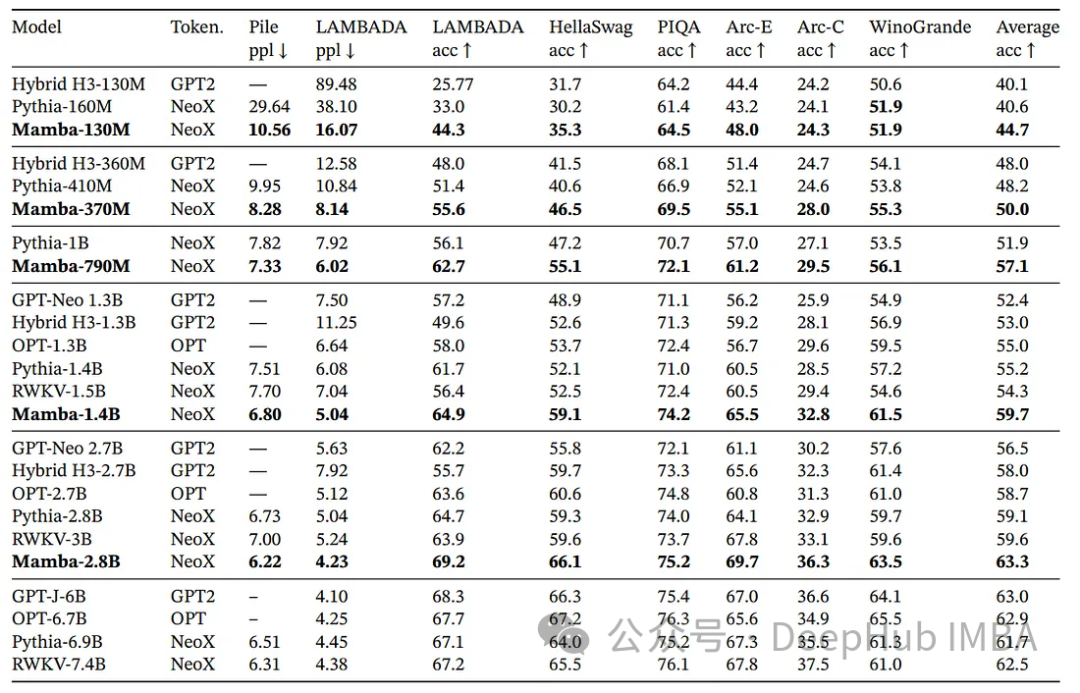
挑战Transformer的新架构Mamba解析以及Pytorch复现
今天我们来详细研究这篇论文“Mamba:具有选择性状态空间的线性时间序列建模” Mamba一直在人工智能界掀起波澜,被吹捧为Transformer的潜在竞争对手。到底是什么让Mamba在拥挤的序列建中脱颖而出?
在介绍之前先简要回顾一下现有的模型 Transformer:以其注意力机制而…

Transformer架构的局限已凸显,被取代还有多久?
江山代有才人出,各领风骚数百年。这句话无论是放在古往今来的人类身上,还是放在当今人工智能领域的大模型之上,都是最贴切不过的。无论是一个时代的伟人,还是统治一个领域的技术,最终都会有新的挑战者将其替代。Transf…
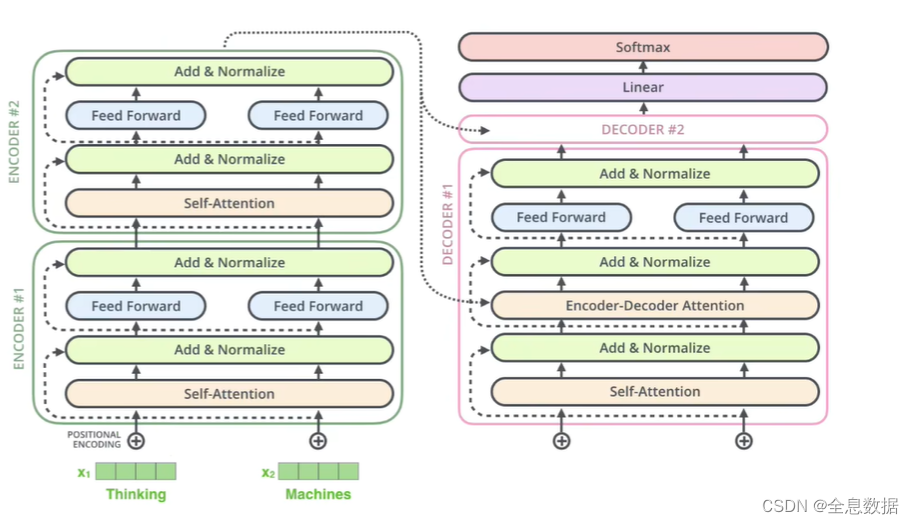
Transformer详解【学习笔记】
文章目录 1、Transformer绪论2、Encoders和Decoder2.1 Encoders2.1.1 输入部分2.1.2 多头注意力机制2.1.3 残差2.1.4 LayNorm(Layer Normalization)2.1.5 前馈神经网路 2.2 Decoder2.2.1 多头注意力机制2.2.2 交互层 1、Transformer绪论 Transformer在做…
RNN 和 Transformer 复杂度比较
这里假设BatchSize为 1,就是单样本的情况。
原始 RNN 块:
(1)单步计算 H,包含两个矩阵向量乘法,和一个激活,复杂度HidSize
(2)一共有SeqLen步,所以整体复杂…
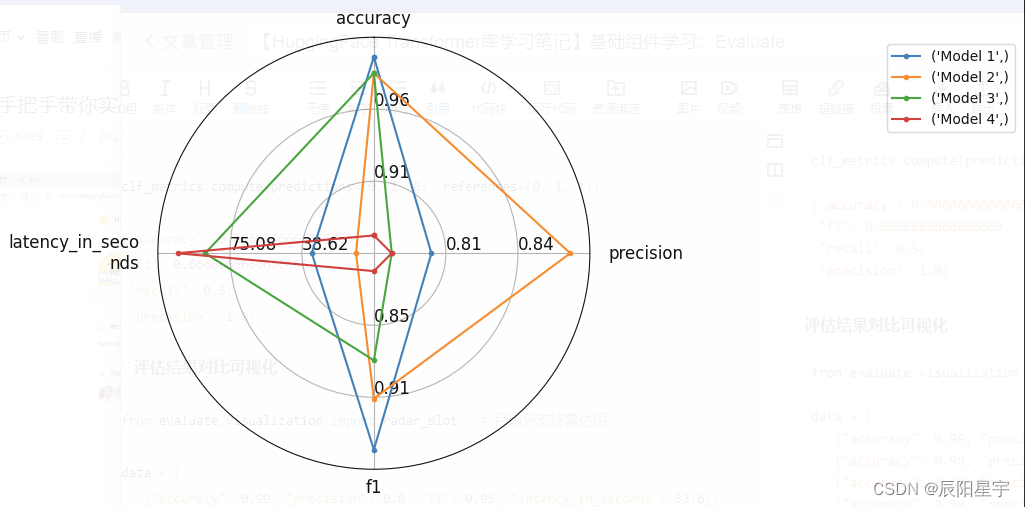
【HuggingFace Transformer库学习笔记】基础组件学习:Evaluate
基础组件学习——Evaluate Evaluate使用指南
查看支持的评估函数
# include_community:是否添加社区实现的部分
# with_details:是否展示更多细节
evaluate.list_evaluation_modules(include_communityFalse, with_detailsTrue)加载评估函数
accuracy…
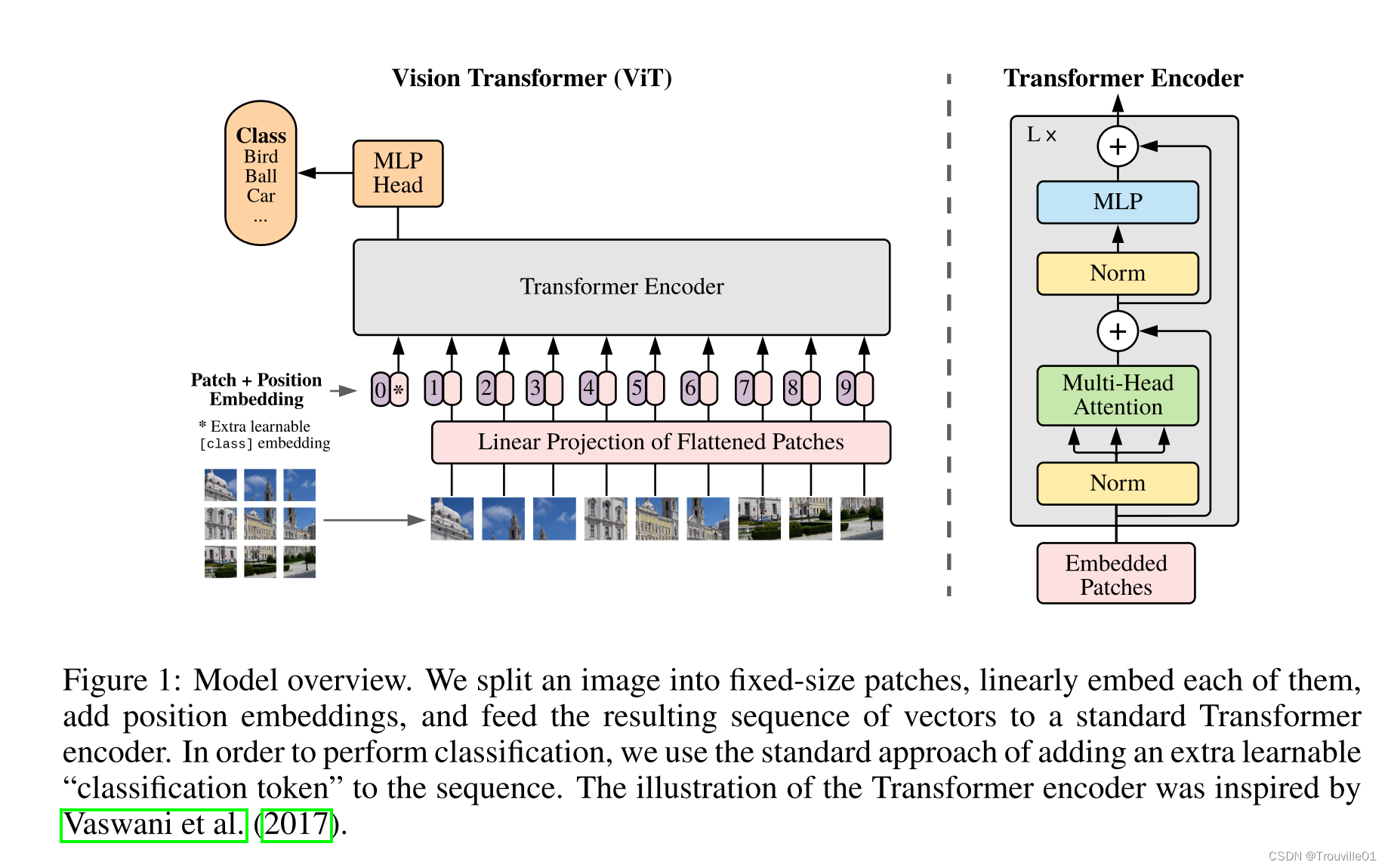
详解VIT(Vision Transformer)模型原理, 代码级讲解
一、学习资料链接准备
1. 首先提供原始论文,VIT(An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale)模型提出论文下载:VIT论文 ;
2.推荐的代码仓库,可以star我这个GitHub开源…
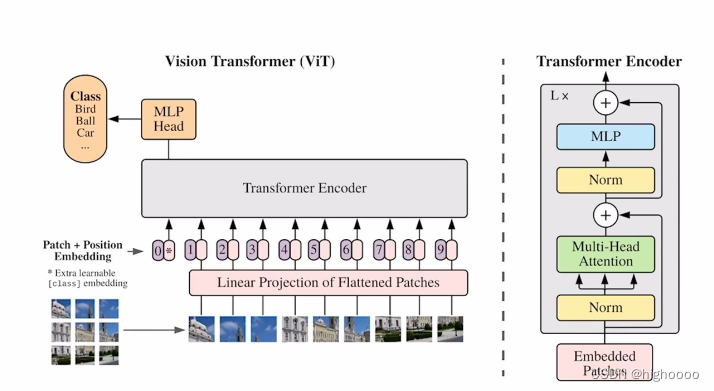
论文阅读 Vision Transformer - VIT
文章目录 1 摘要1.1 核心 2 模型架构2.1 概览2.2 对应CV的特定修改和相关理解 3 代码4 总结 1 摘要
1.1 核心
通过将图像切成patch线形层编码成token特征编码的方法,用transformer的encoder来做图像分类
2 模型架构
2.1 概览 2.2 对应CV的特定修改和相关理解
解…

Python数据分析案例33——新闻文本主题多分类(Transformer, 组合模型) 模型保存
案例背景
对于海量的新闻,我们可能需要进行文本的分类。模型构建很重要,现在对于自然语言处理基本都是神经网络的方法了。
本次这里正好有一组质量特别高的新闻数据,涉及 教育 科技 社会 时政 财经 房产 家居 七大主题,基本涵盖…
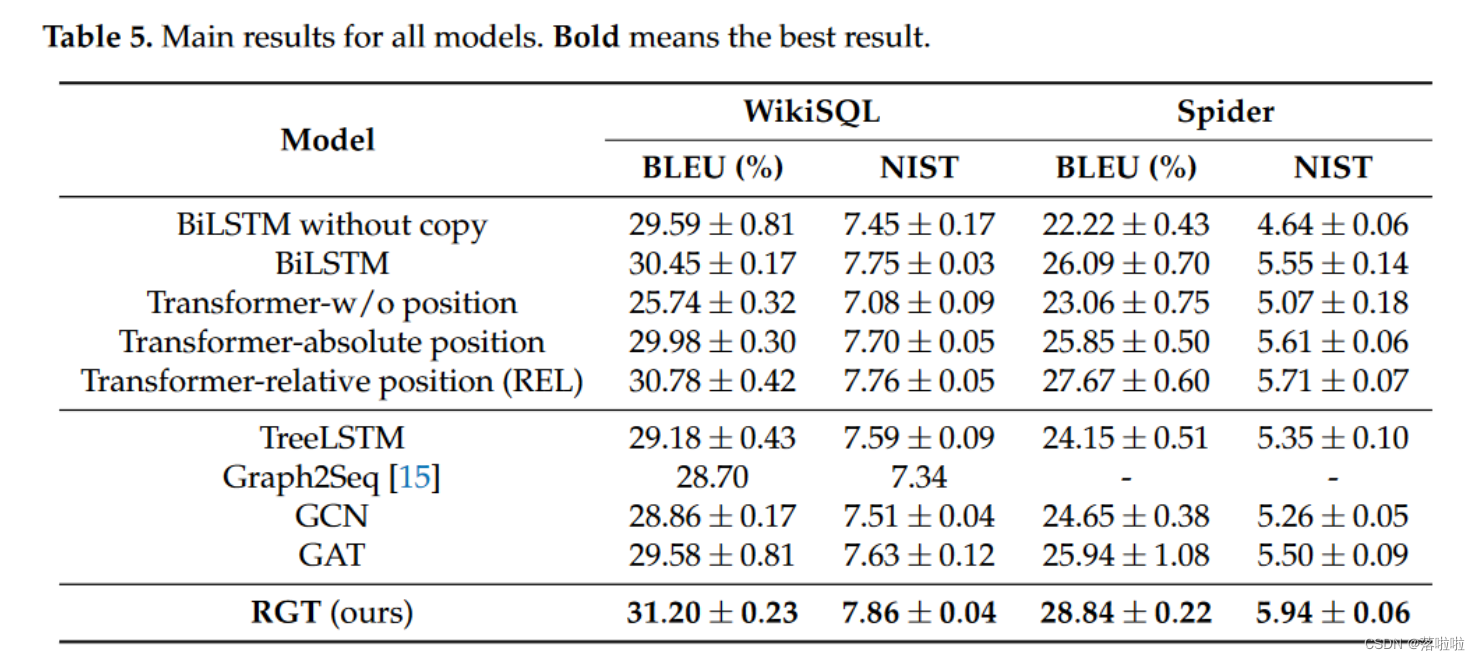
Relation-Aware Graph Transformer for SQL-to-Text Generation
Relation-Aware Graph Transformer for SQL-to-Text Generation
Abstract
SQL2Text 是一项将 SQL 查询映射到相应的自然语言问题的任务。之前的工作将 SQL 表示为稀疏图,并利用 graph-to-sequence 模型来生成问题,其中每个节点只能与 k 跳节点通信。由…
【论文阅读】Relation-Aware Graph Transformer for SQL-to-Text Generation
Relation-Aware Graph Transformer for SQL-to-Text Generation
Abstract
SQL2Text 是一项将 SQL 查询映射到相应的自然语言问题的任务。之前的工作将 SQL 表示为稀疏图,并利用 graph-to-sequence 模型来生成问题,其中每个节点只能与 k 跳节点通信。由…
基于FFT + CNN - Transformer 时域、频域特征融合的轴承故障识别模型
目录
往期精彩内容:
前言
1 快速傅里叶变换FFT原理介绍
2 轴承故障数据的预处理
2.1 导入数据
2.2 制作数据集和对应标签
3 基于FFTCNN-Transformer的轴承故障识别模型
3.1 网络定义模型
3.2 设置参数,训练模型
3.3 模型评估 往期精彩内容&…
YOLOv8优化策略:Backbone改进 | 支持restnet50和restnet101
🚀🚀🚀本文改进: 将restnet50和restnet101作为backbone引入到YOLOv8,下表为参数量和计算量的对比 layersparametersgradientsGFLOPsyolov8m2952585689925856883
Visual Saliency Transformer (VST) 源代码实现
1.论文信息
1.1论文标题:Visual Saliency Transformer (VST)
Nian Liu, Ni Zhang, Kaiyuan Wan, Junwei Han, and Ling Shao
1.2 Github源代码地址:https://github.com/nnizhang/VST
1.3论文下载链接:http://openaccess.thecvf.com/conte…

Transformer详解(附代码实现及翻译任务实现)
一:了解背景和动机 阅读Transformer论文: 阅读原始的Transformer论文:“Attention is All You Need”,由Vaswani等人于2017年提出,是Transformer模型的开创性工作。
二:理解基本构建块 注意力机制&#…
Transformer从菜鸟到新手(七)
引言
上篇文章加速推理的KV缓存技术,本文介绍让我们可以得到更好的BLEU分数的解码技术——束搜索。
束搜索
我们之前生成翻译结果的时候,使用的是最简单的贪心搜索,即每次选择概率最大的,但是每次生成都选择概率最大的并不一定…
![34、StoHisNet:CNN+Transformer结合首次用于胃病理图像4分类[奔狼怎配质疑雄狮!]](https://img-blog.csdnimg.cn/direct/22390d480e80497fa1909ba746a06bc8.jpeg)
34、StoHisNet:CNN+Transformer结合首次用于胃病理图像4分类[奔狼怎配质疑雄狮!]
本文由贵州大学医学院,贵州省人民医院医学影像教研室,精密影像诊疗国际示范合作基地,贵州大学计算机科学与技术学院,清华大学北京信息科学与技术国家研究中心,共同合作,于2022年5月28日发表于<Computer …

从CNN ,LSTM 到Transformer的综述
前情提要:文本大量参照了以下的博客,本文创作的初衷是为了分享博主自己的学习和理解。对于刚开始接触NLP的同学来说,可以结合唐宇迪老师的B站视频【【NLP精华版教程】强推!不愧是的最完整的NLP教程和学习路线图从原理构成开始学&a…
自然语言处理的技术进步与应用领域的拓展
文章目录
技术进步:推动NLP前行的关键技术
应用场景:NLP技术的实际应用
挑战与前景:NLP的未来发展
未来的发展趋势可能包括
总结 技术进步:推动NLP前行的关键技术
自然语言处理(NLP)是计算机科学和人…
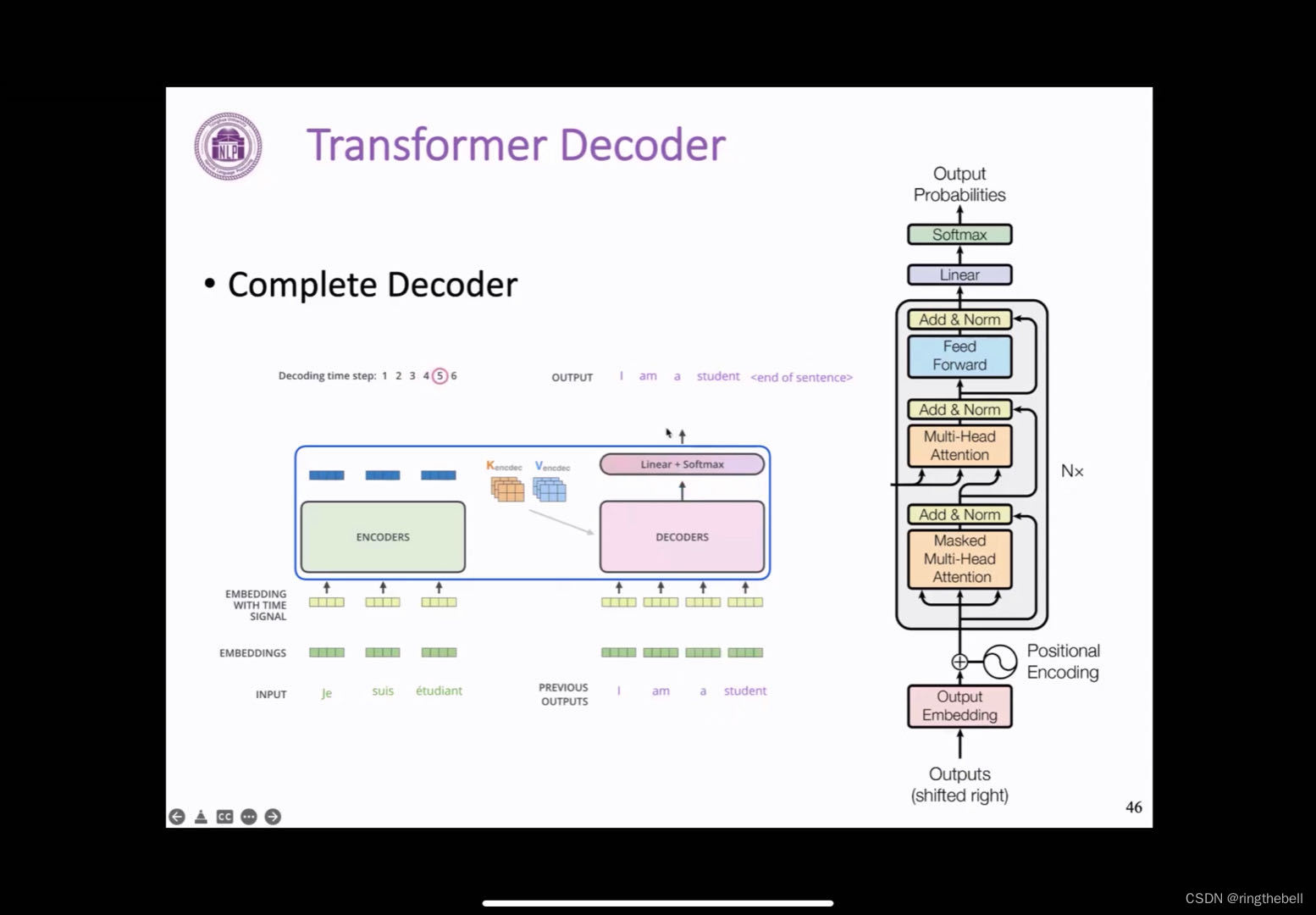
Transformer and Pretrain Language Models3-4
Transformer structure 模型结构
Transformer概述
首先回顾一下之前的RNN的一个端到端的模型,以下是一个典型的两层的LSTM模型,我们可以发现,这样一个RNN模型,一个非常重要的一个缺点就在于,它必须顺序地执行&#x…

DeformableAttention的原理解读和源码实现
本专栏主要是深度学习/自动驾驶相关的源码实现,获取全套代码请参考 目录 原理第一步看看输入:第二步,准备工作:生成参考点的偏移量生成参考点的权重生成参考点 第三步,工作: 源码 原理
目前流行3D转2DBEV方案的都绕不开的transfomer变体-DeformableAttention. 传统transform…
Transformer面试题总结101道
在本文中,我们将回答一系列关于Transformer的问题,涵盖了从基础概念到高级应用的多个方面。无论您是准备面试、学习深度学习,还是对自然语言处理技术感兴趣,都希望本文能为您提供有益的启示和知识。 注,本文的面试题借…
深入理解Transformer架构:从Seq2Seq到无监督预训练的演进
Transformer问答-2
根据我的了解,最开始Transformer的架构为encoderdecoder,是用于处理Seq2Seq任务的,后来GPT系列只采用decoder-only架构专注于next toke prediction任务,在我的认识当中,这两者都可以归为next toke …
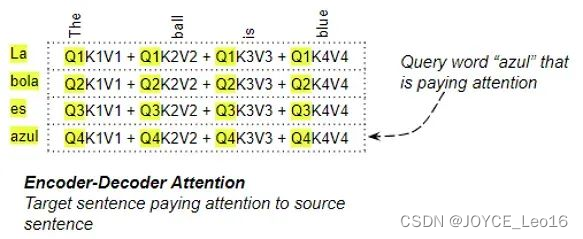
图解Transformer——注意力计算原理
文章目录 1、输入序列怎样传入注意力模块 2、进入注意力模块的矩阵的每一行,都是源序列中的一个词 3、每一行,都会经过一系列可学习的变换操作 4、如何得到注意力分数 5、Query、Key、Value的作用 6、点积:衡量向量之间的相似度 7、Transform…
VMD + CEEMDAN 二次分解,CNN-Transformer预测模型
往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较-CSDN博客
风速预测(一)数据集介绍和预处理-CSDN博客
风速预测(二)基于Pytorch的EMD-LSTM模型-CSDN博客
风速预测ÿ…
【NLP9-Transformer经典案例】
Transformer经典案例
1、语言模型
以一个符合语言规律的序列为输入,模型将利用序列间关系等特征,输出在一个在所有词汇上的概率分布,这样的模型称为语言模型。
2、语言模型能解决的问题
根据语言模型定义,可以在它的基础上完成…
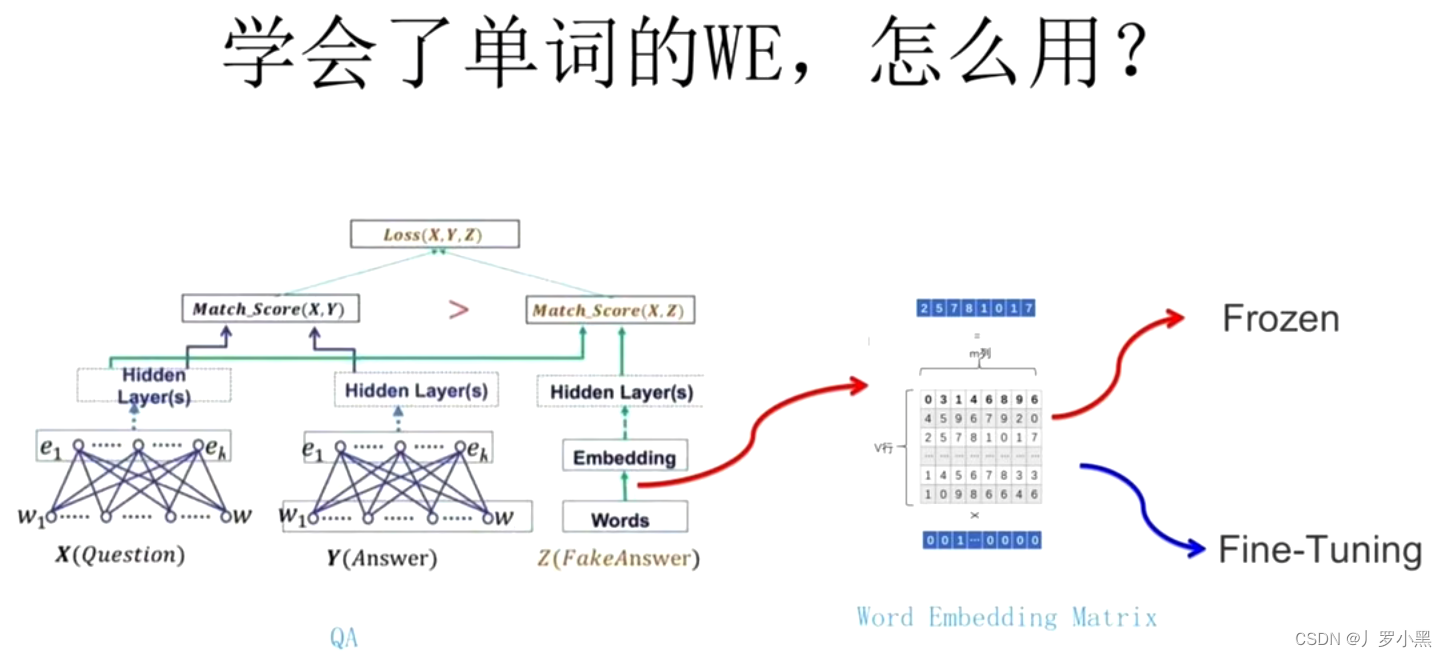
Transformer的前世今生 day03(Word2Vec、如何使用在下游任务中)
前情回顾
由上一节,我们可以得到: 任何一个独热编码的词都可以通过Q矩阵得到一个词向量,而词向量有两个优点: 可以改变输入的维度(原来是很大的独热编码,但是我们经过一个Q矩阵后,维度就可以控…
DFormer: Diffusion-guided Transformer for UniversalImage Segmentation
DFormer:用于通用图像分割的扩散引导transformer
摘要:本文介绍了一种通用的图像分割方法DFormer。所提出的DFormer将通用图像分割任务视为一个使用扩散模型的去噪过程。DFormer首先将不同级别的高斯噪声添加到地面真实掩码中,然后学习一个模型来预测从损坏的掩码中去除噪声…
Combining external-latent attention for medical image segmentation
结合外部潜在注意的医学图像分割
摘要
注意机制是提高医学图像分割性能的新切入点。如何合理分配权重是注意力机制的关键,目前流行的方法包括全局压缩和使用自注意操作的非局部信息交互。然而,这些方法过于关注外部特征,缺乏对潜在特征的开发。全局压缩方法通过全局均值或…

【NLP笔记】Transformer
文章目录 基本架构EmbeddingEncoderself-attentionMulti-Attention残差连接LayerNorm DecoderMask&Cross Attention线性层&softmax损失函数 论文链接:
Attention Is All You Need 参考文章:
【NLP】《Attention Is All You Need》的阅读笔记 一…
深度学习PyTorch 之 transformer-中文多分类
transformer的原理部分在前面基本已经介绍完了,接下来就是代码部分,因为transformer可以做的任务有很多,文本的分类、时序预测、NER、文本生成、翻译等,其相关代码也会有些不同,所以会分别进行介绍
但是对于不同的任务…

Transformer位置编码(Position Embedding)理解
本文主要介绍4种位置编码,分别是NLP发源的transformer、ViT、Sw-Transformer、MAE的Position Embedding 一、NLP transformer
使用的是1d的绝对位置编码,使用sincos将每个token编码为一个向量【硬编码】 Attention Is All You Need 在语言中࿰…

【NLP】多头注意力(Multi-Head Attention)的概念解析
一. 多头注意力
多头注意力(Multi-Head Attention)是一种在Transformer模型中被广泛采用的注意力机制扩展形式,它通过并行地运行多个独立的注意力机制来获取输入序列的不同子空间的注意力分布,从而更全面地捕获序列中潜在的多种语…
【深度学习】NestedTensors
文章目录 NestedTensorsWhy NestedTensor初始化 NestedTensorNestedTensor 操作reshape转置查看维度其他 NestedTensors
DETR 中常见的数据格式为 NestedTensors,那么什么是 NestedTensors 呢? NestedTensor,包括 tensor 和 mask 两个成员&a…
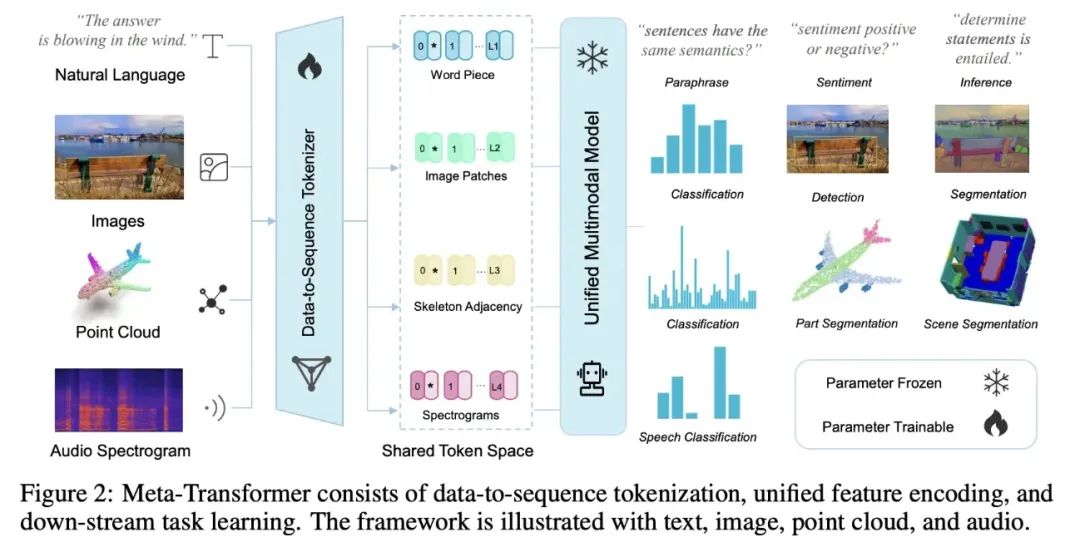
浅析多模态大模型技术路线梳理
前段时间 ChatGPT 进行了一轮重大更新:多模态上线,能说话,会看图!微软发了一篇长达 166 页的 GPT-4V 测评论文,一时间又带起了一阵多模态的热议,随后像是 LLaVA-1.5、CogVLM、MiniGPT-5 等研究工作紧随其后…
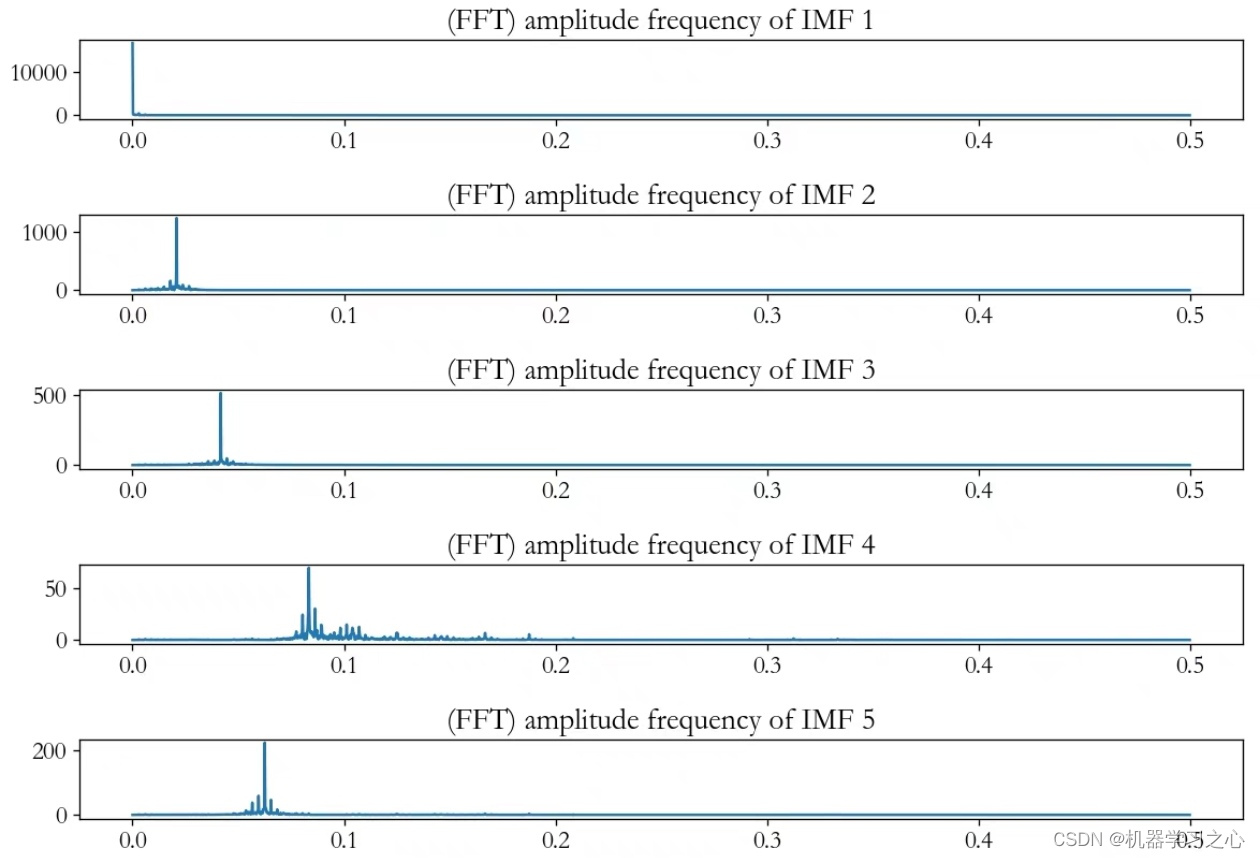
风速预测 | Python基于CEEMDAN-CNN-Transformer+ARIMA的风速时间序列预测
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 CEEMDAN-CNN-TransformerARIMA是一种用于风速时间序列预测的模型,结合了不同的技术和算法。收集风速时间序列数据,并确保数据的质量和完整性。这些数据通常包括风速的观测值和时间戳。CEEMDAN分…

mask transformer相关论文阅读
前面讲了mask-transformer对医学图像分割任务是非常适用的。本文就是总结一些近期看过的mask-transformer方面的论文。 因为不知道mask transformer是什么就看了一些论文。后来得出结论,应该就是生成mask的transformer就是mask transformer。 相关论文: …
手搓 国内首个非Attention大模型,训练效率7倍于Transformer
手搓 国内首个非Attention大模型,训练效率7倍于Transformer 非Attention大模型代码解析非Attention大模型代码
import torchclass FeedForward(torch.nn.Module):def __init__(self, hidden_dim):super

预训练语言模型transformer
预训练语言模型的学习方法有三类:自编码(auto-encode, AE)、自回归(auto regressive, AR),Encoder-Decoder结构。 决定PTM模型表现的真正原因主要有以下几点:
更高质量、更多数量的预训练数据增加模型容量…

OJAC近屿智能张立赛博士揭秘GPT Store:技术创新、商业模式与未来趋势
Look!👀我们的大模型商业化落地产品📖更多AI资讯请👉🏾关注Free三天集训营助教在线为您火热答疑👩🏼🏫 亲爱的伙伴们: 1月31日晚上8:30,由哈尔滨工业大学的…
Transformer模型 | Pytorch实现Transformer模型进行时间序列预测
Transformer模型最初是为了处理自然语言处理任务而设计的,但它也可以用于时间序列预测。下面是将Transformer模型应用于时间序列预测的一般步骤:
数据准备:准备时间序列数据集,包括历史观测值和目标预测值。通常,你需要将时间序列转换为固定长度的滑动窗口序列,以便输入…
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】Transformer
目录 什么是 Transformer?
什么是注意力机制?
Transformer编码器 位置编码
Transformer的PyTorch实现之若干问题探讨(一)
《Transformer的PyTorch实现》这篇博文以一个机器翻译任务非常优雅简介的阐述了Transformer结构。在阅读时存在一些小困惑,此处权当一个记录。
1.自定义数据中enc_input、dec_input及dec_output的区别
博文中给出了两对德语翻译成英语的例子:
# S: de…
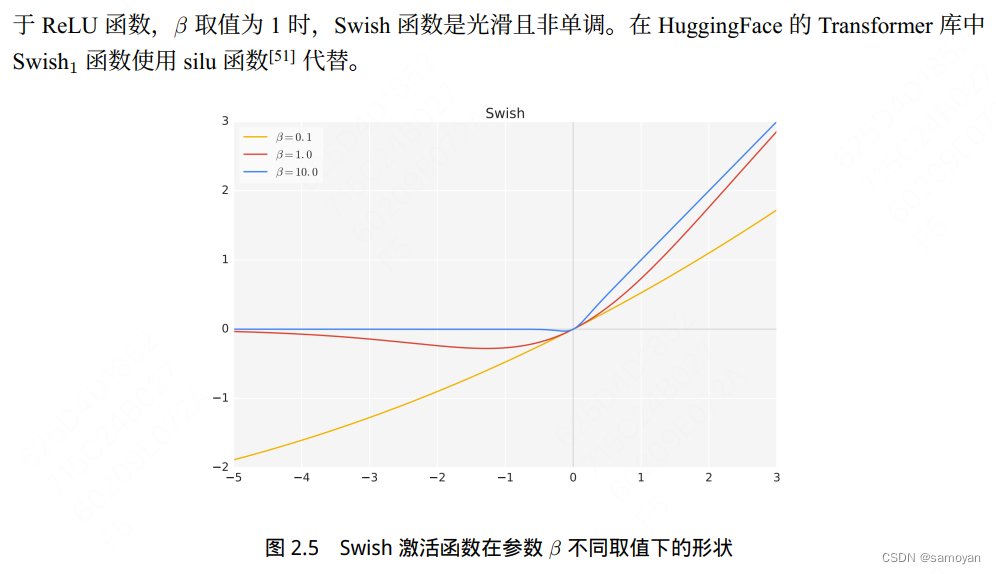
LLaMA 模型中的Transformer架构变化
目录
1. 前置层归一化(Pre-normalization)
2. RMSNorm 归一化函数
3. SwiGLU 激活函数
4. 旋转位置嵌入(RoPE)
5. 注意力机制优化
6. Group Query Attention
7. 模型规模和训练超参数
8. 分布式模型训练
前置归一化与后置…

Vision Transformer(二):位置嵌入向量
1. 什么是位置嵌入向量
位置嵌入向量是Transformer兴起时就引入的一个概念。早期在处理文本信息时,词语之间是相关联的,只有具有一定位置关系的词语组合才能够表达一些正确的意思。
2. 在Transformer中是如何实现的?
在Transformer的训练过…
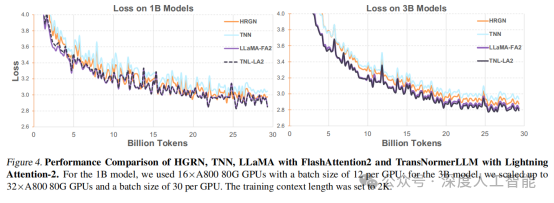
大模型基础架构的变革:剖析Transformer的挑战者(下)
上一篇文章中,我们介绍了UniRepLKNet、StripedHyena、PanGu-π等有可能会替代Transformer的模型架构,这一篇文章我们将要介绍另外三个有可能会替代Transformer的模型架构,它们分别是StreamingLLM、SeTformer、Lightning Attention-2ÿ…
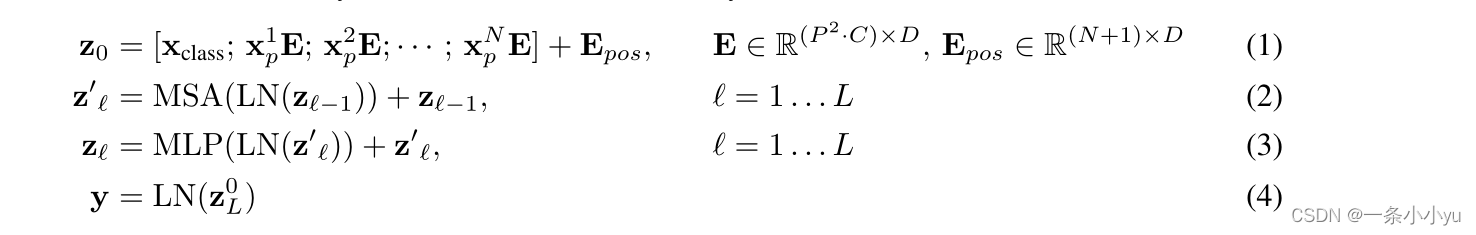
关于VIT(Vision Transformer)的架构记录
在VIT模型设计中,尽可能地紧密遵循原始的Transformer模型(Vaswani等人,2017年)。这种刻意简化的设置的一个优势是,可扩展的NLP Transformer架构及其高效的实现几乎可以即插即用。 图:模型概述。我们将图像分…

Encoder-decoder 与Decoder-only 模型之间的使用区别
承接上文:Transformer Encoder-Decoer 结构回顾 笔者以huggingface T5 transformer 对encoder-decoder 模型进行了简单的回顾。
由于笔者最近使用decoder-only模型时发现,其使用细节和encoder-decoder有着非常大的区别;而huggingface的接口为…
Transformer:Attention机制、前馈神经网络、编码器与解码器
主要介绍Transformer的一些工作原理与优势。 文章目录 Transformer中的Attention机制 一、引言 二、Transformer中的Attention机制 1. 背景介绍 2. 工作原理 3. 优势分析 Transformer中的前馈神经网络 一、引言 二、神经网络的基本概念 三、前馈神经网络 四、Transformer中的前…
【文生视频】Diffusion Transformer:OpenAI Sora 原理、Stable Diffusion 3 同源技术
文生视频 Diffusion Transformer:Sora 核心架构、Stable Diffusion 3 同源技术 提出背景变换器的引入Diffusion Transformer (DiT)架构Diffusion Transformer (DiT)总结 OpenAI Sora 设计思路阶段1: 数据准备和预处理阶段2: 架构设计阶段3: 输入数据的结构化阶段4: …

GPT 的基础 - T(Transformer)
我们知道GPT的含义是: Generative - 生成下一个词 Pre-trained - 文本预训练 Transformer - 基于Transformer架构
我们看到Transformer模型是GPT的基础,这篇博客梳理了一下Transformer的知识点。 BERT: 用于语言理解。(Transformer的Encoder…
大语言模型系列-微调技术
前言
以BERT模型为代表的“预训练语言模型 下游任务微调”训练模式成为了自然语言处理研究和应用的新范式。此处的下游任务微调是基于模型全量参数进行微调(全量微调)。
以 GPT3 为代表的预训练语言模型(PLM)参数规模变得越来越…
Transformer之Residuals Decoder
The Residuals
我们需要提到的编码器架构中的一个细节是,每个编码器中的每个子层(self-attention,,ffnn)周围都有一个残余连接,然后是 layer-normalization 步骤。 如果我们要可视化向量和与 self attention 相关的 layer-norm 运算&#x…
Transformer机器翻译模型(代码实现案例)
目标
了解有关机器翻译的知识了解seq2seq架构使用Transformer构建机器翻译模型的实现过程
1 Transformer架构
Transformer模型架构分析
Transformer模型架构, 大范围内包括两部分分别是encoder(编码器)和decoder(解码器), 编码器和解码器的内部实现都使用了注意力机制实现,…

大模型之SORA技术学习
文章目录 sora的技术原理文字生成视频过程sora的技术优势量大质优的视频预训练库算力多,采样步骤多,更精细。GPT解释力更强,提示词(Prompt)表现更好 使用场景参考 Sora改变AI认知方式,开启走向【世界模拟器】的史诗级的…

LLM 推理优化探微 (2) :Transformer 模型 KV 缓存技术详解
编者按:随着 LLM 赋能越来越多需要实时决策和响应的应用场景,以及用户体验不佳、成本过高、资源受限等问题的出现,大模型高效推理已成为一个重要的研究课题。为此,Baihai IDP 推出 Pierre Lienhart 的系列文章,从多个维…

ChatGPT预训练的奥秘:大规模数据、Transformer架构与自回归学习【文末送书-31】
文章目录 ChatGPT原理与架构ChatGPT的预训练ChatGPT的迁移学习ChatGPT的中间件编程 ChatGPT原理与架构:大模型的预训练、迁移和中间件编程【文末送书-31】 ChatGPT原理与架构
近年来,人工智能领域取得了巨大的进展,其中自然语言处理…

【Pytorch】论文复现 Vision Transformer (ViT)
文章目录 0. 进行设置1. 获取数据2. 创建Dataset和DataLoader3. 复现 ViT 论文:概述4. Equation 1: 将数据拆分为 patch 并创建类、位置和 patch 嵌入5. Equation 2: Multi-Head Attention (MSA)6. Equation 3: Multilayer Perceptron (MLP)7. 创建 Transformer 编码…

Transformer中的FeedForward
Transformer中的FeedForward
flyfish
class PoswiseFeedForwardNet(nn.Module):def __init__(self, d_ff2048):super(PoswiseFeedForwardNet, self).__init__()# 定义一维卷积层 1,用于将输入映射到更高维度self.conv1 nn.Conv1d(in_channelsd_embedding, out_ch…
深度学习中的Attention机制
深度学习中的Attention机制 一、Encoder-Decoder框架二、Attention机制(1) Soft Attention模型(2) Attention机制的本质思想(3) Self Attention模型(4) Attention机制的应用 一、Encoder-Decoder框架
Encoder-Decoder框架是一种深度学习领域的研究模式,应用场景异常…
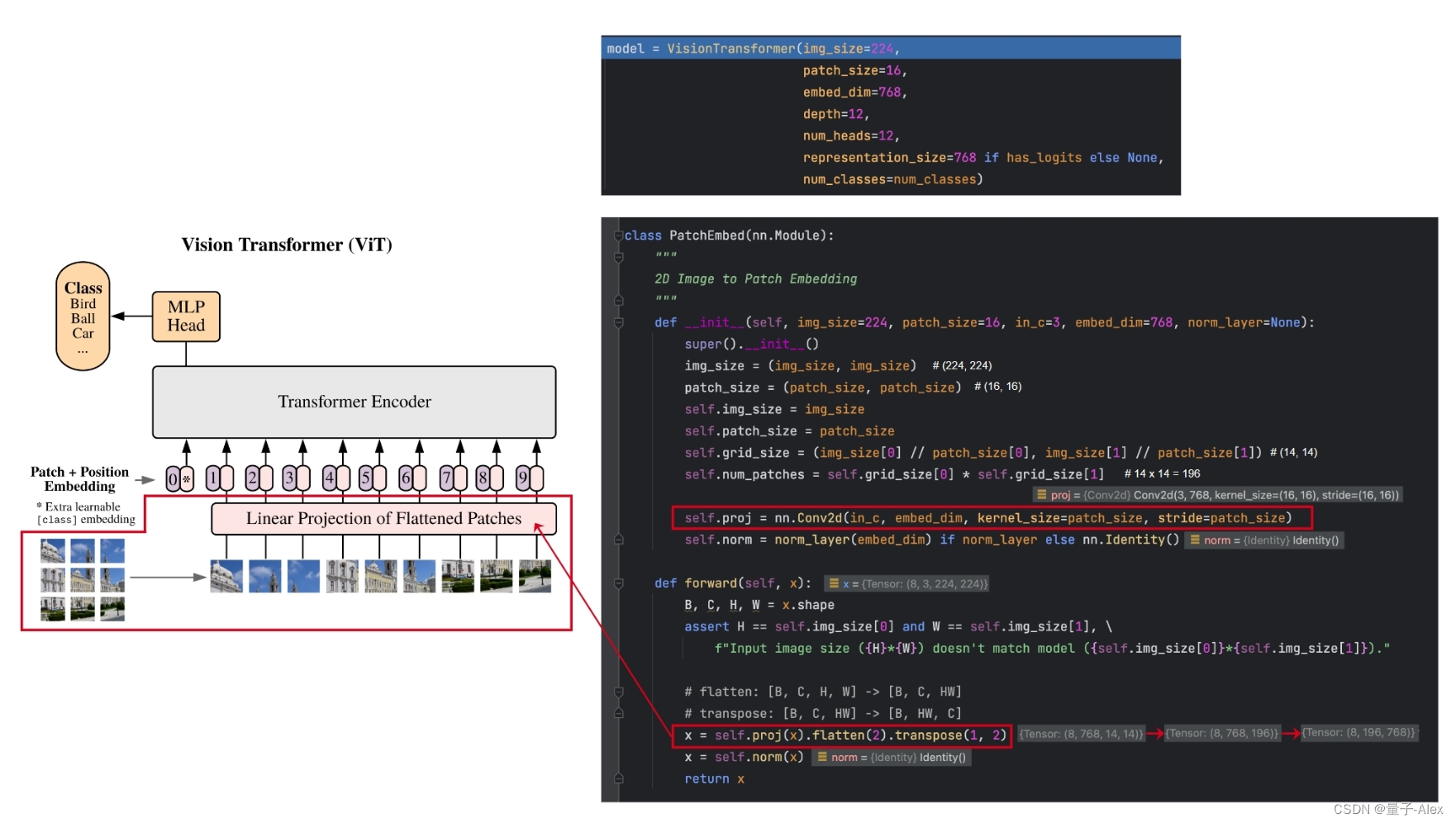
【ViT】Vision Transformer的实现01 patch embedding
对于224*224的图像,将它输入到Transformer里面,就需要将图像展开成一系列的token, 如果逐像素视为token进行注意力的计算,难免计算量太大,因此一个更加合理的想法是将图像划分为一个个的patch 将每个patch进行embeddin…
Transformer的前世今生 day06(Self-Attention和RNN、LSTM的区别)
Self-Attention和RNN、LSTM的区别
RNN的缺点:无法做长序列,当输入很长时,最后面的输出很难参考前面的输入,即长序列会缺失上文信息,如下: 可能一段话超过50个字,输出效果就会很差了 LSTM通过忘…
Transformer的前世今生 day10(Transformer编码器、解码器)
前情提要
ResNet(残差网络)
由于我们加更多层,更复杂的模型并不总会改进精度,可能会让模型与真实值越来越远,如下: 我们想要实现,加上一个层把并不会让模型变复杂,即没有它也没关系…
【论文阅读笔记】Activating More Pixels in Image Super-Resolution Transformer
论文地址:https://arxiv.org/abs/2205.04437 代码位置:https://github.com/XPixelGroup/HAT
论文小结 本文方法是基于Transformer的方法,探索了Transformer在低级视觉任务(如SR)中的应用潜力。本文提升有效利用像素范…
![[nlp入门论文精读] | Transformer](https://img-blog.csdnimg.cn/direct/559a85a143524ae793f96e61e3f1c580.png)
[nlp入门论文精读] | Transformer
写在前面 最近工作从CV转向了NLP,于是空余时间便跟着哔哩哔哩李沐老师的视频学习。其实研一NLP课程讲论文的时候,我们小组就选择了经典的Attention和Bert,但还有很多细节并不完全理解,实际使用时也很困惑。 因此这个系列就来记…

TEASEL: A transformer-based speech-prefixed language model
文章目录 TEASEL:一种基于Transformer的语音前缀语言模型文章信息研究目的研究内容研究方法1.总体框图2.BERT-style Language Models(基准模型)3.Speech Module3.1Speech Temporal Encoder3.2Lightweight Attentive Aggregation (LAA) 4.训练…

机器学习--Transformer 2
紧接上篇介绍一下Transformer的解码器
一、解码器
1.自回归解码器 以语音识别为例,输入一段声音,输出一串文字。如上图所示,把一段声音(“机器学习”)输入给编码器,输出会变成一排向量。解码器把编码器的…
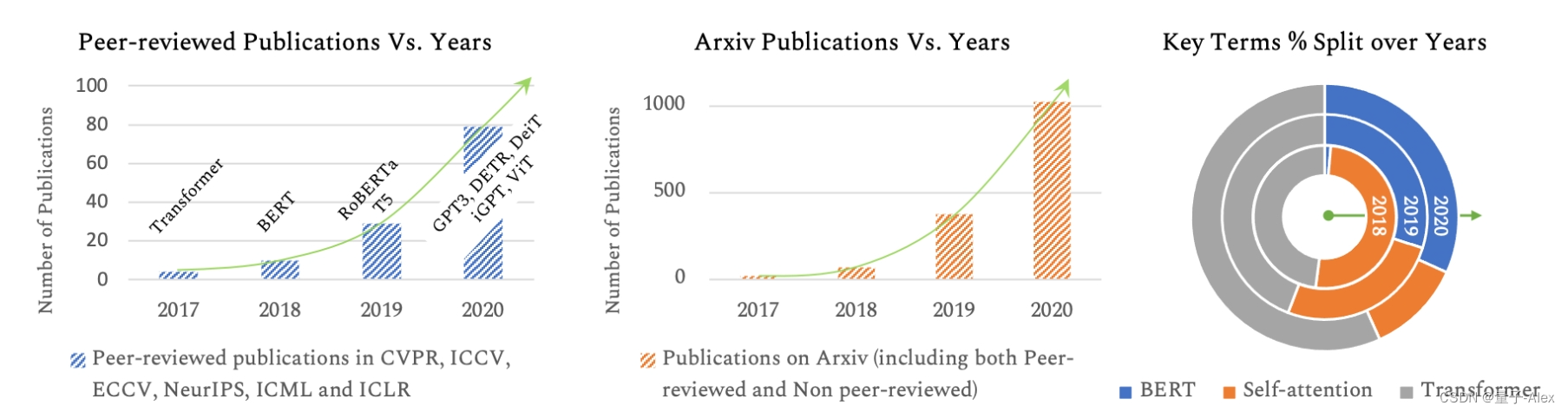
【CV论文阅读】【计算机视觉中的Transformer应用综述】(1)
0.论文摘要
摘要——自然语言任务的Transformer model模型的惊人结果引起了视觉社区的兴趣,以研究它们在计算机视觉问题中的应用。在它们的显著优点中,与递归网络例如长短期记忆(LSTM)相比,Transformer能够模拟输入序…

Transformer模型引领NLP革新之路
在不到4 年的时间里,Transformer 模型以其强大的性能和创新的思想,迅速在NLP 社区崭露头角,打破了过去30 年的记录。BERT、T5 和GPT 等模型现在已成为计算机视觉、语音识别、翻译、蛋白质测序、编码等各个领域中新应用的基础构件。因此&#…
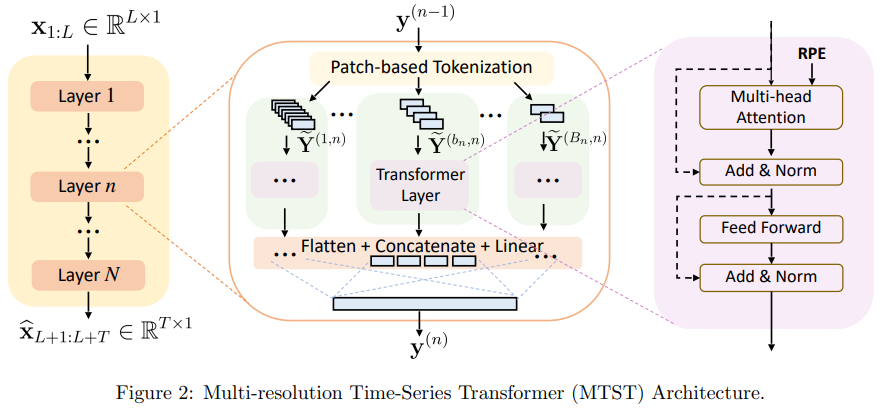
超越Transformer!基于Patch的时间序列预测新SOTA!
目前基于深度学习的时间序列预测主要有两大创新方向:一是模型结构创新,以informer为代表;二是数据输入创新,以PatchTST为代表。
在多变量时序预测领域,Patch的使用是为了将时间序列数据转换成适合深度学习模型处理的形…
为什么要使用注意力机制?
通过注意力机制,网络的文本生成解码器部分能够有选择地访问所有输入标记,这意味着某些输入标记在生成特定输出标记时比其他输入标记更重要。
具体来说:
提高模型的焦点:注意力机制允许模型在处理信息时“关注”到更重要的部分。…
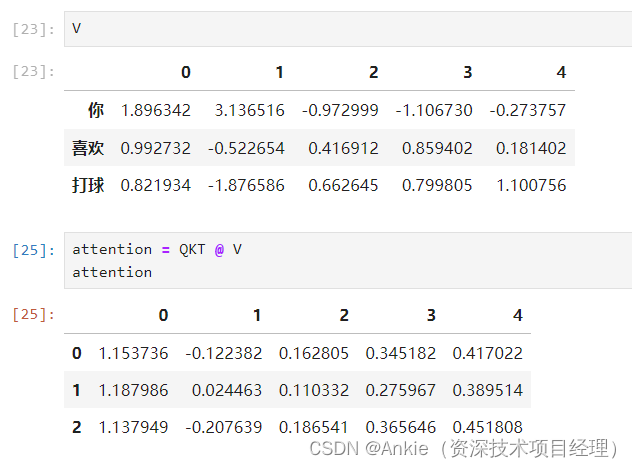
学习transformer模型-用jupyter演示逐步计算attention
学习transformer模型-用jupyter演示如何计算attention,不含multi-head attention,但包括权重矩阵W。
input embedding:文本嵌入
每个字符用长度为5的向量表示: 注意力公式: 1,准备Q K V: 先 生…
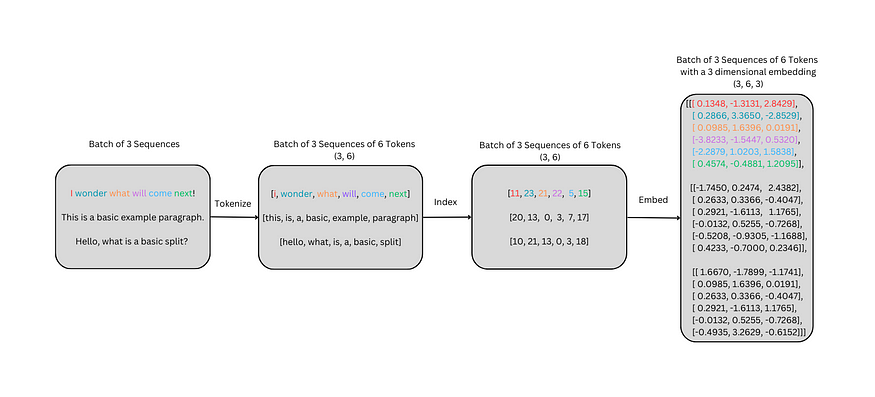
学习transformer模型-Input Embedding 嵌入层的简明介绍
今天介绍transformer模型的Input Embedding 嵌入层。 背景 嵌入层的目标是使模型能够更多地了解单词、标记或其他输入之间的关系。 从头开始嵌入Embeddings from Scratch 嵌入序列需要分词器tokenizer、词汇表和索引,以及词汇表中每个单词的三维嵌入。Embedding a s…
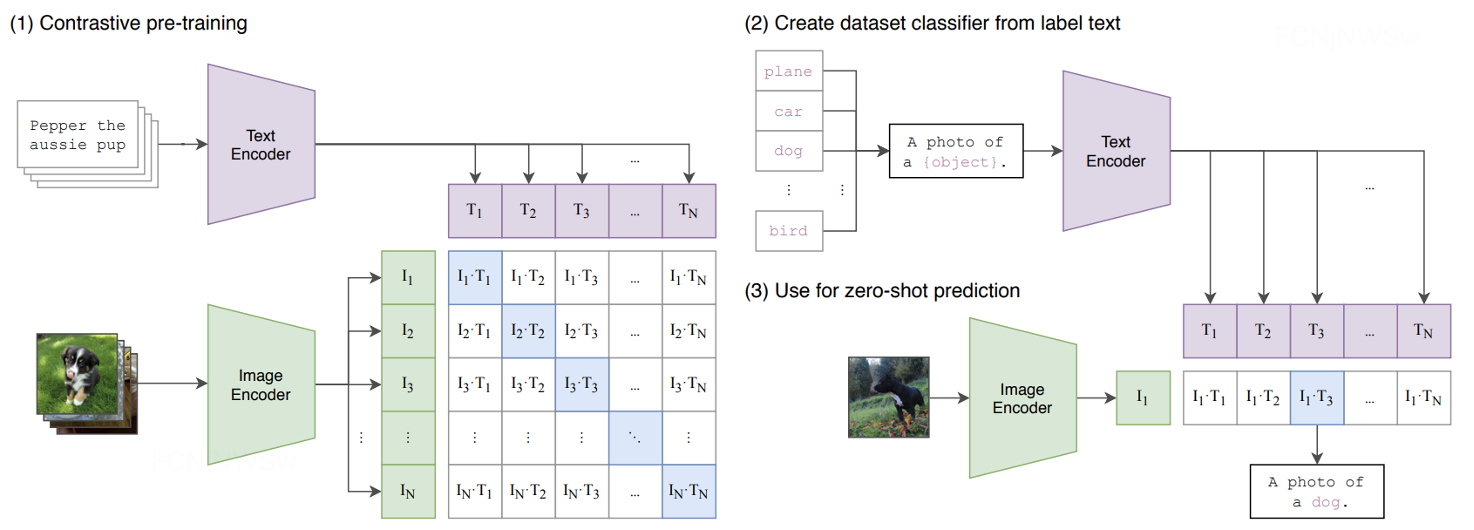
文生图大模型三部曲:DDPM、LDM、SD 详细讲解!
1、引言
跨模态大模型是指能够在不同感官模态(如视觉、语言、音频等)之间进行信息转换的大规模语言模型。当前图文跨模态大模型主要有: 文生图大模型:如 Stable Diffusion系列、DALL-E系列、Imagen等 图文匹配大模型:如CLIP、Chinese CLIP、…
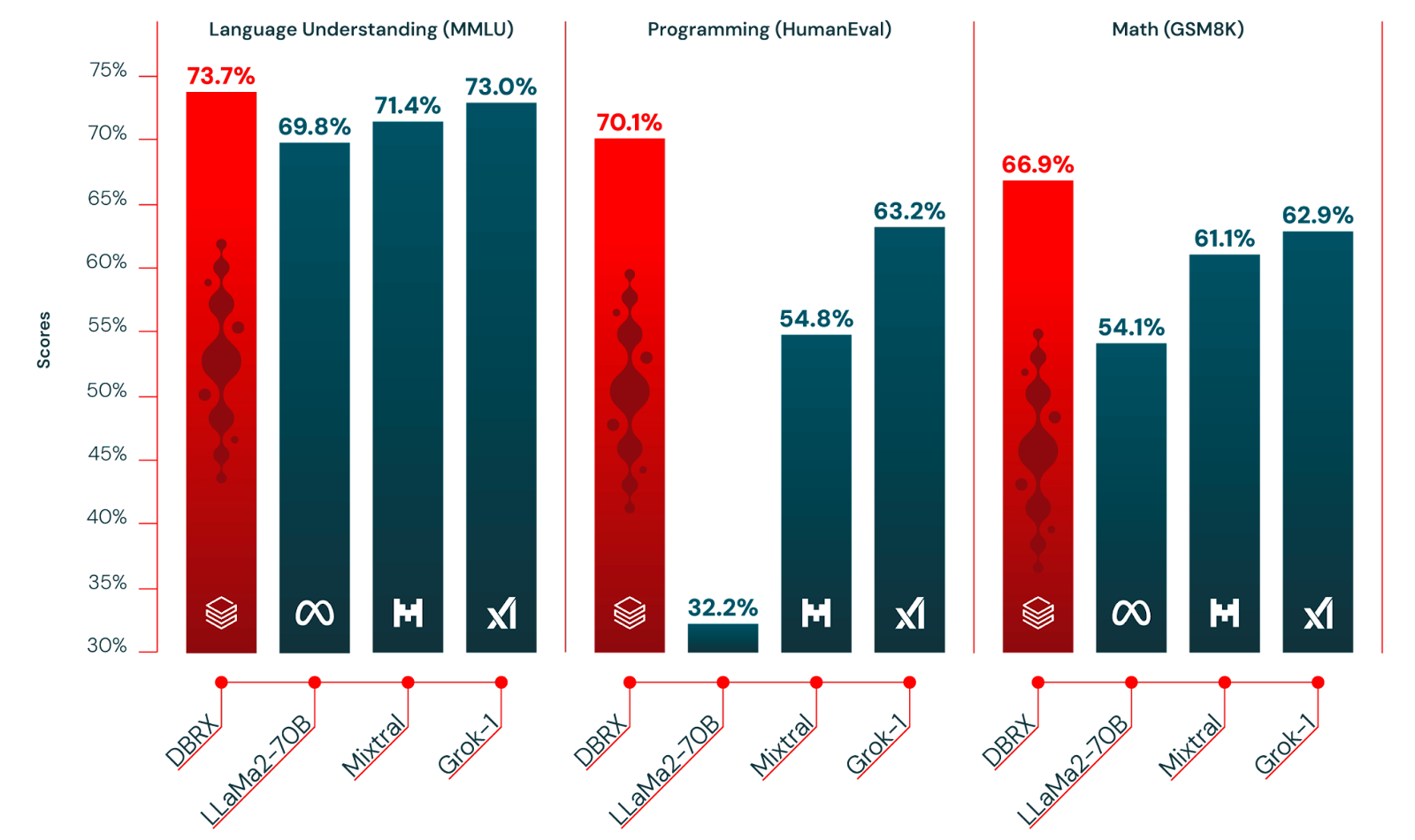
结合Transformer与Mamba,Jamba来了!
B站:啥都会一点的研究生公众号:啥都会一点的研究生
近期AI相关资讯,一起看看吧~
X 的 Grok 得到重大升级
马斯克的人工智能初创公司X.ai推出了Grok-1.5,是Grok聊天机器人的升级版AI模型。该新版本增强了推理能力,特…

五倍吞吐量,性能全面包围 Transformer:新架构 Mamba 引爆AI圈
屹立不倒的 Transformer 迎来了一个强劲竞争者。 在别的领域,如果你想形容一个东西非常重要,你可能将其形容为「撑起了某领域的半壁江山」。但在 AI 大模型领域,Transformer 架构不能这么形容,因为它几乎撑起了「整个江山」。
自…

R2GenCMN中的Encoder_Decoder结构
R2GenCMN中的 Encoder_Decoder 结构
Encoder_Decoder 结构直接关系到文本的生成,它结构参考的transformer的结构 我们这里主要看代码的实现,从视觉编码器的输出开始
1. 模型结构
首先介绍一下整体结构,这里的baseCMN其实就是一个包装了的T…
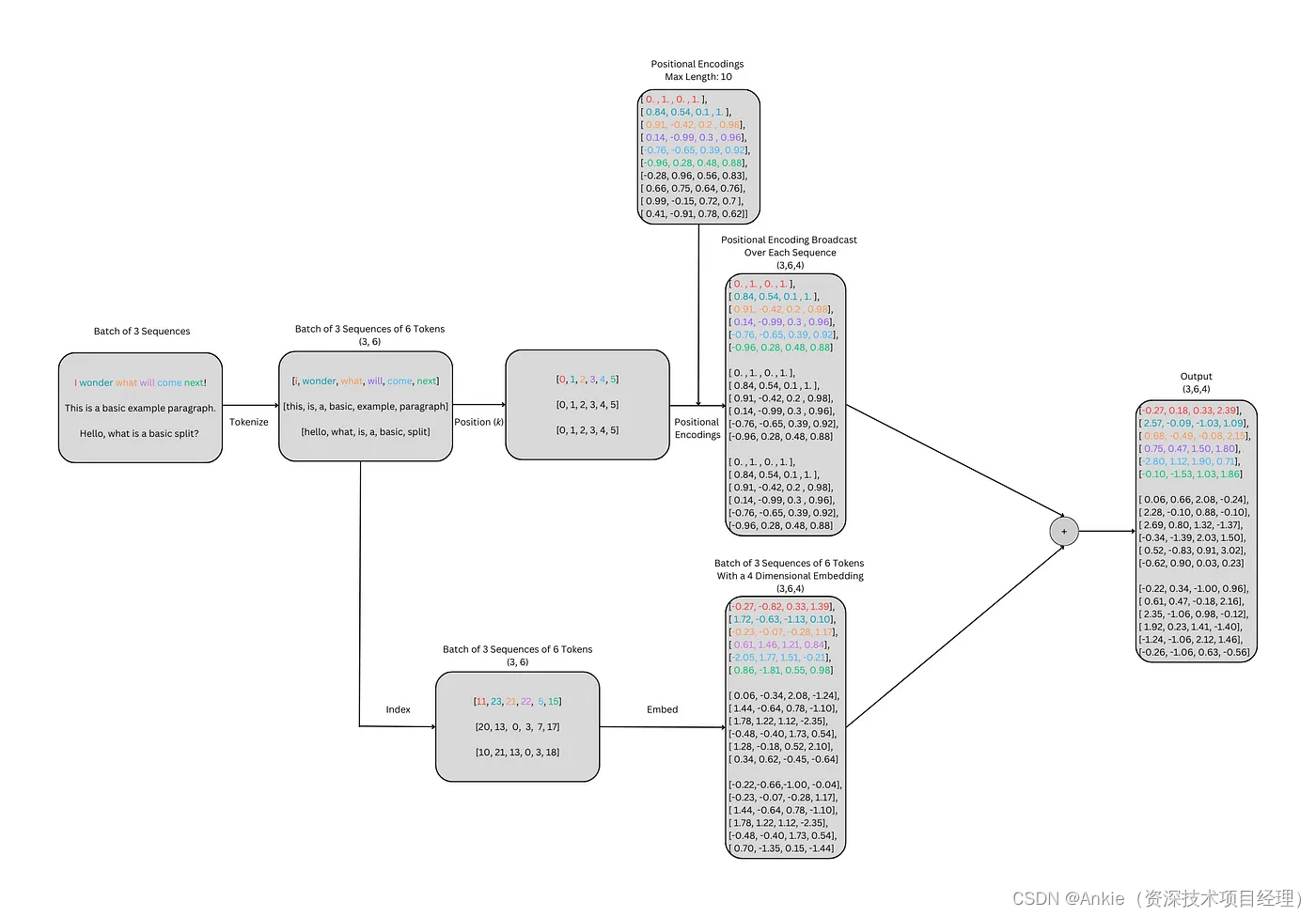
学习transformer模型-Positional Encoding位置编码的简明介绍
今天介绍transformer模型的positional encoding 位置编码 背景
位置编码用于为序列中的每个标记或单词提供一个相对位置。在阅读句子时,每个单词都依赖于其周围的单词。例如,有些单词在不同的上下文中具有不同的含义,因此模型应该能够理解这…
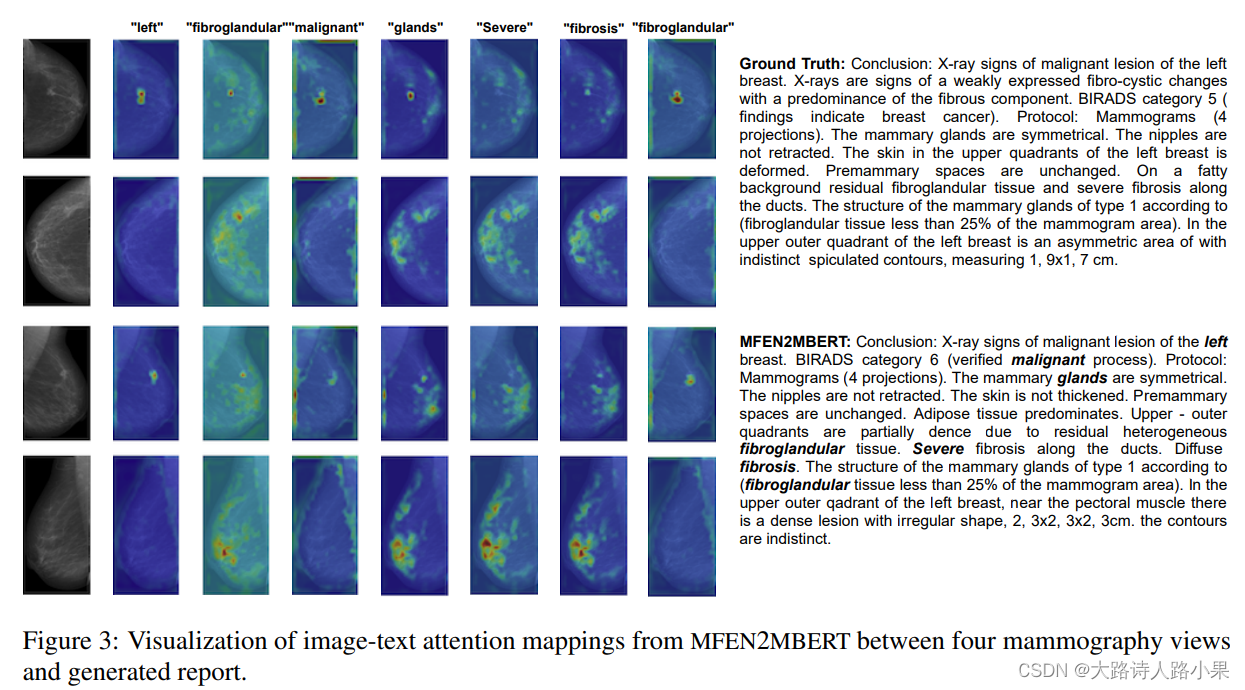
精读 Generating Mammography Reports from Multi-view Mammograms with BERT
精读(非常推荐) Generating Mammography Reports from Multi-view Mammograms with BERT(上)
这里的作者有个叫 Ilya 的吓坏我了
1. Abstract
Writing mammography reports can be errorprone and time-consuming for radiolog…

Sora 基础作品之 DiT:Scalable Diffusion Models with Transformer
Paper name
Scalable Diffusion Models with Transformers (DiT)
Paper Reading Note
Paper URL: https://arxiv.org/abs/2212.09748
Project URL: https://www.wpeebles.com/DiT.html
Code URL: https://github.com/facebookresearch/DiT
TL;DR
2022 年 UC Berkeley 出…
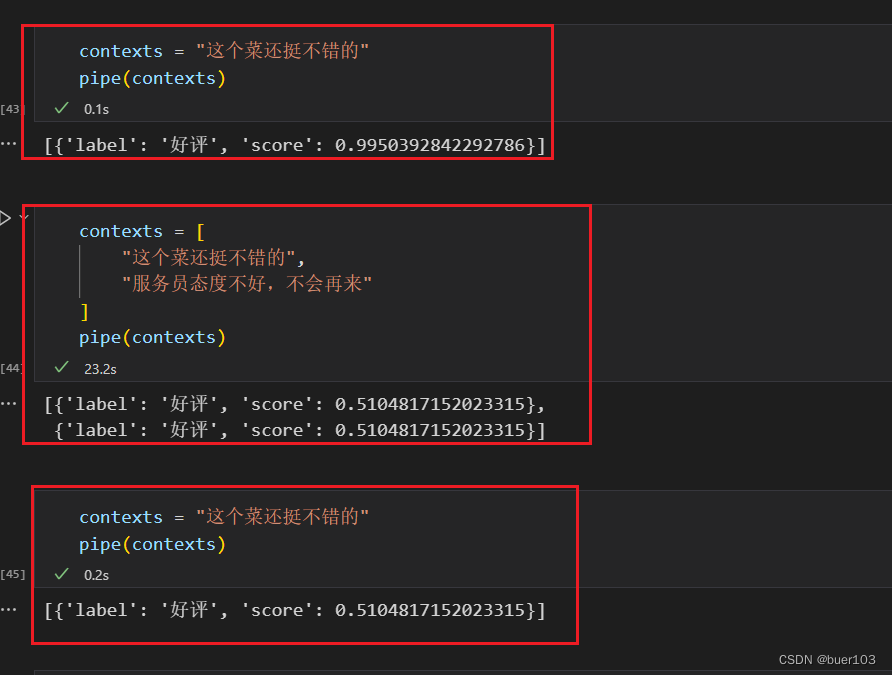
transformers微调模型后使用pieline调用无法预测列表文本
初学transformers框架 使用trainer简单训练一个文本分类模型三个epoch后 使用piepline调用model 和tokenizer后 发现 传入列表文本后 输出就变得不正常了,为么子哇 如下图
YOLOv9改进策略 :主干优化 | 极简的神经网络VanillaBlock 实现涨点 |华为诺亚 VanillaNet
💡💡💡本文改进内容: VanillaNet,是一种设计优雅的神经网络架构, 通过避免高深度、shortcuts和自注意力等复杂操作,VanillaNet 简洁明了但功能强大。 💡💡💡引入VanillaBlock GFLOPs从原始的238.9降低至 165.0 ,保持轻量级的同时在多个数据集验证能够高效涨点…

【DETR系列目标检测算法代码精讲】01 DETR算法02 DETR算法数据预处理+图像增强+dataset代码精讲
今天这一节主要对DETR算法的数据预处理和数据增强部分的代码做逐行的精讲。 这一部分的代码主要的功能就是将COCO数据集中的原始图像和原始标注处理成能够输入到DETR网络中的图像和标注。
我首先采取任务流程逐行讲解的办法,然后再debug演示一下
准备
这个读取数…

East: Efficient and Accurate Secure Transformer Framework for Inference
目录 1. 概述2.遗忘分段多项式求值算法(OPPE)3.为softmax与LN精心设计安全协议3.1 softmax优化3.2 LN优化 4.进一步优化 1. 概述
本文提出了一个高效并且准确的安全Transformer推理框架East。作者将该框架应用到BERT上面其推理精度与明文推理保持一致。
在激活函数上应用一种…

实现泛化,强大,有规模的Graph Transformer
概述 该工作来自于:Recipe for a General, Powerful, Scalable Graph Transformer,Nips2022,名为GPS。Graph Transformer (GTs)已经在图表示学习领域取得了很多成果,GPS作为图表示学习的系统性方法,是一个模块化的框架…
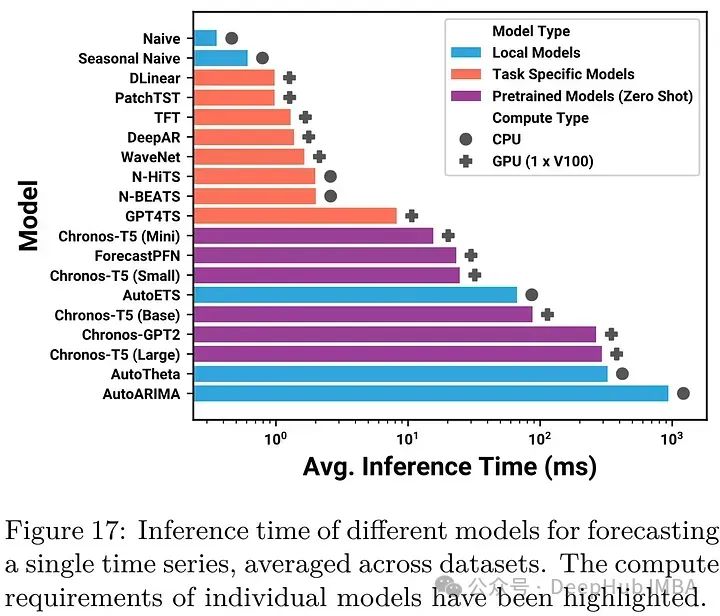
Chronos: 将时间序列作为一种语言进行学习
这是一篇非常有意思的论文,它将时间序列分块并作为语言模型中的一个token来进行学习,并且得到了很好的效果。 Chronos是一个对时间序列数据的概率模型进行预训练的框架,它将这些值标记为与基于transformer的模型(如T5)一起使用。模型将序列的…
![[从0开始AIGC][Transformer相关]:Transformer中的激活函数:Relu、GELU、GLU、Swish](https://img-blog.csdnimg.cn/img_convert/b6acc964c165baeb1ebaad9ecdac1c8d.png)
[从0开始AIGC][Transformer相关]:Transformer中的激活函数:Relu、GELU、GLU、Swish
[从0开始AIGC][Transformer相关]:Transformer中的激活函数 文章目录 [从0开始AIGC][Transformer相关]:Transformer中的激活函数1. FFN 块 计算公式?2. GeLU 计算公式?3. Swish 计算公式?4. 使用 GLU 线性门控单元的 FF…

Transformer - model architecture
Transformer - model architecture
flyfish Transformer总体架构可分为四个部分: 输⼊部分 输出部分 编码器部分 解码器部分
输入部分 输出部分 输⼊部分包含: 源嵌⼊层和位置编码 ⽬标嵌⼊层和位置编码
输出部分包含: 线性层 softmax处理器 左侧编码器部分和右侧解码器部…

Transformer - 注意⼒机制
Transformer - 注意⼒机制
flyfish
计算过程
flyfish # -*- coding: utf-8 -*-import torch
import torch.nn as nn
import torch.nn.functional as F
import os
import mathdef attention(query, key, value, maskNone, dropoutNone):# query的最后⼀维的⼤⼩, ⼀般情况下就…
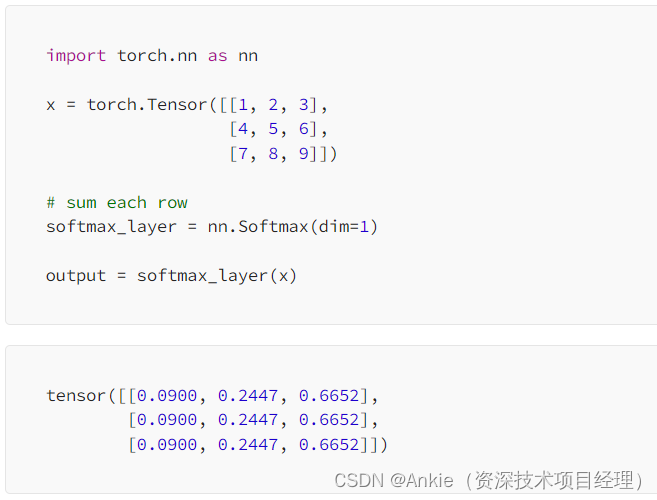
Transformer模型-softmax的简明介绍
今天介绍transformer模型的softmax softmax的定义和目的:
softmax:常用于神经网络的输出层,以将原始的输出值转化为概率分布,从而使得每个类别的概率值在0到1之间,并且所有类别的概率之和为1。这使得Softmax函数特别适…

Transformer - Positional Encoding 位置编码 代码实现
Transformer - Positional Encoding 位置编码 代码实现
flyfish
import torch
import torch.nn as nn
import torch.nn.functional as F
import os
import mathclass PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len5000):super(PositionalEnco…

Transformer - Outputs(Shifted Right)
Transformer - Outputs(Shifted Right)
flyfish 输入: “je suis etudiant” 预期输出 : “i am a student” 除了普通词汇之外,模型还引入了一些特殊token,常有的(start of sequence)、(end of sequence)…
PyTorch示例——使用Transformer写古诗
文章目录 PyTorch示例——使用Transformer写古诗1. 前言2. 版本信息3. 导包4. 数据与预处理数据下载先看一下原始数据开始处理数据,过滤掉异常数据定义 词典编码器 Tokenizer定义数据集类 MyDataset测试一下MyDataset、Tokenizer、DataLoader 5. 构建模型位置编码器…
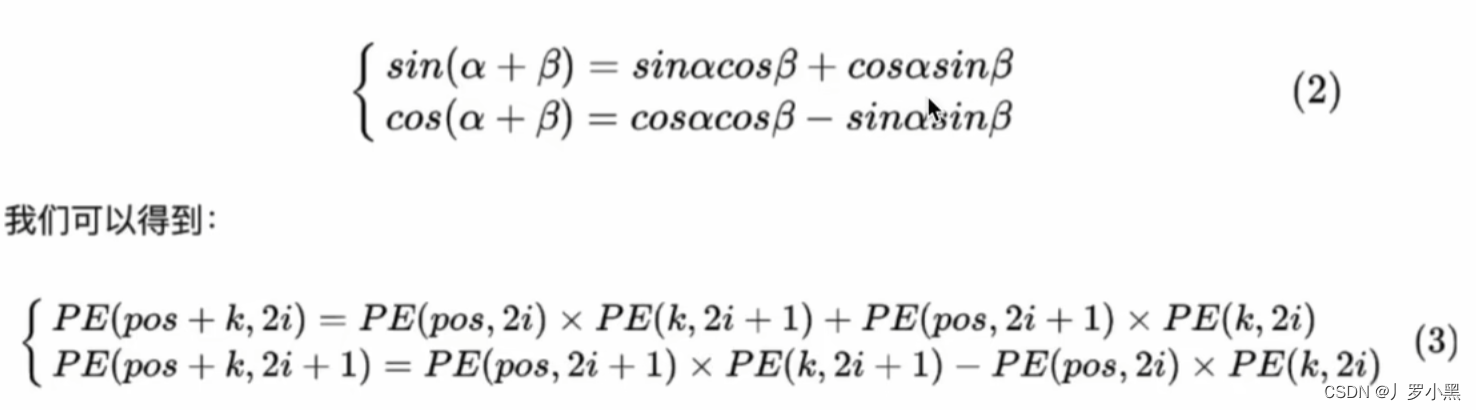
Transformer的代码实现 day03(Positional Encoding)
Positional Encoding的理论部分
注意力机制是不含有位置信息,这也就表明:“我爱你”,“你爱我”这两者没有区别,而在现实世界中,这两者有区别。所以位置编码是在进行注意力计算之前,给输入加上一个位置信息…
Transformer模型-用jupyter演示逐步计算attention
学习transformer模型-用jupyter演示如何计算attention,不含multi-head attention,但包括权重矩阵W。
input embedding:文本嵌入
每个字符用长度为5的向量表示: 注意力公式: 1,准备Q K V: 先 生…
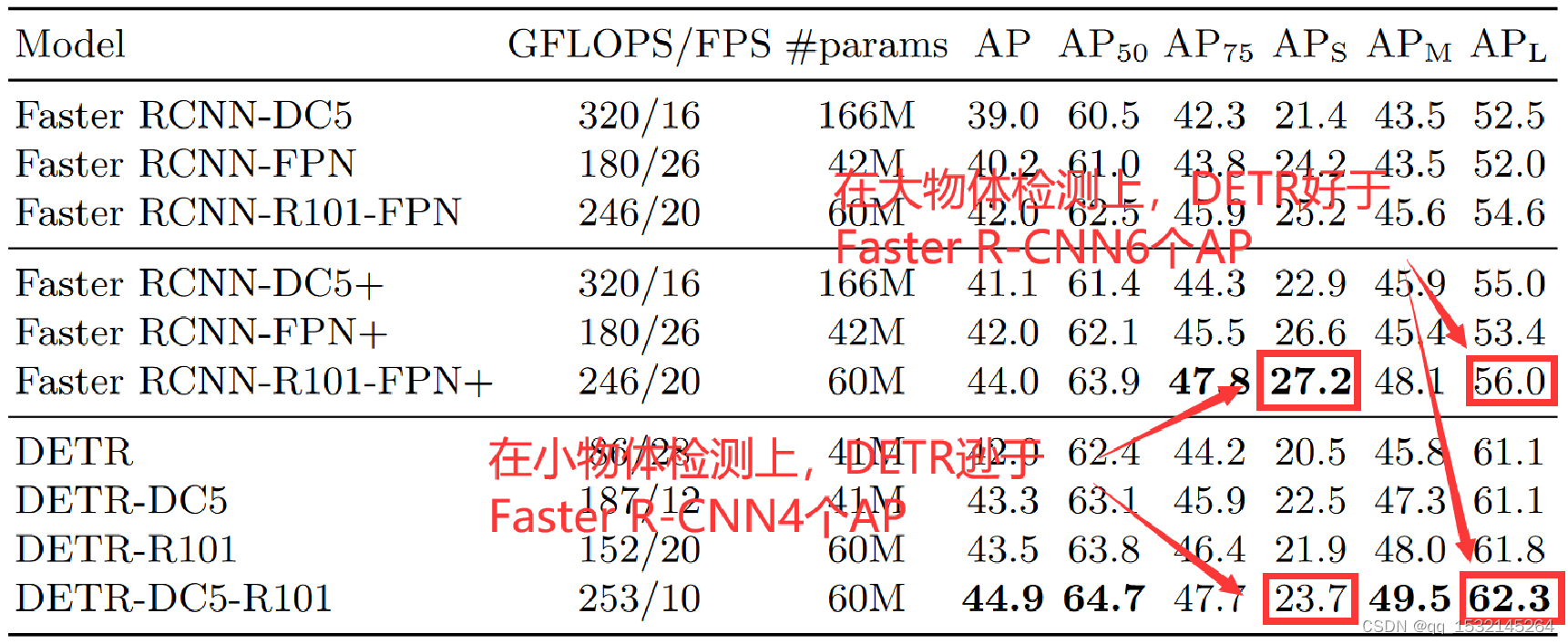
DETR【Transformer+目标检测】
End-to-End Object Detection with Transformers 2024 NVIDIA GTC,发布了地表最强的GPU B200,同时,黄仁勋对谈《Attention is All You Need》论文其中的7位作者,座谈的目的无非就是诉说,Transformer才是今天人工智能成…

『大模型笔记』LLMs入门:从头理解与编码LLM的自注意力机制
LLMs入门:从头理解与编码LLM的自注意力机制 这里直接引用我语雀上的的文章:《从头理解与编码LLM的自注意力机制》
Transformer Based Multi-view Network for Mammographic Image Classification
“C-Tk” means “Classification Token”
辅助信息
作者未提供代码
PyTorch搭建Autoformer实现长序列时间序列预测
目录 I. 前言II. AutoformerIII. 代码3.1 Encoder输入3.1.1 Token Embedding3.1.2 Temporal Embedding 3.2 Decoder输入3.3 Encoder与Decoder3.3.1 初始化3.3.2 Encoder3.3.3 Decoder IV. 实验 I. 前言
前面已经写了很多关于时间序列预测的文章:
深入理解PyTorch中…
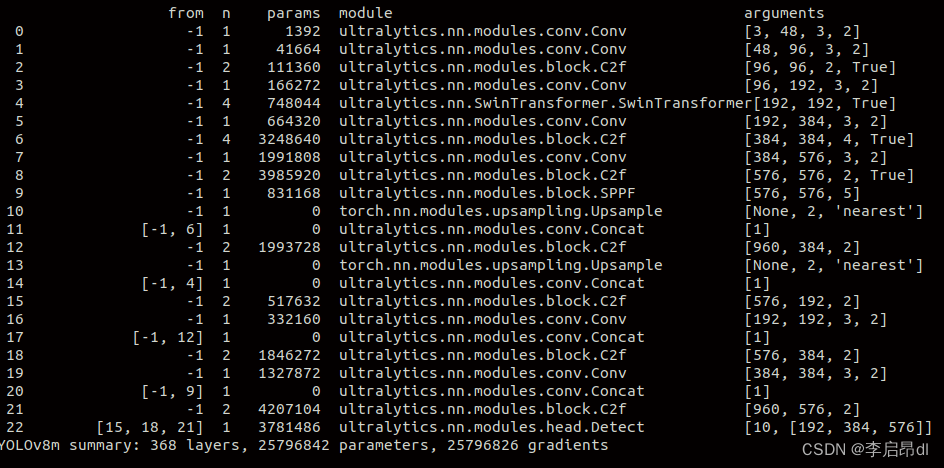
改进YOLO:YOLOv8结合swin transformer
目录
1、修改yaml文件
2、添加 SwinTransformer.py
3、修改 tasks.py
4、根目录增加文件 1、修改yaml文件
修改 ultralytics/cfg/models/v8/yolov8.yaml
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] #…
PyTorch搭建Informer实现长序列时间序列预测
目录 I. 前言II. InformerIII. 代码3.1 输入编码3.1.1 Token Embedding3.1.2 Positional Embedding3.1.3 Temporal Embedding 3.2 Encoder与Decoder IV. 实验 I. 前言
前面已经写了很多关于时间序列预测的文章:
深入理解PyTorch中LSTM的输入和输出(从i…
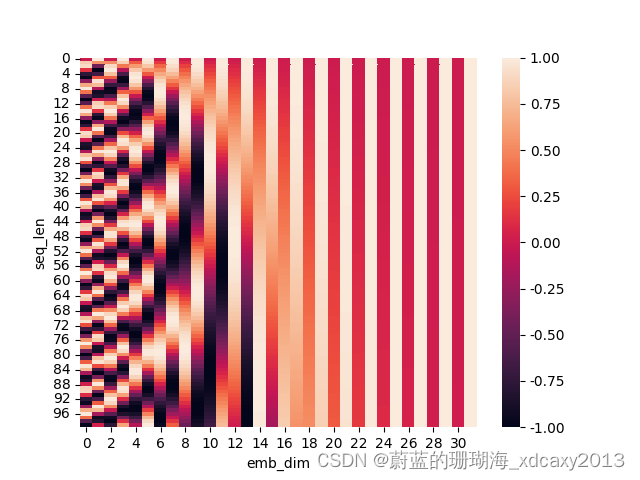
Transformer位置编码详解
在处理自然语言时候,因Transformer是基于注意力机制,不像RNN有词位置顺序信息,故需要加入词的位置信息来显示的表明词的上下文关系。具体是将词经过位置编码(positional encoding),然后与emb词向量求和,作为编码块(Enc…

【论文精读】Transformer:Attention Is All You Need
《动手学深度学习》关于Transformer和注意力机制的笔记
李沐《动手学深度学习》注意力机制 文章目录 《动手学深度学习》关于Transformer和注意力机制的笔记一、文章概览(一)摘要(二)结论部分(三)引言&am…
一文总结CNN中【各类卷积】操作
本文详细总结CNN中各类卷积,旨在指导 domain-specific 更好的模型设计,包括标准卷积,分组卷积(Group Conv),深度可分离卷积(Depthwise Separable Conv),转置卷积…

【IJCAI】CostFormer即插即用的MVS高效代价体聚合Transformer,FaceChain团队出品
一、论文题目:
CostFormer: Cost Transformer for Cost Aggregation in Multi-view Stereo,https://arxiv.org/abs/2305.10320
二、论文简介: 多视角立体是三维重建的一种重要实现方式,该方式会从一系列同一场景但不同视角的二维…

AIGC实战——GPT(Generative Pre-trained Transformer)
AIGC实战——GPT 0. 前言1. GPT 简介2. 葡萄酒评论数据集3. 注意力机制3.1 查询、键和值3.2 多头注意力3.3 因果掩码 4. Transformer4.1 Transformer 块4.2 位置编码 5. 训练GPT6. GPT 分析6.1 生成文本6.2 注意力分数 小结系列链接 0. 前言
注意力机制能够用于构建先进的文本…
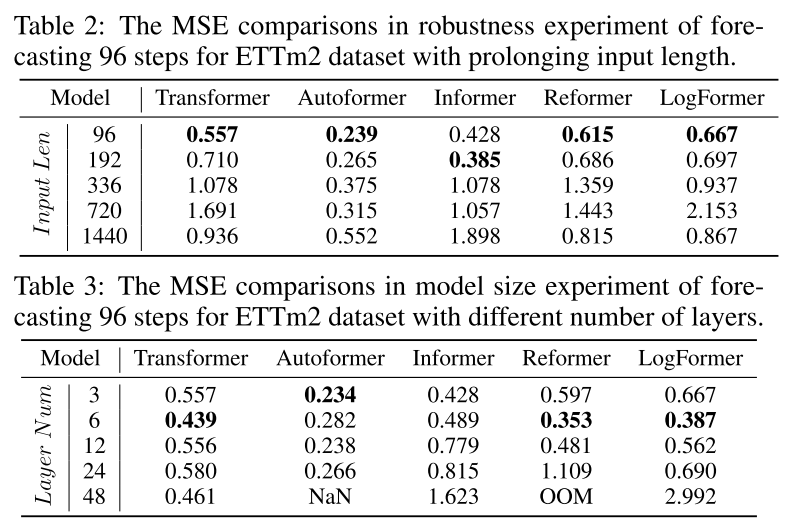
【论文笔记合集】Transformers in Time Series A Survey综述总结
本文作者: slience_me 文章目录 Transformers in Time Series A Survey综述总结1 Introduction2 Transformer的组成Preliminaries of the Transformer2.1 Vanilla Transformer2.2 输入编码和位置编码 Input Encoding and Positional Encoding绝对位置编码 Absolute …

YOLOV5添加 ECA CA SE CBAM 等八种注意力机制(小白可用)
目录
CBAM注意力机制原理及代码实现
代码实现 yaml文件
修改后的结构图
SE注意力机制
SE结构图
完整代码实现
报错 ⭐欢迎大家订阅我的专栏一起学习⭐
🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀&…

黄仁勋对话Transformer背后的英雄,还有李飞飞等大佬分享!GTC 2024 AI大会来了!...
点击下方卡片,关注“CVer”公众号 AI/CV重磅干货,第一时间送达 大家好,Amusi 带来重磅消息啦!NVIDIA GTC 2024 即将盛大开幕!没错,就是那个全球人工智能领域的顶级行业盛会,令 AI 和 GPU 开发者…
Python轴承故障诊断 (15)基于CNN-Transformer的一维故障信号识别模型
目录
往期精彩内容:
前言
1 轴承数据加载与预处理
1.1 导入数据
1.2 数据预处理,制作数据集
3 基于Pytorch的CNN-Transfromer轴承故障诊断分类
3.1 定义CNN-Transfromer分类网络模型
3.2 设置参数,训练模型
3.3 模型评估
代码、数据…

Transformer模型的Pytorch实现
Transformer的Pytorch实现有多个开源版本,基本大同小异,我参考的是这份英译中的工程。
为了代码讲解的直观性,还是先把Transformer的结构贴上来。 针对上述结构,我们从粗到细地来看一下模型的代码实现。
1. 模型整体构造
clas…
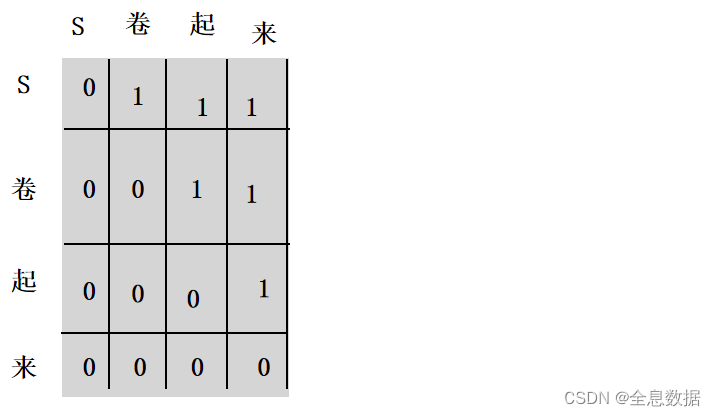
Transformer代码从零解读【Pytorch官方版本】
文章目录 1、Transformer大致有3大应用2、Transformer的整体结构图3、如何处理batch-size句子长度不一致问题4、MultiHeadAttention(多头注意力机制)5、前馈神经网络6、Encoder中的输入masked7、完整代码补充知识: 1、Transformer大致有3大应…
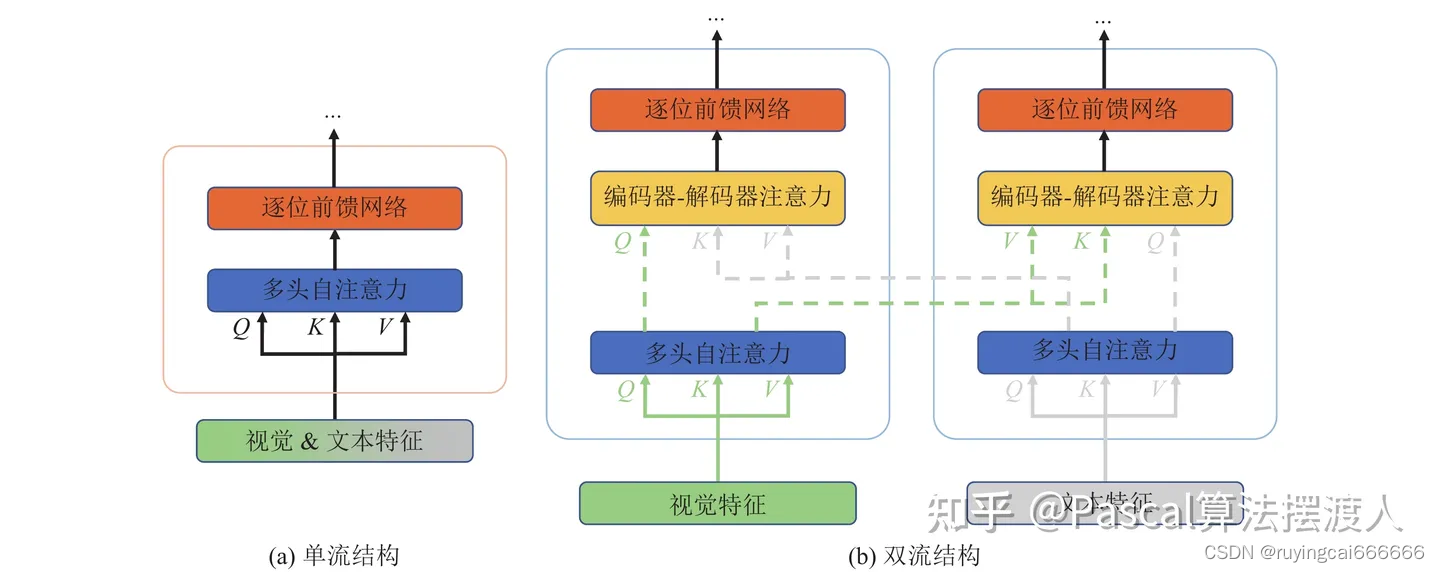
多模态学习 - 视觉语言预训练综述-2023-下游任务、数据集、基础知识、预训练任务、模型
参考: https://zhuanlan.zhihu.com/p/628840228 https://zhuanlan.zhihu.com/p/628994098 https://zhuanlan.zhihu.com/p/629996372 https://zhuanlan.zhihu.com/p/582424974 多模态学习 - 视觉语言预训练综述-2023-下游任务、数据集、基础知识、模型 1. 多模态介绍…
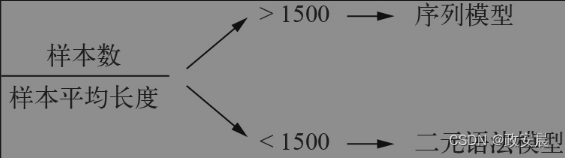
政安晨:【深度学习处理实践】(九)—— Transformer架构
咱们接着这个系列的上一篇文章继续:
政安晨:【深度学习处理实践】(八)—— 表示单词组的两种方法:集合和序列https://blog.csdn.net/snowdenkeke/article/details/136762323
Transformer是一种架构,用于在…
Transformer的前世今生 day02(神经网络语言模型、词向量)
神经网络语言模型
使用神经网络的方法,去完成语言模型的两个问题,下图为两层感知机的神经网络语言模型: 假设词典V内有五个词:“判断”、“这个”、“词”、“的”、“词性”,且要输出P(w_next | “判断”、“这个”、…

VPCFormer:一个基于transformer的多视角指静脉识别模型和一个新基准
文章目录 VPCFormer:一个基于transformer的多视角指静脉识别模型和一个新基准总结摘要介绍相关工作单视角指静脉识别多视角指静脉识别Transformer 数据库基本信息 方法总体结构静脉掩膜生成VPC编码器视角内相关性的提取视角间相关关系提取输出融合IFFN近邻感知模块(NPM) patch嵌…

Mamba 基础讲解【SSM,LSSL,S4,S5,Mamba】
文章目录 Mamba的提出动机TransformerRNN Mama的提出背景状态空间模型 (The State Space Model, SSM)线性状态空间层 (Linear State-Space Layer, LSSL)结构化序列空间模型 (Structured State Spaces for Sequences, S4) Mamba的介绍Mamba的特性一&#…
Transformer的前世今生 day06(Self-Attention和RNN、LSTM的区别
Self-Attention和RNN、LSTM的区别
RNN的缺点:无法做长序列,当输入很长时,最后面的输出很难参考前面的输入,即长序列会缺失上文信息,如下: 可能一段话超过50个字,输出效果就会很差了 LSTM通过忘…

【机器学习】一文搞懂算法模型之:Transformer
Transformer 1、引言2、Transformer2.1 定义2.2 原理2.3 算法公式2.3.1 自注意力机制2.3.1 多头自注意力机制2.3.1 位置编码 2.4 代码示例 3、总结 1、引言
小屌丝:鱼哥, 你说transformer是个啥? 小鱼:嗯… 啊… 嗯…就是… 小屌…
复试专业前沿问题问答合集9——密码学
复试专业前沿问题问答合集9——密码学
网络安全中的密码学加密算法原理及基础知识问答:
Q1: 对称加密算法是如何工作的?
A1: 对称加密算法使用相同的密钥进行数据的加密和解密。这种加密方式的关键在于密钥的保密,因为任何拥有密钥的人都可以解密信息。对称加密算法速度快…
【Transformer 】 Hugging Face手册 (02/10)
一、说明 启动🤗并运行变形金刚!无论您是开发人员还是日常用户,此快速教程都将帮助您入门,并向您展示如何使用 pipeline() 进行推理、使用 AutoClass 加载预训练模型和预处理器,以及使用 PyTorc…
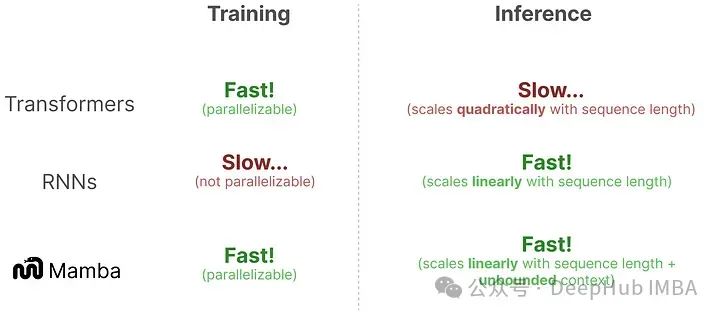
Mamba详细介绍和RNN、Transformer的架构可视化对比
Transformer体系结构已经成为大型语言模型(llm)成功的主要组成部分。为了进一步改进llm,人们正在研发可能优于Transformer体系结构的新体系结构。其中一种方法是Mamba(一种状态空间模型)。 Mamba: Linear-Time Sequence Modeling with Select…
Vit Transformer
一 VitTransformer 介绍
vit : An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 论文是基于Attention Is All You Need,由于图像数据和词数据数据格式不一样,经典的transformer不能处理图像数据,在视觉领域的应…
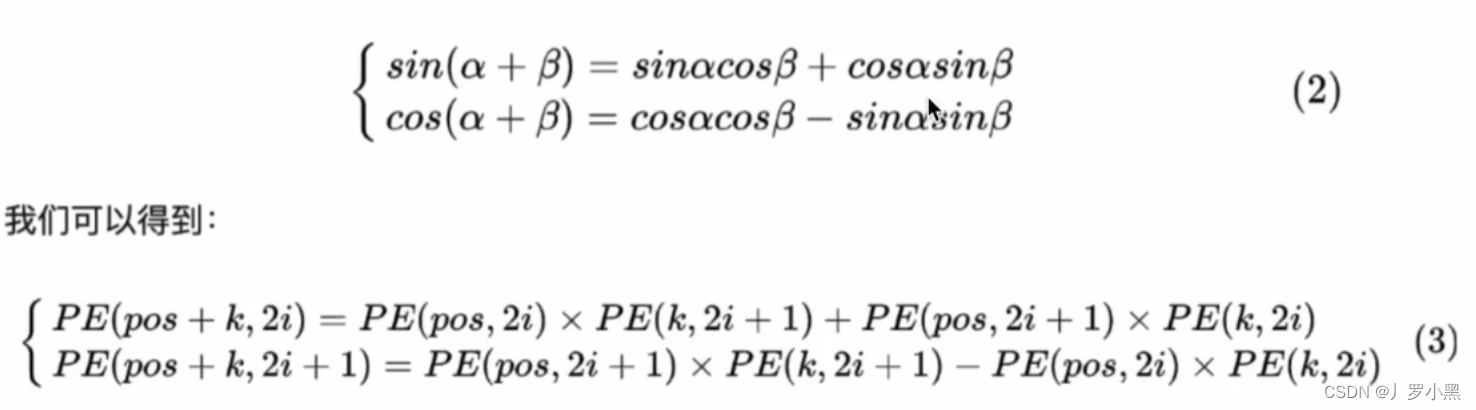
Transformer的前世今生 day08(Positional Encoding)
前情提要
Attention的优点:解决了长序列依赖问题,可以并行。Attention的缺点:开销变大了,而且不存在位置关系为了解决Attention中不存在位置关系的缺点,我们通过位置编码的形式加上位置关系
Positional Encoding&…
论文阅读---VITC----Early Convolutions Help Transformers See Better
论文题目:Early Convolutions Help Transformers See Better
早期的卷积网络帮助transformers性能提升
vit 存在不合格的可优化性,它们对优化器的选择很敏感。相反现代卷积神经网络更容易优化。
vit对优化器的选择[40](AdamW [27] vs. SGD)࿰…
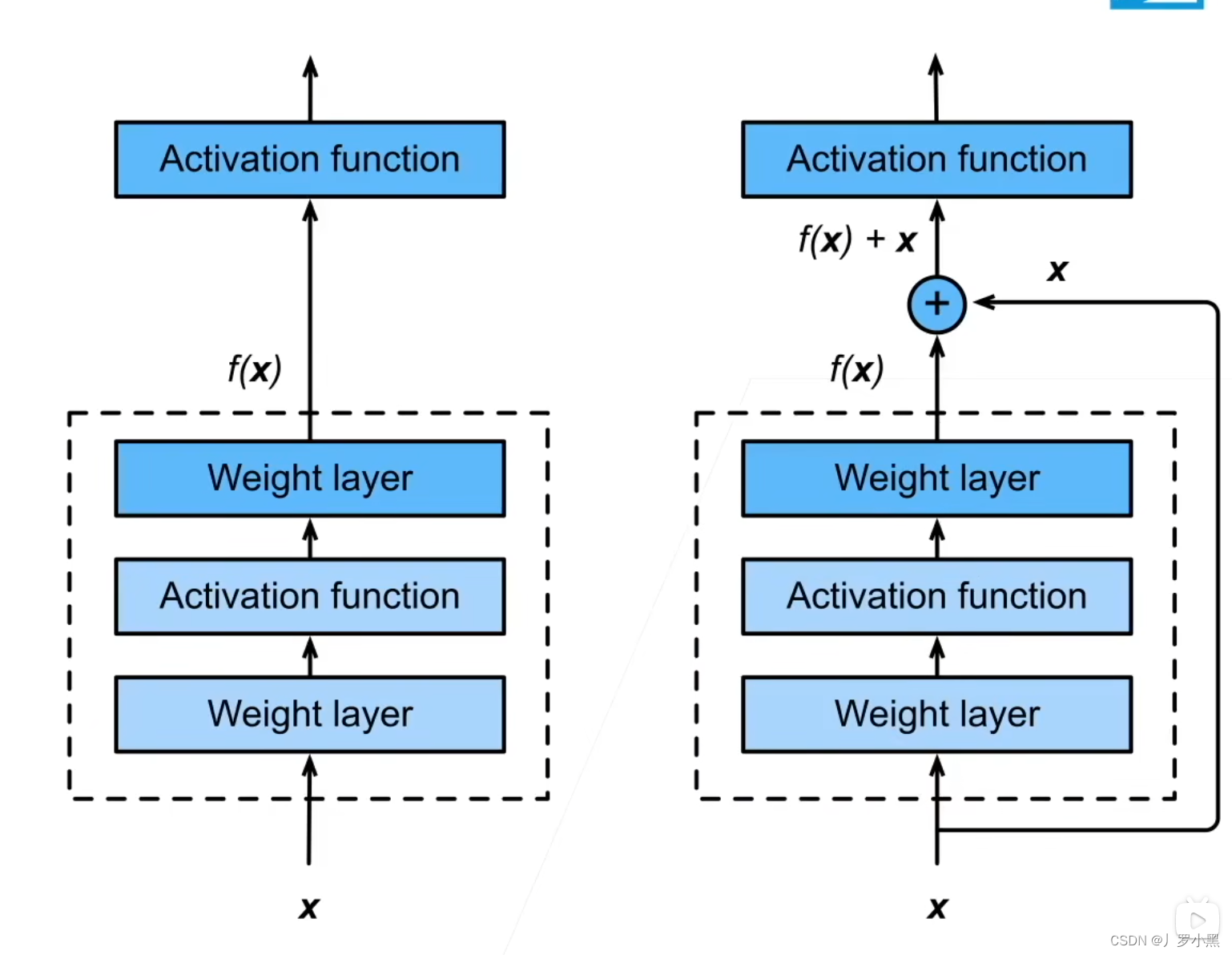
Transformer的前世今生 day10(Transformer编码器
前情提要
ResNet(残差网络)
由于我们加更多层,更复杂的模型并不总会改进精度,可能会让模型与真实值越来越远,如下: 我们想要实现,加上一个层把并不会让模型变复杂,即没有它也没关系…

51-27 DirveVLM:自动驾驶与大型视觉语言模型的融合
本文由清华大学和理想汽车共同发布于2024年2月25日,论文名称DRIVEVLM: The Convergence of Autonomous Driving and Large Vision-Language Models.
DriveVLM是一种新颖的自动驾驶系统,旨在针对场景理解挑战,利用最近的视觉语言模型VLM&…
学习人工智能-点积dot product,计算transformer模型里面的attention
因为transformer模型里面计算attention用到了点积dot product来计算相似度 or 距离,所以补充一下点积的知识。
点积的代数定义:
点积在数学中,又称数量积(dot product; scalar product),是指接受在实数R上…
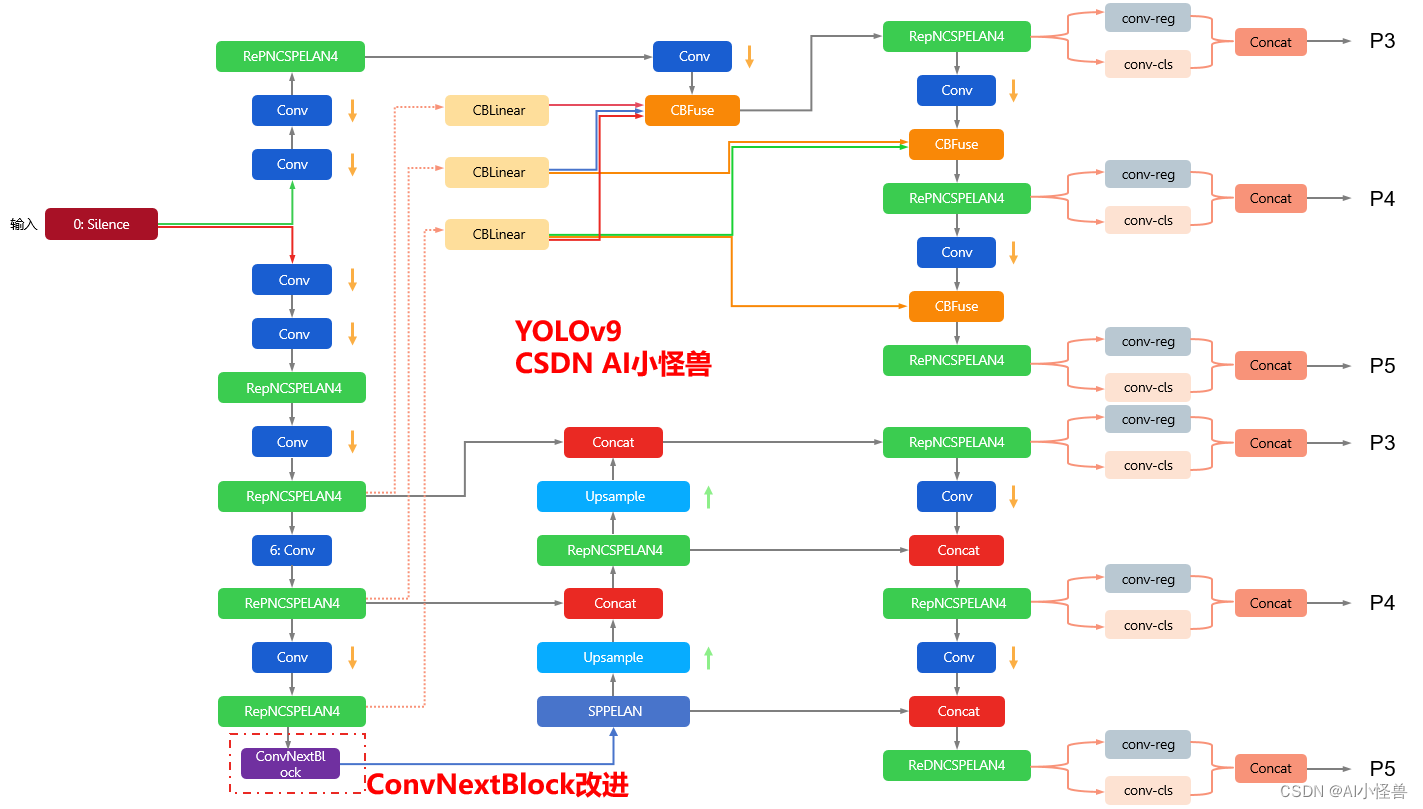
YOLOv9改进策略:block优化 | Transformer架构ConvNeXt 网络在检测中大放异彩
💡💡💡本文改进内容:Transformer架构 ConvNeXt 网络在图像分类和识别、分割领域大放异彩,同时对比 Swin-T 模型,在多种任务中其模型的大小和准确率均有一些提升,模型的 FLOPs 较大的减小且 Acc …
基于SwinTransformer和Unet的自适应多类别分割
1、介绍
transformer的基于全局信息的把握,使得对图像的处理成为了可能
swin-transformer在图像分类应用的成功,证明了transformer比传统的cnn卷积网络可以更好的提取图像特征。因为图像分割也是基于特征信息的融合,将不同尺度下的信息拼接…
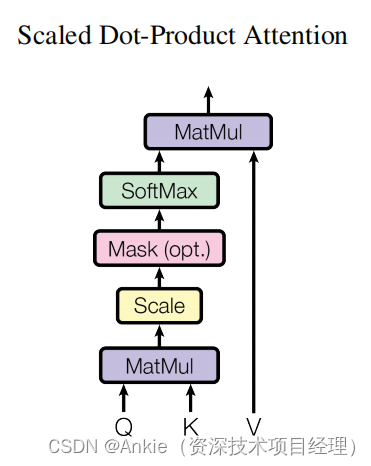
学习transformer模型-矩阵乘法;与点积dot product的关系;计算attention
矩阵乘法: 1、当矩阵A的列数(column)等于矩阵B的行数(row)时,A与B可以相乘。 Ankie的评论:一个人是站着的,一个人是躺着的,站着的高度躺着的长度。 在计算attention的时候…
transformer中selfattention简单实现
AI大模型学习
在当前技术环境下,AI大模型学习不仅要求研究者具备深厚的数学基础和编程能力,还需要对特定领域的业务场景有深入的了解。通过不断优化模型结构和算法,AI大模型学习能够不断提升模型的准确性和效率,为人类生活和工作…
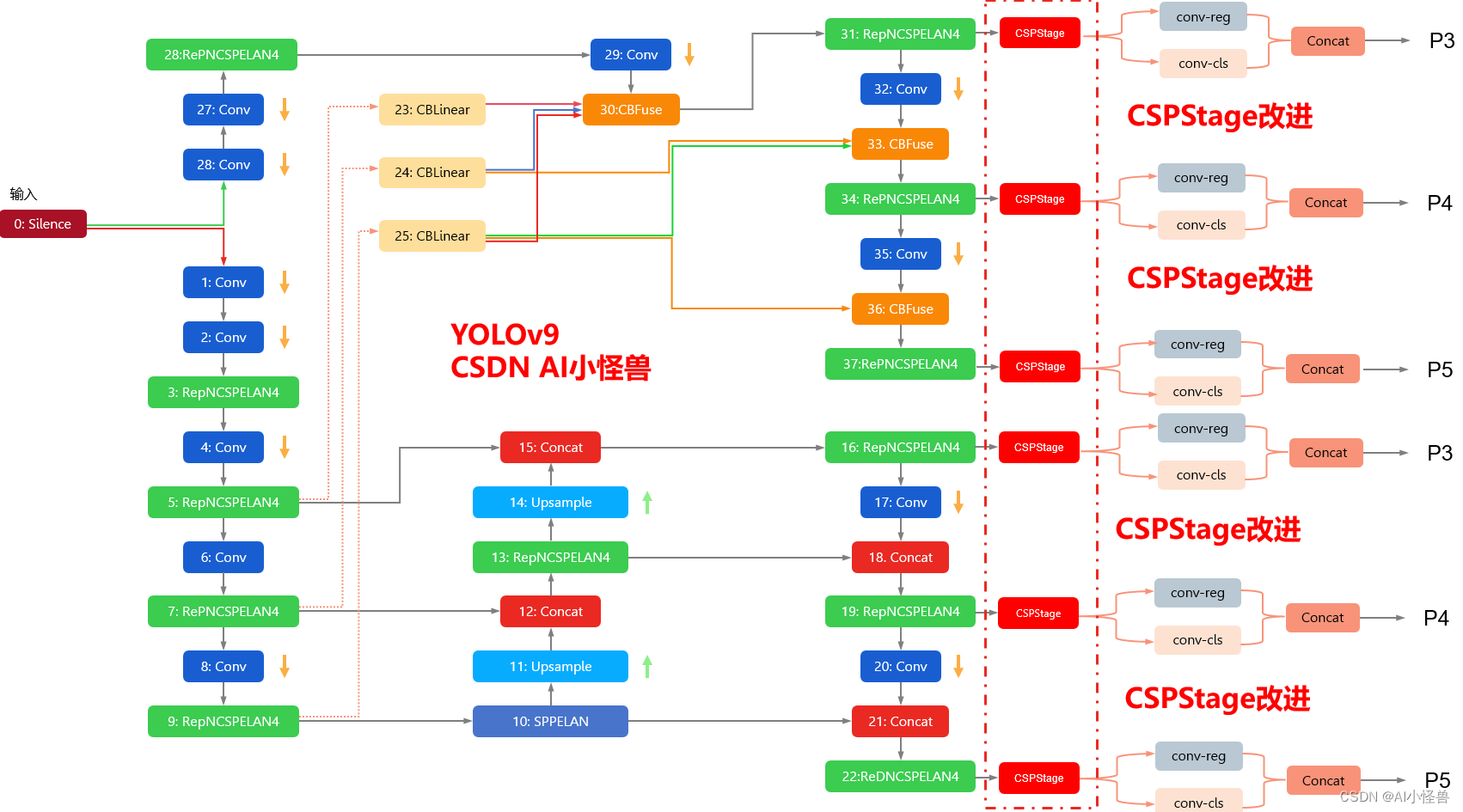
YOLOv9改进策略 :neck优化 | 路径融合GFPN,小目标到大目标一网打尽 | 轻骨干重Neck的轻量级目标检测器GiraffeDet
💡💡💡本文改进内容:设计了一种新的路径融合GFPN:包含跳层与跨尺度连接,改进思路来自ICLR2022 GiraffeDet的核心思想。 💡💡💡GFPN和六个检测头结合,这种跳层…

Transformers —— 以通俗易懂的方式解释-Part 1
公众号:Halo咯咯,欢迎关注~ 本系列主要介绍了为ChatGPT以及许多其他大型语言模型(LLM)提供支持的Transformer神经网络。我们将从基础的Transformer概念开始介绍,尽量避免使用数学和技术细节,使得更多人能够理解这一强大的技术。
Transformers —— 以通俗易懂的方式解释…

首个基于SSM-Transformer混合架构,开源商业大模型Jamba
3月29日,知名AI研究实验室AI21在官网开源了,首个基于SSM-Transformer混合架构的商业大模型——Jamba。
目前,ChatGPT、Stable Difusion 、Lyria等产品使用的皆是Transformer架构,虽然在捕捉序列内长距离依赖关系、泛化能力、特征…

谈一谈BEV和Transformer在自动驾驶中的应用
谈一谈BEV和Transformer在自动驾驶中的应用
BEV和Transformer都这么火,这次就聊一聊。 结尾有资料连接
一 BEV有什么用
首先,鸟瞰图并不能带来新的功能,对规控也没有什么额外的好处。
从鸟瞰图这个名词就可以看出来,本来摄像头…
复试专业前沿问题问答合集8-1——CNN、Transformer、TensorFlow、GPT
复试专业前沿问题问答合集8-1——CNN、Transformer、TensorFlow、GPT
深度学习中的CNN、Transformer、TensorFlow、GPT大语言模型的原理关系问答:
Transformer与ChatGPT的关系
Transformer 是一种基于自注意力机制的深度学习模型,最初在论文《Attention is All You Need》…
复试专业前沿问题问答合集11——信息安全十大安全漏洞
复试专业前沿问题问答合集11——信息安全十大安全漏洞
网络安全方向十大安全漏洞的原理与基础知识:
在信息安全领域,了解常见的安全漏洞对于防范网络攻击至关重要。以下是十大安全漏洞的原理知识:
1. SQL注入(SQL Injection)
Q: 什么是SQL注入攻击? A: SQL注入是一种代…

YOLOv5独家改进:backbone改进 | 视觉新主干!RMT:RetNet遇见视觉Transformer | CVPR2024
💡💡💡本文独家改进:RMT:一种强大的视觉Backbone,灵活地将显式空间先验集成到具有线性复杂度的视觉主干中,在多个下游任务(分类/检测/分割)上性能表现出色!
💡💡💡Transformer 在各个领域验证了可行性,在多个数据集下能够实现涨点
改进结构图如下:
收…

网络模型之Transformer(2017)
Attention is all you need.注意力是你所需要的一切Vaswani A, Shazeer N, Parmar N, et al.Advances in neural information processing systems, 2017, 30. 文章目录 摘要1. 引言2. 背景3. 模型结构3.1 encoder和decoder块3.2 Attention3.2.1 缩放点积注意力(Scaled Dot-Prod…

YOLOv8独家改进:backbone改进 | 视觉新主干!RMT:RetNet遇见视觉Transformer | CVPR2024
💡💡💡本文独家改进:RMT:一种强大的视觉Backbone,灵活地将显式空间先验集成到具有线性复杂度的视觉主干中,在多个下游任务(分类/检测/分割)上性能表现出色!
💡💡💡Transformer 在各个领域验证了可行性,在多个数据集下能够实现涨点
改进结构图如下: 收录
…

LayerNormalization 和 RMSNormalization的计算方法和区别
目录 问题来源
Layer Normalization 与 RMSNormalization 的详细计算方法
Layer Normalization(层归一化)
RMSNormalization(均方根归一化)
Layer Normalization与RMSNormalization的异同
Layer Normalization
RMSNormaliza…

自动驾驶感知新范式——BEV感知经典论文总结和对比(一)
自动驾驶感知新范式——BEV感知经典论文总结和对比(一)
博主之前的博客大多围绕自动驾驶视觉感知中的视觉深度估计(depth estimation)展开,包括单目针孔、单目鱼眼、环视针孔、环视鱼眼等,目标是只依赖于视…
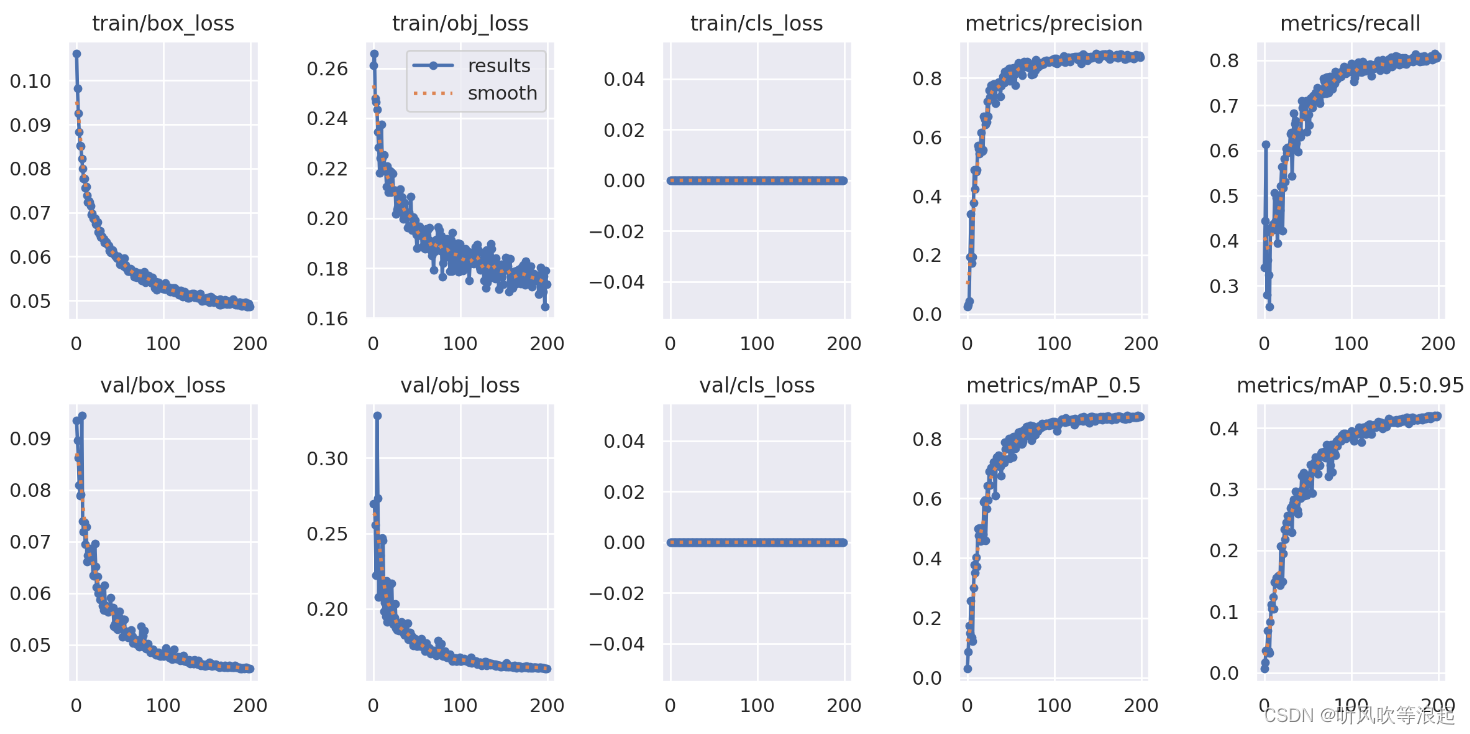
YOLOV5 改进:替换backbone为Swin Transformer
1、前言
本文会将YOLOV5 backbone更换成Swin Transformer 具体为什么这样实现参考上文:YOLOV5 改进:替换backbone(MobileNet为例)-CSDN博客
这里只贴加入的代码
训练结果如下: 2、common文件更改
在common文件中加入下面代码:
这里是swin transformer的实现,参考:…

目标检测中的mAP计算原理和源码实现
简介
在目标检测任务中,mAP(mean Average Precision,平均精度均值)是一个非常重要的评价指标,用于衡量模型在多个类别上的平均性能。它综合考虑了模型在不同召回率下的精确率,能够全面反映模型在检测任务中…
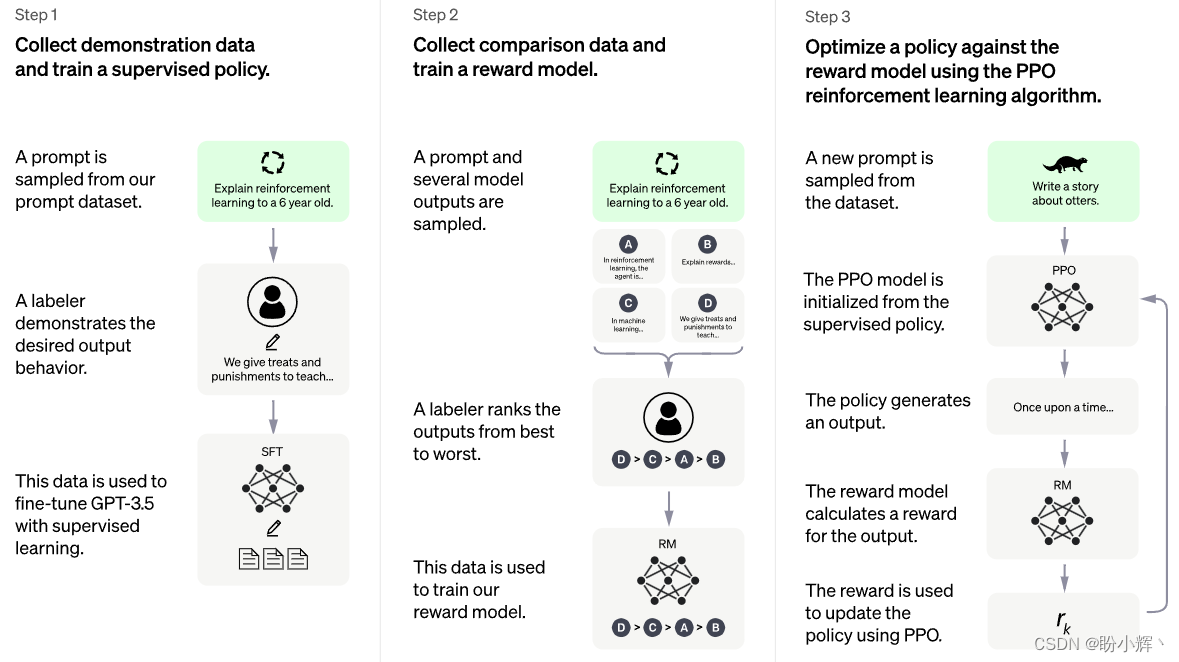
AIGC实战——Transformer模型
AIGC实战——Transformer模型 0. 前言1. T52. GPT-3 和 GPT-43. ChatGPT小结系列链接 0. 前言
我们在 GPT (Generative Pre-trained Transformer) 一节所构建的 GPT 模型是一个解码器 Transformer,它逐字符地生成文本字符串,并使用因果掩码只关注输入字…
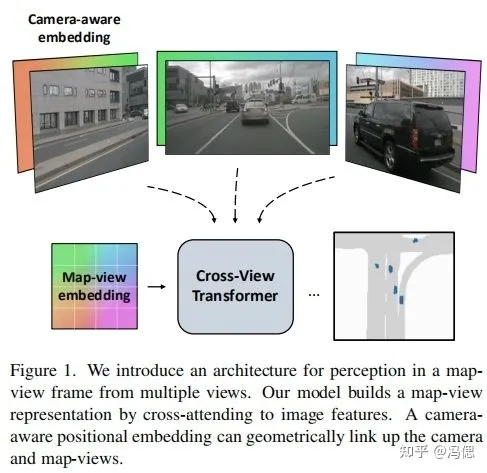
基于BEV的自动驾驶会颠覆现有的自动驾驶架构吗
基于BEV的自动驾驶会颠覆现有的自动驾驶架构吗 引言
很多人都有这样的疑问–基于BEV(Birds Eye View)的自动驾驶方案是什么?这个问题,目前学术界还没有统一的定义,但从我的开发经验上,尝试做一个解释:以鸟瞰视角为基础…

TrOCR—基于Transformer的OCR入门
导 读 本文主要介绍TrOCR:基于Transformer的OCR入门。
背景介绍 多年来,光学字符识别 (OCR) 出现了多项创新。它对零售、医疗保健、银行和许多其他行业的影响是巨大的。尽管有着悠久的历史和多种最先进的模型,研究人员仍在不断创新。与深…

文献阅读笔记(Transformer)
文献阅读笔记(Transformer) 摘要Abstract1、文献阅读1.1 文献题目1.2 文献摘要1.3 研究背景1.4 模型架构1.4.1 Encoder-Decoder1.4.2 注意力机制1.4.3 多头注意力1.4.4 Position-wise Feed-Forward Networks1.4.5 Embeddings and Softmax1.4.6 Positiona…
HuggingFace踩坑记录-连不上,根本连不上
学习 transformers 的第一步,往往是几句简单的代码
from transformers import pipelineclassifier pipeline("sentiment-analysis")
classifier("We are very happy to show you the 🤗 Transformers library.")
""&quo…

目标点注意力Transformer:一种用于端到端自动驾驶的新型轨迹预测网络
目标点注意力Transformer:一种用于端到端自动驾驶的新型轨迹预测网络
附赠自动驾驶学习资料和量产经验:链接
摘要
本文介绍了目标点注意力Transformer:一种用于端到端自动驾驶的新型轨迹预测网络。在自动驾驶领域中,已经有很多…
[Attention IS All You Need]Transformer模型有哪些变种
前言及引子 Transformer by google 2017
笔者写下此系列文章是希望在复习人工智能相关知识同时为想学此技术的人提供一定帮助。
本来计划本文接着之前的系列写transformer架构的原理的,但是我觉得transfomer是一个智慧、重要且有些复杂的架构,不先再次…

Note-模型的特征学习过程分析
模型的学习过程
将数据的特征分为,有用特征和无用特征(噪声).有用特征与任务有关,无用特征与任务无关. 模型的学习过程就是增大有用特征的权重并减少无用特征的权重的过程. 神经网络反向传播过程简化如下: y a 0 x 0 a 1 x 1 , l o s s 0.5 ∗ ( y l a b e l − y ) 2 y …
Transformer架构的自注意力机制
自注意力机制(Self-Attention),有时也称为内部注意力机制,是Transformer架构的核心。它是一种允许输入序列中的每个位置都能够考虑到序列中所有其他位置的机制,这样能够在每个位置捕获全局的上下文信息。自注意力机制使…
Latent Diffusion Transformer for Probabilistic Time Series Forecasting
Latent Diffusion Transformer for Probabilistic Time Series Forecasting
摘要:多元时间序列的概率预测是一项极具挑战性但又实用的任务。本研究提出将高维多元时间序列预测浓缩为潜在空间时间序列生成问题,以提高每个时间戳的表达能力并使预测更易于管理。为了解决现有工…
遥感影像处理利器:PyTorch框架下CNN-Transformer,地物分类、目标检测、语义分割和点云分类
目录
专题一 深度卷积网络知识详解
专题二 PyTorch应用与实践(遥感图像场景分类)
专题三 卷积神经网络实践与目标检测
专题四 卷积神经网络的遥感影像目标检测任务案例【FasterRCNN】
专题五 Transformer与遥感影像目标检测
专题六 Transformer的遥…
Transformer架构顶层应用的基础知识
Transformer架构自从2017年被提出以来,已经在自然语言处理(NLP)和其他领域成为了一种革命性的模型结构。它不仅在各种NLP任务中取得了突破性的表现,也被扩展应用于图像处理、音频处理等领域。理解Transformer架构及其顶层应用的基…

transformer上手(1) —— transformer介绍
1 起源与发展
2017 年 Google 在《Attention Is All You Need》中提出了 Transformer 结构用于序列标注,在翻译任务上超过了之前最优秀的循环神经网络模型;与此同时,Fast AI 在《Universal Language Model Fine-tuning for Text Classificat…
交叉注意力融合时域、频域特征的FFT + CNN -Transformer-CrossAttention电能质量扰动识别模型
往期精彩内容:
电能质量扰动信号数据介绍与分类-Python实现-CSDN博客
Python电能质量扰动信号分类(一)基于LSTM模型的一维信号分类-CSDN博客
Python电能质量扰动信号分类(二)基于CNN模型的一维信号分类-CSDN博客
Python电能质量扰动信号分类(三)基于Transformer…
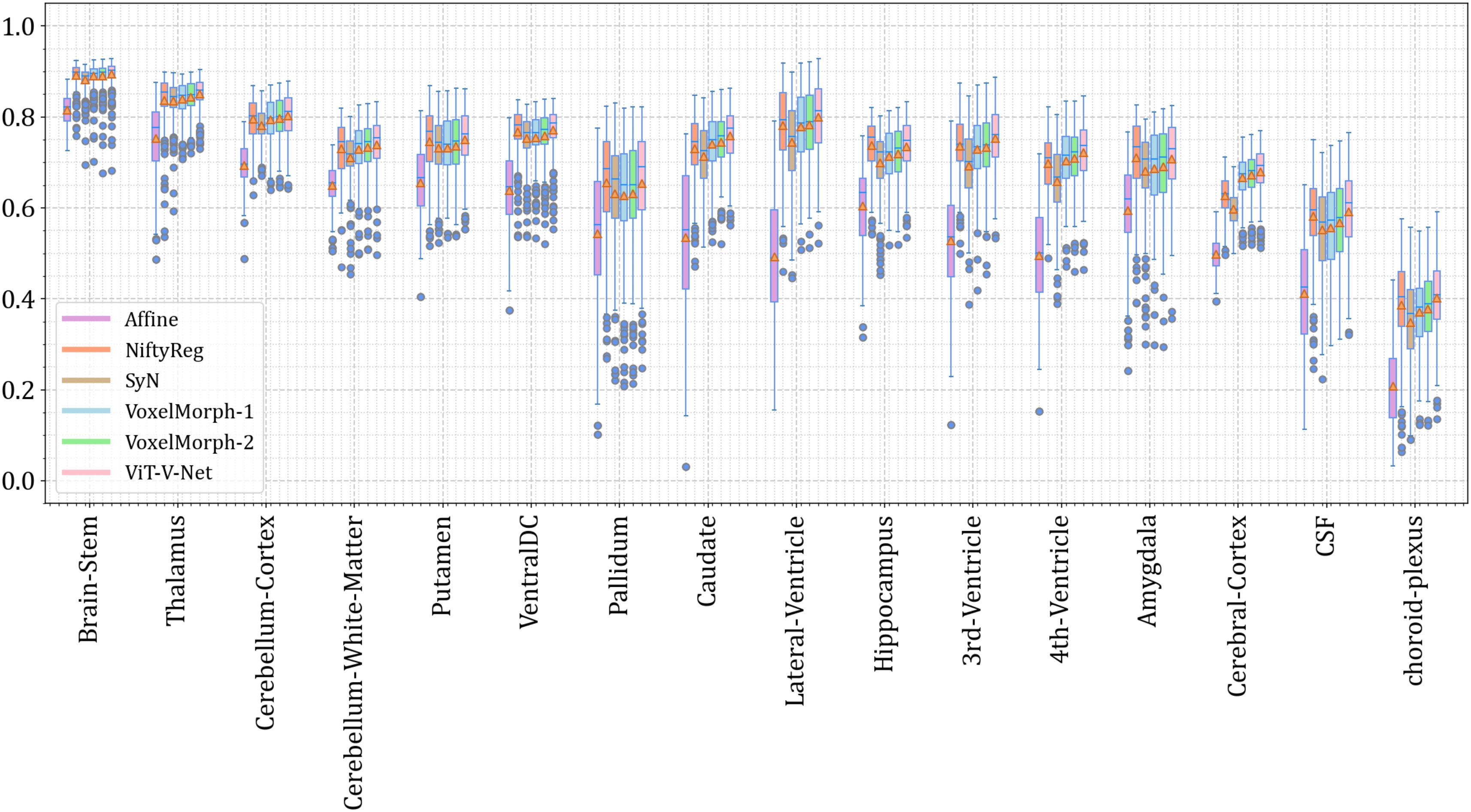
3D医疗图像配准 | 基于Vision-Transformer+Pytorch实现的3D医疗图像配准算法
项目应用场景 面向医疗图像配准场景,项目采用 Pytorch ViT 来实现,形态为 3D 医疗图像的配准。
项目效果 项目细节 > 具体参见项目 README.md (1) 模型架构 (2) Vision Transformer 架构 (3) 量化结果分析 项目获取 https://download.csdn.net/down…

transformer上手(2) —— 注意力机制
自从 2017 年 Google 发布《Attention is All You Need》之后,各种基于 Transformer 的模型和方法层出不穷。尤其是 2018 年,OpenAI 发布的 GPT 和 Google 发布的 BERT 模型在几乎所有 NLP 任务上都取得了远超先前最强基准的性能,将 Transfor…
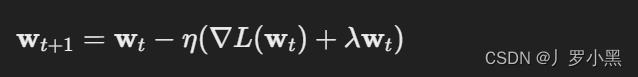
场景文本检测识别学习 day02(AlexNet论文阅读)
怎么读论文
在第一遍阅读的时候,只需要看题目,摘要和结论,先看题目是不是跟我的方向有关,看摘要是不是用到了我感兴趣的方法,看结论他是怎么解决摘要中提出的问题,或者怎么实现摘要中的方法,然…
场景文本检测识别学习 day02(AlexNet论文阅读、ResNet论文精读)
怎么读论文
在第一遍阅读的时候,只需要看题目,摘要和结论,先看题目是不是跟我的方向有关,看摘要是不是用到了我感兴趣的方法,看结论他是怎么解决摘要中提出的问题,或者怎么实现摘要中的方法,然…
![[开源] 基于transformer的时间序列预测模型python代码](https://img-blog.csdnimg.cn/direct/a9e682f5b24949579e45c1604aaa9d4d.png)
[开源] 基于transformer的时间序列预测模型python代码
分享一下基于transformer的时间序列预测模型python代码,给大家,记得点赞哦
#!/usr/bin/env python
# coding: 帅帅的笔者import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import time
import math
import matplotlib.pyplo…

【深度学习|基础算法】初识Transformer-encoder-decoder
关于transformer的学习 一、前言二、初识Transformer2.1 总览2.2 encoder2.3 decoder 三. 流程与细节1、输入2、self-attention 一、前言 我本身是从事图像算法行业的,在之前主要是做传统的图像算法,后来接触了基于CNN的神经网络图像算法,包括…
![[从0开始AIGC][Transformer相关]:算法的时间和空间复杂度](https://img-blog.csdnimg.cn/img_convert/28f9da9b3e171eaf456b2974d0ff1a6f.webp?x-oss-process=image/format,png)
[从0开始AIGC][Transformer相关]:算法的时间和空间复杂度
一、算法的时间和空间复杂度 文章目录 一、算法的时间和空间复杂度1、时间复杂度2、空间复杂度 二、Transformer的时间复杂度分析1、 self-attention 的时间复杂度2、 多头注意力机制的时间复杂度 三、transformer的空间复杂度 算法是指用来操作数据、解决程序问题的一组方法。…
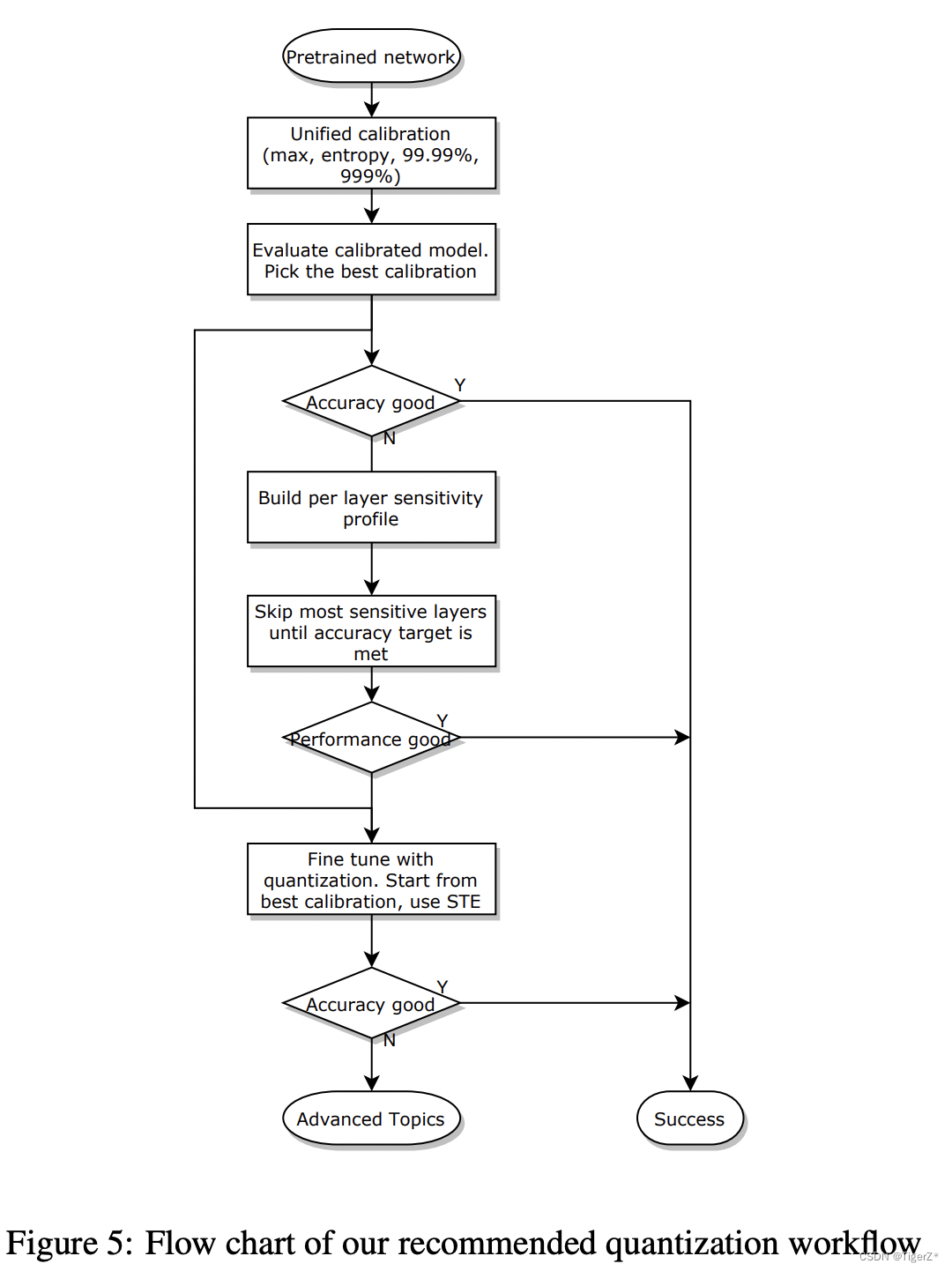
模型量化——NVIDIA——方案选择(PTQ、 partialPTQ、 QAT)
PTQ、 partialPTQ、 QAT 选择流程 PTQ、 partialPTQ、 QAT 咨询NVIDIA 官方后,他们的校正过程一致,支持的量化算子本质是一样的,那么如果你的算子不是如下几类,那么需要自己编写算子。参考TensorRT/tools/pytorch-quantization/py…
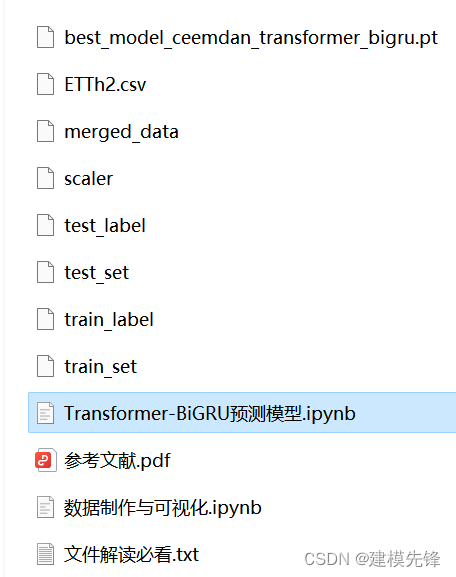
VMD + CEEMDAN 二次分解,Transformer-BiGRU预测模型
创新点:二次分解 多头注意力特征融合 往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较-CSDN博客
风速预测(一)数据集介绍和预处理-CSDN博客
风速预测(二)基于Py…
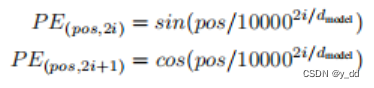
【自然语言处理八-transformer实现翻译任务-一(输入)】
自然语言处理八-transformer实现翻译任务-一(输入) transformer架构数据处理部分模型的输入数据(图中inputs outputs outputs_probilities对应的label)以处理英中翻译数据集为例的代码 positional encoding 位置嵌入代码 鉴于transfomer的重要性…
Transformer详解和知识点总结
目录 1. 注意力机制1.1 注意力评分函数1.2 多头注意力(Multi-head self-attention) 2. Layer norm3. 模型结构4. Attention在Transformer中三种形式的应用 论文:https://arxiv.org/abs/1706.03762 李沐B站视频:https://www.bilibi…